Kimi K2.6 Challenges Claude on Benchmarks as Developer Tooling Fragments Across Agent Harnesses
The AI developer ecosystem is fragmenting across agent harnesses, security scanners, and LLM provider abstractions, while Kimi K2.6 emerges as a serious open-weights competitor to Claude. Meanwhile, the fine-tuning community pushes toward Expert Language Models, and practical debates about testing strategies and AI tool complexity dominate developer discourse.
Daily Wrap-Up
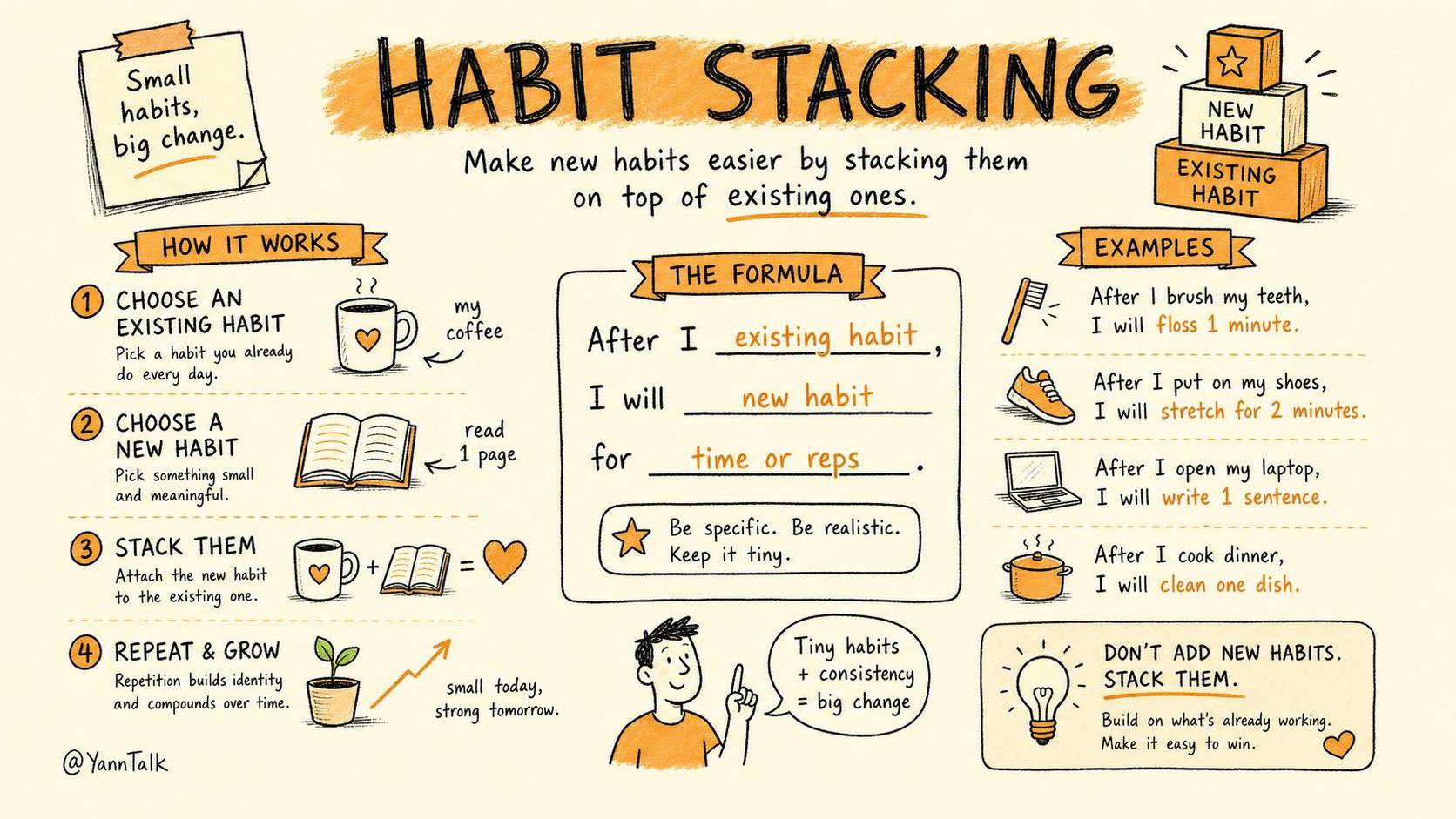
The conversation today felt like a community wrestling with the growing complexity of its own tools. On one side, you have developers like @aschmelyun openly wondering whether skills, MCP servers, and multi-agent orchestrations are worth the overhead when simple prompting gets the job done. On the other side, @garrytan is publishing frameworks for "meta-meta-prompting" that turn a 162-page book into 30,000 words of personalized analysis, and @tobi's "River" concept is spawning corporate clones like "Single Brain" at marketing agencies. The gap between AI power users and practical AI users is widening, and neither camp is wrong.
