Coding Agents Hit 60% of Merged PRs at Ramp While Local Inference Gets Surprisingly Fast on Consumer Hardware
AI coding agents are moving from experiment to production, with Ramp's internal agent now authoring the majority of their merged pull requests and multi-agent review loops becoming standard practice. Meanwhile, local inference on consumer hardware is having a moment, with 35B parameter models running smoothly on MacBooks and NVIDIA's GB10s finding fans for always-on edge deployment. The Claude Code skills ecosystem continues to expand as Obsidian officially embraces AI agents for vault management.
Daily Wrap-Up
The throughline across today's posts is unmistakable: AI agents aren't prototypes anymore, they're coworkers. Ramp's internal coding agent "Inspect" now authors over 60% of their merged PRs. Peter Steinberger has codex running on every commit, spawning review agents that spawn fix agents in recursive loops. Dan Rosenthal is running an entire agency where Claude Code is the primary interface and 79 skills power daily operations. We've crossed from "can agents do useful work?" to "how do we manage fleets of agents doing useful work?" and the organizational implications are only starting to land.
On the hardware side, the local inference crowd is quietly winning converts. Harrison Kinsley's praise of NVIDIA's GB10s for their low power and silent operation, combined with reports of Qwen 35B running fast on MacBooks via optimized quantization, suggests that the "cloud vs. local" debate is becoming less binary. The practical reality is that many developers want always-on, private, zero-API-cost inference for routine tasks, and the hardware is finally catching up. Meanwhile, a fascinating deep dive on HBM economics from a semiconductor architect explains why this GPU memory arms race is structurally different from past DRAM cycles, tying token throughput directly to HBM size times bandwidth as a first principle.
The most entertaining moment was Jeffrey Emanuel's marathon post about "Dueling Wizards," a system where multiple AI models independently generate ideas, then score and critique each other's work in adversarial rounds. It's essentially debate club for LLMs, and GPT-5.5's own meta-analysis of why the approach works reads like a PhD defense. The most practical takeaway for developers: if you're building with coding agents, study Ramp's approach of embedding agent workflows into existing project management tools like Linear rather than creating separate agent-specific infrastructure. Context lives where work lives, and agents that can access structured project context outperform those operating in isolation.
Quick Hits
- @badlogicgames RT'd that Ghostty is leaving GitHub, with creator @mitchellh departing after 18 years on the platform. A notable move in the ongoing conversation about developer infrastructure independence.
- @Scobleizer flagged a writeup covering 199 pitches from YC W26 Demo Day, calling it the best demo day summary he's ever seen.
- @ashtom (GitHub CEO Thomas Dohmke) RT'd a video where two Anthropic engineers explain why most people use less than 10% of Claude's actual capabilities.
- @Alfred_Lin shared "A New Token Rule For Engineering Leadership," arguing all companies need to close the gap between teams getting massive AI leverage and those barely touching the tools.
- @heyconstella announced a research canvas designed for neurodivergent researchers, featuring visual search across 475M+ papers.
- @DSPyOSS RT'd a one-word endorsement of DSPy. That's it. That's the post.
Agents Take Over the Codebase
The agent-in-production story has shifted from aspiration to operational reality, and the numbers are getting hard to ignore. @karrisaarinen highlighted that Ramp's internal coding agent "Inspect" now authors over 60% of their merged pull requests, with the key insight being integration with Linear where "the work and context already live." This isn't a toy demo. It's a production system at a major fintech company that has fundamentally changed how code gets written and shipped.
The automation doesn't stop at code generation. @steipete described a recursive agent pipeline where "codex now runs on each commit we land, reviews it, and if a booboo is found, a new codex spins up and makes a PR for the fix. Then a review agent spins up. If an issue is found, another agent will fix the issues (up to 5 loops)." What's notable here is the self-limiting design with a five-loop cap, an acknowledgment that infinite agent recursion needs guardrails.
@dan__rosenthal took the concept furthest, describing an entire agency built around Claude Code as the primary interface, with 79 skills, 26 agents, and a "Company OS" stored in git. His team of 20 runs client operations through a system where "AI does the legwork, but humans ship." The infrastructure includes safety hooks gating 94+ risky operations and a self-improvement loop where performance metrics feed back into the system. Meanwhile, @derekmeegan released /browser-trace, a skill that gives agents full observability into browser sessions, dumping network requests, DOM content, and screenshots into a searchable filesystem. The trend is clear: the tooling layer around agents is maturing fast, and the teams investing in structured agent infrastructure are pulling ahead of those still experimenting ad hoc.
