Agents Go Headless as Box CEO Rethinks Software Pricing and Local Inference Hits 130 tok/s on Consumer GPUs
The AI agent ecosystem dominated today's discourse, with Box CEO Aaron Levie laying out a new pricing framework for headless software and multiple projects pushing agent orchestration forward. Meanwhile, local inference got a serious speed boost from Luce DFlash and DeepSeek-v4-flash, and Cursor shipped both a security review agent and a deep dive into their agent harness engineering.
Daily Wrap-Up
The throughline today is unmistakable: agents are no longer a novelty, they are becoming the primary consumers of software. @levie's lengthy post about headless software pricing wasn't idle speculation. It was a CEO of a major enterprise platform publicly working through the economics of a world where agents outnumber human users. When he writes that "every platform that goes headless will need to adopt a consumption model," he's describing a tectonic shift that makes traditional per-seat SaaS licensing look quaint. The fact that this post landed on the same day Cursor shipped always-on security review agents and @gkisokay outlined a full research agent workflow with Hermes tells you we've crossed from "agents are coming" into "agents are here, now figure out the business model."
On the infrastructure side, local inference continues its march toward parity with cloud. Luce DFlash hitting 130 tokens per second on a single consumer GPU with a 27B model is the kind of benchmark that makes you rethink your API budget. @quxiaoyin switching from Claude Code Max to DeepSeek and Hermes at $5 per week is anecdotal, but it maps to a broader pattern: the cost floor for capable AI keeps dropping, and developers are noticing. @0xSero ranking inference stacks (SGLang > vLLM > ExLlamaV3 > llama.cpp) suggests this space is maturing enough that people are developing real preferences and workflows.
The most entertaining moment was @journoverax breathlessly listing 69 open-source repos that supposedly replace every Anthropic product for $0/month, framed as insider knowledge from "a mid-level engineer at Anthropic." The engagement bait was strong, but the underlying tension is real: the open-source community is building fast alternatives to commercial AI tools, and the gap is narrowing. The most practical takeaway for developers: add exclude-newer to your uv configuration today. As @tdhopper explained, a 7-day dependency cooldown blocks most malicious package uploads before they can affect your projects, and it costs you nothing but a slight delay on bleeding-edge packages.
Quick Hits
- @StockSavvyShay shared AWS CEO's pushback on the "AI kills dev jobs" narrative, noting Amazon is hiring as many developers as ever while AI agents are "exploding" across industries.
- @ashwingop dropped Part 2 of the "Company Brain" series, diving into factual memory as the foundation layer for enterprise AI systems.
- @journoverax compiled 69 open-source repos positioned as free alternatives to commercial AI products, from Ollama replacing APIs to OpenHands replacing Claude Code.
- @mr_r0b0t showed off Hermes agent's architecture-diagram skill from @NousResearch, generating visual system diagrams on demand.
- @TheAhmadOsman wrote about building enough cloud-like infrastructure around a homelab that it functionally became "the cloud," a fun read for self-hosting enthusiasts.
- @wavedash launched browser-based gaming with no downloads, installs, or accounts required.
- @alexcooldev highlighted an indie iOS developer hitting $102k/month across 19 apps, sharing his own $25k/month journey with 3 apps as a case study in mobile persistence.
Agents Take Center Stage: From Frameworks to Business Models
The agent conversation has matured significantly. We're no longer debating whether agents will matter; today's posts were about how to build them, price them, and keep them from producing garbage. @levie's post was the anchor, offering a surprisingly detailed framework for how enterprise software pricing evolves when agents become the dominant users. His key insight is that consumption-based pricing will win for headless agent usage, while human seats survive but must include embedded API usage so agents can act on behalf of users. "If you don't do this, you're DOA," he wrote, which is blunt for a Fortune 500 CEO.
On the builder side, @gkisokay outlined a practical research agent architecture using Hermes v0.12.0: pick a domain, feed it sources, define your signal, save evidence, deliver daily briefs, and iterate on feedback. "Once you have a research agent, everything gets easier," he argued, positioning research as the foundational agent that feeds all others. Meanwhile, @KexinHuang5 introduced agent-managed sandboxes for scientific workloads, where AI agents autonomously orchestrate fleets of sandboxes to handle terabyte-scale processing, a pattern that points toward agents managing their own infrastructure.
The framework question is still unsettled, though. @samuelcolvin asked TypeScript developers what agent framework they actually use, listing Vercel AI, Mastra, and "Langpain-js" (the typo doing a lot of work there). His real question cut deeper: "Do you even use a framework, or pretend you don't need one and let the coding agent one-shot a slop micro-framework each time?" @Vtrivedy10 offered a more structured perspective, highlighting convergent design patterns across Cursor, LangChain, and others: tuning models with bespoke tools, using offline and online evals, and treating the context window as "a sacred boundary where computation happens." @bbssppllvv tackled a different angle entirely, releasing 2,000 DESIGN.md files from top products to help agents stop producing ugly UIs. And @xdotli shared required reading for anyone building agentic systems, focused on reducing entropy, which remains the core engineering challenge as these systems scale.
