Multi-Agent Coding Pipelines Mature as Edge Inference Hits Raspberry Pi and AI Careers Diverge
The AI development landscape is shifting toward sophisticated multi-agent workflows, with Uncle Bob Martin detailing a full pipeline from specification to mutation testing. Meanwhile, DeepSeek-V4-Flash running on a Raspberry Pi signals that edge inference is becoming practical, and Andrew Ng maps the emerging split between Forward Deployed Engineers and AI Engineers.
Daily Wrap-Up
June 2, 2026 brought a clear signal that multi-agent development workflows have graduated from experimental to operational. The most striking example came from @unclebobmartin, who laid out a complete pipeline where specialized agents handle specification, coding, refactoring, and architecture review in sequence, with human oversight decreasing at each stage. This was not theoretical. He described the exact handoff points, testing strategies, and mutation testing passes that make the system work. Combined with @zodchiii sharing an Anthropic engineer building five focused agents in 45 minutes on camera, and @_jonatasantos posting a detailed build-anything playbook using Hermes with memory vaults, the picture is clear: solo developers and small teams are assembling multi-agent systems that handle work previously requiring entire engineering departments.
The enterprise side of the conversation was equally revealing. @levie used the Kirkland law firm's $500M bet on custom AI tools as a launching point to argue that competitive advantage now lives in institutional knowledge and domain-specific workflows, not in the models themselves. @gabepereyra, who co-founded Harvey, confirmed this view from the vendor side, noting that speed-running to enterprise platform was the right call from day one. The tension between building custom AI tools versus adopting vendor solutions is playing out across every industry, and the answer seems to depend on whether your data is actually differentiated or just feels that way.
The most practical takeaway for developers: start building your personal multi-agent workflow now. Pick one repetitive daily task, wrap an agent around it, and iterate. As @_jonatasantos put it, define clear evals, save learnings to memory, and develop a feeling for how long tasks should take. The developers who build muscle memory with agent orchestration today will have a significant edge as these tools mature.
Quick Hits
- @danveloper got DeepSeek-V4-Flash (284B params) running on a Raspberry Pi 5 at over 1 token per second using only 8 watts, a milestone for edge inference that took 160 experiments over 5 days to achieve.
- @0xSero shared a comprehensive guide to the best AI models by VRAM tier, highlighting LFM-2.5-8B as the standout for 8-16GB setups with its mixture-of-experts architecture and 131k context window.
- @malikwas1f shared UnslothAI's new guide on using the Model Context Protocol (MCP) with local LLMs like Qwen3.6 and Gemma 4 for controlled tool and API access.
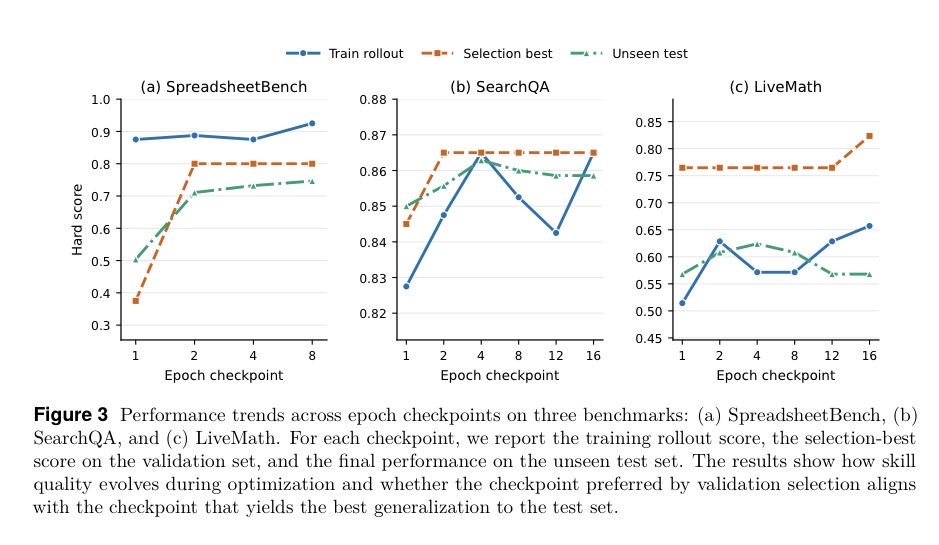
- @hooeem highlighted Microsoft's open-sourced SkillOpt, which trains self-evolving agent skills by making the skill document itself the optimization target, clearing strong baselines on SearchQA, Sheet, Office, and DocVQA benchmarks.
