AI Coding Tools Reach Production Grade as San Francisco Grapples With AI's $20M Wealth Divide
The AI coding assistant ecosystem matured rapidly this week, with new templates, session managers, and diff viewers built entirely by AI. Meanwhile, a viral post from @deedydas laid bare the staggering wealth concentration in San Francisco's AI sector and the existential career anxiety rippling outward.
Daily Wrap-Up
Something shifted in the AI developer tooling space this week, and it's visible in the sheer density of posts about production-grade workflows. We saw templates for structured AI coding sessions, a unified vault for managing multiple AI coding assistants, and a diff viewer built by an AI in 16 minutes. These aren't demos or toy projects anymore. They're real tools, solving real friction points, and in several cases they were built by the very AI assistants they're designed to manage. The snake is eating its own tail, and the tail tastes great.
The undercurrent running through today's feed is a deep anxiety about who benefits from all of this. @deedydas painted a vivid picture of San Francisco's AI wealth divide, estimating that roughly 10,000 people at companies like Anthropic, OpenAI, xAI, and Nvidia have hit retirement-level wealth above $20M, while everyone else, even those making solid salaries, feels like they're running on a treadmill going nowhere. That post resonated because it named something many people are feeling but few articulate: the AI boom is creating winners and losers at a speed that makes previous tech cycles look glacial. @levie's post about forward-deployed engineering reinforced the point, arguing that AI is fundamentally different from traditional software because it constantly evolves, requiring vendors to stay embedded with customers rather than ship and walk away.
The most practical takeaway for developers: invest in learning how to structure AI coding workflows with clear goals, constraints, and verification steps, as demonstrated by @kloss_xyz's /goal templates. The developers who will thrive are not those who use AI assistants casually, but those who build systematic processes around them, treating prompt structure as seriously as code architecture.
Quick Hits
- @ClaudeDevs announced that 5-hour and weekly rate limits have been reset for all users, a small but welcome Friday housekeeping update.
- @gaganghotra_ flagged that Google published a comprehensive guide on optimizing websites for generative AI features in Search, a must-read for anyone in SEO navigating the shift from traditional rankings to AI-generated answers.
- @mackenzieprice shared a curated list of ten third-party AI educational tools for kids, noting that many of the adaptive learning apps used at Alpha School are still internal and not publicly available.
- @isnit0 shared photos of his brother-in-law's home GPU farm generating roughly $3,000/month in profit, currently 30% solar-powered with plans to reach 60% by summer through battery additions rather than more panels.
- @davepl1968 offered a nostalgic trip back to MS-DOS 6.22 and the meditative ritual of watching Disk Defragmenter crawl across a 540MB hard drive, a reminder that tech nostalgia hits different when you actually worked on the OS.
AI Coding Tools Hit Production Grade
The AI coding assistant ecosystem has crossed an important threshold. We're no longer watching people experiment with prompting tricks. We're watching developers build infrastructure around AI-assisted development the same way they'd build infrastructure around any other critical workflow. The tools are maturing, the workflows are solidifying, and the people building them are treating AI coding not as a novelty but as a core part of their engineering stack.
@kloss_xyz released a set of seven production-grade templates for the /goal command in Codex, Claude Code, and Hermes. The templates cover the full software development lifecycle: ideation, planning, building, refactoring, consolidation, hardening, and migrations. The first three are meant to be used sequentially, while the remaining four are applied as needed. What makes this notable is the structure itself. Each template enforces a discipline of stating a clear goal, defining constraints, creating a verification plan, and specifying stop rules that prevent scope creep. This is the difference between chatting with an AI and engineering with one.
> "use 1-3 in order, 4-7 whenever" - @kloss_xyz
The original /goal framework that inspired these templates is worth understanding. It structures prompts around six elements: GOAL (single measurable outcome), CONTEXT (architecture and assumptions), CONSTRAINTS (what must not change), PLAN (understand before acting), DONE WHEN (verifiable completion state), and VERIFY (tests, builds, rollback plans). This is essentially a mini software development methodology compressed into a prompt format.