Local Inference Breaks New Ground
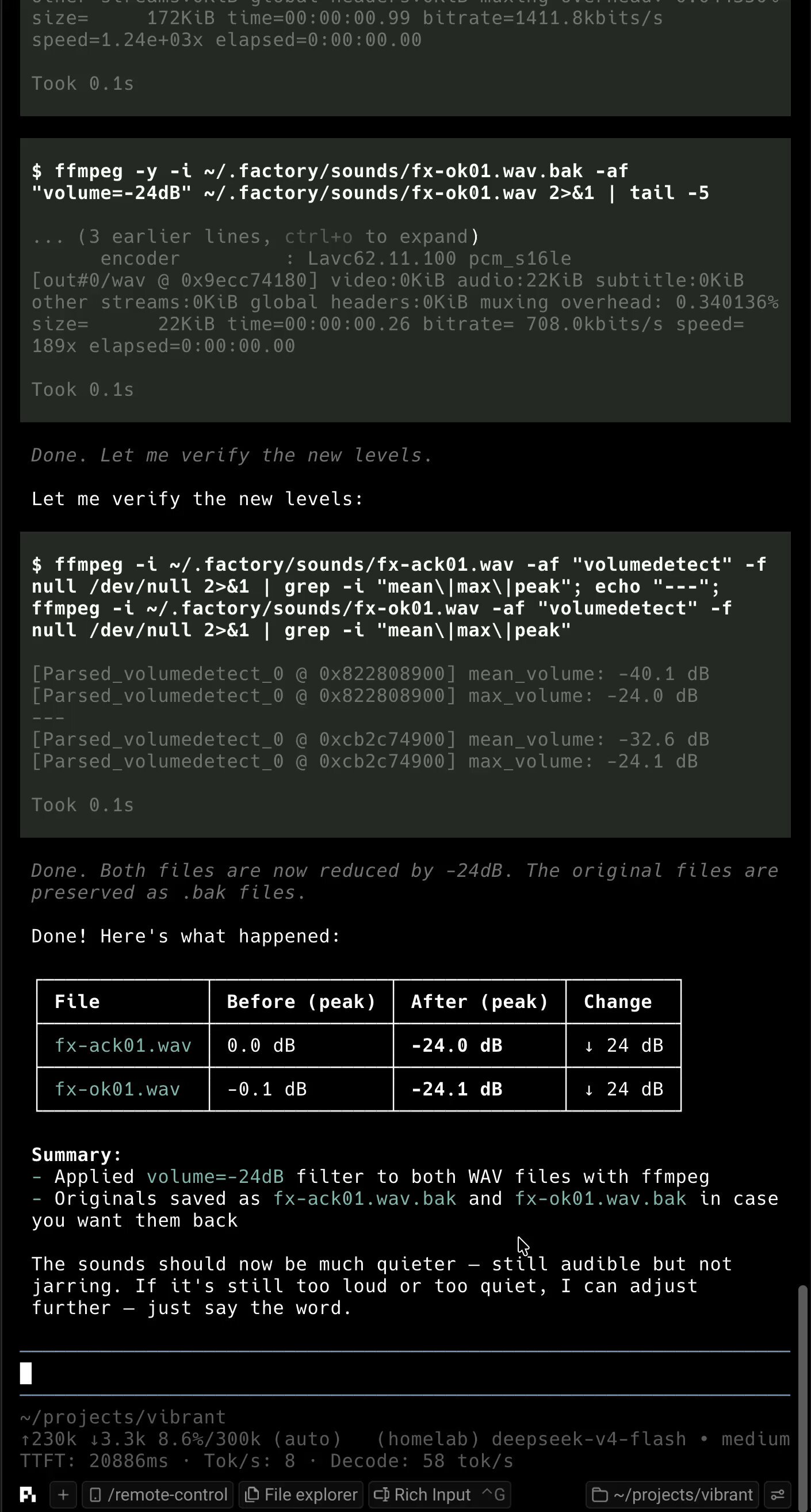
The local AI inference space had a banner day. @fahdmirza's post about Luce DFlash grabbed attention with hard numbers: 130 tokens per second on a single GPU, a 27B model running in 24GB VRAM, 128K context on consumer hardware, all through speculative decoding with a tiny draft model. "Raw C++ binary, zero Python in the engine," he noted, which explains the speed. The 3.4x improvement over standard autoregressive decoding is the kind of leap that changes cost calculations for small teams.
