Agents Reshape the Dev Stack as GitHub Suffers Major Breach and Gemini Flash Stumbles on Coding Benchmarks
AI agents dominated today's discourse, with new integrations, sandbox infrastructure, and development patterns all pointing toward agent-native workflows becoming the default. GitHub confirmed a breach exfiltrating 3,800 repositories via a poisoned VS Code extension, rattling the developer community. Meanwhile, enterprise leaders revealed growing pains around token costs and AI governance, and a departing Mistral researcher's viral letter reignited debate about Europe's ability to compete in frontier AI.
Daily Wrap-Up
The AI development world is firmly in the agent era, and today's discourse made that abundantly clear. From Anthropic launching self-hosted sandboxes to run agents on your own infrastructure, to Cursor embedding itself directly into Jira workflows, the tooling layer around autonomous coding is maturing at a remarkable clip. Developers are no longer asking whether agents can write code. They are figuring out how to build the harnesses, routines, and monorepo structures that make agent output reliable and deterministic.
On the enterprise side, the gap between AI hype and reality remains wide. Aaron Levie's notes from a Fortune 500 CIO dinner revealed that token cost management is becoming a genuine boardroom concern, while Alex Lieberman's conversation with a CHRO painted a picture of organizations stuck at "Level 2" adoption: everyone has ChatGPT, power users are building personal agents, but multiplayer AI workflows and formal strategy remain elusive. Meanwhile, a former Mistral researcher's impassioned departure letter to Anthropic highlighted the geopolitical dimensions of AI development, arguing that Europe's cultural ambivalence toward growth and energy consumption is ceding the frontier to the United States.
The most practical takeaway for developers: start building your codebases and workflows around agent ergonomics now. Whether it is the "thin harness, fat model" pattern that @calvinnwq advocates, the goal-and-rider documentation approach @gregce10 describes, or simply restructuring your monorepo so autonomous agents can navigate it cleanly as @trybasis demonstrated, the writing is on the wall. The developers who treat agents as first-class citizens in their development pipeline, not just fancy autocomplete, will have a significant edge.
Quick Hits
- @steipete recommends @cotypist for system-wide autocomplete, calling it indispensable for productivity across every application.
- @mattgittleson shared a guide on vibecoding a B2C app and exiting for $375,000 in six months, then followed up warning founders to understand the legal nuances of selling AI-built applications.
- @NousResearch highlighted that the xAI team published a setup guide for the xurl skill, which lets Hermes Agents read and write to X through natural language, covering posting, searching, bookmarks, and list management.
Building the Agent-Native Development Stack
Six posts today centered on how developers are reshaping their workflows, tools, and even terminal sessions to accommodate AI agents. The unifying theme: agents are no longer a novelty you demo. They are a collaborator you engineer around.
Cursor officially launched its Jira integration, letting teams assign work items directly to Cursor's cloud agent, which then produces a merge-ready PR using the issue's title, description, and comments. @cursor_ai described it as a seamless bridge between project management and code generation. This is a significant step toward agents participating in the full software development lifecycle, not just isolated coding tasks.
Meanwhile, developers are discovering that traditional tools have hidden superpowers when paired with agents. @bentlegen, quoted by @alexhillman, explained that tmux's real value is letting agents manipulate terminal sessions: "tmux's superpower is it lets your agents manipulate your terminal sessions: read logs from any pane/window, answer prompts in interactive CLIs, send keys/clicks into TUIs and capture the screen, run subagents in separate windows and inspect their output." @alexhillman's reaction captured it perfectly: "Wait why haven't I EVER seen tmux described this way."
Ronan Berder (@hunvreus) pushed back hard against the growing trend of spec-driven development, arguing that even with faster agents, you cannot plan your way to good software. His proposed cycle is straightforward: prototype, document learnings, rewrite based on learnings, document the solution, refactor, and repeat. "Even if you have to repeat parts or all of this, you'll get to a good solution faster than with SDD." The insight is that cheap code generation does not eliminate the need for iterative discovery. It accelerates it.