The model landscape got more interesting with Kimi K2.6 making noise as a genuine open-weights competitor. Running 300 sub-agents across 4,000 simultaneous steps with 12 hours of autonomous execution is the kind of capability that makes closed-model pricing feel steep. Combined with @cjzafir's report of fine-tuning Qwen 3.5 4B models to 98% accuracy and beating second-tier frontier models in niche tasks, the message is clear: the era of "just use the biggest model" is giving way to purpose-built, cost-efficient alternatives. The most entertaining moment was probably @elder_plinius putting AI water usage in perspective by calculating that four quarter-pound burgers consume as much water as decades of daily ChatGPT use, which is either reassuring or a damning indictment of beef production, depending on your priorities.
The most practical takeaway for developers: if you're building anything that touches multiple LLM providers, watch the opencode repo's packages/llm library closely, as @thdxr and team are building a provider abstraction layer born from real-world pain at scale. And if you haven't set up automated security scanning with something like Vercel's deepsec, @tdinh_me's experience of finding 30+ legitimate security issues for $70 in tokens suggests it's one of the highest-ROI uses of AI available right now.
Quick Hits
- @AnhPhuNguyen1 launched Mira, a face-worn AI device that captures conversations for hyper-personalized AI interactions. Wearable AI keeps trying to happen.
- @_bschmidtchen and @reactorworld previewed real-time world models generating interactive environments on low-latency infrastructure. Early but ambitious.
