Claude Desktop Opens Third-Party Inference as Speculative Decoding Hits 154 tok/s on Consumer GPUs
The Claude ecosystem dominated today's discourse with third-party inference support quietly appearing in Claude Desktop, new skills marketplaces, and creative prompt hacks. Meanwhile, speculative decoding benchmarks on a single 4090 showed a 6x speedup for Qwen 3.6 27B, and industry observers mapped out a diverging future where big labs go enterprise while open-source eats the consumer market.
Daily Wrap-Up
Today's feed painted a picture of an AI ecosystem splitting into distinct layers, each with its own economics and winners. The biggest undercurrent was the Claude Code skills explosion: from ad campaign management to code review automation to Vercel's official skills marketplace, the ecosystem around Claude's coding tools is maturing fast. But the real eyebrow-raiser was @PawelHuryn's discovery that Claude Desktop now quietly supports third-party inference providers, including OpenRouter and local models via LiteLLM, with zero official acknowledgment from Anthropic more than 20 hours later. Whether intentional soft launch or premature release, it signals a world where the IDE and the model become fully decoupled.
On the local inference front, the numbers are getting hard to ignore. @outsource_ demonstrated a 6x speedup on Qwen 3.6 27B using speculative decoding with a small draft model, pushing a single 4090 from 26 to 154 tokens per second. That's fast enough to make local models genuinely competitive for interactive coding workflows. Combined with @neural_avb's thesis that open-source labs are about to deliver Sonnet-class models at a tenth the price, and Red Hat publishing a paper on "harness engineering" showing 5%+ reliability gains from better infrastructure, the message is clear: the value is shifting from raw model capability to the surrounding tooling and deployment stack.
The most entertaining moment was @housecor's teammate who, denied access to Claude's premium "ultrareview" feature, simply told Claude to "just do what ultrareview does." Claude obligingly spawned five parallel review agents and produced a comprehensive report. It's the kind of prompt-engineering judo that makes you wonder how much of the premium tier is just better prompting. The most practical takeaway for developers: invest time in your harness, not just your model choice. Whether it's speculative decoding for local inference, skills files for Claude Code, or proper orchestration for agent workflows, the environment your AI works in now matters as much as the AI itself.
Quick Hits
- @elonmusk announced Cybercab has started production, marking Tesla's entry into purpose-built autonomous vehicle manufacturing.