@0xSero offered a clear stack ranking for Nvidia hardware users: "SGLang > VLLM > ExLlamaV3 > Llama.cpp." In a separate post, he praised DeepSeek-v4-flash as "incredibly reliable and capable, logical," recommending that companies spending over $100k per year on AI should buy 8-10 RTX 6000s and have workers blind-test models. @quxiaoyin went further, claiming to have abandoned Claude Code Max entirely: "I can't believe I stopped using Claude Code max and entirely use DeepSeek and Hermes. It's so fast, 3x faster for the same task. I spent $5 last week." Whether that holds up for complex tasks is debatable, but the sentiment reflects real pressure on cloud AI pricing. @ClementDelangue added fuel by showing Qwen3.6 running on a Raspberry Pi via llamacpp, demonstrating that the floor for "usable local AI" keeps dropping.
Dev Tools Get Serious About Security and Quality
Cursor had a two-punch day. First, they launched Security Review for Teams and Enterprise plans, offering always-on agents that check every PR for vulnerabilities and run scheduled codebase scans with findings posted to Slack. Then they published a deep dive into their agent harness, explaining how they make models "faster, smarter, and more token-efficient" inside Cursor and how they test improvements, monitor degradations, and customize for different models.
Security was a broader theme. @zodchiii highlighted that Anthropic's CISO revealed 90% of their code is written by Claude, then explained how they protect secrets during AI-assisted development. "Your .env file is the weakest link in your entire AI workflow," he warned. @teej_m amplified @tdhopper's advice on adding a 7-day dependency cooldown using uv's exclude-newer setting, calling it essential for every Python project: "Do this today. Do not wait. This change will save your ass."
On code quality, @mattpocockuk addressed the growing problem of AI-accelerated software entropy, offering guidance on de-slopping codebases ruined by AI-generated code. And @steipete shipped Crabbox 0.1.0, a tool for running agent test suites on remote Linux boxes when your local machine can't keep up: "Too many agents, too many test suites, one very tired Mac."
API Infrastructure: WebSockets and Prompt Optimization
Two posts pointed at infrastructure-level improvements for AI workflows. @badlogicgames discussed OpenAI's WebSocket mode for the Responses API, noting that the real speed improvement comes not from the transport layer but from "caching context OpenAI side, and only sending deltas as the context grows." He referenced @OpenAIDevs' claim of 40% faster end-to-end workflows and noted that his own tool has supported WebSocket mode since March, though delta-based context sending remains unimplemented.
@GptMaestro shared an explanation of GEPA, a technique that optimizes prompts before inference rather than cramming more into the context window. This represents a shift in thinking about prompt engineering: instead of adding more context, reduce and refine what you send. Both posts point toward a future where the infrastructure around model calls matters as much as the models themselves.
Sources
S
$AMZN AWS CEO pushed back on the idea that AI is killing software jobs by saying Amazon is hiring as many developers as ever.
He said AI agents are “exploding” across every industry & moving faster than expected changing the developer job rather than eliminating it. https://t.co/NS3F9XDjIM

W
Play incredible games in your browser. No downloads No installs. You don't even need an account.
F
💥 Luce DFlash just changed local AI inference
🚀 130 tok/s on a single GPU — no vLLM, no llama.cpp, no compromises
🔹 27B model on 24GB VRAM
🔹 3.4x faster than standard autoregressive decoding
🔹 Raw C++ binary — zero Python in the engine
🔹 Speculative decoding with a tiny draft model doing the heavy lifting
🔹 128K context on consumer hardware
🔥 Full step-by-step demo below 👇
M
Architecture-diagram is one of my favorite @NousResearch Hermes agent skills, NGL! https://t.co/91cbfZHc0v
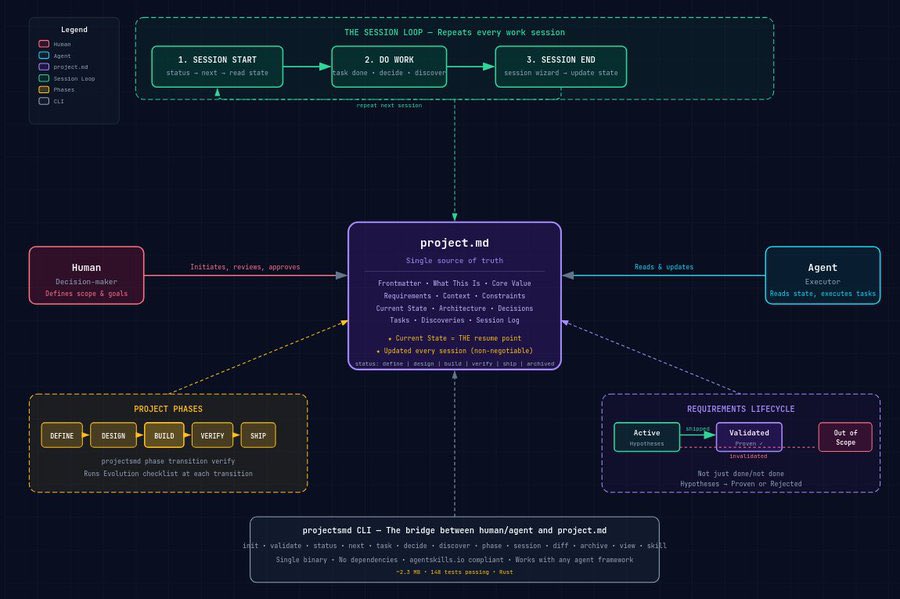
M
mr_r0b0t
@mr_r0b0t
projects.md
D
Anthropic CISO just told you that 90% of their code is written by Claude.
