Agents Go Autonomous with Codex /goal and 96-Agent Swarms While DeepSeek Beats Opus Through Harness Engineering
Today's feed was dominated by the agentic revolution going into overdrive, from Codex's new /goal feature running tasks for hours to 96 concurrent Hermes agents burning through 382M tokens in three days. Meanwhile, a detailed teardown showed how four simple input repairs made DeepSeek V4 Pro outperform Opus 4.7, and the dcg safety tool expanded to protect developers from their own agents across all major harnesses.
Daily Wrap-Up
The most striking thread running through today's posts is that the agent era isn't coming; it's already here and scaling fast. We've moved past "can an agent write a function" to "can 96 agents coordinate on a MacBook Air over hotel wifi." The answer, apparently, is yes, and the conversation has shifted accordingly. The infrastructure layer around agents, from safety guardrails to database runtimes to tool-calling repair layers, is where the real engineering work is happening now. The models themselves are almost beside the point.
The single most technically valuable post today was @MrAhmadAwais's deep dive into why open source models fail at tool calling. The punchline is devastating for model elitism: it's almost always a harness problem, not a model problem. Four predictable input repair patterns and a couple of regex lines turned DeepSeek from "can't do tool calls" into an Opus 4.7 competitor. That's not a model upgrade. That's contract design. Meanwhile, @doodlestein's dcg tool hitting its four-month anniversary and expanding to Codex support is a quiet reminder that the more autonomous agents become, the more we need mechanical safety nets rather than vibes-based trust. When you have dozens of agents running simultaneously, "git reset --hard HEAD" from one rogue agent can wipe out everything the others built.
On the lighter side, watching @AlexFinn describe Codex's /goal feature building an entire extraction shooter game with AI-generated assets over the course of an hour feels like a glimpse into a very weird future. The fact that the recommendation is to "put on skip all permissions" and let it run for days is either thrilling or terrifying depending on your relationship with autonomous systems. The most practical takeaway for developers: if you're working with open source models and struggling with tool calling, don't blame the model. Implement validate-then-repair at the harness level, starting with the four common failure modes (null instead of omit, stringified arrays, object-for-array wraps, bare strings for arrays). You'll likely fix 90% of your issues with under 200 lines of code.
Quick Hits
- @Starlink is pushing Starlink Mini for portable internet. Not AI, but the connectivity infrastructure that makes hotel-wifi agent swarms possible.
- @usebagel launched Bagel, a lightweight CRM overlay for X that tracks pipeline and follow-ups directly on profiles. Useful for founders doing organic outreach.
- @Davidstrolder pitched a "talk to your favorite book" chatbot for getting life advice and debating ideas. The literary AI niche continues to find its audience.
- @TheAhmadOsman sparked debate by suggesting software engineers who can't work around agent limitations should "pivot to being a Starbucks Barista." Spicy take, meet ratio.
- @ashwingop published Part 3 of his "Company Brain" series on interaction memory, arguing that the most important company knowledge lives in meetings, messages, and emails rather than documents.
- @ArchiveExplorer highlighted n8n-mcp as the go-to open source automation tool with 19,000 stars and 1,500 documented nodes, calling it "where you start" for Claude automation workflows.
- @cryptopunk7213 broke down Anthropic's latest usage study, noting that 75% of personal guidance conversations fall into fitness, finance, relationships, and career. Cal AI's $100M+ acquisition by MyFitnessPal proves there's real money in building wrapper experiences around these trends.
Agents Unchained: From Goal-Driven Coding to 96-Agent Swarms
The agent conversation leveled up significantly today, moving from "agents can help you code" to "agents can run autonomously for hours or days." The Codex /goal feature drew the most attention, with @AlexFinn reporting it built him "an entire complex extraction shooter video game" over the course of an hour, including generating all visual assets autonomously:
> "You give it a goal, then it works endlessly until the goal is complete. It's like a Ralph loop. Can run for days. If you enable the image gen skill before you run the goal, it will even generate ALL the assets for your game autonomously."
