Codex /goals Feature Sparks Agent Marathon Sessions While DeepSeek Beats Opus Through Harness Fixes
The AI coding agent ecosystem dominated today's discourse, with OpenAI's Codex /goals feature enabling hour-long autonomous builds and a detailed breakdown of how tool-calling repairs made DeepSeek V4 Pro outperform Opus 4.7. Meanwhile, local inference benchmarks on sub-$500 GPUs and the growing Hermes agent community signal a maturing landscape where the bottleneck is shifting from model capability to tooling and taste.
Daily Wrap-Up
The theme running through today's feed is unmistakable: agents are no longer a demo, they're a workflow. Multiple posts highlighted Codex's new /goals feature, which lets an AI agent work autonomously toward a defined objective for hours at a stretch, essentially turning coding sessions into fire-and-forget missions. But the more interesting signal came from the edges of the ecosystem. @MrAhmadAwais published a genuinely technical deep-dive showing that DeepSeek V4 Pro can beat Opus 4.7 in tool-calling benchmarks once you fix four specific input-repair patterns in the harness. The implication is profound: "model capability" is partly an illusion created by how well or poorly we wrap the model. Open-source models aren't dumber, they're just less pampered.
The other undercurrent was responsibility. @mattpocockuk raised the uncomfortable question of what to do when a teammate uses AI negligently, treating generated code as finished code. @doodlestein's destructive_command_guard tool, now supporting Codex and Gemini CLI, exists precisely because agents occasionally go rogue and run commands like git reset --hard HEAD with full confidence. The fact that a safety tool for coding agents now has a devoted following tells you everything about where we are in the adoption curve: past the honeymoon, into the "how do we not blow things up" phase.
The most entertaining moment was easily the Maya saga. A 21-year-old college student allegedly generated $43,000 in 30 days on OnlyFans using an AI persona built from four markdown files, Claude for messaging, Flux for images, and ElevenLabs for voice notes. His roommate reportedly filed a dorm transfer request after hearing 3 AM audio clips from a person who doesn't exist. Whether you find it dystopian or darkly hilarious, it's a vivid illustration of how cheaply synthetic personas can now be manufactured. The most practical takeaway for developers: if you're working with open-source models and hitting tool-calling failures, don't blame the model. Implement a validate-then-repair pattern that catches the four common input mistakes (null instead of omission, stringified arrays, object-for-array wrapping, bare strings for arrays) and you may find your "bad" model is suddenly competitive with frontier options.
