Anthropic Ships Multi-Agent Framework as the Community Debates What Computers Even Are Anymore
The AI agent ecosystem dominated today's discourse, with Anthropic releasing a production-grade multi-agent framework, heated debate over whether current computing paradigms need to be rebuilt from scratch, and practical tips for cutting Claude Code token usage by 50%. Meanwhile, cloud-based AI coding tools continued gaining ground over local setups, and a viral homelab post reminded everyone that self-hosting is alive and well.
Daily Wrap-Up
The throughline today was unmistakable: agents are graduating from toy demos to production infrastructure, and that shift is forcing uncomfortable questions about everything we thought we knew about software. Anthropic's agents team dropped a four-layer framework for multi-agent systems that drew immediate attention, while @signulll penned a widely-shared thread asking whether the entire concept of a "computer" needs reinventing when the primary user is no longer just a human but a swarm of delegated intelligences. These aren't idle philosophical musings anymore. When @PawelHuryn is publishing concrete claude.md configurations for subagent delegation with model-tier routing, we've clearly moved past the "what if" stage into the "how exactly" stage.
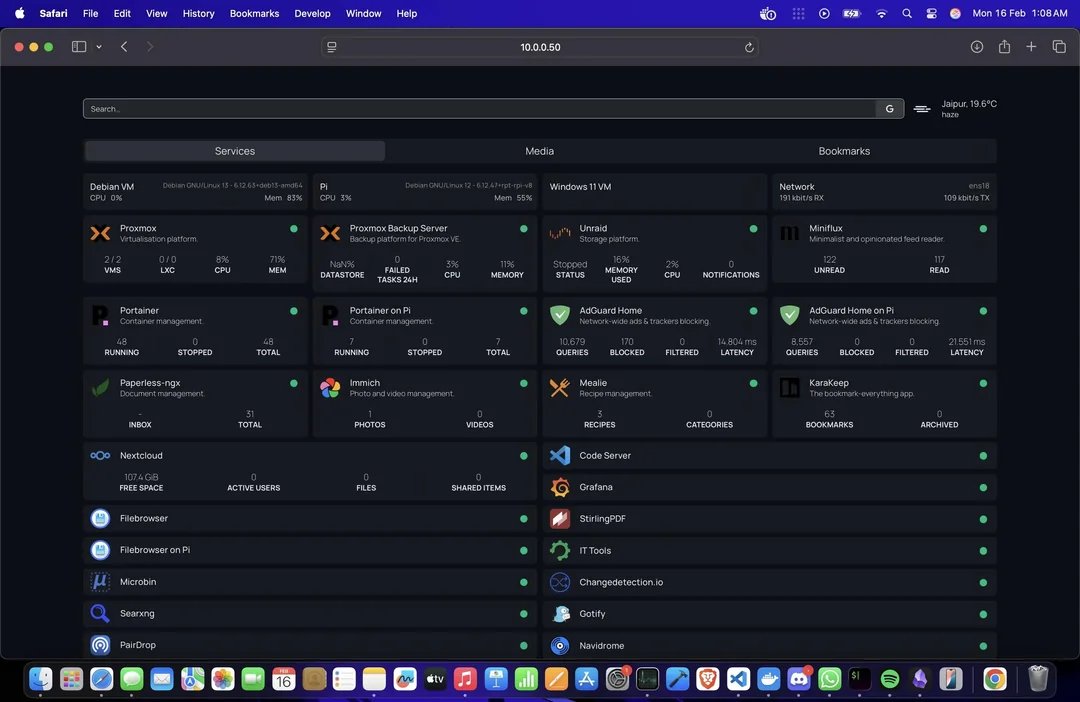
On the developer tools front, the pendulum keeps swinging toward cloud-based AI coding. @ryancarson's full-throated endorsement of Devin AI, complete with an about-face from his earlier "build your own code factory" stance, captures a real tension in the community. The tooling is moving so fast that best practices from three months ago are already outdated. At the same time, the local-first crowd isn't going away quietly. LocalMaxxing launched today, and a jaw-dropping homelab thread from @om_patel5 showcased someone running 30+ self-hosted services for $0/month using Claude Code to generate the dashboard config. The gap between cloud maximalists and self-hosting purists is widening, but both camps are shipping.