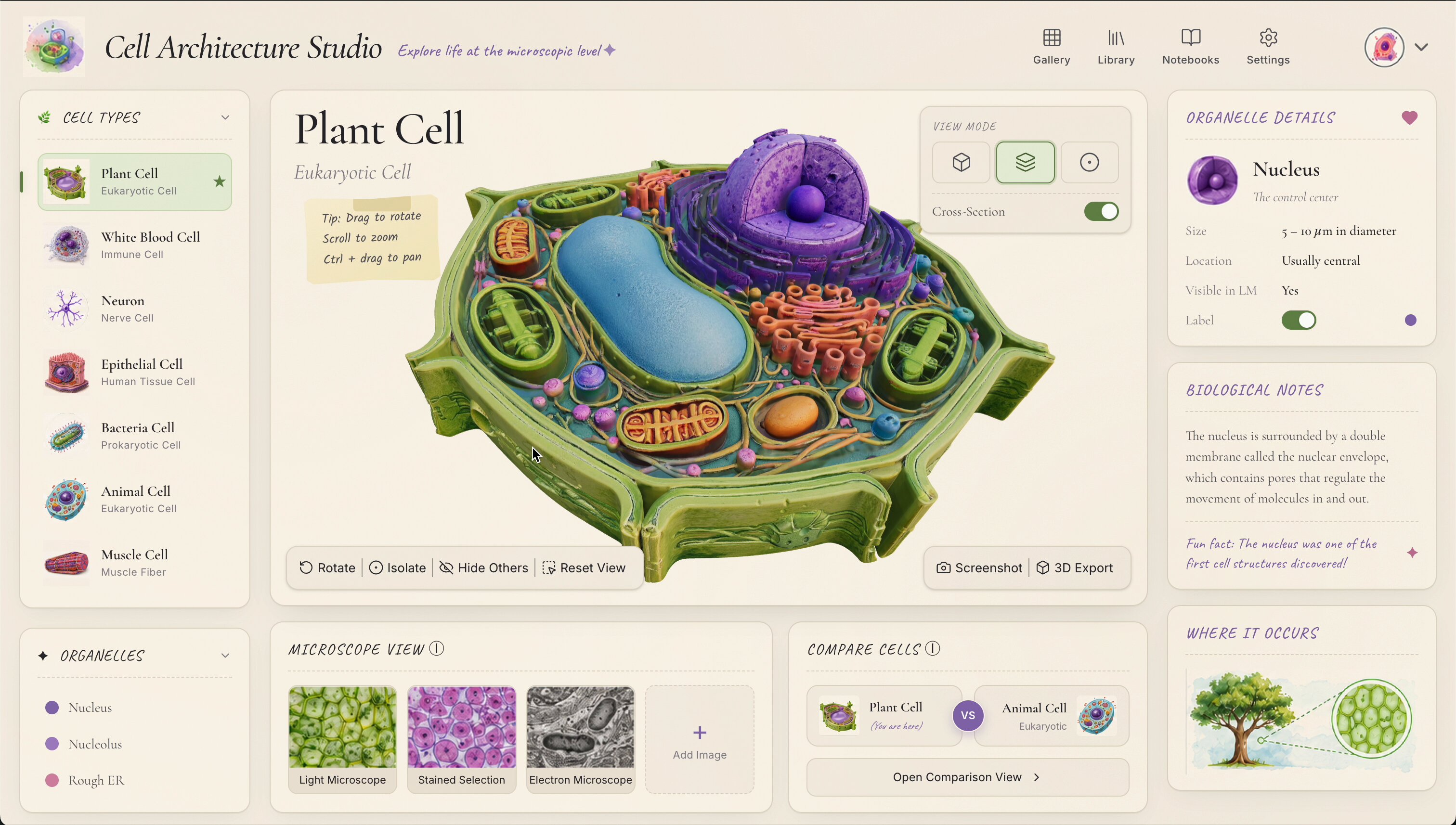
- @DilumSanjaya built interactive 3D biological structure explorers using GPT Images 2 for design and Gemini 3.1 Pro for code, showcasing multi-model workflows for educational apps.
- @damianplayer highlighted the Volonaut Airbike by Polish engineer Tomasz Patan, a jet-propelled bike hitting 124 mph with no propellers. "We got the Oppressor MK2 before GTA 6."
- @Supermicro promoted AI Factory infrastructure with NVIDIA, continuing the drumbeat of enterprise-scale GPU deployment.
- @nexudotio released Open Design, an open-source tool that converts Markdown into styled HTML pages and videos, riffing on the "unreasonable effectiveness of HTML" with Claude Code.
- @Howaboua shipped a cross-platform
apply_patchtool compiled from Codex's codebase as an npm package for the Pi ecosystem.
- @TheAhmadOsman hosted the first Local AI Get-Together, reporting a 4+ hour session covering GPUs, open weights, inference engines, and homelabs. The local AI community is building real momentum offline.
AI Agent Tooling Hits an Inflection Point
The agent ecosystem is maturing fast, but the growing pains are visible. This week saw multiple efforts to tame the complexity that comes with running AI agents in production. Vercel open-sourced deepsec, a CLI-first security harness designed for large-scale repos with sandbox-based scaling and pluggable coding agents. @tdinh_me gave it a real-world test and came away impressed:
> "Just tried this in my codebase, burned ~$70 worth of tokens and resulted in 30+ PRs, all non-critical but totally legit security issues."
