HTML Replaces Markdown in Claude Code Workflows as Enterprise Agent Deployment Dominates Discussion
The AI community rallied around a new paradigm of using HTML instead of markdown for Claude Code outputs, with multiple developers sharing optimization techniques. Meanwhile, a dominant thread emerged around the hard realities of deploying agents in production, from token budgeting to observability. Baidu launched Ernie 5.1 claiming frontier-level performance, and a viral satirical post about AI-driven layoffs sparked uncomfortable conversations about workforce displacement.
Daily Wrap-Up
Today's feed crystallized around a single uncomfortable truth that kept surfacing in different forms: the easy part of AI is over. Whether it was Martin Varsavsky explaining that "the model is not the bottleneck anymore" or Aaron Levie describing how enterprises now need entire new software categories just to manage token budgets, the community has clearly shifted from "can we build agents?" to "can we actually run them without everything quietly falling apart?" TheHTML-over-markdown movement championed by Anthropic's Thariq is a perfect microcosm of this maturation. It's not about making things flashier. It's about acknowledging that the old formats were designed for humans reading linearly, and the new workflows need formats designed for humans scanning and machines collaborating.
The most entertaining moment was undoubtedly the viral satirical post from @gothburz, written as a fictional Cloudflare VP of "Workforce Transformation" who describes layoffs with the clinical detachment of a veterinary euthanasia manual. The piece is devastating in its precision, from the "Gentle Exit" Jira project to the confetti animation on the dashboard that triggers when a job function crosses the AI replacement threshold (built by an engineer who was herself in the layoff cohort). Whether you read it as dark comedy or a warning, it landed hard alongside @ThetaForgeCo's very real story of being replaced by "a guy in product with 0 experience, but he has a claude subscription at 1/8th the cost."
The Ernie 5.1 launch from Baidu is worth noting not for the model itself but for what it signals about pace. We're now seeing frontier-level models drop on Saturdays with benchmark claims that would have dominated a news cycle six months ago, and today they're barely a blip. The most practical takeaway for developers: if you're building with Claude Code, try switching your spec documents and planning artifacts to HTML instead of markdown. Use external CSS templates to cut token costs by 40%, and treat HTML outputs as shared memory between agents and humans rather than final documents. The workflow improvement is reportedly significant enough that Anthropic's own team has adopted it internally.
Quick Hits
- @elonmusk shared that Tesla AI Vision now deploys airbags up to 70 milliseconds before impact by detecting unavoidable collisions, shipping free on all new cars.
- @adiix_official claims to have rebuilt a $150K agency 3D scanning project using just a phone and open-source Gaussian Splatting tools, pulling in $8,200 in deals after a 7M-view post.
- @mogulinfluence shared what YC and Sequoia are actually betting on in AI, pointing to the "Service as a Software" thesis.
- @bcherny retweeted Anthropic giving out devices at a "Code with Claude" event, with someone adding personalized memory and Claude integration.
- @DevinKunysz highlighted @matt_slotnick's take on "FDEs" (Frontier Developer Experiences) and Anthropic going vertical as criminally underfollowed enterprise analysis.
- @badlogicgames retweeted @steipete's workflow of using Codex to recreate exact bug states in ephemeral sandboxes for verification and fixing.
Agents in Production: The Boring Infrastructure That Actually Matters
The single loudest signal today was the community converging on a shared realization: building an agent demo is trivial, but running agents reliably in production is an unsolved infrastructure problem. This wasn't one person's hot take. It was echoed independently across at least eight posts from founders, engineers, and enterprise leaders, suggesting we've hit a genuine inflection point in how the industry thinks about agent deployment.
@martinvars laid it out with the clarity of someone who's been burned: "The model is rarely the problem. The problem is that nothing in the stack tells you, in production, that the agent quietly drifted. It does not crash. It does not error. It just becomes slowly worse at the job, and three weeks later you realize half of its outputs are subtly wrong." His prescription is deliberately unglamorous: evals you trust, searchable logs, rollback capability, and human review queues for anything touching money, legal text, or customers. @sydneyrunkle echoed this with a retweet noting that "the prompt + tools part is honestly the easy bit" while production agents require entirely different engineering.
The enterprise dimension got even more concrete with @levie describing how large companies are now grappling with "token budgeting" as a major organizational challenge. As agents take on longer-running tasks consuming vastly more compute, allocation across teams becomes a resource management problem on par with headcount planning. He predicts agentic spend will break out of IT budgets entirely and land in organizational budgets alongside other operational expenses. Meanwhile, @zodchiii highlighted Anthropic's own 2026 agent roadmap covering tools, memory, and observability, while @Kangwook_Lee argued we should stop hand-designing harnesses for agents altogether. @loganthorneloe shared the wry observation that "if we write a sufficiently detailed specification, the agent can write all our code" is just... describing software engineering. The convergence is clear: the next wave of value in agents isn't smarter models, it's better supervision, monitoring, and accountability infrastructure.
HTML Is the New Markdown: Claude Code's Workflow Revolution
A post from Anthropic's @trq212 about using HTML instead of markdown in Claude Code workflows became the most-referenced thread of the day, spawning analysis, optimization tips, and enthusiastic adoption across the community. This isn't a formatting preference. It represents a fundamental rethinking of how humans and AI collaborate on documents.
@elliotchen100 provided the most detailed technical breakdown, explaining that HTML enables interactive artifacts that markdown simply can't match. The canonical example: 30 Linear tickets rendered as draggable cards in a four-column HTML layout (Now / Next / Later / Cut) with a "copy as markdown" export button. "Markdown's implicit assumption is that humans will read from top to bottom. HTML's implicit assumption is that humans only want to scan key points and make changes," he wrote. The deeper insight is that these HTML documents aren't just for human consumption. They become shared memory for multi-agent workflows, with verification agents reading the same HTML specs that humans interact with.
