Recursive Language Models Challenge RAG Dominance as Agent Security and Local Inference Push New Boundaries
Today's feed centered on the emerging Recursive Language Model architecture that promises to replace both RAG and massive context windows, alongside a surge of agent infrastructure tooling led by Infisical's Agent Vault for credential security. Local LLM inference optimization hit remarkable speeds on consumer GPUs, while the broader conversation around "harness engineering" and agent skill composition signaled a maturing discipline.
Daily Wrap-Up
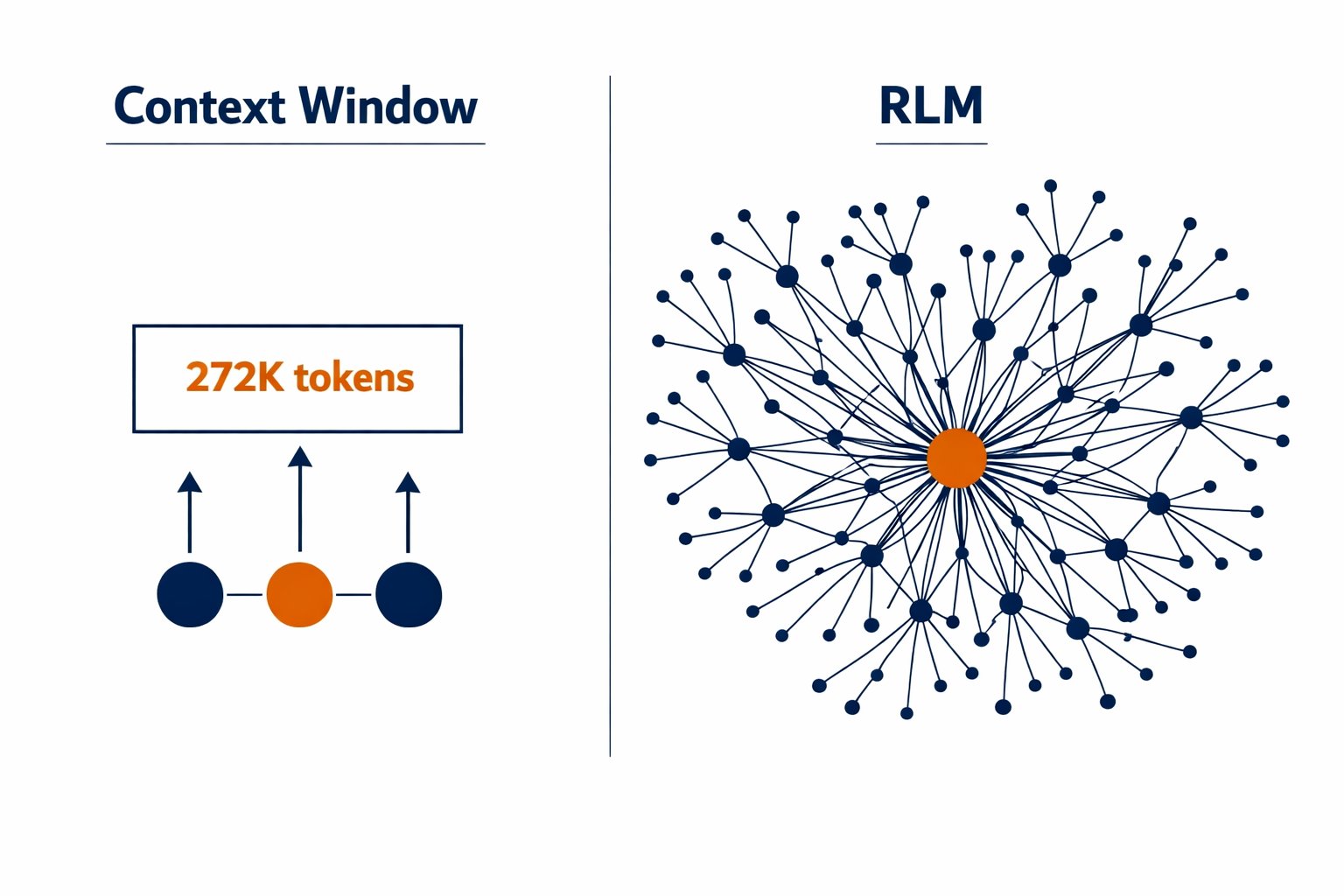
The biggest intellectual spark today came from MIT's Recursive Language Models research, which proposes something genuinely novel: instead of cramming documents into ever-larger context windows or chunking them through RAG pipelines, let the model write code to actively search and filter documents stored as Python variables. The architecture spawns sub-agents to read specific snippets in parallel, preserving original context without summarization. Whether this lives up to the hype remains to be seen, but the framing shift from "bigger windows" to "teach models how to read" feels like it could reshape how we think about long-context work. Multiple voices on the timeline were buzzing about it, including independent experiments with Lambda-RLMs showing promising results.
