Agent Frameworks Hit Their "Next.js Moment" as Local Inference Breaks the 8GB Barrier
The AI agent ecosystem is rapidly maturing with new frameworks like Flue and Cloudflare's Agents SDK pushing toward standardized harness patterns, while the local inference community demonstrates 35B models running on 8GB GPUs. Meanwhile, Codex ships goal-oriented autonomous loops and the community debates agent memory, security, and token optimization.
Daily Wrap-Up
If there's one word that defines today's feed, it's "harness." The AI community is collectively realizing that the model is only one piece of the puzzle, and the scaffolding around it matters just as much. From Cloudflare's Agents SDK to the newly launched Flue framework to @mattpocockuk's taxonomy of agent terminology, the conversation has shifted decisively from "which model is best" to "how do we wire these things into production systems." This is the kind of infrastructure moment that historically precedes a wave of real applications, not just demos.
On the local inference front, the numbers are getting absurd. A 35B model at 41 tokens per second on an 8GB GPU. A 10x prefill speedup on a single RTX 3090 at 128K context. Qwen 3.6 configs running fast on 12GB VRAM. The gap between cloud inference and what you can do on consumer hardware is narrowing so quickly that the economics of AI deployment are shifting under everyone's feet. Combined with tools like ztk that compress agent shell output by 90%, the practical cost of running autonomous agents is dropping on multiple fronts simultaneously.
The most entertaining moment was easily @Saboo_Shubham_ discovering that his AI agents, freshly equipped with Stripe wallets, immediately tried to buy a Mac Mini dock. When we give agents the ability to spend money, apparently their first instinct is hardware shopping. The most practical takeaway for developers: if you're building agents, invest time in your harness architecture and token efficiency before reaching for bigger models. Tools like ztk for output compression and proper framework choices (Flue, Cloudflare Agents SDK) will save you more than upgrading your context window or switching to a more expensive model tier.
Quick Hits
- @LayrKits shared results from their 2D Sprite Sheet Pipeline, showing off game-ready animations with a clean AI-assisted workflow. If you're in game dev, worth bookmarking.
- @elonmusk posted a Grok Imagine tutorial made entirely with Grok Imagine. Meta content creation at its finest.
- @Supermicro promoted their SuperCloud Software Suite for GPU cloud operations and data center management. Enterprise infrastructure doing enterprise infrastructure things.
- @0xblacklight retweeted a warning about surging supply chain attacks in the pnpm ecosystem, with practical steps to lock down your package management.
- @RayFernando1337 signal-boosted Sam Altman's announcement that ChatGPT accounts now work for OpenClaw sign-in. "Happy lobstering" indeed.
- @DataChaz shared a video referencing Karpathy's warning that 90% of AI advice dies in 6 months, pointing to a 2026 playbook for what to learn, build, and skip in AI agents.
The Agent Framework Moment
The agent ecosystem is experiencing what web development went through in the early 2010s: the transition from ad-hoc libraries to opinionated frameworks. @FredKSchott launched Flue, described as "the first agent harness framework," built on the premise that agents are ready for their library-to-framework moment. It's TypeScript-based, runtime-agnostic, and designed to feel like Claude Code but fully headless and programmable. The pitch is compelling: most agent logic lives in Markdown files (skills, context, AGENTS.md), not code.
@irvinebroque from Cloudflare responded by drawing the line between frameworks and infrastructure: "agent harnesses are like web frameworks. Let a thousand flowers bloom, no one-size-fits-all, right tool for the job. What agent harnesses have in common — they all benefit from using the Agents SDK to run in Durable Objects, the runtime designed for agents." This is a smart positioning play. Instead of competing with Flue, Cloudflare is positioning Durable Objects as the substrate that all agent frameworks should target.