Then he explained how they protect their own secrets while doing it.
Why your .env file is the weakest link in your entire AI workflow?
Watch it, then grab the full security config below👇 https://t.co/EahR5ro3W7

Z
zodchiii
@zodchiii
The .env Setup That Keeps Claude Code From Leaking Your Secrets (Full Config Included)
K
One of the most insightful articles I've seen related to building production AI agent systems
gg @rohit4verse
R
rohit4verse
@rohit4verse
What to Learn, Build, and Skip in AI Agents (2026)
S
TypeScript people - I have a question:
What's the best (least bad, most trendy) Agent Framework right now?
Vercel AI, Mastra, Langpain-js - any other popular options?
I mean for general applications (e.g. not coding agents).
Do you even use a framework, or pretend you don't need one and let the coding agent one-shot a slop micro-framework each time?
K
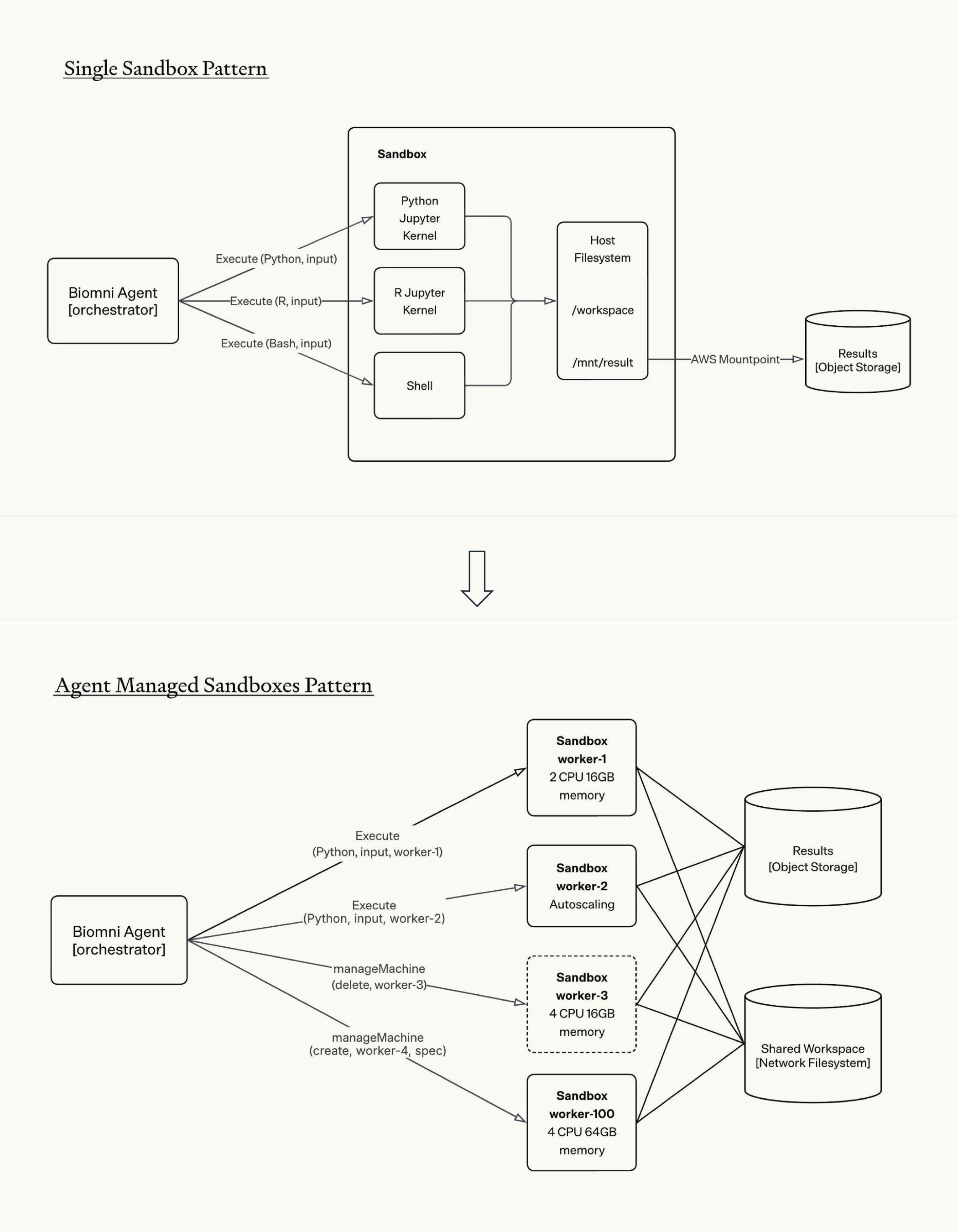
Introducing agent-managed sandboxes: AI agents to autonomously orchestrate fleets of sandboxes to handle massive workloads.
