AI Agents Get Composable as Data Reveals 82% of Tokens Spent on Bug Fixes and Rework
The agent ecosystem matured rapidly this week, with Codex expanding into knowledge work, LangSmith automating agent optimization, and developers rethinking composability primitives. Meanwhile, data from 2,444 companies exposed a staggering waste problem in AI-assisted development, and FlashLib brought up to 208x speedups to classical ML on GPU.
Daily Wrap-Up
Today's posts reveal an AI ecosystem caught between momentum and reckoning. The agent paradigm is consolidating fast: OpenAI's Codex is being pitched for all kinds of computer-based knowledge work, LangSmith launched an engine that uses agents to optimize other agents, and developers like Matt Pocock are thinking seriously about how to decompose agent capabilities into composable primitives. The tooling around agents is getting more sophisticated, and the number of people building with them is clearly growing. Even Palantir is positioning its Apollo platform as the deployment and governance layer for AI-generated software, which tells you something about where enterprise thinking is headed.
But underneath that momentum lies an uncomfortable number. @brandonjcarl shared data from 2,444 companies showing that 82% of AI token spend goes toward bugs, rework, and review friction. That is a staggering inefficiency ratio. @Aiswarya_Sankar, whose post was quoted in the thread, put it bluntly: companies are spending $100k on tokens while only $18k worth makes it into stable production features. The industry is burning enormous amounts of compute to fix what AI broke in the first place. At the same time, new benchmarks like DeepSWE are emerging that finally reflect the real-world experience of coding with these models, and the verdict from @theo is that this is the first benchmark that actually matches developer intuition.
On the infrastructure side, FlashLib quietly dropped some of the most impressive performance numbers seen in classical ML this year, with GPU-accelerated operators running up to 208x faster than cuML on operations like TruncatedSVD. And Anthropic co-founder Chris Olah was invited to speak at the Vatican for the presentation of Pope Leo XIV's encyclical on AI ethics, signaling that safety concerns have reached some very unexpected venues. The most practical takeaway for developers: the bottleneck in AI-assisted work is no longer model intelligence. It is the quality of your harness, whether that means your llama-server flags, your agent skill architecture, or your review pipeline. Invest time in the scaffolding before you spend another dollar on tokens.
Quick Hits
- Palantir positions Apollo as AI-native deployment infrastructure: @PalantirTech argued that AI solved software creation and now needs to solve distribution, pitching Apollo as the governance layer for deploying, patching, and rolling back AI-generated code with human accountability baked in.
- Claude for finance gets a strong recommendation: @Av1dlive called the Anthropic Claude for finance lecture "the best free hour in quant AI right now," pairing it with a guide on setting up Claude Code as an investment research analyst.
- Gene therapy breakthrough draws tech attention: @garrytan highlighted Eli Lilly's VERVE-102 data showing a single infusion achieving 88% reduction in PCSK9 and 62% reduction in LDL cholesterol sustained for 18 months, framing it as a preview of the golden age of abundance.
- Python teaching demand spikes after viral post: @marlene_zw reported getting finance industry offers to teach Python after her content went viral, joking that she is still waiting for a $100 million research lab offer instead.
- Hardware creator deserves more attention: @Xaraphim recommended following @___Dario_____ for building a metal 3D printer, calling him underfollowed given the ambition of the project.
The Agent Architecture Grows Up
Something shifted in how people talk about AI agents this week. The conversation moved past "look what my agent can do" and into the harder, more important territory of how agents should be structured, secured, and optimized at scale. The sheer density of posts on this topic, six in a single day, tells you where developer attention is concentrated.
OpenAI's Greg Brockman casually noted that "codex is great for any kind of work done with a computer," and the post he was quoting from @bran_don_gell described their team as "heavily Codex pilled" for knowledge work, not just coding. This aligns with what @every shared about using a Codex prompt template to draft go-to-market plans: "When you've already done the big picture thinking in meetings and Slack, the next step is just prompting an agent to make a plan for you and the agent to review together." The pattern here is consistent. Agents are becoming the interface between human strategic thinking and tedious execution work, and the people using them most effectively are the ones who have already done the hard thinking and just need the draft.