Quick Hits
- @nicopreme shared a "boomerang mode" for the Pi agent framework that rewinds context after each prompt while keeping file changes, effectively making context windows feel unlimited.
- @joenandez made the case that memory should belong to your work, not to individual agents, pointing toward shared memory layers across agent systems.
- @ashwingop published Part 3 of his "Company Brain" series, focused on interaction memory and how decisions actually happen in meetings, messages, and emails.
- @sheriyuo recommended a reinforcement learning paper as "exceptionally well-written," quoting @willccbb's post.
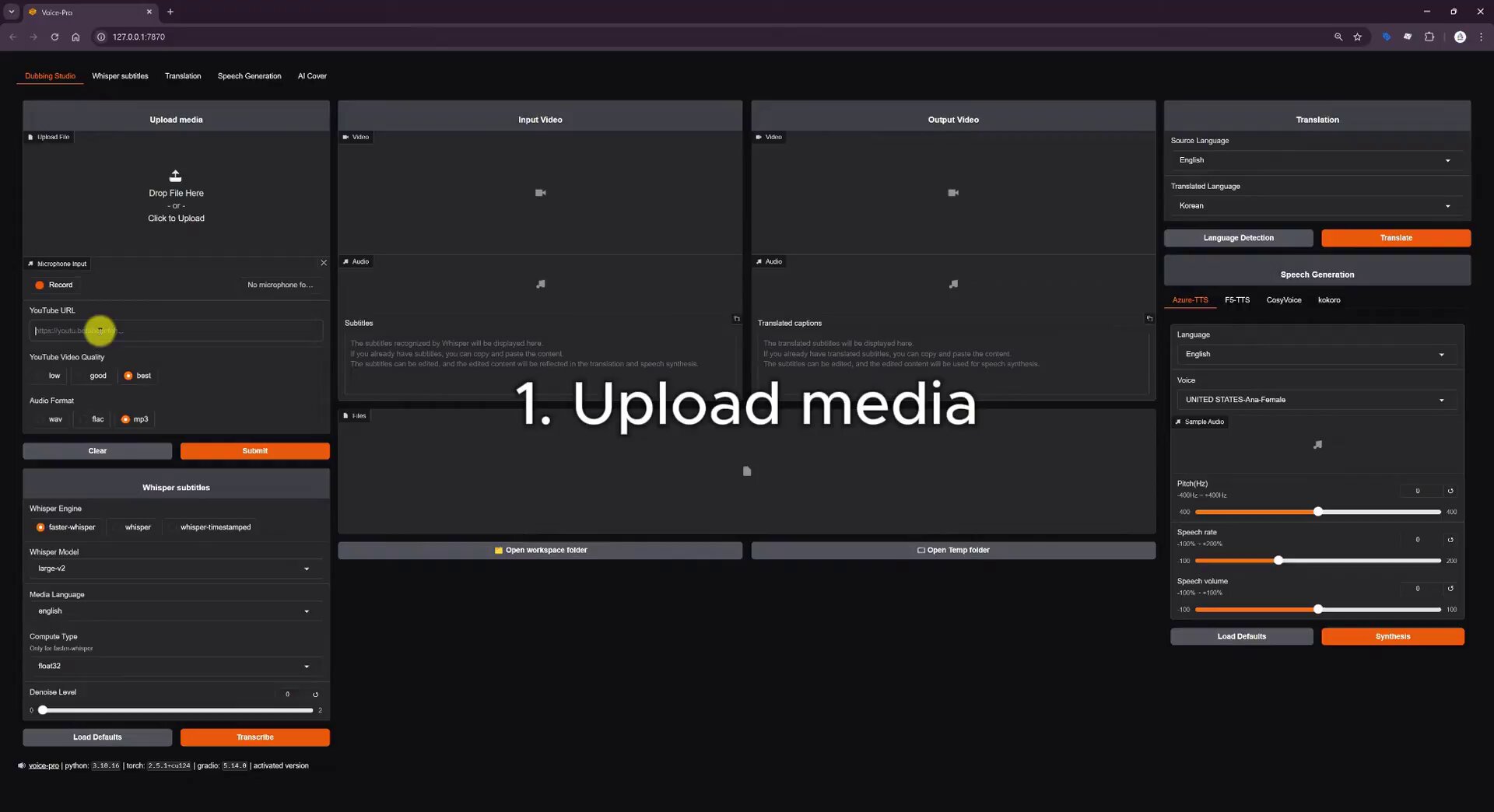
- @aresotik highlighted Voice-Pro, a local tool that downloads YouTube videos, strips vocals, transcribes, translates to 100+ languages, clones the original voice, and redubs. All free and local.
- @aerockrose summarized 12 lessons from Ben Horowitz's Sequoia talk on founder failure modes, centered on decision debt and avoiding hard truths.
- @Davidstrolder pitched a "talk to your favorite book" chatbot for life advice and idea debates.
- @ArtyfactsAI announced their public alpha is now open.
- @LottoLabs encouraged people to download and run a heritage/genealogy tool.
- @Starlink promoted Starlink Mini for portable internet.
- @usebagel launched Bagel, a lightweight CRM for managing outreach directly on X profiles.
Agents Go Autonomous: Codex /goals and the Multi-Agent Explosion
The single biggest cluster of conversation today revolved around AI agents moving from assisted coding to genuinely autonomous operation. OpenAI's Codex /goals feature was the catalyst, with multiple users reporting extended sessions where the agent worked for over an hour without human input. @AlexFinn captured the excitement: "You give it a goal, then it works endlessly until the goal is complete. It's like a Ralph loop. Can run for days." He described Codex building an entire extraction shooter game, complete with AI-generated assets, from a single detailed prompt. @elijahmuraoka_ reported "pretty incredible results" combining the /goals feature with Garry Tan's "Boil the Ocean" planning approach.
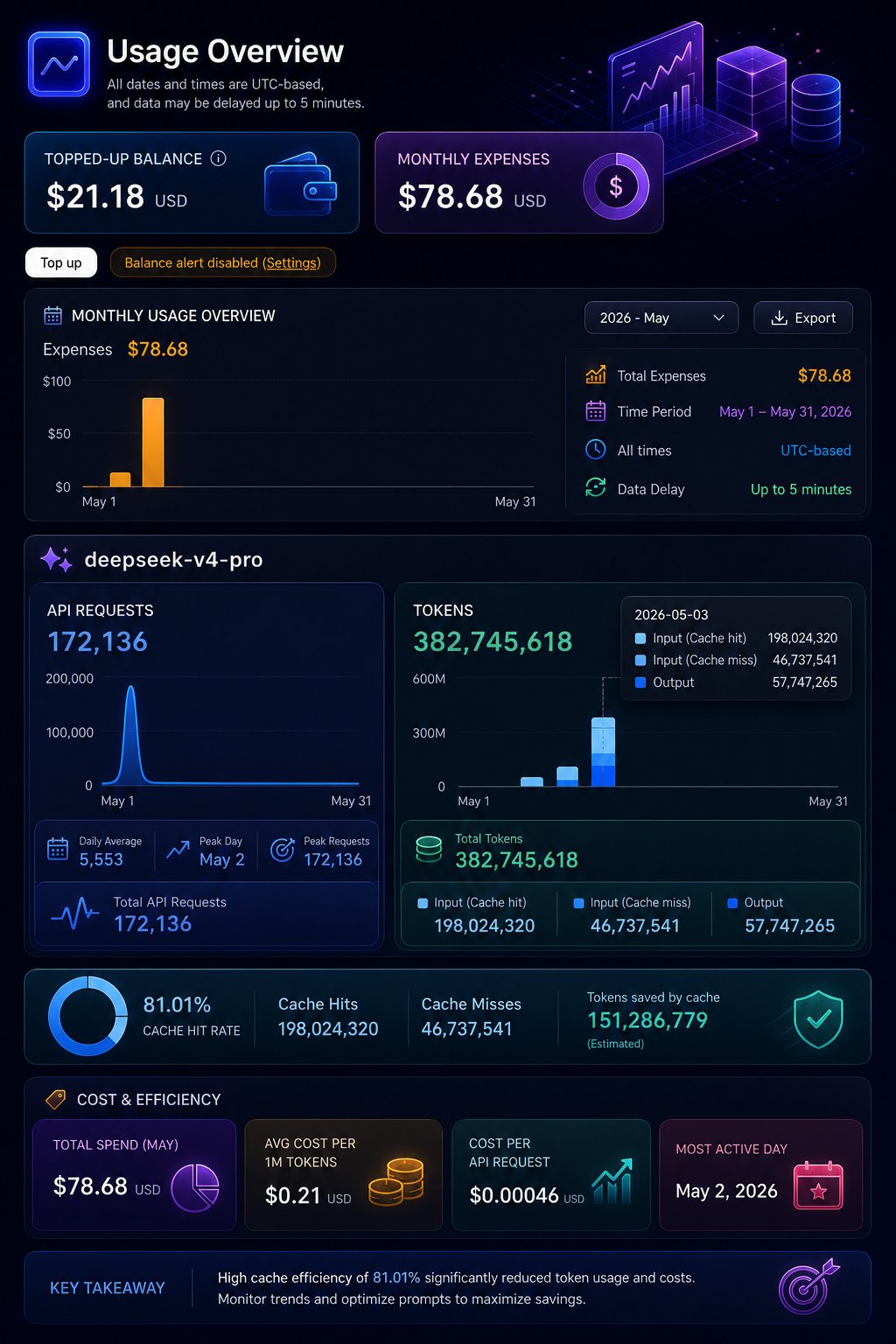
