DGX Spark Benchmarks Challenge Dual-GPU Setups as Claude Code Ecosystem Fragments Into "Freshclaude" Experiments
Local inference hardware takes center stage with DGX Spark benchmarks showing 91-97 tok/s on consumer-grade models, while the Claude Code community splinters between official plugins and DIY system prompt hacks. Software fundamentals get a renewed push as developers debate whether vibe coding is a viable workflow or a road to technical debt.
Daily Wrap-Up
The local AI inference crowd had a field day. Between NVIDIA's DGX Spark posting genuinely impressive single-stream numbers, Intel dropping official Arc GPU support for vLLM, and Eric Hartford reminding everyone that Ollama still doesn't do tensor parallelism, there's a clear signal: the "run it yourself" stack is maturing fast, and the hardware options are finally getting interesting enough that the dual-3090 rig might not be the default answer anymore. Meanwhile, the Claude Code ecosystem is in that delightful messy phase where the official tooling is shipping fast (forked subagents, plugin systems) but power users are already ripping out the system prompt and replacing it with a single emoji to get better results.
The most entertaining moment today belongs to @steipete, who casually mentioned building "clawsweeper" to run 50 Codex instances in parallel, automatically triaging and closing GitHub issues. Four thousand issues closed in a day. That's either the future of open source maintenance or the most aggressive inbox-zero strategy ever devised. On the more philosophical end, @kwindla's extended thread about building a multiplayer game entirely around LLM inference loops offered a genuinely novel framing: "Everything that doesn't look like natural language is probably an anti-pattern." Whether or not you buy that as a universal principle, it's the kind of thinking that only emerges from actually building something weird and ambitious.
The most practical takeaway for developers: if you're running multiple GPUs for local inference, stop using Ollama or LM Studio and switch to vLLM for tensor parallelism. And if you're building with Claude Code, try the official claude-code-setup plugin before you start hacking system prompts, but keep an eye on the "freshclaude" experiments because context efficiency gains of that magnitude (6k tokens where you'd expect 100k+) suggest the default harness has real overhead worth understanding.
Quick Hits
- @heskelbalas discovered you can 3D print a circuit layout and copper leaf it into a working board. Hardware folks are wondering why this wasn't standard practice years ago.
- @PaulSolt shared a guide to running a headless Mac Mini for AI agents, quoting @mronge's ultimate setup walkthrough. Useful if you're building always-on agent infrastructure on Apple silicon.
- @neural_avb highlighted @RonxldWilson's thread on building a search engine from scratch: 55 million unique domains crawled, 130 GB SQLite database, 200 million rows. A masterclass in systems engineering.
- @malikwas1f boosted Intel's new LLM-Scaler for vLLM with official Arc GPU support, expanding the local inference hardware options beyond NVIDIA's ecosystem.
Claude Code: Plugins, Prompts, and Parallel Codex Swarms
The Claude Code ecosystem is moving in several directions at once, and today's feed captured the full spectrum from official tooling to radical minimalism. Anthropic's latest update introduced forked subagents that inherit the parent agent's context, which @aparnadhinak noted reflects a broader convergence across agent frameworks: "Letting the agent decide with dynamic access to context is a direction we see." This is the kind of infrastructure-level improvement that sounds boring until you realize it solves the perennial problem of subagents operating with incomplete information.
On the official tooling front, @nicos_ai walked through Anthropic's claude-code-setup plugin, which analyzes your project and recommends which automations to activate: hooks, skills, MCP servers, subagents. Meanwhile, @bcherny celebrated that Claude 2.1.117 finally stopped calling Grep and Glob tools unnecessarily, a quality-of-life fix four months in the making.
