Claude Code Becomes the Developer OS as Open Source Disrupts the Integration Layer
The AI coding agent ecosystem consolidated around Claude Code and Codex with new skills, mobile access, and model-agnostic flexibility. Open source tools like Nango challenged expensive SaaS integration platforms, while agent infrastructure from Microsoft and others matured rapidly. Dan Shipper's predictions about the future of work offered a grounded counterpoint to both AI hype and doom.
Daily Wrap-Up
Today's signal is unmistakable: the AI coding agent is becoming the primary interface for knowledge work, and the infrastructure around it is maturing fast. Paras Chopra's HTML commenting skill for Claude Code, Garry Tan's pointer to skill optimization as a trainable discipline, and Microsoft's Playwright update designed specifically for agents all point to the same conclusion. We're no longer building tools for humans who occasionally use AI. We're building tools for agents that occasionally need human approval. The power dynamic has flipped, and the tooling is catching up to that reality.
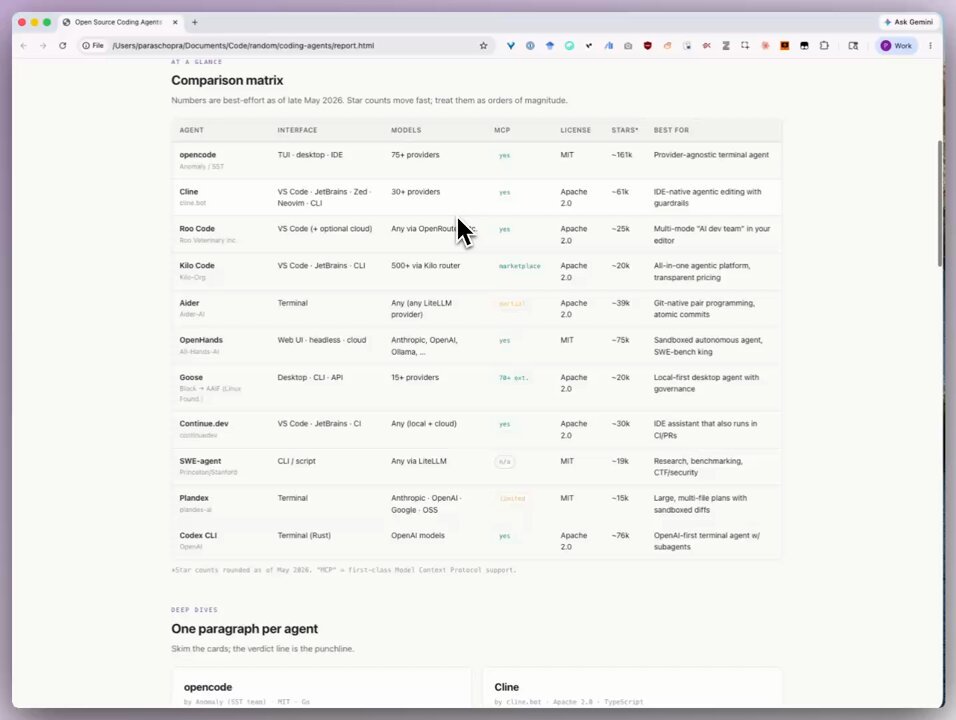
The open source movement continued its march through expensive SaaS fiefdoms. Nango, an open source integration layer with 700+ API connectors, landed like a bomb on the "unified API" industry that has been charging companies $50,000 to $100,000 a year for what amounts to managed OAuth and rate limiting. Meanwhile codedb claimed 50,000x speed improvements over grep for code search, and Files SDK pushed toward cross-provider file workflows with real observability hooks. The pattern is clear and accelerating: if your SaaS product is essentially a well-maintained wrapper around open protocols and standardized flows, your clock is ticking.
The most practical takeaway for developers: invest in learning Claude Code skills and agent orchestration patterns right now. The developers who thrive in this cycle will be the ones who can write effective skill files, set up label-based agent triggers in GitHub, and build interfaces that humans and agents can use together. The tooling is stabilizing, the community patterns are emerging, and the window to build genuine expertise is open today but visibly closing.
Quick Hits
- @krishgarg introduced Shard, a KV cache compression technique achieving 10x compression on Llama-3.1-8B with zero quality loss, beating Google DeepMind's turboquant which tops out at 4-6x at the same fidelity.
- @Atenov_D highlighted MoneyPrinterTurbo, an open source tool with 13,000+ GitHub stars that generates complete short videos from a keyword, including script, footage, subtitles, and voiceover. Runs locally with no subscriptions or watermarks.