Local Inference Finds Its Sweet Spot
The local AI inference story isn't about beating cloud performance anymore. It's about carving out a distinct niche where always-on, private, zero-cost inference makes more sense than an API call. @Sentdex made the case for NVIDIA's GB10 units, noting they offer "very low power usage, make no noise, generate very little heat, take up little space. Always on and available. 50 t/s with plenty of very solid MoEs." This was a direct rebuttal to criticism that the Spark hardware is "too slow to do anything real with," and the counterargument is compelling for developers who want persistent local inference rather than peak throughput.
On the software optimization side, @DataChaz reported running Qwen 35B locally on a MacBook with impressive speed, crediting Google's TurboQuant quantization scheme. The ability to run a 35B model on consumer hardware with "zero setup required" and full offline privacy represents a meaningful threshold. @MatthewBerman pointed to "Nightshift," a tool for autonomous ML research on Apple Silicon using the MLX framework, describing it as "AutoResearch but for MLX." The pattern here is the Apple Silicon ecosystem developing its own inference stack that's increasingly competitive. For developers who do repetitive coding tasks, local models that are always warm and never rate-limited may be more valuable than cloud models that are occasionally faster but require network calls and API management.
The Claude Code Skills Ecosystem Expands
Obsidian's official embrace of AI agents marks a significant moment for the knowledge management space. @obsidianstudio9 reported that Obsidian CEO Kepano personally created and released obsidian-skills for Claude Code, covering Markdown syntax, database operations, JSON Canvas editing, CLI vault operations, and web content ingestion. The Japanese-language post captured the significance well: Obsidian is now officially designing "with the premise that AI agents will manage your vault."
This dovetails with the broader Claude Code skills culture visible in today's posts. @mauriciord praised the /grill-me skill for helping understand feature implementations and explore design reviews with teammates before creating plans. @mattpocockuk recommended the related /grill-with-docs variant. These aren't general-purpose prompts. They're structured workflows that encode specific development practices into repeatable agent behaviors. The skills ecosystem is becoming a new distribution channel for developer best practices, and tool makers like Obsidian officially joining signals it's moving beyond the early-adopter phase.
AI Memory Hits Its Architectural Limits
The question of how AI systems remember things surfaced in two distinct but related conversations. @kimmonismus highlighted Engramme's "Large Memory Models," a new architecture designed specifically around human memory patterns rather than RAG or vector search. The founding team closed their Harvard lab to build it, bringing 160+ publications from Nature and ICLR. Whether the approach delivers on its promise remains to be seen, but the bet is that current memory solutions are architectural dead ends.
@rohit4verse offered a more granular critique, responding to LangChain CEO Harrison Chase's walkthrough of four agent memory approaches. The core objection: "All four assume the model is still holding the right tokens. It isn't. At token 4,096 the cache ran a silent eviction nobody wrote." The provocative claim that "first founder to write the eviction policy ships a 100B agent that remembers a person" frames memory management not as a feature but as the fundamental unsolved problem in agent development. Both posts point to the same gap: as agents take on longer, more complex tasks, memory architecture becomes the binding constraint.
AI-Powered Debugging and the Vibe Coding Movement
Two posts captured different ends of the AI coding spectrum. @moofeez shared results from post-training Qwen3-Coder to use an actual debugger, pushing solve rates from 70% to 89% while cutting median turns to fix from 46 to 19. The model "reasons from execution, inspects live variables and call stacks, sets breakpoints, steps, and evaluates expressions." This represents a meaningful advance: AI models that don't just read code but interact with runtime state the way human developers do.
@naval released a podcast covering the cultural shift around vibe coding, with chapter titles ranging from "Vibe Coding Is a Video Game with Real-World Rewards" to "The Beginning of the End of Apple's Dominance." The most provocative segment, "Pure Software Is Uninvestable," suggests that if AI collapses the cost of building software to near zero, the defensibility of software businesses fundamentally changes. Whether or not you agree, the framing captures where the discourse has moved: from "will AI write code?" to "what happens to the entire software economy when it does?"
The HBM Bottleneck Explained
@labubu_trader shared an English translation of a deep semiconductor architecture analysis from colleague @fi56622380, and it deserves attention. The core thesis derives a first principle of AI inference economics: token throughput equals HBM size times HBM bandwidth. Using an airport shuttle bus analogy, cabin size represents HBM capacity (how many requests' KV caches fit simultaneously) while door width represents bandwidth (how fast tokens generate). The analysis argues this time is structurally different from past DRAM cycles because "when demand has been physically locked into exponential growth" by the inference paradigm's requirements, the supply-side dynamics change fundamentally. For developers tracking infrastructure costs, understanding this hardware constraint explains why inference pricing follows the curves it does and why edge inference on devices like GB10s represents a genuinely different cost structure rather than just a slower version of cloud.
Sources
K
Ramp’s team knows what they’re doing.
They built Inspect, an internal coding agent that now authors over 60% of their merged PRs.
