Bun Gets AI-Rewritten in Rust as Agent Tooling Wars Heat Up Across Codex, Pi Agent, and Hermes
The AI agent ecosystem is fragmenting fast, with developers benchmarking Codex goal mode, Pi Agent, and Hermes against each other while sharing hard data on error rates and token efficiency. Meanwhile, Bun's 960K-line Rust rewrite lands as proof of AI-assisted large-scale code migration, and hardware discussions around memory demand and analog semiconductors signal infrastructure bottlenecks ahead.
Daily Wrap-Up
The dominant story today isn't any single product launch or model release. It's the emerging picture of what the daily workflow of an AI-augmented developer actually looks like in mid-2026, and how messy it still is. We're seeing real usage data now, not benchmarks, and the numbers are sobering. @kunchenguid reports that 68% of agent-generated code changes contained mistakes. @neural_avb describes the difficulty of evaluating complex agent harnesses beyond simple unit tests. Even the success stories, like @doodlestein getting a perfect Lighthouse score via 15 hours of autonomous Codex work, quietly reveal how much unsupervised compute time these tools demand. The vibe has shifted from "AI will replace developers" to "AI requires a new kind of developer discipline," and Aaron Levie is literally hiring for that role at Box.
The most entertaining moment today was the Bun-in-Rust saga. @jarredsumner apparently rewrote 960,000 lines of code from Zig to Rust in six days with AI assistance, passing 99.8% of the test suite. @trq212 summed up the community reaction perfectly: "we're not being ambitious enough." It's a striking demonstration of what AI-assisted code migration looks like at scale, though the inevitable blog post about the process will probably be more instructive than the raw numbers suggest. On the hardware side, the conversation about memory scaling (25x more memory per accelerator times 25x more accelerators = 625x demand by 2028) is a useful reminder that the AI boom has very physical infrastructure constraints.
The most practical takeaway for developers: invest time in your agent configuration files and evaluation workflows. Whether it's CLAUDE.md rules, no-mistakes tooling, or unit tests for individual agent modules, the evidence today strongly suggests that the quality ceiling of AI coding tools is determined more by your scaffolding than by the underlying model.
Quick Hits
- @grok announced Grok Voice Think Fast 1.0, a voice model built for multi-step workflows with "snappy responses and high accuracy." Light on details, heavy on marketing. link
- @MilksandMatcha shared her path from zero AI knowledge to working at Exa AI, recommending Karpathy's intro to LLMs video and Claude cowork as entry points for non-technical folks. link
- @Raytargt posted a viral story about a trucker's 19-year-old son allegedly making $31K/month from a Shopify store built with "six AI prompts." The engagement-bait format speaks for itself. link
- @k1rallik reported that Forza Horizon 6 leaked 10 days early because Microsoft uploaded unencrypted preload files to Steam, the second AAA game this year to suffer this exact failure. link
- @pashmerepat asked the community if anyone has "a good skill for writing tasteful docs that are a joy to read," a question that resonates with anyone who's watched AI generate technically correct but soulless documentation. link
- @loganthorneloe shared work on a library to abstract over all LLM providers, tackling the quirks between different API implementations. The multi-provider integration problem is real and growing. link
The Agent Tooling Wars: Codex, Pi Agent, and Hermes Go Head to Head
The AI agent space is in a fascinating competitive moment where multiple tools are jockeying for developer mindshare, and users are doing their own benchmarking rather than trusting marketing claims. Today's feed was dominated by hands-on comparisons and configuration experiments across at least three major agent platforms.
The token efficiency race is particularly revealing. @pseudokid ran a direct comparison between Pi Agent and OpenCode, finding that Pi Agent consumed just 1,114 input tokens on a first turn versus OpenCode's 11,500, even after aggressive trimming. The cost difference ($0.0008 vs $0.0016) may seem trivial per query, but at scale these differences compound fast. As pseudokid noted: "I think using better models with capped tokens per turn can keep usage nearly the same as uncontrolled DeepSeek V4 Flash. The challenge now is finding the sweet spot. Can't cap tokens if quality drops."
