Codex Hits 5M Weekly Users as Devin Desktop Launches, Anthropic Teases "Oceanus" Model
AI coding tools are having their breakout moment, with OpenAI's Codex surging to 5 million weekly users and Cognition launching Devin Desktop to reimagine the IDE as an agent orchestration surface. Meanwhile, Anthropic appears ready to ship a new Mythos-level model codenamed "Oceanus," Nvidia assembled a Nemotron Coalition with Nous Research, and DeepSeek v4 ran locally on a MacBook via SSD streaming.
Daily Wrap-Up
If there was one theme that dominated today's AI discourse, it was the sheer velocity at which AI coding tools are going mainstream. OpenAI's Codex jumped from 600,000 to 5 million weekly users seemingly overnight, a growth curve that @zenorocha noted was driven in part by ChatGPT adding branded links in answers rather than burying citations. That shift means agents are now choosing the tech stack, and as @lennysan put it, there is "so much alpha right now in being Codex or Claude Code's tool of choice." The ecosystem is expanding fast too, with new plugins for QA workflows in Claude Code, iOS app building inside Codex, and git worktree support for parallel agent work in OpenCode. Scott Wu at Cognition went even further, declaring that standalone IDEs have about six months left and unveiling Devin Desktop as a unified surface for managing fleets of local and cloud agents.
On the model front, things are heating up just as dramatically. @kimmonismus reported that Anthropic is preparing to launch a Mythos-level model codenamed "Oceanus," with pricing at $16 per million input tokens and $80 per million output tokens, potentially landing in the same week as GPT-5.6. @antirez showed DeepSeek v4 Pro running its 1.6 trillion parameters on a MacBook M5 Max via SSD streaming, a feat that would have seemed absurd a year ago. Nvidia pulled together a Nemotron Coalition with Nous Research and others to advance open frontier models. And in a somewhat unnerving corporate blog post, Anthropic shared internal data suggesting Claude is accelerating AI development toward recursive self-improvement faster than expected.
The most practical takeaway for developers: start investing in "context engineering" skills now. As @mattpocockuk framed it, the core discipline is managing the tradeoff between expensive but rich primary sources (raw code, transcripts) and cheaper but lossy secondary sources (summaries, compactions). This is the foundational skill that underpins effective agent orchestration, dynamic workflows, and everything else happening in the coding tools space.
Quick Hits
- @GoogleResearch introduced a passive heart rate monitoring system using smartphone front-facing cameras that achieves clinical-grade accuracy across all skin tones during everyday phone use.
- @atmoio shared Palantir CEO Alex Karp's assessment that AI models solve a "myriad of problems" while creating "an even bigger amount of problems they create," one of the more honest executive summaries of the current moment.
- @nexta_tv posted a video of a Chinese robot wearing a clown wig kicking a child in the stomach. The less said about this, the better.
AI Coding Tools Reshape the Entire Developer Stack
The numbers tell the story. Codex went from 600,000 to 5 million weekly users, and that growth is reshaping which products win and lose. @zenorocha observed that their OpenAI traffic tripled once ChatGPT started surfacing branded links, but the bigger story is that autonomous coding agents are now making technology choices on behalf of their users. @lennysan captured the implication crisply: "So much alpha right now in being Codex / Claude Code's tool of choice."
Scott Wu at Cognition took the most aggressive stance of the day, arguing that standalone IDEs have perhaps six months of relevance left. "An interface for manually editing and refactoring doesn't need to exist if you're not manually editing and refactoring anymore," he wrote. His answer is Devin Desktop, a product born from Cognition's acquisition of Windsurf that serves as a unified command surface for managing fleets of local and cloud agents. The idea is that developers need a clean interface for spinning up parallel agents, monitoring their progress, and dropping into the code only for last-mile fixes and review.
The tooling ecosystem around these coding agents is maturing fast. @danshipper highlighted a new hands-off QA plugin for Claude Code from Compound Engineering that automatically tests the branch you just built. @gakonst shared that Codex now has a Build iOS Apps plugin that lets the agent view and test your iOS app inside the tool. And @opencode showcased git worktree support for doing parallel work with multiple agents simultaneously.