- @0xblacklight shared a viral Claude skill called /seppuku that agents now trigger spontaneously when they make unforgivable mistakes. The internet remains undefeated at anthropomorphizing LLMs.
- @itsolelehmann revived the concept of using Claude for "premortems," having the model simulate traveling six months into the future to tell you exactly how your plan failed before you start executing it.
- @mobilevibecom pointed out that Claude Code, Windsurf, Codex, and Cursor can now all be used from your phone, removing one of the last practical objections to agent-first development workflows.
Claude Code Becomes the Developer OS
The Claude Code ecosystem is no longer just a coding assistant. It's becoming a full development environment where agents write, review, iterate, and even self-correct in structured ways. The velocity of community-built skills and extensions suggests we're watching a platform consolidate in real time, and the people building on top of it are finding genuinely novel interaction patterns.
Paras Chopra @paraschopra demonstrated what might be the most elegant Claude Code workflow yet: a skill that generates static HTML files and lets you comment directly in the browser to iterate. "I wanted to iterate on the file by commenting in browser and having Claude update the output live," he explained. The result is Google Docs-style commenting applied to any HTML output, whether it's a research report, mockup, or code structure exploration. It's a small thing that fundamentally changes the feedback loop. You're no longer switching between your code editor and your browser and your chat window. The artifact and the conversation about it live in the same space.
Meanwhile the Codex ecosystem is being opened up in a different direction. @0xSero highlighted work by @OnlyTerp to make Codex model agnostic, meaning you can plug in any LLM backend instead of being locked into a single provider. @OnlyTerp noted that adding "prompt catching" to the shim makes it roughly 7x cheaper and 5-10x faster by reducing redundant inference calls. This matters because it decouples the agent orchestration layer from the model provider, giving developers flexibility to optimize for cost, speed, or capability on a per-task basis. When your coding agent can route simple tasks to a cheap model and complex architecture decisions to a frontier model, the economics of agent-driven development start looking very different.
The broader implication, reinforced by Lenny Rachitsky's @lennysan summary of Dan Shipper's workflow, is that coding agents are evolving from single-purpose code generators into general-purpose work environments. Shipper now spends all his time in Codex doing everything from writing documents to managing email to checking PostHog analytics. The agent sees what he's doing through an in-app browser and carries full context across all of it. When your coding agent becomes the place where you write strategy docs and review dashboards, it's not a coding agent anymore. It's an operating system. And the skills people are building for it are the applications.
Agent Infrastructure Grows Up
If 2025 was the year of the agent demo, 2026 is shaping up to be the year of agent infrastructure. The tooling around how agents interact with codebases, browsers, and security data is getting serious, production-grade attention from both major companies and independent developers. The focus has shifted from "can an agent do this?" to "how do we make agent workflows reliable, observable, and composable?"
Microsoft dropped a significant Playwright update called Webwright, built specifically for agentic browser use. @mr_r0b0t highlighted that every browser session becomes a reusable workflow, and the repo ships with a NousResearch Hermes Agent skill out of the box. This is Microsoft implicitly acknowledging that browser automation is no longer primarily a testing concern. It's an agent concern. When your agent can record a browser workflow and replay it deterministically, the entire web becomes a programmable API surface. The gap between what agents can reach and what they can reliably interact with just narrowed considerably.
On the code management side, Matt Pocock @mattpocockuk shared his evolved approach to using GitHub labels to trigger agent actions. Labels like agent:implement, agent:review, and agent:to-issues turn GitHub's existing interface into an agent control panel. "Tried this 6 months ago but I didn't like it," he admitted. "Pure skill issue on my part, it actually rocks." The honesty is refreshing and the pattern is powerful. Instead of building custom agent dashboards that nobody wants to maintain, use the collaboration tool developers already live in. A label is a lightweight, reviewable, auditable instruction that fits naturally into existing workflows.
Garry Tan @garrytan amplified a deep analysis from @koylanai on SkillOpt, a research paper that treats markdown skill files as trainable parameters with proper optimization machinery. The key insight: "Frozen model + trained context is the practical adaptation." A smaller model with an optimized skill file can match frontier behavior on procedural benchmarks at zero inference-time cost. @koylanai's practical findings were equally valuable: bounded edits of 4-8 per step outperform full rewrites, compact skills around 920 tokens consistently beat verbose ones, and the verification bottleneck remains the hardest unsolved problem in the space. He also noted a structural finding from the paper: removing the protection that prevents fast edits from overwriting slow-learned lessons cost 22 points on benchmarks. Skill optimization needs guardrails, not just gradients.