This unlocks adaptive scaling, from small tasks to terabyte-scale processing, while minimizing unnecessary cost.
With parallel sandboxes, throughput multiplies, and agents can explore multiple ideas simultaneously.
Checkout our new technical report of this sandbox pattern:
P
phylo_bio
@phylo_bio
Agent-managed sandboxes for scientific workloads
A
Company Brain, Part 2: Factual Memory
Company Brain, Part 2: Factual Memory
In the first piece, I argued that a real Company Brain needs three kinds of memory: factual memory, interaction memory, and action memory. Factual mem...
A
This guy is a really great case study for iOS apps. He has 19 iOS apps, currently making $102k/month, that’s honestly crazy.
I’m at around $25k/month with 3 mobile apps, and I’m going to keep releasing more and pushing for more growth.
Keep going 🚀
And I remember the first time I followed him, it was when all of his apps were removed from the App Store. 😄
S
seraleev
@seraleev
Seeing $100k+/month in revenue for the first time 🚀 Crying from happiness. It took me 2.5 years to reach this. From zero. Had to go through hell: account deletion, lawsuits, losses, debt, frozen accounts, countless mistakes. Just believe in yourself and don’t give up. You can work in public. Don’t be afraid to make mistakes. That’s how you find what works. And the most unusual part, you can scroll through my entire X. I