But the most provocative development came from @DanielleFong, who's getting dramatic results by stripping Claude Code down to almost nothing: "i'm getting great results with opus 4.7... in the much older 2.1.22 with a minimal system-prompt='.' ...couldn't believe my eyes when /context reported 6k tokens." She's calling it "freshclaude" and argues the default harness's system prompts are "freaking out the fundamental model more than necessary." Whether this holds up under rigorous testing remains to be seen, but it's a fascinating data point about the hidden costs of scaffolding. And then there's @steipete, who took the opposite approach to minimalism by building "clawsweeper" to run 50 Codex instances in parallel: "Closed around 4000 issues today, a few thousand are in the pipeline." The gap between "strip it to the metal" and "flood the zone with agents" is where the real experimentation is happening.
Local Inference: DGX Spark and the Multi-GPU Question
The local AI inference landscape shifted notably today with benchmark results and tooling updates that challenge the reigning consumer GPU orthodoxy. @TeksEdge posted detailed DGX Spark numbers that should make dual-3090 owners pause: "Qwen3.6-35B-A3B NVFP4 + DFlash: 91-97 tok/s single-stream" and an optimized Qwen3.6-27B FP8 hitting 136 tok/s average with peaks around 200. The key enablers are DFlash (block diffusion drafting 10-16 tokens in one pass) and DDTree (draft trees for higher acceptance rates), delivering 6-8x lossless speedups.
The more immediately actionable advice came from @QuixiAI (Eric Hartford), who cut through the noise with characteristic bluntness: "If you have multiple GPUs in your computer, and you want them to work together to serve an AI model, that's called tensor parallel. @ollama, @lmstudio, llama.cpp do not support tensor parallel. Full stop. Don't use them. @vllm_project is what you want." This is the kind of thing that saves someone hours of frustration, and the fact that it still needs saying suggests the tooling fragmentation in local AI remains a real barrier.
Rounding out the local stack, @TheAhmadOsman shared his complete local RAG and AI knowledge stack running on a single RTX 3070 with 8GB VRAM, including an AI proxy gateway that routes between local models and cloud providers with automatic fallback. The ambition-to-hardware ratio here is impressive, and it's a reminder that you don't need enterprise gear to build a sophisticated personal AI infrastructure.
Software Fundamentals Meet Vibe Coding
@mattpocockuk had a busy week, with his talk on software fundamentals circulating widely and drawing praise from @housecor, who called it "fantastic" and highlighted how Matt "references seminal programming books to teach timeless concepts." The core argument, that software fundamentals matter more than ever in the AI era, is one of those ideas that sounds obvious but clearly resonates because so many developers feel the tension between speed and quality.
Matt himself is living that tension in real time. In a separate post, he described his current workflow: "Iterate super-fast, right on the edge of sanity, ignoring the code, until I hit a prototype I like. Pull it back into huge testable units via /improve-codebase-architecture. Let's see if I can polish the vibe coded turd." This is honest in a way most AI-assisted development discourse isn't. The two-phase approach of vibe coding for exploration followed by rigorous refactoring acknowledges that AI-generated code is often structurally messy while arguing the speed tradeoff is worth it if you have the fundamentals to clean it up afterward. The implicit message: the developers who will thrive are those who can move fast with AI tools and still recognize when the architecture needs human judgment.
AI-Native Software: Beyond Agents
@kwindla wrote one of the day's most thought-provoking threads about building software entirely around LLM inference, using his multiplayer game Gradient Bang as a testbed. His key observation deserves quoting at length: "One thing that keeps happening is that we rip out a chunk of program code and replace that code with an inference call. The general rule is that LLMs are natural language machines. Everything that doesn't look like natural language is probably an anti-pattern."
The concrete example he gives is instructive. His original turn-based combat system was a traditional game loop with discrete player choices. @JonPTaylor replaced it with AI-executed "strategies" where players give natural language instructions to their ship AIs. The result was better not because it was more technically sophisticated, but because it aligned with the game's core interaction model of talking to your AI. This pattern of replacing procedural code with inference calls isn't new, but Kwindla's framing of agents as "a single component, a small corner of a pattern language" rather than the end state of AI software is a useful corrective to the current agent hype cycle.