- @_djdumpling recommended a deep dive from @whatthelukh on asynchronous RL theory and infrastructure, surveying eight frontier labs on how they handle train-inference mismatch at scale.
- @Saccc_c reported on a vibe coder live-streaming product builds and clearing $20K per month, spending most of the revenue on Claude Max and Codex subscriptions while running six or seven terminals simultaneously.
- @10_Xeng gave a shoutout to @dthakur for impressive robotics content that deserves way more than 500 followers.
- @steipete configured Codex to call him via phone when it gets stuck during tasks like npm releases gated by 1Password, describing the voice notifications as "the coolest thing ever."
Multi-Agent Development Workflows Go Operational
The day's densest theme was the maturation of multi-agent coding systems, with four posts detailing how developers are orchestrating specialized AI agents to handle the full software development lifecycle. What makes this moment different from earlier automation attempts is the granularity of the handoffs and the specificity of the testing regimes.
@unclebobmartin provided the most detailed blueprint. His pipeline starts with informal hand-written specifications that an agent converts into harder, subdivided tasks. From there, a specifier agent converts each task to Gherkin, prunes it, and hands off to a coder agent. The coder writes acceptance tests directly from the Gherkin, then unit tests, then code. When tests pass, the result goes to a refactorer agent that reduces complexity and writes property tests. Finally, an architect agent runs language mutation and Gherkin mutation testing, killing any survivors before running the full suite. As he described it: "This is an exercise of transformations from the informal to the formal through managed stages, with human interaction decreasing with each stage." The limiting factor is raw compute, since mutation tests eat CPU cycles fast.
@_jonatasantos offered a complementary but more accessible approach with his "how to build anything right now" playbook. His stack involves Hermes hosted on a VPS with a custom memory vault using qmd and SQL, GPT-5.5 in fast mode for execution, and a structured process of deep research, grilling sessions to uncover unknowns, and iterative building against defined evals. The key insight is that saving learnings to memory throughout the process creates a compounding knowledge base that makes future sessions more effective. His advice to "pay attention to the process" and "develop a feeling for how long tasks should take" is the kind of tacit knowledge that separates productive agent use from expensive spinning.
@zodchiii amplified an Anthropic engineer who built five focused agents from scratch in 45 minutes on camera, each handling a daily manual task like code review, testing, and documentation. The barrier to building useful agents has dropped so low that the real competitive advantage lies in identifying which tasks to automate, not in the technical implementation.
@steipete showed the lighter side of agent autonomy, configuring Codex to phone him when it needs help with tasks like npm releases gated by 1Password. The image of an AI coding assistant literally calling its developer for help captures something essential about where we are: the agents are capable enough to know when they are stuck, and the human still holds the keys.
Enterprise AI Strategy and the Data Moat Debate
Three posts converged on the question of where competitive advantage lives when everyone has access to the same frontier models. The discussion was sparked by news that Kirkland & Ellis is spending $500M over four years to build custom internal AI legal tools, a move that @levie used as a springboard to articulate a broader strategic framework.
@levie argued that the companies best able to harness their institutional knowledge, existing data assets, and domain-specific workflows connected with AI will be the ones that stay ahead. At Box, he is seeing customers demand the flexibility to bring any AI model to their data at any time, rather than being locked into a single vendor's ecosystem. The Kirkland case illustrates the tension: building custom tools preserves control, but most enterprises lack the software development culture to execute well, and non-lawyers cannot be given equity in the firm due to regulation.