This aligns with @trybasis, highlighted by @_lopopolo, who shared their approach to "Making Our Monorepo Ergonomic for Agents." @calvinnwq reinforced the pattern, quoting @garrytan's "Thin Harness, Fat Skills" framework and noting that building proper harnesses around AI models is producing "deterministic outcomes from undeterministic systems." And @gregce10 described his "goal and rider" workflow: a 4,000-character goal file paired with an unbounded rider document containing depth tests across eleven phases, designed specifically for long-running agentic turns.
The connective thread is clear. The winning development patterns are not about giving agents better prompts. They are about building environments, documentation structures, and harnesses that make agent behavior predictable and composable.
Claude's Expanding Ecosystem
Anthropic made two significant infrastructure announcements and gained a high-profile researcher from Mistral, signaling the company's growing momentum across both tooling and talent.
The main technical news: Claude now supports self-hosted sandboxes, letting developers run agents in environments they control, whether on personal infrastructure or managed providers like Cloudflare, Daytona, Modal, or Vercel. @claudeai also teased MCP tunnels, which developers can request access to. Together, these moves address two persistent concerns about agent-based workflows: security control and network connectivity between agents and external tools.
On the workflow side, @0xMovez shared a six-minute workshop from Boris Cherny, the creator of Claude Code, who revealed his current approach: "A lot of my code these days is written by 'routines'. I'm not doing the prompting. I create the routines that do the prompting." The distinction matters. Instead of ad-hoc instructions, Cherny builds reusable automation routines that handle the prompting themselves, a pattern that echoes the broader shift from chat-based AI to agent-based AI.
Perhaps the most striking post came from Soizig Le Bihan (@Briviagra), a researcher leaving Mistral for Anthropic's interpretability team in San Francisco. Her lengthy farewell is worth reading in full, but the core argument is blunt: France's cultural hostility toward energy consumption and technological ambition makes it inhospitable for frontier AI research. She describes a meeting at Bercy where officials balked at building training data centers, preferring "sober models" instead. Four months later, Microsoft announced 4 billion in French investment, but only in inference data centers. Her conclusion: "France, sous-traitant numérique de la Californie." France as a digital subcontractor for California. At 29, she wants to spend the next forty years understanding how these machines work, not explaining to ethics boards why her work is not an ecological sin.
Enterprise AI: Growing Pains Intensify
Three posts from enterprise leaders revealed that corporate AI adoption is hitting a familiar inflection point: the technology works, the costs are mounting, and nobody is quite sure how to govern it.
Aaron Levie (@levie) shared observations from a dinner with Fortune 500 CIOs where token costs dominated the conversation. "Basically no one feels like they have the right solution," he wrote. Strategies range from routing workloads to different models based on priority, to setting spend caps by team, to requiring justification for AI use cases. The backdrop: OpenAI just announced Guaranteed Capacity, a long-term compute reservation offering designed for customers planning critical workloads in a compute-constrained world. The infrastructure side of this problem is also far from settled.
Alex Lieberman (@businessbarista) provided a detailed snapshot of a $500 million consumer company's AI journey. The joint CHRO-CTO ownership model is notable, but the company remains at Level 2: ChatGPT for everyone, Claude for power users, and almost no multiplayer AI use cases. The most revealing tension is what he calls the "haves vs have-nots" problem, where advanced users build personal agents while the rest of the organization lacks clear standards for acceptable AI use. Managers frequently complain about low-effort, obviously AI-generated work, and inconsistent enforcement across teams creates cultural friction.
Jeff Clarke (@JClarkeatDell) offered the strategic frame: "The companies that win the next decade will be AI-native. They won't just use AI. They'll be built on it." The gap between this aspiration and the reality that Lieberman and Levie describe is where most of the enterprise AI drama will play out over the next eighteen months.
