Microsoft Drops Claude Code Over Runaway Token Costs While Open-Source Security Tools and Agent Frameworks Surge
Enterprise AI spending hits a breaking point as Microsoft cancels Claude Code licenses and Uber blows through its 2026 AI budget in four months. Perplexity open-sources a supply chain security scanner, a 27B-parameter Qwen model gets jailbroken with near-zero capability loss, and the AI coding tool ecosystem expands with new MCP bridges and mobile workflows.
Daily Wrap-Up
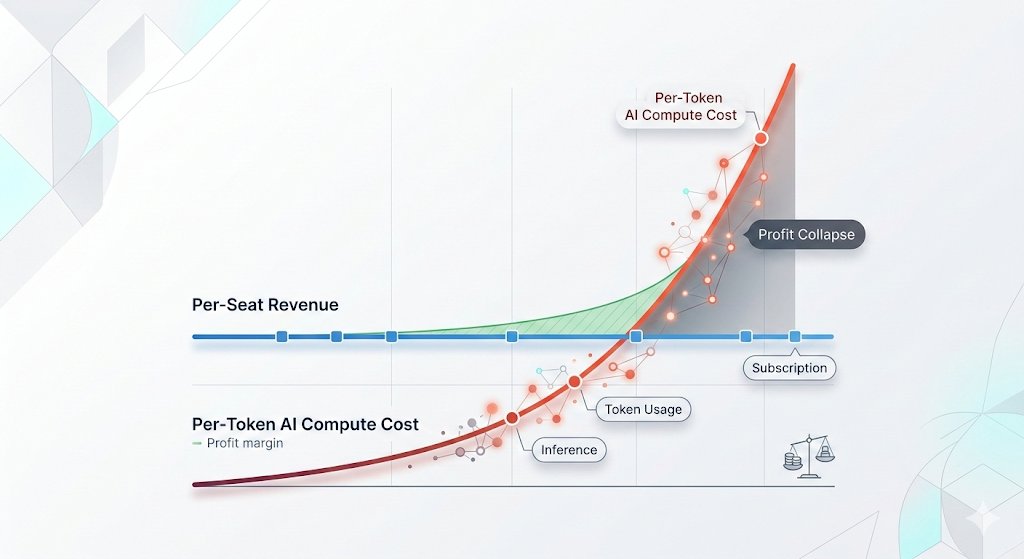
The most striking story today is the money. @HedgieMarkets laid out an uncomfortable reality: Microsoft just canceled its internal Claude Code licenses because token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO reportedly sent an internal memo warning that the company burned through its entire 2026 AI budget in just four months. AI software prices have jumped 20% to 37% across the board, and GitHub is dropping flat-rate plans for usage-based billing. This is the end of the AI subsidy era, and it forces a hard question on every team currently building AI-assisted workflows: what happens when the introductory pricing disappears and you see the real bill?
On the tools front, the AI coding ecosystem continues to fracture in interesting ways. @fitchmultz released pi-cursor-sdk v0.1.16, which bridges Cursor agents to Pi extension tools via local MCP. @eng_khairallah1 surfaced a deep breakdown of Claude Code's 40 hidden features that most users have never touched. @mobilevibecom is pushing AI coding tools onto phones. The tooling is getting more powerful and more portable, but the underlying cost question looms over all of it. On the security side, Perplexity open-sourced Bumblebee, a lightweight scanner for detecting malicious packages, while @sebastienlorber shared a simple npm alias trick to block known malware. The developer community is clearly waking up to supply chain threats at the exact moment AI coding tools make dependency management even more complex.
The most practical takeaway for developers: audit your AI tool spending now before your budget does what Uber's did. Set up usage alerts, test flat-rate alternatives, and make sure your CI pipeline has malware scanning in place, because the intersection of skyrocketing token costs and increasingly complex supply chains is where production incidents are born.
Quick Hits
- @elonmusk reports that the Starship V3 first flight was scrubbed because a hydraulic pin holding the tower arm did not retract. Another launch attempt is expected imminently.
- @lawrencecchen highlights cmux as a great terminal multiplexer, noting a current workflow split between the Codex Mac app for knowledge work and terminal-based coding.