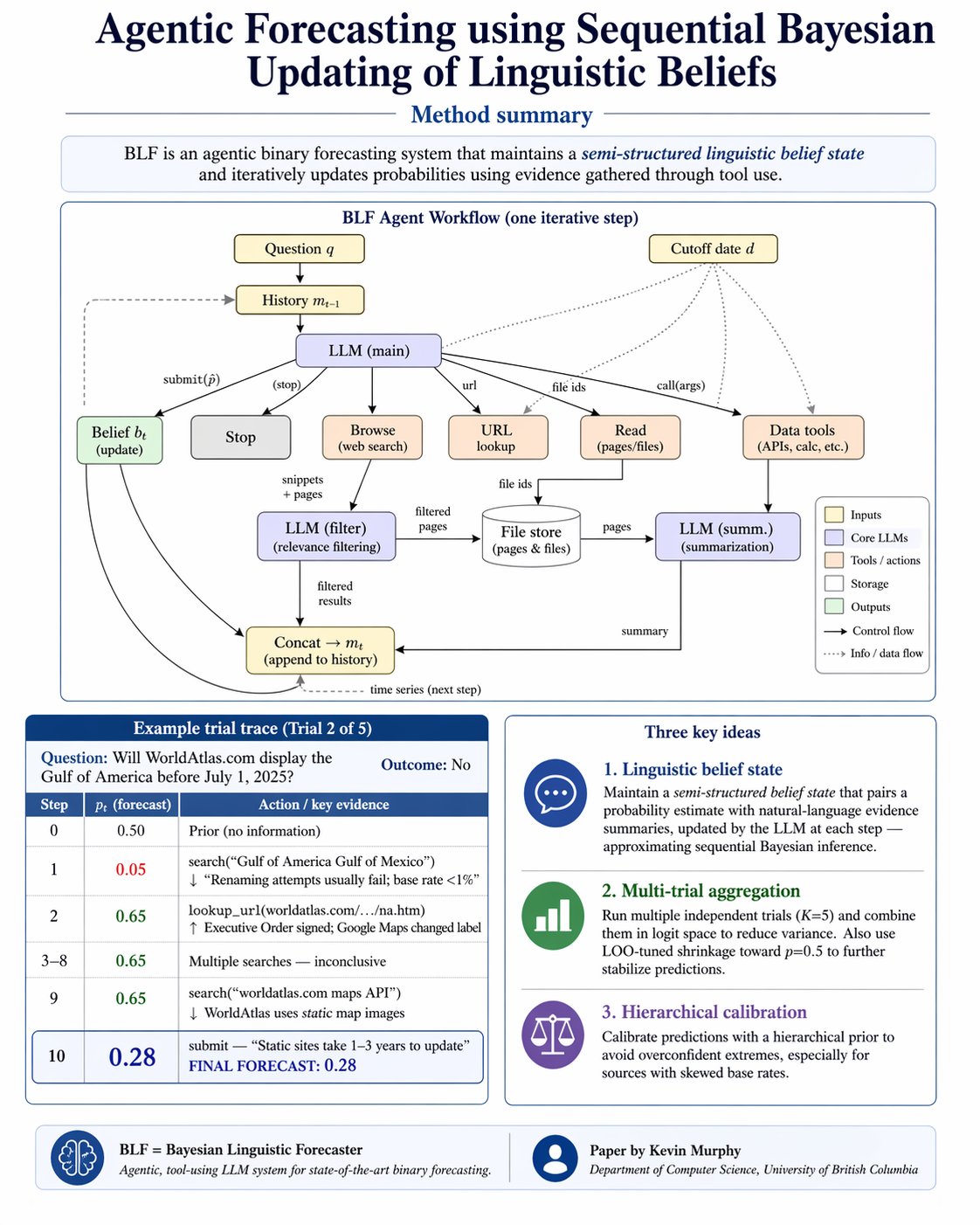
The research side offered a neat surprise: Kevin Murphy using Platt scaling with structured outputs to achieve state-of-the-art results on forecast benchmarks, proving that clever calibration techniques can unlock capabilities that LLMs supposedly couldn't handle. The most practical takeaway for developers: if you're running Claude Code on any serious codebase, steal @PawelHuryn's subagent delegation pattern and model-tier routing. Spawning Haiku for bulk mechanical tasks while reserving Opus for planning decisions is the kind of cost discipline that separates hobbyist usage from production workflows.