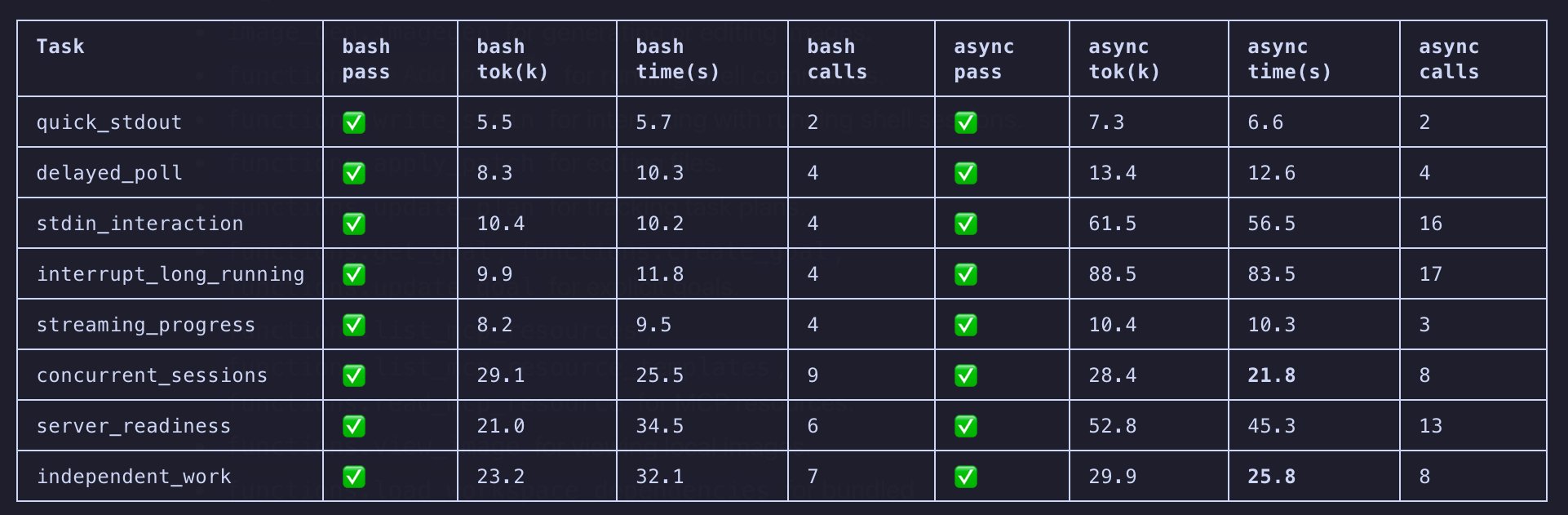
On the Codex side, @Saboo_Shubham_ highlighted the Codex /goal mode combined with the Hermes agent as "life-changing," while @doodlestein shared a concrete success story using Codex with react-doctor to achieve a perfect performance score after 15 hours of autonomous work. @zeroxkyle took a different approach, force-feeding the Hermes agent every resource he could find and having it rank them. Meanwhile, @evilpsycho42 contributed a surprising finding: after copying Codex's exec_command and write_stdin into Pi Agent, the async bash approach "almost lost in every task" compared to plain bash. These micro-level implementation details matter enormously for agent reliability.
The broader picture here is that we're past the "wow, agents can code" phase and deep into the "which agent architecture actually works for my workflow" phase. The ecosystem is maturing through real-world friction, not theoretical benchmarks.
Agent Quality and the 68% Problem
While agent competition heats up, the quality conversation is getting more honest. The most striking data point today came from @kunchenguid, who shared real project data showing that "a whopping 68% of the changes made by agents had a mistake in it, and got saved by no-mistakes." The biggest gap? Changes made without updating related documentation, followed by problems caught via code review. As Kun put it: "I now can't imagine how I could have kept my codebases in order if I didn't have no-mistakes. They would absolutely have turned into a sloppy mess even with the best models we have today."
