Agent Frameworks Ship Production-Ready Defaults as Token Optimization Saves Millions for Coding Agents
The conversation around AI agents shifted decisively from minimalist experimentation to production-ready tooling, with Teknium's Hermes Agent embracing opinionated defaults and Tencent releasing a sophisticated memory plugin. Meanwhile, developers shared concrete strategies for reducing token consumption in coding agents, and NVIDIA teased a new "superchip" for personal AI.
Daily Wrap-Up
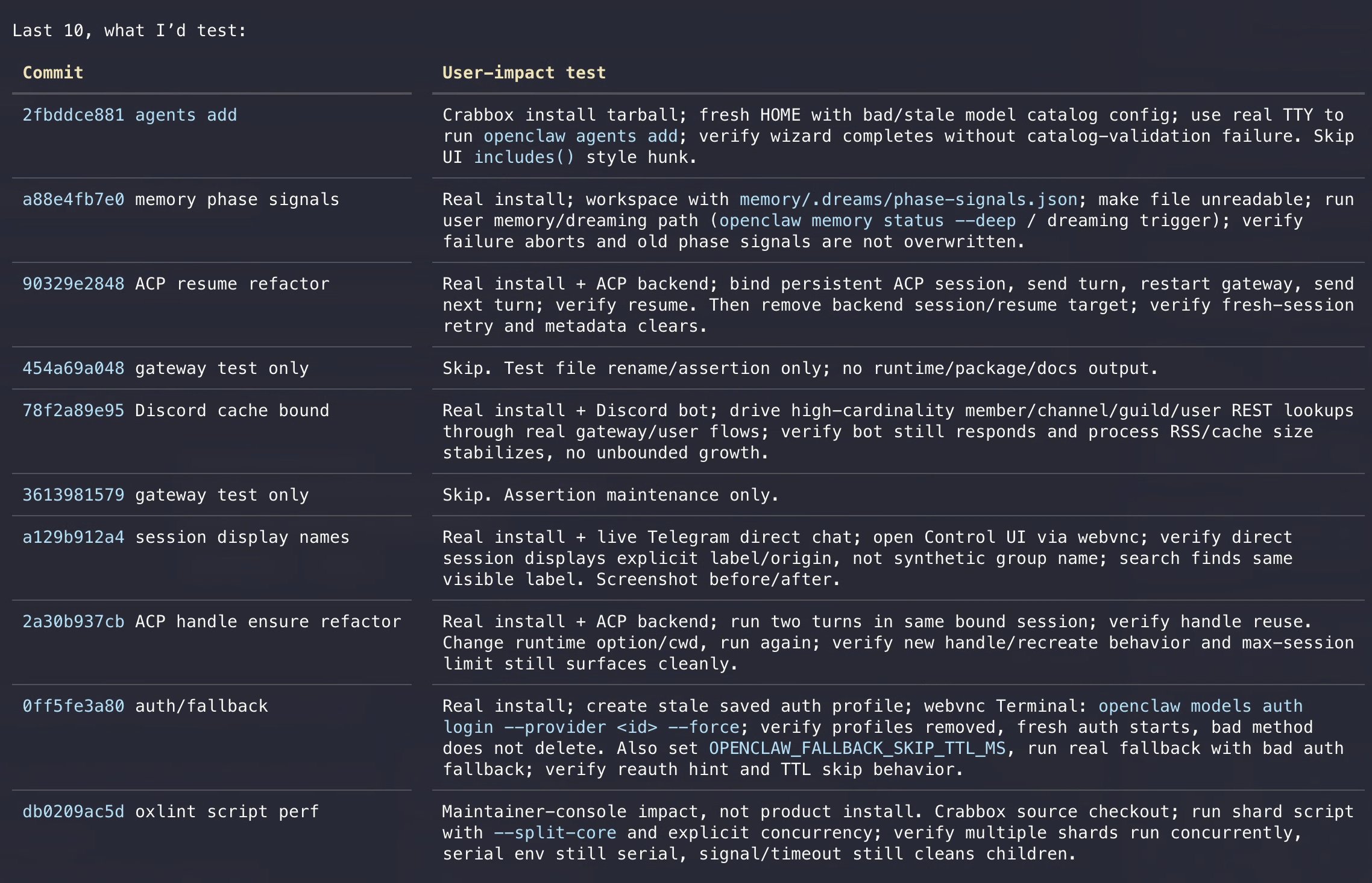
Something subtle but important shifted in the AI agent ecosystem today. For months, the prevailing wisdom in agent development has been "start minimal, build up." Blank-slate agents that force you to wire everything from scratch were seen as the pure, flexible approach. Teknium's candid post about Hermes Agent's design philosophy pushed back hard on that notion, arguing that most people don't want to become agent engineers. They want something that works. That tension between minimalism and usability ran through several posts today, from Tencent's feature-rich memory plugin to Peter Steinberger's automated QA agent that just runs in the background and opens PRs.
