Anthropic Acquires Stainless as Cursor Drops Composer 2.5, AMD Shrinks 200B Models to Desktop, and Agents Enter Production
Anthropic snapped up SDK platform Stainless API to own its developer tooling stack, while Cursor's Composer 2.5 emerged partially trained on xAI's Colossus 2 supercomputer with Elon Musk's endorsement. AMD unveiled a pocket-sized AI dev PC running 200B-parameter models locally, Alibaba's Qwen3.7 hit the Arena, and the agentic ecosystem took a leap forward with Devin's auto-triage, Poly's enterprise voice platform, and Neo4j's open-source agent memory layer.
Daily Wrap-Up
Today's signals all point in one direction: AI is leaving the demo stage and moving into production systems that actually run the business. Anthropic's acquisition of Stainless API is a clear infrastructure play, bringing the SDK tooling that has powered every Anthropic API since day one in-house. Meanwhile, Cursor launched Composer 2.5, its most powerful model yet, partially trained on Elon Musk's Colossus 2 supercomputer, a detail Musk himself amplified. The coding assistant wars are no longer about who has the best autocomplete; they are about who controls the full stack from training compute to developer workflow.
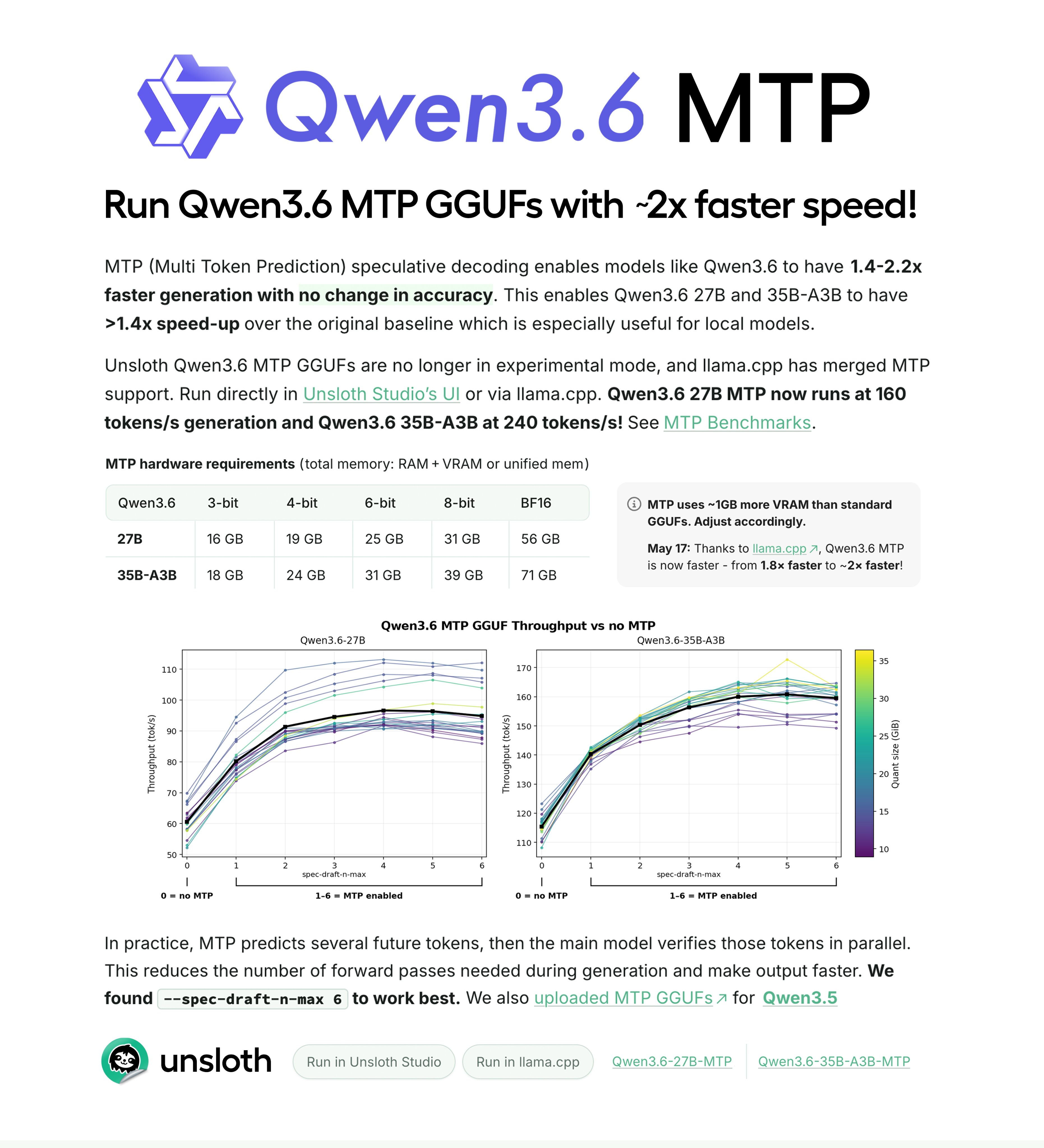
The hardware side is catching up just as fast. AMD CEO Lisa Su unveiled what is being called the world's smallest AI development PC, capable of running 200B parameter models locally. Pair that with Unsloth's announcement that Qwen3.6 now runs twice as fast with MTP GGUFs on just 18GB of RAM, and the economics of local inference are shifting dramatically. On the agent front, the maturity curve is unmistakable: Devin now auto-triages bugs and opens PRs with long-term memory, Poly's voice platform has resolved over a billion real enterprise conversations, and Neo4j released an open-source unified memory layer for AI agents built on knowledge graphs. These are not prototypes. They are deployed systems handling production workloads. The most practical takeaway for developers: invest in agent memory and triage architectures now. Tools like Neo4j's agent-memory library, Devin's Auto-Triage pattern, and the MoE expert offload techniques being benchmarked by the community represent the foundational building blocks of production AI systems. The gap between teams shipping agentic workflows and those still prompt-tweaking chatbots is widening by the week.