This point was sharpened by @fleetingbits in a quoted post that @levie engaged with, arguing that Kirkland likely does not have differentiated data compared to other elite firms, that cultural and structural issues make it hard for law firms to manage software developers, and that firms are better off using tools like Harvey and Legora while focusing on client relationships and legal R&D. He framed this as a broader phenomenon: "AI creates [unbundling] across a lot of industries, where firms that were previously vertically integrated become unbundled due to AI because part of the intelligence gets moved to the labs or otherwise gets commoditized."
@gabepereyra, who co-founded Harvey, confirmed the strategic calculus from the vendor side: "When we started Harvey we got a ton of advice to solve a specific legal workflow as a wedge but felt very strongly we had to speed run to law firm / in-house enterprise platform as fast as possible." The lesson extends beyond legal tech. In a world where AI commoditizes certain types of intelligence, the winning strategy is to build platforms that capture domain expertise across workflows, not point solutions that solve single tasks.
@businessbarista is launching a 30-day series on enterprise AI transformation observations, drawing from his experience co-running an enterprise AI firm with deep relationships across Anthropic, OpenAI, Lovable, Cursor, Perplexity, and Vercel. His promise of actionable, non-technical daily observations suggests the enterprise adoption conversation is moving past "what is AI" to "how do we actually deploy this at scale."
Local and Edge Inference Keeps Getting More Practical
The dream of running capable models on consumer hardware took several steps forward. @danveloper achieved what sounds impossible on paper: DeepSeek-V4-Flash, a 284 billion parameter model, running on a Raspberry Pi 5 with only 8GB of RAM at over 1 token per second while drawing roughly 8 watts. He used an unmodified GGUF file from @antirez and arrived at the solution after 160 experiments over 5 days, bouncing between GPT-5.5 xhigh and Opus 4.8 max for debugging help. This is less about the practical utility of a 1 tok/s model and more about what it signals for the trajectory of efficient inference. If a 284B model runs on a Raspberry Pi today, what runs on your laptop next year?
@0xSero provided the community-oriented counterpart with a detailed tier list of the best models for different hardware configurations. For the 8-16GB VRAM bracket, he highlighted LFM-2.5-8B as a standout: an 8 billion parameter mixture-of-experts model with only 1.5B active parameters, trained on 38 trillion tokens, with 131k context. He called it "truly a phenomenal piece of work" for GPU-poor users. At the high end, he pointed to Step-3.7-Flash at 199B with 11B active parameters, vision support, and 150 tok/s on 6000-series GPUs.
The local inference thread was rounded out by @malikwas1f sharing UnslothAI's guide on using MCP with local LLMs including Qwen3.6 and Gemma 4. The ability to connect locally running models to tools, files, and APIs through a standardized protocol removes one of the last advantages of cloud-based AI services. Together, these posts paint a picture of a rapidly closing gap between local and cloud AI capabilities.
AI Career Paths Diverge
Andrew Ng weighed in with a nuanced take on the emerging split between Forward Deployed Engineers and AI Engineers, a distinction that is becoming urgent as OpenAI and Anthropic both build FDE teams to embed within client organizations. Ng traced the FDE role back to Palantir's model of sending engineers to government locations on secure networks, noting that modern AI FDEs need communication and business skills alongside technical ability to navigate client relationships and push back on unrealistic requests.
However, Ng argued that AI Engineer roles will vastly outnumber FDE positions. Companies might accept a few embedded vendor engineers, but they will want far more of their own employees building on their own projects. He also flagged a key concern: FDEs are incentivized to tightly integrate their employer's product, which reduces a company's optionality at a time when it is impossible to predict which AI service will be best in twelve months. He sees surging demand for AI Engineers who can build applications using LLM prompting, agentic frameworks, and evals while effectively using coding agents like Claude Code, Codex, Antigravity CLI, and OpenCode. As the role matures, Ng expects it to fragment into specialized positions the way Software Engineer eventually split into frontend, backend, mobile, devops, and data engineering.
The Coming AI Memory Wars
@garrytan made a concise but provocative prediction about the next frontier of platform competition: "You should want to control and host your own memory. It's the one thing that you should be able to take to any platform. Watch for this to be a defining battle in the new browser war: the AI harness wars of 2027."
