OpenAI Strips AGI Clause on Trial Day as Local DeepSeek V4 Flash Stuns Developers
OpenAI removed its foundational AGI protection clause the morning of the Musk trial, while the local inference community celebrated DeepSeek V4 Flash as the first truly frontier model running on consumer hardware. Meanwhile, the AI coding tool ecosystem saw major updates from Claude Code, Playwright, and Cognition, alongside emerging research on AI systems that manage other AI systems.
Daily Wrap-Up
The biggest news today wasn't a model release or a funding round. It was a deletion. OpenAI quietly removed the AGI clause from its charter on the same morning jury selection began in the Elon Musk trial. This was the clause that gave the nonprofit board a kill switch over Microsoft's commercial rights if AGI was ever achieved. Combined with the removal of the profit cap and the end of Microsoft exclusivity, every structural safeguard from OpenAI's original nonprofit mission is now gone. Whether you see this as pragmatic corporate evolution or a betrayal of founding principles, the timing is hard to ignore.
On the technical side, the local inference crowd is having its moment. DeepSeek V4 Flash is generating the kind of excitement usually reserved for cloud-only frontier launches, with developers like antirez calling it the first time a frontier model genuinely feels usable on personal hardware. The Qwen 3.6 ecosystem is maturing in parallel, with clever inference tricks (constraining the think block to a tiny grammar) delivering dramatic token savings without accuracy loss. The gap between local and cloud is narrowing faster than most predicted, and the practical implications for developer workflows are enormous. The AI coding tools space continues to fragment and consolidate simultaneously: Claude Code shipped a substantial update, Cognition is betting on cloud agents as the next curve, and a new open course on "harness engineering" is teaching developers to build reliable scaffolding around AI assistants rather than just prompting harder. The most practical takeaway for developers: if you haven't tried running a quantized frontier model locally yet, this week's DeepSeek V4 Flash releases make it worth the experiment. Even 2-bit quantized versions are reportedly performing at frontier quality, which changes the economics of AI-assisted development entirely.
Quick Hits
- @MattSchrage left AWS to join @cognition, calling cloud agents the next S-curve in agentic coding. The Fig-to-Amazon-to-Cognition pipeline is a fascinating career arc in the AI tools space.
- @HoytEmerson distilled the 2026 data stack down to three pieces: Parquet on S3, DuckDB for querying, Arrow for in-memory compute. Hard to argue with the simplicity.
- @mattpocockuk is crowdsourcing a rename for his
/domain-modelslash command, a code-focused alternative to/grill-me. The developer tools naming game continues. - @everestchris6 showcased OpenClaw, a bot that scrapes restaurants with ugly menus, rebuilds them as branded web menus, and mails the owner a physical postcard. Automation taken to its logical (absurd?) conclusion.
- @oliviscusAI shared an open-source tool for searching scenes across hours of raw video and exporting exact clips. Runs locally, which fits the day's theme perfectly.
- @thirdmetax surfaced a clip of MrBeast explaining he made his first 250 employees read "The Goal" so they'd understand what he means by "bottleneck." Theory of Constraints meets YouTube empire building.
AI Coding Tools Get Serious Infrastructure
The AI coding tools ecosystem is maturing past the "wow, it wrote code" phase into something more structural. Today brought updates across the stack that reveal where the real competition is heading. Claude Code 2.1.121 shipped with 39 CLI changes, including a notable addition: MCP servers can now set alwaysLoad to skip search deferral, the Bash tool drops shell state between runs, and PostToolUse hooks can now replace output for all tools. As @ClaudeCodeLog noted, these are the kind of infrastructure-level changes that matter more for reliability than any benchmark improvement.
Meanwhile, Playwright released v0.1.9 of their CLI with features explicitly designed for coding agents: visual confirmation via highlight and annotate commands, bounding box snapshots, and stable locator generation. @playwrightweb described it as "sharper tools for coding agents," and the framing is telling. Browser automation tooling is now being built agent-first rather than human-first.
The most thought-provoking contribution came from @cyrusnewday, who shipped gepa-research, an open-source coding agent plugin inspired by Karpathy's autoresearch: "Instead of greedy hill-climbing or tree-search, it explores the pareto frontier." This represents a shift from agents that just complete tasks to agents that optimize across multiple objectives simultaneously. But not everyone is convinced the tooling is ready for full autonomy. @0xblacklight pushed back on the idea of AI agents autonomously pulling tickets from Linear boards: "We felt really productive for a few weeks and then ripped it down. It's a product manager's dream but it sucks for doing real engineering work." The tension between autonomous agent workflows and human-in-the-loop engineering remains unresolved, and the honest post-mortems are more valuable than the hype threads.