In security, Diana Damenova @dianadamenovaa highlighted @Cyb3rWard0g's presentation at NDC Security on agentic workflows that use code-driven analysis rather than simple query-and-summarize patterns. The approach lets agents orchestrate tools through Python and DataFrames, documenting everything in Jupyter notebooks that analysts can review, critique, and reuse. "The goal is not to replace the analyst. It is to accelerate and complement the data analysis stage, making it more transparent, repeatable, and useful," the presentation emphasized. This is the mature framing that separates production agent tooling from conference demos.
Open Source Takes Aim at Expensive SaaS
The open source community is building direct replacements for some of the most expensive SaaS categories, and the quality gap is closing fast enough to make venture-backed incumbents nervous. Today's standout is Nango, an open source integration layer that Sukh Sroay @sukh_saroy described as the thing "every SaaS company has been paying $50,000 a year to rent."
Nango provides managed OAuth for 700+ APIs out of the box, handles token refreshes, rate limits, retries, and per-tenant isolation. Companies like Replit, Ramp, and Mercor already run it in production. It includes an AI builder that generates integration code from natural language prompts and outputs readable TypeScript you own and version control. The "unified API" startups that raised hundreds of millions selling this exact capability as closed-source software are suddenly competing with a GitHub repo that has 7.4K stars, 726 forks, and 189 releases. The license is Elastic, not MIT, so you can self-host commercially but can't resell it as a competing service. For 99% of teams building integrations into their product, that distinction doesn't matter at all.
Hayden Bleasel @haydenbleasel shipped Files SDK v1.6, described as their biggest release yet, with a focus on observability and cross-provider workflows. Hooks for actions, errors, and retries, plus multipart uploads and range downloads, signal that file handling in AI applications is becoming a first-class engineering concern. When agents are moving large files between providers and you need to know exactly what happened when something fails, ad-hoc error handling doesn't cut it.
On the performance front, Rach @rachpradhan announced codedb v0.2.5818 with striking benchmarks: roughly 1 microsecond per lookup, 50,000x faster than grep, 20-30x faster wall-time, and 49% fewer tokens consumed. The tool has saved 2.4 billion tokens across 200,000+ operations in the last 30 days. When your code search is fast enough that agents can query it reflexively without token budget anxiety, the way agents explore and reason about codebases fundamentally changes. Speed at this scale isn't a nice-to-have. It's an enabling constraint.
The Future of Work: Agents, Not Apocalypses
Lenny Rachitsky @lennysan compiled ten takeaways from his conversation with Dan Shipper that paint a nuanced, grounded picture of where AI-powered work is actually heading, a useful corrective to both the utopians predicting zero-cost labor and the doomers predicting mass unemployment.
The most provocative claim is also the most empirically supported: "Automation is a lie. Every automation needs a human." Shipper's company doubled in size this year despite being deeply AI-forward, precisely because keeping automations running requires people who understand the systems they orchestrate. This is the paradox of AI-native organizations. The more you automate, the more you need skilled humans maintaining the automation layer and catching the edge cases that no workflow anticipates. Shipper also predicted that every company will have one "super-agent" in Slack, maintained by a forward-deployed engineer, rather than every employee running a personal agent. The reasoning is pragmatic and behavioral: agents need humans who actively care about them, and personal agents degrade when their owners lose interest or get busy.
On SaaS, Shipper made a contrarian bullish case. When users bring their own AI agents to use SaaS products through in-app browsers, the user pays for tokens, not the SaaS company, protecting margins. And since agents need their own seats and make high-volume API calls, agent usage will create massive new demand. "I would buy SaaS stocks right now," he said. It's a neat inversion of the "SaaS is dead" narrative: agents don't replace SaaS, they multiply it.
The PM and designer roles emerged as unexpected winners. PMs who become AI-native will be "incredibly dangerous" because the building is commoditized by agents but figuring out what to build and whether it's great remains a human skill. Designers are becoming full-stack builders because AI eliminates the traditional handoff bottleneck with engineering. The common thread: roles that combine taste, empathy, and strategic thinking gain enormous leverage from AI, while roles that are purely execution-oriented get squeezed from both sides.
From a different era but strikingly relevant, @Etudecn resurfaced a 45-minute closed-door talk Elon Musk gave at Stanford in 2003, walking through how to build a company from zero using his own three companies as live case studies. The talk was described as "worth ten entrepreneurship books" because it contains the kind of operational detail that usually stays behind closed doors. The resonance with today's posts is clear: the fundamentals of building something from nothing haven't changed, even as the tools have evolved beyond recognition. The builders who combine those timeless fundamentals with the new leverage of AI agents will be the ones worth watching.