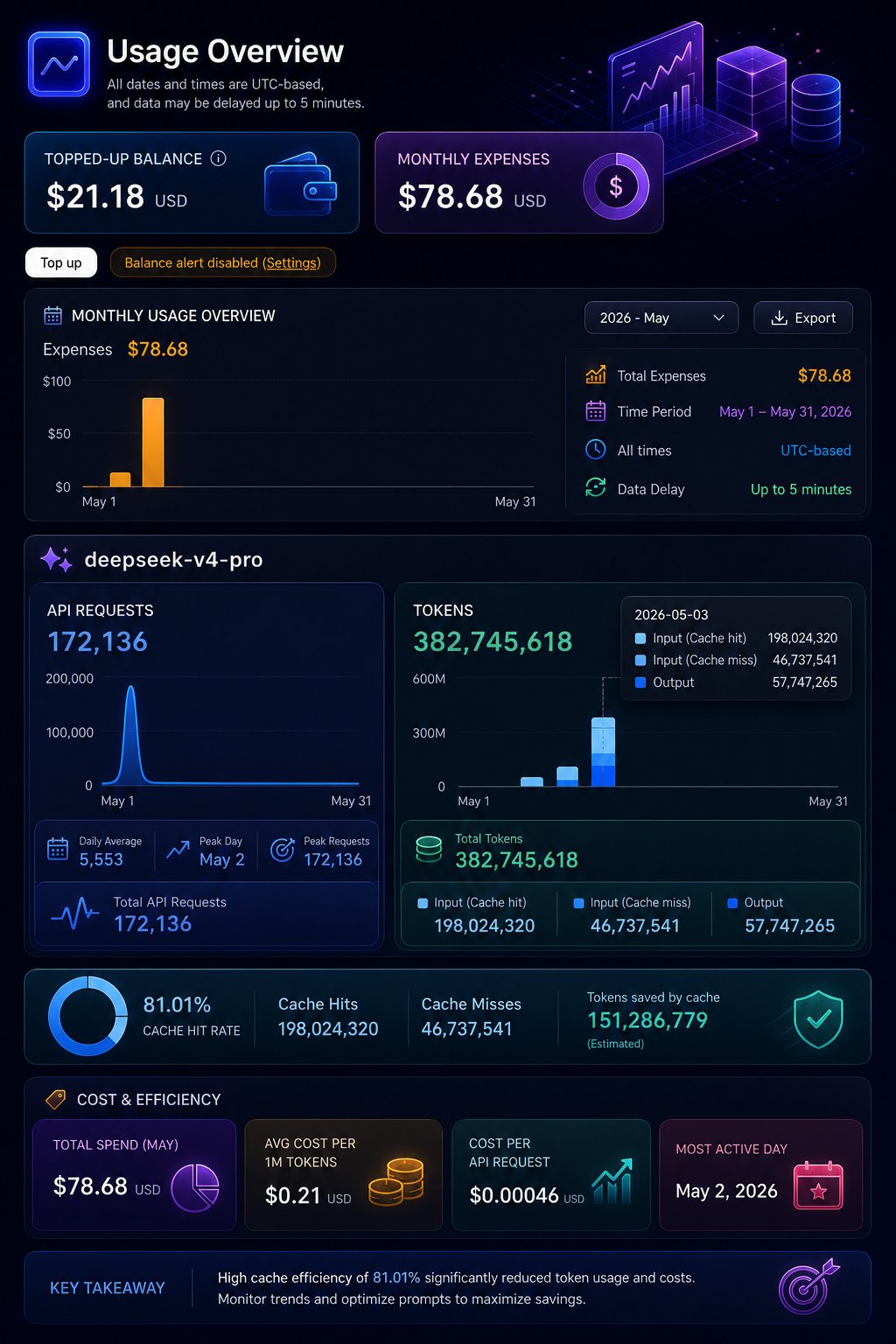
But the real jaw-dropper was @mr_r0b0t casually revealing that he ran 96 concurrent Hermes agents using DeepSeek V4 Pro, burning through "382,745,618 tokens over 171,136 API calls" in under three days, all from an M4 MacBook Air on hotel wifi with an 81% cache hit rate. Meanwhile, @vmiss33 published a practical guide on how they actually use Hermes agents in a multi-agent setup day to day, offering a grounded counterpoint to the hype.
