Multi-Agent Teams Eclipse Single-Model Workflows as Anthropic Teases Claude Memory Files and Local Inference Heats Up
The conversation around AI has shifted decisively from prompt engineering to agent architecture, with multiple high-profile voices arguing that single-agent workflows are already obsolete. Anthropic continues expanding its ecosystem with a new memory upgrade and a notable hire, while developers show that small local models like Qwen 3.5-4B can power sophisticated agent memory stacks on consumer hardware.
Daily Wrap-Up
If there was one unmistakable signal across today's feed, it is that the AI community has moved past the era of chatting with a single model and calling it productivity. From Boris Cherny's talk about Claude Code's multi-agent architecture to Garry Tan's metaphor of building the cerebellum before the prefrontal cortex, the consensus is clear: teams of specialized agents working in concert are the new baseline for serious AI work. This is not theoretical. People are shipping these systems today, and the posts that resonated most were the ones showing exactly how.
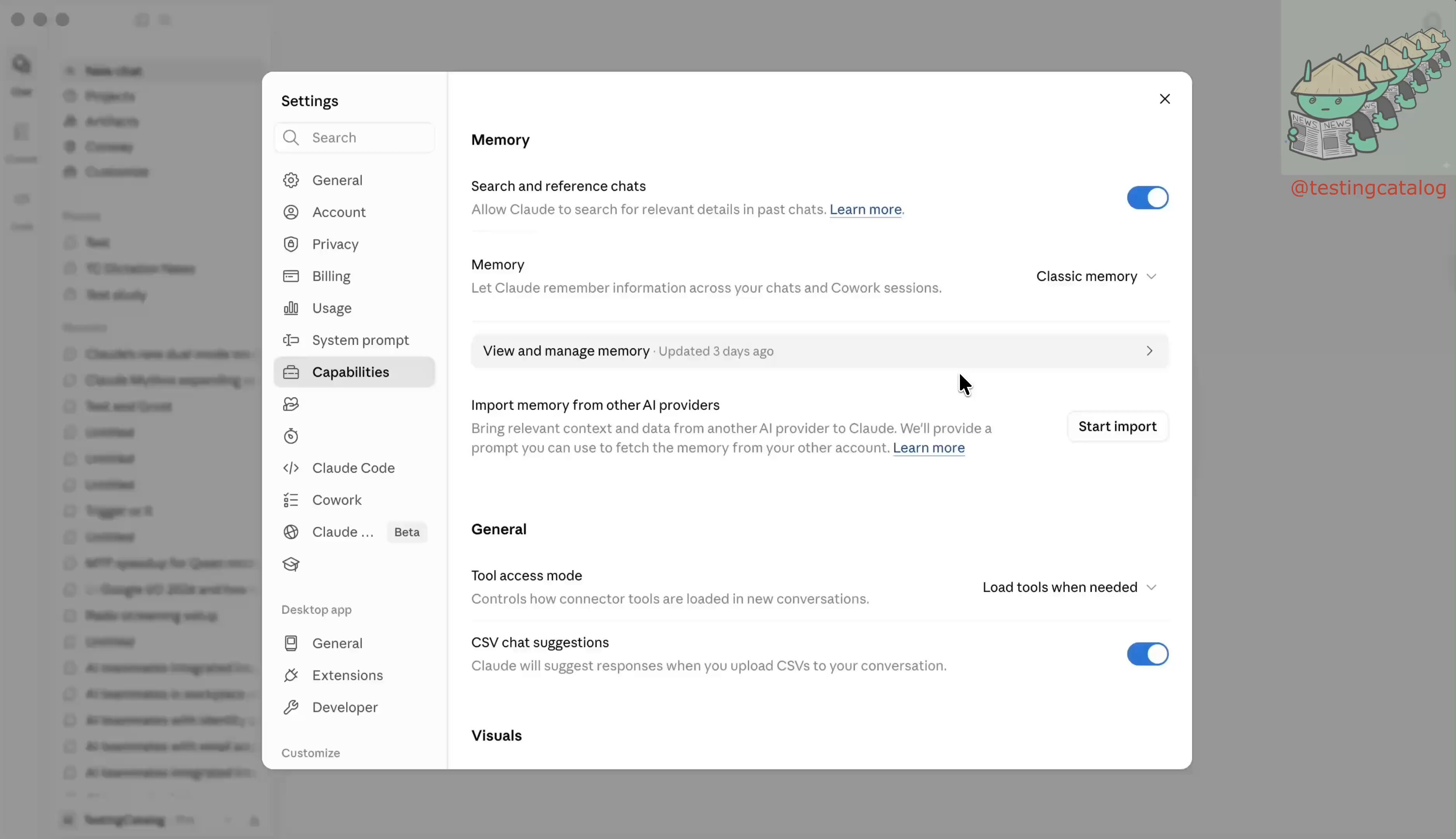
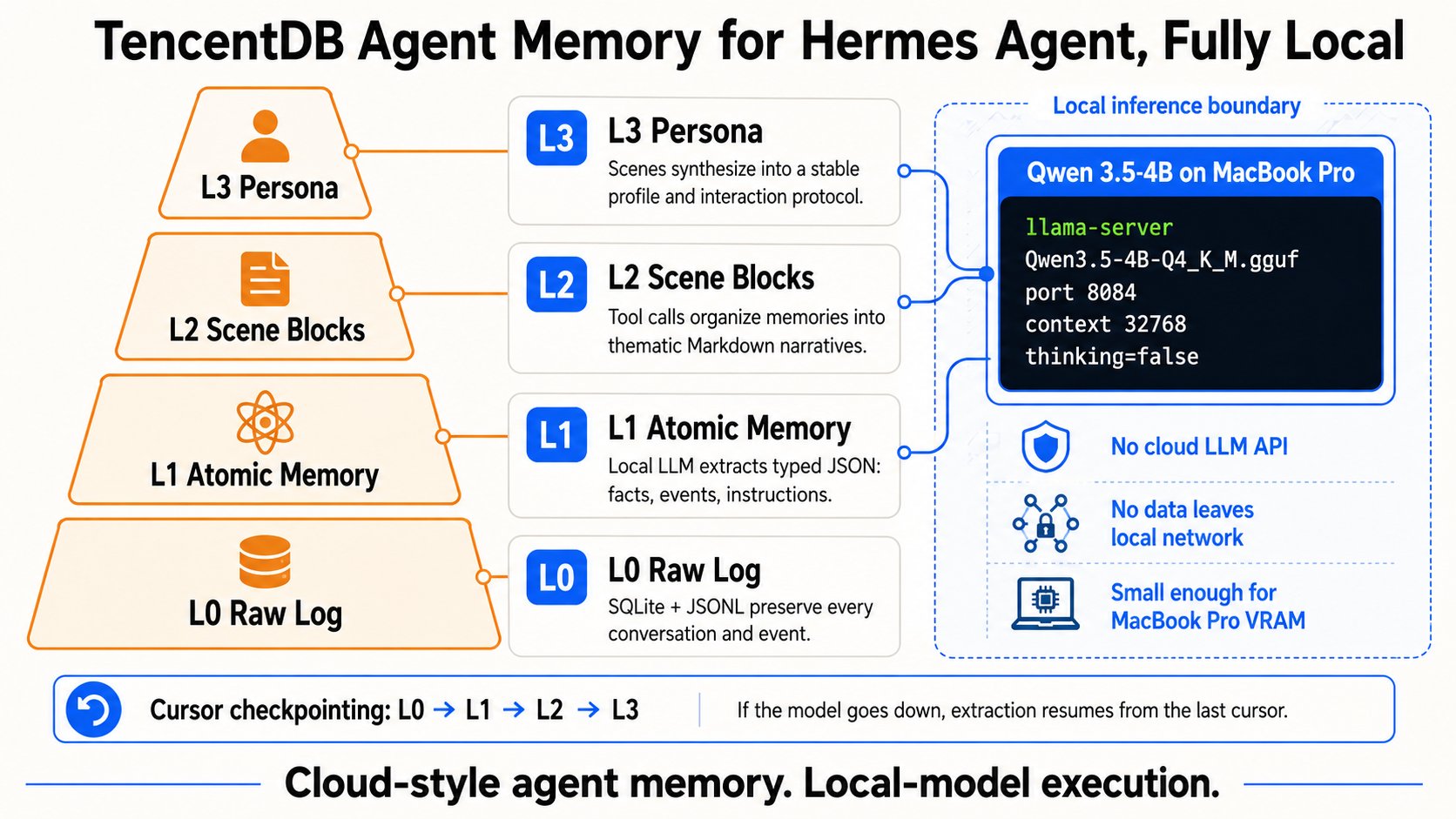
Anthropic sits at the center of this shift in multiple ways. TestingCatalog reported that Claude will soon get a file-based memory system that lets users browse and edit organized notes, a feature that looks like preparation for always-on agent experiences. Meanwhile, @sattyyouneed broke the news that @dudufolio has joined Anthropic, continuing the company's aggressive talent acquisition. And at the infrastructure level, developers like @Michaelzsguo are wiring TencentDB's layered memory architecture to Qwen 3.5-4B running locally on a MacBook Pro, proving that agent memory does not require cloud-scale infrastructure or massive models.
