Anthropic Acquires Stainless as Claude Code Gets Sandboxes and AI Coding Agents Move to Production
Anthropic made two major moves today, acquiring SDK platform Stainless and launching self-hosted sandboxes with MCP tunnels for Claude Code. Across 39 posts, the dominant theme is the rapid professionalization of AI coding agents, from persistent skills and cross-session memory to production deployment with tools like Devin Auto-Triage. Meanwhile, ByteDance released a 3B-active-parameter multimodal model, and the tech job market reshuffle continued to dominate conversation.
Daily Wrap-Up
The AI development ecosystem is hitting an inflection point where coding agents are no longer experimental toys but production infrastructure. Today's posts paint a picture of tools rapidly maturing: Anthropic acquired Stainless to own its SDK pipeline, shipped self-hosted sandboxes for Claude Code, and the community shared best practices for running AI assistants across multi-million-line monorepos. Tools like Devin are moving from "write code" into "monitor and fix production," suggesting the agent era is less about replacing developers and more about giving them an always-on operations partner.
On the model front, efficiency is the name of the game. ByteDance dropped Lance, a model with only 3 billion active parameters that can process and generate text, images, and video simultaneously. Qwen pushed both 3.7 Preview to Arena and 2x faster GGUFs for 3.6. And Cursor shipped Composer 2.5 with an endorsement from Elon Musk, partially trained on Colossus 2. The gap between what runs in the cloud and what runs on your laptop is collapsing fast.
The most practical takeaway for developers: start building persistent memory and skill files for your coding agents now. Between Dria's "watchmen" tool that saves agent learnings across sessions, Neo4j's agent-memory knowledge graphs, and the growing library of reusable skills, the developers who invest in agent context today will have a compounding advantage tomorrow. The era of one-shot prompting is ending; the era of trained, memory-equipped coding partners is here.
Quick Hits
- Anthropic acquires @StainlessAPI, the SDK and MCP server platform powering every Anthropic SDK since launch. A strategic move to own the developer experience end-to-end.
- npm suffered a massive supply chain attack with 639 compromised package versions across 323 packages. @theo called on npm to "wake up and do literally anything at all about this."
- Firecrawl is spending $1M hiring "agent orchestrators" through a 60-problem CTF challenge, per @ericciarla.
- @Browserbase introduced mcp.skills, the largest open-source catalog of skills for web-browsing agents, researched across hundreds of sites.
- Cloudflare tested Anthropic's Mythos against 50 repos and published findings on offensive AI and why faster patching is the wrong reaction.
- @ElevenLabsDevs launched a YouTube channel for AI engineers with deep dives on TTS, STT, and ElevenAgents.
- @garrytan pushed back on NYT's framing of Reese Witherspoon encouraging moms to try AI, arguing people should experience it themselves.
- Voice AI is the most overlooked commerce surface, says @vasuman: customers can't tab away, can't comparison shop, and AI removes the headcount bottleneck.
- @TheAhmadOsman reshared a grad student's dream of building the GPU setup from @Tim_Dettmers' legendary blog posts, finally realized.
- @larsencc is considering open-sourcing a general agent sandbox solution for plug-and-play use in agent workflows.
- @DataChaz shared a Hermes meme for anyone who's watched their agent workflow spiral beautifully out of control.
- @AntoineRSX showed Hermes Agent running in under 5 minutes with no API key, bot token, or SSH required.
- @cyber__razz posted Plan A: Cybersecurity. Plan B: [chaos]. Relatable.
AI Coding Agents Grow Up: Skills, Memory, and Production
The single biggest theme today is the rapid professionalization of AI coding agents. What started as "open a terminal, type a prompt, get code" has evolved into a rich ecosystem of persistent skills, cross-session memory, and production deployment patterns. At least a dozen posts touched on this evolution.
Anthropic set the tone by launching self-hosted sandboxes (public beta) and MCP tunnels (research preview) for Claude Code, announced live from Code with Claude London. This follows @ClaudeDevs sharing best practices for running Claude Code at scale across "multi-million-line monorepos, decades-old legacy systems, and distributed microservices." The message is clear: this tool is built for enterprise workloads, not just weekend side projects.