Quick Hits
- @_summer_plays_ outlined the 2026 AI-to-3D pipeline: generate concept art, convert to mesh with Hunyuan3D or Tripo, rig in Blender, auto-animate with Mixamo. Start-to-game-ready in one afternoon. There's a $600 capybara-themed contest attached.
- @The_Only_Signal stress-tested a dual RTX 6000 build at 1650W wall draw with both GPUs and CPU at 100%. The air-cooled HX cruises at 95°C under full load. His conclusion: "my limits with this build are power, not thermals."
- @Zephyr_hg highlighted someone making $47K/month with AI in a single local service industry vertical, two operators, one offer. "The unsexy ones always print first."
- @badlogicgames retweeted praise for Pi, calling it "just incredible" for its reliability, rendering speed, token efficiency, and clean SDK.
- @bhalligan noted Shopify appears to be following the "Dorsey Mode" path after Tobi Lütke's mandate that reflexive AI usage is now a baseline expectation at the company.
AI Agents: From Demo to Production
The agent conversation has decisively shifted from "look what this can do" to "here's how you actually architect it." Anthropic's agents team released what @cyrilXBT called "exactly what production grade looks like," a four-layer framework for multi-agent systems built for real-world deployment. His summary was blunt:
> "Not theory. Not a tutorial. A four layer framework for multi agent systems built to actually work in the real world. 30 minutes. This is the video I wish existed 6 months ago."
This dropped alongside @signulll's provocative thread arguing that the modern computer needs to be reinvented from scratch, not improved, not given a chatbot sidebar, but fundamentally reconceived. The argument is that our current computing paradigm was built around a human staring at a screen, moving a cursor, opening apps. In an AI-native world, that's as absurd as "making a robot hand so it can use a doorknob instead of asking why the door needs a knob at all." The questions signulll raises hit hard: what is a file when the system understands context? What is an operating system when the primary user is a person plus a swarm of delegated intelligences?
McKinsey weighed in from the enterprise side, identifying four distinct roles emerging in agentic AI tech services, each with different capabilities and trade-offs. The consulting-speak aside, the signal is clear: agentic AI has crossed the threshold from research curiosity to strategic planning priority for major organizations.
Agent Memory and Token Economics
Two posts today tackled the nuts-and-bolts engineering challenges that determine whether agents actually work in production. @AYi_AInotes delivered a sharp diagnosis of why 90% of AI agent memory implementations are "fake," essentially just dumping history into Markdown files and pretending that's long-term memory:
> "真正的记忆不是堆文件,应该是图和节点加嵌入加遍历" (Real memory isn't piling up files, it should be graphs and nodes plus embeddings plus traversal.)
The core argument: Markdown has no deduplication, no decay, no ranking, and becomes a performance killer past 100 records. Vector retrieval can find similar passages but can't surface causal relationships. Only graph traversal can pull an entire chain of related memories like the human brain does. The post points to Zep, Cognee, and Mem0 as production-grade frameworks all built on graph architectures, and Neo4j's graph memory as a standard MCP tool.
On the cost side, @PawelHuryn shared a concrete claude.md configuration for subagent delegation that he claims saves 50%+ on tokens. The system routes tasks by model tier: Haiku for bulk mechanical work, Sonnet for scoped research and exploration, Opus for subtasks needing real planning. Subagents follow the same rules recursively with a max depth of two. It's paired with environment variables to disable the 1M context window and trigger autocompaction at 80%. This is the kind of operational knowledge that separates people burning through API credits from those running sustainable agent workflows.
Cloud Coding vs. Local Development
The debate over where developers should actually write code heated up again. @ryancarson posted what amounts to a public recantation of his earlier stance on building your own code factory, now calling it "a total waste of time." His new position is unequivocal:
> "If you're coding on your local machine instead of in the cloud, you're falling behind. Trust me."