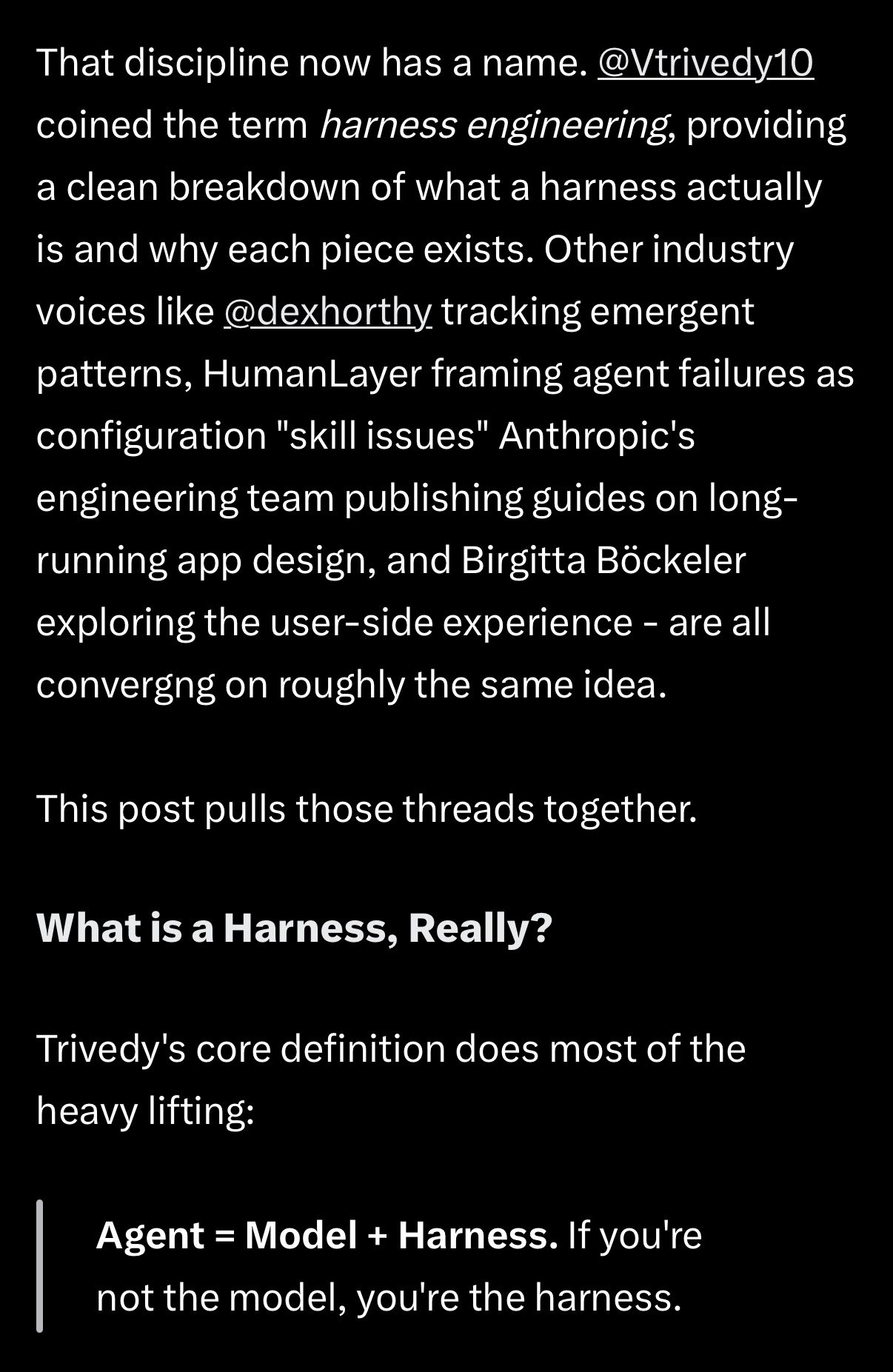
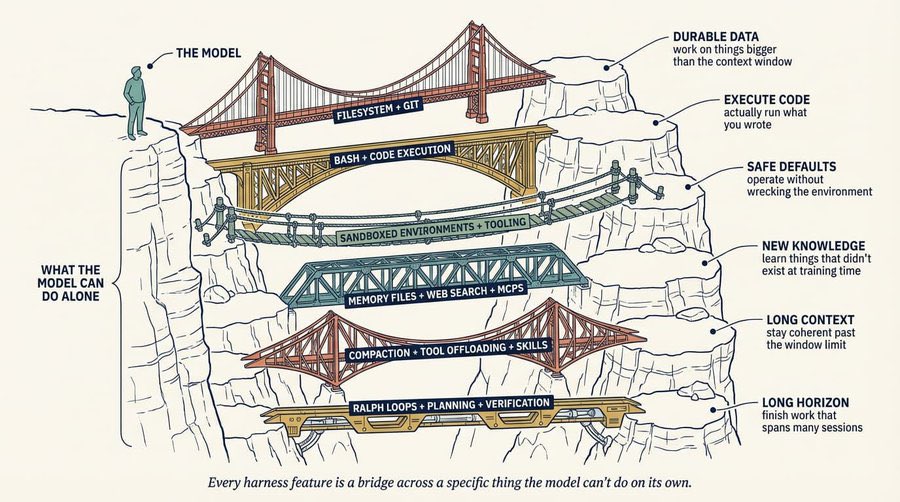
That's a remarkable signal-to-cost ratio for automated security scanning. Meanwhile, Google's @addyosmani published a piece on "Agent Harness Engineering" that @Vtrivedy10 praised for its shared mental models with the LangChain team, noting "the visuals in here are pretty sick, image gen models are so good now!" The convergence between how different teams think about agent architecture suggests the field is starting to coalesce around common patterns.
On the infrastructure side, @thdxr announced work on a provider abstraction library in the opencode repo, prompting @0xSero to vent about the current state of affairs: "I cannot begin to explain the pain I have suffered dealing with all the provider specific insanity." The fact that every agent framework has to independently solve LLM provider quirks is a clear sign the ecosystem needs shared primitives. The most interesting tension, though, comes from @aschmelyun, who admitted to feeling like he's "missing out" by not using skills, MCP, or multi-agent orchestrations, then immediately questioning why he'd change when simple prompting feels "fast and accurate." Not every developer needs the full agent stack, and that's a healthy realization for the community to internalize.
The Expert Language Model Thesis Gains Ground