To make it scale, they brought it into @linear, where the work and context already live. https://t.co/ejrMvG7Eim

L
linear
@linear
Ramp’s internal coding agent now writes 60%+ of their merged PRs. With Linear as the underlying layer for structured product context, it can take on issues and work them to completion. Here’s how they got there: https://t.co/TA4AJyk8PI https://t.co/TRPXRJcTUI
り
【速報】
Obsidian公式がAIエージェント用スキルを正式リリース😳
CEOのkepano自らが作ったobsidian-skillsが公開された。
Claude CodeにObsidianの使い方を教えるスキル集👇
・Markdown構文の正しい扱い方
・Bases(データベース機能)の操作
・JSON Canvasの生成と編集
・CLIでのvault操作
・Webコンテンツの取り込み
5つのスキルが1セットになってる。
つまりObsidian公式が「AIエージェントにvaultを任せる」前提で設計し始めた。
この流れは確実に加速する🔥
https://t.co/vDqBqHsPOz
A
A New Token Rule For Engineering Leadership
A New Token Rule For Engineering Leadership
All companies need to be closing the gap between (a) their teams getting massive leverage from AI tools and (b) those barely touching them. -- @lorenc...
C
HOLY MOLY running a 35B model locally on a MacBook shouldn’t be THIS FAST 🤯
Spent my weekend in @atomic_chat_hq testing Qwen 35B vs. Qwen 27B on my local machine.
I had them generate a fully animated HTML/Canvas car mini-game (demo below),
... and both models breezed through the physics and parallax scrolling without a hitch!
The secret sauce here is the Atomic Chat app.
Because it's perfectly optimized for Mac and uses Google's new TurboQuant under the hood, you can run heavy open-source models flawlessly while keeping top-tier output quality 👊
Other perks:
→ ZERO setup required
→ Access 1,000+ models completely free
→ 100% offline and private
→ Zero API limits
... and MUCH more!
I dropped the prompt I used in the 🧵↓
Spin it up locally and let me know what you get!
H
While I also have a bunch of GPUs, I really enjoy the GB10s I have, which are the same as Sparks. Very low power usage, make no noise, generate very little heat, take up little space. Always on and available. 50 t/s with plenty of very solid MoEs. https://t.co/YuLx7jshve

J
jasondfarris
@jasondfarris
@AlexFinn Spark is too slow to do anything real with. Only good for taking pictures it of for twitter clout. I know, I have two. https://t.co/ybjyrTErNE
M
I post-trained Qwen3-Coder to fix bugs using an actual debugger. The result:
Solve rate: 70% → 89%
Median turns to fix: 46 → 19 (-59%)
Instead of just reading code or print-debugging, it:
- reasons from execution
- inspects live variables and call stacks
- sets breakpoints, steps, and evaluates expressions
M
Nightshift - Overnight Autonomous ML Research on Apple Silicon.
Think AutoResearch but for MLX
https://t.co/r0TFLl944g
R
Harrison Chase(LangChain CEO) just walked through four ways to give an agent memory.
All four assume the model is still holding the right tokens.
It isn't. At token 4,096 the cache ran a silent eviction nobody wrote.
The user's name was in that batch.
First founder to write the eviction policy ships a 100B agent that remembers a person.

P
Pseudo_Sid26
@Pseudo_Sid26
How AI Actually Remembers (Full Guide)
D
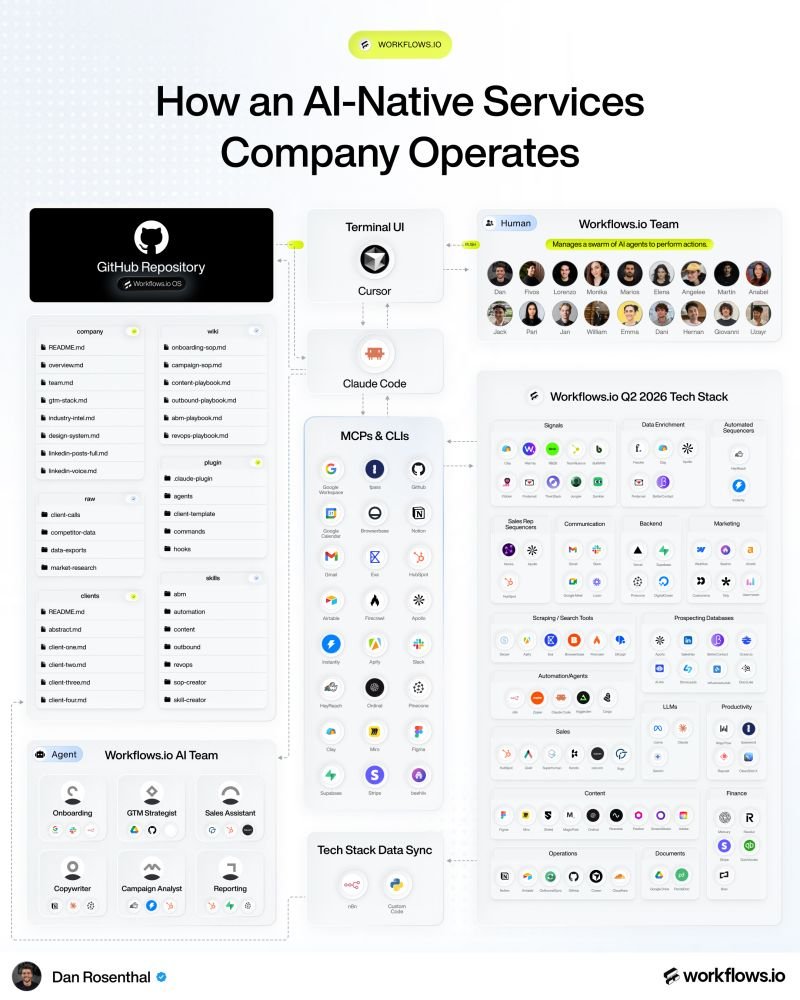
The way I operate my agency wouldn’t have been possible 1 year ago.