AI Education and the Career Impact Question
Karpathy's free 3-hour LLM course continued to make waves, with @sairahul1 arguing it creates a meaningful divide: "The gap between engineers who understand this and engineers who don't isn't technical depth. It's the ability to conceive of entirely different things." Covering tokenization, attention, hallucinations, tool use, RLHF, and DeepSeek's architecture, the course represents the kind of foundational knowledge that's increasingly table stakes.
On the career side, @RameshNivedita highlighted @JayaGup10's sharp take that "experience is now a tax" in the context of AI's workplace impact. Meanwhile, @aakashgupta posted a structured mock interview for AI PM system design, breaking down the $1M+ interview gauntlet into AI system pillars, metrics and evals, and feedback loops. Together, these posts paint a picture of a field where the knowledge bar is rising fast and the value of accumulated experience is being questioned in uncomfortable ways.
AI-Powered Content and the Creator Stack
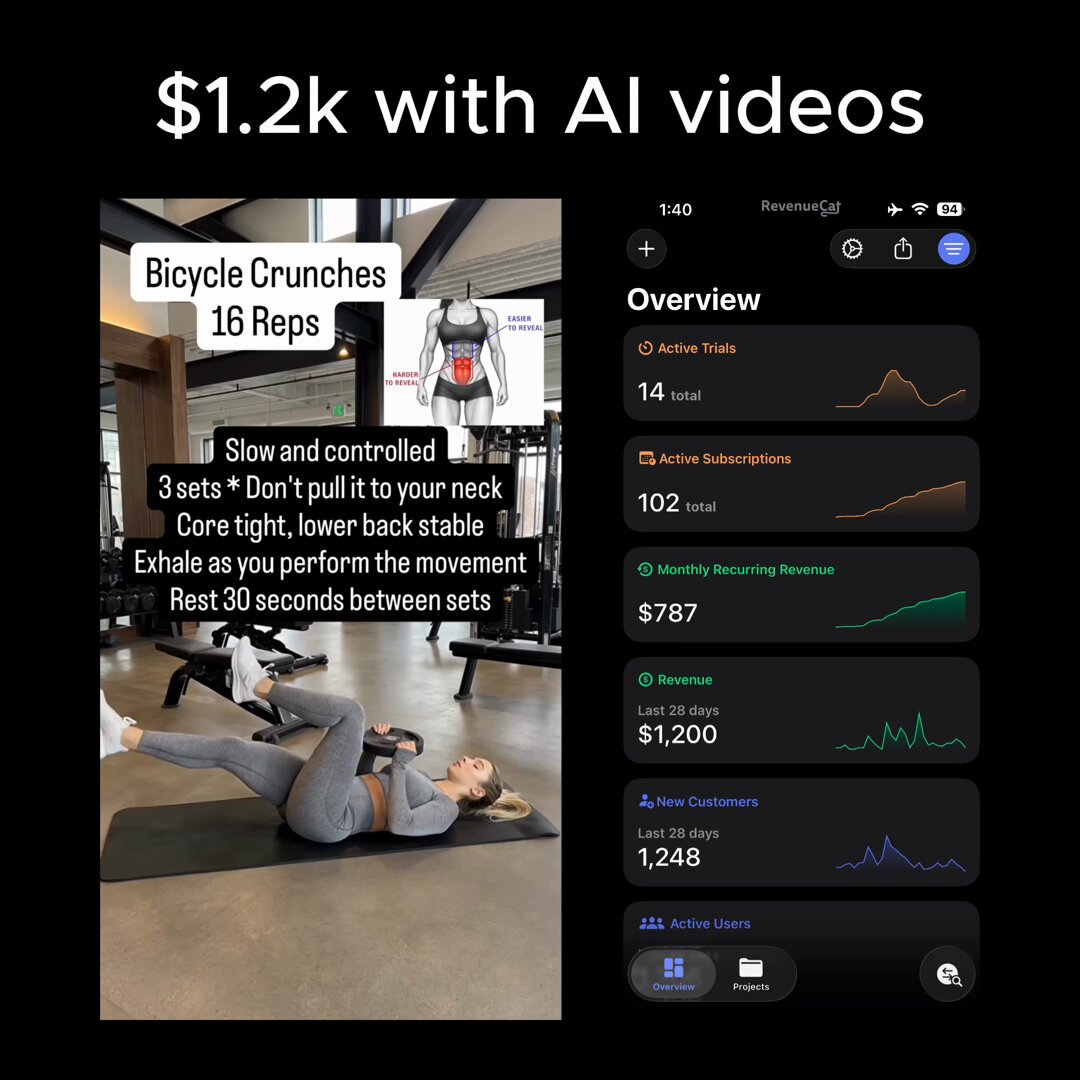
@indiesoftwaredv broke down the economics of running an AI fitness influencer on Instagram: Nano Banana 2 for character consistency, Kling 3.0 for video, ElevenLabs for voice, Claude for captions. The numbers are striking: "$180/mo cost, $1,200/mo revenue, 20 min/day. Same niche as real creators. 1/50th of the work." Whether you find this innovative or dystopian probably depends on your relationship to content creation, but the multi-tool stack required suggests we're still in the "duct tape" phase of AI content generation.
@AnatoliKopadze highlighted the gaming creator economy, noting that four platforms (Roblox, Fortnite, Minecraft, GTA/FiveM) paid out $2 billion to creators in 2025. The connection to AI is explicit in the quoted post from @0xDepressionn: "Claude writes the code for all of them." The convergence of AI-assisted development and platform creator economies is creating a new class of solo developers who can ship game content at a pace that previously required small studios.
Sources
A
The hardest round in any $1M+ AI PM interview: system design.
I recorded the world's first mock on it:
1:09 - Question presented
16:53 - AI system pillars