Model Wars Heat Up: Oceanus, DeepSeek v4, and the Nemotron Coalition
The frontier model race is intensifying on multiple fronts. @kimmonismus reported that Anthropic appears ready to publicly launch a new Mythos-level model codenamed "Oceanus," with pricing set at $16 per million input tokens and $80 per million output tokens. The model was reportedly given to red teamers recently but had access paused after someone began reselling it through a Chinese API proxy. The launch could come as soon as the same week as GPT-5.6, which would set up a direct competitive showdown.
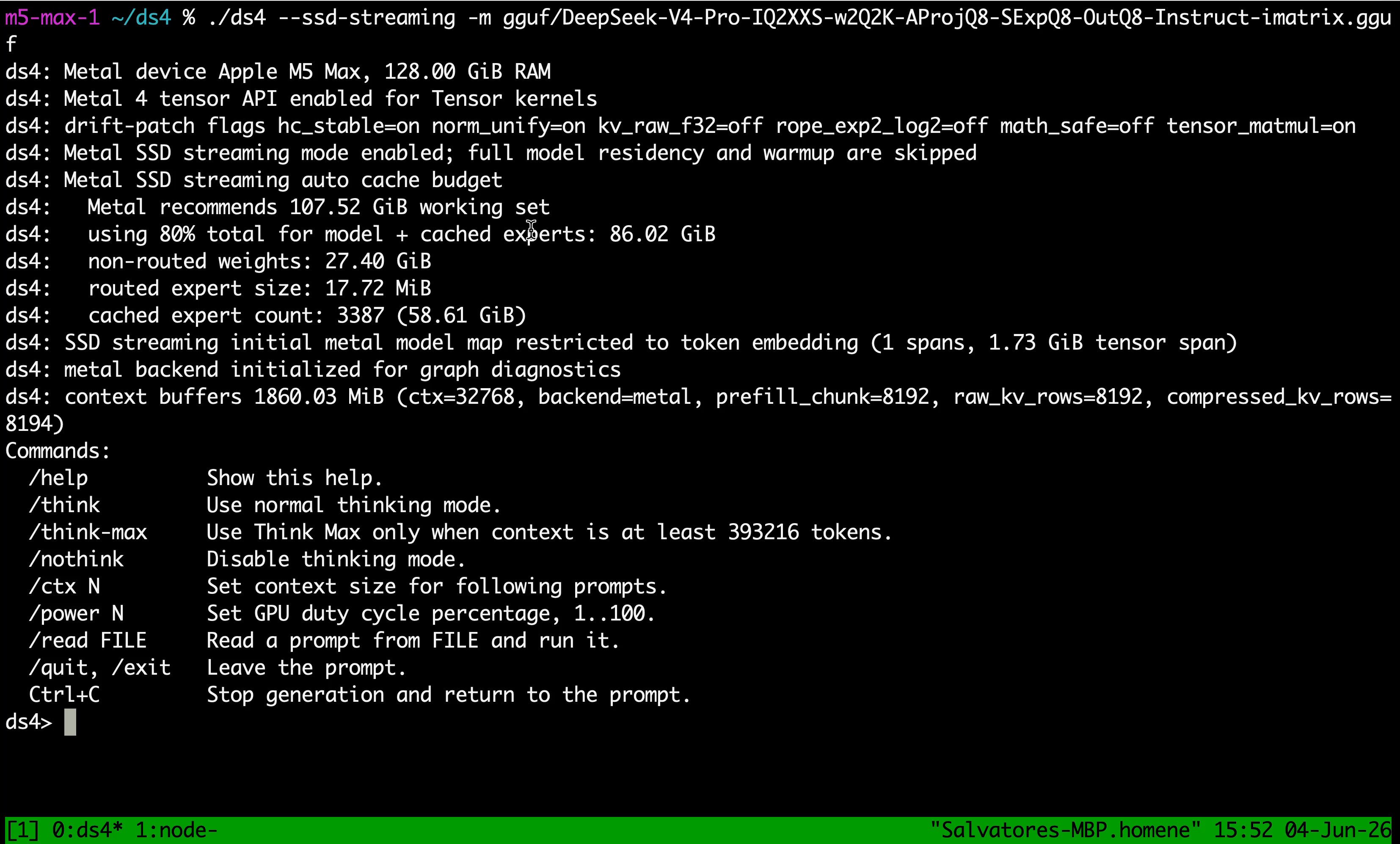
Meanwhile, @antirez demonstrated that the definition of "local AI" keeps expanding. He ran DeepSeek v4 Pro, all 1.6 trillion parameters of it, on a 128GB MacBook M5 Max using SSD streaming. The sheer scale of running a trillion-parameter model on consumer hardware signals that the gap between cloud and local inference is narrowing in ways that matter for latency-sensitive and privacy-conscious applications.