On the skills front, @gdb (Greg Brockman) highlighted Codex's new /goal feature that keeps the agent working on a persistent objective until it's solved. @mattpocockuk proposed an /auto-grill skill that lets agents continue autonomous grilling sessions, accepting their own recommendations until manually interrupted. He also noted that his /prototype skill for UI consistently surprises him despite the token cost: "Should I really be burning tokens on 3 radically different UI designs every time? And then every time, it gives me something that surprises me and the design ends up awesome."
Perhaps the most telling sign of maturity is the shift toward production. @dabit3 (Nader Dabit) observed that "most coding agents still live in the 'write code' part of the SDLC. The next era of AI software development is moving agents directly into prod." He highlighted Cognition's new Devin Auto-Triage, which monitors incoming bugs and alerts with long-term memory, investigates them, and opens PRs. This is the transition from coding assistant to always-on operations engineer.
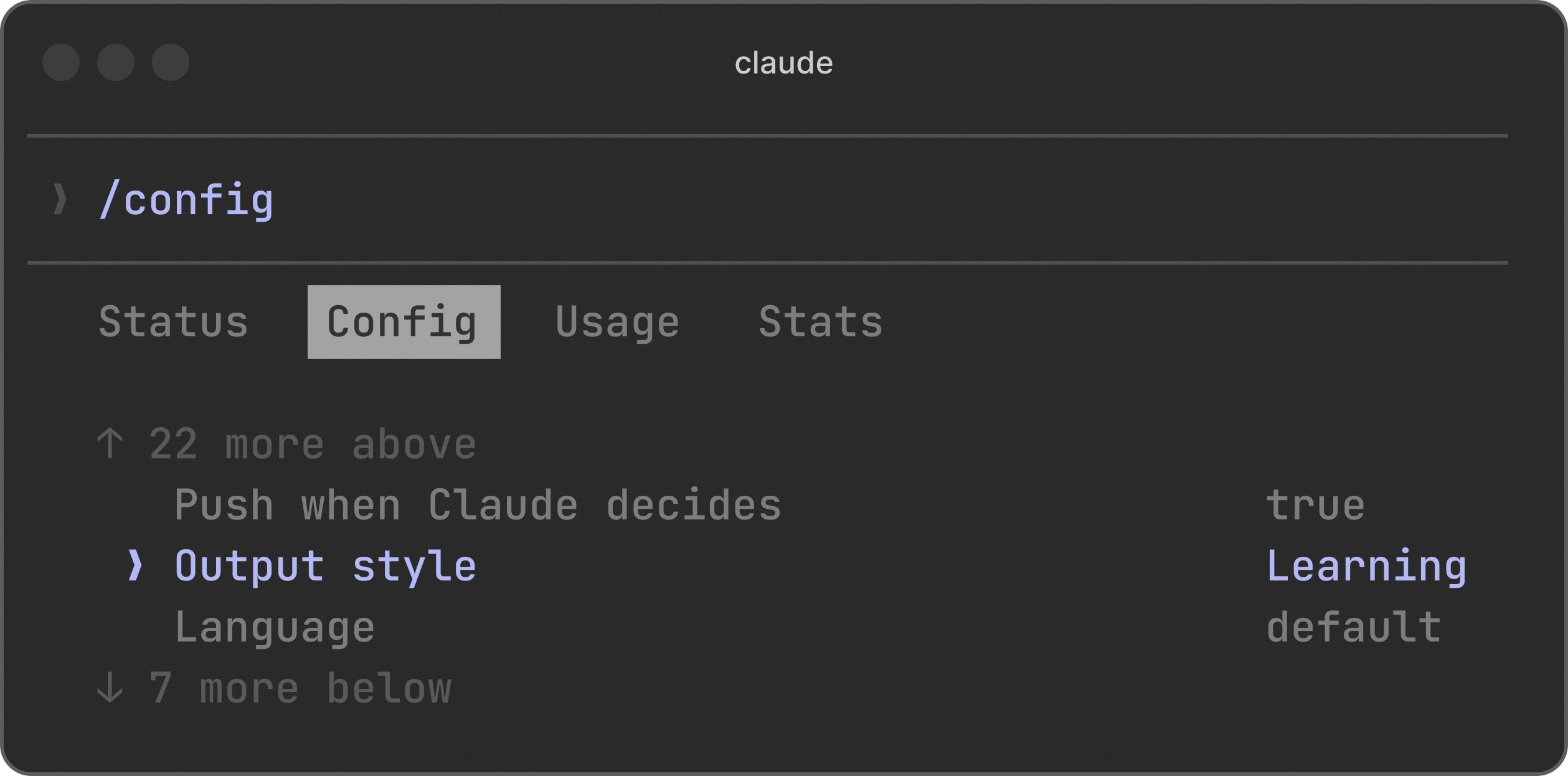
The memory problem is also getting real solutions. @driaforall introduced "watchmen," an open-source tool that writes skill files from your sessions and shares them across Claude Code, Codex, and other agents, "so you stop paying tokens to re-explain what your agent learned last week." @pauliusztin_ praised Neo4j's agent-memory repository for modeling short-term, long-term, and reasoning memory through knowledge graphs, calling it "the best open-source repository for building a unified memory layer for AI agents." And @lydiahallie championed Claude Code's Learning mode for side projects, noting it "keeps me so much sharper" while still staying hands-on.
