OpenAI and Slack Go All-In on MCP as Enterprise AI Confronts Its ROI Reality
The Model Context Protocol earned major endorsements from OpenAI and Slack today, signaling that agentic infrastructure is rapidly becoming standardized. Meanwhile, enterprise leaders are publicly acknowledging that individual AI productivity gains are not translating into firm-level returns, and SpaceX revealed a custom C-based training stack claiming 10x speedups over JAX.
Daily Wrap-Up
The most important shift happening in AI right now is not about models getting smarter. It is about infrastructure growing up. Today saw three major developments in the Model Context Protocol alone: OpenAI announced support for private MCP servers inside corporate networks, Slack revealed that Slackbot is now an MCP client with plans for more agents than humans within two years, and startups are building entire products around MCP-native workflows. When Greg Brockman and Slack are backing the same open protocol, that is not a coincidence. That is a sign the industry is converging on how AI agents should talk to the tools we already use.
The second theme worth watching is the growing gap between AI hype and enterprise reality. Azeem's observation that a senior executive with 1,000 engineers using Claude Code said the ROI "doesn't add up" was amplified by Hiten Shah, Dharmesh, and others today. Individual developers are shipping faster, but companies are struggling to capture that speed as business value. Dharmesh's advice was the sharpest of the bunch: stop trying to compete with frontier model companies and focus on workflows, proprietary data, and deterministic outcomes. It is a blueprint for building defensible businesses in a world where the underlying models are a commodity race to the bottom.
The most practical takeaway for developers: start treating AI interaction as a design problem, not a chat problem. Whether it is Parth Jadhav's approach of giving agents measurable goals like "fix issues until you get a score of 100," Matt Pocock encoding teaching instincts into a reusable /skill, or John Yeo's team building a dedicated agent for log investigation, the developers extracting real value are the ones creating structured, repeatable patterns. Vague prompting is dead. Structured agent workflows are what separate toy demos from production systems.
Quick Hits
- @vijayiyengar advocates for outcome-based AI pricing instead of per-token billing, noting that Sierra's early adoption of this model forces "clarity on what your outcome is and token discipline because you own the risk."
- @rileybrown teased that May 29 will be "a VERY big day in the world of AI agents," so expect announcements.
- @OmarShahine is hunting for a browser automation tool that delivers a "massive boost over Playwright," pointing to ongoing frustration with current web automation frameworks.
MCP and the Agentic Infrastructure Layer
Four separate developments today point to the same conclusion: MCP is becoming the connective tissue of the agentic web. The most significant came from OpenAI, where @gdb (Greg Brockman) shared that ChatGPT, Codex, and the Responses API now support private MCP servers through outbound-only HTTPS connections. This means enterprise teams can keep their MCP infrastructure inside corporate firewalls while OpenAI's products reach out to them. For companies that have been hesitant about agent adoption due to data governance concerns, this removes a meaningful barrier.
Slack is going even further. As @designertom highlighted, @SlackHQ announced that Slackbot is now an MCP client capable of creating NetSuite purchase orders, updating Jira projects, and summarizing Salesforce cases without switching tools. They are reporting 1 million MCP users in the first six weeks and a 350% quarter-over-quarter jump in active weekly users. Their prediction that agents will outnumber people on Slack within two years sounds provocative until you look at the numbers.
The application layer is evolving alongside the protocol. @anvisha shared how her team built Moda, essentially Google Drive for HTML docs, with WYSIWYG editing, commenting, and share links, all accessible through MCP. The insight was that HTML docs are replacing Notion for many teams, but collaboration was the missing piece. Now Claude can upload documents directly. @johnyeo_ described a different but complementary pattern: an in-house agent that automatically queries logs and investigates support tickets. He explained the architecture in a linked post, and it represents exactly the kind of focused, single-purpose agent that enterprises actually need. Together these four posts paint a picture of MCP maturing from protocol to platform.