Local Inference Hits a Tipping Point
Something shifted this week in the local AI community, and it's not just incremental improvement. DeepSeek V4 Flash appears to be the model that finally makes "frontier quality on consumer hardware" feel real rather than aspirational. @antirez, the creator of Redis and someone not prone to hype, was unequivocal after 24 hours of testing: "Even with the 2 bit selective quantization GGUF, it is the FIRST time I feel I have a frontier model running on my computer. This is crazy, and probably a much stronger change in the landscape than PRO." That's a strong statement from someone who understands systems-level performance deeply.
The enthusiasm is spreading. @outsource_ posted a GPU listing with the suggestion to "lowball this guy $2k and we can run Deepseek locally," capturing the gold-rush energy around local hardware acquisition. On the Qwen side, @0xkeenz shared a clever technique for constraining Qwen 3.6's thinking block to a structured grammar, referencing @andthatto's original finding: "22x fewer think tokens, no accuracy loss" on HumanEval+, with a 14% improvement on LiveCodeBench. And @malikwas1f amplified a detailed breakdown of the memory math for fitting Qwen 3.6 27B Q4 on 24GB VRAM at 262K context, a question apparently landing in DMs "5 times a week."
What ties these threads together is a shift in the conversation from "can we run models locally?" to "how do we optimize local inference for production workflows?" The community has moved past proof-of-concept into practical engineering, and the economics are increasingly favorable for developers who invest in local hardware.
OpenAI's Mission Architecture Collapses on Trial Day
The timing alone makes this story remarkable. On the morning of jury selection in the Elon Musk lawsuit, OpenAI announced the removal of its AGI clause, the provision that would have let the nonprofit board terminate Microsoft's commercial rights upon achieving AGI. @k1rallik captured the mood: "They deleted the ONE clause that legally prevented them from becoming a regular corporation. Gone. Today. While jury selection was happening in the courtroom."
The underlying details, surfaced in a quoted thread from @ns123abc, are even more striking. Three structural protections existed in OpenAI's 2019 capped-profit structure: the 100x profit cap (removed in the PBC conversion), the AGI clause (removed today), and Microsoft exclusivity (also removed today). All three are now gone. The defense theory in the Musk trial, that Microsoft's investment was necessary for the mission, gets harder to maintain when OpenAI is simultaneously decoupling from Microsoft and removing mission-protection mechanisms. Whatever the legal outcome, the organizational transformation from mission-driven nonprofit to conventional tech company is now structurally complete.
AI Managing AI: The Conductor Paradigm
Sakana AI's ICLR 2026 paper introduces a concept that feels like a preview of where multi-agent systems are heading. @hardmaru described training a 7B "Conductor" model with reinforcement learning to orchestrate a pool of frontier models: "What surprised me most was how it dynamically adapts. For simple factual questions, it just queries one model. But for hard coding problems, it autonomously spins up a whole pipeline of planners, coders, and verifiers."
The results are noteworthy: the 7B Conductor surpassed every individual worker model in its pool, hitting 83.9% on LiveCodeBench and 87.5% on GPQA-Diamond. The research also introduced recursive test-time scaling, where the Conductor selects itself as a worker to review and correct its own team's output. As @hardmaru framed it, we're moving from "chain-of-thought" to "chain-of-command." The practical implication: a small, cheap model learning to be an expert prompt engineer for larger models might be more cost-effective than scaling any single model further. This research, powering Sakana's new Fugu system, suggests the future of AI performance may lie in orchestration rather than raw model capability.
Learning to Harness AI, Not Just Prompt It
A new open-source course called "Learn Harness Engineering" is gaining traction, and the framing is significant. As @wsl8297 described, the course breaks AI collaboration into five mechanisms: instructions, state, verification, scope, and sessions, "letting every task be trackable, resumable, and verifiable, no longer relying on luck for results." The course includes 12 theory sessions, 6 hands-on projects, and reusable template files.
This reflects a growing recognition that the bottleneck in AI-assisted development isn't model capability but the scaffolding around it. If you're using Claude Code or similar tools and finding results inconsistent, the problem likely isn't the model. It's the harness.