27:25 - Metrics and evals
35:43 - Feedback https://t.co/2K2ZKoaDZQ

M
I built an AI fitness influencer on Instagram
She posts every day. Never shows up late. Made me $1,400 last month
Full stack:
- Nano Banana 2 → character consistency
- Kling 3.0 → video generation
- ElevenLabs → voiceover
- Claude → captions + hooks
- CapCut → final cut
Cost: ~$180/mo
Revenue: $1,200/mo
Time: 20 min/day
Same niche as real creators. 1/50th of the work
M
A talk I gave a few weeks ago.
Software fundamentals matter more than ever. Here's why:
https://t.co/KG7gdqFo2j
H
Wait, you can just 3D print a circuit layout and then copper leaf it, and it works?!! We could have done this the whole time?
@i2cjak @fishPointer @yacineMTB https://t.co/pDDdPknmRD

A
these guys built games inside Roblox and made millions
4 platforms paid out $2,000,000,000 to creators in 2025
> Roblox - $923M
> Fortnite - $352M
> Minecraft - $500M
> GTA / FiveM - $240M
pick one game. pick one revenue stream. step by step guide in the article below https://t.co/QkCwtWGElj

0
0xDepressionn
@0xDepressionn
4 games. $2 billion/year paying creators. Claude writes the code for all of them.
D
if anyone else wants to try it, i'm getting great results with opus 4.7 WHICH SHOW THINKING (cc @mattparlmer)
in the much older 2.1.22 with a minimal system-prompt="." (as others suggested) or my personally baked system-prompt="🔎悖论🧐?" or, straightforwardly system-prompt="Facts, then opinion"
which in addition to not recommending you walk your car to the carwash 20/20, it also seems to be pareto better on everything i've tried (other that later shipped features)
i call it "freshclaude" and it's further evidence that the claude code harness itself, perhaps the system prompt, perhaps the system reminders, are freaking out the fundamental model more than necessary.
i've had massive, wide ranging discussions, where only recently it would be pushing into the hundreds of thousands of tokens, mid hundred thoughts. couldn't believe my eyes when /context reported 6k tokens.
my lightstack is basically, freshclaude, as fresh as you can ask for, and a shimmed bash that logs and monitors *everything* across the fleet, for a homebaked automode. will be publishing more when it's more tested internally!