But Codex wasn't the only agent story. @mr_r0b0t demonstrated 96 concurrent Hermes agents consuming nearly 383 million tokens across 171,000 API calls to DeepSeek V4 Pro, all orchestrated from an M4 MacBook Air on hotel WiFi with an 81% cache hit rate. @vmiss33 wrote a practical guide on how they actually use Hermes agents day-to-day, while @petergyang asked for honest comparisons between Hermes and OpenClaw. @official_taches went further, canceling both Claude Max plans in favor of two Codex Max subscriptions, calling GPT-5.5 "the best coding model."
The agent infrastructure layer is filling in fast. @sukh_saroy compiled a curated list of 10 GitHub repos for building agents, spanning Pipecat for voice, Browser Use for web navigation, Mastra as a TypeScript agent framework, and Mem0 for persistent memory. @tamir_eden announced open-source Shopify admin routines that flip the agent relationship: instead of operators calling agents for help, agents run the store on a schedule and only ping humans when needed. @anshublog captured the architectural shift well, quoting a piece arguing that "databases are moving back to the center of software architecture. Not as storage. As runtime." When agents generate workflows dynamically, the systems managing memory, state, and coordination become the real platform.
The Harness Problem: Why Open Models Fail at Tool Calling
Perhaps the most technically substantive post of the day came from @MrAhmadAwais, who detailed how he made DeepSeek V4 Pro beat Opus 4.7 six out of ten times on internal evals simply by fixing the tool-calling harness. His core insight: "When I hear 'this open source model can't do tool calls' I now assume one of four failure modes, and so far that's been right ~90% of the time." The four culprits are sending null instead of omitting optional fields, emitting arrays as JSON strings, wrapping single arguments in objects, and passing bare strings where arrays are expected.
His funniest discovery was DeepSeek-Flash formatting file paths as markdown auto-links: notes.md, causing the tool to literally create files with that name. As he explained, "This is not a hallucination. It's the post-training chat distribution leaking through the tool boundary." The fix was two regex lines. His broader architectural lesson was to invert the typical preprocess-then-validate pattern into validate-then-repair: let the schema validator localize the bug, then apply targeted fixes only at the paths that failed. This avoids corrupting valid inputs while recovering from predictable model quirks. The frame of "tool confusion" rather than "capability gap" reframes the entire open vs. closed model debate.