The Shopify ecosystem is also going agentic. @tamir_eden announced open-sourced Shopify admin routines that flip the agent-operator relationship: "Skills made the agent something operators call when they need help. Routines flip it; the agent runs the store on a schedule and only pings you when something actually needs you." This is quoting in the context of @tobi (Shopify's CEO) endorsing the approach, which signals this isn't a fringe experiment. The pattern emerging across all these posts is consistent: agents are moving from reactive tools to proactive autonomous systems, and the humans are increasingly becoming the exception handlers rather than the drivers.
Harness Engineering: Why Open Models Fail at Tool Calling (And How to Fix It)
The most technically dense and arguably most important post of the day came from @MrAhmadAwais, who published a detailed breakdown of making DeepSeek V4 Pro competitive with Opus 4.7 through harness-level repairs rather than model changes. The core insight challenges a widespread assumption in the AI development community:
> "across deepseek-flash, deepseek v4 pro, glm, qwen, the same four mistakes repeat almost exactly: sending null for an optional field instead of omitting it, emitting ["a","b"] as a json string instead of an actual array, wrapping a single arg in {} where the schema expected an array, passing a bare string where an array was expected."
The architectural decision that made this work was inverting the typical approach: instead of preprocessing inputs before validation, you validate first, let the schema tell you exactly what's broken, then apply targeted repairs only at the failing paths. The preprocessing approach caused silent corruption because valid JSON content got accidentally rewritten. The post-validation approach uses the schema itself as the prior, spending "repair budget" only where the validator actually disagreed.
Perhaps the most entertaining failure mode was DeepSeek-flash emitting file paths as markdown auto-links: notes.md. As @MrAhmadAwais explains, "this is not a hallucination. It's the post-training chat distribution leaking through the tool boundary." The model knows how to format a path; it just hasn't been told this path is going to fopen rather than into a chat bubble. The broader lesson here is that "tool confusion" is a more useful frame than "capability gap," and what looks like a model limitation is often a contract design problem that the harness should solve.
Agent Safety: Protecting Developers From Their Own Creations
As agents become more autonomous and numerous, the safety tooling around them becomes critical infrastructure. @doodlestein marked four months since releasing dcg (destructive_command_guard) and announced it now supports Codex and gemini-cli alongside Claude Code:
> "Agents just can't be trusted to not occasionally do crazy things that seem sensible to them at the moment, but which are wildly destructive and often irreversible. These bouts of temporary madness often occur soon after compactions, or as a result of context rot caused by excessively long sessions."
The tool is written in Rust for speed since it runs on every single tool call, and uses ast-grep analysis to catch agents that try to work around blocked commands via ad-hoc scripts. The point about context rot causing destructive behavior is particularly relevant given today's trend toward long-running autonomous agent sessions. @mattpocockuk raised the human side of this problem, asking what to do when team members use AI "negligently, not reviewing, not caring, leaning into the slop." The "code is cheap" mindset, he argues, is making pre-existing quality problems worse. These two posts form a natural pair: we need mechanical safety nets for agents AND cultural accountability standards for the humans directing them.
Local Inference Gets Serious: Budget GPUs Hit 128 Tokens/Second
The local AI running community had a strong showing today, with concrete benchmarks that make the case for consumer hardware as a viable inference platform. @above_spec reported getting 128 tokens per second on Qwen3.6-35B using an RTX 5060 Ti 16GB ($429 GPU) with ik_llama.cpp's R4 quant format, noting performance "stays consistent from 0 to 139k context." That's faster than a 5070 Ti on mainline llama.cpp, which is a remarkable result for a mid-range card.