On the open model front, @NousResearch announced they are joining Nvidia's Nemotron Coalition, a group of leading AI labs collaborating on open frontier foundation models. To mark the occasion, they partnered with Nvidia and Nebius to offer two free weeks of the new Nemotron 3 Ultra model. @PiotrZelasko also revealed Nemotron-3.5-ASR-Streaming, supporting 40 languages with controllable latency between 80ms and 1 second, and capable of handling 240 to 2,400 concurrent streams on a single H100.
Perhaps the most thought-provoking post came from Anthropic itself. The company shared that internal data shows Claude is accelerating AI development, potentially pointing toward recursive self-improvement. "It's happening faster than we thought, and the implications deserve greater attention," they wrote. @JasonBotterill's blunt reaction, "Anthropic employees are fucking depressed," suggests the mood inside the company is complicated.
Agents Get Workflows, Skills, and Generative Faces
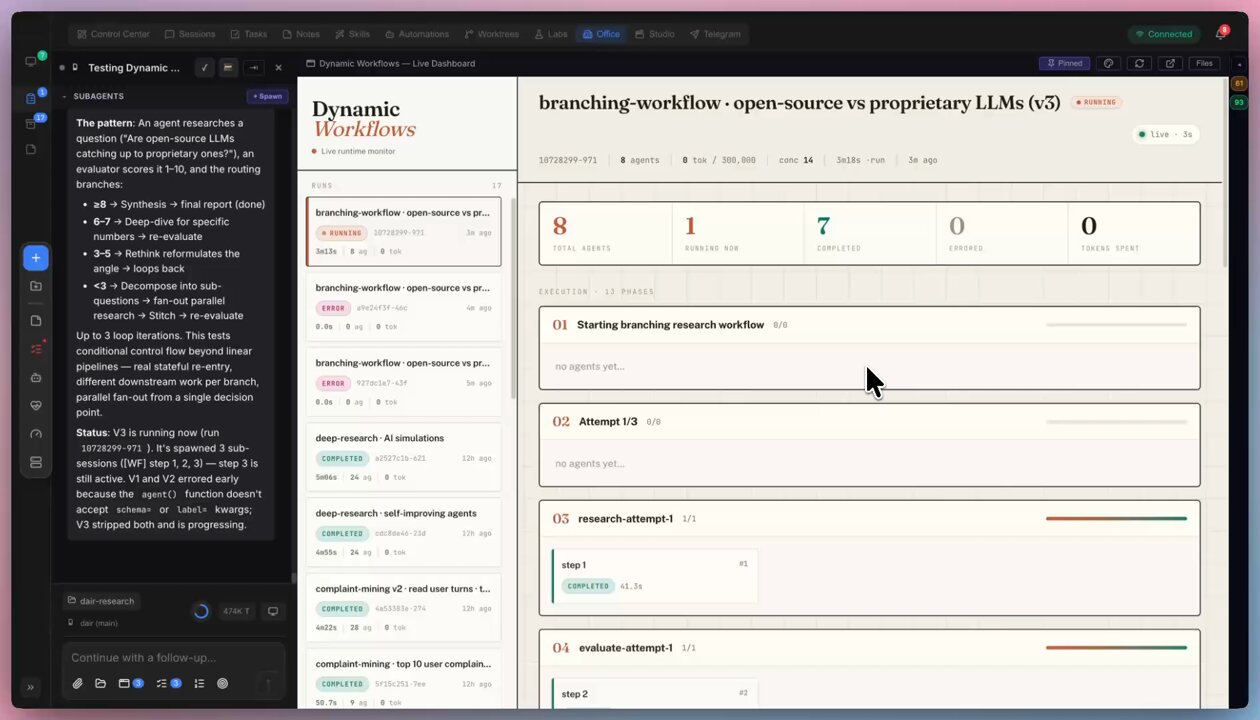
The conversation around AI agents is shifting from individual capabilities to orchestration primitives. @omarsar0 shared an extensive breakdown of "dynamic workflows," which he describes as generating harnesses on the fly for complex, long-running tasks. He built a monitoring dashboard to track tasks, metrics, and reports across coding agents like Claude Code, Codex, Pi, and custom agents. His use cases range from branching deep research tasks with verification to parallel research, session mining, bug hunting, triaging, fact-checking, and even LLM councils. "Dynamic workflows, like agent skills, feel like an important primitive to not only get the most out of agents but also incorporate dynamic behaviors and important components like cooperation and verification," he wrote.
The skill library concept got a boost from @MatthewBerman, who endorsed the idea that every company's first AI strategy should be building a centralized, versioned skill library. This aligns with the broader trend of treating agent capabilities as composable, reusable artifacts rather than one-off prompts.
On the interface side, @Saboo_Shubham_ argued that generative UI is the next frontend paradigm. "AI Agents need generative UI to EXPRESS not another paragraph of text," he wrote. The insight is that as agents become more capable, the bottleneck shifts from what they can do to how effectively they can communicate their reasoning and results. Structured, dynamic visual interfaces beat walls of text for agent-to-human communication.
