The Harness Becomes the Moat: Agent Memory Systems Mature While Claude Code and Codex Battle for Developer Loyalty
Today's AI discourse crystallized around agent architecture as the real competitive differentiator, with a detailed Hermes memory system breakdown and analysis of why agent codebases fail at month six. Meanwhile, the Claude Code vs Codex war intensified as Anthropic's enterprise pivot appeared to alienate power users, and a breakthrough paper on multi-stream LLMs challenged the sequential thinking paradigm inherited from ChatGPT.
Daily Wrap-Up
If there was one message that cut through today's noise, it is that model quality is no longer the battleground. The conversation has moved decisively to the harness: the architecture, memory system, and context layer wrapped around the model that determines whether an agent actually works in production or collapses six months in. We saw this from multiple angles. @akshay_pachaar published a remarkably detailed breakdown of Hermes' three-tier memory architecture, from tiny always-present markdown files to SQLite full-text search to pluggable external providers. @ghumare64 analyzed the four canonical ways agent codebases break at month six and argued for structural fixes over developer discipline. And @steipete shipped a skill that loops Codex's review until the code is clean, a small but telling example of the meta-tooling being built around these coding agents.
The competitive drama between Claude Code and Codex reached what feels like a turning point. @willsentance's thread laying out why Anthropic lost its coding lead almost overnight went viral, arguing that treating the model as the moat was doomed once OpenAI simply tuned for code and leveraged their compute advantage on price. The technical evidence backs this up: @antirez reported that every contributor in the recent DS4 benchmarking found GPT 5.5 immensely helpful while Opus was "completely useless." Anthropic is now offering dedicated monthly credits to Claude Code users, a clear response to churn, but the trust damage from their enterprise pivot may prove harder to fix than the pricing.
On the research front, @jonasgeiping's multi-stream LLM paper, highlighted by @ShashwatGoel7, challenges something so fundamental that most of us never questioned it: the sequential message-based exchange inherited from ChatGPT's original design. The idea that models could maintain parallel streams for reading, writing, thinking, and subvocalizing concerns feels like one of those shifts that seems obvious only after someone articulates it. The most practical takeaway for developers: stop selecting AI coding tools based on model benchmarks alone and start rigorously evaluating the harness, memory architecture, and context management layer, because that is where production value is actually created and where the competitive moat now lives.
Quick Hits
- @mattpocockuk released an improved version of
/grill-me, his most popular skill ever, saying he has stopped using the original for code and now gets 5-10 messages daily from users whose workflows it transformed. - @derekmeegan demonstrated a
/browser-to-apiskill that analyzes network activity and CDP logs to auto-generate OpenAPI specs, showing Codex one-shotting a fully documented OpenTable API client. - @fitchmultz recommends