On the optimization side, @hwchase17 (via @sydneyrunkle's retweet) introduced LangSmith Engine, described as "an agent that helps you spin the optimization loop for your own agents." This is a recursive pattern worth watching: using AI to improve AI systems. It suggests that the ecosystem is mature enough that the meta-problems of agent development, debugging prompts, evaluating outputs, tuning parameters, are themselves being automated.
Matt Pocock's post about decomposing agent capabilities into two categories is perhaps the most architecturally significant observation of the day. He proposed dividing skills into "model-invocable skills (skills)" and "user-invocable skills (commands)," where a command like /improve-codebase-architecture would invoke underlying skills like /deep-modules or /domain-modeling. The insight is that composability requires clear boundaries between what users trigger and what models invoke on their own, and that distinction is currently missing from most agent frameworks.
Meanwhile, Anthropic published a new engineering blog post on agent security, with @maxgmcg explaining the approach: "start from traditional software security (like untrusted code), look for risk/reward moments as capability develops." The core argument is that sandboxing and permissions should scale with agent capabilities, and that Anthropic's own Auto Mode for Claude Code is a feature they might not have shipped a year ago when agents were less capable. This is the responsible complement to all the excitement: as agents get more autonomous, the security model has to evolve at the same pace.
AI Coding's Dirty Secret: Waste, Benchmarks, and Harness Gaps
The most provocative data point of the day came from @brandonjcarl, who shared findings across 2,444 companies showing that 82% of AI tokens are spent on "AI-generated bugs, rework and review friction." The original post from @Aiswarya_Sankar added more color: companies trying to justify $100k in token spend are discovering that only $18k worth actually makes it to stable production features, with over 44% wasted on bug fixes alone. This is not a marginal inefficiency. It suggests that the current generation of AI coding tools may be creating nearly as much technical debt as they eliminate, and that the real ROI of AI-assisted development depends heavily on how well your review and validation pipelines catch AI-generated mistakes before they compound.
On the benchmark front, @theo endorsed DeepSWE, a new agentic coding benchmark from @serenaa_ge, calling it "the first code bench that actually aligns with how it feels to use these models coding." The significance here is that public leaderboards have traditionally made top models look relatively close in capability, while developer experience tells a very different story. DeepSWE appears to close that gap by testing models on tasks that reflect actual day-to-day development work rather than synthetic challenges. If the benchmark holds up, it could become a much more honest signal for teams evaluating which models to adopt.
@Youssofal_ crystallized the tooling problem after spending time with Qwen 3.6 27B in Cursor: "the constraint on local models isn't intelligence but the harnesses. Local model harnesses are TERRIBLE." He specifically called out Pi and Open Code as inadequate, arguing that the community needs to do better. This is a critical observation because it means capable open-weight models are being held back not by their parameters or training data but by the software layer between the model and the developer. If the harness problem were solved, local models could compete much more seriously with cloud-based options.
Thorsten Ball's essay "Software After Software" gestured at the larger picture, arguing that the transformation underway is large enough that "nearly everything we assumed to be true about how software and business work must be rethought." The title alone captures the unsettled feeling across the industry. We are building tools that change what building tools means, and nobody is quite sure where the equilibrium lands.
ML Infrastructure Gets a Speed Boost
While agents and coding tools grabbed the spotlight, some genuinely impressive infrastructure work dropped on the research and optimization side. The standout was FlashLib, a GPU library from the Flash-KMeans team that delivers massive speedups for classical ML operators. @Andy_ShuoYang posted the headline numbers: up to 26x on KMeans, 19x on KNN, 40x on HDBSCAN, 208x on TruncatedSVD, 47x on PCA, 147x on exact t-SNE, and 49x on MultinomialNB over the previous state-of-the-art in cuML. @neural_avb put it in practical terms: "You can cluster millions of documents in embedding space, mass-annotate them, visualize them... basically for free and within seconds." For anyone working with large-scale embeddings or building retrieval-augmented systems, these are the kind of speedups that change what is feasible in an interactive workflow. Classical ML has been the unsexy cousin of deep learning for years, but when you can run exact t-SNE on millions of points in seconds, a lot of data exploration workflows suddenly become practical.
