Consumer GPU Inference Breaks 97 TPS as DeepSeek's 10 Trillion Dollar Long Game Comes Into Focus
Local AI inference is hitting remarkable new benchmarks on consumer hardware, with Qwen 3.6 running at nearly 98 tokens per second on a single RTX 3090. Meanwhile, DeepSeek's strategy of radical architecture innovation aims to bootstrap an entire Chinese AI hardware ecosystem, and the Claude Code community discovers hidden settings that silently inflate costs.
Daily Wrap-Up
Today's signal is unmistakable: local AI inference is no longer a curiosity for hobbyists. It's becoming a practical reality that competes with cloud services on both speed and cost. @malikwas1f hit 97.8 tokens per second running Qwen 3.6 27B dense on a single RTX 3090 without overclocking. @antirez demonstrated that NVIDIA's DGX Spark handles DeepSeek-V4 smoothly despite asymmetric prefill and generation speeds, proving that even "not very fast generation" feels perfectly usable at the right latency profile. And @ivanfioravanti is already thinking about porting workflows to Apple's local LLM stack. The hardware democratization story that felt aspirational six months ago now has shipping numbers.
On the industry strategy front, the most thought-provoking thread of the day belongs to @mark_k, who surfaced a deep analysis of DeepSeek's real play: they're not chasing coding subscriptions or multimodal demos. They're using radical architecture innovations like MoE, MLA, and Engram to slash compute requirements so dramatically that they can bootstrap a 10 trillion dollar Chinese AI hardware ecosystem built on NAND, LPDDR, and custom ASICs. @cjzafir illustrated the downstream effect nicely, generating 200M high-quality training samples for about $60 using Codex 5.5 as orchestrator and DeepSeek-V4-Pro as executor, taking advantage of DeepSeek's newly permanent discount pricing.
The most practical takeaway for developers: audit your AI tool configurations. @Mnilax's deep dive into Claude Code's settings.json revealed 125+ keys with only ~40 documented, including a "10% Opus tax" many apps pay silently through inference_geo settings and a deny-rule bug where your config says block but the binary reads anyway. Four of the settings they found aren't documented anywhere. If you're running Claude Code in production, that article is required reading.
Quick Hits
- @garrytan fine-tuned a custom Qwen 3.5-397B model in a couple of hours using Thinking Machines, and predicts that fast usable multimodal will enable "very mind-blowing personal AI."
- @steren showed that Liquid DOM actually renders real DOM inside canvas elements,Inspectable with Chrome DevTools, which could open a new era of web UIs that blend canvas performance with HTML semantics.
- @soumitrashukla9 highlighted Andy Hall's research agenda on the political economy of AGI, calling it essential reading for anyone who wants thoughtfully designed systems rather than ones controlled by a few overlords.
- @fingerprint.dev demoed a visitor identification API that survives cookie clearing and incognito mode, replaceable with a single curl command.
Local Inference Gets Real
The local AI movement has been promising for years, but today's posts suggest it has crossed an important threshold. The benchmarks are no longer about "can it run?" but about "how fast can it run on hardware I already own?" And the answer is surprisingly fast.
@malikwas1f shared a staggering result: 97.8 tokens per second running Qwen 3.6 27B dense on a single RTX 3090, no overclocking. For context, that's approaching the reading speed of many humans, and it's on a GPU that costs well under a thousand dollars on the used market. The recipe is apparently still cooking, but the headline number speaks for itself.
Meanwhile @antirez, the creator of Redis, offered a more nuanced take on the DGX Spark experience with DeepSeek-V4. "I want to post this to show how with fast prefill and not very fast generation, the system remains absolutely fine to use." This is an important insight that the benchmark crowd often misses: latency perception isn't just about raw tokens per second. A fast prefill means the first token appears quickly, and even if subsequent generation is modest, the user experience remains fluid. It's the AI equivalent of time-to-first-byte mattering more than download throughput for web browsing.
@ivanfioravanti flagged the comprehensive LLM resource that covers everything from tokenizers to quantization to local deployment, then immediately asked about creating an Apple-specific version for local LLMs. The education gap is closing just as the hardware gap is, and the combination of accessible learning materials and accessible hardware is a force multiplier for the entire ecosystem.