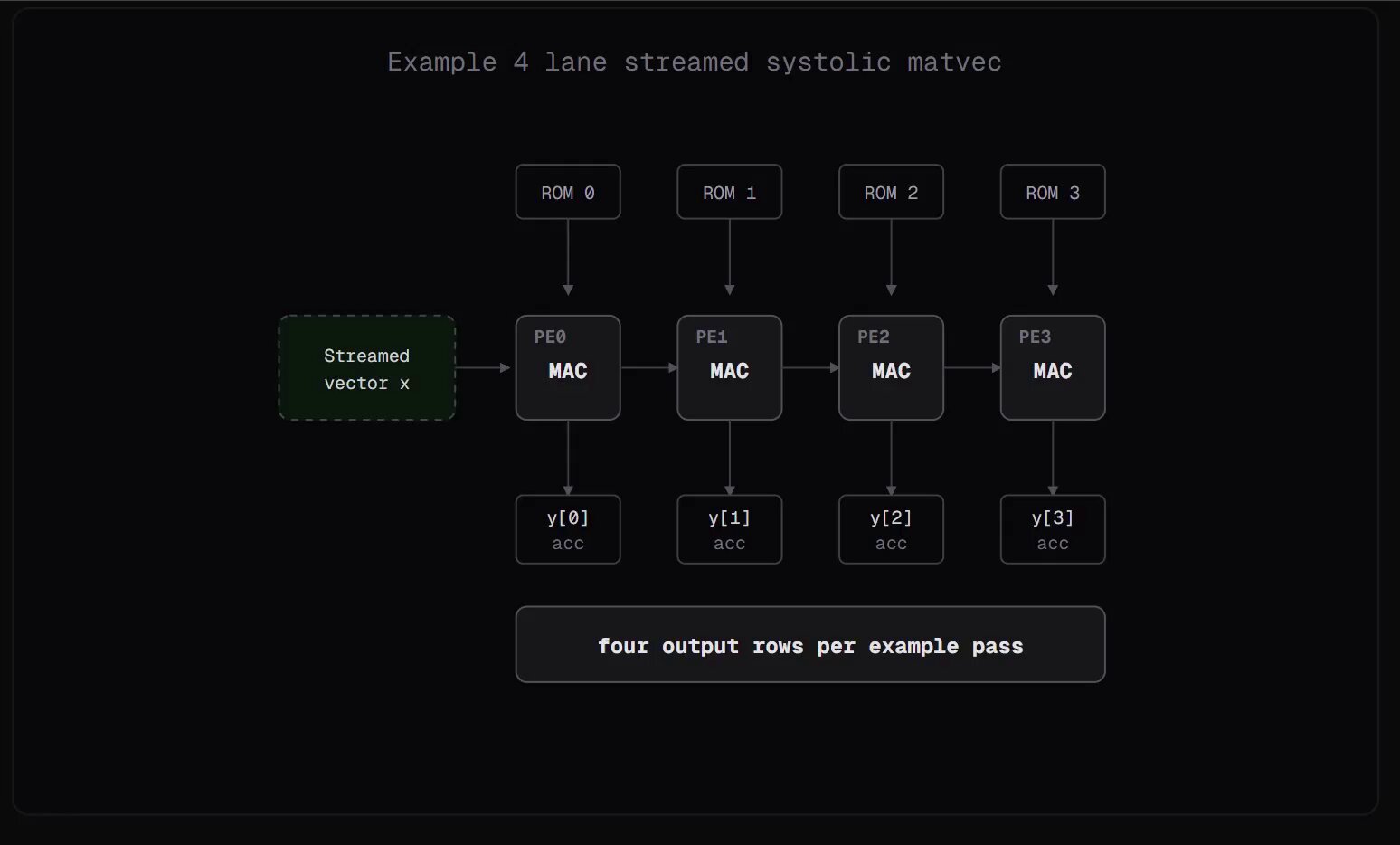
@Maor_Elkarat dug into the technical details that make these results possible, pointing out that "weights are only half the story. KV cache is eating your VRAM alive." Understanding the flags and cache management strategies is what separates a frustrating 12GB experience from one that runs "insanely fast." Meanwhile, @luthiraabeykoon shared work on a hardware-level approach: building a transformer using Q4.12 fixed-point math and ROM-backed weights, with a reusable 16-lane streamed MatVec tile time-multiplexed across Q/K/V, MLP, and LM head projections. The stack is deepening at every layer, from silicon to quantization to cache management, all in service of making powerful models run on hardware regular people can actually buy.