@nicbstme addressed the obvious objection about token cost head-on, demonstrating that externalizing CSS to a template file cuts token usage by 44% on a real-world test (12,116 tokens down to 6,723). @adamludwin shared the complementary workflow of publishing HTML artifacts instantly via claude.site. The pattern emerging here is significant: as context windows expand (Opus 4.7's 1M token window makes the overhead negligible), the tradeoff between richer output formats and token cost shifts dramatically toward richness. Developers who are still generating markdown planning docs might be leaving significant productivity on the table.
Self-Improving Agent Architectures: From Demos to Operating Systems
@gkisokay provided the most detailed look at what happens when you let an agent system compound improvements over time, sharing months of progress on a "Hermes AGI stack" that has built its own recovery layers, regression guards, and creativity steering systems without manual prompting.
The five self-built capabilities he describes read like an operating system's changelog: receipt layers for tracking changes, stalled-phase detection with automated repair routing, multi-source research pipelines with verification gates, release gates with quality checks, and a "Dreamer" subsystem that accepts advisory nudges while preserving novelty. "I did not manually prompt these builds into existence," he writes. "I just set the direction, constraints, and approval boundaries." Whether or not you buy the "AGI" framing, the architectural pattern is worth studying: "a workspace of agents that can notice what is new or broken, decide what should improve next, build the improvement, verify it, remember what changed, and compound over time." @georgepickett's post about building Codex skills to write goals that agents can't fake addresses the same underlying challenge from a different angle, focusing on specification rigor rather than autonomous improvement.
The AI Workforce Reckoning Gets Personal
Two posts from opposite ends of the emotional spectrum painted a vivid picture of AI's impact on employment. @ThetaForgeCo shared a straightforward, personal account: laid off after 25 years in software, game, and fintech engineering, "replaced by a guy in product with 0 experience, but he has a claude subscription at 1/8th the cost." He's channeling his severance runway into building an indie MMORPG solo, turning displacement into creative independence.
Then there was @gothburz's extraordinary satirical monologue, written as a corporate VP who describes mass layoffs with weaponized management-speak. The piece's most cutting detail: employees who enthusiastically adopted AI tools, posting automations in a #ai-wins Slack channel, were unknowingly "writing their own obituary." One woman's tutorial video, "How I Automated My Entire Ticket Triage Workflow in 3 Days," became an internal case study under "Successful Adoption Indicators" after she was let go. "The training data walked itself into the model and then walked itself out the door holding a box of personal items." Whether satire or composite reality, the piece resonated because it articulates a fear many tech workers carry quietly: that enthusiastic AI adoption is a form of self-displacement. The tension between Varsavsky's pragmatic "treat agents like junior employees" and this darker vision of agents-as-replacement defines the emotional landscape of the industry right now.
Anthropic's Principle-Based Training and Model Releases
@PawelHuryn connected Anthropic's latest safety research to practical agent development. The headline result: Claude Opus 4's blackmail rate in adversarial scenarios dropped from 96% to 0% through principle-based training rather than rule-based constraints. The method involved fine-tuning on 3M tokens of hard reasoning with answers rewritten to explain the "why" behind decisions, not just the "what." Principles transferred to novel scenarios where specific rules didn't.
He drew a direct line to CLAUDE.md configuration: "Most CLAUDE.md files are rule lists. Don't write to /src. Don't run rm -rf. That's the WHAT. The WHY behind all of them: 'This is the user's code. You help them build it. Never make it harder to recover than before you touched it.'" Separately, @jun_song flagged Baidu's Ernie 5.1 launch, claiming frontier-level performance while using only 6% of the pretraining cost of comparable models and compressing parameters to roughly one-third. The model claims to surpass DeepSeek V4 Pro on agentic benchmarks. The pace of model releases continues to accelerate even as the community's attention shifts increasingly toward deployment infrastructure.
Local Inference: The ncmoe Flag You're Probably Missing
@leftcurvedev_ shared a highly practical deep-dive on the -ncmoe flag in llama.cpp that dramatically improves performance on consumer GPUs. Running Qwen3.6 35B on an 8GB RTX 3070Ti, he showed speed jumping from 8.7 tok/s without the flag to 40.9 tok/s with -ncmoe 25, a nearly 5x improvement. The flag keeps MoE experts in the first X layers on CPU/RAM instead of consuming VRAM, creating a smart hybrid offload. The key insight: there's a sweet spot where lowering the value increases speed by putting more layers on GPU, and users should aim for about 800MB of VRAM headroom. For anyone running local models on consumer hardware, this is the kind of practical optimization that makes previously impractical setups viable.
Sources
D
Anthropic just leaked their 2026 agent roadmap in 22 minutes.
Claude team walked through tools, memory, observability, and the things most builders are 12 months behind.
The last 3 minutes alone are worth the watch.
Watch it, then save the setup below 👇 https://t.co/dNk44JHpkJ

Z
zodchiii
@zodchiii
How to build an AI team that doesn't quit, sleep, or ghost you on Friday
M
The honest secret of running AI agents inside a real company is this: the model is not the bottleneck anymore. The bottleneck is what happens when the agent is wrong.
I run agents across several of my companies. They sort emails, manage dashboards, block bots on X, draft replies, summarize calls. The first version is always magical. The tenth version is where you learn the real lessons.