Sources
Qwen 3.6 is frontier for local. It also thinks forever. I tried a dumb inference-time trick: make its <think> block obey a tiny grammar. Result: - HumanEval+: 22x fewer think tokens, no accuracy loss - LiveCodeBench public slice: +14% pass@1, ~5x fewer total tokens


Jensen Huang pays his top executives the exact same dollar amount. Same number for 55 people. He opens Excel, types one figure, and drags it down. Nvidia crossed $5 trillion on Friday. Performance reviews go unwritten. The standing one-on-one cadence that anchors most CEO calendars simply doesn't exist, and information flows to all 55 directs at once or not at all. The man running the world's most valuable company threw out the entire CEO operating manual. The conventional read is eccentricity. 55 directs blows past Dunbar. The identical pay surrenders talent retention as a lever, and zero scheduled 1:1s skips the most basic CEO ritual in the management playbook. A board reviewing this on paper would fire the CEO. What reads as three quirks is one architecture. Each rule removes a specific class of executive politics that traditional companies spend 40% of CEO time managing. Identical pay removes compensation negotiation as a variable. There's no "I should make more than Ajay" conversation, because the conversation has no surface area. Nvidia's most recent proxy shows Colette Kress, Ajay Puri, Debora Shoquist, and Timothy Teter all receiving the same $1.5M cash bonus this year. Identical to the dollar. Skipping one-on-ones removes information asymmetry across the entire executive layer. Every exec operates on identical intel, because Jensen never says anything to one of them that the other 54 don't also hear. Status games inside executive teams need private information to function. Jensen made every piece of information public. 55 directs forces a flat structure. A Fortune 500 with 5-7 directs per manager typically runs 9-10 layers deep. Nvidia runs roughly 3-4 layers from Jensen to a senior individual contributor. Information that takes a quarter to move at Microsoft moves in a single meeting at Nvidia. The deeper trade is what most people miss. The traditional CEO spends 30-40% of their week on executive management overhead: 1:1s, comp reviews, conflict mediation between directs, performance plans. Jensen runs the same headcount with effectively zero of that. His management system IS the engineering meeting. Every exec is a co-designer in real time. Management happens as a byproduct of the work. The Excel drag-down is the most surgical move in the system. Differentiated executive comp creates permanent political machinery. Every cycle, every exec compares their number to their peers, recalibrates relative status, and adjusts behavior accordingly. Jensen looked at that entire machinery and unplugged it. The whole architecture was designed for the moment money stops working. Once a senior Nvidia exec clears $50M+ in vested stock, comp differentiation stops functioning as a motivational lever. It becomes noise. Jensen built the system as if money was already off the table from day one. $5 trillion is the validation. The most heretical management architecture in the Fortune 500 sits on top of the most valuable company in the world. Nobody else will copy it. The system requires a CEO with no executive favorites.
Introducing our new work: “Learning to Orchestrate Agents in Natural Language with the Conductor” accepted at #ICLR2026 https://t.co/Wnh9ZACmLm What if we trained an AI not to solve problems directly, but to act as a manager that delegates tasks to a diverse team of other AIs? To solve complex tasks, humans rarely work alone; we form teams, delegate, and communicate. Yet, multi-agent AI systems currently rely heavily on rigid, human-designed workflows or simple routers that just pick a single model. We wanted an AI that could dynamically build its own team. We trained a 7B Conductor model using Reinforcement Learning to orchestrate a pool of frontier models (including GPT-5, Gemini, Claude, and open-source models available during the period leading up to ICLR 2026). Instead of executing code, the Conductor outputs a collaborative workflow in natural language. For any given question, the Conductor specifies: 1/ Which agent to call 2/ What specific subtask to give them (acting as an expert prompt engineer) 3/ What previous messages they can see in their context window Through pure end-to-end reward maximization, amazing behaviors emerged. The Conductor learned to adapt to task difficulty: it 1-shots simple factual questions, but autonomously spins up complex planner-executor-verifier pipelines for hard coding problems. The results are very promising: The 7B Conductor surpasses the performance of every individual worker model in its pool, setting new records on LiveCodeBench (83.9%) and GPQA-Diamond (87.5%) at the time of publication. It also significantly outperforms expensive multi-agent baselines like Mixture-of-Agents at a fraction of the cost. One of our favorite features: Recursive Test-Time Scaling! By allowing the Conductor to select itself as a worker, it reads its own team's prior output, realizes if it failed, and spins up a corrective workflow on the fly. This opens a new axis for scaling compute during inference. This research proves that language models can become elite meta-prompt engineers, dynamically harnessing collective intelligence. Alongside our TRINITY research which we announced a few days earlier, this foundational research powers our new multi-agent system: Sakana Fugu! (https://t.co/36Ud311KCP) 🐡 OpenReview: https://t.co/e5WqTleQNL (ICLR 2026)
I got early access to a CLI that is SO GOOD, everything else is cooked when this comes out I can't talk about what it is yet, but they just gave me the infinity stones, I feel like thanos right now with this
Wild times are coming https://t.co/2layXY5mXn

🚨 OpenAI just REMOVED the AGI clause that was a structural protection of OpenAI's charitable mission, while jury selection was happening today The 2019 capped-profit structure had three protections for the charitable mission: 1. 100x profit cap: REMOVED in PBC conversion 2. AGI clause: REMOVED today 3. Microsoft exclusivity: REMOVED today All three are gone. This is exactly what Musk's lawsuit alleges: the people running OpenAI systematically dismantled the mission-protection mechanisms. Today they did it again. The defense theory just got harder. OpenAI's defense includes: "Microsoft's $13 billion-plus investment was necessary for our mission. Without that capital, OpenAI couldn't have shipped GPT-4 or scaled ChatGPT." But today, on the morning of trial, OpenAI announced they are decoupling from Microsoft: • AGI clause REMOVED. The nuclear option that let the non-profit board terminate Microsoft's commercial rights once AGI was achieved. Gone. • Microsoft IP license now NON-EXCLUSIVE through 2032. OpenAI can license to anyone. • Cloud exclusivity ENDED. OpenAI can sell across AWS, Google Cloud, Oracle. • Revenue share capped. Microsoft no longer pays revenue share to OpenAI; OpenAI still pays Microsoft through 2030. If Microsoft was so necessary, why restructure on the day the case reaches a jury? Musk's lawyers will use this in court tomorrow.