The most practical takeaway for developers: stop trying to find the perfect single prompt and start decomposing your workflows into discrete, repeatable steps that specialized agents or skills can own. Whether you use Karpathy's autonomous research setup, Vaibhav Srivastav's Codex workflow auditor, or simply break your next project into researcher/builder/reviewer roles, the compound advantage of multi-agent orchestration is already too large to ignore.
Quick Hits
- @tpschmidt_ shares a pragmatic AWS rule: never build on fancy abstractions, only primitives. Six container services that tried to simplify ECS are now archived, EOL, or shut to new customers.
- @reevo_ai pitches an AI-native CRM built from scratch, arguing that legacy CRMs predate AI entirely.
- @zavudev warns that unofficial WhatsApp libraries can get expensive fast when banned numbers block messages for your users. Their platform offers the official Cloud API with automatic fallback to SMS and email.
- @Teslahubs promotes ProGuard, a weather-sealing kit that claims up to 6x less cabin noise for Teslas with a 20-40 minute no-tools install.
- @mumaren_2 shares a curated "Follow Builders, Not Influencers" list featuring Karpathy, swyx, Amanda Askell, and dozens of others worth tracking for substantive AI content.
- @MichaelHyatt asks whether to install the Hermes agent locally or on a VPS, signaling that always-on personal agents are reaching mainstream adoption curiosity.
The Multi-Agent Imperative: Specialized Teams Beat Single Models
The most striking pattern today is how many independent voices converged on the same conclusion: single-agent workflows are a transitional phase, not the destination. @eng_khairallah1 summarized a talk by Boris Cherny, the creator of Claude Code at Anthropic, who argued that the future is teams of agents, not better prompts. The breakdown is surgical: one agent researching, one building, one reviewing, one orchestrating. Cherny also highlighted that CLAUDE.md alone consumes roughly 14% of context before you type a single word, which means context budgeting is already a critical architectural concern.
This maps directly onto @garrytan's framing of the problem. "Everyone building AI agents is focusing on building the prefrontal cortex. Planning. Reasoning. Multi-step chains," he wrote. "But also, a reframe: there is value in building the cerebellum." His argument is that most agent frameworks will fail because they treat all cognition as high cognition. The winners will nail the boring, reflexive stuff first. Your mortgage gets paid by a standing order, not a committee. The same should be true for automated workflows.
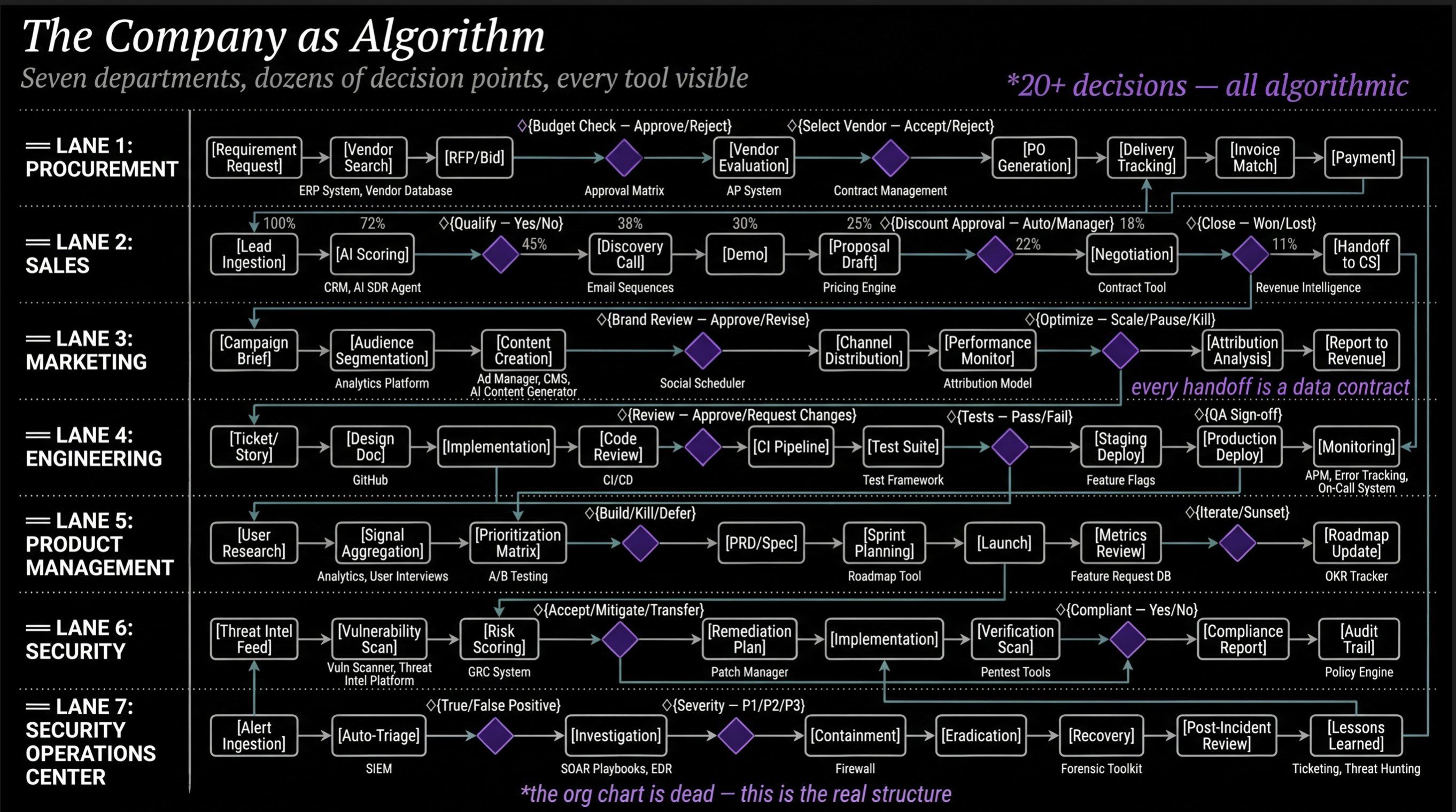