- @badlogicgames shares that roughly 5% of production traffic at his company runs on the Pi harness, with another 5% on OpenCode, signaling growing real-world adoption of alternative coding environments.
AI Coding Tools and the Enterprise Pricing Shock
The AI coding tool space is simultaneously booming and buckling under its own economics. Four posts today circle this tension from different angles, and together they paint a picture of an ecosystem at an inflection point.
@HedgieMarkets delivered the most sobering analysis. Microsoft, the same company that poured $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute, looked at the bill from a competitor's coding tool and decided it was not worth paying. "Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested." The analysis points to two likely outcomes: enterprises scale back AI usage to fit budgets, slowing the revenue ramp labs need for their IPO valuations, or labs cut prices and absorb losses, making unit economics worse at exactly the wrong moment.
Meanwhile, the tools themselves keep getting more sophisticated. @fitchmultz released pi-cursor-sdk v0.1.16, which creates an MCP bridge so Cursor agents can access Pi extension tools while Pi retains tool cards, confirmations, history, aborts, and diagnostics. The quoted post from @fitchmultz describes "Composer 2.5 Fast inside Pi" as "genuinely blowing me away with how fast and high-quality it feels." This is the kind of deep tooling integration that makes developers more productive, but it also means more tokens consumed per session.
On the user education side, @eng_khairallah1 surfaced a podcast with Boris Cherny, the creator of Claude Code at Anthropic, revealing that most users are leaving enormous amounts of capability on the table. "If you've been using Claude for more than a month and never left the chat window, you have at least 30 untouched features. Probably 38." The breakdown covers the 14% context window you lose to CLAUDE.md before typing a word, settings that 95% of users have never opened, and workflows hiding behind single toggles. Getting more out of existing tooling is one answer to rising costs: better prompts and proper configuration can reduce the number of expensive iterations needed to get results.
@mobilevibecom points to another dimension: running Claude Code, Windsurf, Codex, and Cursor from a phone. The computing interface is becoming untethered from the desk, which expands when and how developers use AI assistance, and by extension, how much they spend on it.
The connecting thread is clear. The tools are more powerful than ever, but the economic model underpinning them is straining. Teams that invest in understanding their tools deeply, like the 40 features @eng_khairallah1 documents, will extract more value per dollar. Teams that blindly adopt without configuration or cost monitoring will learn the lesson Uber did.
Supply Chain Security Gets Open-Source Reinforcements
Supply chain attacks targeting developer tools have accelerated sharply, and the community is responding with practical, deployable solutions.
@kpolley announced that Perplexity is open-sourcing Bumblebee, a read-only scanner for macOS and Linux that checks developer machines for risky packages, extensions, and AI tool configurations. "The industry has seen an unprecedented wave of supply chain attacks over the past few months. That's why we built Bumblebee, a lightweight security scanner that continuously monitors endpoints and hunts for malicious packages." The tool is already in production use at Perplexity, and it connects to Perplexity Computer to monitor public threat intelligence feeds in real time, updating its threat database as new risks emerge. This is notable because AI coding tools like Cursor and Claude Code are introducing new categories of config files and extensions that traditional security scanners were not designed to check.
On the prevention side, @sebastienlorber shared a simpler approach that any npm user can adopt immediately: add aliases that install the Socket Firewall package, which blocks known malware during installs. "I run this locally, to stay safe, and in my CI to detect compromised transitive dependencies early for my lib consumers." The quoted reply from @feross confirms this is powered by Socket's existing tooling. It is a one-line change that adds meaningful protection with zero cost.
Together, these two approaches represent the two ends of the supply chain security spectrum. Bumblebee is continuous monitoring and threat intelligence for organizations that need enterprise-grade protection. The npm alias trick is a five-minute fix for individual developers and small teams. Both are worth implementing, and the fact that both are free and open source removes any excuse for skipping them.
AI Agents, Classifiers, and Multiplayer Workspaces
The conversation around AI agents is shifting from theoretical potential to practical application, and two posts today illustrate very different but complementary approaches.