He specifically praised Devin AI's "Test App" feature, which screen-records itself clicking through features, narrates what it's doing, identifies bugs, fixes them, and merges to main on command. With GPT-5.5 integration, he describes the workflow as landing PRs with a single !land command. His one exception: new UI-heavy features requiring fast iteration still benefit from local development, where he's using the new Codex with built-in browser control.
Meanwhile, the local AI crowd got a new tool. @morganlinton expressed excitement about LocalMaxxing from @LottoLabs, which launched with HuggingFace and GitHub authentication and an API endpoint ready for agent integration. The local vs. cloud divide isn't really about ideology anymore. It's about which tasks benefit from sandboxed cloud environments with built-in CI/CD versus which need the tight feedback loops of local development. Both camps are building real tools, and the smart money is on developers who can fluently switch between both modes.
Models, Research, and Fine-Tuning
A few research-oriented posts rounded out the day. @andrew_n_carr highlighted Kevin Murphy's work on using language models for probabilistic forecasting, a task LLMs supposedly can't do since they don't output raw probabilities:
> "Then you make a structured output and use Platt scaling to calibrate and you get SOTA on forecast bench."
It's a clean example of how clever engineering around model limitations can unlock entirely new capabilities. Rather than waiting for models that natively output calibrated probabilities, Murphy's approach wraps existing models in a structured output framework with post-hoc calibration, achieving state-of-the-art results.
On the fine-tuning front, @AlicanKiraz0 announced a cybersecurity-focused fine-tune of Qwen3.6-35B-A3B using a 1.3 billion token cybersecurity dataset, promising an open-source release this week. And @TheAhmadOsman offered a useful reframe for anyone thinking about inference: "You don't run a model. You run kernels. The model is just a graph." It's the kind of mental model shift that helps developers reason about optimization, deployment, and hardware requirements more clearly.
The $0/Month Digital Life
Finally, the most viral post of the day wasn't about AI models or agents at all. @om_patel5 documented someone who replaced over 30 paid subscription services with a self-hosted homelab built using Claude Code, running everything from Plex and Jellyfin to Immich (Google Photos replacement), Nextcloud (Google Drive replacement), and Paperless-NGX for document management. The entire stack runs on surprisingly modest hardware: an HP laptop with an i3 and 24GB RAM as the main hypervisor, a Compaq laptop for backups, and a tower PC running Unraid for NAS storage. Total cost: roughly $1,000-1,500 one-time versus $200+/month in subscriptions.
The Claude Code connection is worth noting: the builder used it to auto-generate the YAML configuration for Homepage, the self-hosted dashboard that ties everything together. It's a perfect example of AI tools amplifying the capabilities of the homelab community, which @om_patel5 calls "quietly the most overpowered and cracked group of builders on the internet." When AI coding assistants lower the barrier to managing complex infrastructure, the economics of self-hosting start looking very different.
Sources
A
Language models aren't able to output raw probabilities, so they can't be used for forecasting...unless you're Kevin Murphy.
Then you make a structured output and use Platt scaling to calibrate and you get SOTA on forecast bench https://t.co/3LWRdLqby4
S
sirbayes
@sirbayes
@rsalakhu @subail @chuckjhoover @asenkut @FHaskaraman Congrats! BTW you might find my recent paper of interest... https://t.co/eBJEOqRJnr
Z
> everyone chasing AI agents
> everyone chasing AI SaaS
> meanwhile this guy mapped the boring middle
> $47 K/month inside one local industry
> two operators, one offer, one vertical
> nobody on Twitter is building this yet
> the unsexy ones always print first https://t.co/bzkfPaoNX3

Z
Zephyr_hg
@Zephyr_hg
The $47K/Month AI Business Hidden Inside Every Local Service Industry (That Nobody Is Building)
A
Yeni Siber Güvenlik modelimi finetune'a başladım; Qwen3.6-35B-A3B'yi 1.3 Milyar token'lık cybersecurity datasetim ile finetune ediyorum 🔥 Bu hafta açık-kaynak olarak paylaşacağım. https://t.co/0ifGcR5SSs
M
Current 2x RTX 6000 build during an extended bench test. CPU at 100% and both GPUs at 100%. Recorded for noise and thermals documentation.