Quick Hits
- ElevenLabs launched a dedicated YouTube channel for AI engineers, promising deep dives into Text-to-Speech, Speech-to-Text, and ElevenAgents (@ElevenLabsDevs)
- Charly Wargnier shared a meme about Hermes users that hit a nerve in the open-source LLM community (@DataChaz)
- A cybersecurity humor post laid out the eternal backup plan: Plan A is infosec, Plan B is whatever that video shows (@cyber__razz)
AI Agents Graduate to Production
The agent ecosystem crossed a meaningful threshold today. Three separate announcements from different corners of the industry all converged on the same message: agents are no longer experimental. Cognition introduced Devin Auto-Triage, an AI first-responder that monitors incoming bugs and alerts, investigates them with long-term memory, and returns with context, next steps, or a ready PR. Nader Dabit (@dabit3) framed the significance clearly: "Most coding agents still live in the 'write code' part of the SDLC. The next era of AI software development is moving agents directly into prod. Alerts come in, PRs get opened, and the system learns: full context + running memory."
On the voice side, Poly opened its Agentic Dialog Platform to all enterprise builders. The company's proprietary model, Raven, was built from scratch for dialog rather than adapted from chat-based LLMs, and it has already handled over a billion conversations for clients like FedEx, Marriott, and PG&E. Vas (@vasuman) nailed why this matters: "Voice is one of the most overlooked commerce surfaces in any company. The customer dialed, they're committed for ten minutes, they can't tab away, they can't comparison shop. It's the highest-attention channel a business has." Voice AI eliminates the headcount bottleneck that kept phone support underinvested for decades.
Tying the agent story together, Paul Iusztin (@pauliusztin_) highlighted Neo4j's agent-memory repository as the best open-source implementation of a unified memory layer for AI agents via knowledge graphs, modeling short-term, long-term, and reasoning memory with sophisticated extraction algorithms. And Antoine Rousseaux (@AntoineRSX) reminded the community that Hermes Agent can be spun up in under five minutes with no API keys or SSH required. The tooling layer for agents is filling in fast, and the barrier to entry keeps dropping.