The frontier model race is being flanked from below, and the results are striking. @cjzafir reported fine-tuning Qwen 3.5's 4B model to 98% accuracy with minimal quality loss even at Q4 quantization, using a stack of Codex 5.5 as orchestrator, DeepSeek v4 Pro for example generation, and Unsloth for the tuning recipe. The entire pipeline ran for 8-9 hours across seven phases, from dataset creation through quantization and evaluation. The punchline was pointed:
> "It's now that we move towards ELMs (Expert Language Models) rather than running everything on LLMs. You don't use Porsche everywhere! Build Camry for companies and make $."
This resonates with a broader trend toward right-sizing models for specific tasks rather than defaulting to the most powerful (and expensive) option available. On the inference side, @badlogicgames amplified @antirez's work running DS4 on a DGX Spark at 12 tokens/sec, noting the memory bandwidth limitations of the GB10/CUDA system. Even at that modest speed, the fact that serious models are running on increasingly accessible hardware reinforces the ELM thesis: you don't always need cloud-scale compute.
Kimi K2.6 Disrupts the Model Leaderboard
Perhaps the most consequential development today was the growing buzz around Kimi K2.6, the Chinese model that's been flying under the radar. @kirillk_web3 laid out the case with characteristic directness:
> "Drop K2.6. 300 sub-agents. 4,000 steps simultaneously. 12 hours continuous execution. Zero human oversight. Beats Claude Opus 4.6 on SWE-Bench Pro. Open weights. Free."