The framing of AI memory as the next battleground reframes the current competition between AI platforms. Models are increasingly commoditized. Context windows are growing. But the persistent memory that an AI assistant builds about your preferences, workflows, and knowledge is becoming the real lock-in mechanism. The platforms that own your AI memory own the switching cost. This connects directly to @_jonatasantos's memory vault approach and the broader push for local AI infrastructure. If your memory lives on your own server in a format you control, no platform can hold it hostage. Expect this to become a central tension in the next twelve months.
Sources

https://t.co/XKq6qBjLxY
https://t.co/8lOtmSSCGw
I WILL NOT STOP VIBE CODING UNTIL $1,000,000 Just crossed $16,646 MRR. Three months ago I was at $1,500. No investors. No employees. No safety net. Just me and a bunch of AI agents shipping every day. Here's what nobody tells you about consistency: it's boring. There's no secret. I show up, I build, I ship, and I do it again the next day. The results are starting to compound. And I'm just getting started. https://t.co/LKWKqN52F3


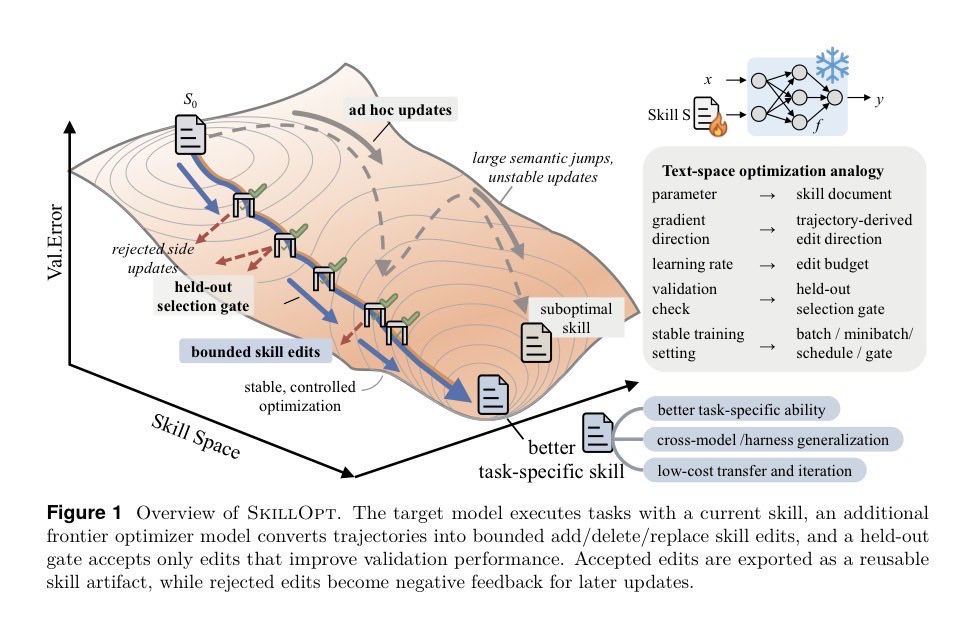
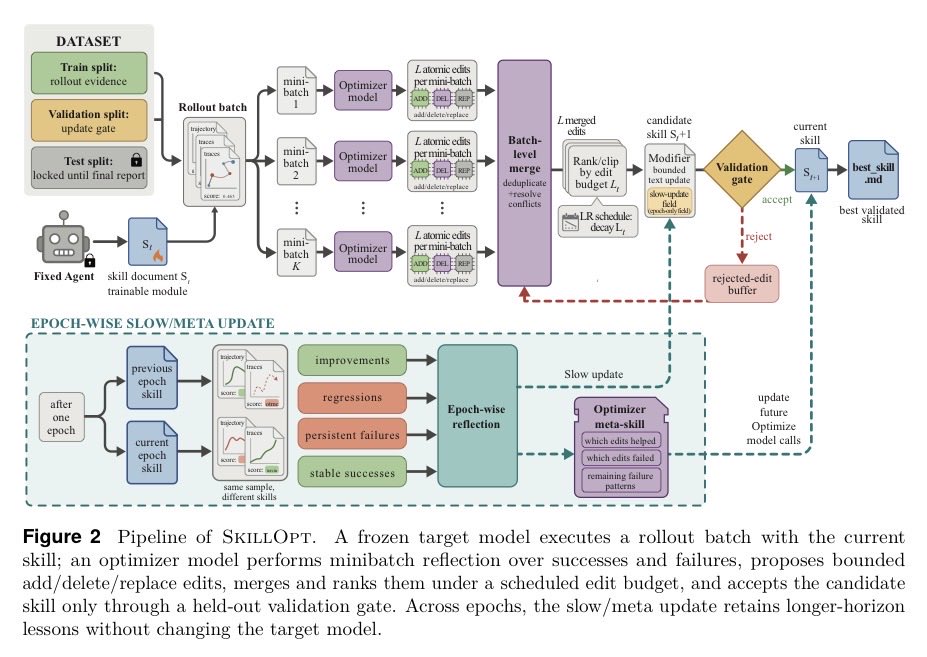
I want to create self-evolving agent skills.
New blog! Is frontier asynchronous RL solved? The blog covers Async RL theory and infrastructure, surveying 8 open-weight frontier labs for the algorithmic techniques and systems fixes to handle train-inference mismatch. Also answered: why do current methods still fail at high policy lag? Which methods scale with horizon and compute?
The Death of the Three-Act Playbook
Best models I’ve seen this week for your hardware: if you have 8-16gb you have a competitive model finally! ———- 4gb - 8gb: - minicpm5: this model was built for agentic tool use on tiny machines: https://t.co/LvNnIDSh7u - tops benchmarks in weight class - extremely small - great for using in projects with AI - blazing fast ———— 8gb - 16gb Most exciting model - LFM-2.5-8B: https://t.co/5SYi6D56FR Frontier for vram: - 8b moe with - 1.5B active - trained on 38T tokens (MASSIVE) - 131k context ————- 96GB - 128GB - ds4flash either q2 or reap + q4 https://t.co/BaphZfWrwG - or https://t.co/EAZB4bDYjA - very strong agent - logical pleasant to talk to - good in Hermes - fast - high contexts for little vram ————- 196gb+ Step-3.7-Flash: https://t.co/oaVf5wMILx - 199B with 11B active (FAST) - vision support! - its predecessor was topping benchmarks for 3 months - 256k context - 150 tok/s on 6000s