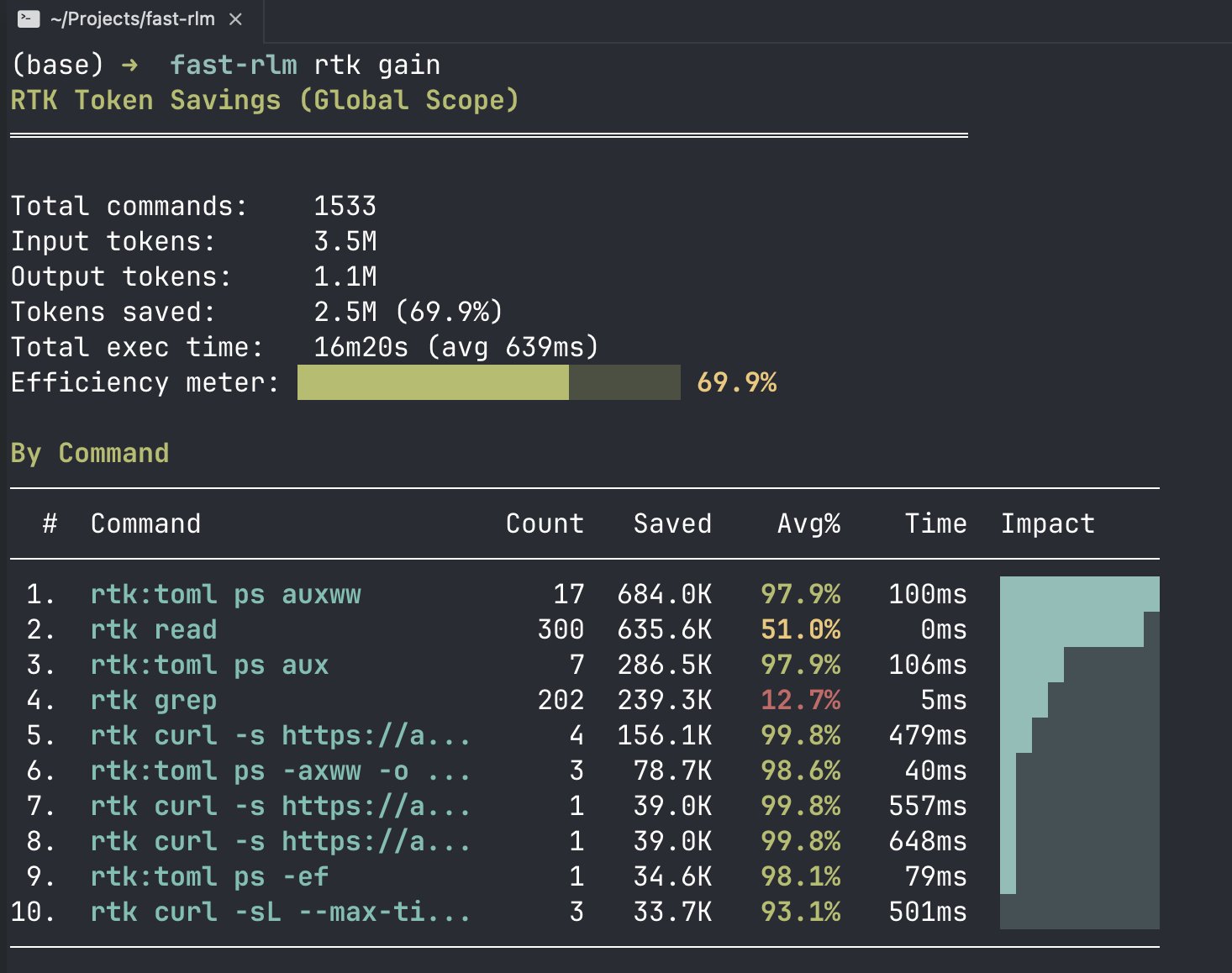
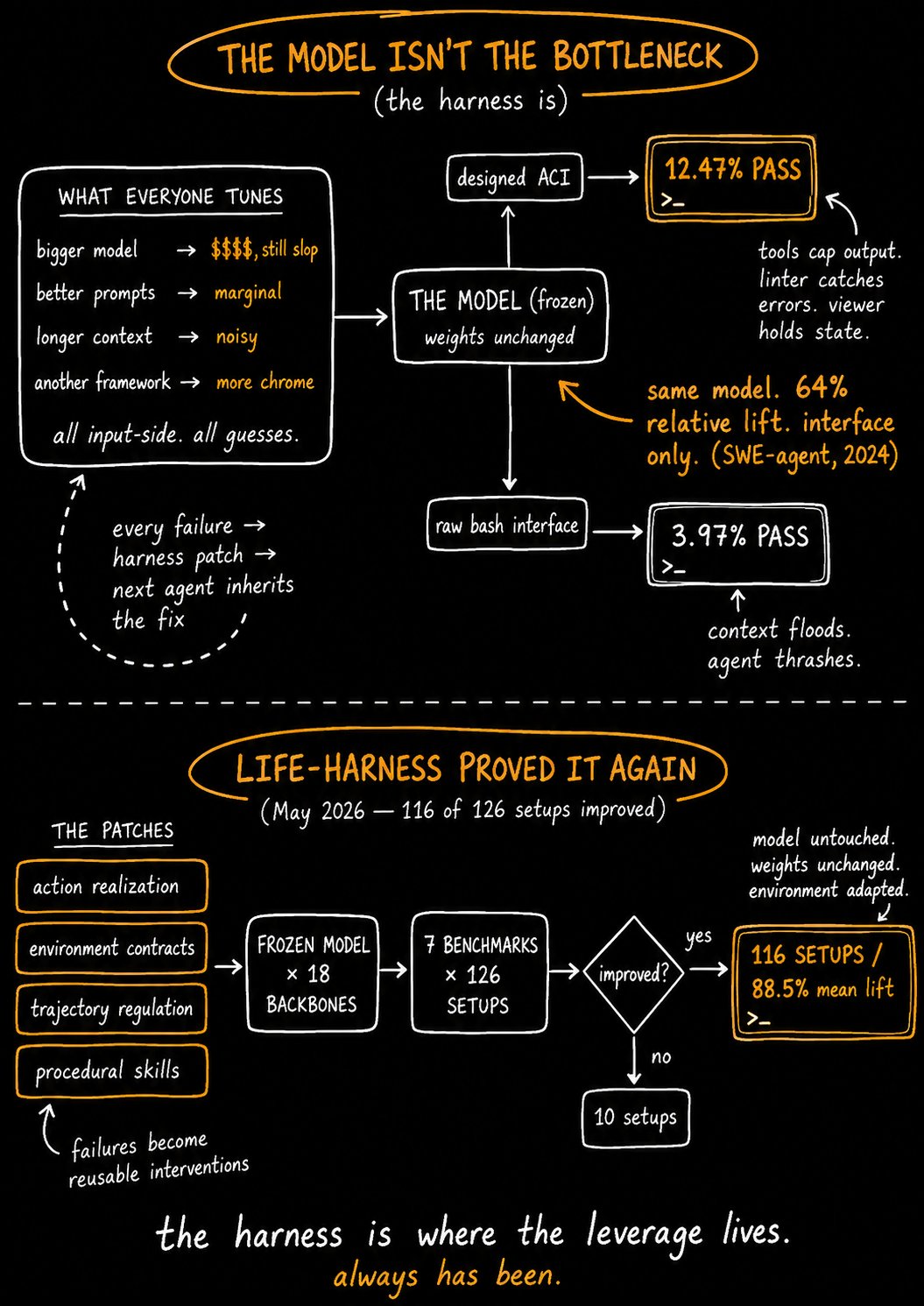
The second thread worth watching is the growing sophistication around coding agent infrastructure. It's no longer enough to throw a prompt at Claude Code or Codex and hope for the best. Developers are building harness layers, token optimization libraries, and custom skills that dramatically improve output quality while cutting costs. AVB's rtk library reportedly saved 2.5 million tokens across their coding agents in just two weeks. Rohit's follow-up on his viral "The Harness Is Everything" post showed that patching the harness alone, with no model changes, improved results in 116 out of 126 test setups. The model is no longer the bottleneck. Your scaffolding is.