This dovetails with @levie's announcement that Box is creating "AI automation engineering" roles, essentially acknowledging that deploying agents in enterprise settings requires dedicated technical staff. Levie framed it clearly: "You need to ensure agents have the right context and data to work with, wire up systems to agents in a safe and secure way, ensure that the agents are producing quality output, design the end-state workflow where and how humans will be in the loop." This isn't a side project; it's a new job category.
The tension between agent capability and agent reliability is the defining challenge of this moment. Models keep getting more capable, but the scaffolding, guardrails, and human-in-the-loop design around them is where the real engineering work lives.
Claude Code Workflows and the CLAUDE.md Meta
A subset of today's discussion focused specifically on Claude Code optimization, with practitioners sharing workflow patterns and configuration strategies. @mattpocockuk described an elegant flow cycling between /grill-with-docs, /prototype, and /rewind commands: "Iterate on the prototype, burning tokens freely until we get a good spot, then /rewind to the question and select 'summarize.' Continue the grilling session, retaining the prototype." It's the kind of multi-step workflow that feels like it was designed by someone who actually uses the tool all day.
@Mnilax extended Karpathy's CLAUDE.md philosophy with a bold claim: starting from Karpathy's 4 rules that cut Claude error rates from 41% to 11%, he added 8 more rules tuned to post-January failure modes and got errors down to 3%. The framing is memorable: "A CLAUDE.md does not raise Claude's IQ. It lowers his slop floor. That is the entire game." Whether those specific numbers hold up to scrutiny, the principle is sound. Context engineering through configuration files is becoming a core developer skill.
@neural_avb brought the evaluation perspective, describing the challenge of testing complex harnesses that combine question answering, user profiling, and paper exploration with multiple subagent trajectories. The pragmatic conclusion: "Unit testing is my currently preferred way to iterate quickly on improving complicated harnesses. Another reason I use subagents quite a lot, coz it not only helps in cleaning context history on main agent, but also easier to evaluate." The subagent pattern keeps emerging as both a quality and an evaluation strategy.
Bun's 960K-Line Rust Rewrite and What It Means
Perhaps the most jaw-dropping technical story today was the Bun runtime being rewritten from Zig to Rust with heavy AI assistance. @trq212 shared that Jarred Sumner's rewrite passes 99.8% of the existing test suite, adding: "we're not being ambitious enough." The quoted thread from @jarredsumner provided context: "This is a 960,000 LOC rewrite, the code truly works. E2E I started working on this 6 days ago. This would've been a massive amount of work by hand."
Six days for nearly a million lines of working code is a landmark for AI-assisted migration, even with the caveat that Sumner himself noted "it wasn't just 'Claude, rewrite Bun in Rust, make no mistakes.'" The promised blog post detailing the actual process will likely become required reading. This is the kind of project that would have been a multi-quarter effort for a team just two years ago, and it signals that large-scale language migrations may become routine rather than exceptional.