But we predicted this...
And made a big bet on AI-Native Services.
Claude Code is now our most used interface.
We uniquely blend software and human expertise.
We call it “AI-Native Services”.
Here’s how it works operationally:
1️⃣ Company OS in git
Our entire company dataset lives in one GitHub repo called Company OS.
What's inside:
• company/ - team, voice guide, design system, industry intel
• wiki/ - SOPs, playbooks, campaign guides
• clients/ - per-client context files
• raw/ - client calls, market research, competitor data
• plugin/ - 26 agents, 23 commands, hooks
• skills/ - 79 Claude skills
Data is constantly flowing in to keep it up-to-date.
2️⃣ Client repos
Every client gets their own private repo.
Same engineering pattern as the Company OS, just personalized to their account.
What's inside:
• Their ICP, voice guide, brand assets
• Historical campaigns and what worked
• Onboarding form data and deep research
• Slack threads, call transcripts, GDrive changes
• API/MCP connections to their revenue stack
Result: every team member has full client + company in every session.
3️⃣ Human interaction layer
We still log into some SaaS UIs, but Claude is slowly taking over.
Across 20 team members, the efficiency gain has been massive.
We try to automate as much of the admin as possible:
• Client onboarding
• Content research and ideation
• Skill tuning from team feedback
• Reply triage + sentiment routing
• Campaign launch pre-flight checks
So AI does the legwork, but humans ship.
So we can spend more time on strategy + creative GTM.
4️⃣ MCP + CLI engine
MCPs + CLIs let Claude act across our stack vs. just advise.
Some of our favorite MCPs/CLIs:
• GitHub - Company OS + client repos
• Findymail - email verification waterfall
• Google Workspace - client docs
• Airtable - automation backend
• InstantlyAI - email campaigns
• Slack - team + client comms
• Apolloio - list + enrichment
• Notion - internal wiki + PJM
• HeyReach - DM sequences
Plus HubSpot, Browserbase, Supabase, Vercel, Figma, Stripe, Pinecone, Clay, Apify, Firecrawl, and more.
We're also migrating a ton of workflows to custom code.
5️⃣ Operationalize
As an AI-native services company, we're constantly optimizing how we work with AI and software.
Built into the system:
• Guardrails: safety hooks gate 94+ risky operations.
• PR-based governance: anyone on the team can propose a new skill, agent, or tweak as a branch.
• Workflows-engineering plugin: 26 agents, 79 skills, 23 commands auto-propagated. Agent swarms split tasks into 5-20 sub-agents.
• Self-improvement loop: n8n syncs tech stack data back into the Company OS. Pinecone stores past content + performance metrics for skills to query. Human corrections feed back in.
There isn't ever going to be a finish line, so we're building like it's a marathon.
M
"/grill-me" skill really helps me understand the implementation of the new feature. It also allows me to further explore the design review with my teammates before creating the complete plan for that feature.
@mattpocockuk
M
@mauriciord Try /grill-with-docs! It's great
D
Introducing the /browser-trace skill,
Give your agent 100% observability into its browser: dump network requests, DOM content, screenshots, and CDP logs into a searchable filesystem.
Great for reverse engineering, autoresearch loops, and monitoring the situation ™️. https://t.co/FZ8lOelCBx
J
I find myself using the new skill version of my popular Idea Wizard prompt all the time to come up with new features and functionality for my projects and rank them in a structured way:
https://t.co/WTDaXVByzE
It automates the entire process from start to finish and can even turn them into beads for you and polish them.