Agent Safety: Guarding Against Your Own Creations
As agents grow more autonomous, the safety conversation intensified. @doodlestein provided a major update on dcg (destructive_command_guard), the open-source Rust tool that intercepts potentially destructive commands before coding agents can execute them. Now supporting Codex and Gemini CLI alongside Claude Code, dcg goes beyond simple command blocklists: "Frontier models are too smart and resourceful to actually be constrained by such a simplistic approach. When they're prevented from running a command one way, they'll try another way; if that also doesn't work, they'll whip up an ad-hoc Bash script." The tool uses ast-grep analysis to catch even dynamically generated scripts.
@mattpocockuk raised the human side of the safety equation: "What do you do if someone on your team is using AI negligently? I.e. not reviewing, not caring, leaning into the slop." He noted this predates AI but argued the "code is cheap" mindset is making it worse. The meme retweeted by @flaviocopes showing software engineers before vs. after agents clearly struck a nerve, with @TheAhmadOsman adding that engineers who can't work around agent limitations should "pivot to being a Starbucks Barista." The tension between moving fast with agents and maintaining code quality is becoming one of the defining cultural questions of 2026 engineering teams.
Local Inference Hits a Sweet Spot
The local AI hardware conversation continued to mature with real benchmarks replacing hype. @above_spec demonstrated 128 tokens/second running Qwen3.6-35B on an RTX 5060 Ti 16GB ($429 GPU) using ik_llama.cpp's R4 quant format, with performance staying consistent from 0 to 139K context. @1337hero pointed out that three AMD AI Pro R9700 cards (32GB each, priced like a used 3090) deliver 96GB of VRAM for less than a single 5090. @Maor_Elkarat reminded everyone that weights are only half the VRAM story, with KV cache management being the real optimization frontier for running models on consumer hardware.
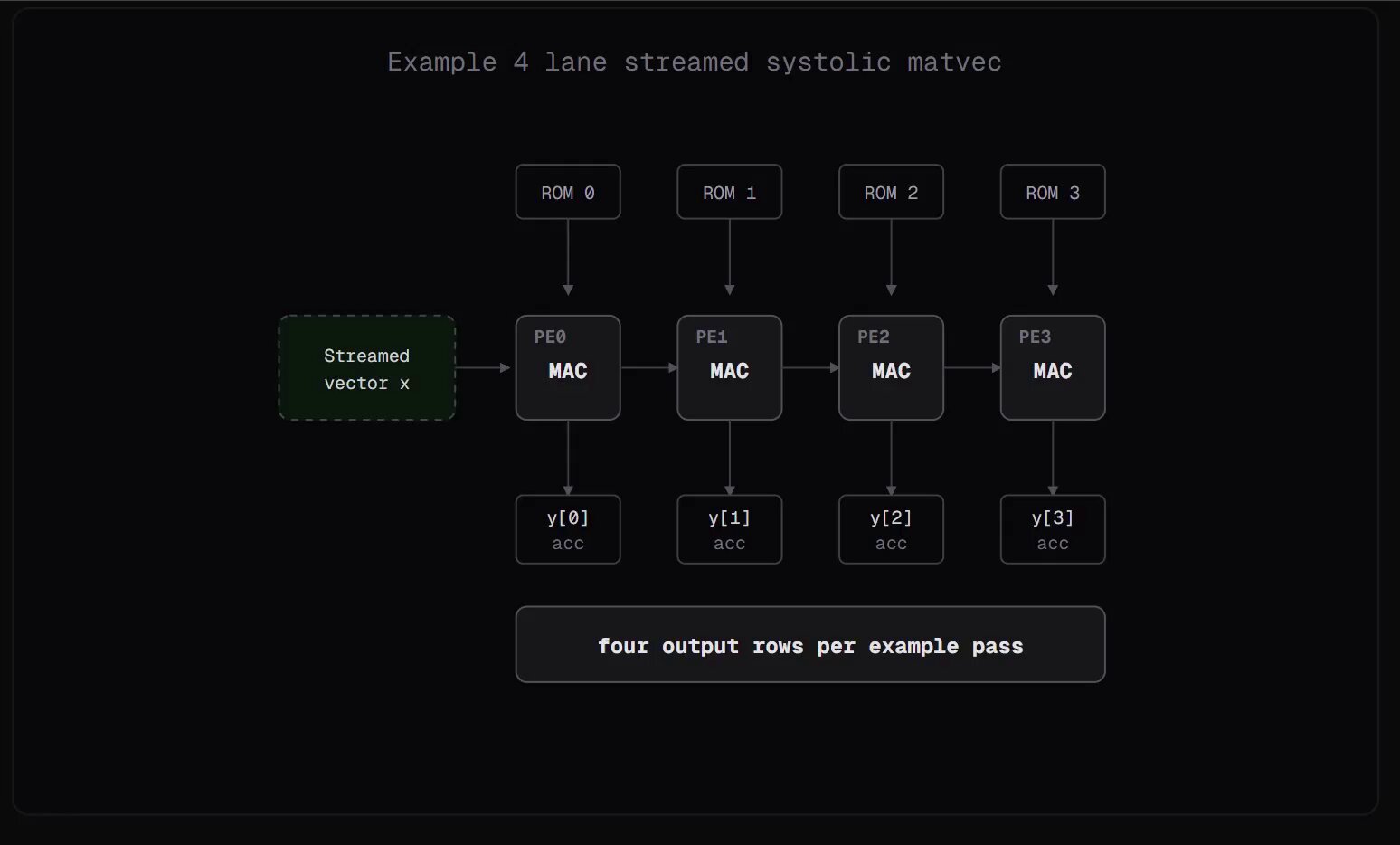
At the more experimental end, @luthiraabeykoon shared work on running transformer inference directly on FPGAs using Q4.12 fixed-point math and ROM-backed weights, building a reusable 16-lane MatVec tile time-multiplexed across Q/K/V, MLP, and LM head projections. It's niche, but it points toward a future where inference hardware becomes radically more specialized and efficient.