The claim that Vercel saw a "50%+ improvement on our benchmark" adds institutional credibility to what could otherwise be dismissed as hype. The open-weights aspect is the real story here. If K2.6 genuinely matches or exceeds Claude Opus 4.6 on coding benchmarks while being freely available, it shifts the economics of every AI-powered development workflow. The model's ability to run 300 sub-agents autonomously for 12 hours represents a different paradigm from the interactive, human-in-the-loop approach most Western tools favor. Whether that level of autonomy is desirable or safe is a separate question, but the capability gap between open and closed models continues to narrow.
Meta-Prompting and the Personalization Frontier
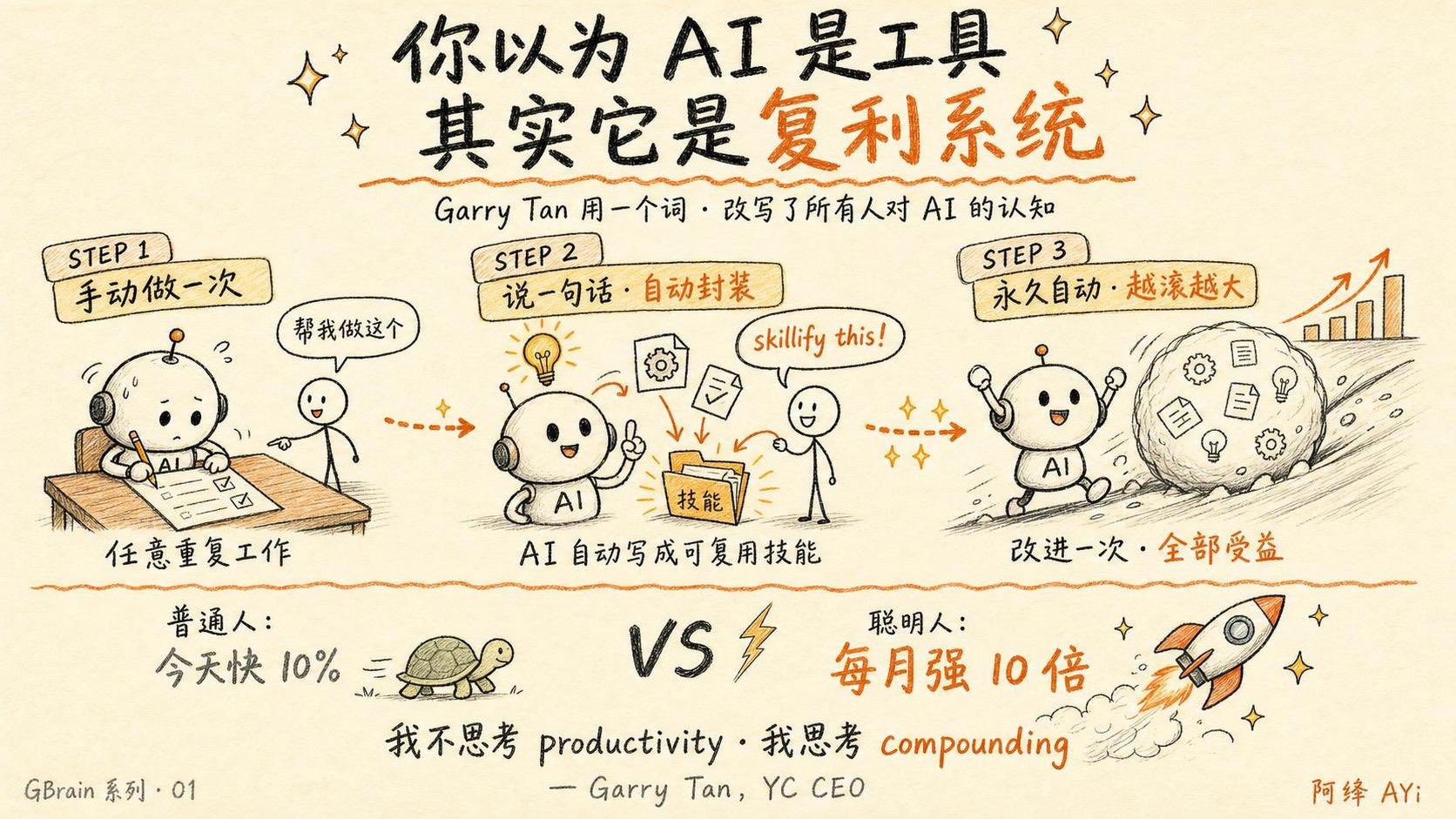
@garrytan's piece on "Meta-Meta-Prompting" generated significant discussion, with @AYi_AInotes calling it "the most important AI article I've read this year." The showcase example, "Book Mirror," takes a 162-page book and produces 30,000 words of personalized analysis in 40 minutes by mapping every author insight against the reader's own life context, from family history to therapy notes to professional conversations.