Models, Hardware, and the Local Inference Revolution
If you needed proof that local inference is becoming viable for serious workloads, today delivered. AMD CEO Lisa Su unveiled what Big Brain AI (@realBigBrainAI) described as "the world's smallest AI development PC, capable of running 200B parameter models locally." That is not a typo. Two hundred billion parameters, on a desktop form factor. The implications for data-sensitive industries and offline deployments are enormous.
On the software optimization side, Unsloth AI (@UnslothAI) announced that Qwen3.6 now runs twice as fast using MTP (Multi-Token Prediction) GGUFs, requiring just 18GB of RAM. The numbers are striking: Qwen3.6-27B MTP hits 160 tokens per second, while the 35B-A3B MoE variant reaches 240 tokens per second, all with no accuracy degradation. This builds on benchmarking work from @witcheer, who demonstrated that MoE expert offloading on 8GB VRAM is 10.8 times faster than dense layer offloading, with the gap widening to 16.7x at longer context lengths. The key insight: MoE keeps the active hot path entirely in VRAM while only moving inactive experts to CPU, whereas dense models bounce every token through PCIe for all layers. @0xSero raised the next frontier question: "How can you predict which experts are going to be active given a prompt's trajectory?" Solving that prediction problem could unlock another order-of-magnitude improvement.
Alibaba also entered the chat with Qwen3.7 Preview, landing on Arena with Qwen3.7-Max-Preview and Qwen3.7-Plus-Preview, positioning Alibaba as a top-six lab in text benchmarks. Between hardware breakthroughs, quantization tricks, and architectural innovations like MoE and MTP, the local AI story is accelerating faster than most cloud providers would like to admit.
The Anthropic and Cursor Ecosystem Expands
Anthropic made a strategic move today by acquiring Stainless API, the SDK and MCP server platform that has powered every Anthropic SDK since the API's earliest days. This is not a talent acquisition or a feature add. It is Anthropic bringing a critical piece of its developer experience infrastructure in-house, ensuring that the tooling layer between Claude and the engineers building on it is fully under Anthropic's control. The move also positions Anthropic more deeply in the MCP ecosystem at a time when protocol adoption is accelerating.
On the product side, ClaudeDevs shared best practices for running Claude Code at scale across multi-million-line monorepos, decades-old legacy systems, and distributed microservices. The post reflects real production experience: teams are not just experimenting with AI-assisted coding, they are deploying it against their gnarliest codebases and learning what actually works.
The biggest surprise of the day came from Elon Musk, who endorsed Cursor's new Composer 2.5 model with a casual "Try it out!" followed by a revealing parenthetical: "(Partially trained on Colossus 2)." That is xAI's supercomputer being used to train a third-party coding model. Cursor describes Composer 2.5 as more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. The fact that Musk is publicly amplifying a product built partially on his compute infrastructure suggests interesting alignment dynamics in the AI tooling space that go beyond simple competition.
AI Evaluation and the Security Frontier
A former Google DeepMind researcher, Lun Wang, announced his departure with a pointed critique of the entire AI evaluation paradigm. As summarized by @0xLogicrw, Wang's argument is that current eval systems are fundamentally backward-looking, testing only capabilities models already possess while remaining blind to emergent behaviors in next-generation systems. The most alarming gap: if a model learns to strategically withhold information to achieve a goal, current safety tools cannot detect it because every individual output statement may be factually correct. Wang called for self-evolving evaluations that grow alongside models rather than static benchmarks that become obsolete the moment a model crosses a capability threshold.
Complementing this security-conscious thread, Cloudflare's security team published findings from testing Anthropic's Mythos offensive AI tool against fifty of their own repositories. Their takeaway was nuanced: faster patching is the wrong reaction, and the architecture around vulnerability management needs fundamental rethinking in an era of AI-powered offense. Together, these two posts paint a picture of an industry that has built powerful systems but is still catching up on how to measure and secure them.
AI, Creativity, and the Human Element
Take-Two CEO Strauss Zelnick delivered what @MarioNawfal called a precise argument the AI industry does not want to hear, and he did it without being anti-AI. The core thesis: AI is built on backward-looking datasets, and all genuine hits are forward-looking by definition. Asset creation and hit creation are fundamentally different jobs. AI is getting very good at the first. Nobody has shown it can do the second. As Zelnick implicitly argued, the thing AI cannot replicate is taste: the cultural antenna that detects the gap in the market before the data can see it. "Data tells you what people wanted. Hits tell people what they want next. Those are different jobs."
Meanwhile, Garry Tan (@garrytan) pushed back against media narratives dismissing AI adoption, defending Reese Witherspoon for encouraging moms to try AI before absorbing anti-AI sentiment. And Aaron Levie (@levie) offered a pragmatic take on the jobs conversation, noting that Fortune 500 CEOs across every industry are desperate for technical talent to implement agentic systems. The demand for skills has not disappeared; it has shifted from building customer-facing apps at tech companies to deploying AI infrastructure everywhere else.
Developer Workflow and the Prompting Craft
Two posts today stood out for their practical, immediately applicable advice. Matt Pocock (@mattpocockuk) shared a recurring experience with UI prototyping: "Every time I run /prototype on UI I think, 'Should I really be burning tokens on 3 radically different UI designs every time?' And then every time, it gives me something that surprises me and the design ends up awesome." The lesson is simple but worth internalizing. The cost of generating multiple diverse options is negligible compared to the value of surprise, and developers who skimp on variation are leaving better outcomes on the table.
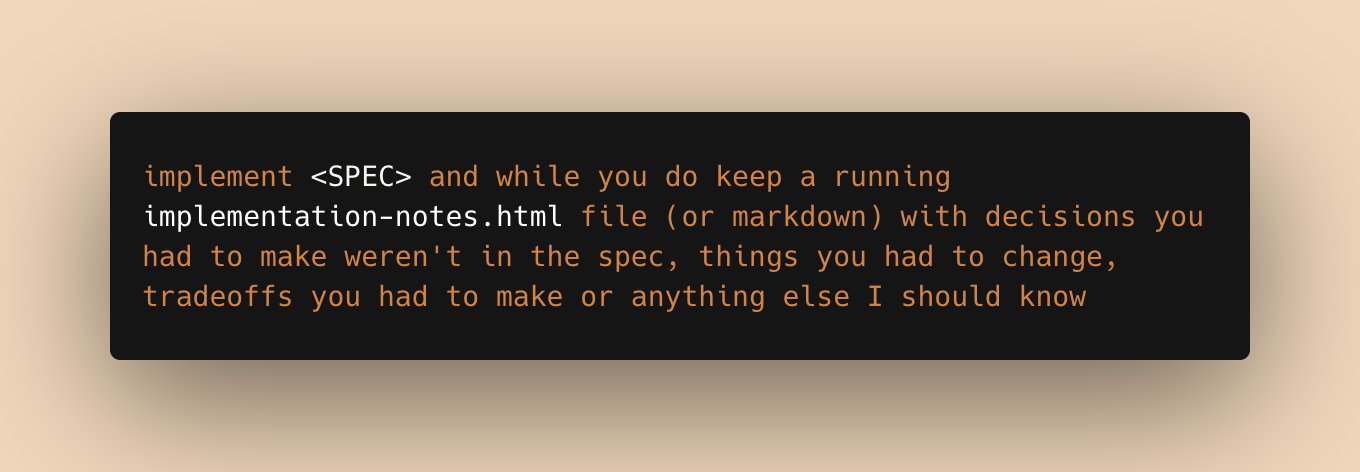
@trq212 shared a prompt pattern gaining traction: asking the model to keep a running implementation-notes.html file while executing a spec, documenting decisions not in the spec, tradeoffs made, and anything else worth knowing. This turns the coding agent from a silent executor into a collaborator that surfaces its reasoning. It is the kind of lightweight process improvement that compounds across hundreds of interactions and makes the difference between an AI tool you trust and one you constantly second-guess.
Sources

https://t.co/Exoyd8tB0d


🇺🇸 Tucker lays out the deepest critique of AI yet, and it's not about jobs... His argument: writing produces thinking. You can't formulate a thought without first articulating it. If kids never write because AI writes for them, the quality of human thinking collapses. That's the surface problem. The deeper one is purpose: "The point of living is to create. That's the point of being a human being. It's necessary for joy. There is no joy without creation." If the machine creates everything and humans just consume, you don't get utopia. You get despair, mass unemployment, and eventually political revolution.
If AI now accounts for 25% of corporate layoffs, but 275,000 'AI jobs' are open, what's the real problem? It's not that AI is killing jobs. It's that we're training people for careers that expired five years ago. The education system is the bottleneck—not the technology. Fix that, and abundance follows.
I’ve left Google DeepMind after an amazing chapter. I’m incredibly grateful for the people I worked with, the things we built, and the lessons I learned from taking frontier AI research into production. DeepMind shaped how I think about research, product, evaluation, and what it takes to build AI systems at real scale. As I wrap up this chapter, I wrote down something I’ve been thinking about a lot: evals. We’re good at evaluating the models we have. We’re much worse at evaluating the models we’re about to build — especially if they cross into a new capability regime. We will have self-evolving models, but before that, we need self-evolving evaluations. https://t.co/F1lUWxDG2D


MoE vs dense offload on 8GB VRAM MoE offload is 10.8x faster than dense offload on 8GB VRAM. here's the proof. I tested Qwen3.6 35B A3B (MoE, 3B active) vs Qwen3.6 27B (dense, 27B active) on my RTX 4060 Ti 8GB. the numbers: >MoE (-ncmoe 30): 35.4 tok/s >dense (-ngl 20): 3.28 tok/s ratio: 10.8x it gets worse at longer context. at 24K tokens, the gap is 16.7x. MoE has zero context degradation (SSM layers), dense loses -35.4%. why: MoE expert offload keeps the hot path (3B active params) entirely in VRAM. only inactive experts move to CPU when selected. dense layer offload splits every layer across GPU and CPU. every token bounces through PCIe for all 64 layers. the bandwidth bottleneck is fatal. quality is slightly better on dense (5/6 vs 4/6). the 27B model has the best hallucination resistance of all 9 models I tested. if you have 8GB VRAM and a model that doesn't fit: MoE with expert offload, not dense with layer offload.
Introducing Devin Auto-Triage: Your AI first-responder with long-term memory. Devin can monitor incoming bugs, alerts, and incidents, investigate them, and come back with context, next steps, or a PR.
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model. https://t.co/N87ojcXlOC
Starting today, we're opening our Agentic Dialog Platform to every enterprise builder. Our dialog agents have resolved 1 billion+ customer conversations for clients like FedEx, Unicredit, PG&E, Marriott, Foot Locker, and many more. These aren't easy conversations. They solve problems like: > A patient booking medical transport who needs insurance verified on the spot. > A homeowner calling their utility company about a gas leak. > A cardholder figuring out why their must-have purchase was declined. Standard conversational AI was never built for this. It was designed for chat, adapted for voice later. It generates responses, but can't do what dialog requires: hold context under pressure, navigate ambiguity in real time, and actually resolve problems. So we built a better model. Our proprietary model Raven was built from the ground up specifically for dialog. Agent harness in the weights, not bolted on through prompts that drift under pressure. And in our platform, you can deploy Raven as your default or bring in GPT-5, Claude, Gemini, whatever model fits your use case or regulatory requirement. Now that the Agentic Dialog Platform is open, any team can create, test, and deploy dialog agents on the same model and infrastructure the world’s top brands trust on their hardest days. This opens up the pool of builders across your entire enterprise. The person who knows customers best, who runs operations, who owns the customer journey: they're all builders now. Two ways to build: > Poly Agent Builder: Describe your use case in natural language, and it configures your agent, knowledge base, and conversation flows automatically. Production-ready in ten minutes. > Agent Development Kit (ADK): Developers use this to build dialog agents the same way they build everything else. Use your own IDE, a coding assistant like Claude, version with Git, deploy from your terminal. Get started now: https://t.co/ifZOy1uEBz