@DanielMiessler took this further by sketching what companies will actually look like when this plays out: graphs of algorithms that are transparent and optimizable, with humans stepping in only as exceptions to be resolved. "Humans doing the main, anticipated work will be a failure case to be solved," he wrote. SOPs and clearly articulated workflows, similar to what Anthropic is building, become the core operational layer.
On the practical side, @rohit4verse shared a concrete setup based on Andrej Karpathy's open-sourced autonomous research agent. The process is elegantly simple: a coding agent edits one file, trains for five minutes, keeps the change if validation loss drops, and reverts if it does not. Git is the memory. The metric is the judge. You wake up to a staircase of validated improvements. Meanwhile, @reach_vb published a detailed Codex prompt that audits your last 30 days of work, identifies repeated manual workflows, and packages them as skills, subagents, or automations. The prompt is remarkably thorough, specifying evidence hierarchy, confidence thresholds, and explicit skip criteria to avoid over-automation.
Tying this all together is @BetterCallMedhi's analysis of Ramp, which he describes as one of the most fascinating companies right now precisely because it is building specialized agent swarms trained on proprietary data rather than relying on generalist LLMs. Ramp's Fast Ask subagent, built with PrimeIntellect using reinforcement learning, scores 4% above Opus on exact match accuracy at Haiku latency. That is the multi-agent thesis in production: small, specialized models that outperform giants on vertical tasks at a fraction of the cost.
Anthropic's Expanding Ecosystem
Anthropic is positioning itself as the platform layer for the multi-agent future, and today's posts show multiple vectors of that expansion. @testingcatalog reported that Claude will soon receive a file-based memory upgrade called Memory Files, offering users a choice between organized notes and classic memory. The feature lets Claude write notes as you chat and read them when relevant, with full browse and edit capabilities. TestingCatalog notes this appears to be an evolution of the previously discovered "Knowledge Bases" feature and closely resembles memory systems in always-on agents like OpenClaw and Hermes. The implication is clear: Anthropic is building toward persistent, stateful agent experiences, and memory is the foundation.
The hiring front is equally active. @sattyyouneed reported that @dudufolio has joined Anthropic, adding to a growing roster of talent focused on safety and product. Combined with Cherny's public talks about Claude Code architecture and Daniel Miessler's references to upcoming Anthropic workflow releases, the picture is of a company systematically assembling both the people and the infrastructure for an agent-native platform.