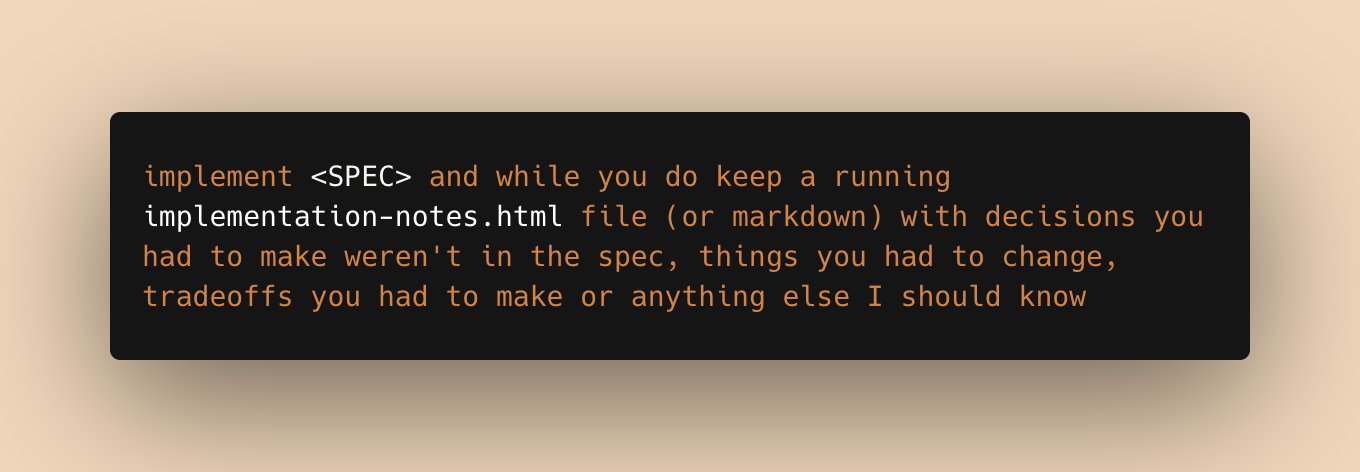
@zodchiii captured the aspirational arc many developers are on: "you open Claude Code, fix a bug, close the terminal... then you copy Shopify's exact config, you set up your first agent team, you go to sleep, 3 PRs are ready by morning." Meanwhile @trq212 shared a simple but effective prompt: ask the agent to maintain a running implementation-notes file with decisions, tradeoffs, and changes not in the spec. Small habits, compounding returns.
New Models Push Efficiency Boundaries
The model releases this week share a common thread: doing dramatically more with dramatically less.
ByteDance released Lance, an open-source model running on just 3 billion active parameters that can simultaneously process and generate text, images, and video. @support_huihui called it "absolutely mind-blowing" for the sparse activation efficiency on display.