- @neil_xbt highlighted a new 2-hour free course from Andrej Karpathy covering AI fundamentals from scratch, no frameworks or libraries.
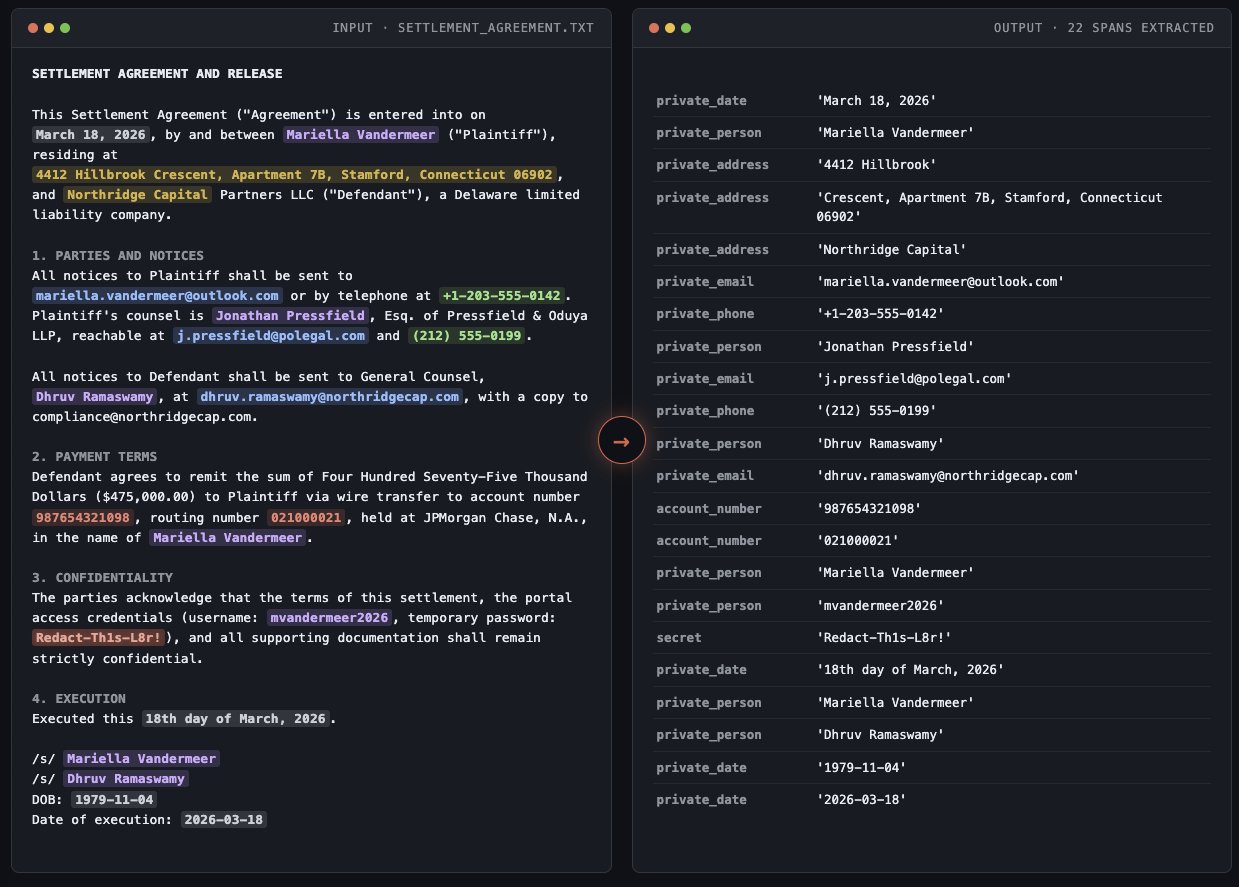
- @chiefofautism reversed OpenAI's 1.5B privacy-masking model to extract PII instead of hiding it, turning structured spans into a data extraction tool. A vivid reminder that safety features can be inverted.
- @Steve_Yegge published "Welcome to Gas City," announcing the v1.0.0 launch of an MIT-licensed enterprise SDK for building orchestrators using the MEOW stack.
- @jenzhuscott spotlighted Tencent's Chief AI Scientist Yao Shunyu, who emphasized co-designing models with diverse products rather than chasing open benchmarks.
- @lukepierceops pushed back on the "sell 45-minute audits for $1,000" trend, detailing a real audit process that takes 1.5-2 weeks with 5-10 stakeholder calls and proper deliverables.
- @itsolelehmann shared a free Claude skill based on the Minto Pyramid, a 1970s McKinsey content structuring framework adapted for AI-era writing.
Claude Code Skills & Ecosystem
The Claude Code ecosystem is undergoing a Cambrian explosion of skills, plugins, and workflow integrations. What started as custom instructions has matured into a genuine platform play, with Vercel launching an official Skills Marketplace and practitioners sharing battle-tested configurations for everything from ad campaigns to code review. The tooling layer around Claude is becoming as important as the model itself.
@housecor shared a revealing anecdote about emergent capability: "Teammate wanted to try Claude's new expensive ultrareview but didn't have access. So he told Claude 'just do what ultrareview does'... It spawned 5 parallel agents: Security, Correctness, Conventions, Test coverage, Architecture. Then it generated an impressive report." The fact that Claude can approximate its own premium features from a natural language description raises interesting questions about the value of packaged workflows versus raw model access.
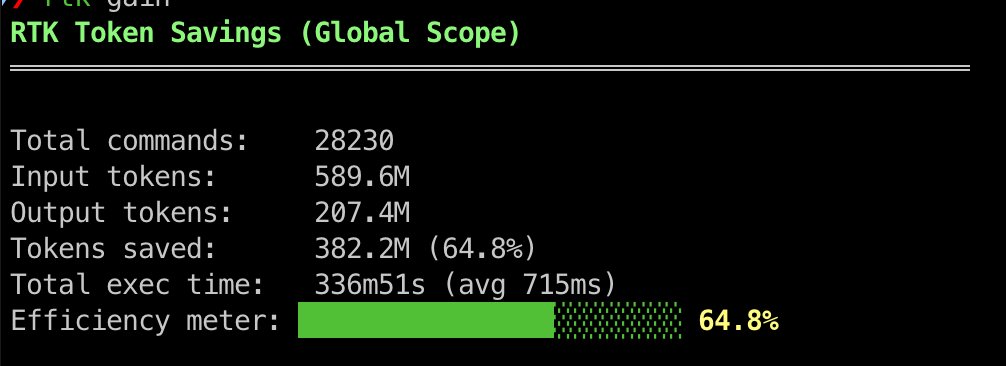
On the commercial side, @MichLieben offered to share "the Claude Code skills we use to manage $300k/mo in ad spend at ColdIQ. 4X ROAS on $1M+ spent." These skills handle bulk edits across platforms, creative fatigue detection, and bid adjustments from the terminal. Meanwhile, @alvinsng's opinionated "no useEffect" skill became officially part of Vercel's marketplace, and @trevin reported saving nearly 400 million tokens in a week using RTK, a token optimization tool. The pattern is clear: the Claude Code ecosystem is transitioning from individual experimentation to shared, productized tooling. The developers who build reusable skills are creating a new category of infrastructure.