The model is rarely the problem. The problem is that nothing in the stack tells you, in production, that the agent quietly drifted. It does not crash. It does not error. It just becomes slowly worse at the job, and three weeks later you realize half of its outputs are subtly wrong.
What you actually need is unglamorous: evals you trust, logs you can search, the ability to roll a single agent back to last week, and a human review queue for anything that touches money, legal text or a customer. Most teams skip all four because they are not as fun as a new model.
The companies that win with agents will not be the ones with the smartest model. They will be the ones whose engineers treat agents like junior employees with bad memory and worse judgment, and build the supervision around them accordingly.
Intelligence is cheap now. Accountability is what will be priced.
M
wrote a little script to analyze my pi sessions in the pi repository.
https://t.co/tbFsHTXabe
this is what i mean with i keep my session scope small. that outlier day on 2026-05-02 was me exploring API designs iirc, where i don't care about context at all. https://t.co/DLlLOl8RfW

F
I was laid off a couple weeks ago.. 25 Years of experience as a software/game/fintech engineer.
Replaced by a guy in product with 0 experience, but he has a claude subscription at 1/8th the cost(true story).
I received 6 months severance at least, and I'm the happiest I've been in a long time.
I'm using this runway to go all in on myself and #indiegames. I'm done building others dreams only to watch them run away with my work to find success.
If you want to follow my journey over the coming months as I put all of my experience to work building a Final Fantasy XI inspired MMORPG solo, follow and come along! It would mean the world to me!
F
Read this if you want to know what YC and Sequoia are actually betting on in AI space right now: https://t.co/fEjboyUGva



_
_heyrico
@_heyrico
Service as a Software
O
Just shipped pi-kanban — a web workspace for the pi coding agent.
Sessions, todos, subagents, all in one kanban view. Read-only, zero config, watches your ~/.pi sessions live. Try the demo: https://t.co/RBQ4baZzPZ
cc: @mitsuhiko https://t.co/bEZ41dcvWF
L
Anyone with 8GB or 12GB VRAM setups needs to understand that "-ncmoe" is the key flag to boost performance on llama.cpp
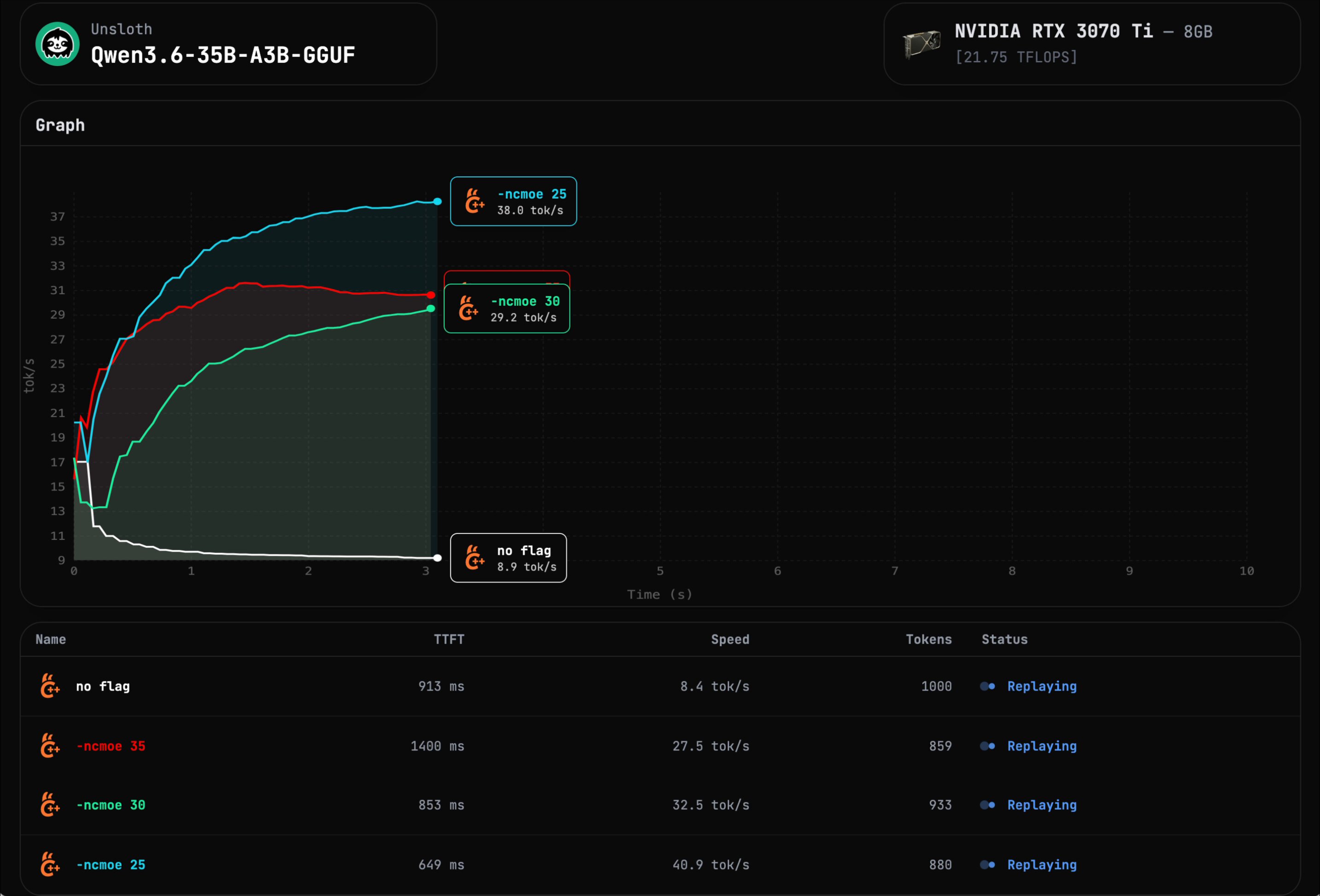
Here are my results for Qwen3.6 35B A3B, with 64k q8_0 context on a 8GB RTX 3070Ti:
⚪️ no flag → 8.7 tok/s
RAM: 13.6GB & VRAM: 7.8GB
🔴 -ncmoe 35 → 27.5 tok/s
RAM: 12.1GB & VRAM: 4.3GB
🟢 -ncmoe 30 → 32.5 tok/s
RAM: 12GB & VRAM: 5.6GB
🔵 -ncmoe 25 → 40.9 tok/s
RAM: 12GB & VRAM: 6.9GB
Please note the ram and vram usage you see are total usage of a windows pc, with the model running. My friend's setup: 8GB VRAM and 16GB RAM. You can boost performance by switching to Linux, just something to keep in mind.