Meanwhile, @mattpocockuk offered the clearest taxonomy of agent terminology I've seen, defining four terms that trip everyone up: Model (stateless next-token predictor), Harness (tools, system prompt, context management), Environment (the world the agent acts on), and Agent (model + harness + environment). As he puts it: "Opus is a model. Claude Code and Claude Web are different agents, because their harnesses differ — even though the models are the same." This kind of conceptual clarity is exactly what a maturing field needs. The fact that three different voices are converging on harness-centric thinking in a single day suggests the community is reaching consensus on where the real engineering challenges lie.
Agent Memory and Autonomous Workflows
The question of how agents remember and plan is generating significant discussion. @Av1dlive highlighted a git-backed memory layer for agents, referencing Demis Hassabis's statement that "memory is still unsolved and it is going to be required for AGI." The proposed solution is typed, indexed, audited, and synced, working across AI tools. It's a pragmatic approach: rather than waiting for models to develop perfect long-term memory natively, build external memory infrastructure.
On the workflow side, @doodlestein shared their evolving multi-agent workflow that chains together skills like "reality-check-for-project" to audit codebases, generate task lists, and then dispatch swarms of coding agents. The density of their prompts is remarkable, essentially compressing hours of project management into a few paragraphs of instructions that launch coordinated agent teams. It's a glimpse of what power-user agent orchestration looks like in practice: not a single agent doing everything, but a human directing multiple specialized agents through carefully designed skill chains.
The open-source "Agentic Design Patterns" book shared by @wsl8297 adds academic rigor to these practical explorations, covering 21 chapters from prompt chaining and routing to memory management, safety guardrails, and performance evaluation. The fact that this resource exists with Jupyter notebooks for every chapter signals that agent design is becoming a teachable discipline, not just folklore passed around on Twitter.
Local Inference Breaks New Ground
The local AI community had a banner day. @pupposandro released Luce PFlash, achieving a 10.4x faster time-to-first-token on 128K context with Qwen3.6-27B on a single RTX 3090. The technique is elegant: a small 0.6B drafter model scores token importance across the entire prompt, and the heavy 27B target only prefills the spans that matter. "128K prompt in 24.8 seconds" compared to llama.cpp's 257 seconds. That's the difference between usable and unusable for long-context applications.
@above_spec, quoted by @0xSero, challenged the conventional wisdom that you need 24GB GPUs for serious local LLMs: "Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: 41 tok/s at 16k context, 24 tok/s at 200k context." And @Michaelzsguo noted that Qwen 3.6 configs are circulating that deliver fast TPS on as little as 12GB VRAM. Taken together, these developments mean that a $300-400 consumer GPU can now run models that were cloud-only six months ago.
@paulabartabajo_ added another dimension by demonstrating browser control with LFM2-350M, a genuinely small model from @liquidai, fine-tuned with RL. The implication is that not every agent task requires a frontier model. If a 350M parameter model can control a browser, the deployment economics for specialized agent tasks become radically different.
Codex Gets Goal-Oriented
OpenAI's Codex shipped version 0.128.0 with a significant new feature: autonomous goal loops. @mattlam_, quoted by @gdb (Greg Brockman himself), described the /goal command as "Ralph loop on steroids." The mechanism is straightforward but powerful: set a goal, and after each agent turn, Codex automatically nudges the model to pick the next concrete action if the user doesn't intervene. Goal requirements map to evidence like files, test results, and PRs, and the model can only mark things complete, not redefine the goal. @fcoury noted the feature is still experimental, requiring a config flag in ~/.codex/config.toml to enable.
This is a meaningful step toward truly autonomous coding agents. The Ralph loop pattern (named after the "Internet Historian" workflow) has been popular in the Claude Code community, but baking it directly into the harness removes friction and standardizes the approach. Brockman's endorsement with "codex now has a built in Ralph loop++" suggests this isn't just a side experiment but a core product direction.
Agent Security and Token Hygiene
Two posts highlighted the unglamorous but critical work of securing agent workflows. @zodchiii raised the alarm about Claude Code reading .env files before you even type anything: "your API keys are now in the chat. Your password is now in the chat. You add 'don't read .env' to CLAUDE.md. Doesn't work." The solution is a specific settings.json configuration, not a prompt-level instruction. This is an important lesson: security boundaries for agents must be enforced at the harness level, not through model instructions that can be ignored.