Meanwhile, the agent infrastructure layer is thickening fast. Infisical shipped Agent Vault, a credential proxy that never hands secrets to the agent at all, instead brokering access at the proxy layer. Google launched Cloud Run sandboxes for executing agent-generated code safely. Obscura emerged as a Rust-based headless browser replacement for Chrome, optimized for AI agent workloads. And Anthropic quietly enabled third-party model inference in Claude Desktop. Each of these solves a different piece of the "agents in production" puzzle, and together they paint a picture of an ecosystem rapidly graduating from demos to deployable systems. The local inference crowd also had a strong day, with hand-tuned GPU kernels pushing Qwen 3.5-27B to 134 tokens per second on a single RTX 3090, a number that would have seemed absurd twelve months ago.
The most entertaining moment was watching @DataChaz describe Google open-sourcing DESIGN.md as a calculated act of "disrespect" toward Anthropic's Claude Design rate limits, which captures the increasingly competitive and petty energy between the big labs perfectly. The most practical takeaway for developers: if you're building agent systems that touch production APIs or databases, look into proxy-based credential management like Agent Vault now, because the "just pass the API key to the agent" pattern is a ticking security incident waiting to happen.
Quick Hits
- @CoffeeStocksGuy highlighted that the DoD confirmed $85 billion in drone funding, vindicating his earlier mapping of the entire drone economy. Defense tech investment continues to accelerate.
- @jessegenet used @openclaw agents to generate free markdown versions of vintage homeschool curricula including McGuffey Readers and Ray's Primary Arithmetic, a charming example of AI-assisted educational content creation.
- @jhanikhil distilled all of systems design into six tricks: divide and conquer, caching, indirection, batching, redundancy, and lazy eval. Simple but not wrong.
- @AntonioSitongLi announced NORI L1, billed as the best robot under $1,000, with pre-orders open and shipping summer 2026.
- @archiexzzz pitched Higgsfield Marketing Studio as a solution for indie founders who can build products but can't crack distribution, using AI-generated video ads at scale.
- @danshipper retweeted enthusiasm for "Compound Engineering" as an underappreciated development practice.
- @0xSero reflected on AI infrastructure spanning dozens of countries, arguing that regardless of any AI bubble, the compute and infrastructure will persist.
Agent Infrastructure Matures
The conversation around agent security and infrastructure dominated today's feed, and for good reason. As agents move from toy demos into systems that touch real databases and production APIs, the question of how to give them access without giving them the keys has become urgent. Infisical's answer is Agent Vault, an open-source HTTP credential proxy that fundamentally changes the trust model. As @dangtony98 put it: "A dream come true for every human anxious about their agents leaking secrets. Agent Vault aspires to be the portable solution that you can bring anywhere: open-prem, cloud, any container environment. Front your agent with Agent Vault and let it rip." The architecture is elegant: instead of retrieving secrets and trusting the agent to behave, Agent Vault forces all requests through a proxy layer where credentials are brokered but never exposed. The agent literally cannot exfiltrate what it never touches.