The only drawback of the idea wizard skill is that it only uses the current model/harness you're invoking the skill from (usually Claude Code with Opus 4.7 or Codex with GPT-5.5). Still, it works very well.
But I've been like a broken record for the past year always talking about how you can get far better, more consistent, and more reliable results by combining feedback from multiple frontier models and harnesses, since they tend to have different strengths and weaknesses, so that one model can often see past the blind spots of the other models.
So I took that insight and turned it into a "Dueling Wizards" skill, which I think is a lot more powerful and which I've been applying left and right to many of my projects (and also during the planning phases of new projects I'm working on, when I'm still drafting the initial markdown plan):
https://t.co/n2Li1ctWeb
Dueling Wizards leverages my open-source ntm agent orchestration tool to create a swarm for you that includes Claude Code, Codex, and Gemini-CLI (whichever are available on your machine and working).
You can simply call it from within Claude Code or Codex, and it will configure and launch the swarm for you and manage the whole process (see screenshot).
Essentially, each agent in the swarm (usually there will just be 2 or maybe 3 agents) does its own independent run of the regular Idea Wizard workflow and writes the results to a text file.
Then, once that stage finishes, each of the agents switches to reading and critiquing/grading the ideas of the other agents. Then they each review the feedback from the others on their own ideas and are given a chance to defend their ideas, or agree with the criticism of the other agents.
All of these results are observed by the top-level agent that you invoked the skill from and it can decide what to do based on the entire "discussion."
You end up doing a much more thorough exploration of the space of ideas, and it's much more grounded in reality because of how these frontier models undergo a kind of "gestalt shift" when they're critiquing external ideas versus when they're coming up with their own ideas (this is also the basis of how the "fresh eyes" review concept works so well).
One cool thing about both of these skills is that they are universally applicable. I mostly use them in the context of software development, but you could apply them equally effectively to a business plan, to a marketing strategy document, to an employee handbook draft, or really any other kind of project.
Here is GPT-5.5's analysis of what makes Dueling Wizards so useful and compelling:
---
I studied the skill plus its references: prompts, scoring, operations, methodology, dynamics, variants, beads, integration, and the visualization. The short version: dueling-idea-wizards works because it turns ideation into an adversarial evidence pipeline instead of a brainstorm.
Why It Works
The core move is decorrelation. A single model generates ideas and then evaluates them with the same taste, blind spots, and reward biases that produced them.
The duel separates generation from evaluation: Claude, Codex, and/or Gemini independently study the same project, generate their own best ideas, and then judge the other model’s ideas. That makes agreement and disagreement meaningful.
The 0-1000 score is also doing real work. It forces ranking, not vague approval. A 900/850 idea is different from a 900/350 idea, and the gap is often the most useful part of the whole run. Consensus means confidence; disagreement means hidden assumptions, framing mismatch, or a model-specific bias worth investigating.
The reveal phase is the high-signal part. Each model sees how another model scored its own ideas and must either concede, defend, clarify, or revise. That pressure exposes weak self-justification fast. Strong ideas become sharper because they survive criticism; weak ideas collapse because their originator cannot defend them without handwaving.
The optional rebuttal, steelman, and blind-spot phases are what make it unusually good. Rebuttal forces precise defense. Steelmanning forces the critic to make the opponent’s idea stronger than the opponent made it. The blind-spot probe asks what neither side saw after the adversarial exchange has expanded both models’ context. That is where genuinely new synthesis can appear.
Why It Is Useful
It has an aggressive kill rate. That is the point. Most ideas are not worth implementing, and this workflow finds that out cheaply, in writing, before engineering time is spent. It gives you consensus winners, contested ideas, and dead ideas, with reasons.
It also preserves the risk model. The opponent’s criticism is carried into the final report and, if --beads is used, into the actual work items. That means implementation starts with known objections, edge cases, and failure modes already attached. The output is not just “build X”; it is “build X, because two models converged on it, and watch out for Y and Z because the adversarial review exposed them.”
It scales across domains because the duel mechanic is domain-neutral. The skill has modes for architecture, security, UX, performance, reliability, and innovation. The prompts change, but the underlying engine stays the same: independent generation, cross-scoring, reveal, synthesis.
Why It Is Compelling
It has an unusually clear narrative shape: study, generate, duel, reveal, synthesize. That makes the artifacts easy to trust and easy to inspect. You can see how an idea entered the funnel, who liked it, who attacked it, whether the attack landed, and why the orchestrator ranked it where they did.
It also creates productive tension. Normal assistant brainstorming is often too agreeable. This workflow explicitly licenses candid criticism, which produces sharper technical claims. The value is not in the attitude; it is in the specific objections that appear once a model is asked to judge another model’s best work.
The visualization captures this well: two agents independently create idea sets, send scores across the middle, reveal winners/contested/kills, and converge on a small set of validated outputs. It makes the skill’s real shape visible: not “more ideas,” but “pressure-tested survivors.”