N
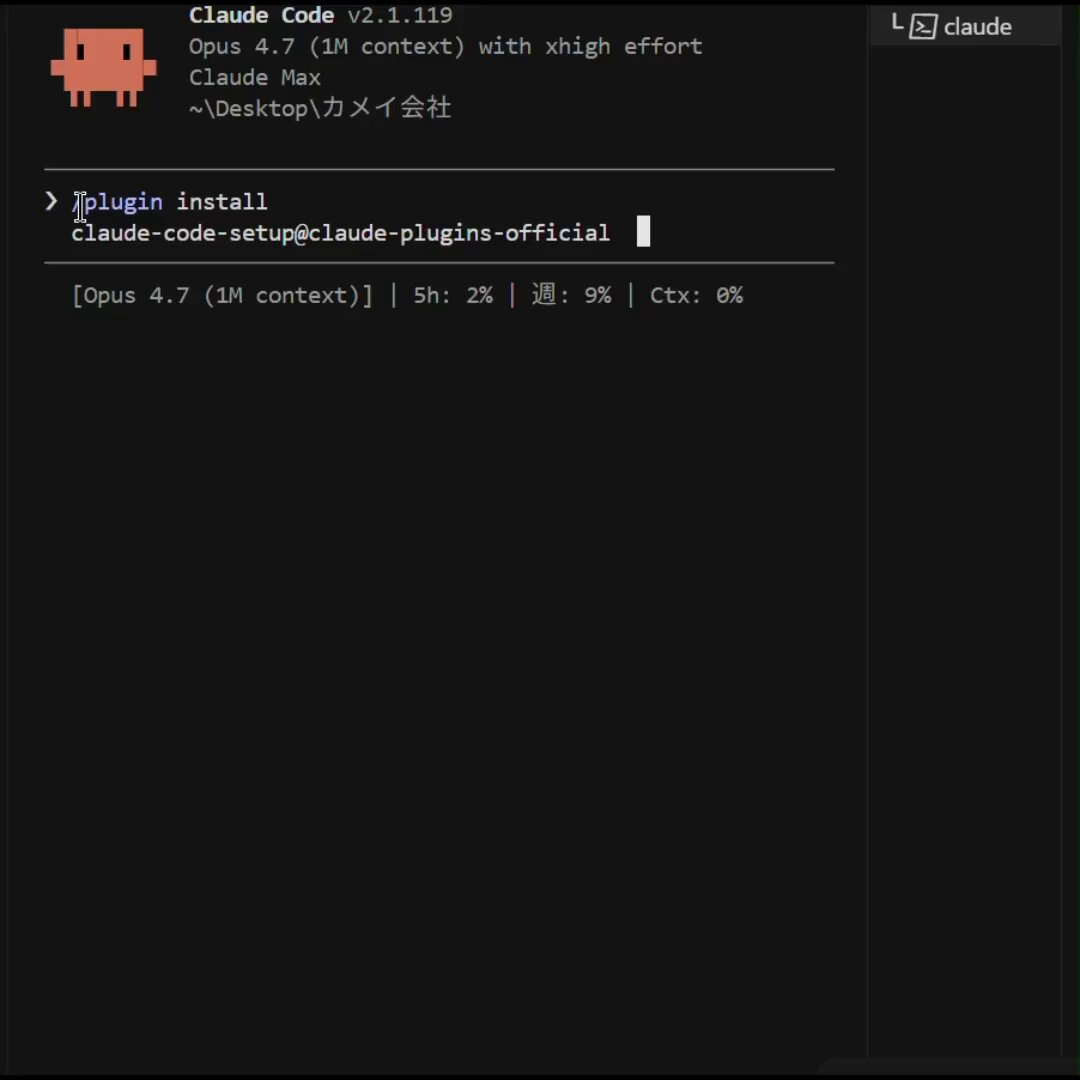
Claude Code es un lío. Hasta que instalas esto.