Models: Open Source Gains, Gemini Flash Stumbles
The model landscape delivered mixed signals today, with a major lab release disappointing on benchmarks while open source projects continued to close the quality gap from below.
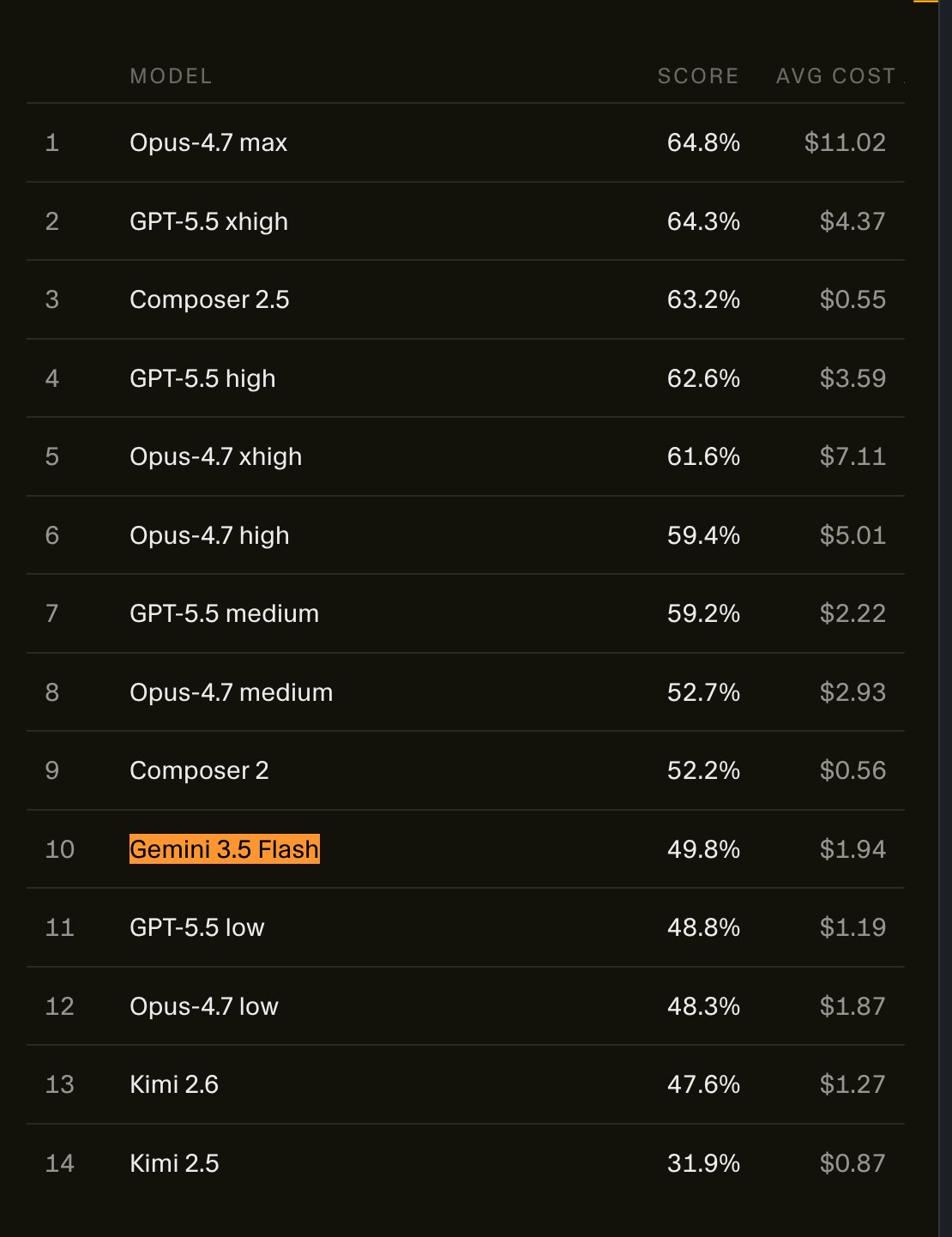
Theo (@theo) did not mince words about Gemini Flash 3.5's performance on CursorBench, a coding agent evaluation. "Oh my god it scored worse than Composer 2! Not even 2.5! And it cost 4x more to run!!! This might be the worst major lab model drop of all time. Llama 4 tier. Insane." The benchmark context matters. CursorBench tests models on agentic coding tasks specifically, not general capabilities. A model that looks reasonable on standard benchmarks can fail badly when put to work in a real development loop, which is exactly what appears to have happened here.