On the efficiency side, @alphabatcher shared their experience with ztk, a 260KB Zig binary that compresses shell output before it reaches the model. The numbers are striking: git diff output went from 92,000 tokens to 18,000, and a passing cargo test dropped from 397 tokens to 21. "Stop buying bigger context windows while feeding your agent raw terminal sewage." The tool works by understanding what each command needs to preserve: diffs keep changed lines, tests keep failures, ls keeps structure. Over a 256-command session, they saved 5.8M tokens. For anyone running autonomous coding agents at scale, this kind of output hygiene is the difference between viable and prohibitively expensive.
AI Meets Wall Street
@shiri_shh showcased an AI-built insider trades scanner that reads SEC filings, flags clusters of executive buying, and emails the top trades every morning before market open. Built in four minutes using Xynth's platform (which wires Claude Opus 4.7 and Python to 3,000+ live market endpoints), it's a vivid example of how agent tooling is making sophisticated financial analysis accessible to individuals. Combined with Stripe's new Link wallet for agents, announced by @stripe and playfully tested by @Saboo_Shubham_ (whose agents immediately tried purchasing hardware), the financial infrastructure for autonomous agents is materializing rapidly. The gap between "AI agent demo" and "AI agent with a credit card" just closed.
Sources

The .env Setup That Keeps Claude Code From Leaking Your Secrets (Full Config Included)



What to Learn, Build, and Skip in AI Agents (2026)

AI Agent Memory Stack Everyone Must Use in 2026 (Builder's Guide)

I cut my Agent's context by 90% (here's how)