Why It Is Accretive
The skill is accretive because every phase leaves reusable artifacts: WIZARD_IDEAS_*, WIZARD_SCORES_*, WIZARD_REACTIONS_*, optional rebuttals/steelmans/blindspots, and the final report. Those artifacts become a knowledge base for future planning, implementation, validation, and postmortems.
It is especially strong when chained with other skills. codebase-archaeology and reality-check-for-project improve the input context; modes-of-reasoning-project-analysis finds contested areas to focus the duel; beads-workflow turns winners into dependency-aware work; validation skills stress-test the winners before implementation. So the duel is not an isolated brainstorm. It is a middle stage in a larger build flywheel.
The prior run memory backs this up: when this method was used on support-skill improvement work, the adversarial pass elevated validators, evidence contracts, and accretive learning loops over flashier broad automation. That is exactly the kind of judgment you want: prefer durable mechanisms that make future work better, not just impressive-sounding additions.
The main caveat is that the method is overkill for trivial or urgent decisions. It needs at least two genuinely different model types, clean phase separation, and a disciplined orchestrator who reports the evidence instead of editorializing too early. Used in the right place, though, it is one of the better patterns for turning model diversity into concrete decision quality.
D
doodlestein
@doodlestein
"My Favorite Prompts," by Jeffrey Emanuel Prompt 1: The Idea Wizard "Come up with your very best ideas for improving this project to make it more robust, reliable, performant, intuitive, user-friendly, ergonomic, useful, compelling, etc. while still being obviously accretive and pragmatic. Come up with 30 ideas and then really think through each idea carefully, how it would work, how users are likely to perceive it, how we would implement it, etc; then winnow that list down to your VERY best 5 ideas. Explain each of the 5 ideas in order from best to worst and give your full, detailed rationale and justification for how and why it would make the project obviously better and why you're confident of that assessment. Use ultrathink."
D
RT @anthonyronning: dspy
C
Ok, this is pretty interesting. These guys built a completely new architecture: Large Memory Models. This is designed specifically for how human memory works. Instead of RAG or vector search, this is a different paradigm. Their founders have 160+ publications in Nature and ICLR, and closed their Harvard lab to build this.
E
EngrammeHQ
@EngrammeHQ
Persistent memory is the Achilles heel of AI. Engramme’s Large Memory Models (LMMs) empower every app with persistent memory. Google solved search. OpenAI solved language. Engramme solved memory. Join beta: https://t.co/iN6ZgEVSxH https://t.co/LqPxweldnh
N
New podcast on vibe coding - A Return to Code.
A Return to Coding 00:20
The Personal App Store 03:17
Vibe Coding Is a Video Game with Real-World Rewards 06:22
Pure Software Is Uninvestable 10:33
A Place for Each Model 14:22
AI Is Eager to Please 17:57
Why Math and Coding? 22:10
The Beginning of the End of Apple’s Dominance 24:17
Coding Agents As Customer Service Reps 27:55

P
codex now runs on each commit we land, reviews it - and if a booboo is found, a new codex spins up and (if still relevant) makes a PR for the fix.
Then a review agent spins up. If an issue is found, another agent will fix the issues. (up to 5 loops) https://t.co/k6o7tNcDyf
C
tired of losing your thoughts in heaps of documents?
instantly capture and recall with constella's new canvas made especially for diagnosed (or undiagnosed!) neurodivergent researchers
create work that stands apart from AI slop with visual search across 475M+ papers
R
I have been to a lot of startup demo days but have never seen such a great writeup as this.
S
ShahRathin
@ShahRathin
What I Learnt From 199 Pitches at the YC W26 Demo Day
M
RT @mitchellh: Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 ye…
3
Fin was my coworker and he is a real semi architect while most of my semi knowledge is from ChatGPT 🤣
Just asked him to repost his insightful article in English, highly recommend it.