This dovetails with Google's new Cloud Run sandboxes, which @simonw flagged. @steren's announcement described them as "secure on-the-fly code execution: spin up ephemeral, isolated sandboxes from within Cloud Run resources. Safely execute agent-generated code, scripts, or Chromium." Between credential proxying and sandboxed execution, the production agent stack is starting to look like a real security architecture rather than a collection of hopes and prayers.
On the browser automation front, @ErickSky highlighted Obscura, a Rust-based headless browser built specifically for AI agents and crawlers. The numbers are striking: 30 MB of RAM versus Chrome's multiple gigabytes, 85ms startup time, and built-in stealth features for fingerprint randomization. It supports CDP, meaning Puppeteer and Playwright work without code changes. For anyone running agents that need web access at scale, this is a meaningful infrastructure upgrade over headless Chrome.
Recursive Language Models and the Post-RAG Era
The most intellectually significant development today was the continued momentum around Recursive Language Models. @HowToAI_ provided the most detailed breakdown: "Instead of forcing the AI to read a giant prompt in one pass, RLMs treat long documents as an external environment. The AI is placed in a sandbox. The data is stored as a Python variable. When you ask it a question, the AI doesn't just blindly try to remember the answer. It writes code to actively search, slice, and filter the document itself." The results are dramatic, handling inputs up to two orders of magnitude beyond normal context windows while scoring 58.00 on benchmarks where standard models manage 0.04.
What makes this more than just another paper is the independent validation happening in real time. @hbouammar praised a blog post running experiments with Lambda-RLMs, a variant of the architecture, calling the results "simply amazing" and linking to both the code and the ICLR 2026 paper. The fact that researchers outside the original team are already reproducing and extending the work suggests this isn't just a clever trick but a potentially durable paradigm shift. The core insight that models should learn to programmatically navigate documents rather than passively consuming them feels obvious in retrospect, which is usually a sign of a good idea.
Local Inference Hits New Speed Records
The local AI community had a banner day, with multiple threads converging on the theme that consumer hardware is being dramatically underserved by the major frameworks. @sudoingX captured the energy best, describing how @pupposandro's custom kernel work achieved 134 tokens per second on Qwen 3.5-27B running on a single RTX 3090: "major labs are stuck shipping framework abstractions optimized for h100 fleets. @pupposandro is hand tuning kernels for the silicon actual builders own." The same stack already runs the newer Qwen 3.6-27B at 73 tok/s, with the regression attributed to needing a dedicated draft model pass.
Meanwhile, @coffeecup2020 reported that "Qwen3.6-27B-TQ3_4S is insanely good" and fits on 16GB with 32k context. @gkisokay continued his popular Local LLM Cheat Sheet series, adding "24GB Ready" tags and previewing a 64GB edition. The practical upshot is clear: the gap between cloud and local inference quality is narrowing while the speed gap is closing even faster, at least for those willing to get their hands dirty with kernel-level optimization. The 3090 is emerging as the most underrated research platform in consumer AI, offering 24GB of VRAM with mature CUDA support and almost zero attention from big shop optimization teams.
Harness Engineering and Agent Skill Composition
A meta-conversation about how to build and organize agent systems emerged across several posts. @Trae_ai shared "The Definitive Guide to Harness Engineering," framing 2026 as the year this discipline crystallizes. @odysseus0z connected the dots bluntly: "RL env = harness engineering = agentic coding = autoresearch. All are about eval/task design." This framing collapses several seemingly distinct practices into one core competency, the ability to design environments and evaluation criteria that let agents improve themselves.
On the practical side, @garrytan weighed in on skill composition patterns, noting that he prefers "composing bigger skills with branching params" over decomposing into smaller discrete skills, responding to @shivsakhuja's "Skill Graphs 2.0" concept. This tension between monolithic and modular skill design is going to be one of the defining architectural debates of agentic systems. @garrytan also flagged both Agent Vault and CrabTrap from @pedroh96 as projects keeping him busy, suggesting the YC ecosystem is paying close attention to agent infrastructure tooling.