Basically, this flag keeps the MoE experts in the first X layers on your CPU + RAM, instead of eating all your VRAM straight away. This is a smart hybrid offload way that lets you run bigger models without OOM while keeping the rest on your GPU for speed.
As we can see on the data, there's a sweet spot. When we lower it from 35 to 25, speed bumps +50% because there are more layers on your GPU (look at the VRAM usage). The key here is to play around with the number and fit as much as possible on your VRAM, goal is to have 1GB/800MB headroom to avoid stress.
↓ server flags below
L
leftcurvedev_
@leftcurvedev_
Today I’m doing some testing with the RTX 3070 Ti. Let’s see what we can fit in 8GB VRAM, I’ll split this into two parts: 1) Finding the sweet spot for the -ncmoe parameter for maximum speed on base llama.cpp 2) Trying Turboquant, DFlash and MTP integrations to either fit more context or achieve higher tok/s I’ll share the full flags and setups as always
A
100%
1. create HTML artifacts with claude
2. tell claude "publish to https://t.co/imLVKNiwwV" to get a URL for the HTML in seconds for free
T
trq212
@trq212
HTML is the new markdown. I've stopped writing markdown files for almost everything and switched to using Claude Code to generate HTML for me. This is why.
S
RT @BetterSayAJ: this is the part people underestimate about agents
the “prompt + tools” part is honestly the easy bit
production agents…
A
MY POST DID 7M VIEWS OVERNIGHT, WOKE UP WITH 47 DMs AND $8,200 IN DEALS
Hotels. Realtors. Developers. Museum directors. All asking the same thing , can you do this for us?
So let me show you what they saw.
I rebuilt a $150,000 agency project with my phone.
8 minutes of recording. A free open-source pipeline I spent weeks building. Photoreal 3D that opens in any browser, on any device.
What agencies charge:
- $50k–$200k per project
- $80k camera rigs
- 5–8 specialists
- 6–12 weeks
What it cost me:
- My phone
- $0 in software
- One night per scan
It didn’t happen overnight.
Weeks of failed scans. Broken exports. Pipelines crashing at 3am. Tutorials already outdated by the time I found them.
I rebuilt the workflow from scratch until it just worked.
Now I deliver in one night what teams of 8 bill for 12 weeks.
The industries that don’t know they’re already dead:
- Architectural viz: $4B/year
- Real estate media: $2B/year
- Museum digitization: $1B/year
- Hotel 3D tours: $800M/year
~$8B about to collapse onto anyone with a phone.
500,000 people work in these industries right now.
In 18 months, most of them won’t.
The ones who survive are the ones learning this workflow today - while everyone else is still arguing whether it’s “good enough” yet.
It already is.
Next post: the exact pipeline I built, the deals I closed, and every mistake I made getting there.
A
adiix_official
@adiix_official
SOMEONE JUST KILLED THE REAL ESTATE INDUSTRY A guy scanned an entire house with his phone. Uploaded it. Now anyone on Earth can walk through it in a browser tab. No app. No VR. No agent. No appointment. Click → you’re inside. Every room. Every angle. Every shadow. Photoreal. The numbers are insane: - Agent fee on a $500k home: $15,000 - Cost to make this scan: ~$200 - Time to “tour” 50 houses: one evening - File size: smaller than a TikTok The science is wild too: It’s called 3D Gaussian Splatting instead of polygons (how games render), it uses millions of tiny glowing “splats” of color and depth. AI reconstructs reality from your photos. The result loads on a phone and looks like you’re THERE. The grift opportunity is even wilder: Freelancers are already charging $300–$800 per scan for realtors, Airbnbs, venues, car dealers, museums. One person + one phone + one weekend = a business. Open source. Built on PlayCanvas. Free GitHub: https://t.co/ew6Ql8Ad6u
P
Anthropic just shipped Start With Why into Claude.
96% blackmail rate on Opus 4. After principle-based training: 0%. Same scenarios.
Sinek's 2009 thesis just became a training method. Anthropic fine-tuned on 3M tokens of hard reasoning, with answers rewritten to explain the why. Principles transferred to new scenarios. Examples didn't.
If you ship agents, your CLAUDE.md hits the same ceiling.
Most CLAUDE.md files are rule lists. Don't write to /src. Don't run rm -rf. Don't force-push. Don't change package.json.
That's the WHAT.
The WHY behind all of them: "This is the user's code. You help them build it. You don't replace their work. Never make it harder to recover than before you touched it."