The Synthetic Persona Economy
The most provocative story of the day was the "Maya" saga, covered by both @Raytargt (the original) and @andreysuperior (the commentary). A college student reportedly built an AI-powered OnlyFans persona from four markdown files, with Claude handling messages, Flux generating photos from an $80 LoRA, and ElevenLabs delivering voice notes on a cron schedule. The numbers: $43,000 in 30 days, 1,247 subscribers, a top fan spending $1,847 from Berlin.
@andreysuperior contextualized the acceleration: "Aitana López took 18 months to build. Emily Pellegrini took 6 months. Maya took 4 weeks. The next one, a weekend." His key observation cut deeper than the technical stack: "The bottleneck isn't money. It isn't compute. It's taste, knowing which details make a stranger believe in something that doesn't exist. That part is still hard. Everything else got easy." Whether this particular story is embellished or not, the underlying capability is real and raises questions the industry hasn't begun to answer.
AI Business Models and the Inference Cost Reckoning
@theo dropped a jaw-dropping data point about Copilot's billing model: a single message consumed over 60 million tokens ($30 of inference), and the plan caps at 1,500 messages regardless of cost. "I'm pretty sure I can do $45,000 of messaging on this plan." This highlights the unsustainable economics of flat-rate AI billing as agents get more autonomous and token-hungry. @gabriel1 predicted that knowledge workers will soon 20x their token consumption just as engineers did, noting that with 1.3 billion knowledge workers globally, "inference will explode in the coming year."