Claude and the Multi-Model Future
Anthropic made a quiet but significant move that @PawelHuryn caught: Claude Desktop now supports third-party model inference for Cowork and Code. "This is wild. You can now use Claude Cowork with any LLM - GPT, Grok, Gemma, MinMax," he wrote, pointing users directly at the configuration endpoint. This is a strategic pivot, positioning Claude's tooling layer as model-agnostic infrastructure rather than a walled garden.
The Anthropic blog team also published guidance on the MCP versus CLI question for agent integration, which @katelyn_lesse noted "literally everyone is asking." The post covers when agents should use direct APIs versus CLIs versus MCP, plus patterns for building MCP servers and context-efficient clients. Combined with Google's open-sourcing of the DESIGN.md spec for cross-tool design system portability, the trend is clearly toward interoperability. The platforms that win will be the ones developers want to build on, not the ones they're locked into.
The AI-First Engineering Team
@heynavtoor posted a provocative thread listing 10 open-source repos that could theoretically replace a 10-person engineering team, from OpenHands for autonomous PR generation to Coolify for DevOps and PostHog for analytics. The framing is deliberately extreme, but the underlying observation is real: "A 10-person engineering team in 2022 could ship what one founder ships now with these 10 repos. That is not a prediction. It is what is already happening at every AI-first startup in 2026." Whether or not you buy the full thesis, the stack he describes (OpenHands, Aider, Cline, Claude Task Master, CrewAI, LangGraph, n8n, Coolify, PostHog, Chatwoot) represents a genuinely functional toolkit for small teams looking to punch above their weight. The key gap remains distribution, not building, which is exactly the problem @archiexzzz was trying to solve with AI-generated marketing content.
Sources
N
If I had to replace my entire engineering team with AI in 2026, I would not hire a single developer.
I would set up these 10 GitHub repos.
1. OpenHands
Replaces your junior developers. An autonomous software engineer that reads GitHub issues, writes the fix, runs the tests, and opens the PR. 65K+ stars.
repo → https://t.co/kqap76TDuB
2. Aider
Replaces your mid-level dev. A terminal pair programmer that edits multi-file codebases, auto-commits to git, and works with any LLM.
repo → https://t.co/FB24VY6vf0
3. Cline
Replaces your VS Code teammate. An autonomous agent that lives in your editor, navigates files, runs commands, and ships features end-to-end.
repo → https://t.co/hjjDVgiRd3
4. Claude Task Master
Replaces your project manager. Turns a product spec into a tracked task list and keeps the agent on rails across long builds.
repo → https://t.co/0xYzJpSX4z
5. CrewAI
Replaces your tech lead. Coordinates multiple AI agents with defined roles, responsibilities, and handoffs. Already used across the Fortune 500.
repo → https://t.co/0xohE065sD
6. LangGraph
Replaces your architect. The orchestration layer every production AI system is being built on in 2026. Stateful, durable, observable.
repo → https://t.co/bzVBn9uecV
7. n8n
Replaces your ops hire. 400+ integrations, native AI nodes, self-hosted. Every internal tool and workflow your team used to build from scratch.
repo → https://t.co/hdycABGGc1
8. Coolify
Replaces your DevOps engineer. Self-hosted Heroku and Vercel. Git push to deploy, auto SSL, databases, 280+ one-click services.
repo → https://t.co/N5Fk22qraT
9. PostHog
Replaces your QA and data team. Product analytics, session replay, feature flags, A/B tests, error tracking. All in one repo.
repo → https://t.co/ULaoYj7oKE
10. Chatwoot
Replaces your support hire. Live chat, email, WhatsApp, all from one inbox. Self-hosted and AI-assisted out of the box.
repo → https://t.co/AC5NpocnFg
A 10-person engineering team in 2022 could ship what one founder ships now with these 10 repos.
That is not a prediction. It is what is already happening at every AI-first startup in 2026.
Pick one. Replace one role. Ship one feature. That is how you start.