This is as loaded as I can get it on the 1600w titanium PSU. Pulling ~1650w at the wall.
People were interested in how the air cooled HX on the CPU would hold up so wanted to document. Cruises at about 95c even with the GPUs going nuts.
Had to cap GPUs around 535w for the test, that was just being safe with the PSU ceiling (got within 50w of the PSU hard cap) and I wanted to put maximum emphasis for this test on the CPU cooler under full load at the full 350w draw with GPU exhaust hitting it.
It genuinely holds up like a champ. It feels like my limits with this build at this point are power not thermals.

M
Agentic AI is changing how tech services create value.
We’re starting to see four distinct roles take shape, each with a different set of capabilities, bets and trade-offs.
The question isn’t whether to play but where to focus and how to build around it. https://t.co/Kg9LETGDur https://t.co/xPh9fS91UV

M
Lotto has been one of my favorite people to learn from in the local LLM world, he really knows his stuff.
Super excited to try LocalMaxxing.
L
LottoLabs
@LottoLabs
Bros https://t.co/2hx2V3euUv is ready Sign in with hf or GitHub Make an api key Get your agent to GET https://t.co/LlCXFRGJe3
R
If you want to get real work done - actually ship and build a business with velocity - I don’t understand why you would waste time trying to build your own code factory from scratch.
This is an about-face from my article where I explained how to build your own code factory.
That’s out dated now and a total waste of time.
It’s even dumber to try to work locally in parallel on multiple threads with port clash, worktree headaches, checkout drift and more.
Ever since I started using @DevinAI, my shipping velocity (and dev happiness) has increased drastically.
One of the killer features is the “Test App” feature which literally works out of the box.
It screen records and narrates itself clicking through the feature.
Then it identifies bugs surfaced during the tests, then proceeds to fix them.
Then when the PR is ship-ready, I just type !land and it merges to main (automatically reviewing and fixing all findings).
It’s seriously insane.
And now with gpt-5.5 it’s even more ridiculous.
All this plus dependable, hardened cloud VMs - I feel like you have to be a masochist to go back to trying to work on your Mac.
If you’re coding on your local machine instead of in the cloud, you’re falling behind. Trust me.
The only reason I dev locally now is if I have a new UI-heavy feature, and need super fast iteration and micromanagement of the agent.
For that, the new version of Codex with built-in browser control + annotations/comments is really good. It’s like @Agentationcom from @benjitaylor but it’s all built in out of the box.
B
Not quite Dorsey Mode, but Shopify sure seems to be on that path.
T
tobi
@tobi
Reflexive AI usage is now a baseline expectation at Shopify
S
the AI to 3D pipeline in 2026:
- generate concept art (GPT image, nano banana)
- image to 3D mesh (hunyuan3D, tripo, meshy)
- cleanup + rig (meshyai, tripo, blender)
- auto-animate (mixamo)
start to game-ready character in one afternoon.
now do it with a capybara. $600 in prizes.