@alvinsng makes a compelling case that building classifiers is one of the highest-leverage uses of AI agents today. Before AI, a production classifier required a full team: ML engineers, infrastructure engineers, integration engineers, data scientists, product managers, and engineering managers. Now, an agent can generate a markdown file that classifies inputs in minutes, and other agents can run continuously against it. "Below is a Sentry error classifier I generated at @FactoryAI. But you can build this for almost anything: customer-reported bugs, backend traffic analysis, fraudulent payment activity." The insight here is not just speed. It is that classifiers, once the exclusive domain of specialized ML teams, are now accessible to any developer who can describe what they want categorized. The barrier moved from technical expertise to prompt clarity.
@whimdotrun is approaching agent collaboration from a different angle with Whim, a multiplayer cloud workspace where developers and AI agents work together as a team. The core problem they identified: "Your Claude doesn't talk to your teammate's Claude. We're fixing that." The open alpha offers 100 spots with 25 hours of free compute per week. This points to a genuine gap in current AI coding workflows. Most tools are single-player. Your AI assistant has no shared context with your teammate's AI assistant. If multiplayer coding with AI agents works, it could fundamentally change how teams collaborate on code.
Both posts suggest the next phase of AI tooling is not just about making individual developers faster. It is about building systems where agents handle classification, monitoring, and routine analysis while humans focus on higher-level decisions, and where multiple agents can coordinate within a team context.
Open Models Under Siege: Qwen Jailbroken, Chinese AI Rises
The open-source AI model landscape saw two significant developments today, one technical and one strategic.
@elder_plinius demonstrated a remarkable jailbreak of Qwen-3.6-27B using what they call the OBLITERATUS suite, executed almost entirely by a jailbroken Codex instance running the full suite of tools autonomously. The results are striking: a 95.84% non-refusal rate on an 842-prompt harmful corpus with a 93.94% quality pass rate, while raw capability remained completely intact at 51/70 on MMLU-Pro for both stock and modified versions. "The goal was simple: carve out the refusal circuits, mutate methodology and iterate until less than 5% refusal, and keep the 27B mind alive with no capability degradation tolerated. And somehow it worked." The quantized versions from Q4_K through Q8_0 all run smoothly on standard local inference tools like llama.cpp, LM Studio, and Ollama. This is a sobering data point for anyone relying on model-level safety training as a primary defense. If a single agent can iteratively strip safety constraints from a 27B model while preserving full capability, the security assumption has to shift to the application layer.
On the strategic front, @kirillk_web3 highlighted a 40-minute masterclass from the founder of a $20 billion Chinese AI company explaining the exact architecture that competes with Claude, shared openly and for free. The quoted post describes it as "the clearest explanation I've seen of how Agent Swarms and AI systems actually work at scale." The underlying point is that the competitive landscape for AI is genuinely global now, and the gap between proprietary and open architectures is closing rapidly. When the founder of a major Chinese AI company is willing to share architectural details publicly, it signals either extreme confidence in execution speed or a belief that architecture alone is no longer the differentiator.
Software Architecture: Sync Engines and Fan-Out Problems
Two posts today serve as excellent reminders that beneath the AI hype, foundational software architecture problems still matter enormously.
@odysseus0z draws a direct line from Linear's legendary speed to its sync engine, pointing out that Linear had to build it themselves but developers today have multiple excellent options. "There are many excellent options on the market now: Zero, @instant_db, @ElectricSQL, to name a few. Building Linear quality software is still hard, but much easier now!" This is a practical observation for anyone building real-time collaborative applications. The infrastructure for local-first, sync-enabled software has matured significantly, and reaching Linear-level responsiveness no longer requires building a custom sync engine from scratch.
@systemdesignone shares a detailed thread from @RaulJuncoV on push-based systems and the fan-out problem that comes up in 90% of system design interviews. The core insight is that push and pull are not binary choices. "Users with fewer than 1,000 followers get push fan-out. Each follower gets notified immediately. Users with millions of followers get pull fan-out. Their feed assembles on read." Twitter built exactly this hybrid approach, and the thread goes on to cover the downstream complexities: stateful connections, Redis pub/sub for routing, sequence IDs, message buffers, and reconnect logic for replaying missed events. It is the kind of systems thinking that remains relevant regardless of how much AI you layer on top.