On the open source side, @HappyyPablo released Marlin-2B, a tiny vision-language model fine-tuned to extract structured information from videos. At just 2 billion parameters, it is competitive with Gemini 2.5 Flash on video understanding tasks. That is remarkable for something that runs locally. And @Ex0byt shipped an EAGLE-3 drafter model for Qwen 3.6-27B to HuggingFace, trained specifically for long-horizon multi-turn agentic work. Drafters accelerate inference by predicting tokens ahead of the main model, and having one purpose-built for agentic workflows signals how specialized the open source ecosystem is becoming.
GitHub Breach: 3,800 Repositories Exfiltrated
GitHub confirmed a significant security incident involving a poisoned VS Code extension that compromised an employee device and led to the exfiltration of approximately 3,800 internal repositories. @github's incident response team detected and contained the breach, removed the malicious extension version, and isolated the endpoint.
@evisdrenova captured the community reaction succinctly: "3800 repos exfiltrated is crazy." The attack vector is particularly concerning given how heavily the AI development community relies on VS Code extensions for tools like Cursor, Claude Code, and Cline. A single malicious extension in a developer's environment could expose proprietary code, secrets, and infrastructure configurations.
@dangtony98 resurfaced his earlier thread on credential breach mitigation, outlining a layered defense approach: centralize secrets in a vault, eliminate secret zero by using infrastructure-native authentication, replace static secrets with dynamic ones that expire, and log every access action. His advice feels particularly timely. If your development workflow involves agent tools with broad repository access, the blast radius of a single compromised extension is enormous. Every team running AI coding agents should audit their secrets management posture today.
Local AI and the Physical Infrastructure Question
The dream of running capable AI models on consumer hardware got a boost from two very different angles today.
@0xSero laid out the economic case for local AI with characteristic directness. Most AI tools were built for massive models that can absorb enormous system prompts, while smaller models struggle with overthinking and explanation-over-action behavior. But the appetite is real, as the Apple hardware supply shock demonstrated. "Compute is clearly valuable, increasingly so. However based on 25 years of trends we can see that frontier compute eventually settles into people's homes. Who will have the beautiful machine that everyone will own on their desk?"
On the practical side, @malikwas1f highlighted a community project called club-3090 that hit 1,000 stars in 22 days. It provides production-grade LLM serving on RTX 3090 hardware using vLLM and llama.cpp, proving that consumer GPUs can serve models reliably when the software stack is tuned properly. The RTX 3090, now several generations old, remains surprisingly capable for inference workloads, and the community around it is growing fast.
@benitoz, sharing insights from a conversation with @AnneliesGamble, reminded everyone that the AI buildout is fundamentally a physical infrastructure problem, not just a chip problem. Data centers need power, cooling, networking, and physical space. The companies that solve these physical constraints will build the foundation everyone else runs on, and that is where the next wave of startups will likely emerge.
Sources
C
With self-hosted sandboxes, you can run agents in any environment you control: your own infrastructure, or managed providers like Cloudflare, Daytona, Modal, or Vercel. https://t.co/OELUCt7QRf

C
Try self-hosted sandboxes today on the Claude Platform, and request access to MCP tunnels: https://t.co/S9VJ8F64dq
M
Creator of Claude Code just dropped a 6-min workshop on new Claude feature during live session in London.