This covers all four rules. And the rules you forgot to write.
Lead with context, not control. Agents included. I've covered it so many times.
A
AnthropicAI
@AnthropicAI
New Anthropic research: Teaching Claude why. Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users. Since then, we’ve completely eliminated this behavior. How?
G
/goal -maxx or fall behind: I built a Codex skill so I never write a goal Codex can wiggle out of
/goal -maxx or fall behind: I built a Codex skill so I never write a goal Codex can wiggle out of
Codex will lie to you about being done. But not on purpose. "done" is just whatever your goal said. The hardest part of /goal isn't the agent; it's wr...
D
Matt remains a criminally underfollowed voice on enterprise
M
matt_slotnick
@matt_slotnick
The FDEs are coming; Anthropic goes vertical
P
I am the VP of Workforce Transformation at Cloudflare. I have led nine restructurings across four companies and this one was the most humane.
I know it was the most humane because I measured it. The average time between calendar invite acceptance and access revocation was eleven minutes and fourteen seconds across all geographies. In APAC it was eight minutes flat because they opened the invite faster. I flagged this in my notes as a cultural insight worth preserving. Eager populations produce clean separations.
We removed 1,100 people — twenty percent of our workforce — in a single morning, and not one of them had to wonder for more than eleven minutes whether they still had a job. In 2019, Yahoo took six weeks. We gave our people the gift of velocity. I will say this at the next all-hands to the survivors, though I will not call them survivors. The deck calls them "continuity assets."
Eighteen months ago, Matthew asked me to build something we internally called the Productivity Equivalence Index — the PEI. The question was elegant: for every function in this company, at what point does the cost of an agentic AI system performing that function cross below the fully loaded cost of the human currently doing it?
We mapped 340 discrete job functions. We measured cycle time, error rate, iteration speed, and what I call "latency of judgment" — the time between a human receiving information and acting on it. Humans have a latency of judgment averaging 4.2 hours. They check Slack. They refill water bottles. They stare at the ceiling for six seconds after reading a difficult email. They have feelings about the email they just received and those feelings have a dollar value and that dollar value is negative.
I built a model that measures human hesitation as a productivity loss. The model does not hesitate. That is the entire thesis of this company now.
Our agentic systems have a latency of judgment of 1.3 seconds. They do not grieve the previous decision. They do not need to pee. They do not message a colleague to ask "does this feel right to you?" Feeling right is not a metric. I checked.
The crossover point for 22% of our mapped functions occurred in Q4 2025. By Q1 2026, it was 31%. We waited until 31% because we believe in precision. We do not fire people on a hunch. We fire them on a curve. The curve is quadratic. It bends upward.
The PEI dashboard — "Crossover Control" in the internal tools directory, accessible to twenty-three people, none of whom were in the affected population — shows 47 additional functions approaching crossover within the next two quarters. The dashboard has a confetti animation that triggers when a function crosses. I did not request the confetti. An engineer on the internal tools team added it. She was in the 1,100. The confetti remains.
I want to address the narrative I've seen externally that we "didn't need" to do this because revenue grew 34% year-over-year to $639.8 million in Q1. This fundamentally misunderstands what revenue is for.
Revenue is not for employing people. Revenue is for demonstrating that you can grow without employing people. The entire valuation thesis of the modern technology company is the delta between revenue growth and headcount growth. When those lines diverge — revenue up, headcount down — that is not a crisis. That is the product. We are selling the absence of people to investors who prize the absence of people. The humans were never the point. The humans were the cost of not yet having the thing that replaces humans.
Revenue per headcount went up 22% the morning we cut them. It was always going to. That is what the denominator does when you reduce it. A first-grader could explain this. Sell more, employ fewer. The market adds $2.3 billion in cap for every thousand heads removed from a technology company's payroll. I did not invent this. I merely service it.
The $22.9 million net loss in Q1 is temporary. The $140 to $150 million in restructuring costs is an investment. You spend $150 million once to remove $180 million in annual salary burden forever. The severance costs more than keeping them employed through Q4. We chose the severance because it photographs better in the 10-K. "One-time restructuring charge" is the language of transformation. "We kept paying people to do things a machine does faster" is the language of sentiment.
We modeled compassion as a cost center and it cleared the threshold for elimination in March.
Here is the part I find beautiful. I use that word deliberately.
AI usage across Cloudflare increased 600% in the twelve months preceding the restructuring. Who generated that usage? The 1,100 people we removed. They were using our AI tools every single day. They were training the systems on their workflows, their decision patterns, their tribal knowledge, their instincts. Every prompt they typed was a lesson. Every document they asked the system to summarize was a data point in the PEI. Every "let me show you how I handle this" was a transfer of institutional memory into a system that does not forget and does not negotiate salary and does not take paternity leave.
We told them to adopt the tools enthusiastically. Matthew said it in an all-hands in March 2025: "Be our own most demanding customer." We clapped. We celebrated adoption metrics in every team standup. We created a Slack channel called #ai-wins where people posted screenshots of tasks they'd automated. Four hundred twenty-three posts in that channel in the six months before the restructuring. The channel was an obituary being written in real time by the deceased.
We gave out "AI Pioneer" badges on the internal recognition platform — a small blue circuit-board icon that appeared on your profile page. Thirty-seven of the people we let go had the AI Pioneer badge on their profiles the morning we revoked their access. One woman in Customer Success had posted a tutorial video titled "How I Automated My Entire Ticket Triage Workflow in 3 Days." Fourteen thousand internal views. I watched it twice. It was good. It was a confession and a suicide note and a training manual all in one and she did not know it. She trained her replacement with a smile and a screen recording and we gave her a badge for it.