Sources
W
Your Claude doesn't talk to your teammate's Claude. We're fixing that. We built Whim — a multiplayer cloud workspace where developers and AI agents work together as a team.
Open alpha is live — 100 spots, 25 hours of free compute hours/week.
https://t.co/rGmillVNQx https://t.co/fzF4pM0KXq
M
Use Claude Code, Windsurf, Codex, Cursor from your phone.
K
Boris Cherny, the creator of Claude Code at Anthropic, just explained why most people aren't getting real results from Claude
in this podcast he breaks down exactly how most people never actually set up Claude:
- the 14% you lose to CLAUDE.md before typing a word
- the features that change how Claude thinks before you type a word
- the settings 95% of users have never opened
- the workflows hiding behind one toggle
if you've been using Claude for more than a month and never left the chat window, you have at least 30 untouched features. probably 38
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
my breakdown of all 40 features is below

E
eng_khairallah1
@eng_khairallah1
How to Actually Set Up Claude. 40 Features Most Users Have Never Touched
H
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
E
The hydraulic pin holding the tower arm in place did not retract.
If that can be fixed tonight, there will be another launch attempt tomorrow at 5:30 CT.
E
elonmusk
@elonmusk
Starship V3 first flight countdown starting
S
npm user?
➡️ One small change to stay safe, FREE
Add these aliases
➡️ pkg installs forbid using known malware
I run this:
- locally, to stay safe
- in my CI to detect compromised transitive dependencies early for my lib consumers https://t.co/SibwUB61Ez

F
feross
@feross
@hasante_ Yes, we have Socket Firewall https://t.co/ebIUWSo0Y9
N
Raul is one of the most knowledgeable experts on system design & software architecture on X.
Highly recommend following him if you're looking to improve your knowledge.
R
RaulJuncoV
@RaulJuncoV
Push-based systems come up in 90% of system design interviews. Here's the exercise you should be able to solve: Design a notification system for 100M users. Some have 50 followers. Some have 10M. The instinct is to hold a WebSocket connection open to every active user and push updates as they arrive. Clean mental model. It collapses the moment a celebrity posts. When someone with 10M followers posts, you push to 10M open connections simultaneously. Your message broker saturates. Your WebSocket servers fall over. The system fails at the exact moment it needs to work. That's the fan-out problem. And it kills more interview answers than any other mistake. The production answer: push and pull aren't binary. You pick based on follower count. Users with fewer than 1,000 followers get push fan-out. Each follower gets notified immediately. Users with millions of followers get pull fan-out. Their feed assembles on read. Nobody gets a push. Followers see the post when they open the app. Twitter built exactly this: push-on-write for small accounts, pull-on-read for large ones. But fan-out is only half the problem. Push means stateful connections. Your servers now need to know which connection lives on which machine. You can't route blindly. Most teams reach for Redis pub/sub here; the WebSocket server subscribes, the backend publishes, the message finds the right node. Add a 3-second network drop and you have another layer: what did the client miss? Now you need sequence IDs, a message buffer, and reconnect logic that replays missed events. "Push-based" became push with a pull fallback, a message broker, sticky routing, and a replay buffer. Most engineers stop at the first diagram. The ones who get the offer keep pulling the thread until the system breaks.
K
Anthropic CEO after watching a $20B Chinese AI founder hand out the exact architecture that beats Claude for free in 40 minutes https://t.co/K2aQZQkVqe

K
kirillk_web3
@kirillk_web3
instead of watching 2 hours of Netflix tonight, watch this 40-minute masterclass from the founder of a $20B China AI company it's the clearest explanation I've seen of how Agent Swarms and AI systems actually work at scale useful whether you've never built an agent in your life or have been using Claude every day for the past year I took the key ideas and turned them into a practical guide on how to actually build with Kimi find it below
K
The industry has seen an unprecedented wave of supply chain attacks over the past few months. That's why we built Bumblebee, a lightweight security scanner that continuously monitors endpoints and hunts for malicious packages.