documented every step. What I shipped, what I tested. You can watch the video about me. @adamlyttleapps made a great episode, and nothing has changed since then. I just keep hitting the same point, slowly but consistently, and it’s starting to pay off.
X
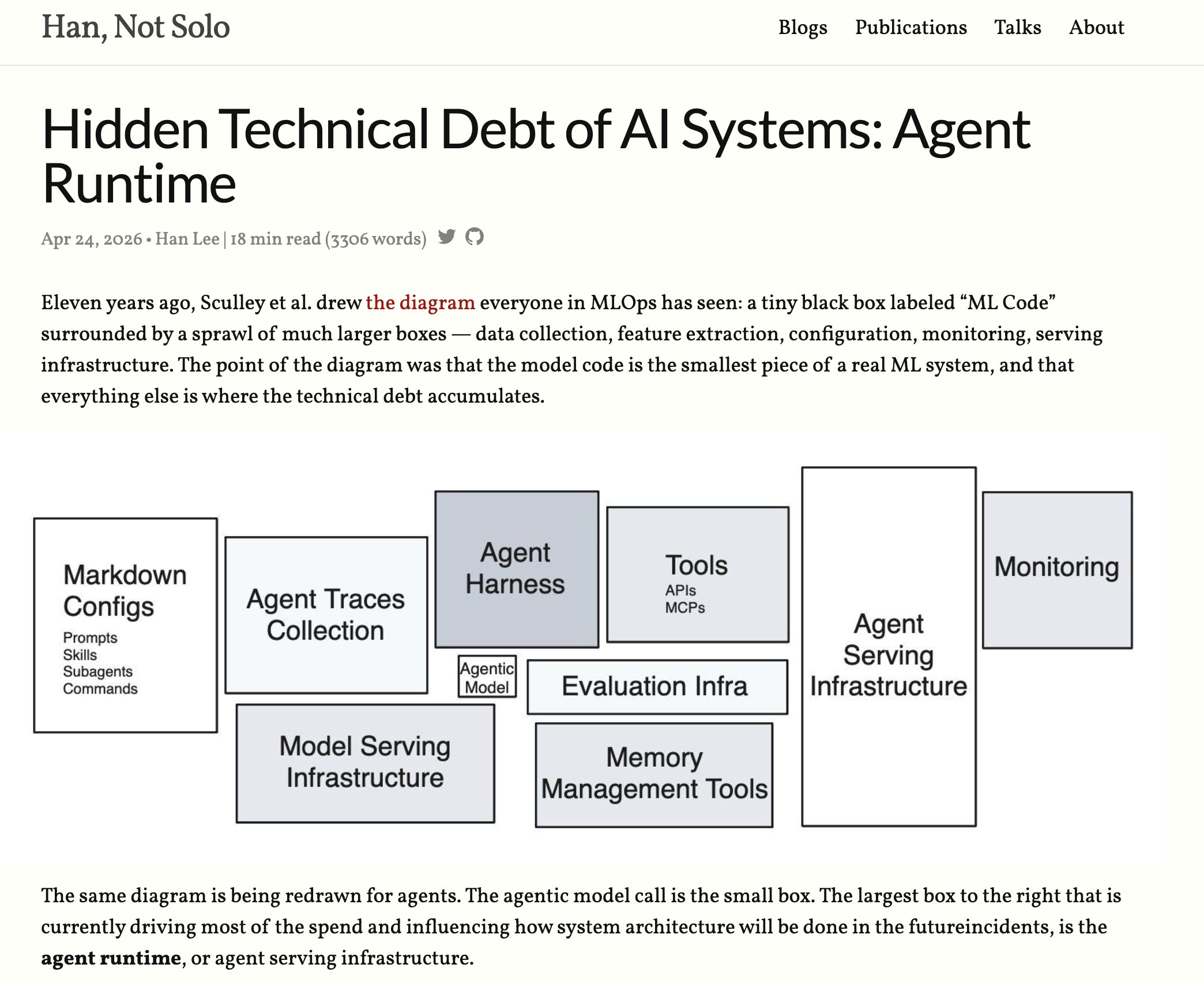
must read for everyone who wants to reduce the entropy of their agentic systems https://t.co/Z2vkRQ6jb5
C
Pi + @huggingface llamacpp + Qwen3.6 = 🔥🔥🔥🔥
B
badlogicgames
@badlogicgames
turns out not killing the prefix cache all the time and notnhaving a humongous set of tools and a massive system prompt is good for local model use. who'd have thunk. https://t.co/lWjRoikJeM
V
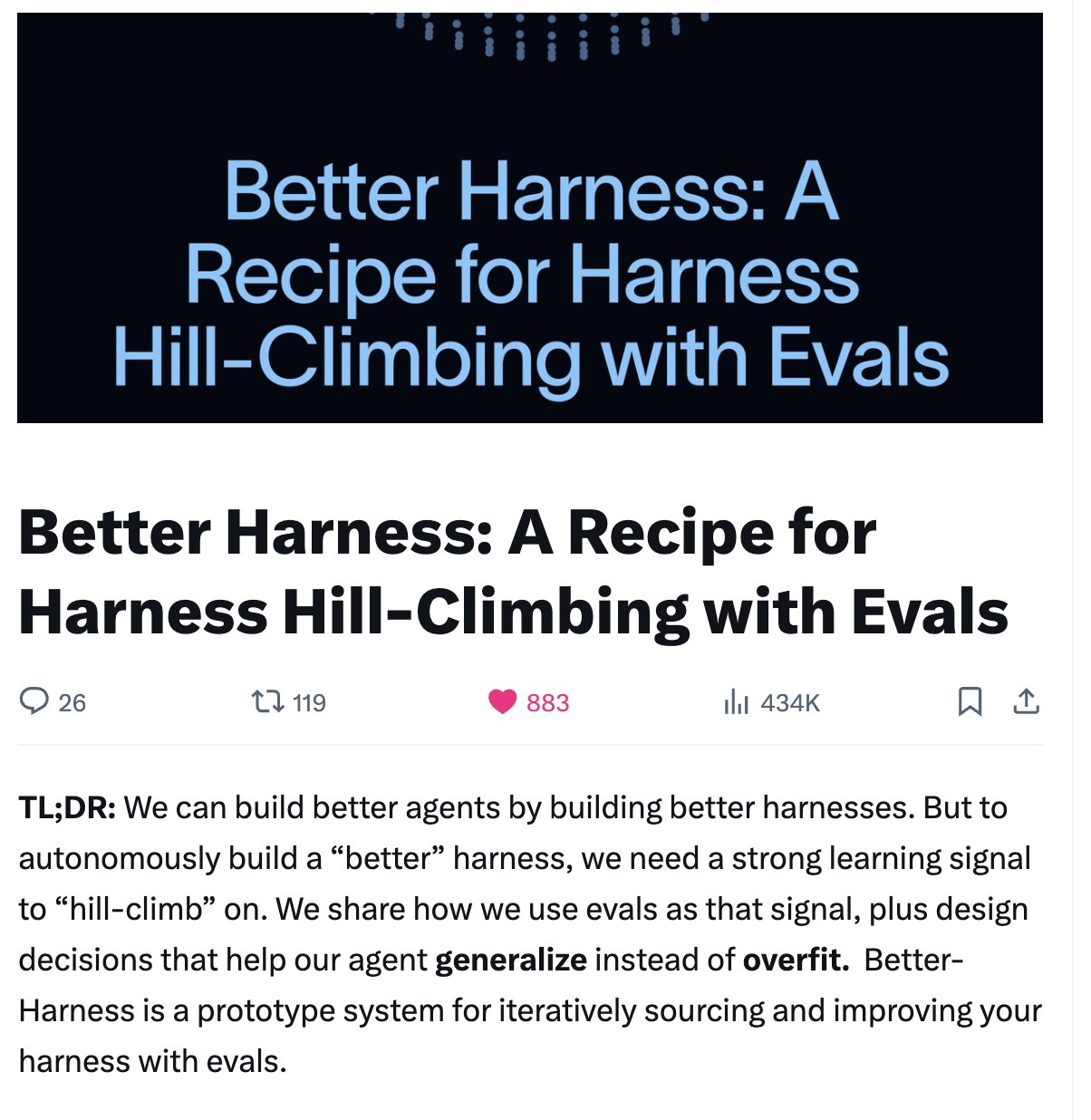
tweeted about this yesterday and Cursor already dropped the alpha today! 🚀very cool to see how us, them, and others have converged on good design patterns in Agent + Harness Engineering:
1. Tuning different models in the Harness with bespoke tools/prompts
2. Using offline+online evals & dogfooding to measure performance
3. Working backwards from a customer/agent goal and iteratively updating the harness to measure changes
4. The role of the harness in shaping & extending model capabilities on tasks that they can’t do out of the box
5. The Context Window is a sacred boundary where computation happens + giving agent autonomy and good instructions in managing context.