The most practical takeaway for developers: stop obsessing over which frontier model to use and start investing in your agent's harness, memory, and token management. The posts today consistently showed that infrastructure decisions matter more than model selection, and tools like rtk for token compaction or custom skills for documentation tasks deliver measurable, compounding returns.
Quick Hits
- @alexhillman praised an unnamed piece of software so highly they abandoned their own competing project, calling it "so much better" than what they were building.
- @mobilevibecom highlighted that you can now use Claude Code, Windsurf, Codex, and Cursor directly from your phone, closing the gap between desktop and mobile AI coding workflows.
- @mvanhorn shared a retweet highlighting several new agent-equipable tools including a
/last30dayscommand, continuing the trend of composable agent skills. - @Dell posted about Maya HTT building real-world AI solutions powered by the Dell AI Factory with NVIDIA, part of the ongoing enterprise AI infrastructure push.
Agent Frameworks Grow Up: Opinionated Defaults Win the Day
The agent framework space is having its "Rails versus Sinatra" moment. Teknium, co-founder of Nous Research, drew a clear line in the sand about what Hermes Agent is and isn't. The design philosophy is unapologetically pragmatic. "We didn't make Hermes Agent to be a 'starts with nothing, you work it all out' agent," Teknium wrote. "We want Hermes to work out of the box for most people. So you aren't spending weeks just getting the agent to work."
This is a direct challenge to the minimalist agent trend embodied by tools like nanoclaw and pi, which ship with almost nothing and expect developers to build up from scratch. Teknium acknowledges that Hermes ships with more built-in capabilities than those alternatives, but frames this as intentional. The baseline is "modest" but broader than most users need, and everything can be disabled via hermes skills config or hermes tools. There's even a mechanism to upload your entire agent configuration as a GitHub repo for sharing or reinstalling. "But if you don't want to become an agent engineer," Teknium concluded, "with Hermes, you don't have to."
That same maturity showed up in Tencent's Hy-Memory release, a memory plugin built specifically for long-term collaborative agents like OpenClaw. The plugin uses a six-layer memory framework with a System 1/System 2 dual-process architecture and a three-layer evolutionary chain. The claimed metrics are substantial: 70% fewer memories stored, 45% higher information density per memory, 35% less token usage on ultra-long contexts, and 20% faster memory updates. Whether those numbers hold up in production, the direction is clear. Agent memory is moving beyond simple retrieval into something that resembles actual cognitive architecture.
Peter Steinberger (@steipete) demonstrated another facet of mature agent usage, teaching Codex to function as an automated QA assistant. For every commit, his setup creates a user-test scenario and uses webVNC and browser automation to test applications like a real QA person. It runs in the background and opens PRs with fixes. This is agents moving from novelty to infrastructure, quietly handling work that would otherwise require dedicated human attention.
The Harness Is Everything: Token Optimization and Coding Agent Infrastructure
If there was a single technical lesson from today's posts, it's that the layer between you and the model matters more than the model itself. AVB (@neural_avb) shared a striking data point: their rtk library saved 2.5 million tokens across all coding agents in roughly two weeks. The library teaches LLMs to use rtk for running shell commands, where the output gets filtered, grouped, and truncated before the agent sees it. "Agents see compacted terminal outputs, less token consumption," AVB explained. It's a simple idea with massive cost implications when you're running agents continuously.
This perfectly complemented Rohit's (@rohit4verse) update on his "The Harness Is Everything" thesis, which originally garnered 1.3 million views. A new paper called "Life-Harness" demonstrated that patching only the harness, with the model completely frozen, improved performance in 116 out of 126 model-environment setups. The mean lift was 88.5% across 18 different model backbones. Rohit connected this directly to how Claude Code and Codex work under the hood, suggesting that the real innovation in these tools isn't the model but the scaffolding around it.
Drew Breunig (@dbreunig) added a practical example, sharing a custom skill developed while writing DSPy documentation that analyzes code repositories. "Have thrown it at several repos over the last week and it is better than alternatives I've tried," Breunig reported. The skill emerged organically from documentation work but ended up being a general-purpose repo analysis tool. This pattern of developers building bespoke harness components for specific tasks, then discovering they generalize, keeps recurring in the coding agent space.