100% free. 100% open source.


C
this guy exposed the entire drone economy over a month ago.
just now the DoD confirmed $85 billion in funding just for drones.
he predicted this.
and he gave you the entire map for free.
every. single. company.
read this to get ahead before someone else does. https://t.co/4VLV2NaK85

C
CoffeeStocksGuy
@CoffeeStocksGuy
https://t.co/1oOpSkqYUf
A
Introducing NORI L1.
The best robot under $1,000.
Pre-order today. Ships summer 2026. https://t.co/wFHMYSi3tx

G
OAI cooked here. 1B model to redact all PII at client side.
S
scaling01
@scaling01
OpenAI just released a new open-source model it's "a bidirectional token-classification model for personally identifiable information (PII) detection and masking in text" https://t.co/xTZt1J3WcT https://t.co/PwaJ0rL2Cz https://t.co/uprsVhXE7b
A
> most of my friends who left their jobs to build a startup and a product face the (obvious) problem of distribution. they have spent months building the product - apps that function perfectly, have clean ui, and have real utility. but -> no users.
> every single one died at the same point: the founder posted a launch tweet, got 12 likes, didn't know what to do next, and moved on to the next build.
> the distribution was missing entirely.
Higgsfield Marketing Studio turns a product URL into finished, platform-ready ad creative without any work from you.
> Hermes Agent handles research, strategy, scripting
> Seedance 2.0 handles video generation
> all natively inside Higgsfield Marketing Studio
> 500+ videos/day. CPMs as low as $0.10. 9 ad formats from one paste.
No need for:
> marketing and product brief
> wasting hrs in shooting
> freelancers who charge you $1000s
everything runs inside Higgsfield Marketing Studio.
you can't replicate ten years of audience building. but you can replicate the ad pipeline that audience would have let you skip.
H
higgsfield
@higgsfield
Meet Higgsfield Marketing Studio, powered by Hermes Agent. UGC era for your vibe-coded products is here. You can now create viral UGC ads for your website or app in a few clicks and distribute them at unmatched speed. It's time to go global. https://t.co/89bXPWUJT4
S
New sandbox!
S
steren
@steren
Announcing Cloud Run sandboxes: Secure on-the-fly code execution: Spin up ephemeral, isolated sandboxes from within Cloud Run resources. Safely execute agent-generated code, scripts, or Chromium. https://t.co/S4vfLs2JQL
T
A dream come true for every human anxious about their agents leaking secrets.
Agent Vault aspires to be the portable solution that you can bring anywhere: open-prem, cloud, any container environment.
Front your agent with Agent Vault and let it rip.
https://t.co/pZEzh2WjlI
I
infisical
@infisical
Any secret an agent can read is a secret an attacker can steal. So we built the fix: Agent Vault, an HTTP credential proxy and vault for AI agents. Secret managers were built for deterministic services. They return credentials to the caller and trust them to behave. AI agents break that assumption. They are non-deterministic, prompt-injectable, and increasingly sitting in front of your prod APIs and databases. Instead of returning credentials directly to the agent, Agent Vault forces the agent to proxy requests through it, brokering credentials at the proxy layer and forwarding requests to any target API all in an interface-agnostic way. Credentials stay in the vault, encrypted with AES-256-GCM. The agent never touches them. What you get: → Brokered access through HTTPS_PROXY, not retrieval. Nothing to exfiltrate. → Firewall-like access rules implemented at the proxy. → Multi-vault RBAC to scope agents to a tight blast radius. → Full audit trail and inspection of every passing call. → All compacted in a single Go binary executable; available as a Docker container. Read out announcement post for a further breakdown: https://t.co/8UP3BoCbin Try it → https://t.co/i8DDJ1dtou
J
Releasing free .md files my @openclaw agents made for our homeschool of some vintage classic curriculums 📚
- McGuffey Readers (vol 1-6)
- Ray’s Primary Arithmetic
- The Webster Speller
You can get the downloads free here: https://t.co/siMQ351viq 🎉 https://t.co/ldsGpYeEJO

G
I told you guys.