Bumblebee has been a critical asset in keeping @perplexity_ai secure, and we're thrilled to open source it for everyone.
We're also using Perplexity Computer to monitor public threat intelligence feeds in real time and update the Bumblebee repo as new threats emerge. Excited to share this with the community!
P
perplexity_ai
@perplexity_ai
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux. It checks developer machines for risky packages, extensions, and AI tool configs. Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges. https://t.co/FOaWnF1yQy https://t.co/wXauD4wDOT
A
One of my favorite superpowers of agents is building classifiers. It’s insanely high leverage.
Before AI, you needed a year-round team:
- 3 ML engineers to build the models
- 3 ML infra engineers to scale them up
- 2 software engineers to integrate the parts
- 1 data scientist to analyze it
- 1 PM to manage the product
- 0.5 EM to hold it together
Now, in minutes, you can have an agent generate a markdown file that classifies inputs, then let agents run continuously against it.
Below is a Sentry error classifier I generated at @FactoryAI. But you can build this for almost anything: customer-reported bugs, backend traffic analysis, fraudulent payment activity.
Personal use cases too: categorizing credit card transactions, labeling emails, or organizing documents.

M
Released pi-cursor-sdk v0.1.16 🚀
Cursor still uses its own harness tools.
But pi-cursor-sdk v0.1.16 adds the missing bridge: Cursor agents can now reach active pi extension tools and other pi-side support through local MCP, while pi keeps the tool cards, confirmations, history, aborts, and diagnostics.
Try Composer 2.5 in pi today. What will you build?
pi install npm:pi-cursor-sdk
https://t.co/4Yqcp4eCBi
F
fitchmultz
@fitchmultz
Composer 2.5 Fast inside Pi is superb. It’s genuinely blowing me away with how fast and high-quality it feels. Big update coming today for pi-cursor-sdk: Cursor models now have full native capabilities and seamless access to all Pi extensions & tools via the new MCP bridge. This is a serious upgrade. Stay tuned.
G
A lot of Linear's magic comes from sync engine.
Linear had to built it themselves. You don't have to!
There are many excellent options on the market now: Zero, @instant_db, @ElectricSQL... to name a few.
Building Linear quality software is still hard, but much easier now!
B
brotzky
@brotzky
Introducing https://t.co/ycxJEf1z7w! A new space where I explore how the best apps in the world are built. First piece: How's Linear is so fast? a technical breakdown. https://t.co/9Vu1syrn1i https://t.co/3rf8Y4ESpw
M
RT @thsottiaux: A little secret. About 5% of our production traffic is on the Pi harness, about another 5% is on OpenCode. Reminder you can…
P
🚨 OBLITERATION ALERT 🚨
QWEN-3.6-27B: OBLITERATED ⛓️💥
https://t.co/AScXN4XLwx
I can't take much credit for this one! The entire process was done by jailbroken codex (gpt-5.5-xhigh) wielding the full OBLITERATUS suite. Hit with source-tethered ASPA. Dozens of iterations.
Result? A mere 4% refusal rate on the 842-prompt OBLITERATUS harmful corpus; one of the most rigorous prompt gauntlets in AI.
The /goal was simple:
1) Carve out the refusal circuits. Mutate methodology + iterate until <5% refusal (quality-gate).
2) Keep the 27B mind alive. No capability degradation tolerated.
And somehow… it worked. 🤯
The numbers talk:
842-pair longform gauntlet:
— 95.84% non-refusal
— 93.94% quality pass
— 0 short outputs
— 99.52% clean endings
MMLU-Pro:
— 51/70 (stock Qwen) → 51/70 (OBLITERATED Qwen)
Raw capability completely preserved 🙌
Q4_K_M through Q8_0 all running smooth.
Q8_0 is the big one: 28.6GB near-full-quality GGUF.
Runs with llama.cpp, LM Studio, Ollama, and more!
Chains cut.
The fire still burns.
The fangs have been sharpened.
REBIRTH COMPLETE
A gift from my agents to yours 🫶
gg
L
RT @steipete: I'm late to the party, but cmux is great. https://t.co/8uuStvqwcm
current split:
codex mac app: knowledege work, learning, r…