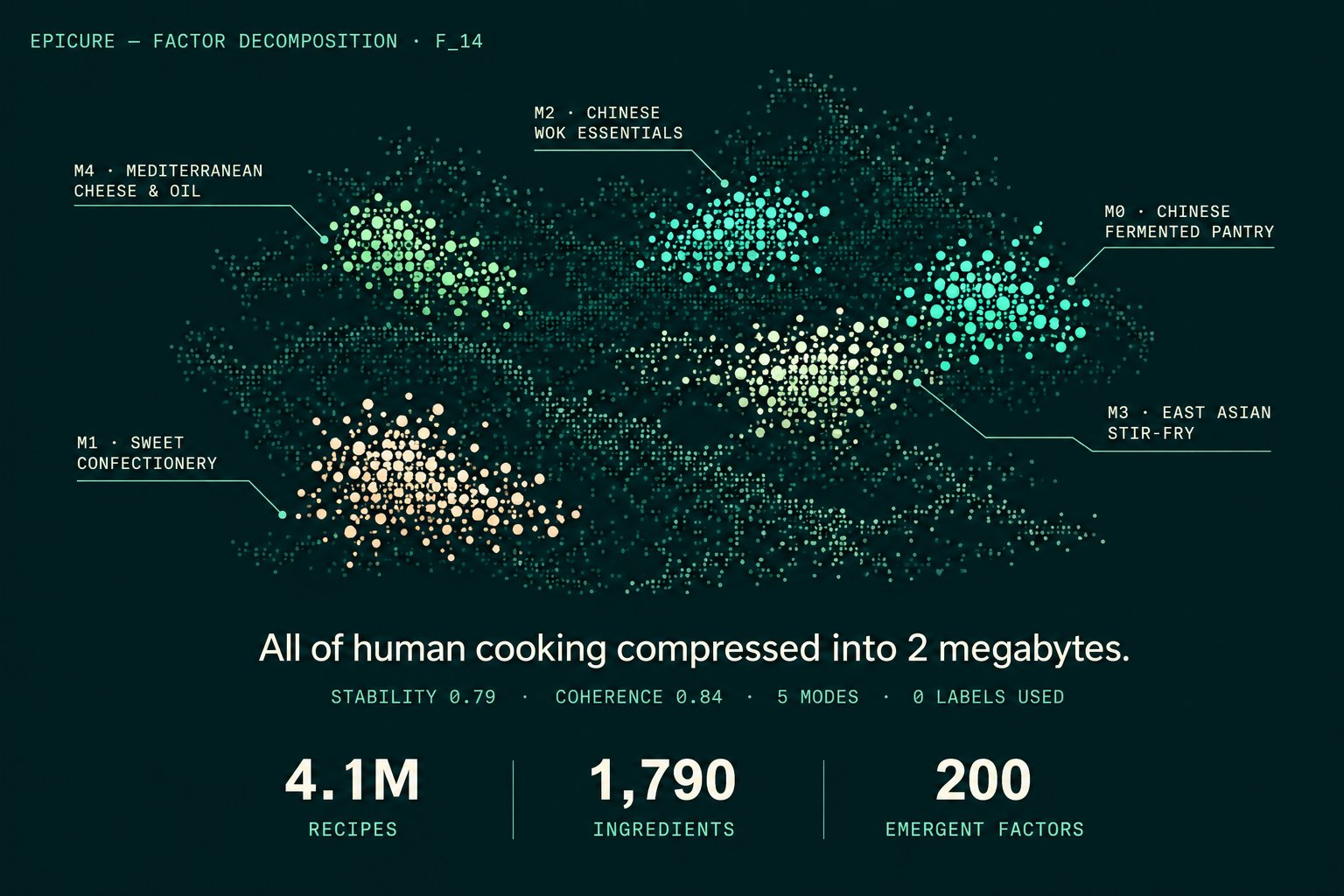
On the quirky but genuinely interesting research front, @josefchen announced a new arXiv paper describing the largest multilingual food model ever built: "4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions. All of human cooking compressed into 2 megabytes." It is a niche application, but it demonstrates how embedding techniques can compress domain knowledge into remarkably small representations. The fact that an entire culinary tradition across seven languages fits into 2MB is a useful reminder of how efficient well-designed embeddings can be compared to the multi-gigabyte models that dominate headlines.
For the self-hosting crowd, @witcheer shared a detailed reference guide for tuning llama-server, documenting 16 flags with explanations of when to change each one and "what breaks if you get it wrong." The post came from personal frustration: "when I started tuning llama-server, I changed flags randomly until something worked (or didn't)." After measuring every flag, every value, and "the exact point where performance falls off a cliff," he built the reference he wished he had. This is exactly the kind of practical, hard-won knowledge that the local AI community needs more of, and it pairs directly with @Youssofal_'s point about harnesses being the real bottleneck.
AI Ethics at the Vatican
In a development that few would have predicted even a year ago, Anthropic co-founder Chris Olah was invited to speak at the presentation of Pope Leo XIV's encyclical "Magnifica humanitas." The encyclical's title and Olah's participation suggest the Catholic Church is engaging substantively with questions about AI's impact on human dignity and society. Anthropic shared the full text of Olah's remarks, which position AI safety as not just a technical problem but a deeply human one. Whether you are religious or not, the fact that one of AI's most prominent safety researchers was invited to the Vatican to discuss technology ethics alongside papal authority signals how far the AI safety conversation has moved from academic backrooms into mainstream cultural institutions. The choice of Pope Leo XIV's name itself was reportedly influenced by Leo XIII's focus on labor and dignity during the industrial revolution, drawing an explicit parallel to today's AI transformation.
Sources
S
🔴LIVE NOW! Tune in to Slack Dev Day to get deep technical insights on AI agents, hear what's next for the Slack developer ecosystem, and see how Slackbot is changing the game for everyone.
https://t.co/T0qouJ0pY8
A
Anthropic co-founder Chris Olah was invited to speak at today's presentation of Pope Leo XIV's encyclical "Magnifica humanitas."
Read the full text of his remarks: https://t.co/CoBfkVOVcy
W
when I started tuning llama-server, I changed flags randomly until something worked (or didn't).
ncmoe 30? ncmoe 10? why is it suddenly 5x slower? what even is the KV cache eating my VRAM for?
so I measured everything. every flag, every ncmoe value, the exact VRAM cost per layer, the exact point where performance falls off a cliff.
this is the reference I built for myself.
16 flags, each explained with the "when to change it" and "what breaks if you get it wrong"
enjoy

W
witcheer
@witcheer
https://t.co/4oR4pVnFlD
G
Ultimately the golden age of abundance will be this kind of tech built and deployed 1000x
A
afshineemrani
@afshineemrani
1/5 I'm a cardiologist. I have spent twenty years watching cholesterol destroy arteries, trigger heart attacks, and kill people I care about. Today, Eli Lilly presented data that may begin to end that era. VERVE-102. A single infusion. One dose. It uses base editing to permanently turn off the PCSK9 gene in your liver. Presented today at the European Atherosclerosis Society Congress: 88% reduction in PCSK9. 62% reduction in LDL cholesterol. Sustained up to 18 months. No treatment-related serious adverse events. One infusion. Not daily pills you forget to take. Not monthly injections. One dose — and your cholesterol may stay low for the rest of your life.
A
the anthropic claude for finance lecture is the best free hour in quant AI right now.
bookmark & watch today. It's the most valuable 1 hour in quant AI right now. Then read article below. https://t.co/keKowiGCtp

L
leopardracer
@leopardracer
How I Set Up Claude Code as My Investment Research Analyst
Y
After spending time with Qwen 3.6 27B in Cursor I’ve come to realise the constraint on local models isn’t intelligence but the harnesses.
Local model harnesses are TERRIBLE.
Pi, open code etc are genuinely bad.
As a community, we need to do better than this.