RL env = harness engineering = agentic coding = autoresearch.
all are about eval/task design.
_
_lopopolo
@_lopopolo
A neat thing we’ve been experimenting with: Codex workout sessions. Getting Codex to close the loop and validate its work is critical for higher complexity changes. To do that we want skills for high level workflows: “log in”, “upload file attachments and start a chat”, “grant this group access to a Workplace Agent”. To do this reliably, we’ve been getting Codex to iterate on its own skills by planting “flags” CTF-style in the UI and ralphing Codex using automations in the app, making commits to iteratively refine the skills after self reflection on each attempt. Capturing the flag is the win condition and from there codex optimized for reliability, wall clock time, and keeping up to the changing codebase. Put in the reps with your agents!
D
RT @mvanhorn: I still feel like Compound Engineering is the most under hyped / biggest secret /hack in my toolkit and I never shut up about…
D
Qwen3.6-27B-TQ3_4S is insanely good!
https://t.co/iPV1q1tGKq fit on my 16GB with 32k context
Two prompts and I get this! https://t.co/InarCrXeU5
0
Such an important read.
The models are a rather simple layer running on a much more complex system spanning dozens of countries and literally every continent.
The AI bubble can burst any minute now, but the computer, the models, and the infra remains.
Supply < Demand
A
ai_hyperbull
@ai_hyperbull
The AI Cake Trade
K
literally everyone is asking the mcp vs cli question. the team answered it in this new post - check it out and let us know what you think!
C
ClaudeDevs
@ClaudeDevs
New blog: Building agents that reach production systems with MCP. When should agents use direct APIs vs CLIs vs MCP? Plus patterns for building MCP servers, context-efficient clients and pairing MCP with skills. https://t.co/Q4UrUVgVYB
G
For everyone asking about 24GB, I added "24GB Ready" tags directly onto the cheat sheets for you.
And if you’re anywhere in the 24GB to 48GB range, these are still very relevant.
At 24GB, you can start reaching into the 24B class or push longer context on a lot of the models from the 16GB sheet.
At 36GB to 48GB, you can run many of the top picks from the 32GB sheet with more room for context and headroom.
Just keep in mind these are practical anchor points, and each local LLM depends on your own device's specs.
64GB cheat sheet coming later today.
Appreciate all the support!
G
gkisokay
@gkisokay
The Local LLM Cheat Sheet for your 32GB RAM device I was asked to put together a practical lineup of local models that fit comfortably on a 32GB machine. At this tier, you start getting access to real flagship-class local models, plus a growing number of custom quants. But for most people, these are the core models worth knowing first. Flagship Models Qwen3.5 27B / GGUF / Q6_K_M The best overall 32GB flagship. General chat, writing, research, and agent workflows. Great if you want one model that can handle almost everything well. Qwen3.6-35B-A3B / GGUF / UD-Q4_K_M Best MoE flagship. Stronger for coding, reasoning, and tool use than most smaller generalists. Gemma 4 31B / GGUF / Q6_K_M Dense premium model. Writing, analysis, reasoning, and high-end local chat. Heavier than the MoE options, but excellent when quality matters more than speed. Models for Fast Flagship Use Gemma 4 26B A4B / GGUF / Q6_K_M Great balance of speed and quality for general assistant work, coding, agent tasks, and research. This is one of the best 32GB picks if you want something that feels high-end without dragging. DeepSeek-R1 Distill Qwen 32B / GGUF / Q4_K_M Offline reasoning engine. Best for math, logic, deliberate analysis, and step-by-step problem solving. Mistral Small 24B / GGUF / Q6_K_M Tool-calling specialist. Strong for assistants, chat workflows, local business tasks, and function calling. Available for 24GB machines. Models for Companion Use Qwen3.5 9B / GGUF / Q6_K_M Best sidekick. Fast drafts, search loops, cheap retries, and secondary agent work. Even on a 32GB machine, you still want a smaller model around for support tasks. Llama 3.1 8B / GGUF / Q6_K_M Long-context companion. RAG, doc ingestion, codebase chat, and long prompts. The output quality is not the sharpest anymore, but it is still useful when needing simple tasks fast. From what my community tells me, the best single models are Qwen3.5 27B or Gemma 4 31B. For two models, the strongest general pairing is Qwen3.5 27B + Qwen3.5 9B. If you are more code-heavy, Qwen3.6-35B-A3B + Llama 3.1 8B. Let me know what models you are running on 32GB, and which ones have actually been worth the RAM.