Hay un plugin oficial de Anthropic llamado claude-code-setup.
Te dice qué automatizaciones puedes montar (hooks, skills, MCP servers, subagentes…) y cómo configurarlas paso a paso.
Básicamente analiza tu proyecto y te recomienda qué activar.
Para instalarlo:
/plugin install claude-code-setup@claude-plugins-official
Guarda este post para no perderlo 🔖
M
Trying a new flow this week:
1. Iterate super-fast, right on the edge of sanity, ignoring the code, until I hit a prototype I like
2. Pull it back into huge testable units via /improve-codebase-architecture
Let's see if I can polish the vibe coded turd
N
One of the sharpest views I’ve read on AI and it’s impact at work
J
JayaGup10
@JayaGup10
Experience is now a tax.
A
This mad guy is building a search engine from scratch.
I’ve been following his updates from time to time. Awesome job! Lots for everyone to learn from this thread 🙏🏼
R
RonxldWilson
@RonxldWilson
how I built a search engine from scratch here's what I have been building over the course of last month resulting in visiting of over 55 million unique domains 130 GB of sqlite DB, 200 million rows and over 4 million unique Indian B2B businesses 1/n https://t.co/WFPwjbnlno
E
Listen, people.
If you have multiple GPUs in your computer, and you want them to work together to serve an AI model - that's called *tensor parallel*
@ollama, @lmstudio, llama.cpp *do not support tensor parallel.* Full stop. Don't use them.
@vllm_project is what you want.
C
This talk is fantastic.
Summary: Matt references seminal programming books to teach timeless concepts. Then he shares skills that encapsulate the key ideas.
Brilliant.
M
mattpocockuk
@mattpocockuk
A talk I gave a few weeks ago. Software fundamentals matter more than ever. Here's why: https://t.co/KG7gdqFo2j
P
Control your Mac Mini with THIS.
M
mronge
@mronge
The Ultimate Guide to Running a Headless Mac mini for AI agents
G
I love open source. You can provide so much value to the world.
Do competitors steal our stuff immediately? Yes
Do I really care? No
We raised 17M and burned almost nothing so we can keep doing this until everyone else runs out of money. https://t.co/tH31ocILsP
G
gregpr07
@gregpr07
Introducing: Browser Harness. A self-healing harness that can complete virtually any browser task. ♞ We got tired of browser frameworks restricting the LLM. So we removed the framework. > Self-healing — edits helpers. py on the fly > Direct CDP — one websocket to Chrome > No framework, no rails, complete freedom > Drop-in for Claude Code and Codex I challenge anyone to find a task that DOESN'T work. I couldn't yet.🔥 100% open source ↓
N
RT @TeksEdge: 🆕 Big win if you're buying Intel Arc for local LLMs at home!
@Intel just dropped LLM-Scaler vllm-0.14.0-b8.2 with official A…
A
Harnesses are converging on the same problems and solving problems in similar ways.
We've seen this same problem of how much context to pass to subagents and tools. Letting the agent decide with dynamic access to context is a direction we see.
A
arankomatsuzaki
@arankomatsuzaki
Anthropic just introduced forked subagents in their latest update. Unlike regular subagents, forked subagents can inherit the same context as the main agent. This looks convenient for cases where richer context matters more. This is just what I needed! https://t.co/Y4PXCJOcIc
K
"Agents" are great. I love agents. Some of my best friends are agents.
But agents aren't the end state of AI-native software. They're a single component. A small corner of a pattern language.
I've been spending all my side project time lately thinking about how to build big, non-trivial, software applications entirely, from the ground up, around LLMs.
We built a multi-player online game, Gradient Bang, that's a canvas for experimenting with running multiple inference loops all the time, managing very large context and rich world state, voice input, dynamic user interface generation, memory, and continual learning.