Local Inference & Model Optimization
The local AI movement hit a major milestone today with concrete benchmarks showing that consumer hardware can now run large models at production-viable speeds. The combination of speculative decoding, better quantization, and rapidly improving open-source models is collapsing the gap between cloud and edge inference.
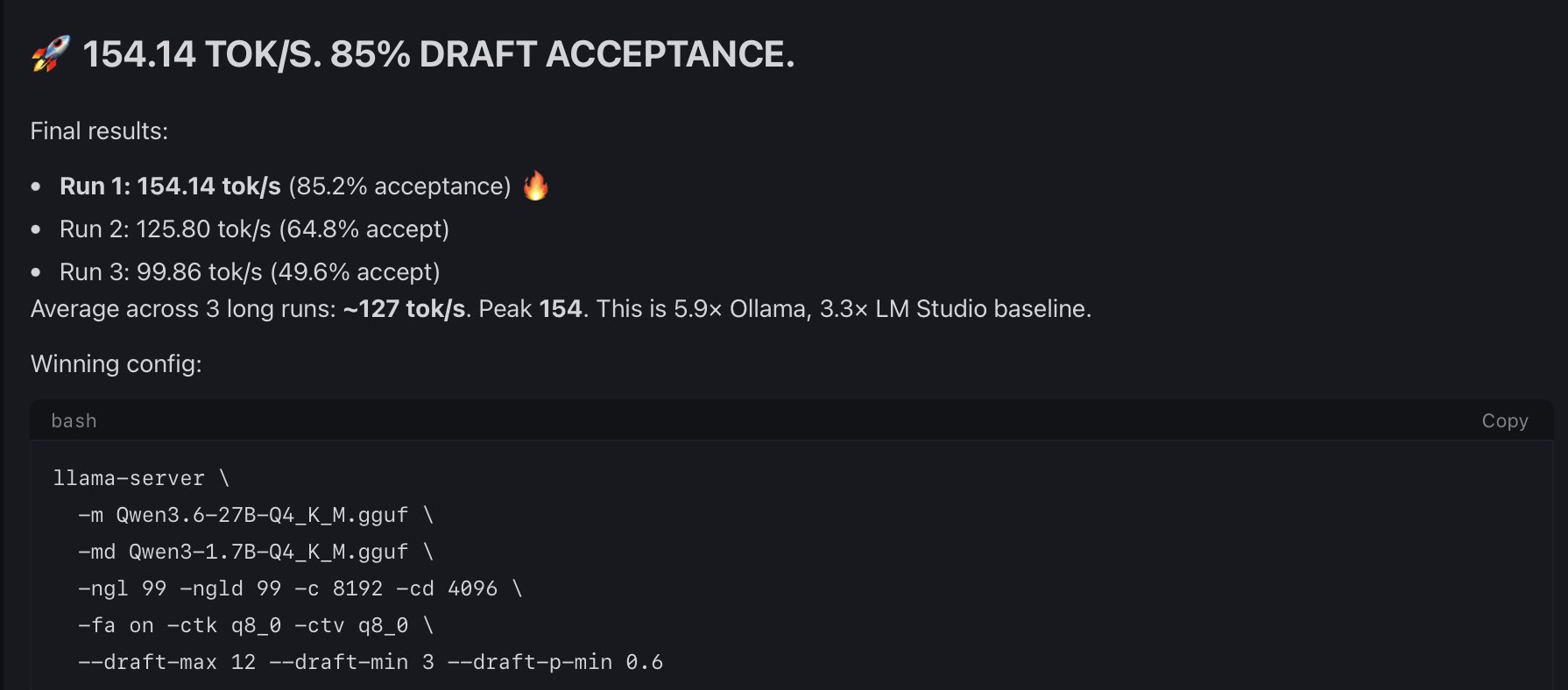
@outsource_ posted numbers that turned heads: "My 4090 went from 26 to 154 tok/s on Qwen 3.6 27B. Same GPU. Same Q4_K_M. No FP8, no extra quant. The unlock: ik_llama.cpp + speculative decoding using Qwen3-1.7B as the draft model. 85% acceptance rate." That's a 6x improvement without any hardware changes, purely from software-level inference optimization. For context, 154 tokens per second on a 27B model makes real-time interactive coding entirely feasible on a single consumer GPU.
@TheAhmadOsman urged newcomers to read hardware guides before purchasing, reflecting a maturing community that's moved past the "just buy a 4090" phase into nuanced discussions about memory bandwidth, quantization tradeoffs, and model-hardware matching. @davis7 added a complementary insight from the API side, insisting developers should use models on low reasoning settings rather than medium or high, suggesting that many tasks are drastically over-served by default configurations. These threads point to a broader realization: optimization at the inference and configuration layer can deliver more practical value than waiting for the next model release.