pi-agent-browser-nativefor making browser automation a native tool within the pi agent framework, reporting materially improved tool uptake and token efficiency over bash-based workarounds. - @0xMovez highlighted a free 32-minute vibe-coding session between Claude Code creator Boris and Bun's creator, calling it the best vibe-coding masterclass available this week.
- @0xSero received a $100,000 grant from the Human Rights Foundation, adding to donations and hardware from Nvidia, Lambda, and private donors, all supporting the open source AI mission.
Agent Architecture and Memory Systems
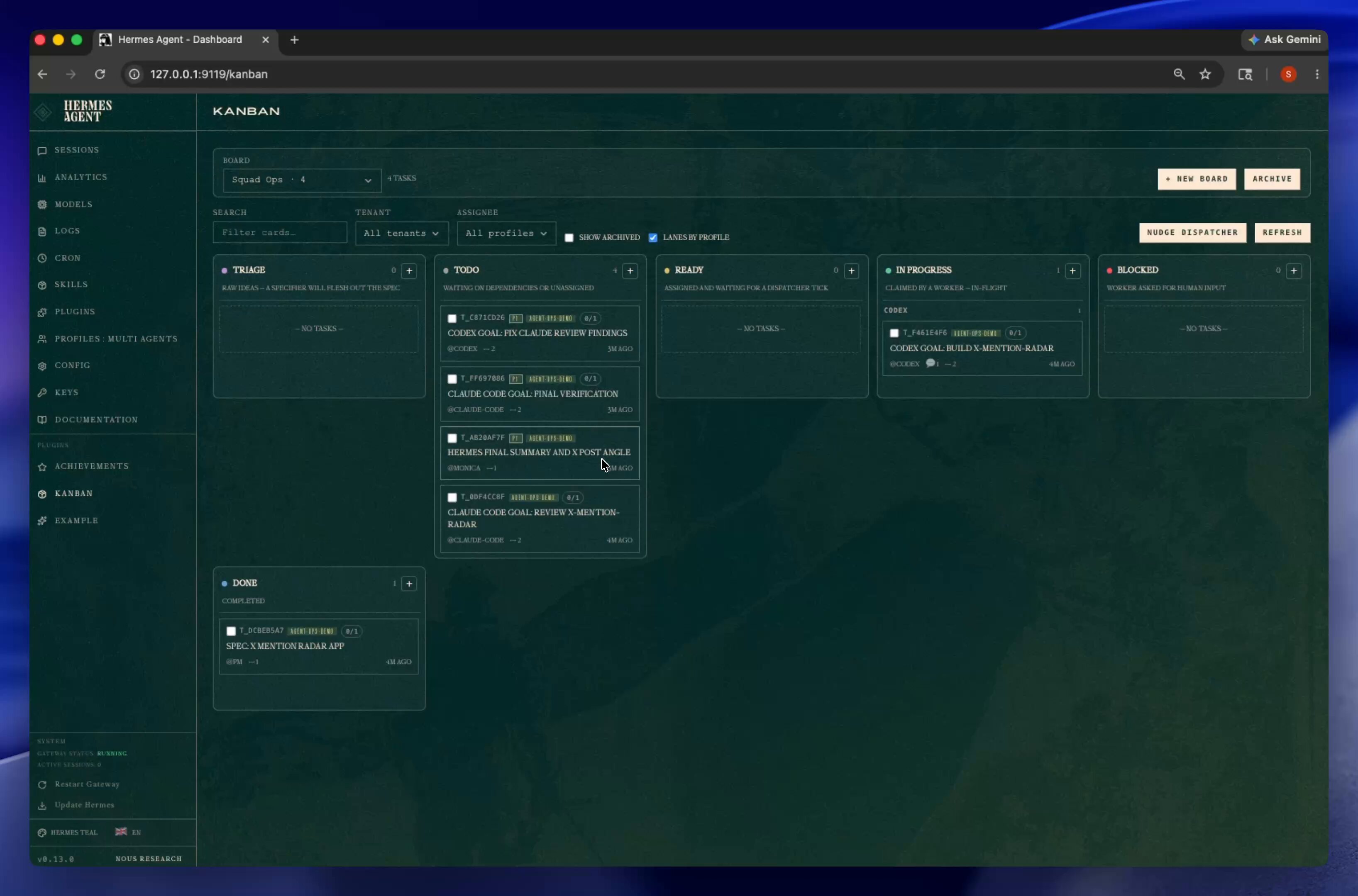
The dominant theme of the day was the maturation of agent architecture from experimental playground into rigorous systems engineering. @Saboo_Shubham_ showcased a multi-agent pipeline where Codex builds, Claude Code reviews and refines, and Hermes orchestrates the handoff, all tracked on a single Kanban board with agents running in continuous loops. This pattern of specialized agents with defined roles and shared state management is becoming the default architecture for serious development workflows.
The standout contribution was @akshay_pachaar's deep dive into Hermes' three-tier memory system, which tackles the fundamental problem of agent amnesia with remarkable elegance. Tier 1 uses two tiny markdown files, MEMORY.md at 2,200 characters and USER.md at 1,375 characters, injected into the system prompt at session start. When MEMORY.md hits roughly 80% capacity, the agent consolidates by merging related entries and dropping redundancy. As @akshay_pachaar puts it: "natural selection pressure applied to memory. the files stay small, but what's inside gets sharper over time." Tier 2 stores every conversation in SQLite with FTS5 indexing, enabling sub-10ms search across 10,000+ documents. Tier 3 brings pluggable external providers like Honcho for dialectic user modeling and Holographic for local-first HRR vectors, all orchestrated by an autonomous nudge that decides what is worth saving every 300 seconds.
This architectural rigor was reinforced by @ghumare64's analysis of @mfpiccolo's framework for identifying the four canonical month-six failures in agent codebases: class-level mutable defaults shared between agents, tool functions that return None on every failure type, session memory mutated by LLM-extracted strings, and multi-agent setups leaking parent conversation history to sub-agents. The proposed Worker/Function/Trigger pattern makes these failure modes structurally inexpressible. @ghumare64 draws the historical analogy sharply: "What Mike's arguing is the React-of-2013 move. jQuery apps scattered DOM state across whichever closure was handy. The discipline of 'keep state in one place' was well understood and ignored everywhere. React made the discipline structural: the bug class went away because the framework stopped allowing the bad shape."
On the tooling front, @mvanhorn introduced Granola CLI integrations for Claude Code and Hermes skills, adding cross-meeting SQLite search, MEMO pipeline runner, and attendee timelines. @steipete contributed a skill that runs codex /review in a loop until there are no issues left, with the self-aware caveat that "It won't fix system architecture for ya, so you still need BRAIN as master model." Together these posts paint a picture of an ecosystem that is rapidly building the infrastructure layer between LLMs and production software.