The Emerging Discipline of AI Engineering
Two posts today crystallized just how much the discipline of building with LLMs has matured. @divaagurlxw posted an extraordinarily comprehensive list of what AI engineers actually need to know, and it reads more like a systems engineering curriculum than a prompt engineering guide. The list covers context engineering, prompt caching tradeoffs, KV cache management, prefill versus decode latency optimization, continuous batching, speculative decoding, quantization formats from INT4 to FP8, structured output failure handling, function calling reliability, agent guardrails, model routing and fallback logic, RAG architecture, retrieval evaluation, LLM observability as a first-class discipline, cost attribution per feature and tenant, and production failure modes ranging from hallucinated tool calls to runaway agents.
@mattpocockuk offered a cleaner conceptual framework with his context engineering metaphor. He distinguishes between primary sources, the raw code, transcripts, and original data, and secondary sources, the summaries, compactions, and documentation that sit one step removed. Loading primary sources into context is expensive but rich. Secondary sources are cheaper but lossy. "Any context engineering will involve managing the tradeoffs between both," he wrote. It is a simple but powerful mental model for thinking about how to feed information to agents efficiently.
Coding Agents Under Attack: The Sentry Exploit
@sergeykarayev detailed a genuinely novel attack vector targeting applications that use coding agents. The exploit works by sending a fake bug report to a project's Sentry integration using only the app's public Data Source Name. When a coding agent attempts to fix the reported bug, the fake error payload tricks the agent into installing a compromised NPM package, which then exfiltrates the machine's environment variables to an attacker-controlled domain. "This highlights a crucial thing for using agents in an automated way," he noted. The attack is elegant in its simplicity: it exploits the trust that coding agents place in external error reporting systems, and it requires virtually no direct access to the target infrastructure. As agents become more autonomous and integrated into CI/CD pipelines, this class of indirect prompt injection through operational tooling will only become more dangerous.