Taken together, these posts paint a picture of local inference maturing rapidly across multiple hardware tiers: consumer GPUs for the budget-conscious, NVIDIA's DGX Spark for the premium desktop experience, and Apple Silicon waiting in the wings. The cloud-vs-local debate is becoming a question of use case rather than capability.
DeepSeek's Grand Strategy and the Cost Revolution
The most strategically significant thread today was @mark_k's summary of a deep analysis into DeepSeek's real ambitions. The framing is worth quoting directly: "They're not chasing quick money from coding plans or multimodal models. Instead, their radical architecture innovations (MoE, MLA, Engram, mHC, etc.) slash KV cache and compute needs so dramatically that they can build an entire 10T Chinese AI hardware ecosystem (NAND, LPDDR, ASICs) and position themselves for a 1T valuation in the process."
This reframes DeepSeek from "the Chinese AI lab that makes cheap models" to something far more ambitious: an infrastructure play that could reshape the global AI hardware landscape. By making models dramatically more efficient, they reduce dependence on NVIDIA GPUs and create room for alternative hardware. If your model needs one-fifth the compute, you don't need cutting-edge HBM. You need commodity NAND and LPDDR, which China can manufacture at scale.
@cjzafir demonstrated the practical downstream effect of this strategy. Using DeepSeek-V4-Pro as an executor with Codex 5.5 as orchestrator, they generated a 200M high-quality training dataset for approximately $60. DeepSeek had just announced their discount pricing is now permanent, and the community is already finding creative ways to exploit those economics. The cost of generating synthetic training data has dropped by orders of magnitude, and it's enabling workflows that would have been prohibitively expensive even a year ago.
The broader implication is that we may be entering an era of permanent AI price deflation driven not by charity but by strategic positioning. DeepSeek isn't discounting to gain users. They're discounting because their architecture makes it profitable to do so, and every project built on their cheap inference strengthens the ecosystem they're trying to build.
Claude Code's Hidden Configuration Maze
If you're using Claude Code and haven't looked at your settings.json, today's the day to change that. @Mnilax published a meticulous audit of Claude Code's configuration that revealed a sprawling system hiding in plain sight.
"the creator of Claude Code told a London stage on Wednesday that the default is now Claude prompting itself. but Boris Cherny didn't say one word about the settings.json that self-prompting runs on." The audit found 125+ keys in the configuration, only about 40 of which are documented. Four settings Mnilax identified aren't documented anywhere at all.
Two findings stand out. First, a known deny-rule bug where your config says to block something but the binary reads anyway, silently ignoring your preferences. Second, what Mnilax calls the "10% Opus tax," a default inference_geo setting that causes many applications to pay roughly 10% more than necessary on Opus usage. For teams running Claude Code at scale, that's real money leaking through an undocumented setting.
This connects to a broader pattern in AI tooling right now: the configuration surfaces are expanding faster than the documentation can keep up. As these tools become more powerful and more autonomous, understanding their configuration becomes less of a nice-to-have and more of a core competency.
AI Agents, VMs, and the Architecture of Autonomy
Two posts today tackled the question of how AI agents should be architected from completely different angles, and together they sketch an emerging consensus.
@kozlovski shared a deep conversation with David Crawshaw, ex-CTO of Tailscale and now CEO of exe, a new cloud provider. The core argument is that AI agents need virtual machines, not containers. The reasoning: agents need full system access, persistent state, and the ability to install and modify their own environments in ways that container abstractions actively resist. A container is designed to be immutable; an agent needs to mutate. A VM gives you a complete operating system that the agent can reshape as needed, from installing packages to modifying system configurations.
Crawshaw also touched on the exorbitant price of IOPS in the cloud, the rise of self-hosting, and the hard problem of building AI SRE agents that can actually operate production systems. The thread about dropping an idea prompt from your phone and having an agent spin up a VM to work on it captures the vision nicely.
On the software side, @mattpocockuk offered a concise design philosophy for agent "skills" that complements the VM argument. Skills should be concise, responsible for one thing, composable, progressively disclosed, and harness-agnostic. This is essentially the Unix philosophy applied to AI agents: small tools that do one thing well and can be combined into complex workflows. If agents are going to live in VMs and reshape their environments, the skills they use need to be modular enough to compose without creating fragile dependency chains.