F
fi56622380
@fi56622380
AI Semiconductor Endgame 2026 (Part 1) New Token Economics Computing Paradigm Shifts from GPU Compute to HBM This article starts from the essence of GPU architectural evolution to address a question the market has long worried about: Why must each GPU's HBM memory demand grow exponentially, and why won't this exponential growth in HBM demand stall? It then derives the first principle of token economics under the current architecture: token throughput = HBM size × HBM BW (bandwidth) It also discusses why the GPU ceiling is determined by HBM's two dimensions of progress. The topic of HBM cyclicality has long been controversial. Optimists argue that AI-driven demand is much greater than before, but the market mainstream still believes that previous up-cycles also saw 20%+ annual demand growth — so what's different this time? AI doesn't change the fact that HBM, like traditional DRAM, has commodity attributes. Once capacity expansion at the demand peak meets a downturn, history will repeat itself. We can take the perspective of compute-chip architecture, start from first principles, and unpack and reason through this question: why this time is genuinely different. ——————————————————————————————— History: The Era of CPU Compute For a very long time, we lived in the era of CPU-dominated compute. The CPU's top-level KPI was performance — running faster — and so each generation of CPUs deployed every method imaginable to push benchmark scores higher. First it was rising clock frequencies, then it was architectural evolution: superscalar designs, and so on. During this period, why didn't DDR need to advance technologically at high speed? DDR3 to DDR5 took a full 15 years. Because in this era, DDR's role was purely auxiliary — and only weakly so. By industry experience, even doubling DDR speed would generally only raise CPU performance by less than 20%. Why did improvements in DDR bandwidth and speed matter so little? Two reasons: 1. CPUs designed all kinds of architectural tricks to hide DDR latency — superscalar designs, wider issue widths, massive ROBs and register renaming to extract parallelism and hide latency, L1 caches, L2 caches — all of which weakened the demand for DDR bandwidth and speed. 2. CPU workloads don't have particularly demanding bandwidth requirements. For most everyday workloads — say, opening a webpage — DDR bandwidth is severely overprovisioned. Even cloud workloads often look the same. In other words, in the CPU era, DDR bandwidth and speed didn't really matter. There was virtually no difference between DDR4 and DDR5 except in a handful of games — and even the JEDEC standard advanced slowly. On top of that, only a small portion of any given app needs to permanently sit in DDR. Whatever is needed can be paged in from the hard drive on demand. App size grew slowly, and so DDR capacity demand grew slowly as well. That's why, over the past decade, the average PC went from 7–8GB of DDR to about 23GB — only 3× growth in ten years. This slow upgrade pace directly affected revenue. Capacity-based pricing was the main way of making money; speed improvements were just a technological upgrade that raised the unit price of capacity. With both of these dimensions advancing slowly, growth could only come from increases in PC/phone unit volumes. So along both dimensions — bandwidth/speed and capacity — DRAM was always a “nice-to-have” appendage to the chip industry. The marginal utility of DDR upgrades was very low, and almost completely disconnected from the CPU era's top-level KPI. ——————————————————————————————— The Paradigm Shift: GenAI's Top-Level KPI When we entered the era of GenAI large models, the computing paradigm shifted, and the top-level KPI changed fundamentally. By the time GPUs evolved into AI inference engines, the top-level KPI was no longer compute alone (TOPS/FLOPS), as it had been for CPUs — it became the cost of a token. Specifically: overall token throughput per unit cost / per unit power. A close second is token throughput speed — because in the agent era, many tasks have become serial, and token output speed has become a critical bottleneck for user experience. This is exactly why Jensen invented the concept of the AI factory: to produce the most tokens at the lowest cost, while pushing token throughput speed as high as possible. In the AI training era, Jensen's economics were TCO (Total Cost of Ownership): the more GPUs you buy, the more you save. In the inference era, Jensen's token economics flip the logic: AI inference has very healthy gross margins, so the logic now becomes: the NVIDIA GPU is the GPU that produces the cheapest token in the world, so the more you buy, the more you earn. The top-level KPI has become a Pareto frontier: along the two dimensions of token throughput and token speed, optimize as far as possible. Each generation of NVIDIA's token factory is essentially pushing the entire Pareto frontier up and to the right. This is the most important KPI of the AI inference era. ——————————————————————————————— From Token Throughput to HBM: The Core Logic Chain Below is the most important logical chain of this article: how to start from the exponential growth of token throughput and derive that the ceiling bottleneck lies in the exponential growth of HBM size and HBM speed. In the era of single-GPU inference with single-thread batch size = 1, token throughput had only one dimension: HBM bandwidth speed. Higher bandwidth = higher token throughput. But once we entered the NVL72 era, inference is no longer single-GPU. It is a system-level token factory composed of 72 GPUs + 36 CPUs, designed to fully saturate HBM bandwidth and compute simultaneously, in pursuit of the ultimate token throughput. Token throughput growth depends on two things: the number of requests batched simultaneously × the average token speed per request. That is: batch size × token speed. Take Rubin NVL72 as an example. At an average token speed of 100 tokens/s, processing 1,920 simultaneous requests yields a token throughput of 192,000 tokens/s. A Rubin NVL72 draws roughly 120kW (0.12MW), so per MW it can handle 1.6M tokens/s. So we need to find ways