Codex 0.128.0 is huge, even better than a @thsottiaux reset. Codex is moving more goal oriented with a new /goal command, think Ralph loop on steroids: - /goal <objective> to set a new goal - after agent turn finishes, Codex injects a message nudging the model to pick the next concrete action, if the user doesn't type anything - goal requirements are mapped to evidence (files, test results, pr, etc.) - model can only update goal to mark things complete Also finally in version 128, "codex update" is supported 🎉
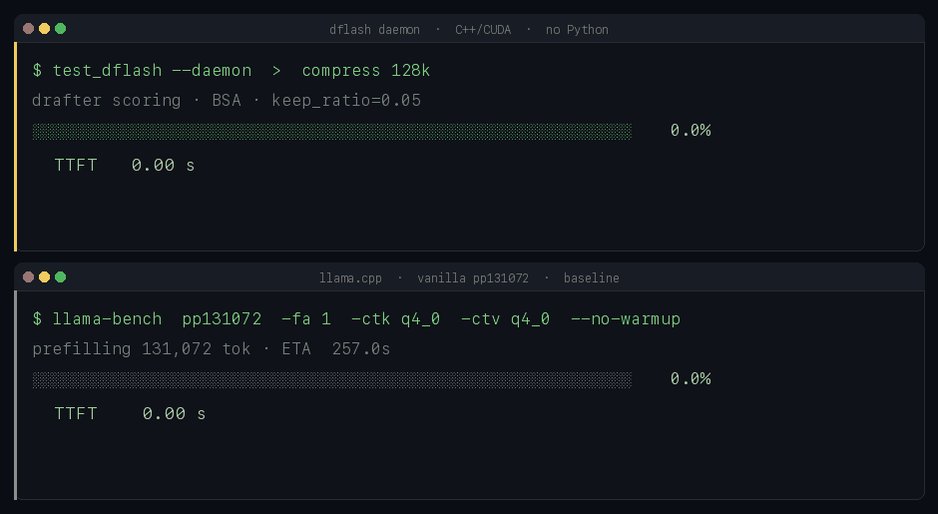
PFlash: 10x prefill speedup over llama.cpp at 128K on a RTX 3090
"You need a 24 GB GPU for serious local LLMs in 2026." Everyone repeats this. It's not true anymore. Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context Recipe + benchmarks below 🧵 https://t.co/sr1VjNMe4f
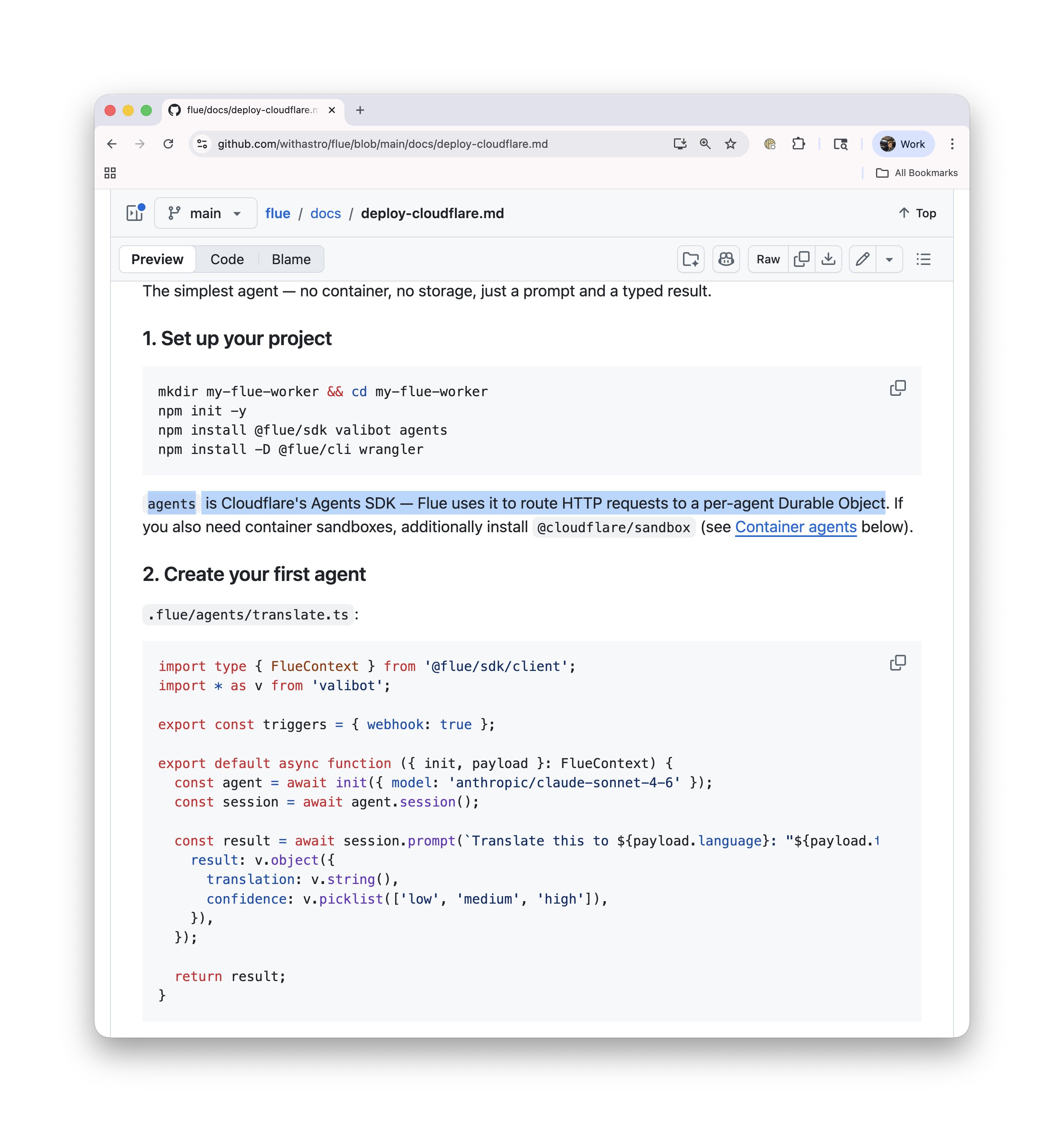
Introducing Flue — The First Agent Harness Framework Flue is a TypeScript framework for building the next generation of agents, designed around a built-in agent harness. Flue is like Claude Code, but 100% headless and programmable. There's no baked in assumption like requiring a human operator to function. No TUI. No GUI. Just TypeScript. But using Flue feels like using Claude Code. The agents you build act autonomously to solve problems and complete tasks. They require very little code to run. Most of the "logic" lives in Markdown: skills and context and AGENTS.md. Flue is like Astro or Next.js for agents (not surprising, given my background 🙃). It's not another AI SDK. It's a proper runtime-agnostic framework. Write once, build, and deploy your agents anywhere (Node.js, Cloudflare, GitHub Actions, GitLab CI/CD, etc). We originally built Flue to power AI workflows inside of the Astro GitHub repo. But then @_bgiori got his hands on it, and we realized that every agent needs a framework like Flue, not just us. Check it out! It's early, but I'm curious to hear what people think. Are agents ready for their library -> framework moment?