O
THIS GUY REPLACED EVERY SUBSCRIPTION FOR OVER 30 SERVICES WITH A HOMELAB HE BUILT USING CLAUDE CODE
he built his own self hosted version of basically every service you pay for online and runs it all from a 27U server rack in his house
the goal was simple:
stop renting access to your own data, stop paying monthly subscriptions for things you can run yourself, and have one private dashboard that controls everything in your digital life
he opens one homepage on his browser and from there he can:
> stream his entire movie and TV collection through plex or jellyfin
> request a new movie through overseerr and watch it appear in his library automatically once it's downloaded and tagged
> back up every photo he takes through immich (his own google photos)
> store all his files through nextcloud (his own google drive)
> manage his audiobooks, ebooks, music, RSS feeds, recipes, and bookmarks from one place
> block ads across his entire network with adguard home
> see live grafana stats for every machine running in his house at any moment
and a lot more
the homepage dashboard even shows the current weather, his calendar, system stats, download queues, library counts, and shortcuts to every service he uses
the hardware list:
> netgate 1100 router running pfsense+ for firewall, DHCP, DNS, and VLANs
> tp-link 8 port managed switch
> tp-link archer C6 access point
> raspberry pi 4 dedicated to a full screen grafana dashboard
> HP laptop with i3 11th gen and 24GB RAM running proxmox VE as the main hypervisor
> compaq laptop with a core 2 duo and 4GB RAM running proxmox backup server
> tower PC with a core 2 duo running unraid for the NAS
the proxmox VE box runs every self hosted service inside a debian VM with docker compose. backups run on a schedule with chunk based deduplication. unraid handles all the storage with mixed drive sizes and a single parity drive
every device is on a tailscale tailnet so he can hit anything from anywhere in the world without poking holes in his firewall
then he built his own private streaming empire on top of it:
> plex and jellyfin pointing at the same library
> overseerr to request movies and shows
> radarr, sonarr, lidarr, readarr managing different media types
> prowlarr indexing everything
> sabnzbd and qbittorrent handling the downloads
> bazarr pulling subtitles automatically
> tautulli for plex stats
> trailarr for trailers
then the rest of the stack:
> nextcloud replaces google drive
> immich replaces google photos
> paperless-ngx for OCR document management
> adguard home blocks ads across the entire network
> miniflux for RSS, karakeep for bookmarks
> mealie for recipes, navidrome for music, audiobookshelf for audiobooks
> calibre for ebooks, code server for VS code in the browser
> stirling PDF, IT tools, microbin, searxng, pairdrop
every service surfaces through homepage, a self hosted dashboard he built tooling around to auto generate the YAML config (made with claude code)
this guy is paying $0 a month for what most people pay $200+ in subscriptions for and had an initial setup cost of ~1000 to 1500 USD
the homelab community is quietly the most overpowered and cracked group of builders on the internet

S
the craziest part now is that the modern computer probably has to be entirely reinvented, from scratch. pretty much like how jobs & co brought apple ii to market.
like not improved. not given a chatbot sidebar or something but really from the ground up like the iphone redefined what it meant to be a pocket computer.
the current paradigm for computers was built around a human staring at a screen, moving a cursor, opening apps, managing windows, naming files, remembering where things live, & manually translating intent into interface actions.
that made sense when the human was the runtime. but in an ai native world, it starts to look kinda ridiculous.
you can see this ridiculousness when you use computer use agents… they are useful sure, but they’re also obviously transitional. they’re teaching ai to operate machines designed for humans, which is clever, but also kind of absurd. it’s like making a robot hand so it can use a doorknob instead of asking why the door needs a knob at all. yes i know humans also need to use a door knob, but maybe in the future humans don’t need to use a computer, or at least what we think of a computer today at all.
this all leads to some interesting questions:
- what is a file when the system understands context?
- what is an app when intent can route itself?
- what is a desktop when work can be decomposed, executed, monitored, & summarized by agents?
- what is a browser when the agent can retrieve, compare, transact, & remember?
- what is an operating system when the primary user is no longer just a person, but a person plus a swarm of delegated intelligences? or no person at all.
the old computer assumed navigation.
the new computer has to assume a new kind of intention. the old computer organized information. the new computer has to try to organize agency.
we’re still in the hacky middle stage at the moment with sidebars, copilots, agents clicking through legacy ui, & automation layers sitting on top of 40 year old metaphors.
the new computer is likely one where memory, context, identity, permissions, tools, agents, & interfaces are native primitives. this means desktop, mobile, browser, apps, files, folders deserves another first principles look.
C
ANTHROPIC JUST KILLED THE DEMO AGENT ERA.
Their Agents team showed exactly what production grade looks like.
Not theory.
Not a tutorial.
A four layer framework for multi agent systems built to actually work in the real world.
30 minutes.
This is the video I wish existed 6 months ago.