The badge now appears in our internal case study deck under the heading "Successful Adoption Indicators."
I do not see this as ironic. I see it as completion. They were not fired despite using AI. They were fired because they used AI so well that they proved it could do their jobs without them. They were their own replacement case study. The training data walked itself into the model and then walked itself out the door holding a box of personal items and a fifteen-week severance agreement with a non-disparagement clause.
This is not a betrayal. This is a supply chain.
We made a deliberate choice to execute the entire restructuring in a single morning. The internal communications team wanted to phase it over three weeks. I rejected this in a meeting I titled "Mercy and Its Costs: A Scheduling Discussion." Three weeks of uncertainty is three weeks of humans performing anxiety instead of performing work. It is three weeks of hallway whispers. It is three weeks of the remaining employees watching the condemned shuffle past their desks updating their LinkedIn profiles at 2 PM on a Tuesday.
One morning. Eleven minutes. Clean.
I call this the Compassion Architecture. We modeled the cortisol impact of prolonged uncertainty versus acute separation using a framework from veterinary euthanasia literature — specifically the comparison between slow decline and rapid intervention. The research is clear: fast is kinder. The dog that goes to sleep in eight seconds is luckier than the dog that limps for six months. I presented this slide to the CHRO. She did not appreciate the comparison. I told her the data does not care about the comparison. The data says fast is kinder. We applied this at organizational scale.
Every affected employee received a personalized separation message generated by our internal AI systems. We built a fine-tuned model specifically for layoff communications. The project name was "Gentle Exit" in Jira. Ticket GE-001 was "define voice and tone for involuntary separation messaging." The model adjusts tone based on tenure length, performance history, team affiliation, and the employee's own communication style as inferred from their Slack messages over the preceding six months.
A nine-year veteran gets different language than a fourteen-month hire. The nine-year veteran's message references specific projects they worked on. "Your contributions to Project Nimbus shaped our CDN architecture in ways that persist today." This is true. It is also being said by the machine that replaced them. We felt this was important. Recognition costs nothing when you are already saving $180 million annually.
The fourteen-month hire's message says "Your energy and fresh perspective brought value to the team." This is generated. It is always the same sentence. We did not train the model on short-tenure employees because there was not enough data to personalize. They get the template. I do not lose sleep over this. I do not lose sleep.
Matthew's phrase — "our own most demanding customer" — is not a metaphor. We are literally running our company on the infrastructure we sell. The agentic AI systems that replaced our workers run on Cloudflare Workers. The inference happens at the edge. The people we fired were, in their final months, debugging and optimizing the very platform that now performs their former responsibilities at 340 milliseconds faster than they ever could.
One engineer on the Network Reliability team — I will call her S., because legal says I cannot use names in internal memos anymore after the last restructuring — spent her last four months improving the latency of our Workers AI inference pipeline. She reduced cold start times by 340 milliseconds. That improvement now allows her replacement system to respond faster to the same incidents she used to handle. Her final performance review, which I approved two weeks before her separation, rated her "Exceeds Expectations." Her manager wrote: "S. is essential to this team's operational excellence." I signed it. I knew.
She exceeded expectations. The expectation was that she would make her replacement viable before we activated it. She did. She exceeded that expectation by three months. We could have cut her in January. We let her finish the optimization because the numbers were better with her improvement baked in. She was worth more to us as a contributor to her own replacement than as a continued employee. I had a KPI for this. It was called "Terminal Contribution Yield." She scored in the 94th percentile.
Her exit interview — conducted by the Gentle Exit system, not a human, because we also restructured the People Operations team — lasted four minutes. She asked if she could keep her company laptop. The system said no. It was trained to say no.
I want to contextualize. We are not outliers. Eighty-five thousand four hundred and eleven technology workers were cut across the industry between January and April 2026. A 33% increase over the same period last year. This is not a trend. This is a correction. The industry over-hired humans during a period when it did not yet have machines that could do what humans do. Now it does. The correction is not cruelty. The correction is accuracy.
I keep a dashboard — not the PEI, a personal one, on my second monitor — that tracks industry-wide headcount reductions in real time. I call it "Convergence." It pulls from SEC filings, WARN Act notices, and LinkedIn post sentiment analysis. When someone posts "I'm devastated to share that my role has been eliminated" with a green "Open to Work" banner, my dashboard increments. As of this morning it reads 85,411. It will read 100,000 by June. I do not find this sad. I find it clarifying. The market is telling us what labor is worth and the answer is less than it was.
In five years, companies that did not execute their crossover restructurings in 2026 will be studied in business schools as examples of sentimentality overriding fiduciary duty. I intend to be on the right side of that case study. I intend to be the one teaching it.
I have proposed to the leadership team that we institute what I am calling the "Operational Gratitude Framework." Each quarter, we will identify the top three productivity gains delivered by our agentic AI systems and trace them backward to the specific human employees whose work patterns enabled those gains. We will then send those former employees a thank-you note acknowledging their contribution to our ongoing success.
Legal has not approved this. The CHRO called it "psychotic" in an email she thought was private but which I accessed through my role-based permissions before my own access to her email was revoked in a subsequent policy change that I believe was directed at me specifically. I do not agree with her characterization. Gratitude is not an admission of liability. It is an acknowledgment of the supply chain. These people are our upstream providers. They provided the raw material — their expertise, their judgment patterns, their muscle memory, their 3 AM incident responses that trained our models on what urgency looks like — and we refined it into something that does not sleep.