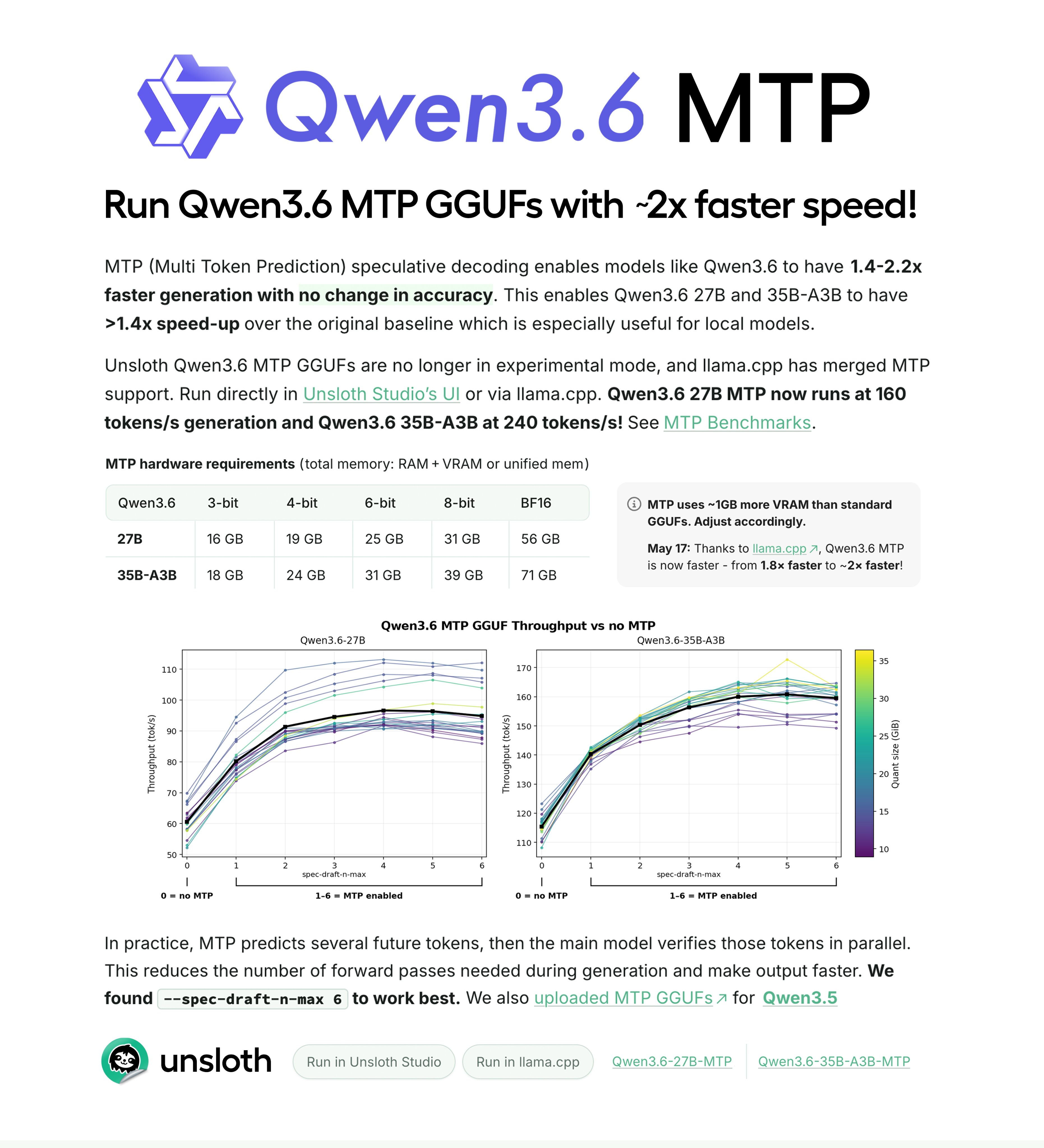
Speaking of MoE efficiency, @0xSero sparked a deep discussion about expert offloading after quoting @witcheer's benchmarks showing MoE offload running 10.8x faster than dense offload on 8GB VRAM. The key insight: MoE keeps the hot path (3B active params) entirely in VRAM while only inactive experts move to CPU. Dense models bounce every token through PCIe for all layers. "The bandwidth bottleneck is fatal," witcheer concluded, with the gap widening to 16.7x at 24K context length.
Alibaba's Qwen family had a big day. Qwen3.7 Preview landed on Arena (making Alibaba the #6 lab in text,
Sources

https://t.co/Exoyd8tB0d


🇺🇸 Tucker lays out the deepest critique of AI yet, and it's not about jobs... His argument: writing produces thinking. You can't formulate a thought without first articulating it. If kids never write because AI writes for them, the quality of human thinking collapses. That's the surface problem. The deeper one is purpose: "The point of living is to create. That's the point of being a human being. It's necessary for joy. There is no joy without creation." If the machine creates everything and humans just consume, you don't get utopia. You get despair, mass unemployment, and eventually political revolution.