> "It's equivalent to the book's author spending two full days in one-on-one conversation with you, discussing only the parts most relevant to your life. More than 50x more efficient than a $300/hour therapist."
This goes well beyond standard RAG, which retrieves relevant chunks but doesn't synthesize them against a deep personal context. The implication is that AI's real value multiplier isn't in answering questions but in creating deeply personalized interpretive layers over existing knowledge. @ericosiu echoed this at the organizational level, describing how his marketing company built "Single Brain," inspired by Shopify's River concept, to unify ads, SEO, creative, and analytics into a single AI-powered workflow. "The moment the individual sees it, they can't ever go back to the old way of working." The personalization thesis is scaling from individual productivity to team-level acceleration.
Software Engineering Adapts to AI-Generated Code
Two posts captured the evolving relationship between traditional engineering practices and AI-assisted development. @thdxr argued that thoroughly decoupled test suites are "more useful than ever," pushing the idea to its logical extreme: "decoupled to the point where you're testing your backend by executing the frontend." When AI generates implementation code, the test suite becomes the source of truth, and the more independent it is from implementation details, the more confidently you can let agents rewrite code.
@QuinnyPig took a different angle on AI code quality, responding to the "AI code is crap" narrative by posting an example of spectacularly bad human-written code with the dry observation that human engineers aren't exactly setting a high bar. The implicit argument is compelling: AI code quality should be measured against the realistic baseline of what humans actually produce, not against some idealized standard that most codebases never achieve.
AI's Real-World Accountability
Tesla's full self-driving mode failed a user-conducted test involving a child mannequin emerging from behind a school bus, hitting the mannequin despite a visible stop sign. @ww3mediaa shared the video, which resonated as a reminder that AI safety isn't just an abstract alignment problem. Meanwhile, @elder_plinius injected some perspective into the AI environmental impact debate, calculating that 1 kg of beef uses roughly the same water as 3 to 47 million ChatGPT queries depending on per-query estimates. The comparison reframes AI sustainability concerns without dismissing them, suggesting that dietary choices dwarf AI's water footprint by orders of magnitude. Both posts highlight how AI's real-world impacts, whether in safety-critical systems or environmental accounting, deserve rigorous measurement rather than reflexive takes.