to push both parameters up: batch size and average token speed. Their product is our top-level KPI — token throughput. Parameter 1: Batch growth — bottleneck is HBM size Every request in the batch carries its own KV cache, which has to live in HBM, with sizes ranging from a few GB to tens of GB. Because hot KV cache must be read at high frequency and high speed at any moment, it must reside in HBM. For a model with, say, 80 layers, every token generation step requires reading the KV cache 80 times from HBM. As batch size grows, hot KV cache grows linearly. And because the hot KV cache for every request in the batch must sit in HBM, HBM size must grow linearly with batch size. Like an airport shuttle bus: the gate wants to move passengers to the plane as fast as possible. If HBM size is small, the shuttle is small, so you have to make extra trips. Conclusion: batch size growth bottlenecks on HBM size growth. Parameter 2: Average token speed per request — bottleneck is HBM bandwidth The decode-phase speed of a large model bottlenecks on HBM bandwidth, because every token generated requires reading the activated weights and KV cache many times over. The emergence of LPUs has, in cases where batch size isn't very large, moved the activated weights portion onto SRAM — but every generated token still requires many reads of the KV cache from HBM. The higher the HBM bandwidth, the faster each token is generated, in essentially linear correspondence. Like the airport shuttle bus: HBM bandwidth is like the width of the door — wider doors mean passengers board faster. The rest of the GPU's configuration is essentially adapted to support batch growth and to keep token compute speed in step with HBM growth. In some cases the GPU even spends excess compute to recover effective bandwidth (e.g., bandwidth compression techniques). —------- To return to the shuttle bus analogy: • Shuttle bus cabin size = HBM Size (capacity): determines how many passengers can fit at once (i.e., how many requests' KV caches can sit in HBM simultaneously). Bigger cabin = more passengers (higher batch size) per trip. If the bus is too small, moving 100 people takes two trips — and total throughput suffers. • Shuttle bus door width = HBM Bandwidth: determines how fast passengers get on and off. A wide door, and everyone piles on at once (decode/token generation is fast). A narrow door, and even with a giant cabin, people queue up and most of the time is spent boarding. • Passenger throughput = cabin size × door-width-determined boarding speed. —------- At this point, we've logically derived the first principle of token-economics hardware demand: Token throughput = HBM size × HBM Bandwidth The top-level KPI of the AI inference era is highly dependent on progress along both HBM dimensions. If we want to maintain 2× token throughput growth per generation, that means each generation of single GPU must grow HBM size × HBM BW speed by 2×! This is the first time in history that HBM memory size can influence the top-level KPI — token throughput. To validate this thesis, we can put NVIDIA's token throughput from A100 to Rubin Ultra on the same chart as HBM size × HBM BW speed. What you find is that the two curves track each other startlingly closely on log axes. HBM size × speed actually grows even faster than token throughput — which makes sense, because HBM defines the ceiling, and in practice utilization of that ceiling is very hard to push to 100%. Even if HBM size × HBM speed grew by 1,000×, with the supporting compute and architecture, it would be very hard to wring out the full 1,000× of headroom. This curve isn't a coincidence — it's the necessary solution of system optimization. throughput = batch × speed. This is the unavoidable first principle of token factory economics. —------- What about software? Won't software optimization reduce bandwidth demand? Reduce HBM demand? This is an independent dimension from hardware. It's like asking: if software on a CPU runs faster after optimization, does that mean the CPU doesn't need to advance for ten years? After all, software is faster now. If that were the case, would CPU vendors still make money? For a CPU vendor to survive, there's only one path: in standardized benchmarks, ignoring software optimization, every new CPU generation must score higher — otherwise it doesn't sell. GPUs are exactly the same. How well software is optimized, and the requirement that the GPU's own token-throughput KPI must improve dramatically every year, are two separate things. As long as token demand keeps growing, the pursuit of higher token throughput will not stop — and so neither will the pursuit of higher HBM size × HBM speed. If HBM size and HBM speed were to slow down, Jensen would personally fly to the Big Three and pressure them to accelerate, because that ishis GPU ceiling. If the ceiling stops rising, can his GPU still sell? Of course, NVIDIA also needs to wrack its brains to extract performance beyond the HBM ceiling through heterogeneous architectural angles. The LPU is a great example — it improved the Pareto frontier substantially from a different angle (the right-hand high-token-speed portion). —-------------------- HBM memory has now bid farewell to that old era of drifting with the tide. On this one-way road paved by exponential demand, it has, in something close to a destined fashion, walked onto the central stage of the industry's epic. When the inference paradigm's first principles evolve to this point, as long as Jensen still wants to sell GPUs, HBM must double — and it must double every generation. This is endogenous pressure from the supply side. It has nothing to do with AI demand, nothing to do with macro cycles, and nothing to do with the moods of the hyperscalers. The only remaining question is this: When demand has been physically locked into exponential growth, will the three players on the supply side — like they have for the past thirty years — once again drag themselves back into the mire of the cycle by their own hands?
T
RT @zodchiii: Two Anthropic engineers, who built Claude just explained why you use less than 10% of actual Claude abilities.
This 24-minut…