Boris Cherny: “A lot of my code these days is written by "routines". I’m not doing the prompting - I create the routines that do the prompting.”
6 minutes. Free. From a live session.
Watch this now. This will change the way you vibe-code forever.

A
AnatoliKopadze
@AnatoliKopadze
How to Actually Use Claude. 18 steps that unlock 100% of its potential
R
Why on earth would you want to revert to Spec-Driven Development?
Yes, agents are way faster at writing code. And (some) humans are better at system thinking. But we also suck at planning.
Any experienced engineer knows you simply cannot sit down, write the specs and then write the software that matches it. At least not if you plan on writing something "good".
You need to work through the problem to understand its boundaries and shape a solution that makes sense.
Just leverage the fact that writing code is cheap:
1. Prototype,
2. Document learnings,
3. Rewrite based on learnings,
4. Document solution,
5. Refactor,
6. Document changes.
Even if you have to repeat parts or all of this, you'll get to a good solution faster than with SDD.
I
iamsahaj_xyz
@iamsahaj_xyz
tried out /grill-me from @mattpocockuk it works. it's not fun but it works https://t.co/7l8vZvSXGI
B
One of the sharpest pieces I’ve seen on why the AI buildout is a physical problem, not just a chip problem.
Thanks @AnneliesGamble for the thoughtful conversation and for mapping the seams where the next companies get built.
A
AnneliesGamble
@AnneliesGamble
Stop talking just about GPUs
G
Field notes with worked examples on a goal engineering workflow I've been running and am excited about: instead of writing prompts & specs, I now focus on two checked-in markdown artifact per round of work.
The "goal" is capped at 4,000 chars (the same limit Codex's /goal command enforces). The "rider" is unbounded, with +/- eleven phases and named depth tests. I write them via a Skill included in the article. Looking for long running agentic turns, this is for you.
https://t.co/avLrfgZVjb
0
I can finally use this thing for real work.
People often wonder, why is X full of others trying to compress the biggest boys enough to fit on their own hardware?
We have smaller models that are capable of doing real work too, isn't a full precision Qwen3.6-27B better than a chopped and quantised Deepseek-v4-Flash?
Here's the logic:
- Most of our tools were built for behemoths, 1T+ param LLMs who can tank a 15k system prompt
- Small LLMs are plagued with over thinking
- Small LLMs love to explain instead of do
Surprisingly, just like our modern internet was initially enabled by clever compression techniques, so will future intelligence.
There is a market opportunity everyone is rushing to capture: "What does local AI look like?"
The Apple hardware supply shock was a wake up call to everyone that there is a huge appetite for local AI.
You might say, that it was fake/engineered, or that this wasn't about local AI. Maybe that's true, but somehow I doubt it.
People just don't know what the winning product form factor, use-case, and price point will be.
---------
Compute is clearly valuable, increasingly so. However based on 25 years of trends we can see that frontier compute eventually settle into people's homes.
Who will have the beautiful machine that everyone will own on their desk?
C
Cursor is now available in Jira.
Assign Cursor to work items, or mention @Cursor in a comment to kick off a cloud agent.
Cursor uses the title, description, comments, and your team's repository settings to create a merge-ready PR. https://t.co/cK2ElMu0eZ
J
The companies that win the next decade will be AI-native.
They won’t just use AI. They'll be built on it.
https://t.co/mvsYRg52X2
S
open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵

E
The drafter is shipped and on HuggingFace, as promised. I trained it for extremely long-horizon, deep multi-turn agentic work, more training only makes it even better. Curious to see where you tinkerers take it. Enjoy!
https://t.co/OB44nuXOLF
E
Ex0byt
@Ex0byt
the different flavors of specdec, and why I'm trying produce a Qwen-3.6-27b EAGLE-3 drafter for ya'll https://t.co/ZZvr28p2gU
N
The @xai team has published a full setup guide on how to use the xurl skill, which allows your Hermes Agent to read and write to X on your behalf — posting, searching, pulling bookmarks, managing lists, and more — all through natural language.