Agent Memory and Local Inference
One of the most technically detailed posts today came from @Michaelzsguo, who wired TencentDB Agent Memory to Qwen 3.5-4B running locally through llama-server on a MacBook Pro. The architecture is a layered memory stack: L0 stores raw logs in SQLite and JSONL, L1 extracts typed JSON memories, L2 organizes them into Markdown narratives, and L3 generates a coherent persona synthesis. Each layer uses cursor-based checkpointing, so if the local model crashes, the pipeline resumes seamlessly. His choice of Qwen 3.5-4B is telling. It was the smallest model that could reliably handle both structured JSON extraction and multi-step tool use. Qwen 2.5-3B was too brittle. The local inference sweet spot is moving fast.
This pairs naturally with @ItsmeAjayKV's appreciation post for Qwen 3.6, the 35B Mixture-of-Experts model running on a consumer 3060 GPU. He has burned over a million tokens across Hermes, the Pi coding agent, and other tools, all locally. The open-source local model ecosystem has reached a point where daily-driver inference on consumer hardware is genuinely practical for production agent workloads.
Developer Tooling for the Agent Era
The tooling layer is catching up to the ambition. @AniC_dev introduced Box, a sandboxing solution built specifically for agents that promises to be both simple and affordable. Sandboxes are critical infrastructure for any multi-agent system that needs to execute arbitrary code safely, and the current options are either expensive or complex. Box appears to target that gap directly.
@BHolmesDev shared his experience with Matt Pocock's Skills library, using a grill-with-docs command for major feature work and a handoff command for side-quests he does not want to context-switch into. Instead of temporary markdown files, he tracks these in GitHub issues, which is a small but significant workflow improvement that keeps agent-generated tasks visible to the whole team.
@mitsuhiko, known for Flask and Sentry, wrote about his learnings maintaining Pi as a junior contributor to @badlogicgames. The post touches on agentic engineering from the maintainer's perspective, a viewpoint that is underrepresented in a conversation dominated by builders and users. As AI agents increasingly interact with open-source projects as contributors, the maintenance burden and workflow implications for project maintainers will become a first-class concern.
The AI Productivity Paradox
@thdxr captured a frustration that many developers feel but few articulate clearly: looking back at past projects, it seems obvious they would have been completed faster with AI, yet everything still feels as slow and difficult as ever. This is the productivity paradox of AI tooling. The tools are demonstrably faster at individual tasks, but the overall cadence of complex projects has not meaningfully accelerated. The bottleneck has shifted from execution to integration, decision-making, and the overhead of orchestrating AI assistance itself.
@addyosmani named a related concept: cognitive surrender, defined as the moment you stop thinking altogether and blindly accept the answer the AI gives you. It is the psychological mirror of the productivity paradox. When AI speeds up the easy parts of a task, the remaining hard parts feel harder by contrast, and the temptation to surrender critical judgment grows precisely when it matters most. Together, these two observations frame the real challenge of the agent era. The technology for multi-agent systems, local inference, and persistent memory is arriving faster than our workflows and habits can adapt. The developers who benefit most will be those who treat AI as a system to be architected, not a magic button to be pressed.
Sources

https://t.co/WO3VvIgJZ2


Copy and paste this into your codex: “Look through my recent Codex sessions and identify repeated workflows or repeated asks. For anything I keep doing manually, suggest: 1. a skill if it is a reusable workflow 2. a custom subagent if it is a bounded role or investigation task Focus on practical things like CI failures, PR reviews, changelogs, docs updates, release prep, debugging, and test triage. Create the useful ones only. Keep them simple.”



We partnered with @PrimeIntellect to build Fast Ask, a small RL-trained subagent that helps our Sheets agent find answers in spreadsheets. It scores +4% over Opus on exact match accuracy at Haiku latency. https://t.co/GJQvHJjABl
Interesting.

是不是烦透了时间线上的垃圾内容? 然后刷了半天刷不到有用信息? 今天分享一个X的小技巧 只要3步帮你轻松解决信息源的问题! 1.选择你喜欢的博主,点击右上角,从列表中添加 2.选择添加列表,自定义列表名称,比如我这里有个AI信息源,就是所以我觉得好的AI博主的列表,看到就更新 3.配置时间线,在设置—时间线—主页标签中,可以自定义列表位置和内容 这样设置完,如果看到感兴趣就添加到列表中,每天刷刷列表就行了 如果觉得有用的话,点个赞吧!
How to Build a Claude Research Agent That Reads the Internet Every Morning and Briefs You in 5 Mins