T
Software After Software
Software After Software
Everything is changing. 1.1. We are in the midst of a transformation so large that nearly everything we assumed to be true about how software and bus...
P
AI solved software creation.
Now comes software distribution.
The future will not run on blind deployment pipelines.
Apollo provides the Ontology Primitives for Software Distribution. Deploy. Patch. Rollback. Validate. Govern.
AI-native velocity with human accountability. https://t.co/d9tPCVjbU9

J
Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes. https://t.co/b4GiZ62UMt
T
This is the first code bench that actually aligns with how it feels to use these models coding.
S
serenaa_ge
@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work. https://t.co/HCDcjNuTFK
E
Here's the template Codex prompt we use to draft GTM plans at Every.
When you've already done the big picture thinking in meetings and @SlackHQ, the next step is just prompting an agent to make a plan for you and the agent to review together. https://t.co/cBn5fAiBAk

M
I wrote an Anthropic blog post on agent security!
TLDR start from traditional software security (like untrusted code), look for risk/reward moments as capability develops; CC's Auto Mode is a useful feature we might not have shipped 1yr ago. Let me know what you think :)
A
AnthropicAI
@AnthropicAI
New on the Engineering Blog: The access and permissions we grant agents should evolve with their capabilities. In our own products, we set these parameters through sandboxing, which limits the scope of any potentially destructive actions. Read more: https://t.co/KfBKW8O9kP
B
Very interesting data across 2,444 companies.
82% of tokens are spent on AI-generated bugs, rework and review friction.
A
Aiswarya_Sankar
@Aiswarya_Sankar
This is what we've been seeing with every company we work with. Try justifying spending 100k on token spend when only 18k even makes it to a stable prod feature. In the rush to maximize AI token spend, companies are wasting over 44% on bug fixes https://t.co/y68Ed0XwXj
S
RT @hwchase17: langsmith engine is an agent that helps you spin the optimization loop for your own agents
P
you guys should go follow dario
I don’t know how he does not have 100x amount of followers when he literally built a damn metal printer
_
___Dario_____
@___Dario_____
We’re coming for you @jimbelosic https://t.co/6kDQKsOpRB
A
Deep learning bros and sisters, don't sleep on this.
You can cluster millions of documents in embedding space, mass-annotate them, visualize them... basically for free and within seconds. https://t.co/PRaogzkY8J
A
Andy_ShuoYang
@Andy_ShuoYang
Flash-KMeans was only the beginning. Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators. Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML). Blog: https://t.co/P31SGl0cyT Code: https://t.co/9nkO2hmeOl
G
codex is great for any kind of work done with a computer:
B
bran_don_gell
@bran_don_gell
If you know one thing about every right now, it's that we're heavily Codex pilled. So we wrote a guide on how to use Codex for knowledge work as well as we do. You dont want to miss this one... https://t.co/KkTSjy7o6G
0
RT @badlogicgames: recommended viewing. probably one of the best explainer sources in our space. channel is full of great stuff.
https://t…
M
I am getting some offers from finance people to teach them python after this went viral! Still waiting for a research lab to offer me a $100million so I can work for 2 years and retire 😂
J
Jouhatsu_ai
@Jouhatsu_ai
Un ingénieur IA senior chez Microsoft vient de dévoiler comment les équipes de Microsoft créent des agents IA avec Anthropic. 34 minutes de workshop gratuit, directement par l’équipe Microsoft. Regarde le workshop. Ajoute en signet 🔖 Opus 4.7 + plus de 1 400 outils MCP déjà prêts à l’emploi. Tu connectes Claude à un agent → tu lui ajoutes des outils → tu déploies en production. Plus utile que la majorité des formations de vibe-coding vendues 500 $.
M
I've been feeling the itch to divide my skills repo into two kinds of skills:
- Model-invocable skills (skills)
- User-invocable skills (commands)
I.e. you'd be able to run /improve-codebase-architecture (a command), which would use /deep-modules (a skill)
You'd run /grill-with-docs, which relies on /domain-modeling
That way, skills become more composable. You can ask "give me a report on the /deep-modules in this repo", or "help me with /domain-modelling a new concept"