Sources
https://t.co/MLdudKz6on i sent sero the tech and posted on github for me, i just got added to it so il update the repo soon with all the fixes that make it run smoothly. i also added prompt catching which makes your shim which makes it several times cheaper and faster :) from my testing around 7x cheaper and 5-10x faster
Trump is pushing a peace deal Israel doesn't want, Iran hasn't confirmed, and nobody can price correctly. That's exactly where the edge is. Here's what's actually happening. Trump declared the deal "largely negotiated" - but Iran made zero public confirmation. > Netanyahu's office has "serious concern and disappointment". Israel is demanding full dismantlement of Iran's nuclear program and removal of all enriched uranium before anything gets signed. > The real negotiation isn't about peace. It's about the Strait of Hormuz. One Israeli official called it "a weapon no less effective than nuclear weapons." Iran knows this. The US knows this. Opening the Strait is Iran's leverage - and the price they're extracting for any agreement. > Three scenarios right now: Optimistic: deal signed in 1-3 days after political alignment. Hormuz opens partially. Oil risk drops. Base case: 1-2 weeks of further negotiation. Partial framework, not permanent peace. Breakdown: nuclear terms, sanctions, and Hormuz don't align. Talks collapse. // I will use @CrispPredict for trading // Permanent peace by May 31 is trading at 12 cents. By June 30 at 29 cents. Someone is wrong about the timeline. Find the edge on -> https://t.co/UwtTEVD9Yk
Automation is a lie. CLIs are over. The SaaSpocalypse is dumb. A year ago @danshipper came on the podcast to predict where AI was heading. He was remarkably right—including the call that everyone was sleeping on Claude Code. Dan has a unique lens into where things are going because his team at @every is possibly the most AI-pilled group of people in tech. I always learn a ton talking to Dan. So I brought him back for round two. We'll score these in exactly a year: 🔸 Every company will have one “super-agent” in Slack. 🔸 Codex and Claude Code will become the new operating system for knowledge work. 🔸 The AI job apocalypse is not happening. 🔸 PMs and designers will thrive. 🔸 We will read way more AI-generated writing and we will like it. 🔸 "I would buy SaaS stocks right now." Listen now 👇 https://t.co/wzxQ5bz49h


🤖 Agentic security workflows that involve data analysis typically focus on one pattern: generate the right query, run it, and pass the results back to the language model to summarize or analyze. That pattern can be useful, especially for a few iterations or when the agent is guided by well-scoped correlations, known attack patterns, existing detections, or query templates. 🔍 But sometimes the last step gets blurred: a summary with a few stats is not always the same as data analysis 🧐. When investigating an alert or exploring a larger dataset, analysts often need to keep processing the results, and this is where code-driven analysis can help. Let the agent orchestrate tools through code, process results with Python and DataFrames, and document the workflow in a notebook. Why I think this matters: - Let code compute the counts, filters, groups, and joins. - Let the agent reuse intermediate results across steps. - Let the notebook show how the analysis was produced. - Let analysts review the workflow, not just trust the answer. - Let useful exploration steps become repeatable playbooks. You can take this further by using AI Skills to encode your team's investigation methods, data analysis techniques, and best practices, so autonomous data analysis follows a structured and repeatable workflow. The goal is not to replace the analyst. It is to accelerate and complement the data analysis stage, making it more transparent, repeatable, and useful across any security domain where data supports the engagement 💜. Happy I had the opportunity to share these ideas in my latest presentation at #NDCSecurity. Thank you, @NDC_Conferences , for the opportunity 🙏🏽. 🚀 GitHub Repo: https://t.co/Ny9pCUSJs3 🤖 arXiv Paper - Executable Code Actions Elicit Better LLM Agents: https://t.co/RU1JjIcWDy 📺 Presentation: https://t.co/8evsZndRgm #AgenticSOC #NDCSecurity #AIAgents #Jupyter #AI #CyberSecurity #LLM #DataAnalysis
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness. SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them. A few things I learned that you should consider too. 1. The validation gate is the only thing that matters in a self-editing loop. Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop. 2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot. Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size. 3. Compactness wins. Median final skill: ~920 tokens. Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't. 4. The harness is becoming less important; the skill is becoming more important. A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that produced it. 5. Frozen model + trained context is the practical adaptation. GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models. 6. Verification is the bottleneck. Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage. There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7, gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK: - Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it. - Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is. Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured. The fast/slow split they describe already lives implicitly in the digital-brain-skill repo: - voice-guide and tone-of-voice.md are slow-state (rarely touched) - posts.jsonl and bookmarks.jsonl are fast-state What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing. If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv