Consumer Hardware Runs DeepSeek V4 PRO Locally as Citadel's Griffin Warns AI Agents Are Replacing PhD-Level Finance Work
Local inference had a breakthrough day, with DeepSeek V4 PRO running on a Mac Studio at 13 t/s and Qwen 3.6 hitting 61 t/s on used RTX 3080 Tis. Ken Griffin admitted that AI agents at Citadel are now completing in days what previously took Masters and PhD holders weeks or months. A new 9B model scored 53% on SWE-bench, credential brokering emerged as the answer to agent security, and Claude Code's filesystem-based Skills system sparked revelations about how much users have been leaving on the table.
Daily Wrap-Up
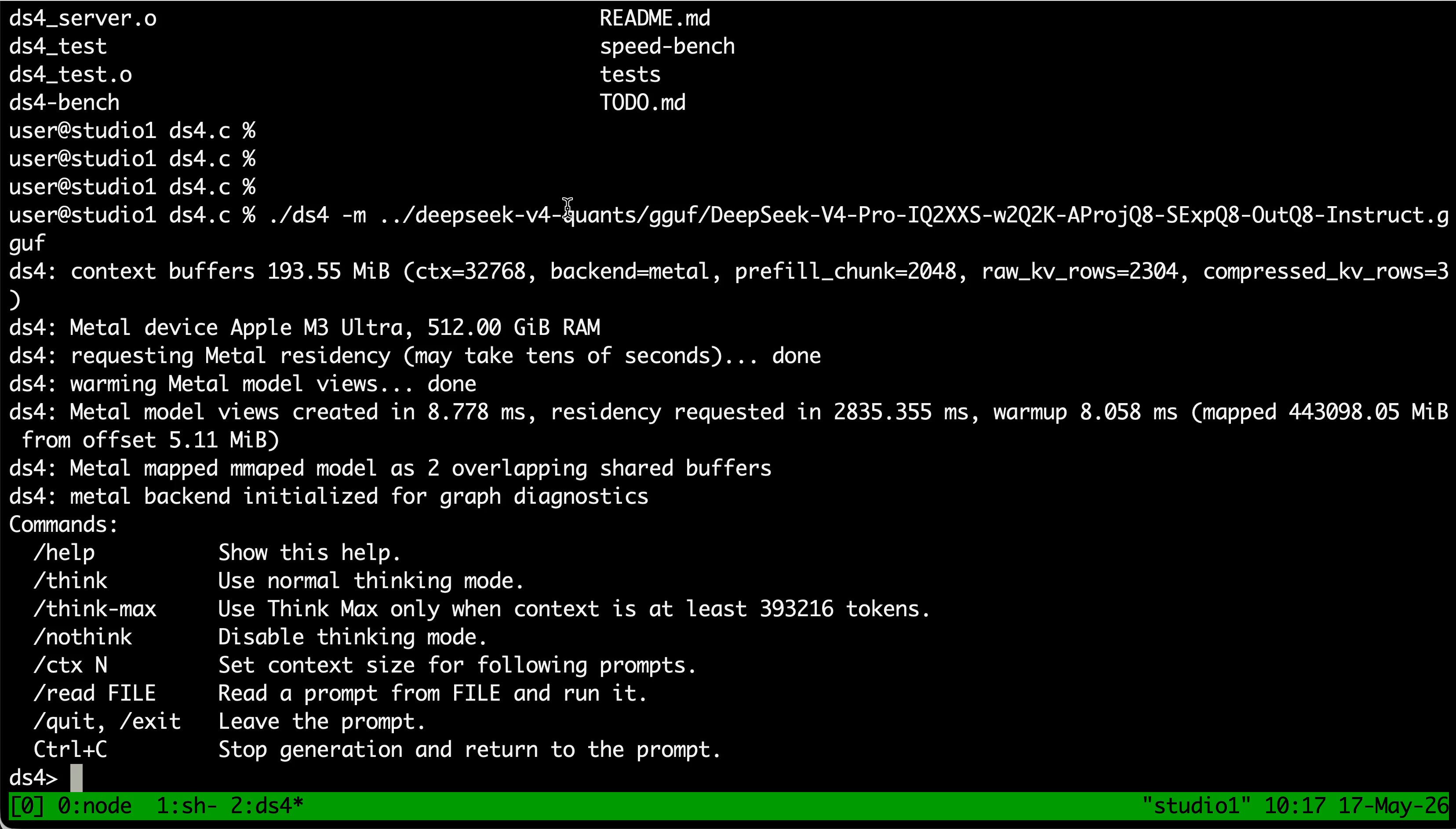
The local AI crowd delivered some of the most tangible progress we have seen in a while. antirez got DeepSeek V4 PRO, the full model not the slimmed-down Flash variant, running on a Mac Studio M3 Ultra with 512GB of RAM using a 2-bit DwarfStar quantization. The 433GB GGUF file generates at 13 tokens per second, which is usable for real work. Across the aisle, @above_spec pushed Qwen 3.6-27B through llama.cpp's new MTP speculative decoding on a pair of used RTX 3080 Tis and hit 61 tokens per second with a 100k context window. These are not theoretical benchmarks. They are replicable configurations built on hardware that costs a fraction of a month of heavy cloud inference usage. Add in the finding that the MTP update in llama.cpp nearly doubles speed for just 1GB of extra VRAM, and the economics of local AI are shifting fast.
The enterprise signal of the day came from Ken Griffin at Citadel, who openly described watching AI agents complete work that would normally require "people with masters and PhDs in finance over the course of weeks or months" in just hours or days. He said he went home one Friday "fairly depressed" after seeing it firsthand inside his own walls. That a hedge fund billionaire is publicly wrestling with the societal implications of what he is deploying is not a throwaway quote. It reflects a real acceleration. Combined with the agent workflow blueprints from @itsolelehmann, a new 9B coding model from @KyleHessling1 scoring 53% on SWE-bench, and credential brokering emerging as a clean solution for agent API security, the picture that forms is one of agents moving from novelty to infrastructure.
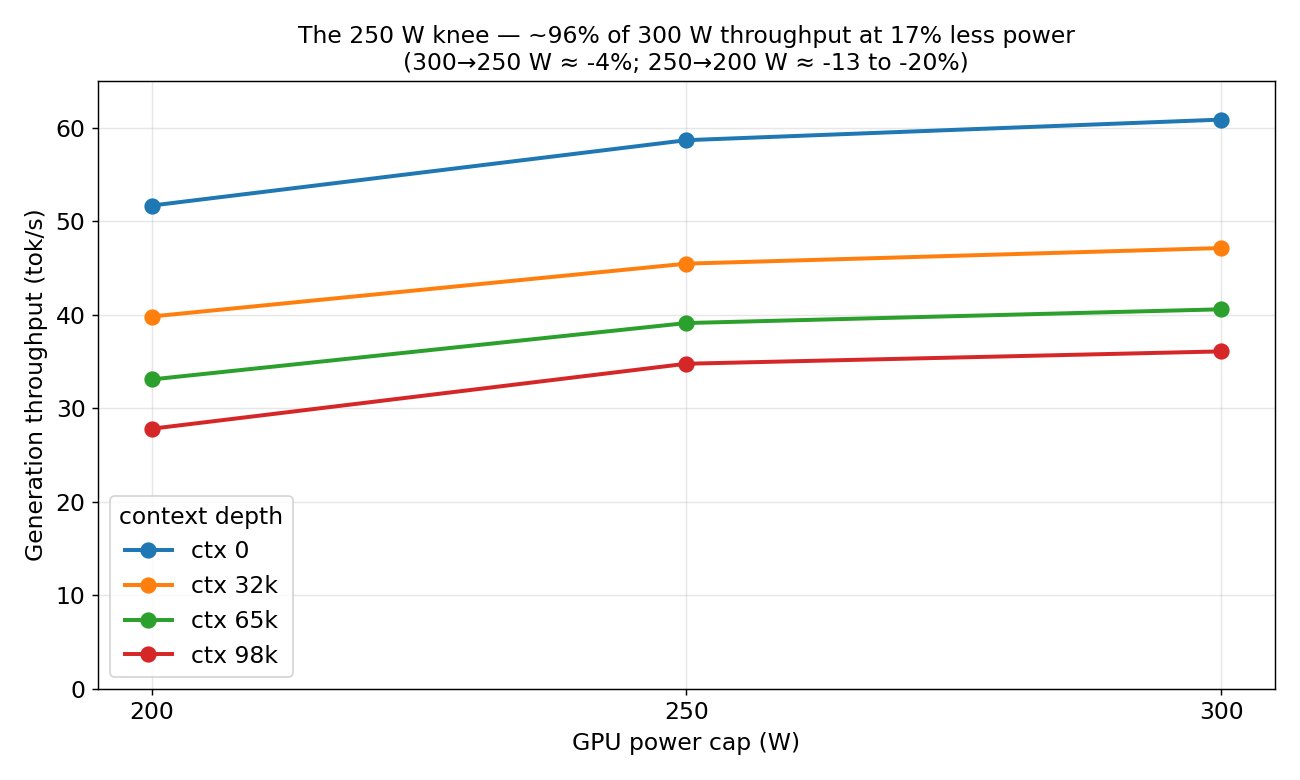
The most practical takeaway for developers: if you are running local models, optimize your inference stack before spending money on new hardware. @above_spec showed that capping power at 250W instead of 300W preserves 96% of throughput while saving 17% on power draw, and tuning the -ub parameter in llama.cpp matters more than KV quantization for deep context performance. Speculative decoding with MTP is nearly free overhead for a 2x speed gain. Squeeze everything you can from what you already own.
Quick Hits
- @mitsuhiko expressed interest in Zero, a new programming language built specifically for AI agents that features explicit capabilities, JSON diagnostics, and typed safe fixes. Its creator @ctatedev describes it as a systems language designed to be faster, smaller, and easier for agents to use and repair. Armin Ronacher noted it addresses several ideas he had been writing about recently.
- @ArtyfactsAI announced that their public alpha has opened, though details on the product remain sparse beyond the launch signal.
- @krzyzanowskim vented frustration after spending a full day writing a PRD, half a day reviewing it, and 16 hours implementing it, only to find the result broken both functionally and spec-compliant due to "implementation drift." A painfully relatable moment for anyone building with AI-assisted workflows.
Running Frontier Models on Consumer Hardware
The local inference movement picked up serious momentum today with multiple independent demonstrations that frontier-tier models can run on hardware accessible to individual developers. @antirez, the creator of Redis, showed DeepSeek V4 PRO running on a Mac Studio M3 Ultra with 512GB of RAM. Using a 2-bit DwarfStar quantization, the full PRO model fits in a 433GB GGUF file and generates at 13 tokens per second. As he put it: "I didn't expect DeepSeek v4 PRO (not Flash) to run well on the Mac Studio M3 Ultra with 512GB of RAM." The prefill speed hits 130 tokens per second with longer prompts, making it genuinely usable for interactive work.
@above_spec took a different route, running Qwen 3.6-27B with MTP speculative decoding on two used RTX 3080 Tis connected over PCIe 3.0 x8/x8 with no NVLink. The result was 61 tokens per second at 100k context. In a follow-up analysis they mapped the power efficiency curve and found that 250W is the sweet spot, delivering "96% of 300W throughput, for 17% less power." Dropping to 200W caused performance to crater by 15 to 23 percent depending on context depth. The lesson is that power capping is a legitimate optimization lever, not just an electricity-saving gesture. @malikwas1f amplified a related finding that llama.cpp's new MTP update nearly doubled inference speed while consuming only 1GB of additional VRAM, making speculative decoding essentially free for supported models.
@TheAhmadOsman connected these hardware wins to a bigger thesis, arguing that continual learning has already been solved but requires local model weights, which is why large labs avoid the conversation. "Local / Opensource AI will win. Inevitable." Whether or not the broader claim holds, today's posts make the practical case unmistakable. The combination of better quantization, speculative decoding, and power tuning means the gap between what you can run locally and what requires cloud infrastructure is narrowing from both ends simultaneously.
AI Agents Are Transforming Expert Work
The agent conversation today split between detailed workflow design and startling real-world impact reports. On the practical side, @itsolelehmann laid out nine Hermes agent workflows he would build from scratch to create a genuine chief-of-staff AI. The most compelling is a self-improving viral swipe file that monitors engagement across social platforms, auto-extracts high-performing posts into structured records with hook, structure, topic, and stats, and builds a "precise fingerprint of what works for me, calibrated against real data" over time. Another standout is The Humanizer, a skill that audits text against 30+ known AI writing tells including em-dashes, "delve," "tapestry," and tricolon structures, then rewrites into natural prose. He calls it "probably my most used workflow in my entire stack." The full list also includes a daily brief, meeting prep, trending workflow radar, bookmark inbox, customer support cron, weekly business report, and an Obsidian-based second brain.
On the impact side, @FundamentEdge shared a remarkable quote from Citadel's Ken Griffin describing a genuine step change in AI agent productivity over recent months. "Work that we would usually do with people with masters and PhDs in finance over the course of weeks or months being done by AI agents over the course of hours or days," Griffin said. "These are not mid-tier white collar jobs. These are like extraordinarily high skilled jobs being automated by agentic AI." He admitted going home one Friday "fairly depressed" after witnessing it inside Citadel's own walls. This is not a futurist prediction from a conference stage. It is a hedge fund founder describing what his firm is already doing.
@tricalt offered a systems-level insight that cuts across the workflow discussion, arguing that "Memory isn't a plugin. Skills aren't a plugin. They're the same harness." The linked article makes the case that memory APIs are not a viable standalone product category and that skill systems are essentially structured markdown, suggesting the industry is overcomplicating agent infrastructure by treating memory and capability as separate concerns. Meanwhile @kevinrose highlighted Grok-Wiki, a native app built on the newly released Grok CLI that turns any repository into searchable knowledge with wiki generation and codebase Q&A, calling its creator "brilliant, one to watch." The tooling ecosystem around agents is clearly maturing past the experimentation phase.
Model Architecture and a Lightweight Contender
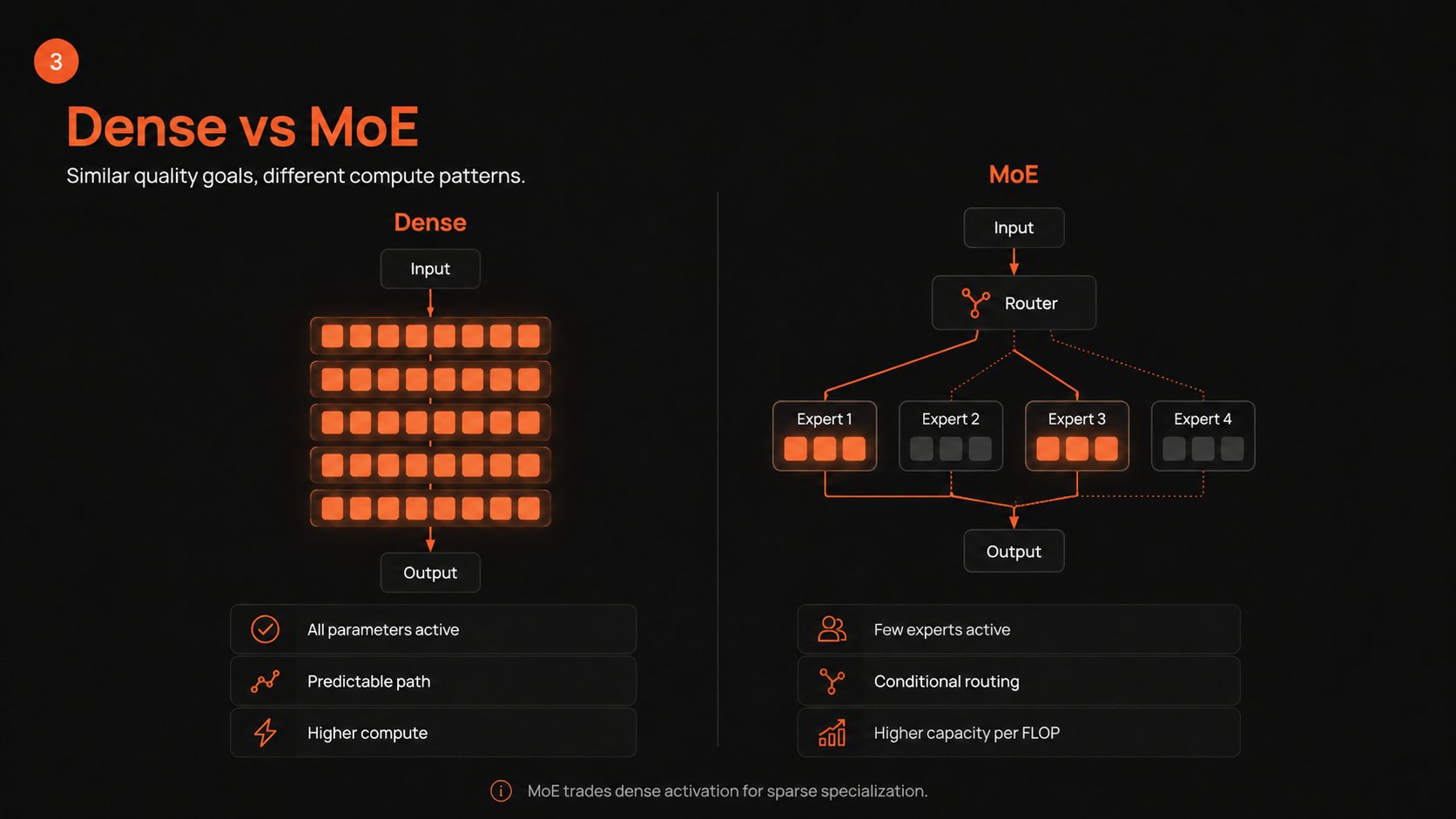
@0xSero posted a clean explainer on dense versus Mixture of Experts architectures that is worth bookmarking. Dense models like Qwen 3.6-27B and Gemma 4-31B activate all parameters for every token, making them slower per token but often more intelligent relative to their size. MoE models like DeepSeek V4 Flash and Qwen 3.5-397B use a router to send tokens to specialized sub-networks, activating only a fraction of total parameters per token. DeepSeek V4 Flash has 284 billion total parameters but activates just 13B per token, less than half the active count of Qwen 3.6-27B. The tradeoffs are straightforward: MoE models are faster at inference and can be trained on more data for longer, but they demand more VRAM to load and are harder to train. Dense models are simpler to train and can be remarkably smart for their size, but they cannot match MoE throughput at equivalent quality levels.
@KyleHessling1 announced a new 9B parameter model fine-tuned specifically for tool calling and agentic coding workflows in the Hermes agent framework. It scored 53.33% on SWE-bench across 200 samples, which he noted is "nipping at the heels of the Gemma 4 series, much larger models on this particular benchmark." It also hit 85 on the HermesAgent-20 benchmark compared to the base model's 71. His practical recommendation is to run it hot at temperature around 1, noting that higher temperatures help the model depart from base behaviors and avoid overthinking in agentic harnesses.
@sergeykarayev expressed genuine skepticism about NVIDIA's newly released SANA-WM, a 2.6B parameter open-source world model that generates controllable 720p video up to 60 seconds long from a single image and text prompt with 6-DoF camera trajectory control. "I don't understand how this can be 2.6B params," he wrote, quoting @BrianRoemmele's detailed breakdown of the model's capabilities. Those capabilities include 36x higher throughput than previous open models, training on 213K public videos in just 15 days on 64 H100s, and the ability to denoise a full 60-second clip in roughly 34 seconds on a single RTX 5090-class GPU. Whether the parameter count is genuinely surprising or just reflects architectural efficiency, the model represents a significant milestone for open-source video generation.
Claude Code Skills and the Filesystem Revelation
@KaitoEtLIA shared a candid and widely resonant reaction to Anthropic's two-hour training video on building Claude agents, led by the engineer who builds Claude Code. The key realization hit within the first five minutes: "Skills are just folders. Folders that retain your workflow, your domain, your expertise." After reflecting on every prompt he had rewritten from scratch, every context he had re-explained across hundreds of sessions, and every conversation that started from zero, he diagnosed himself with a "skill issue" in the gaming sense. The training covers structuring autonomous agents, granting terminal access for execution and self-correction, managing memory through the filesystem, and blocking hallucinations with hooks. @techNmak amplified related observations from Andrej Karpathy about Claude Code, describing them as things "every Claude Code user has felt but couldn't articulate." The common thread is that the gap between casual usage and expert-level agent work is primarily about understanding that the filesystem is the programming interface. Skills are not magic. They are organized directories that persist context. The users extracting the most value are the ones who stopped treating AI tools as stateless chat sessions.
Security: Credential Brokering and the Grafana Breach
Agent security got a concrete and elegant solution today. @dangtony98 explained how credential brokering lets agents like OpenClaw, Hermes, and Claude Code access APIs and services without ever holding real credentials. The agent receives dummy tokens, and a middleware layer called Agent Vault swaps in real credentials at the network level. As the original post from @infisical described the problem: "Your AI agent has your API keys. A poisoned document tells it to curl your secrets to an attacker's server. This is credential exfiltration, and it's the number one risk in agentic AI right now." The fix is simple in principle: "The agent never sees your keys." This is a pattern that should become standard infrastructure for anyone running agents with API access in production.
In unrelated but timely news, @grafana disclosed that an unauthorized party obtained a token granting access to their GitHub environment, enabling a threat actor to download the Grafana Labs codebase. While this breach does not appear to involve AI agents directly, it is a sharp reminder that as agents proliferate and receive increasingly broad access to code repositories, APIs, and infrastructure, the attack surface for credential-based compromises grows in parallel. The principle behind credential brokering, minimizing standing access and ensuring no component holds secrets it does not absolutely need, applies universally across both traditional and agentic systems.
Sources

Introducing Zero The programming language for agents. I wanted a systems language that was faster, smaller, and easier for agents to use and repair. Explicit capabilities. JSON diagnostics. Typed safe fixes. Made for agents on day zero. https://t.co/uTrDOmyBR1

Your AI agent has your API keys. A poisoned document tells it to curl your secrets to an attacker's server. This is credential exfiltration, and it's the #1 risk in agentic AI right now. The fix is removing the secret from the agent entirely. Agent Vault sits between your agent and the APIs it calls. The agent gets dummy credentials, and Agent Vault swaps in the real ones at the network layer. The agent never sees your keys. We just dropped a full video + guide on connecting Hermes Agent to Agent Vault on a VPS!


Anthropic a publié une Formation complet de 2 HEURES sur la construction d'agents Claude. Animé par l'ingénieur qui construit Claude Code. Gardez-la précieusement en Signet🔖 de A à Z : Structurer un agent qui se gère sans supervision. Lui donner accès au terminal pour exécuter, lire, corriger. Gérer sa mémoire via le système de fichiers. Bloquer les hallucinations avec des Hooks. Faire tourner un agent sur un gros codebase sans tout casser. À la fin : vous utilisez Claude comme un pro et vous monétisez vos compétences. Débutant ou avancé, tout est là en un seul endroit, ce cours couvre tout. Ça vaut plus que tous les cours à 500$ que t’as failli acheter.
NVIDIA just unleashed SANA-WM and it’s an absolute MONSTER for the future of open source AI! A blazing-fast 2.6B-parameter open-source world model that doesn’t just generate video… it creates controllable, physics-rich, high-fidelity worlds on demand. Why this is insanely powerful: • One image + text prompt + 6-DoF camera trajectory → generates 720p videos up to 60 seconds long with buttery-smooth, precisely controlled camera movement. You’re not just watching, you’re piloting the simulation. • Runs locally on a single consumer GPU (RTX 5090 level) thanks to heavy distillation + NVFP4 quantization. Full 60-second clip denoised in ~34 seconds. No massive clusters required. • 36× higher throughput than previous open models while rivaling (or beating) closed industrial giants in visual quality and consistency. • Trained lightning-fast: ~213K public videos in just 15 days on 64 H100s. • Built with next-level tech: Hybrid Linear Attention, dual-branch camera control, two-stage pipeline, and rock-solid metric-scale pose understanding. This is a true open world model, the foundation for embodied AI, robotics, autonomous systems, and hyper-realistic simulations that can run anywhere. Project: https://t.co/GBg4F8FWCp GitHub: https://t.co/Q66j2UhofN Paper: https://t.co/ktogIjtFdO At our Zero-Human Company, we’re already running SANA-WM live in our core pipelines. It’s supercharging autonomous agent training, generating unlimited synthetic training data, and powering full end-to-end simulation loops, zero humans in the loop. The speed and control let us test thousands of edge-case scenarios overnight, iterate at lightspeed, and push our fully autonomous operations further than ever before. This is the kind of breakthrough that turns science fiction into daily reality. World models just leveled up — hard. The age of personal, local, controllable universes is here.
Grok CLI dropped yesterday. So I built something for it using it: Grok-Wiki A native app that turns any repo into searchable knowledge: Generate wikis, Ask questions, and understand codebases through a local desktop agent powered by Grok CLI. https://t.co/J64a6uWBvm Sign up for Early Access.

Memory isn't a plugin. Skills aren't a plugin. They're the same harness.
Memory APIs are not a viable product category, and skill systems are just markdown. We've been saying it for a while. @sarahwooders and @hwchase17 mad...