Sources



Using Claude Code: The Unreasonable Effectiveness of HTML
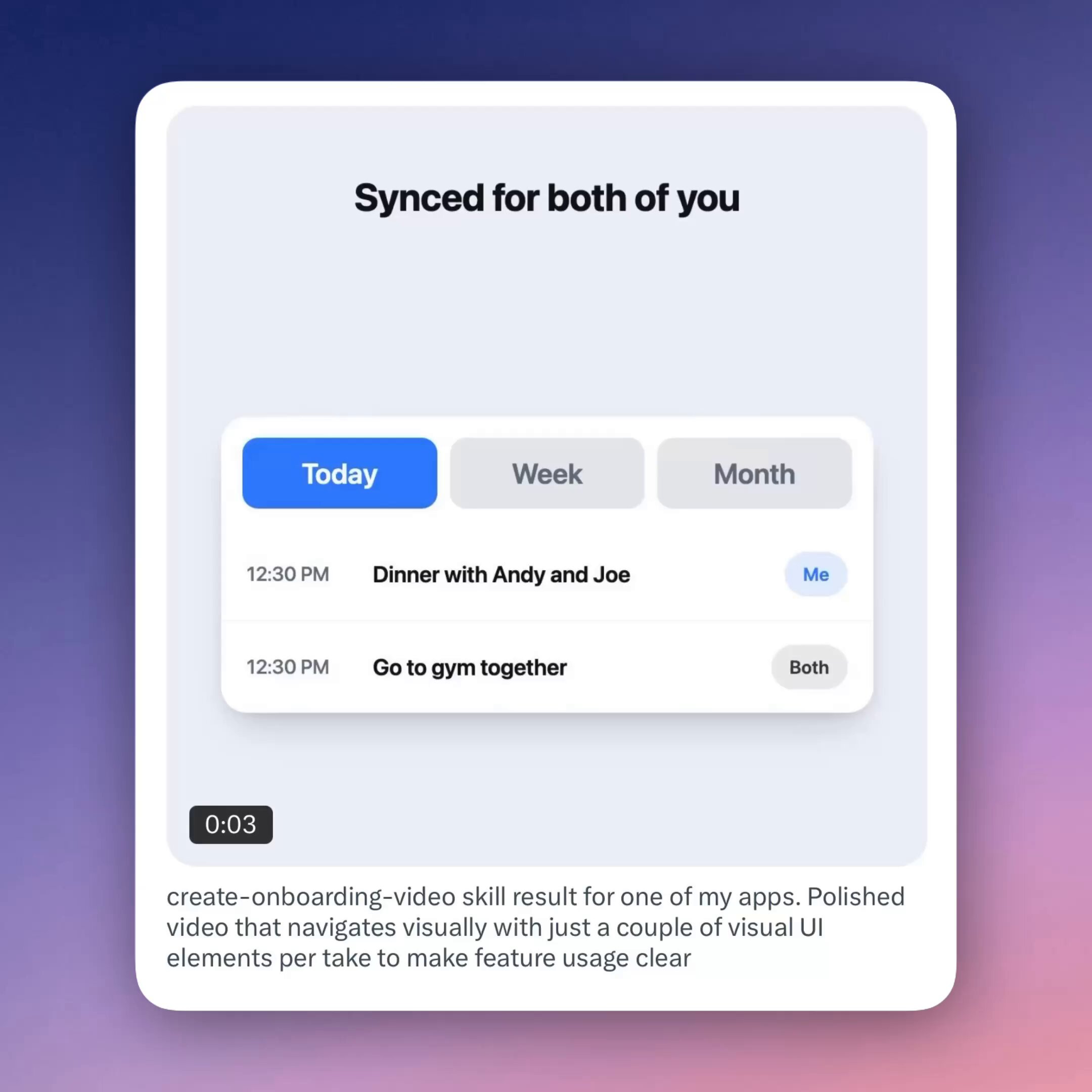
Drop your screenshots and this Claude skill turns them into animated onboarding

Meta-Meta-Prompting: The Secret to Making AI Agents Work


Kimi K2.6: Complete A–Z Guide to the Chinese AI Nobody Saw Coming
Agent Harness Engineering
Learning on the Shop floor

this is a big deal, on the order of Kelsey Hightower’s “Kubernetes The Hard Way” and probably all ai engineers should go thru this once mostly i advocate “just in time learning”, but this is one scenario you want “just in case” https://t.co/Ny7kTvwBr3
we're working on a library to abstract over all the llm providers there's very few teams that have dealt with the quirks between providers at the scale we have it's written in effect but will also have a vanilla api progress is in the opencode repo under packages/llm
Introducing deepsec, an open source coding security harness. • CLI-first • Sandbox-based scaling • Pluggable coding agents • Designed for large-scale repos • Use AI Gateway or your own subscription After months of successful internal use, we put it to the test on some of the largest open source codebases. https://t.co/sPxZ6izJVV