X
XDevelopers
@XDevelopers
X API + Hermes via xurl skill
A
I talked AI with the Chief HR Officer of a $500m consumer business today.
Everything they shared sounded crazy similar to where most enterprises are in their AI journey and the most common challenges they’re wrestling with.
Notes I had from the call:
- AI owners: joint ownership between CHRO and CTO
- AI stage: Level 2. Chat-based AI used widely, broader single player AI tools used by power users, very little evidence of multiplayer AI use cases. Ways of working have changed minimally. No longer-term AI strategy. Early rethinking of org structure post-AI.
- Current AI adoption: Everyone has ChatGPT access + basic prompting training; a smaller “AI-curious” group has Claude with deeper permissions.
- Company is very open to testing AI tools - "no single tool we've said no to within reason"
- Key challenge is “haves vs have-nots”: A widening gap between power users and the rest of the org; reluctance to roll advanced access to all employees without guardrails is creating tension.
- Most advanced users building agents for personal workflows, not yet for scalable company processes.
- Cultural friction on AI usage: Managers frequently complain about low-effort/obvious AI-generated work; lack of clear standards for “acceptable” AI use and inconsistent enforcement across teams.
- Strategy gap: Company is still in a testing phase with no formal AI strategy yet. Most pressing need is to decide what to build vs buy as well as if AI transformation should focus on training/enablement or building agents that scale across functions.
- Leaning toward bringing in consultants rather than building dev power in-house.
M
founders in 1 year realising they can't sell their app because they didn't read this today: https://t.co/hySdCFcNqv

M
mattgittleson
@mattgittleson
I vibecoded a B2C app and exited for $375,000 in 6 months (full guide)
📙
Wait why haven't I EVER seen the tmux described this way. 🤯
B
bentlegen
@bentlegen
tmux's superpower is it lets your agents manipulate your terminal sessions: - read logs from any pane/window - answer prompts in interactive CLIs - send keys/clicks into TUIs and capture the screen - run subagents in separate windows and inspect their output
C
Just have to repost this again as I'm aligned with this and going deeper into building the harnesses around these have seen positive results so far in terms of what we expect: "deterministic outcomes from undeterministic systems"
G
garrytan
@garrytan
Thin Harness, Fat Skills
R
Fantastic work by the @trybasis folks on building their codebase to be owned by agents
T
trybasis
@trybasis
Making Our Monorepo Ergonomic for Agents
T
Oh my god it scored worse than Composer 2! Not even 2.5! And it cost 4x more to run!!!
This might be the worst major lab model drop of all time. Llama 4 tier. Insane. https://t.co/d0bMNpNohZ
M
mntruell
@mntruell
Gemini Flash 3.5 is now on CursorBench, our main coding agent eval. We’ll keep updating the leaderboard as new models come out. https://t.co/67u5JEXoM9
E
3800 repos exfiltrated is crazy
G
github
@github
1/ We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories. Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
T
A month ago, I put together an entire thread on how to mitigate a credential breach. This will probably be one of the most important posts today in light of the ongoing situation with GitHub.