If AI now accounts for 25% of corporate layoffs, but 275,000 'AI jobs' are open, what's the real problem? It's not that AI is killing jobs. It's that we're training people for careers that expired five years ago. The education system is the bottleneck—not the technology. Fix that, and abundance follows.
I’ve left Google DeepMind after an amazing chapter. I’m incredibly grateful for the people I worked with, the things we built, and the lessons I learned from taking frontier AI research into production. DeepMind shaped how I think about research, product, evaluation, and what it takes to build AI systems at real scale. As I wrap up this chapter, I wrote down something I’ve been thinking about a lot: evals. We’re good at evaluating the models we have. We’re much worse at evaluating the models we’re about to build — especially if they cross into a new capability regime. We will have self-evolving models, but before that, we need self-evolving evaluations. https://t.co/F1lUWxDG2D



The Claude Code Setup Behind Shopify's 23,000 Engineers (Exact Config You Can Copy)
Rent the Intelligence. Own the Context.
How to land a job at a frontier lab https://t.co/oHIqLgBMbC
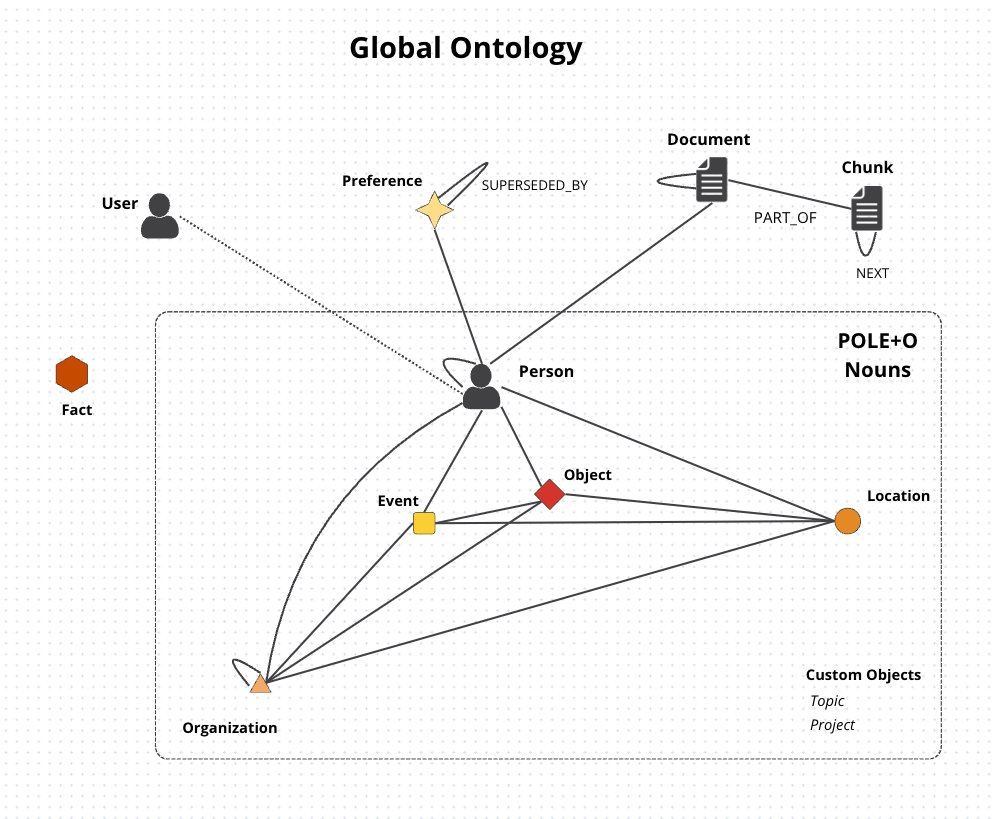
MoE vs dense offload on 8GB VRAM MoE offload is 10.8x faster than dense offload on 8GB VRAM. here's the proof. I tested Qwen3.6 35B A3B (MoE, 3B active) vs Qwen3.6 27B (dense, 27B active) on my RTX 4060 Ti 8GB. the numbers: >MoE (-ncmoe 30): 35.4 tok/s >dense (-ngl 20): 3.28 tok/s ratio: 10.8x it gets worse at longer context. at 24K tokens, the gap is 16.7x. MoE has zero context degradation (SSM layers), dense loses -35.4%. why: MoE expert offload keeps the hot path (3B active params) entirely in VRAM. only inactive experts move to CPU when selected. dense layer offload splits every layer across GPU and CPU. every token bounces through PCIe for all 64 layers. the bandwidth bottleneck is fatal. quality is slightly better on dense (5/6 vs 4/6). the 27B model has the best hallucination resistance of all 9 models I tested. if you have 8GB VRAM and a model that doesn't fit: MoE with expert offload, not dense with layer offload.