Enterprise AI Confronts Its ROI Problem
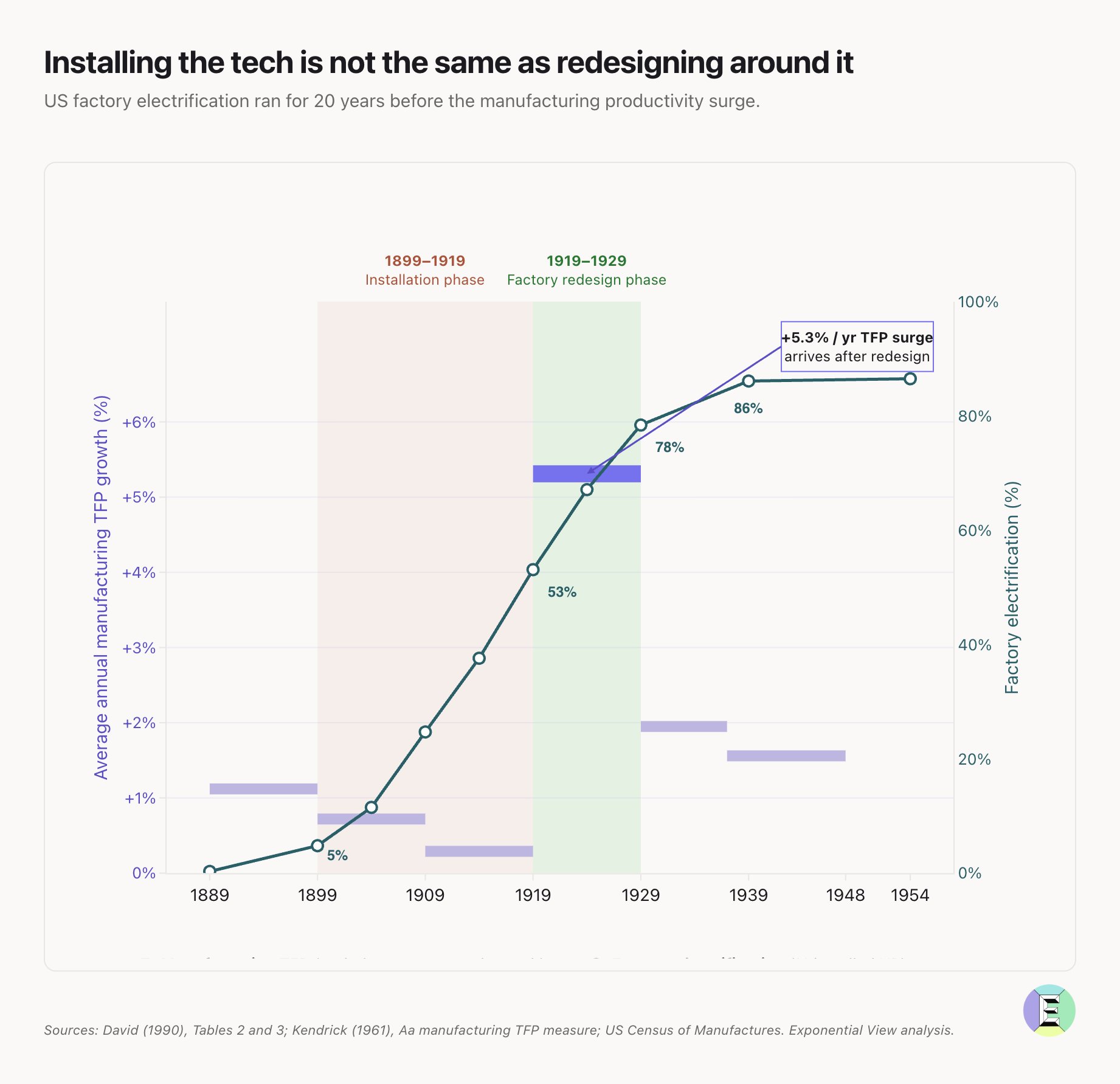
The enterprise AI conversation shifted today from "how fast can we adopt this?" to "why isn't this showing up in our numbers?" @hnshah quoted @azeem's blunt assessment: "Individual productivity is up, but firm-level ROI isn't." The supporting evidence is striking. A senior executive with 1,000 engineers all using Claude Code reported that the math "doesn't add up." Uber's engineering leadership said the same thing publicly this week. As Hiten Shah succinctly put it, "Installing the tech is not the same as redesigning around it."
@dharmesh offered the most actionable strategic response. Quoting @joeschmidtiv's post "Avoiding Death on the Yellow Brick Road," he urged software companies to stop competing directly with frontier model providers and instead focus on three things: building systems of work with real workflows, capturing compounding non-public data, and delivering deterministic outcomes customers can rely on. His framing is worth sitting with. The frontier model companies are racing down a well-funded road, and trying to beat them at their own game is a losing proposition for almost everyone else.