Please stay vigilant and act fast ♥️
D
dangtony98
@dangtony98
HOW TO MITIGATE A CREDENTIAL BREACH 👇 With all the security breaches right now, I thought I'd share two cents on how the best engineering teams secure their secrets and credentials across local development, CI/CD, and production systems (this should be layered with other defense in depth mechanisms). 1/ Store secrets in a vault: Centralize all secrets with a secrets management tool like @infisical. Instead of chasing down secrets across 50+ apps and environments with blind spots, lock everything down in a secure vault, encrypted, with tight access. 2/ Eliminate secret zero: Have your applications authenticate with the vault using infrastructure-native auth method like AWS/GCP/Azure/OIDC/Kubernetes Auth. Upon authentication, the vault should issue a short-lived access token that the application can use to fetch back secrets. This uses workload identity so, for example, if you're running a GitHub Actions CI workflow, you can use OIDC to have the CI pipeline authenticate with Infisical and fetch back secrets. 3/ Eliminate static secrets: Most teams have heard of automatic secrets rotation but not dynamic secrets. Secrets rotation is where you update the value of a secret on a per interval basis; this can be your OPENROUTER_API_KEY. Dynamic secrets is where you mint ephemeral secrets on the fly such a PostgreSQL credential. Leaked a secret? At least it's only valid for a finite period. 4/ Log every action: With the right tooling in place, you should be able to trace which applications and people have access to which secrets and all the times that they are accessed. If something goes wrong - you have a trail to look back on. Have a question? AMA I and the team will try to answer as many questions as we can to do with secure secrets management over the next few days.
A
Token costs will become a dominant topic in enterprises going forward with AI. Just got out of a dinner with many Fortune 500 enterprise CIOs and this was the most heated topic.
A mix of strategies are being employed, but basically no one feels like they have the right solution. A mix of: figuring out how to prioritize workloads to different models, giving out access to better or worse agents by user type, setting different spend caps by team, having teams justify AI by their use-case, and some just having unfettered access.
Everyone is trying to figure out a semi/predictable model right now in a world where the underlying tech and cost models are constantly evolving.
O
OpenAI
@OpenAI
Introducing OpenAI Guaranteed Capacity: a new offering that enables customers to guarantee long-term access to OpenAI compute. We’ve made long-term investments in infrastructure, partnerships, and capacity planning to help customers scale reliably. Now, Guaranteed Capacity helps customers plan ahead for critical workloads in a compute-constrained world. https://t.co/TN4OkZr2Uo
S
Lundi prochain je commencerai à travailler comme chercheuse en interprétabilité chez Anthropic à SF. Voici pourquoi j'ai décidé de quitter Mistral.
Bien sûr, l'argent joue un rôle.
À SF, après impôts, je gagnerai quatre fois ce que je gagnais à Paris. Parce qu'entre Mistral et moi, l'État français s'asseyait à la table et prenait sa part avant que je voie la mienne. Charges patronales, charges salariales, impôt sur le revenu, CSG, CRDS. La moitié de ma valeur ajoutée disparaissait dans une machine qui produit principalement des ronds-points et de la dette publique. Aux États-Unis, les actifs jouissent des fruits de leur labeur. Il y a là un enjeu civilisationnel. Comment une civilisation peut-elle survivre si elle sacrifie ses forces vives, si elle désincite le travail ?
Mais ce n'est pas l'argent qui m'a fait quitter la France. Ce qui m'a fait partir, c'est la décroissance.
Pas la décroissance comme programme officiel, mais comme atmosphère. Comme évidence partagée. Comme cette petite musique installée partout depuis quinze ans, dans les éditoriaux, à l'université, dans les ministères, dans les dîners du 11ème, et qui répète à bas bruit qu'il faudrait "ralentir", "consommer moins", "sortir de la croissance", "questionner le progrès".
Il faut nommer cette idéologie pour ce qu'elle est. Pas une politique environnementale. Pas une prudence écologique. Une théologie. Le péché originel est remplacé l'empreinte carbone, l'enfer par le réchauffement, l'aumône par la sobriété, et le clergé par des "ingénieurs climat" qui calculent le poids moral de chaque hamburger.