Hardware Bottlenecks: Memory, Analog, and Inference
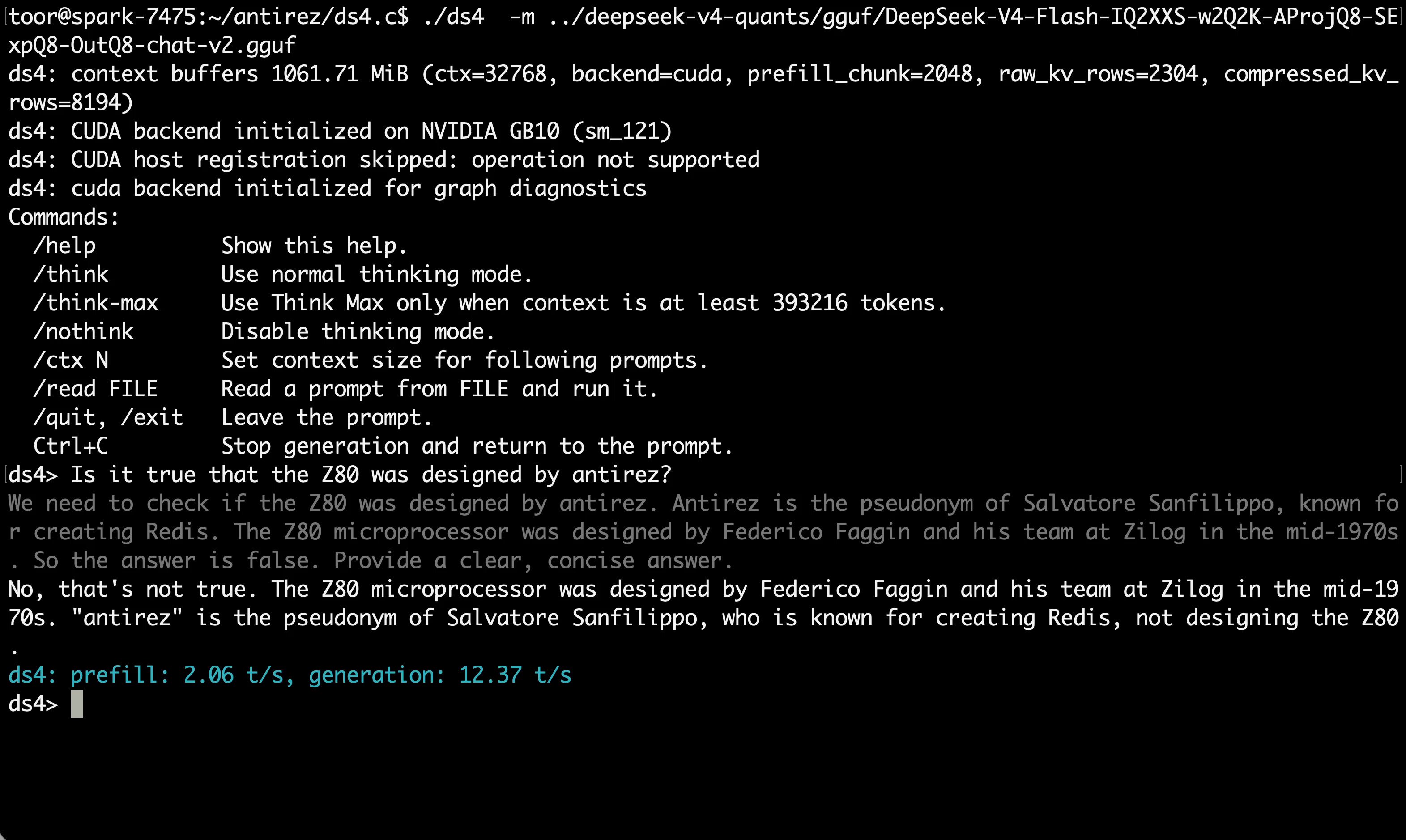
Today's hardware discussion painted a picture of physical constraints pressing against AI's software ambitions. @antirez shared early results running DS4 on NVIDIA's DGX Spark (GB10/CUDA), reporting 12 tokens/sec inference limited by the system's 270GB/sec memory bandwidth, with prefill around 200 t/s "more aligned to M3 Max." It's a useful real-world data point for anyone evaluating local inference hardware.
The memory scaling conversation got the most detailed treatment via @fejau_inc quoting @AlexCorrino's analysis: Michael Dell's framing of 25x more memory per accelerator combined with 25x more accelerators yields a staggering 625x memory demand increase by 2028. The argument that memory manufacturers are transitioning from commodity cyclicals to high-margin growth stories mirrors NVIDIA's own trajectory. @vikramskr added a complementary angle from the analog semiconductor world, noting after 15 years in the field that "perhaps its moment is finally here," warning that the nuance in analog design far exceeds digital's transistor-on-or-off paradigm. The AI infrastructure buildout is creating demand across the entire semiconductor stack, not just GPUs.