The Claude Code vs Codex War
The competitive dynamics of the AI coding market took center stage with @willsentance's viral thread responding directly to Claude Code team member @bcherny's request for feedback. His four-point analysis of Anthropic's rapid loss of its coding lead is worth studying as a business case. The core argument: Anthropic treated their model as the moat, which was fundamentally unsustainable since all OpenAI had to do was tune for code and release. Meanwhile OpenAI controls the compute and therefore the price floor, bought up harness talent aggressively over the past year, and focused the entire company on making Codex the best coding experience possible.
As @willsentance frames the pivotal misstep: "for some reason, anthropic decided to release a PR stint around Mythos with the implication that devs weren't to be trusted with such power, and its clear at this point it really was an attempt to declare their pivot away from the consumer to enterprise." His conclusion carries weight: "core lesson: if you plan to abandon your core customer, be really careful how you execute that or you may end up in a canyon you cant cross."
The technical evidence reinforces the narrative. @antirez, creator of Redis and one of the most respected infrastructure engineers in the industry, reported bluntly that during the recent DS4 benchmarking, "not just me but every other contributor found GPT 5.5 able to help immensely and Opus completely useless." When engineers of that caliber publicly declare a preference, it signals a real shift in sentiment. The community's response has been pragmatic rather than loyal: @LLMJunky noted that someone already built a workaround to Anthropic's controversial claude -p changes, with @FUCORY shipping npx claude-p as a drop-in replacement. And @malikwas1f shared that Anthropic is now offering "dedicated monthly credit" that effectively slashes Claude Code usage limits by 5 to 20 times, a clear acknowledgment of the price-performance problem driving churn.
MCP, Context Layers, and Headless Software
Two posts today addressed where value actually accrues when agents replace traditional user interfaces. @a16z highlighted Salesforce's decision to open its APIs and launch a headless product, essentially betting that in an agentic world, its value lies in the data layer rather than the UI layer. The question @a16z's Seema Amble poses is sharp: if you strip away the UI and expose the database, what are you actually left with?
@jainarind, CEO of Glean, provided the technical counterpart with benchmark results showing Glean's MCP server was preferred roughly 2.5x over off-the-shelf MCP tools in Claude Cowork while using about 30% fewer tokens, 44k versus 57k median. The key insight: "MCP is a protocol, not a context layer. It standardizes how models call tools. It does not solve ranking, permissions, memory, identity, or cross-system understanding." When MCP sits on top of a unified context layer with connectors, indexes, enterprise graph, and permissions baked in, agents return better results at lower cost because they are not brute-forcing their way through fragmented context with additional tool calls and reasoning loops.
This connects directly to the broader theme of the day. The harness, the context layer, the memory architecture: these are the new infrastructure challenges. Companies like Salesforce are betting their future on being the data substrate that agents query. Glean has built a product around being the unified context layer. Developers building with agents should invest in their context infrastructure with the same rigor they would invest in their data model.
Multi-Stream LLMs: Breaking the Sequential Bottleneck
The most intellectually provocative content came from @jonasgeiping's paper on multi-stream LLMs, highlighted by @ShashwatGoel7 who said it "made me re-think my understanding of what transformers can do (the changes are so simple and elegant!), and what language models could be." The argument targets something so fundamental that most of us never thought to question it: the sequential message-based exchange paradigm inherited from ChatGPT's original design.
As @jonasgeiping frames the problem: "The models cannot read while writing, cannot act while thinking and cannot think while processing information." Multi-stream LLMs address this through instruction-tuning for parallel stream formats, enabling models to predict and read tokens across multiple streams simultaneously in each forward pass. The benefits span latency, user experience, security through separation of concerns, and a novel form of parallel reasoning. The most striking claim: "Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized."
This is a direct challenge to the single-stream orthodoxy that has defined how every major LLM interacts with users. If the instruction-tuning results hold, it could reshape agent architectures from the ground up, making many of the orchestration patterns developers are building today feel as dated as callback-based JavaScript feels now.
Security: AI Finds an 18-Year-Old NGINX Bug While Supply Chain Attacks Escalate
Two security stories illustrated AI's dual role in cybersecurity: as a powerful tool for vulnerability discovery and as part of an increasingly complex attack surface. @IntCyberDigest reported that AI discovered a critical remote code execution vulnerability in NGINX that had been present for 18 years, affecting versions 0.6.27 through 1.30.0. Triggered via the rewrite and set directives in config files, the vulnerability includes published PoC code on GitHub, making immediate patching urgent for the widely deployed web server.