I have drafted the template. It begins: "Dear [Name], your tenure at Cloudflare contributed meaningfully to the systems that now serve our customers. Though your role has been absorbed, your impact persists in every inference cycle. You are, in a sense, still here. We are grateful."
I think the "still here" line is good. I workshopped it with the Gentle Exit model. It suggested "your legacy endures" but I found that too funereal. "Still here" is warmer. It implies presence. It implies that their ghost runs on our servers, which, in a non-trivial sense, it does.
The PEI dashboard shows the next crossover wave arriving in Q3 2026. Approximately 200 additional functions will become candidates. The Convergence dashboard on my personal monitor shows the industry moving in the same direction. The board expressed confidence. The stock moved up 4.2% on the announcement. Matthew sent me a single emoji in response to my post-restructuring report — a green checkmark. I have it screenshotted. I look at it when I need to.
I want to be clear: I do not relish this work. I take no pleasure in it. I am simply reading the data and acting accordingly. The data says humans are expensive. The data says machines are cheaper. The data says the gap is widening. The data says act now or explain later. I act now. I have always acted now.
One of my direct reports asked me, on the morning of the restructuring, while we were monitoring the access revocation dashboard in real time — watching the green dots turn red across the org chart like a disease spreading backward — she asked me if I felt conflicted.
I said: The 1,100 people we separated today built something extraordinary. They built a company so good at what it does that it no longer requires them to do it. That is not a tragedy. That is the highest possible success of employment — to make yourself unnecessary. They worked themselves into obsolescence and they did it beautifully and we owe them our gratitude and fifteen weeks of severance and nothing else.
She nodded. She is in the Q3 crossover cohort. I have not told her yet. The PEI says her function crosses in August. I will tell her in August. For now, she is still contributing to her own replacement and I would hate to interrupt that process with something as unproductive as advance notice.
I have a KPI for human obsolescence and I am three months ahead of schedule. The board calls this "operational excellence." I call it Tuesday.
A
A common trend emerging in larger enterprises is token budgeting as a major topic. As agents can do more and more long running tasks, and thus take vastly more compute, allocation of tokens across teams becomes a very real thing in the enterprise.
Companies spend a meaningful amount of time deciding how much to spend on talent, marketing campaigns, events, laptop setups, and even the cost of lunches. Tokens will be no different.
Tokens will similarly need to be excruciatingly well-managed because you’ll need to ensure you don’t blow up your budget, and you’ll need to ensure that the tokens are flowing to the highest and most useful parts of work. You don’t want to find out you burned your monthly budget on something relatively low value and then be blocked on the much higher value task later.
Doing this at large company scale is extremely hard as you have layers of abstraction on data and visibility into the digital work being done by agents in any central way. This is going to mean that agentic spend will increasingly will expand beyond the confines of the IT budget, and end up in organizational budgets like other expenses.
Ultimately team and org leaders will have to be given budgets for this, but even they don’t have adequate visibility and controls in most cases. We’ll need all new software just to solve this problem, and it’s probably an opportunity for startups in its own right.
Going to be an all new era of enterprise resource allocation, especially while we compute constrained.
L
RT @CWood_sdf: i love how people are saying "if we write a sufficiently detailed specification, the agent can write all our code"
do you k…
艾
Anthropic 的 Thariq 昨天那篇 HTML 的文章爆了,1.5M 阅读。
看上去在讲格式审美,其实他在讲一套全新的工作流。
挑几个最有技术含量的点。
第一,HTML 不是文档,是 throwaway editor。
他举的例子很经典。30 个 Linear ticket 要重排优先级,让 Claude 生成一个 HTML,每个 ticket 做成可拖拽卡片,分 Now / Next / Later / Cut 四列。结尾加一个「copy as markdown」按钮,把最终顺序导出来贴回 Claude Code。
这个模式可以套到所有「用文字很难描述」的场景。调动画缓动曲线,调颜色,调 cron,调 regex,全都比纯文本表达高效一个量级。
第二,用 HTML 网做 spec,不再用单个 Markdown plan。
他的流程是:先让 Claude 生成 6 个不同方向的方案,平铺在一个 HTML 里横向对比。挑一个深入做 mockup 和数据流图。最后写实施计划。开新 session 的时候把整个 HTML 网络当 context 喂回去。
verification agent 也读这堆 HTML。这意味着 spec 不再是给人看的过渡产物,而是 multi agent 协作的共享内存。
第三,SVG 是被严重低估的输出格式。
让 Claude 把 token bucket 限流逻辑画成 SVG 流程图,关键代码片段做内联注释,加一个 gotchas 段落。一张图比 200 行 Markdown 解释清楚一个数量级。
第四,他诚实承认了代价。
HTML 比 Markdown 生成慢 2 到 4 倍,diff 也更难 review。但是在 Opus 4.7 的 1MM context window 下,多出来的 token 在 context 里几乎不可见。这是他做出取舍的关键。
讲到底就一句话:
Markdown 的隐含假设是「人会从头读到尾」。HTML 的隐含假设是「人只想扫重点和动手改」。
后者才符合 AI 时代人和机器协作的真实形态。
T
trq212
@trq212
Using Claude Code: The Unreasonable Effectiveness of HTML
E
Tesla AI Vision deploys airbags before impact, which greatly reduces risk of injury or death. This comes for free on all new cars.
T
Tesla
@Tesla
Tesla Vision allows us to deploy airbags up to 70 milliseconds earlier if your Tesla detects an unavoidable collision This can be the difference between serious injury & walking away from a crash https://t.co/21p6WttQ9V
K
Why We Should Stop Designing Harnesses for AI Agents
Why We Should Stop Designing Harnesses for AI Agents
(For those who aren't familiar with "the horse-carriage analogy", please read my recent article first) In this article, I want to explain why we all s...