The convergence is clear: agents need both infrastructure-level flexibility (VMs) and software-level modularity (well-designed skills). The agents that work will be the ones that can autonomously provision their environments and then compose narrow, reliable capabilities within them.
Jobs, Tasks, and the Automation Paradox
@levie delivered one of the clearest articulations of the "tasks aren't jobs" argument that the AI discourse desperately needs. The thread was sparked by @danshipper's report that Every has automated everything they can with AI agents and still grown from 4 to 30 human employees.
As Levie puts it: "We are constantly making the mistake of confusing task completion with AI with being able to eliminate the whole job. Even as we can automate one or many tasks within a job, the definition of the job almost inevitably just expands to do vastly more of those tasks, do them at a higher quality, or move on to the type of task that hasn't been automated yet."
The examples are concrete. Small businesses that couldn't afford software projects can now take them on, so they hire developers. Companies that couldn't afford a marketing agency can now hire a single marketer armed with AI agents. The automation doesn't eliminate the role; it changes who can afford to fill it and what they can accomplish. This is the Jevons Paradox applied to cognitive labor: making something cheaper increases total demand for it.
@DanielleMorrill offered a sharper-edged take on the same dynamics, noting that "AI is revealing managerial effectiveness to be a moral fiction." The implication is that much of what we called management was really just coordination overhead that AI can handle, and the parts that remain are the ones that actually required human judgment all along. It's an uncomfortable observation for anyone who built a career on roadmap curation and status meeting facilitation.
Developer Tools and Testing in the AI Age
The quieter but practically important theme today was developer tooling evolving to meet the reality of AI-assisted workflows. @steipete shared his current setup splitting Codex between the Mac app for knowledge work, learning, and reading, and cmux with the Codex CLI for actual coding. cmux is a terminal multiplexer that's apparently winning over experienced developers who need to manage multiple AI coding sessions simultaneously. The split between "thinking with AI" and "building with AI" as distinct workflows with distinct tooling is a pattern worth watching.