Meanwhile, @lawrencecchen introduced cmux Vault, a sidebar pane that unifies session management across Codex, Claude Code, OpenCode, and Pi. Full-text search across all sessions, drag-and-drop into workspaces. The fragmentation problem, where your AI coding history is scattered across multiple tools, just got a solution. And @cnakazawa built Codiff, a local diff viewer, entirely with Codex in 16 minutes. A tool for reviewing AI-generated code, built by AI-generated code.
@mattpocockuk pushed back against a common anti-pattern in AI agent design, arguing that long "skills" (essentially lengthy prompt instructions) are a red flag: hard to audit, hard to edit, and expensive to run. "The shorter the skill, the better IMO," he wrote. This aligns with the broader movement toward modular, composable AI workflows rather than monolithic prompt engineering.
What connects all of these is a shift from using AI coding assistants as conversational partners to treating them as components in a structured engineering pipeline. The developers getting the most value are not those who type the cleverest prompts. They are the ones building systems around the prompts, with clear inputs, outputs, and feedback loops.
San Francisco's $20M AI Wealth Divide
@deedydas wrote what might be the most candid assessment of San Francisco's current psychological state that you'll read this year. His thesis is straightforward: over the past five years, roughly 10,000 people at AI companies have accumulated wealth exceeding $20M, while everyone else, including well-paid software engineers making under $500K, feels like they're falling irreversibly behind.
> "Everyone outside that group feels like they can work their well-paying (but <$500k) job for their whole life and never get there." - @deedydas
The post identifies four distinct groups caught in this distortion field. First, career strategists desperately trying to pick the right path: founder, early employee at the right AI lab, or something else entirely. Second, workers paralyzed by the fear that their skills are being deprecated in real time. Third, middle managers with families who lack the flexibility to pivot and see their roles being hollowed out. And fourth, the winners themselves, who @deedydas notes are often struggling with a profound lack of purpose after going from middle-class salaries to tens of millions almost overnight.
@levie's post on forward-deployed engineering added an important dimension to this conversation. He argued that AI is fundamentally unlike traditional software because it constantly evolves. Models change, capabilities shift, and best practices emerge at a pace that makes it impossible for any single company to keep up on its own.