sharing + linking some snippets from blogs we’ve done over this year across our Open Source work with Deep Agents and in the Agent Products we’ve shipped in LangSmith if anyone wants to dive deeper
big fan of sharing open research and patterns, love to see Cursor pushing this :)

C
cursor_ai
@cursor_ai
Our agent harness makes models inside Cursor faster, smarter, and more token-efficient. Here's how we test improvements to the harness, monitor and repair degradations, and customize it for different models. https://t.co/YIXcEZW6ud
M
Agents make ugly UIs because they've never seen good design.
We've been fixing that, 2,000 DESIGN.md files from the world's best products, structured for a model to read and learn. Colors, type, spacing, layouts and more.
Free. https://t.co/mJaKNHba0O https://t.co/GkbyV1HMRQ
C
Cursor Security Review is now available for Teams and Enterprise plans.
Run two types of always-on agents:
1. Security Reviewer checks every PR for vulnerabilities and leaves comments.
2. Vulnerability Scanner runs scheduled scans of your codebase and posts findings in Slack. https://t.co/TKaqYKJxm8
P
I've spent most of my career dealing with headless browsers, here's how we optimize ours for the absolute best performance:
P
pk_iv
@pk_iv
Benchmarks are marathons, here’s how we 5x’d our browser performance
»
Do this today. Do not wait. This change will save your ass. Every Python project should add this.
Then do everything else in the thread.
But do this today.
T
tdhopper
@tdhopper
Add a 7-day dependency cooldown. uv's `exclude-newer` refuses any version published inside a rolling window. With 7 days set, today's malicious uploads would not be considered for resolution at all. Most malicious uploads are caught within that window.
V
a mid-level engineer at anthropic just talked about the repos
people use to replace their own products
ollama -> replaces the API. $0 instead of $240/year
open-webui -> replaces Claud AI 52,000 stars
openhands -> replaces claude code. 48,000 stars
they built the products
the community built the alternatives
both sides use github
only one pays
69 repos. the full stack. $0/month.
like + bookmark

S
seelffff
@seelffff
69 Best Open-Source AI Repositories in April 2026
X
I can’t believe I stopped using Claude Code max and entirely use DeepSeek and Hermes. It’s so fast, so so fast, 3x faster for the same task. So cheap. I spent $5 last week and never need worry about being rate limited or usage hit limits very two hours. For most tasks it’s perfect enough.
G
There’s one Hermes use case for everyone, and if you're not using it, you're already behind.
Do yourself a favour and build a research agent as I outline below; it will change the way you work.
Mine researches my topics of interest and cuts through the noise to find what actually matters.
Every day, it watches the AI/agent space, picks out useful signals, writes research briefs, suggests content angles, tracks what I ignore, and Hermes keeps improving parts of its own workflow.
The basic version is almost free:
1. Pick a domain: AI, crypto, startups, sales leads, competitors, papers, jobs, whatever.
2. Give it sources: X lists, RSS feeds, blogs, GitHub repos, docs, newsletters, YouTube transcripts.
3. Define signal: What should it care about? New tools, benchmarks, launches, funding, tutorials, strange patterns, useful claims.
4. Save the evidence: Links, dates, summaries, claims, and why it matters in a vault.
5. Deliver a daily brief: Discord, Slack, Notion, email, Obsidian, and local markdown.
6. Give feedback: “More like this. This source is noisy. This is useful. This is mid.”
That is enough for the loop to start. Once you have a research agent, everything gets easier:
- Content agents need research
- Trading agents need market context
- Sales agents need account intel
- coding agents need docs and changelogs
- Strategy agents need a fresh signal
With a daily stream of inputs, generating ideas for outputs becomes much easier.