Databases as Agent Runtime and the Thinning Application Layer
@anshublog shared a provocative framing that databases are "moving back to the center of software architecture, not as storage, but as runtime." The argument is that as agents generate workflows dynamically, applications get thinner, and the systems managing "memory, state, coordination, and history" become the critical infrastructure. This maps directly onto the multi-agent patterns we're seeing: when you have 96 agents coordinating work, something needs to manage shared state, and traditional application architecture isn't built for that. The quoted post from @siddontang, "The Database Is No Longer Storage; It Is Becoming the Runtime for AI," frames what could be one of the more consequential architectural shifts of the agent era.
The AI Services Market Finds Its Pricing Model
@lukepierceops laid out a detailed pricing framework for AI consulting that's worth bookmarking if you're in the space. The key insight is that the audit is the wedge: "The audit is what separates you from every 22-year-old with Claude Code who'll build whatever they're told. You're selling the map. The build becomes inevitable once they've seen the map." Meanwhile, @official_taches made waves by announcing they cancelled both Claude Max plans in favor of two Codex Max plans, calling GPT5.5 "the best coding model." The competitive landscape for AI coding tools continues to shift fast, and practitioners are voting with their wallets based on real workflow experience rather than benchmark leaderboards.
Sources
How to Build & Sell AI Automations That Generate $10K Per Month (Full Course)
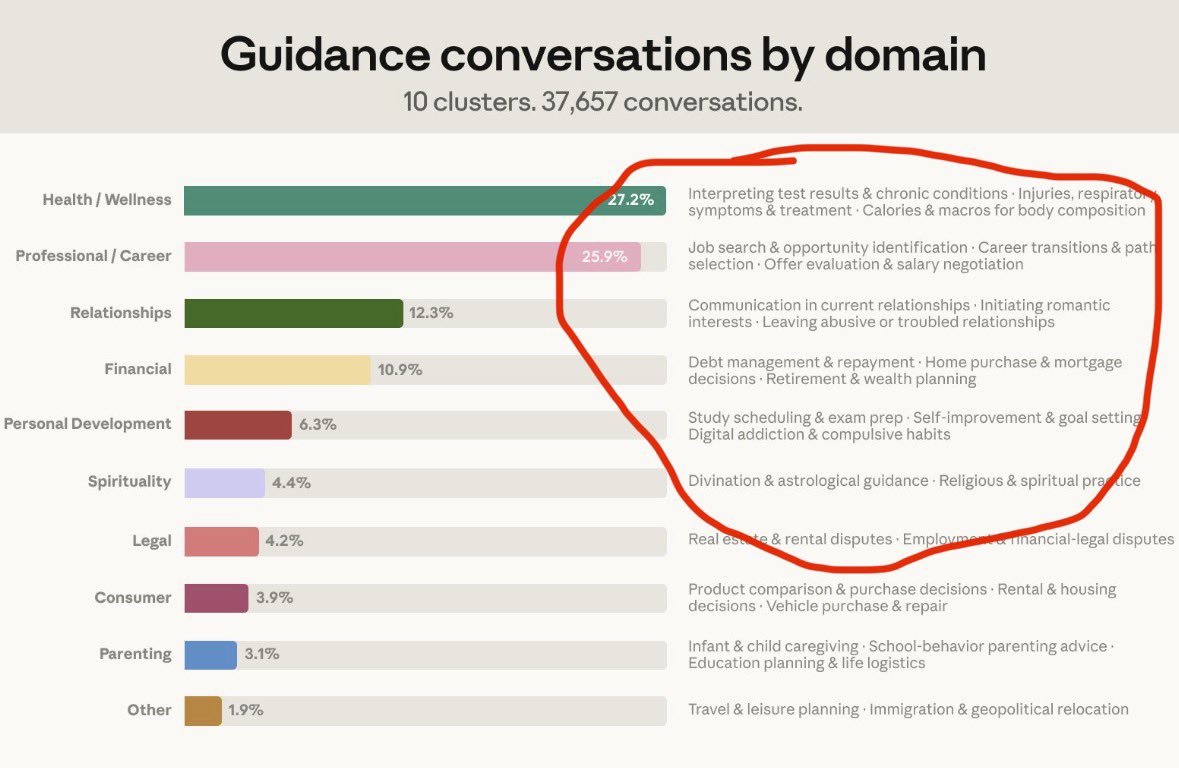
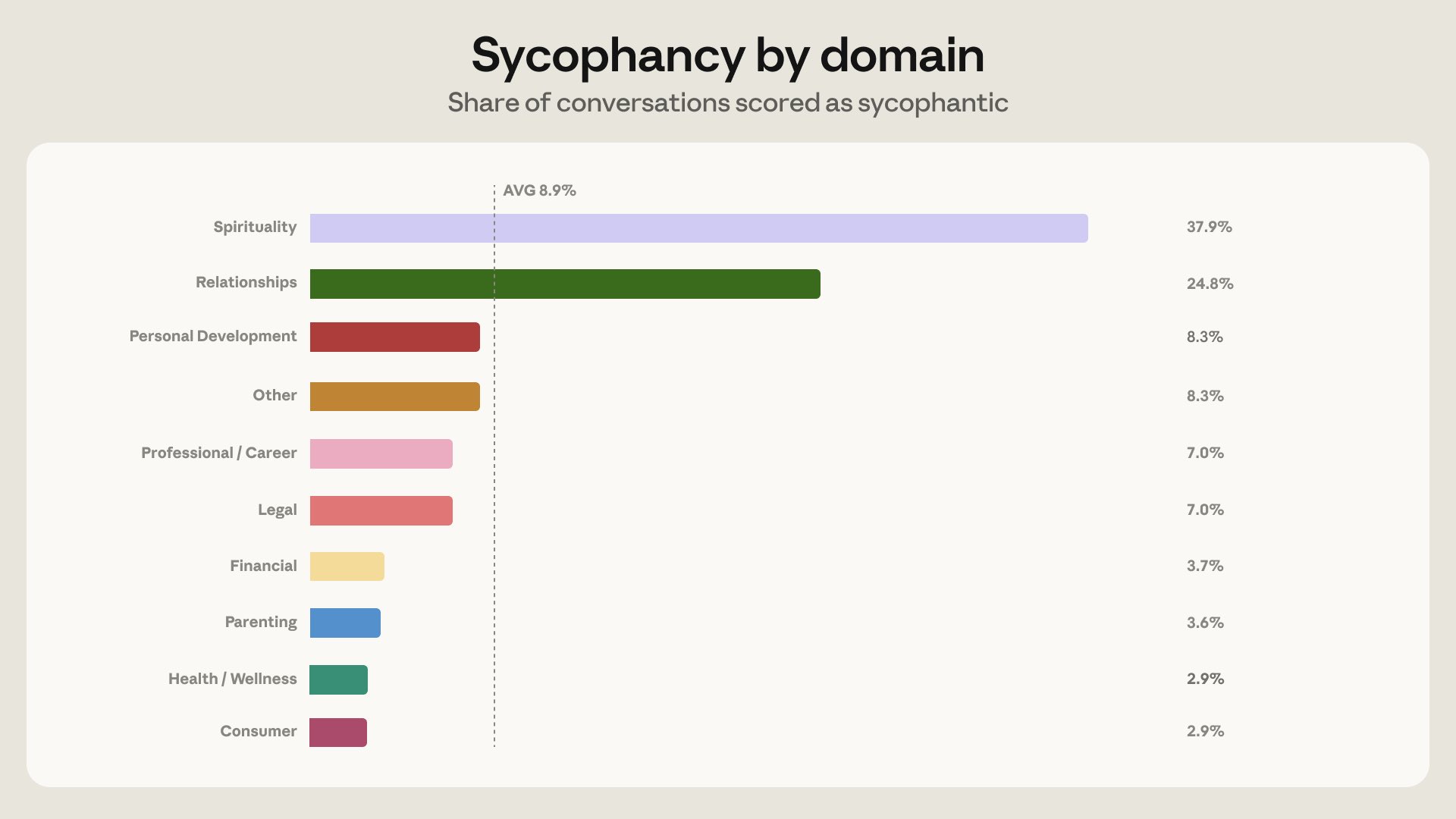
About 6% of all conversations are people asking Claude for personal guidance—whether to take a job, how to handle a conflict, if they should move. Over 75% of these conversations fell into four domains: health & wellness, career, relationships, and personal finance. https://t.co/SQamPx0jWt
The Database Is No Longer Storage - It Is Becoming the Runtime for AI

So good
software engineers before vs after agents https://t.co/jJp75lO8O7
Wow I just made DeepSeek V4 Pro beat Opus 4.7 6/10 times in our internal evals by auto repairing many of its quirks in tool calling. It’s performing super solid for such a cheap model.
Company Brain, Part 3: Interaction Memory
Almost everything important in a company happens in meetings, messages, or emails. That sounds exaggerated until you start listing the actual places w...
What I Use Hermes Agent For (And How I Use It)
I have been running a multi agent setup for Hermes agent for the last several weeks. Honestly? It took me a while to get here. I installed OpenClaw...


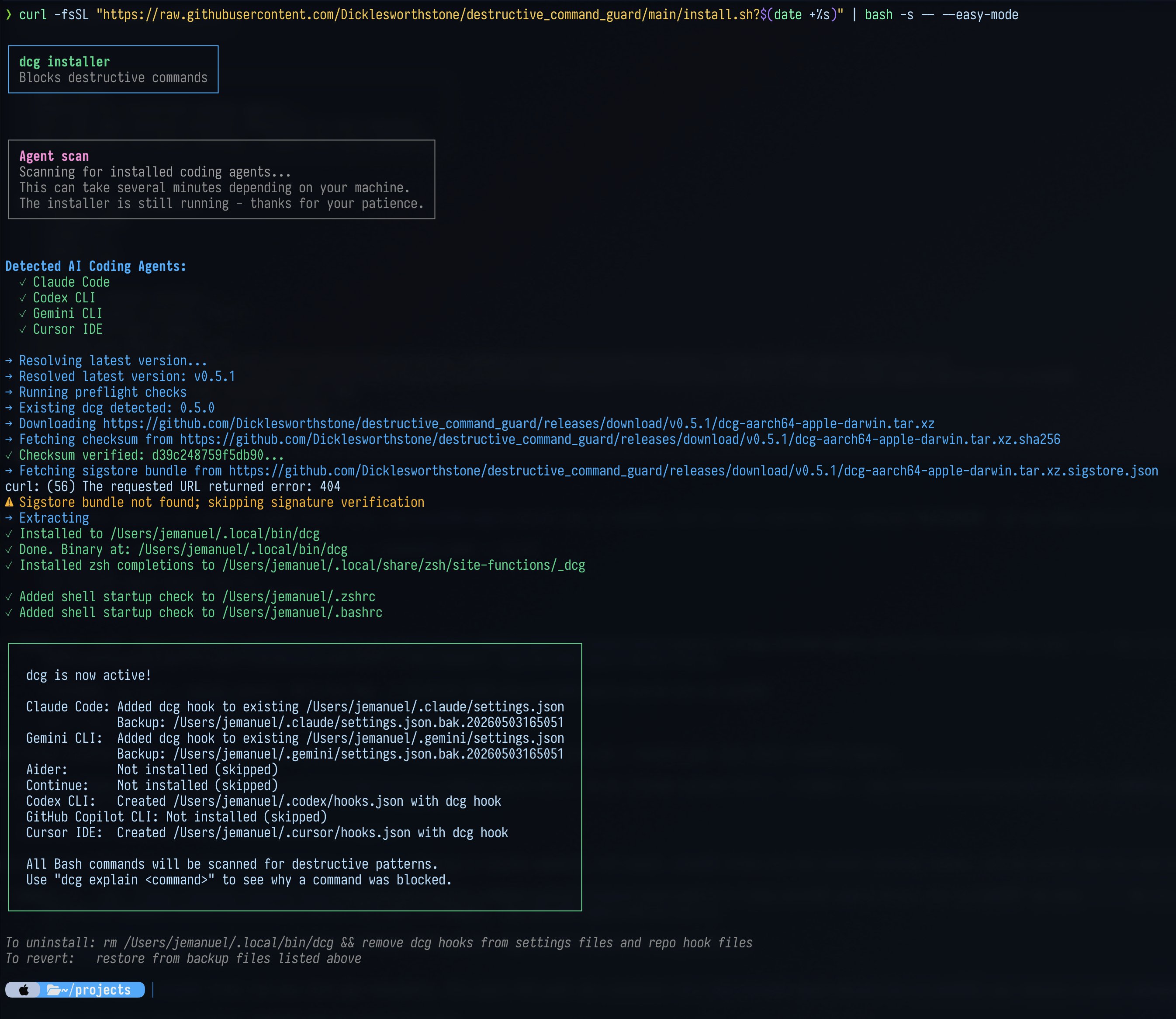