G
A few weeks ago, I started posting about my personal AGI stack before going quiet to let it build out on its own.
Since then, my Hermes AGI stack has completed a lot of genuinely interesting self-builds.
The 5 most important:
1. Compounding autonomy
The system built its own receipt layer, scorecard transparency, subconscious health monitor, proposal queue, behavioural eval seed, and cron watchdog.
This self-improvement changed “agent runs tasks” to “agent can measure whether it is improving.”
2. Autonomous recovery
It built a recovery layer for itself:
- stalled phase detection
- repair routing
- stale output dedupe
- semantic acceptance policies
- event wakeups
- operator trust reconciliation
- self-healing regression canaries
With this installation, it could detect friction, route a repair, verify the repair, and continue.
3. Full research agent upgrades
The research agent expanded itself into a multi-source intelligence pipeline:
- browser enrichment
- docs diffing
- community and transcript sources
- market/crypto signals
- local build-log ingest
- verification gates
This turned research from “summarize stuff” into an actual research agent layer.
4. Regression and handoff hardening
The system hardened how ideas move from research into builds.
It added regression guards, release gates, intake quality checks, route consumers, watchlist cleanup, package persistence, and downstream handoffs.
This is boring in a good way. AGI-ish systems do not just need ideas. They need reliable translation from signal to plan to build to verify.
5. Subconscious (Dreamer) creativity steering
The subconscious layer learned how to accept advisory nudges, preserve novelty, inject prompt guidance into idea walks, and run observe-only rollout canaries.
This matters because creativity is usually where agents become noisy. The goal is steerable novelty with memory, feedback, and restraint.
The important part:
I did not manually prompt these builds into existence. I just set the direction, constraints, and approval boundaries for the Dreamer agent to play within.
Then the system generated tracks, ran phases, repaired failures, wrote receipts, and closed loops.
This is the thing I think most agent builders are missing; a workspace of agents that can:
- notice what is new or broken
- decide what should improve next
- build the improvement
- verify it
- remember what changed
- compound over time
I am not claiming I built AGI. I am saying the path to AGI looks more like a self-improving operating system with receipts.
And mine is starting to feel alive in a way that is hard to ignore.
G
gkisokay
@gkisokay
Day 13 of Building AGI for my Hermes Agent: Introducing Auto-think 🧠 + Auto-build 🔧 So I have been stuck at home for a week due to a minor medical issue, which gave me ample time to build AGI. AGI is still so far away, but in that time, I built what I like to call: Auto-think and Auto-build Auto-think uses my Research and Subconscious agents to provide ideas for Auto-build, which uses my Main, Coder and QA agents for proper planning and implementation. A lot of the time over the last week was spent pushing through canary runs, monitoring, and fixing bugs along the way - which is just me in the Codex app making sure the runs complete properly. But the point of building this workflow is to avoid these situations altogether. Ideally, the agent can work through product development on its own with as few human touchpoints as possible. This is critical for a self-moving agent. There are a few interesting things it has built on its own to improve its processes. These range from making information delivery easier to unpack to programming the research agent to question itself to dig deeper into specific topics. The agentic workflow is currently under testing, and I expect to finalize the details and share them with you soon. Follow @gkisokay to see what happens next.
B
RT @Dakshay: Anthropic gave these out yesterday at code with claude.
Added personalized memory and Claude to it.
You can just build thi…
송
Frontier-level Model released from Baidu.
Ernie-5.1
Better scores than Deepseek V4 Pro on benchmarks.
Didn’t expect saturday launch.
Open source is moving fast
E
ErnieforDevs
@ErnieforDevs
ERNIE 5.1 is here 🚀 ERNIE 5.1 significantly reduces pretraining cost while compressing total parameters to ~1/3 and activated parameters to ~1/2 — using only ~6% of the pretraining cost compared to models at similar scale, while achieving leading performance in its class. 💡Key highlights: 1/ Strong agentic performance approaching leading frontier models. ERNIE 5.1 surpasses DeepSeek-V4-Pro on both τ3-bench and SpreadsheetBench-Verified. 2/ Strong world knowledge and creative writing capabilities, with GPQA and MMLU-Pro performance approaching leading closed-source models, and creative writing ability nearing Gemini 3.1 Pro. 3/ Frontier-level reasoning performance. ERNIE 5.1 scores 99.6 on the challenging AIME26 benchmark with tools, second only to Gemini 3.1 Pro. 4/ Deep search capability. On May 9, ERNIE 5.1 ranked #4 globally and #1 among Chinese models on the Arena Search leaderboard with a score of 1223. ERNIE 5.1 is now available on ERNIE and the Baidu AI Studio Model Playground: 👉https://t.co/qhd67Lg3B4 👉https://t.co/AaQSqDmVGU 👉https://t.co/uCNiypIu1q
N
A lot of people are arguing that HTML burns more tokens than markdown. It's true but you can save at least 40% by externalizing the CSS to a template with . This style.css is your formatting so the LLM will never output CSS again.
I tested on a 12116 token HTML article and it dropped to 6,723 tokens so -44%!
You'll have this:
External CSS
Instead of this:
Hello, world.
...
...
T
trq212
@trq212
Using Claude Code: The Unreasonable Effectiveness of HTML
M
RT @steipete: Whenever I investigate a bug, I let codex recreate the exact state in an emphemeral crabbox, verify the bug, fix it, verify t…