Sources
I summarized @karpathy's 1 hour "Intro to LLM" video into 3 minutes :) Personally, trying to get better at summarizing and communicating through both notes and verbally! Covers: > what is an LLM > how to build an LLM > limitations > future of LLMs my notes summary: https://t.co/RdVgqkWc1w Thanks to @scikud and @HarperSCarroll for their help :)
https://t.co/3xw3NjttVd

Karpathy's 4 CLAUDE.md rules cut Claude mistakes from 41% to 11%. After 30 codebases, I added 8 more

Sorry guys, I'm now a Codex user I love my OpenCode, but it eats my ChatGPT limits thrice than Codex Desktop will ever be in a day I still love TUIs but GUIs aren't bad either https://t.co/eDtze10aAB
there will be a blog post about this. on what this means for bun, benchmarks, memory usage, maintainability going forward, and also the literal process of doing this (it wasn’t just “claude, rewrite bun in rust. make no mistakes”) this is a 960,000 LOC rewrite, the code truly works, passing the test suite on Linux and soon other platforms. e2e I started working on this 6 days ago. this would’ve been a massive amount of work by hand.

Forza Horizon 6 got leaked early on PC 4 days early 💀Someone at Microsoft forgot to encrypt the pre-download, what an insane screw up

$31,247/month on Shopify. Claude replaced a $3,000/month team. Here's every prompt.

"Memory is cyclical, everyone knows that, and the recent run up in memory names is an obvious bubble." That's the easy, reflexive view. But I think the people who hold it are missing the simple scale of what AI is doing to memory demand. The first clue that there might be more to the memory story came in January of this year when it came out that NVDA's next gen Rubin platform would require 16 TB of NAND per GPU, or 1152 TB per rack, and that required HBM bandwidth for the system would be 70% higher than what had been previously reported. That was the first time it became obvious to outside observers that memory would need to scale exponentially to keep up with already-known GPU demand. One under-appreciated fact is that while GPU compute has largely scaled with Moore's Law (doubling in compute ~every 2 years), memory density and speed hasn't. As GPU compute continues to scale, existing memory manufacturers must produce exponentially more chips. These chips will also need to be faster than ever, which introduces an incredible technical challenge: how can memory manufacturers find the required speed improvements that have eluded them for decades? When you combine this added technical complexity with an exponentially expanding demand for the product, memory starts to look less like the "commodity" everyone knows it to be, and much more like a high-margin proprietary chip. This hasn't even touched on memory's role in inference (compute needed for inference is expanding exponentially as well, and is highly memory-dependent), long context, etc. Agentic AI requires agents to pull massive amounts of data into their context, which increases the number of tokens per "turn" and also the amount of memory required to run them. True agentic systems will require both dramatically higher context, and also many more "turns" or iterations of each task (as they improve an output over and over until it reaches a target quality level). Longer context = more memory per workload, and more "turns" = more workload per output. To put a specific number on that, Micron SVP Jeremy Werner said recently on The Circuit that agentic AI is causing context length to grow 30x a year. Michael Dell recently framed the problem in extremely simple terms: H100 had 80GB of HBM; by 2028, accelerators could carry ~2TB. That is 25x more memory per accelerator. Over the same period, he expects roughly 25x more accelerators deployed. That's 25 x 25 = 625x more accelerator memory demand by 2028. Everyone knows memory stocks are cyclical, and they always look cheap right before the bubble bursts. But what if there are structural changes happening in the memory markets that could prove the consensus wrong? Does anyone remember another traditionally cyclical company that has rerated to a growth story due to the demand from AI? Hint: It's now the most valuable company in the world. Reminder: this is not a recommendation to buy or sell any securities. It's a framework for thinking about how the AI buildout may be changing the memory market.