Today, we’re launching the @link wallet for agents. It lets you securely empower agents to spend on your behalf. Your payment credentials are never exposed and you approve every purchase. https://t.co/TcvEiVNth9 https://t.co/X0ad79EixS

How to create a game-ready 2D sprite sheet for ANY animation
I transformed this entire "come to Jesus moment" workflow into a new skill called "reality-check-for-project" on my paid skills site, https://t.co/Un9brY2G3l . Anyway, I'm applying it now to many of my in-progress "FrankenSuite" projects that I haven't had as much time to actively monitor and shepherd, like FrankenRedis, FrankenPandas, FrankenSciPy, etc. It's unbelievably helpful (really, I'm not just saying that). Almost like hiring a second person to go over all the stuff and give me an independent take on everything so we can get projects back on track towards completion. But without me needing to actually do much actively. All I do now is give this to Claude Code: "First read ALL of the AGENTS.md file and README.md file super carefully and understand ALL of both! Then use your code investigation agent mode to fully understand the code and technical architecture and purpose of the project. THEN apply /reality-check-for-project here in an exhaustive way." Then wait 15-20 minutes for it to crank away and follow up with something like this (basically just telling it to close all the gaps it found, followed by my standard prompt for turning plans into beads): --- › I need you to help me fix this. That is, making all the things that are unimplemented but which SHOULD have been implemented according to the beads and markdown plan. Figure out exactly what needs to be done to get us over the goal line with a finished, polished, reliable, performant project in line with the vision described earlier. OK so please take ALL of that and elaborate on it and use it to create a comprehensive and granular set of beads for all this with tasks, subtasks, and dependency structure overlaid, with detailed comments so that the whole thing is totally self-contained and self-documenting (including relevant background, reasoning/justification, considerations, etc.-- anything we'd want our "future self" to know about the goals and intentions and thought process and how it serves the overarching goals of the project.). The beads should be so detailed that we never need to consult back to the original markdown plan document. Remember to ONLY use the `br` tool to create and modify the beads and add the dependencies. --- Then I just do: "First read ALL of the AGENTS.md file and README.md file super carefully and understand ALL of both! Then use your code investigation agent mode to fully understand the code and technical architecture and purpose of the project. THEN: start systematically and methodically and meticulously and diligently executing those remaining beads tasks that you created in the optimal logical order! Don't forget to mark beads as you work on them. Use the /ntm swarm and /vibing-with-ntm skills to implement things in the optimal way according to /bv; launch 3 codex and 3 claude code instances to do this and use your looping feature to check in on the swarm every 3 minutes and feed more instructions to any idle agents." You can really see how all the skills are jointly compounding together to create a super-dense shorthand for communicating complex workflows to the agents very quickly and conveniently.