Meanwhile, the enterprise opportunity itself is enormous. @giyu_codes highlighted @vasuman's description of a $60T market, with over 100 companies in the $1B to $100B revenue range reaching out unsolicited. Contracts are hitting eight figures with projected savings in the nine to ten figure range per client. The constraint is not demand. It is finding people who deeply understand AI, know how to apply it inside complex organizations, and can communicate that knowledge effectively. @giyu_codes called this "the only person on this app doing quality work within AI on Enterprise transformation," a striking endorsement in a space drowning in thought leadership.
Developer Tooling Gets an AI Upgrade
Claude Code is getting more reliable, and the timing matters. @ClaudeDevs acknowledged ongoing efforts to improve responsiveness and reliability, addressing one of the most common complaints from power users. The update itself was light on specifics, but the public commitment signals that Anthropic views developer experience as a competitive differentiator, not a nice-to-have.
The more interesting pattern emerged from how developers are structuring their AI interactions. @ParthJadhav8 shared what he calls the best tokens you can spend on a React app: tell your agent to "run npx react-doctor@latest and fix issues until you get a score of 100." This is a clean encapsulation of goal-driven agent behavior. Instead of vaguely asking an agent to improve your codebase, you define a specific tool, a concrete metric, and a target score. The agent loops autonomously until the condition is satisfied. It is deterministic in outcome but flexible in execution, exactly the sweet spot where AI agents deliver real value.
@mattpocockuk took a more meta approach, encoding his personal teaching philosophy into a /teach skill that he uses to learn topics like Linux user permissions from scratch. He is applying it to fix bugs in his Sandcastle project, but the broader implication is that experienced practitioners are starting to package their expertise into reusable interaction templates. What began as ad-hoc prompting is evolving into something closer to skill libraries, and that is a shift worth tracking.
Speed, Rust, and Bare Metal
The performance frontier of AI is moving in two directions simultaneously: toward bare-metal optimization at the training cluster level, and toward fast local inference for everyday applications. @elonmusk dropped the most eye-catching claim of the day, announcing that SpaceX has nearly completed a custom AI training stack written in C that maps directly to 220,000 GB300 GPUs with 800G NICs. The approach uses heavy pipeline parallelism to minimize framework overhead, and Musk claims the potential speed improvement versus JAX for large training runs is over an order of magnitude. Whether those numbers hold up under independent verification, the strategic direction is clear. When you operate at the scale of hundreds of thousands of GPUs, the abstraction cost of frameworks like JAX becomes a measurable bottleneck, and custom C starts to pay for itself.
At the other end of the spectrum, @jerryjliu0 announced LiteParse v2, a PDF parser rewritten entirely in Rust with native packages for Python, Node, and WebAssembly. He describes it as the world's fastest and most accurate open-source, model-free PDF parser, outperforming pymupdf, pypdf, markitdown, and others. In a world where every RAG pipeline needs to ingest documents at scale, parsing speed directly determines application cost and responsiveness. The Rust rewrite is part of a broader trend of performance-critical AI infrastructure migrating away from Python toward compiled languages.
@badlogicgames reported that the local AI stack is reaching a genuine inflection point. He is combining Parakeet for speech-to-text, Qwen3-TTS for text-to-speech (which he calls "FANTASTIC"), and Gemma 4 via llama.cpp to build a fully local voice interaction pipeline for a robotics project. Zero cloud dependency. The fact that a complete STT/TTS/LLM pipeline can run locally on consumer hardware would have seemed improbable a year ago, and it has real implications for latency, privacy, and cost in robotics and embedded applications.
Sources
O
Need to try this. Hoping for massive boost over Playwright for browser automation. https://t.co/fjekNQ2JHA
A
HTML docs are starting to replace Notion for us.
The missing piece was collaboration.
So we built a Google Drive for HTML docs with a WYSIWYG editor, commenting, share links, and password protection.
It works through MCP. Just ask Claude to upload to Moda: https://t.co/XcwBQKnFmK
T
trq212
@trq212
Using Claude Code: The Unreasonable Effectiveness of HTML
M
Just wrote a /teach skill on the tube
It encodes all my instincts about good teaching.
Using it to teach me Linux user permissions properly so I can fix Sandcastle bugs
LMK if you like it:
https://t.co/iFBX0PVQ6V
J
One of the biggest levers we've built in house is an agent to automatically query our logs and investigate tickets - explained how it works here!
https://t.co/CcGOPoGUaz
J
johnyeo_
@johnyeo_
Building an AI agent to automatically investigate support tickets
C
We’ve been putting a lot of effort into making Claude Code more responsive & reliable.