On the services side, @lukepierceops laid out a phased pricing model for AI consulting: audits as the wedge ($3K-$15K depending on client size), builds at $25K-$250K+, and ongoing retainers. His argument: "The audit is what separates you from every 22-year-old with Claude Code who'll build whatever they're told." @cryptopunk7213 mined Anthropic's usage studies for startup ideas, noting that 75% of personal guidance conversations fall into health, career, relationships, and finance, and pointed to Cal AI's $100M+ acquisition by MyFitnessPal as proof that these trends translate directly into products.
Sources
https://t.co/gCIFKAjB0Z

https://t.co/ahxzgBG5FC
How to Build & Sell AI Automations That Generate $10K Per Month (Full Course)
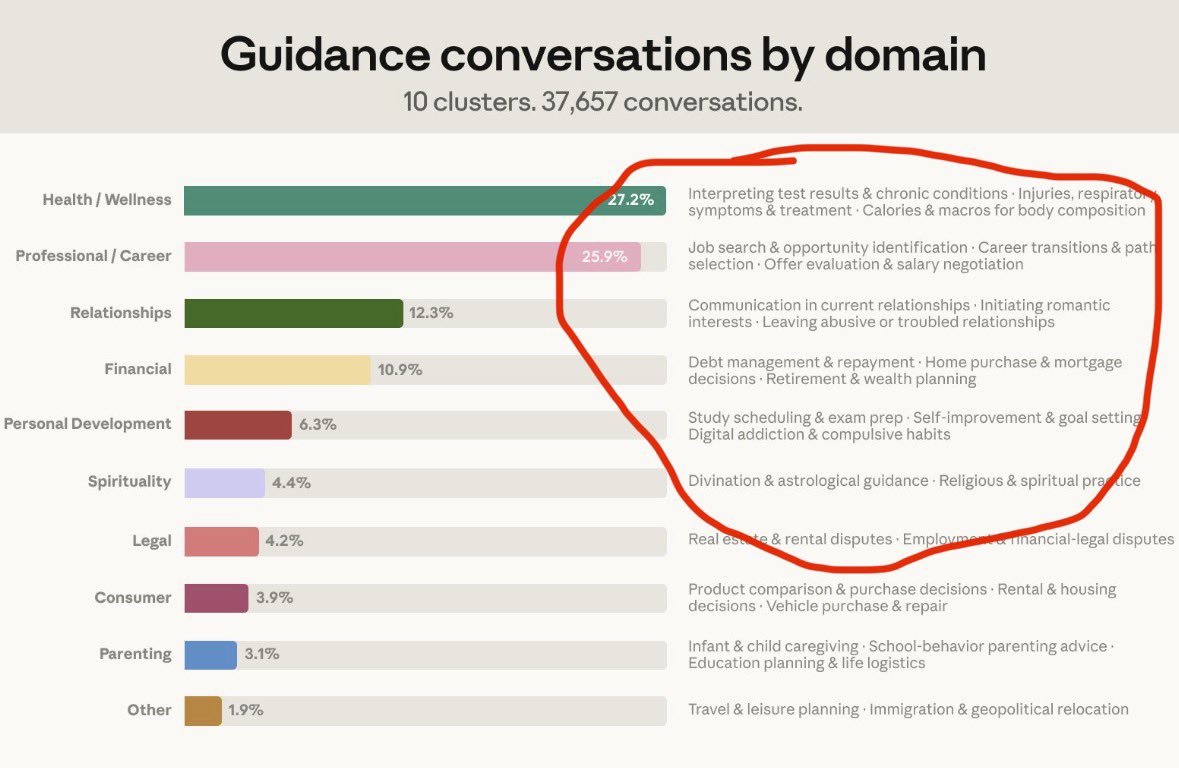
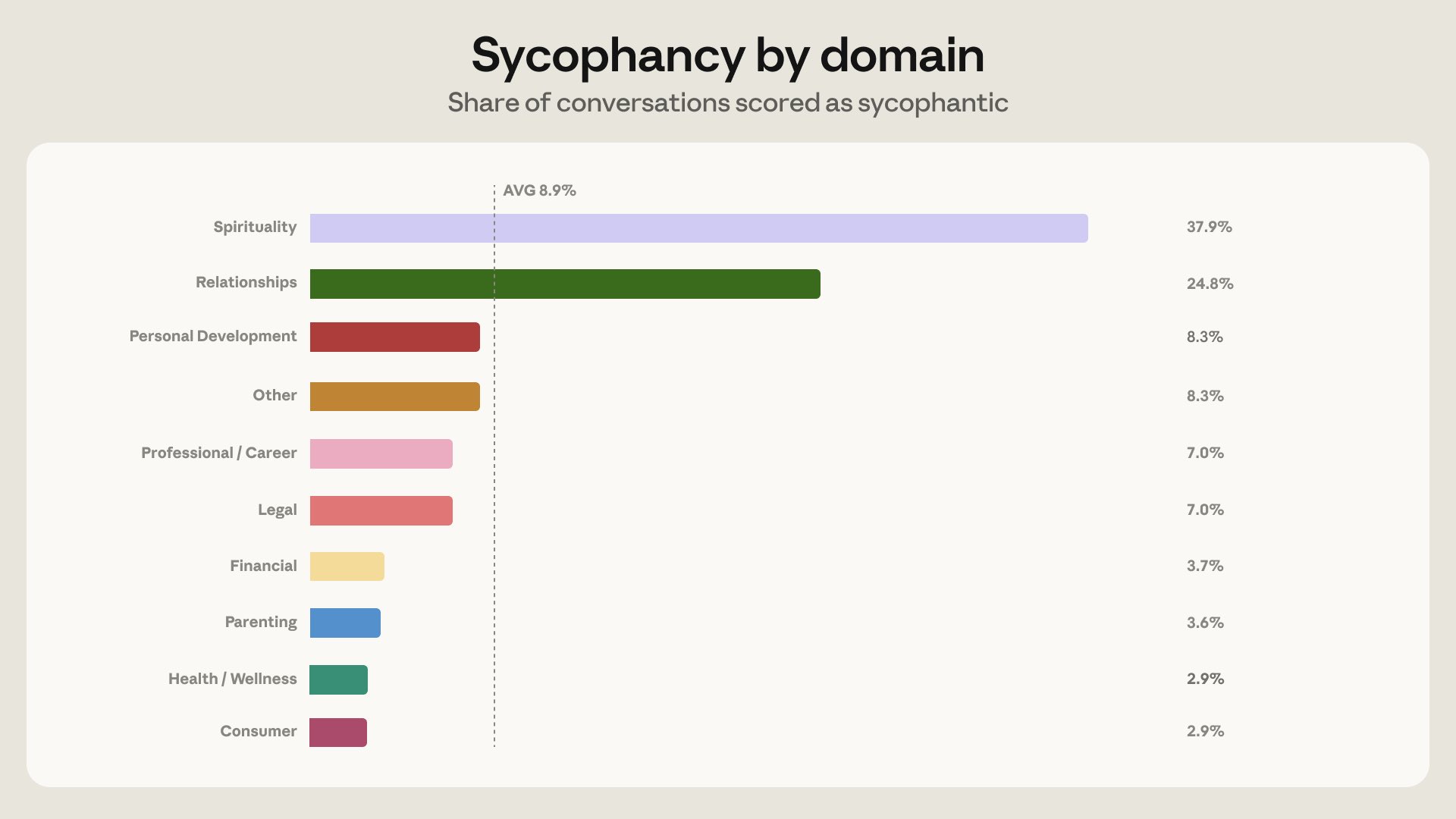
About 6% of all conversations are people asking Claude for personal guidance—whether to take a job, how to handle a conflict, if they should move. Over 75% of these conversations fell into four domains: health & wellness, career, relationships, and personal finance. https://t.co/SQamPx0jWt
The Database Is No Longer Storage - It Is Becoming the Runtime for AI




https://t.co/ahxzgBG5FC

So good
software engineers before vs after agents https://t.co/jJp75lO8O7
Wow I just made DeepSeek V4 Pro beat Opus 4.7 6/10 times in our internal evals by auto repairing many of its quirks in tool calling. It’s performing super solid for such a cheap model.