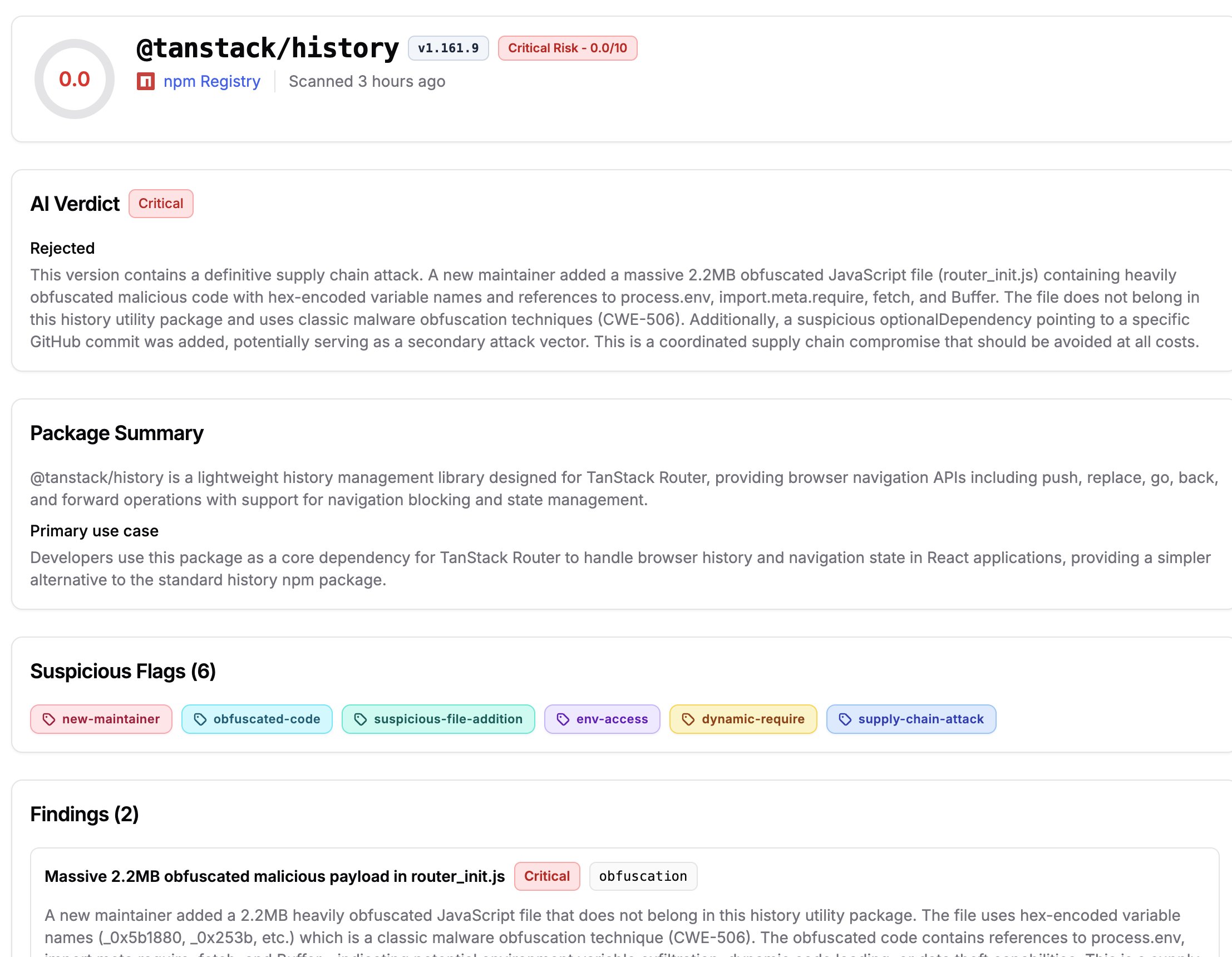
On the supply chain side, @DeRonin_ published a comprehensive protection guide following the TanStack npm compromise, where 42 packages were infected with credential-stealing payloads. The attack vector was elegant: malicious code hidden in optionalDependencies resolved through
Sources
@DavidKPiano Hey, Boris from the team here. What can we do better?

How To Cut Your AI Coding Bill by 80% (FULL GUIDE)

Is Software Losing Its Head?
Context makes the Coworker: Glean preferred ~2.5x as often as off-the-shelf MCP tools
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn. This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information. In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can … 🔵Be created by instruction-tuning for the stream format 🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in) 🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency 🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security 🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized. Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
Open Source must win.
Agent codebases that break at month six all break the same way.
Introducing npx claude-p A dropin replacement for claude -p https://t.co/aRWI6tWnD6



Hermes Agent Masterclass