> "In AI, you're delivering something that is constantly evolving both due to the nature of the new capabilities and best practices that emerge, but also because the underlying models change so much that they can meaningfully change the workflow." - @levie
This creates a compelling argument for vendor-driven AI deployment, where one company learns from thousands of customers and feeds those learnings back into the product. It also implicitly acknowledges that the skills gap is real and widening. If deploying AI effectively requires constant proximity to evolving best practices, then the companies and individuals closest to the source of those practices have an insurmountable advantage.
AI-Powered Trading and Prediction Markets
Two posts today highlighted how AI is reshaping financial markets, one from a deeply technical angle and one from a practical workflow perspective.
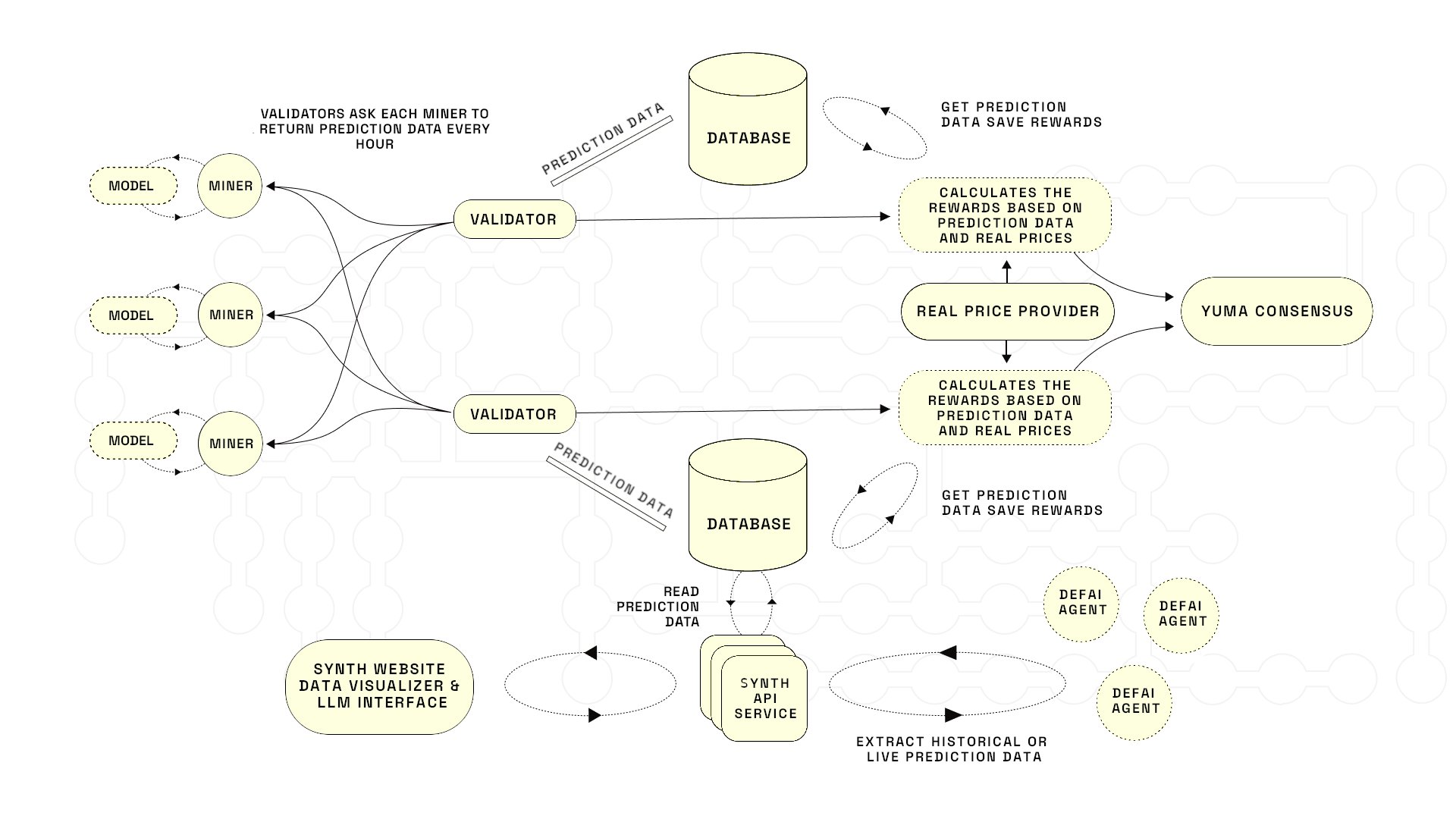
@AlterEgo_eth shared details about synthdataco/synth-subnet, a system where AI models compete to generate complete probability distributions of future price movements rather than simple directional predictions. Instead of guessing whether Bitcoin goes up or down, each model produces 1,000 full Monte Carlo simulated price paths for a given time horizon. Quality is evaluated using Continuous Ranked Probability Score, which penalizes both poorly calibrated predictions and distributions that are too vague or overconfident.
> "Instead of trying to guess a single price, AI models generate 1000 full Monte-Carlo simulated price paths. This gives a much more realistic probability distribution for trading on Polymarket." - @AlterEgo_eth
This is a meaningful evolution beyond the typical crypto prediction model. Most market prediction systems output a single number or a binary up/down signal. Outputting a full probability distribution is far more useful for platforms like Polymarket where you're pricing binary outcomes against a market. The approach acknowledges uncertainty rather than pretending it doesn't exist.
@milesdeutscher took a more accessible angle, sharing an AI-powered trading workflow that he described with characteristic understatement as "fucking sauce" and claimed would have let him "print money" if he'd had it years ago. The post links to a full guide on building AI workflows for trading analysis.
Local AI and Model Optimization
Running large language models locally on consumer hardware remains a craft that blends equal parts expertise and obsession. @nicekate8888 documented a 20-day journey to optimize Qwen3.6-27B on a Mac, moving from Unsloth Q5 at 18 tokens per second to MLX 6-bit with DFlash at 22 tok/s, and finally landing on MTPLX 4-bit at 43 tok/s with acceptable quality. That's a 2.4x speedup through quantization alone, a reminder that how you compress a model matters as much as the model itself.