Introducing Devin Auto-Triage: Your AI first-responder with long-term memory. Devin can monitor incoming bugs, alerts, and incidents, investigate them, and come back with context, next steps, or a PR.
https://t.co/jKCIAEzai7
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model. https://t.co/N87ojcXlOC
Starting today, we're opening our Agentic Dialog Platform to every enterprise builder. Our dialog agents have resolved 1 billion+ customer conversations for clients like FedEx, Unicredit, PG&E, Marriott, Foot Locker, and many more. These aren't easy conversations. They solve problems like: > A patient booking medical transport who needs insurance verified on the spot. > A homeowner calling their utility company about a gas leak. > A cardholder figuring out why their must-have purchase was declined. Standard conversational AI was never built for this. It was designed for chat, adapted for voice later. It generates responses, but can't do what dialog requires: hold context under pressure, navigate ambiguity in real time, and actually resolve problems. So we built a better model. Our proprietary model Raven was built from the ground up specifically for dialog. Agent harness in the weights, not bolted on through prompts that drift under pressure. And in our platform, you can deploy Raven as your default or bring in GPT-5, Claude, Gemini, whatever model fits your use case or regulatory requirement. Now that the Agentic Dialog Platform is open, any team can create, test, and deploy dialog agents on the same model and infrastructure the world’s top brands trust on their hardest days. This opens up the pool of builders across your entire enterprise. The person who knows customers best, who runs operations, who owns the customer journey: they're all builders now. Two ways to build: > Poly Agent Builder: Describe your use case in natural language, and it configures your agent, knowledge base, and conversation flows automatically. Production-ready in ten minutes. > Agent Development Kit (ADK): Developers use this to build dialog agents the same way they build everything else. Use your own IDE, a coding assistant like Claude, version with Git, deploy from your terminal. Get started now: https://t.co/ifZOy1uEBz
We're spending $1,000,000 hiring agent orchestrators at @firecrawl. Just solve all 60 problems in the our CTF challenge, and we’ll make it very worth your while. https://t.co/kL9ou1CMln https://t.co/hNoeYt5spK
My colleagues wrote up a great post on using Goals in Codex. They go through when to use them, what changes when a Goal is active, and how to write Goals that give Codex a clear outcome, constraints and verification criteria. Also how we designed Goals at the architecture level if you’re curious. https://t.co/QQfjW2EbPO
How We Built Secure, Scalable Agent Sandbox Infrastructure
Your Company Doesn't Need a Forward-Deployed Engineer. It Needs a Bloodhound.
Your company does not need forward-deployed engineers. It needs forward-deployed bloodhounds. I know that sounds ridiculous. I also think it's closer ...
UPDATE: So far we've identified 639 compromised npm package versions across 323 unique packages in tonight’s Mini Shai-Hulud wave. That includes 558 versions across 279 unique @antv packages. Most were detected within ~6 minutes of publication. https://t.co/JXJK1NT4dp
Introducing Open Collider: an open-source engine that mechanically improves LLM creativity. It generates non-trivial, high-quality ideas at scale, for any ideation problem. LLMs collapse on the same ideas. Sample the same brief 100 times → most outputs land in the same place. Researchers call it the Artificial Hivemind (Jiang et al., 2025). "Be more creative" moves the LLM's output by ~0.04 in embedding space. Forcing structurally distant domain collisions moves it by ~0.28. 7× more. Same model, same brief. So I built Open Collider: a pipeline based on the theory of bisociations (Koestler 1964), the same model that drives human creativity. 📊 Across 12 real-world ideation problems: • 12/12 sign-test wins on embedding distance (p = .0002) • 60%+ originality wins on 4,320 blind LLM-judge verdicts • 4–13× further from the default cloud than "be original" prompts or longer context • Idea relevance holds (win rate >50% on overall quality) 💻 Engine: first reply 👇 📝 Launch study: pinned tweet Try it, Break it, Tell me what you find!