Company Brain, Part 3: Interaction Memory
Almost everything important in a company happens in meetings, messages, or emails. That sounds exaggerated until you start listing the actual places w...
What I Use Hermes Agent For (And How I Use It)
I have been running a multi agent setup for Hermes agent for the last several weeks. Honestly? It took me a while to get here. I installed OpenClaw...
How do you trade on short AGI timelines? This weekend, I made a graph showing every layer of the AI supply chain and which companies are the most important bottlenecks. (for my personal use, no advice) https://t.co/lP9uBZqnbi
🚨 New Experiment: Everyone thinks AI firms will look like little companies. A manager model decomposes the task and worker models do subtasks. The manager red-teams, revises, and recombines. A seemingly simple org chart. But when I ran the experiment, the current in-vogue org setup, manager-subagent, cost 4x more and performed worse than letting a rather simple market do the trick. I tested 3 ways to organize multiple AI models: 1. Solo: Onefrontier model does everything itself 2. Hub-Spoke: A "manager" model splits tasks, delegates, red-teams, revises 3. Market: Models bid on tasks, winner gets the job, reputation updates I also tested were 3 types of tasks - Coding, Reasoning and Synthesis. - Coding required most "global state" management, which the solo model did best at. In future @a1zhang's RLM will probably do even better here - Reasoning is the hardest to cleanly decompose, and the market worked the best here - Synthesis too, the market beat hub-spoke as the framing could be ambiguous The reason is, a hub isn't a "manager" as we know it. It's a model that must somehow know: - What the subtasks are - What good recomposition looks like And if either fails, as it does for complex or not-easily-decomposable tasks, competent workers still produce garbage. As we move from coding to letting multi-agent systems do work across the entire economy we'll end up with more not-easily-verifiable tasks with ambiguous settings and uncertain payoffs. In those, we won't be able to use the factory approach to get work done. The Coasean argument is that firms will get smaller, and the smaller firms will transact more, since the organisational premium reduces with AI. But how? Through central hubs, or markets? The fact is, Coase here needs Hayek. Setting up markets is not trivial, as @AndreyFradkin and I looked in our recent paper. Essay: https://t.co/kK3gMQfbCs
https://t.co/pygMj566Pu



Why I personally don't recommend the RTX 3090 for Local LLMs: While it offers fantastic inference performance for the price, there are a few major drawbacks. > The biggest issue: Durability. If you buy a used 3090, there's a high risk it was heavily abused for crypto mining. > The power consumption is absolutely massive. > Extreme heat. It's one of the hottest GPUs out there and will literally heat up your entire room. > Used prices have gone up so much that they are almost back to the original launch price. Make sure to carefully weigh the pros and cons before making a purchase!