Motors and blades https://t.co/oAJ1SxxS28
some thoughts on kirkland building its own harvey 1) kirkland is spending $500m over four years in order to build its own internal ai legal tools; kirkland intends to spend $100m this year 2) i suspect that kirkland is doing this because they have told themselves that they have valuable data and because they want to appear differentiated 3) i think the first issue is that kirkland probably does not have differentiated data from other elite law firms; at least, not at the level a harvey would absorb 4) all the elite firms probably have similar internal workflow data and so long as some of them defect, that is enough to commoditize the data kirkland wants to use for its platform 5) and, to the extent that they do have different internal workflows, harvey and legora will end up representing a better version of them and this will put kirkland at a disadvantage 6) moreover, companies like kirkland will have difficulty building their internal legal platforms because they do not have experience with software development 7) and, there are both cultural and structural issues with them managing software developers, like they cannot give non-lawyers equity in the firm due to regulation 8) so, i think firms like kirkland are better off using tools like harvey and legora and then looking to focus on where their value really is now: client relationships, local knowledge (litigation, regulation) and legal r&d (novel structures, etc...) 9) anyway, this seems to me like a phenomenon that ai creates across a lot of industries, where firms that were previously vertically integrated become unbundled due to ai because part of the intelligence gets moved to the labs or otherwise gets commoditized 10) and so, a new set of companies are created whose job it is in order to provide services complementary to the labs: forward deployed like harvey and legora and data providers like mercor, surge and handshake