Here’s an update on everything we’ve done:
P
If you've a React app, just tell your agent this:
/goal run npx react-doctor@latest and fix issues until you get a score of 100.
Best tokens you'll ever spend on a react-app.
also @aidenybai is 🐐
J
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50+ different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: https://t.co/ckb0G73ESs
Repo: https://t.co/JNER0mVcB8

L
llama_index
@llama_index
LiteParse v2.0 is out now, and it is blazing fast + runs everywhere! We rewrote everything from scratch in Rust, and now: - up to 100x faster parsing - install natively in Rust, JS/TS, and Python - a custom WASM package enables browser and edge runtime usage pip install liteparse npm i @llamaindex/liteparse npm i @llamaindex/liteparse-wasm cargo install liteparse Blog: https://t.co/zWnhGNrgeb Repo: https://t.co/UJy6KQ1Dyi
M
jesus, qwen3-tts is FANTASTIC. going for full local stt/tts/llm with parakeet, qwen3-tts, and gemma 4 via llama.cpp for my little robot. excite, excite!
https://t.co/5x7vTEE9RN
G
bring-your-own MCP servers:
O
OpenAIDevs
@OpenAIDevs
Private MCP servers 🤝 OpenAI products Your team can keep MCP servers inside your network while ChatGPT, Codex, and the Responses API connect through outbound-only HTTPS. 🔗 https://t.co/UVq0KpT0km https://t.co/uMsQJJK9ho
D
If you work in the software industry and have time to read only one long-form post today, read this one.
If you have time to read two, read this one twice.
Highly #recommend
tl;dr: Stay off the yellow brick road that the frontier model companies are racing down. There is plenty of opportunity to solve hard problems elsewhere. Focus on areas where you can build the system of work (workflows), capture compounding, non-public data and deliver deterministic outcomes that customers need.
J
joeschmidtiv
@joeschmidtiv
Avoiding Death on the Yellow Brick Road
H
✅ "Installing the tech is not the same as redesigning around it" https://t.co/KwQWknIvtc
A
azeem
@azeem
Individual productivity is up, but firm-level ROI isn't. A senior exec with 1,000 engineers all using Claude Code told me that "it doesn't add up". Uber's @andrewgordonmac said the same publicly this week. Here's why: https://t.co/gnn2iZJV21 cc @erikbryn @jack @arakharazian
G
This is the only person on this app that I truly believe is doing quality work within the "AI on Enterprise" transformation.
Jealous of those in SF that get to work with him and his team.
V
vasuman
@vasuman
AI transformation at the enterprise level is a 60T market: the largest unsolved market in history. Over the last few months, 100+ companies doing $1B to $100B in revenue have reached out to us. We do zero outbound. The contracts are 8 figures, with 9 to 10 figures in savings and revenue uplift per client. Most "AI services" firms top out transforming startups. A 10,000-person company is a different problem entirely. Our only constraint right now is hiring talented people fast enough. You have to understand AI deeply, know how to apply it, and be a brilliant communicator. Lowering the bar would fail our clients, and we refuse to do so. If you know someone great who wants in on what could be a generational company being built out of SF, send them our way. We'll give you a $20,000 referral bonus if they join. We're hiring Staff Engineers, AI Engagement Managers, Forward Deployed AI Strategists, AI Engineers, and Full Stack Engineers, full-time, in-person, in SF. Apply below or DM me - I read every one.
T
Genuinely very pleased to hear this from Slack
S
SlackHQ
@SlackHQ
In 2 years there will be more agents using Slack than people. That's not a prediction. It's a roadmap. Q1 FY27: • Slack MCP: 1 million users in the first 6 weeks • Slack AWUs: up 350% QoQ • Slack in nearly half of Salesforce's $1M+ wins this quarter (+80% YoY) Slackbot is now an MCP client. Create a NetSuite PO. Update a Jira project. Summarize a Salesforce case. No switching tools. The future of work isn't in a browser tab. Welcome to Agentic Slack. ⚡
R
I hope you know tomorrow is going to be a VERY big day in the world of AI agents...
V
Banger.
Corollary is to price by outcome instead of by token. Forces both clarity on what your outcome is and token discipline because you own the risk.
Sierra was pretty early to this thesis and has been critical to our growth: https://t.co/o1tmd5SfXp
J
JayaGup10
@JayaGup10
Token Budget Wars
E
SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.