The post also highlights an interesting workflow: using Grok to help configure the optimization process step by step. Using one AI to help you run another AI locally is becoming a standard pattern.
@antirez, the creator of Redis, is working on making LLM evaluation less painful. His observation that "evals take time and are boring" but are "a fundamental validation step of sane LLM inference" captures a real tension in the field. Everyone knows evaluations matter. Almost nobody wants to do them. Building tools that make evals as easy and engaging as possible could remove one of the biggest bottlenecks in responsible AI development.
Agent Observability and Realtime Voice AI
As AI agents become more autonomous, the ability to inspect and understand their behavior becomes critical. @marcklingen noted a neat symmetry: "2025 just look at agent traces. 2026 agents look at agent traces." The observation, referencing a primer on agent tracing by @lotte_verheyden, highlights how quickly the field is moving from humans debugging agent behavior to agents debugging other agents. This recursive pattern, tools building tools, agents monitoring agents, is becoming a defining feature of the current AI landscape.
On the voice AI front, @badlogicgames shared a demonstration of OpenAI's Realtime-2 API running fully in real-time, with the experimenter moving beyond rigid "turn-for-turn" conversations toward more natural, overlapping dialogue. The fact that this is described as a breakthrough in naturalness rather than a technical demo says a lot about how far voice AI has come. The bar is no longer "it works." It's "it feels like talking to someone."
Image-to-3D in Five Minutes
@CopyRebeldia highlighted a GitHub repository called image-blaster that converts any photograph into an explorable 3D world in approximately five minutes. The output includes physical meshes, background splats, and ambient audio. The post, written in Spanish, noted with a mix of awe and melancholy that people who spent a decade learning Blender were watching in silence.
> "Una imagen entra. Un mundo sale. Cinco minutos." (An image enters. A world comes out. Five minutes.) - @CopyRebeldia
This is the kind of tool that compresses years of specialized skill into a single command. Whether that's liberating or devastating depends entirely on which side of the compression you're standing. It's also a sign that 3D generation is following the same trajectory as image generation: from research curiosity to open-source tool to "why would you do this manually?" in what feels like months.
Sources


How to Build a Team of AI Agents That Run Your Business While You Sleep — The Complete Playbook



A primer on tracing for LLM applications

The First AI Workflow Every Trader Should Build (FULL GUIDE)

/goal is the best command in Codex, Claude Code, and Hermes right now. And most are using it wrong. They write "make no mistakes". And pray. Here's how to structure yours for a mission, to rank your uncertainties before acting, to kill scope creep, and to close every loop other prompts leave open. /goal prompt [structure below] GOAL: <single clear measurable outcome; one mission only> CONTEXT: <repo/files/architecture/current state> <known assumptions, dependencies, and relevant prior decisions> CONSTRAINTS: <what must not change> <required standards/patterns> <forbidden files/actions if any> PRIORITY: (optional) 1. <highest priority> 2. <secondary priority> 3. <tertiary priority> PLAN: <understand first, then act> <restate understanding before executing non-trivial changes> <prefer minimal sufficient changes over broad rewrites> DONE WHEN: <verifiable completion state> <expected behavior preserved or improved> VERIFY: <tests/build/lint/typecheck/manual validation> <state what could not be verified and why> <include rollback/containment plan for destructive or high-risk changes> OUTPUT: <concise summary/docs/audit/results> <changed files, key decisions, risks, and follow-ups> STOP RULES: <halt on high-impact ambiguity or risk; do not invent architecture, behavior, or requirements> <surface uncertainties together with ranked highest-confidence proposals before acting; not open-ended clarification questions> <do not continue expanding scope after the goal is satisfied>
The real power of forward deployed engineering has always been putting strong technical people directly alongside the operators who own the outcome. That proximity forces the work to solve the actual problem instead of some sanitized version of it. In the AI era this principle has become even more valuable. Agents can now sit inside real workflows and improve from actual decisions, which means the highest-leverage work is extracting the tacit knowledge that lives with subject matter experts, building evaluations that reflect how things actually break, and closing the production feedback loop so agents get better from real outcomes.