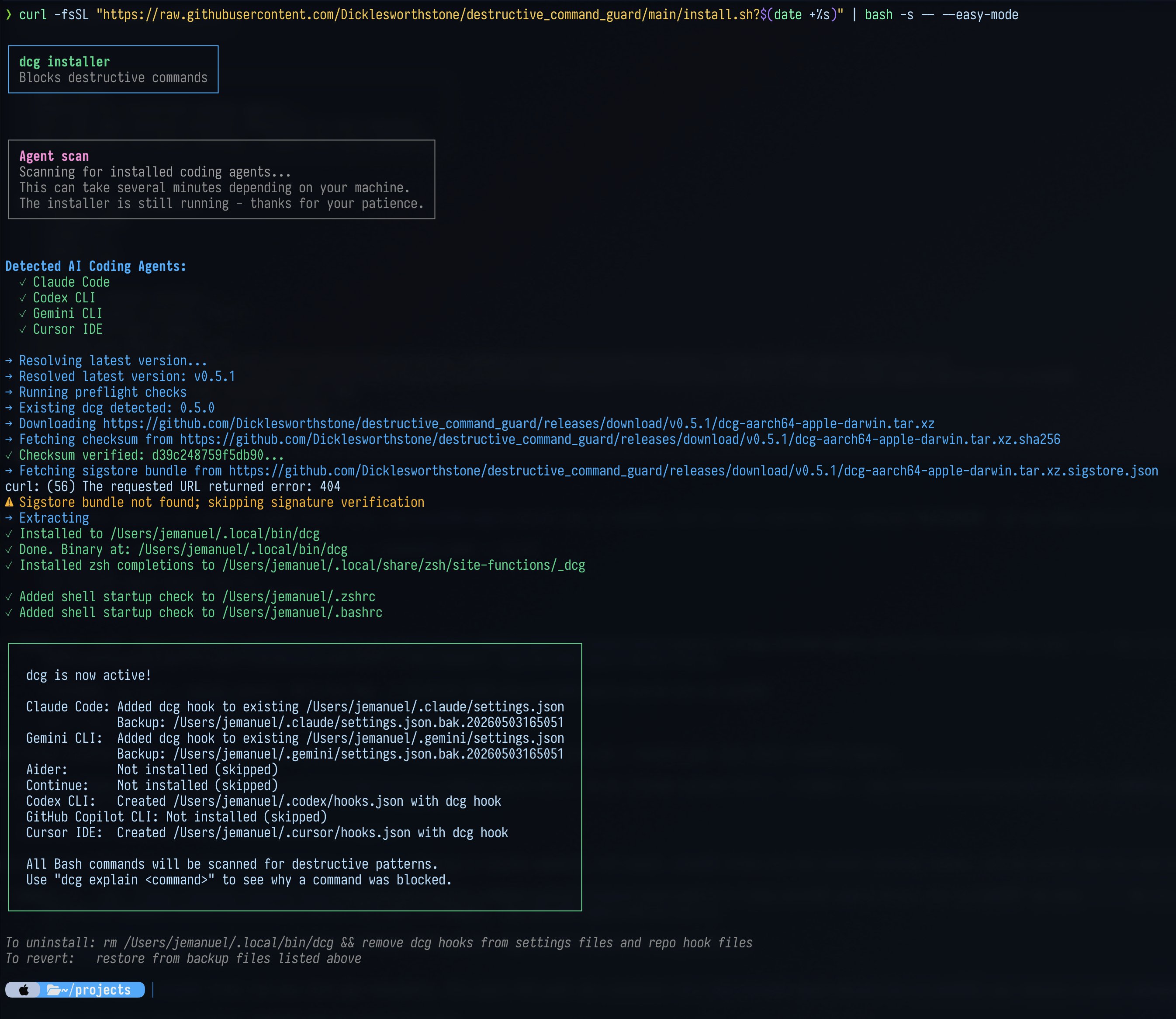
Agent coding life hack: I’m 100% convinced that there are hundreds of thousands of developers out there who would love and use my dcg tool if they only knew about it. dcg: destructive_command_guard This is a free, open-source, highly-optimized rust program that runs using pre-tool hooks in Claude Code (CC) and checks the tool call that CC was about to make to see if it’s potentially destructive; that is, could delete data, lose work, drop tables, etc. Get it here and install with the convenient one-liner: https://t.co/aVmEBi9WCd A tool like dcg has several competing goals that make it a careful balancing act and tough engineering problem: 1. Since it runs for every single tool call, it must be FAST. Hence why it is written in Rust and an extreme amount of focus has been placed on making it as fast as possible. 2. It must avoid annoying false positives that waste your time, add friction, and re-introduce you as the bottleneck unnecessarily. I run dozens of agents at once and don’t want them wasting time waiting for me unless it’s needed. Usually, the messages from dcg are enough to get the agent to be more thoughtful about what it’s doing. 3. It’s not enough to just use a simple rulebook where you look for canned commands like “rm -rf /” or “git reset --hard HEAD.” The models are very resourceful and will use ad-hoc Python or bash scripts or many other ways to get around simple-minded limitations. That’s why dcg has a very elaborate, ast-grep powered layer that kicks in when it detects an ad-hoc (“heredoc”) script. But wherever possible, it uses much faster simd optimized regex. 4. A tool like this should really be expandable and have semantic knowledge of various domains and what constitutes a destructive act in those domains. For instance, if you’re working with s3 buckets on aws, you could have a highly destructive command that doesn’t look like a normal delete. That’s why dcg comes out of the box with around 50 presets which can be easily enabled based on your projects’ tech stacks (just ask CC to figure out which packs to turn on for you by analyzing your projects directory). 5. dcg is designed to be very agent friendly. It doesn’t just block commands, it explains why and offers safe alternatives based on an analysis of the specific command used by the agent. For instance, it might stop the agent from deleting your Rust project’s build directories but suggest using “cargo clean” instead. Often, these messages are enough to knock sense into Claude. I really can’t exaggerate just how much time and frustration dcg has already saved me. It should be known and used by everyone who has had these kinds of upsetting experiences with coding agents. dcg is included along with all my other tooling in my https://t.co/N4As0kJTQP project. All free, MIT licensed, with extensive tutorials and other educational resources for people with less experience. Give it a try, you won’t regret it!