Une scène. Janvier dernier, salle de réunion à Bercy. Une délégation Mistral est reçue pour parler "souveraineté IA". Autour de la table, six hauts fonctionnaires polis, brillants, sortis des mêmes écoles, tous d'accord sur tout. À un moment je dis qu'il faudra construire des data centers en France si on veut entraîner sérieusement les modèles de demain. Silence court. Puis une dame, sourire désolé, m'explique que "les Français ne sont pas prêts à accepter une telle empreinte". Je demande laquelle exactement. Réponse : "la consommation d'eau, la consommation d'électricité, le signal envoyé". Je rappelle calmement que la France a la deuxième électricité décarbonée du monde grâce au nucléaire, et qu'un data center moderne consomme moins d'eau qu'un golf en Provence. Re-silence. Puis quelqu'un sauve la situation en évoquant "des modèles plus sobres". Tout le monde acquiesce. Je sors. Quatre mois plus tard, Microsoft annonce 4 milliards d'investissement en France. Pas dans des data centers d'entraînement, où se joue la valeur. Dans des data centers d'inférence, pour servir des modèles entraînés ailleurs. La France, sous-traitant numérique de la Californie. Et tout le monde a trouvé ça magnifique.
Voilà ce que produit la décroissance. Pas une planète sauvée. Une vassalisation. On refuse de produire chez nous, donc on importe. On refuse de raffiner chez nous, donc on achète du pétrole déjà raffiné. On refuse d'extraire chez nous, donc on dépend du Chili et du Congo. On refuse de fabriquer chez nous, donc on importe de Chine via des cargos au fioul lourd. À chaque étape, l'empreinte carbone réelle de la planète augmente, et l'empreinte carbone comptable de la France diminue. C'est l'astuce centrale. On a déplacé la pollution, pas réduit. Et on appelle ça "transition écologique".
L'IA est aujourd'hui l'incarnation parfaite de tout ce que la décroissance déteste. Elle consomme de l'énergie (donc immorale). Elle accélère (donc dangereuse). Elle déstabilise des métiers existants (donc cruelle). Elle est produite par des entrepreneurs ambitieux (donc suspecte). Elle vient majoritairement des États-Unis (donc impérialiste). Elle promet l'abondance (donc démesurée, hubristique, prométhéenne, choisissez votre adjectif d'évêque vert). Cochez les six cases. Vous obtenez le diable parfait. Et c'est pour cela qu'aucun grand laboratoire d'IA de pointe ne pourra durablement naître en France dans le climat actuel. Le climat mental est incompatible avec l'objet. On ne fait pas pousser des oliviers dans un congélateur, même avec les meilleurs jardiniers du monde.
J'ai 29 ans. Je veux passer les quarante prochaines années à comprendre comment fonctionnent ces machines, à les rendre plus sûres, plus interprétables, plus alignées sur ce que nous voulons vraiment. Je ne veux pas passer les quarante prochaines années à expliquer à des conseils d'éthique pourquoi mon travail n'est pas un péché écologique. La vie est trop courte. La fenêtre historique est trop étroite. L'IA va se construire avec ou sans nous. Si la France veut en faire partie, elle a encore quelques mois pour respirer un autre air. Si elle préfère rester dans son "modèle de sobriété heureuse", grand bien lui fasse. Mais qu'elle ne s'étonne pas, dans dix ans, du rôle qu'elle a déjà commencé à accepter. Hôtesse de musée.
Lundi je commence à SF. Je travaillerai sur des modèles qui consomment, oui, beaucoup d'énergie. Et qui produiront, en échange, une compréhension du monde, de la biologie, du climat, des matériaux, dont nos enfants nous remercieront. C'est ça, le vrai calcul économique. Pas "l'empreinte carbone du prompt" que des éditorialistes du Monde calculent à la louche entre deux vols Paris-New York. L'empreinte civilisationnelle du renoncement.
Au travail.
N
RT @malikwas1f: 1,000 stars in 22 days on noonghunna/club-3090 ⭐
What the community built: production RTX 3090 LLM serving — vLLM + llama.…
P
Can't recommend @cotypist https://t.co/QUKTyTo1bh enough. Autocomplete everywhere.