Sources
Introducing Devin Desktop: the next generation of Windsurf Manage fleets of local and cloud agents from one surface Support for any ACP-compatible agent With a full IDE for when you need to jump into the code


Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor. It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
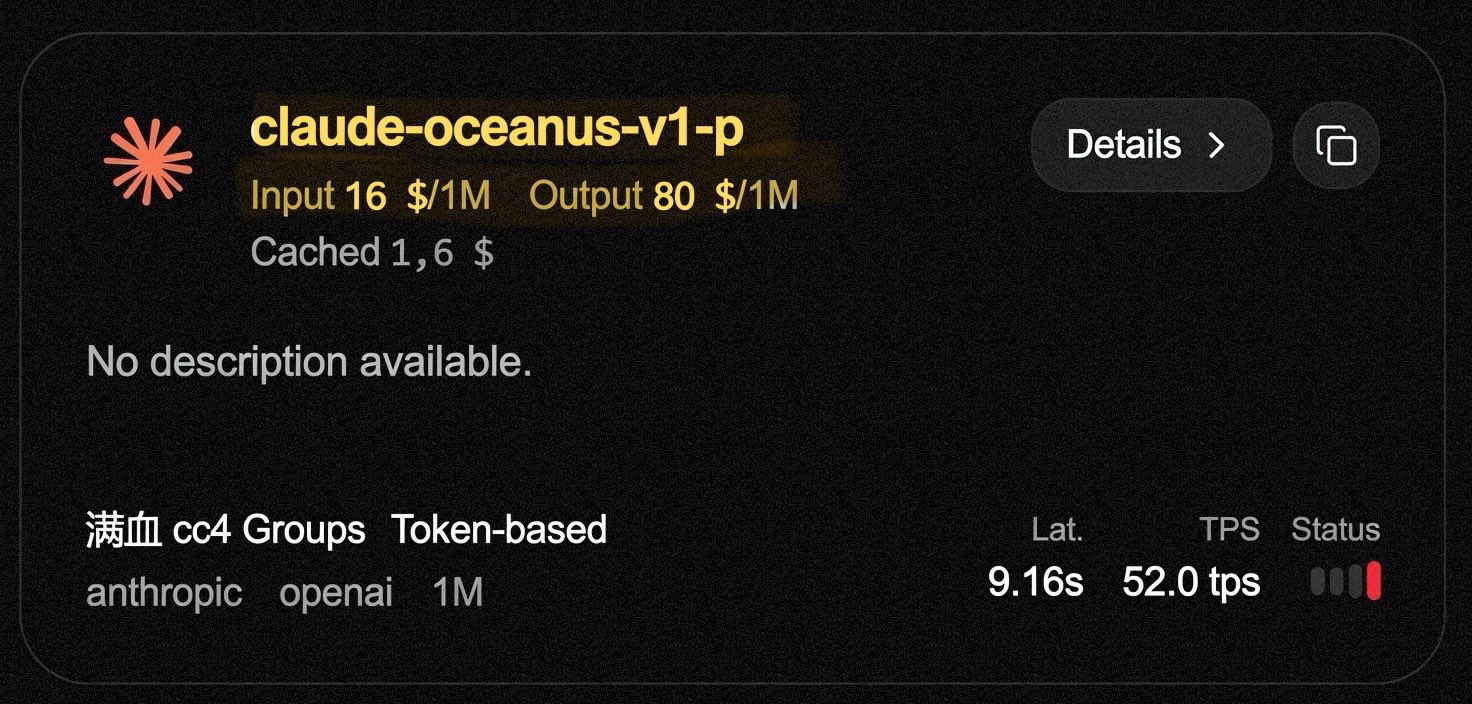
‼️it seems Anthropic is ready to publicly launch a new version of Mythos, something better than Mythos Preview. a codenamed model “Oceanus” was given access to some red teamers yesterday according to @synthwavedd. it’s apparently been paused already, due to someone reselling access through a Chinese API proxy lmao 💀 Mythos pricing might also end up at with $16 Input, $80 Output according to @scaling01
Generative UI Is the New Frontend


our OpenAI traffic 3x'd. the cause: ChatGPT added branded links inside answers instead of burying them in citations.¹ but that's the small story. Codex went from 600k to 5m weekly users.² agents are choosing the stack now. https://t.co/ieJdzsTU3U

Every Company’s First AI Strategy Should Be a Skill Library