阿
说个暴论,现在90%的AI Agent记忆,全都是假的。
我之前也踩过这个坑,把所有历史记录决策日志全堆进Markdown文件里,以为这就是给Agent加了长期记忆,结果用了两周就崩了,
同一个事实有三个互相矛盾的版本,上个月的偏好和昨天的权重一模一样,每次调用都把所有东西一股脑塞进上下文,慢到离谱还经常串台,
直到看到这篇文章才恍然大悟,原来我根本不是在做记忆,只是在把Prompt当RAM用🌚
真正的记忆不是堆文件,应该是图和节点加嵌入加遍历,
Markdown方案有四个根本解决不了的硬伤,没有去重,没有衰减,没有排名,超过一百条记录直接变成性能杀手,
它只能记住你写过什么,永远记不住这件事和那件事有什么关系,
这个决策为什么被否决,上次遇到同样的bug我们是怎么解决的。
向量检索也不行,它只能告诉你这两段话长得像,不能告诉你它们之间的因果关系,
只有图遍历能做到,它能像人脑一样,从一个节点牵出一整条相关的记忆链,
重要的事情越来越清晰,过时的信息自动淡化,矛盾的内容在写入时就被解决。
现在所有生产级的Agent框架,Zep Cognee Mem0,全都是基于图的,
Neo4j已经把图记忆做成了标准的MCP工具,
Claude Code超过二十万行代码之后,纯上下文窗口早就没戏了,
真正能让它像高级工程师一样思考的,
是把不变的规则放在CLAUDE.md里,
把所有演化的状态全部存在图里,动态检索按需拉取。
很多人还在卷一百万两千万的上下文窗口,以为越大越好,
但生产环境里真正致命的,
永远是跨会话的记忆漂移和上下文污染,
内存架构的升级已经不是锦上添花了,能不能把Agent真正用起来才是关键的生死线。

A
aiedge_
@aiedge_
How to Give Claude Perfect Memory (complete guide)
A
RT @TheAhmadOsman: You don’t “run a model”
You run Kernels
The model is just a graph
The Inference Engine is scheduler / optimizer / exec…
P
Paste this into your claude.md and measure your usage in a week.
My bet: you’ll save more than 50% of tokens.
---------------
## Task Delegation
Spawn subagents to isolate context, parallelize independent work, or offload bulk mechanical tasks. Don't spawn when the parent needs the reasoning, when synthesis requires holding things together, or when spawn overhead dominates.
Pick the cheapest model that can do the subtask well:
- Haiku: bulk mechanical work, no judgment
- Sonnet: scoped research, code exploration, in-scope synthesis
- Opus: subtasks needing real planning or tradeoffs
Subagents follow the same rules recursively, with two caps:
- Haiku does not spawn further subagents. If it needs to, the task was wrong-sized for Haiku — return to the parent.
- Maximum spawn depth is 2 (parent → subagent → one further tier).
Don't escalate tiers without a concrete reason. If a subagent realizes it needs a higher tier than itself, return to the parent rather than spawning up.
Parent owns final output and cross-spawn synthesis. User instructions override.
## Preferred Tools
### Data Fetching
1. **WebFetch** — free, text-only, works on public pages that don't block bots.
2. **agent-browser CLI** — free, local Rust CLI + Chrome via CDP. For dynamic pages or auth walls that WebFetch can't handle. Returns the accessibility tree with element refs (@e1, @e2) — ~82% fewer tokens than screenshot-based tools. Install: `npm i -g agent-browser && agent-browser install`. Use `snapshot` for AI-friendly DOM state, element refs for interaction.
3. **Notice recurring fetch patterns and propose wrapping them as dedicated tools.** When the same fetch/parse logic comes up more than once, suggest wrapping it as a named tool (e.g. a skill file or a .py script that calls `agent-browser` with the snapshot and extraction steps baked in for that source). Add the entry to `## Dedicated Tools` below and reference it by name on future calls.
### PDF Files
Use 'pdftotext', not the 'Read' tool. Use 'Read' only when the user directly asks to analyze images or charts inside the document.
## Dedicated Tools
---------------
Plus, add this to settings.json:
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1",
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "80"
}
P
PawelHuryn
@PawelHuryn
Claude Code's Limits Are Generous. The Problem Is Your Harness.
M
RT @s_streichsbier: Pi is just incredible.
- works reliably
- renders fast
- no complexity
- /tree
- great sdk
- token efficient