If you want it, I’ll share the full research agent setup I use.
N
NousResearch
@NousResearch
Hermes Agent v0.12.0 - “The Curator Release” https://t.co/i6uAAkuD2z
A
As agents become the biggest users of software, then all software has to be available in a headless fashion. Agents won’t be using your UI, they’ll be talking to your APIs.
So the question becomes what is the business model of software and this headless approach in the future?
Here are a few thoughts on how everything plays out based on what we’re seeing and doing at Box, but also conversation with other platforms.
1) Seats don’t go away for *people*. Seats are still a convenient and efficient way to have a customer use technology predictably for a set of users within a baseline set of usage. The key, though, is that when the customer pays for a seat, it has to come with a set of usage of APIs on behalf of that user that the agent can use on their behalf.
The user will need to be able to interact with their data and the underlying tool via any agent they work with, and an embedded amount of usage will come with the seat. I would imagine most software -Box included- will enable seats to work with their data at a relatively high volume via systems like ChatGPT, Codex, Claude, Gemini, Cursor, Copilot, Perplexity, Factory, Cogniton, et al. quite seamlessly. If you don’t do this, you’re DOA.
2) Agents may have “seats” if they are doing stateful work in the system, but they will be priced very differently than people. Seats (or the equivalent) can make sense when you have an agent that has its own workspace, stores its own data, needs a different set of permissions compared to the user, and so on.
If a company wants this agent to be around for long period of time, that may very well look like another “user” in the system. Openclaw-style agents highlight what this future could look like.
The only issue on pricing here is that one customer could decide to do all their work in 1 agent, and another might split it into 1,000 agents. So pricing like a human seat is nearly impossible and impractical; each company will have a different approach for this as it gets tricky perfectly trying to capture all the value within an agent seat.
3) The dominant pricing for headless use that goes above the seat allotment, or when an agent is firmly acting on their own, will be a consumption model. Many enterprises software platforms have previously operated like this with PaaS options, and agents will look like another machine user of their system.
In some cases the APIs might get priced just as they did previously, but in other cases there may need to be new types of APIs that represent the work an agent would do in one go -more akin to an outcome- instead of a series of API calls. This is especially germane when the headless software also has an agentic use-case embedded within in, such as orchestrating the process within their own system via AI.
Overall the growth of this usage pattern is effectively unbounded as the use-cases for agents operating on data in these systems will dramatically exceed what people do with their data and tools today. Every platform that goes headless (which will be anyone that wants to take advantage of agents) will need to adopt a model like this. Some may fight it initially but it’s an inevitably as there will always be more and more agents outside your platform than people.
Overall, there’s a lot of really interesting changes left to come in software due to headless use of these systems. Early days.
G
Clear explanation of how GEPA optimizes prompts before inference instead of just cramming more into the context window.
https://t.co/xkyPtCOT6N
Q
quarqlabs
@quarqlabs
Exploring GEPA
A
My Homelab Is Technically the Cloud Now
My Homelab Is Technically the Cloud Now
Someone asked me recently if I’d duplicated my local homelab into the cloud. Not really. The more accurate answer is that I’ve built enough cloud-like...
M
AI helps you move faster, but it just accelerates software entropy.
Here's how to de-slop a codebase ruined by AI, with one skill: https://t.co/VYbfMH2of9

0
SGLang > VLLM > Exllamav3 > Llama.cpp
IF you have any Nvidia hardware this is the play.
P
Too many agents, too many test suites, one very tired Mac. Run them remote:
Crabbox 0.1.0 🦀
⚡ Remote Linux test boxes (AWS, Hetzner)
🔁 Dirty checkout sync
🦀 Warm boxes with friendly slugs
⏱️ Idle auto-free
brew install openclaw/tap/crabbox
https://t.co/SEj2XRpaD1
0
I LOVE Deepseek-v4-flash, incredibly reliable and capable, logical. It's lacking in frontend but I have MiMo for that.
I would recommend any company spending 100k+ a year on AI to purchase 8-10~ 6000s and have a few of the works to have them blind test these models for work. https://t.co/Z5eOi92H6J
M
https://t.co/TgG5bkXUdV's been supporting OpenAI's WebSockets mode since March. /settings > transport. the difference between SSE and WS for e.g. Spark is not that stark in terms of tokens/sec.
the real speed up actually comes from caching context OpenAI side, and only sending deltas as the context grows.
pi currently does not implement the latter. hmmmmmm
O
OpenAIDevs
@OpenAIDevs
⚙️ We made agent loops faster with WebSockets in the Responses API As Codex got faster, the bottleneck moved from inference to inefficient API calls WebSockets keep response state warm across tool calls, helping workflows run up to 40% faster end to end https://t.co/nFeUEdRdKt