Taken together, these posts paint a picture of a rapidly professionalizing ecosystem. The era of just prompting a model and accepting whatever comes back is ending. Developers who invest in token optimization, output filtering, and custom skill development are seeing compounding returns that dwarf the incremental improvements from switching between frontier models.
New Models and Personal AI Hardware
MiniMax officially entered the open-weights arena with M3, which @malikwas1f shared as "the first open-weights model to combine three frontier capabilities" including coding and agentic performance at a reported top-tier level. Details were sparse in the tweet, but the announcement itself matters. Another serious open-weights option for coding and agentic tasks puts competitive pressure on the incumbents and gives developers more flexibility in choosing models that fit their specific harness and infrastructure.
On the hardware side, NVIDIA's RTX Spark channel made its debut. @NVIDIARTXSpark described it as "a new superchip for the age of personal AI," promising that local AI content would continue on the channel with the new hardware as its centerpiece. The framing is notable. NVIDIA is explicitly positioning consumer hardware around personal AI workloads, not gaming or content creation. As agent frameworks like Hermes and memory systems like Hy-Memory push more processing to the edge, having hardware purpose-built for local inference becomes a meaningful advantage.
The combination of more open-weights models and better local hardware creates a virtuous cycle for developers who want to run agents privately and cheaply. You don't need to send every token to a cloud API when a local model handles most tasks and a frontier model is reserved for the hard problems. That hybrid approach is exactly what the token optimization crowd is already preparing for.
Vibe Coding Meets Developer Infrastructure
The vibe-coding movement continued to gain definition today. @0xSero published "Vibe-coding 102," a guide to personal AI infrastructure and tooling described as covering "how I do everything I do." The framing is instructive. What started as a meme about casually prompting your way to working software has evolved into a serious conversation about developer infrastructure. Vibe-coding isn't anti-engineering. It's engineering at a higher level of abstraction, where your agent handles the implementation details and you handle the architecture and orchestration.
@Atenov_D contributed a particularly crafty post detailing how to get six months of ChatGPT Pro, worth $1,200, by spending one evening building projects with Claude Code. The trick is straightforward: OpenAI has an open form for developers that approves most applicants with an active GitHub profile. Atenov_D's suggested approach is to use Claude Code to generate several polished projects in a single evening, complete with READMEs and commit history, then submit the form. "One evening. 2-3 finished projects. Claude writes the README. The result looks like a month of work," they wrote. Whether or not the approval rate is as high as claimed, the underlying insight is real. The bar for what counts as a demonstrable software project has shifted dramatically, and developers who leverage AI coding tools can produce portfolio-worthy output at unprecedented speed.
This section of posts captures the current moment in microcosm. The tools are powerful enough that the bottleneck has moved from writing code to designing systems and making good decisions about what to build. The developers winning right now are the ones treating AI coding agents as force multipliers within deliberate infrastructure, not as replacements for thought.
Sources

Three GitHub repos. One command each. Your Claude Code agent gets Polymarket scanner, edge analyzer, and live executor. Nobody packaged this before. Most people running AI trading agents build everything from scratch. Scanner, analyzer, execution logic - weeks of work. Someone just open-sourced all of it as installable Claude skills. Three repos that matter: > mjunaidca/polymarket-skills - scanner finds markets, analyzer spots edge and momentum, strategy advisor recommends entries, paper trader goes live when you're ready. One command: → npx skills add mjunaidca/polymarket-skills https://t.co/2oztgoNGJc > joinQuantish/skills - one command spins up 3 MCP servers simultaneously. Discovery searches 50k+ markets. Polymarket server handles full order lifecycle. Kalshi server adds CFTC-regulated markets on top. → https://t.co/Hp928SCWXT > caiovicentino/polymarket-mcp-server - 45 tools. Market discovery, trading engine, analysis, portfolio management. WebSocket monitoring in real time. Web interface included. → https://t.co/PONXW7gXiW Works with Claude Code, OpenClaw, Cursor, Codex. Any SKILL.md-compatible agent. The stack that used to take weeks now takes three commands.
The Harness Is Everything: What Cursor, Claude Code, and Perplexity Actually Built
What Do Humans Need From Docs?