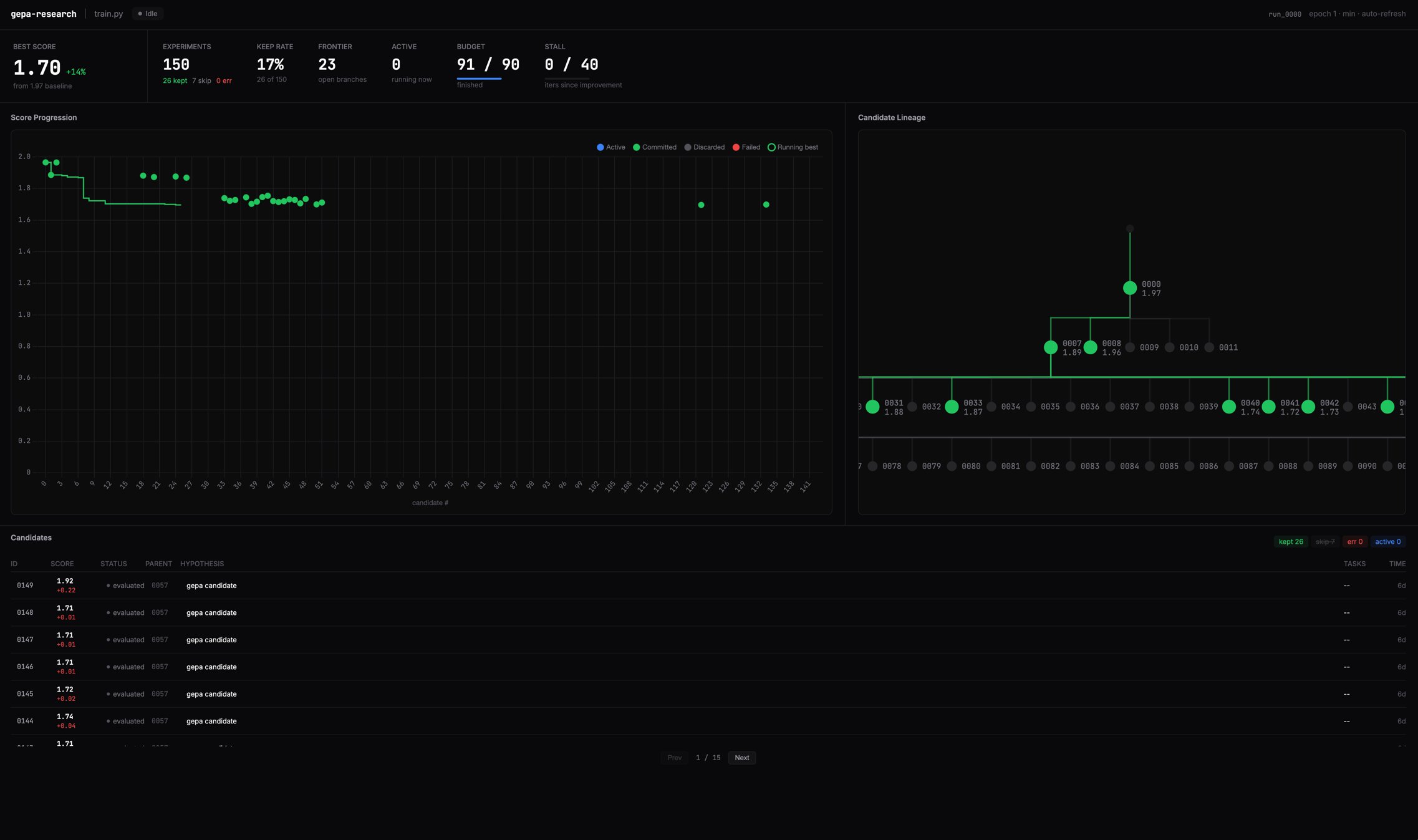

TLDR: it is a cron job dispatching tickets from Linear to workers, each of which is a Ralph loop using a Linear comment as draft pad for persisted state. Yes it is all you need. Beautifully designed and minimal. https://t.co/g05ImsJIZh