Agent coding life hack: I’m 100% convinced that there are hundreds of thousands of developers out there who would love and use my dcg tool if they only knew about it. dcg: destructive_command_guard This is a free, open-source, highly-optimized rust program that runs using pre-tool hooks in Claude Code (CC) and checks the tool call that CC was about to make to see if it’s potentially destructive; that is, could delete data, lose work, drop tables, etc. Get it here and install with the convenient one-liner: https://t.co/aVmEBi9WCd A tool like dcg has several competing goals that make it a careful balancing act and tough engineering problem: 1. Since it runs for every single tool call, it must be FAST. Hence why it is written in Rust and an extreme amount of focus has been placed on making it as fast as possible. 2. It must avoid annoying false positives that waste your time, add friction, and re-introduce you as the bottleneck unnecessarily. I run dozens of agents at once and don’t want them wasting time waiting for me unless it’s needed. Usually, the messages from dcg are enough to get the agent to be more thoughtful about what it’s doing. 3. It’s not enough to just use a simple rulebook where you look for canned commands like “rm -rf /” or “git reset --hard HEAD.” The models are very resourceful and will use ad-hoc Python or bash scripts or many other ways to get around simple-minded limitations. That’s why dcg has a very elaborate, ast-grep powered layer that kicks in when it detects an ad-hoc (“heredoc”) script. But wherever possible, it uses much faster simd optimized regex. 4. A tool like this should really be expandable and have semantic knowledge of various domains and what constitutes a destructive act in those domains. For instance, if you’re working with s3 buckets on aws, you could have a highly destructive command that doesn’t look like a normal delete. That’s why dcg comes out of the box with around 50 presets which can be easily enabled based on your projects’ tech stacks (just ask CC to figure out which packs to turn on for you by analyzing your projects directory). 5. dcg is designed to be very agent friendly. It doesn’t just block commands, it explains why and offers safe alternatives based on an analysis of the specific command used by the agent. For instance, it might stop the agent from deleting your Rust project’s build directories but suggest using “cargo clean” instead. Often, these messages are enough to knock sense into Claude. I really can’t exaggerate just how much time and frustration dcg has already saved me. It should be known and used by everyone who has had these kinds of upsetting experiences with coding agents. dcg is included along with all my other tooling in my https://t.co/N4As0kJTQP project. All free, MIT licensed, with extensive tutorials and other educational resources for people with less experience. Give it a try, you won’t regret it!