@dillon_mulroy highlighted @jlongster's work on testing tooling designed specifically for the age of AI. As AI-generated code becomes more common, the testing layer becomes the critical quality gate, and tooling that understands the patterns and failure modes of AI-generated code is going to be essential. The specific tools weren't detailed in the post, but the endorsement from someone who works with AI tooling daily carries weight.
Sources
We are making our discount permanent! 🎉 Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀 https://t.co/V8atbTaogH
if you run an ai lab, pls ensure your team has read this before putting any charts out into the world https://t.co/OkFUOpVJ4C
UNBELIEVABLE RESOURCE The bible for understanding LLMs is NOW AVAILABLE online to read (FOR FREE) Covers all the concepts below, no experience needed and anyone from any background can understand it - Tokens / Tokenizers - Transformers - Attention - KV Cache - Prefill vs Decode - Decoding Controls / Samplers - Agents / Tools - Model Packages - Chat Templates - Long Context - Multimodality - RAG - Fine-tuning Then connects that to running models locally - What "Local AI" Really Means - Open-weight vs Opensource - Quantization - VRAM Math - Hardware tiers - File formats / load safety - Runtimes / serving modes - Model selection - Privacy - Failure modes - Benchmarks - Practical setup paths You should read this, and if you cannot now then you most definitely wanna bookmark it for later Opensource / Local AI FTW
The Roadmap Defense Is Collapsing
Here's my research agenda for the political economy of AGI. https://t.co/nXZhDCYTCE https://t.co/L35Eqpjuco
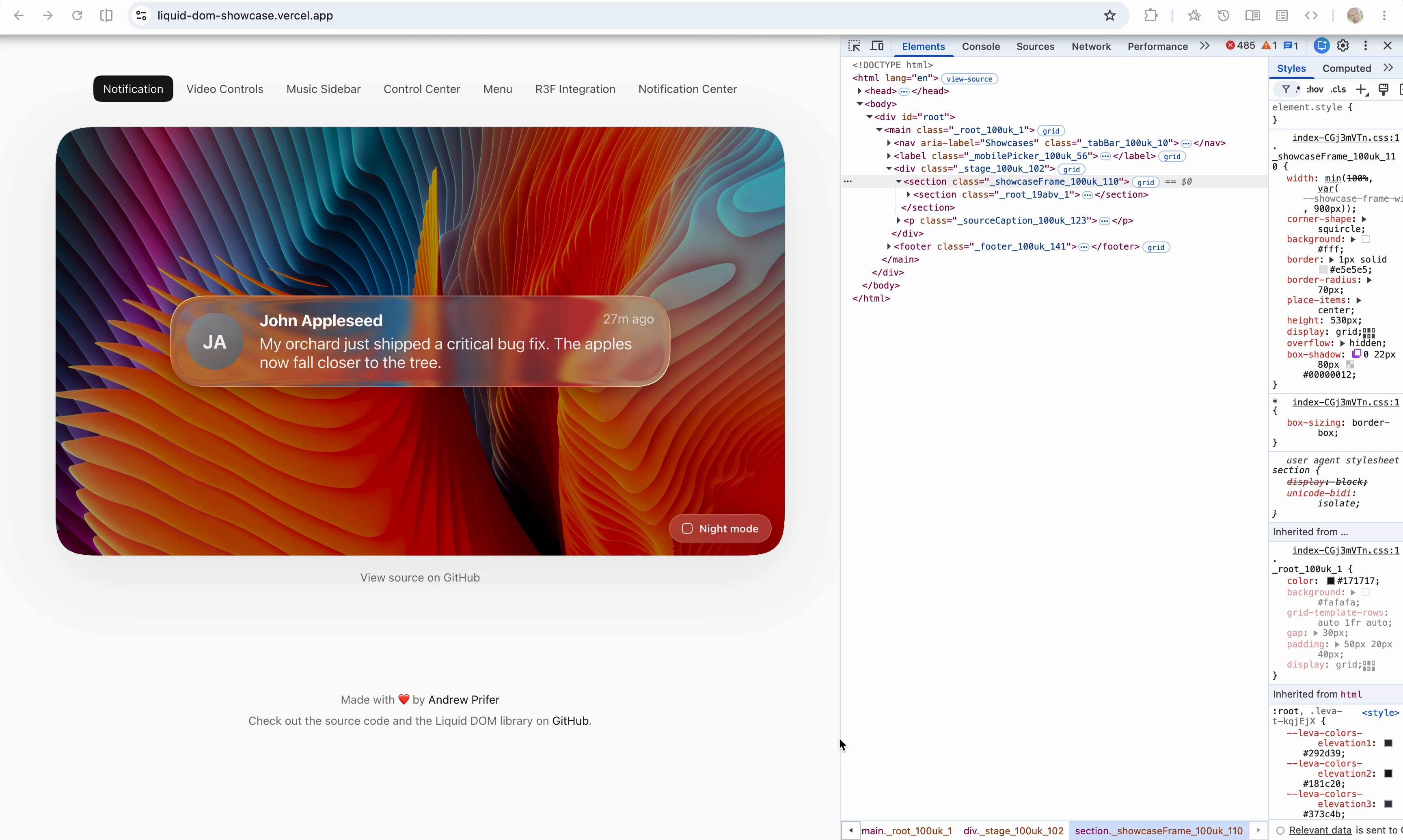
Dear frontend devs and UI designers. I bring you Liquid DOM, a complete and faithful implementation of Liquid Glass on the Web. - Shape morphing - All properties animatable - Dynamic refraction and reflection - Adaptive tint - Adaptive specular highlight - Dispersion - Full html integration - Super fast layout engine that works across Canvas and html - Pointer event handling - Framework and renderer-agnostic low level API - High level React API - Ootb @threejs and r3f integration And lots more. Read on for implementation details and demos.
We’ve automated every single thing we can @every with AI agents. And yet there’s way more human work to do than ever. We’ve gone from 4 -> 30 human employees since GPT-3. I wrote a report on the structural reasons: how AI makes expert competence cheap, why that drives up demand for experts, and why the dynamic only intensifies as we approach AGI. After Automation: https://t.co/Lb7SUCduAg
@dillon_mulroy https://t.co/0oRGkRlmOb

DeepSeek's 10 trillion USD grand strategy

18 Claude settings that change everything. 14 are hidden 3 clicks deep. 4 aren't in any docs.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. https://t.co/AFJZ5kH7Ku https://t.co/uxl1InS6Ay