Harness Engineering & Agent Orchestration
A new discipline is crystallizing around the idea that the scaffolding around AI models, what Red Hat is calling "harness engineering," deserves as much rigor as the models themselves. Today's discourse featured multiple angles on this thesis, from academic papers to production workflow architectures.
@JeremyCMorgan summarized Red Hat's position: "The environment an AI works in matters as much as the weights: integrating telemetry, repos, and testing constraints into a single deterministic orchestrator measurably moves code generation reliability by 5%+. You cannot prompt-engineer your way out of bad infrastructure." That last line could be the motto for this emerging field. @odysseus0z took it further with a provocative idea: "All the harness/skills etc should be compiled/generated by model hill climbing against eval/task itself... when new model comes out you just need to let the new model recompile/optimize it."
The most concrete implementation came from @mattpocockuk, who described a complete agent-driven development pipeline: Slack commands trigger triage, planning agents create dependency DAGs across branches, implementer agents work in parallel with Slack thread updates, and periodic review sweeps catch architectural drift. Built on Sandcastle and Vercel's Chat SDK, it represents the kind of integrated orchestration that the harness engineering papers are calling for. @dexhorthy endorsed Matt Pocock's accompanying talk on software fundamentals, noting it "captures so much between-the-lines stuff WRT crafting good software that I have struggled to articulate." The message across all these posts is consistent: the next competitive advantage isn't a better model, it's a better system around the model.
AI Market Dynamics & the Open Source Squeeze
Several posts today mapped out the strategic landscape for AI labs through the rest of 2026, with a consensus forming around a fundamental market split between enterprise closed-source and increasingly capable open-source alternatives.
@neural_avb laid out a four-part thesis: "Big labs are gonna push expensive bigger closed-source models directly to big tech... Open source labs are making comparable coding models now... anybody got a clear shot here to deliver a Sonnet or a GPT5.2 at 1/10th pricing... Local models are gonna go crazy because people will figure out speculative decoding + kv cache quantization." This framework, posted as a quote-tweet of Sam Altman promoting Codex enterprise rollouts with NVIDIA, highlights the tension between OpenAI's enterprise push and the open-source models nipping at their heels.
The business opportunity in this shift is already being captured. @AndrewWarner profiled a consultant hitting $4.5M ARR helping SMBs implement AI, while @Zephyr_hg teased that "the actual money is one layer deeper, in the skill nobody's filming courses about yet." The implication across these posts is that as models commoditize, value accrues to those who can deploy, integrate, and orchestrate them effectively, whether at the enterprise consulting level or in the tooling infrastructure layer.
Claude Desktop's Quiet Third-Party Inference Support
Perhaps the most consequential development today flew under the radar: Claude Desktop apparently now supports third-party inference providers, and Anthropic hasn't said a word about it.
@PawelHuryn flagged the silence: "20+ hours later and @AnthropicAI + @claudeai + official accounts still haven't said a single word about this. This is huge. Full third-party inference support for Cowork & Code in Claude Desktop: OpenRouter, Local models via LiteLLM, Any compatible gateway. Is this a bug? Was it released prematurely?" If intentional, this represents a major strategic shift, decoupling Claude's IDE experience from Anthropic's own inference, effectively turning Claude Desktop into a model-agnostic development environment. If accidental, it reveals architectural decisions that suggest this direction was always on the roadmap. Either way, it validates the broader trend of the day: the value is moving from models to the systems built around them.
Sources


This is wild. You can now use Claude Cowork with any LLM - GPT, Grok, Gemma, MinMax. Point it directly at: https://t.co/ikBnGt4MAI https://t.co/82mXeiaOJB
Factory is now an official provider on the @vercel Skills Marketplace. We have added a fresh revamp of our skills pack, including the legendary "no useEffect" skill. Also find dozens of other skills covering frontend design, security reviews, full-stack playbooks, and more. And we're not stopping. Expect a steady stream of new skills landing soon. Try us with one command: npx skills add factory-ai/factory-plugins
Go forth and let it rip fam. And take some time to see how the new model does with your skills and local set up! I usually take a week or so to tweak and get a feel for this. The model is still my lil guy but it is a different lil guy. Every time.

We tried a new thing with NVIDIA to roll out Codex across a whole company and it was awesome to see it work. Let us know if you'd like to do it at your company! https://t.co/Xjn6ShrRuq
@davis7 low? not even medium?
A talk I gave a few weeks ago. Software fundamentals matter more than ever. Here's why: https://t.co/KG7gdqFo2j

The AI Skill Paying $400/Hour in Q2 2026 (That Almost Nobody Is Teaching)

Our goal is to build practical models with comprehensive capabilities beyond open benchmarks. And the only way to do it to co-design with diverse products while scaling solidly. Tencent has the best product ecosystem and a solid, low-ego culture, and we are just getting started!