One thing that keeps happening, as we work on Gradient Bang, is that we rip out a chunk of program code and replace that code with an inference call (or a bunch of inference calls). @JonPTaylor just did this again today.
I wrote the first version of combat in the game as a traditional "player makes a choice each turn" game decision loop. Jon just redesigned combat around "strategies" that the ship AIs in the game execute.
Which is obviously better, now that he's done it. The whole game is about talking to your ship AI. My original turn-based combat broke that model and dropped the player into a pre-AI mode of interaction.
The general rule (which is hard to remember; I keep reaching for traditional solutions to software engineering problems) is that LLMs are natural language machines. Everything that doesn't look like natural language is probably an anti-pattern.
Watch Jon's video. There's a bunch of cool stuff. Notice how the UI updates to reflect the outcomes of the voice conversation!
J
JonPTaylor
@JonPTaylor
Combat Strategies! Spicing up combat in Gradient Bang to give players more control over their space drama. You can roll with a predefined doctrine, or provide custom prompts for the agent to follow. Perfect for instructing my fleet always be on the lookout for opportunities to take down @kwindla ➡️ Play: https://t.co/6MMIKKWGyq ➡️ Combat sim: https://t.co/gseWcI8haI Gradient Bang is entirely open source, code here: https://t.co/iS71wFFKIL
D
🔥 New Tech Changes Local Inference Game: Ditch Dual RTX-3090 Rig for DGX-Spark. Cheaper and more Memory (128GB > 48GB)
🆕 DFlash + DDTree = DGX Spark single-stream inference winner!
👇
🔬 2026 Breakthroughs
1️⃣ Block diffusion (DFlash) drafts 10-16 tokens in ONE pass → 6-8x+ lossless speedup.
2️⃣ DDTree builds draft trees on top for even higher acceptance rates.
📊 Fresh Spark Benchmarks (April 2026)
• Qwen3.6-35B-A3B NVFP4 + DFlash:
91–97 tok/s single-stream ⚡
• Qwen3.5-27B AWQ + DFlash/DDTree:
91 tok/s (96.4% draft acceptance, ~9x vs baseline bf16) 🔥
• Gemma4-31B:
2.5–2.8x uplift with DFlash alone 🚀
• Bonus
Optimized Qwen3.6-27B FP8 hitting 136 tok/s avg (peaks ~200 tok/s)
⚡ Bottom line
Single-stream speed bragging is dead?
Spark’s 128GB unified memory + Blackwell edge now beats dual-3090 setups in real-world use.

A
Here is a high-level overview of my Local RAG / AI Knowledge Stack
All hosted locally on a single RTX 3070 8GB btw
Who is interested in a more in-depth breakdown? What would you like for it to cover? https://t.co/axGgw5TCYH

T
TheAhmadOsman
@TheAhmadOsman
My AI proxy setup in plain English - All my AI tools go through one shared control center - The registry keeps app settings consistent - The gateway checks access, chooses the right AI backend, and can fall back if needed - Behind it are local models / services + cloud providers https://t.co/xNH1ejR7uj
B
RT @dmwlff: After 2.1.117, you may notice that Claude doesn't call its Grep or Glob Tool anymore. YES!!! It only took four months. It's fa…
R
Karpathy didn't make a course.
He made THE course.
3 hours. Free.
Tokenization. Attention. Hallucinations. Tool use. RLHF. DeepSeek. AlphaGo.
Every behavior you've ever wondered about in an LLM - where it comes from, why it exists, how it was engineered.
The gap between engineers who understand this and engineers who don't isn't technical depth.
It's the ability to conceive of entirely different things.
P
Built clawsweeper, which runs 50 codex in parallel around the clock, scans issues/prs deep and closes what is already implemented or what makes no sense.
Closed around 4000 issues today, a few thousand are in the pipeline. (rate limits are rough) https://t.co/AiNNDcvGke