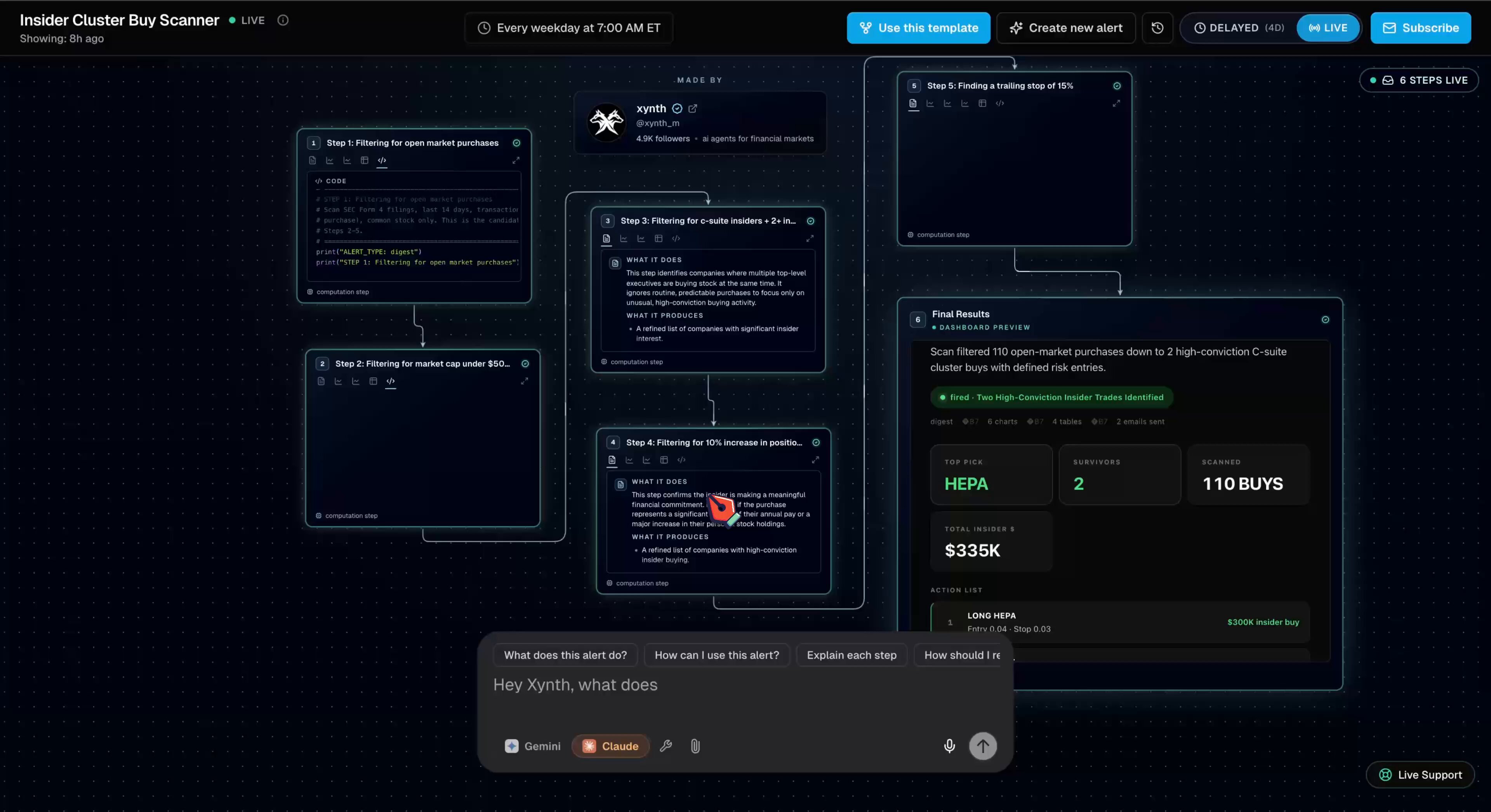
Xynth can now scan the stock market for you 24/7 ! Simply describe what you want monitored in plain English. Under the hood, we wire Claude Opus 4.7 + Python to 3,000+ live market endpoints to build your custom alert. The workflow lives in the cloud, hunting your setup the moment it hits. As part of this launch, we're giving free access to the top 5 most profitable alerts built so far. RT + comment "Xynth" below to get access ↓