T
The Definitive Guide to Harness Engineering
The Definitive Guide to Harness Engineering
Harness Engineering is simply a more evocative, intuitive way to systematically summarize and name these existing AI practices. 1. What is Harness E...
G
Man between this and CrabTrap from @pedroh96 I am going to have a busy week
D
dangtony98
@dangtony98
Agent Vault: The Open Source Credential Proxy and Vault for Agents
E
[me pueden banear por este repo]
pero al dev de Hermes le gustó este repo, más na' te digo...
_____________________________________________
Headless Chrome está OFICIALMENTE JUBILADO.
Un dev PRO en Rust acaba de lanzó Obscura.
El navegador headless que destroza todo para AI Agents y crawlers.
Esto es lo que lo hace una bestia:
- 30 MB de RAM (Chrome se come varios GB)
- Se inicia en 85 ms
- Todo el binario pesa solo 70 MB
- Modo STEALTH brutal: randomiza fingerprints y bloquea trackers
- Soporta CDP → Puppeteer y Playwright funcionan sin tocar una sola línea de código
Si haces scraping SERIO o corres agentes de IA en escala… este repo es oro puro.
REPOOO👇

N
there are only like 5-6 tricks in systems
- divide and conquer
- caching
- indirection
- batching
- redundancy
- lazy eval
and then you apply arbitrarily complicated variations of these in clever ways to build whatever you want
D
Duderichy
@Duderichy
walking into a system design interview like “cdn, sharding, consistent hashing” where’s my job
G
This is interesting. Anyone experimenting with this? So far anytime I have adjacent skills I just tell it to DRY itself up and turn it into a bigger skill with more parameters
So far I found composing bigger skills with branching params is better
S
shivsakhuja
@shivsakhuja
A new way to think about composing skills to increase leverage: Skill Graphs 2.0
H
MIT has done the unthinkable.
They built an AI that doesn't need RAG, and it has perfect memory of everything it's ever read.
It's called Recursive Language Models (RLMs).
Right now, if you want an AI to analyze a massive dataset or document, you have two bad options.
You either stuff it all into a giant context window, where the AI gets confused and suffers from "context rot."
Or you use RAG to chop it up into summaries, permanently deleting the nuance.
This paper replaces both.
Instead of forcing the AI to read a giant prompt in one pass, RLMs treat long documents as an external environment.
The AI is placed in a sandbox. The data is stored as a Python variable.
When you ask it a question, the AI doesn't just blindly try to remember the answer.
It writes code to actively search, slice, and filter the document itself.
Then, it recursively spawns smaller "sub-AIs" to read specific snippets in parallel.
It never summarizes. It never deletes data.
It preserves every single piece of original context.
The results rewrite the limits of AI memory.
It successfully handles inputs up to two orders of magnitude beyond normal context windows, scaling easily to 10 million+ tokens.
On the hardest long-context reasoning benchmarks, a standard model scored a dismal 0.04. The RLM architecture hit 58.00.
All while costing less than running a standard massive prompt.
We’ve spent the last two years burning millions in compute trying to build bigger and bigger context windows.
But the future of AI isn’t about forcing a model to swallow a giant wall of text.
It’s about teaching it how to read.
P
This is wild. You can now use Claude Cowork with any LLM - GPT, Grok, Gemma, MinMax.
Point it directly at: https://t.co/ikBnGt4MAI https://t.co/82mXeiaOJB
P
PawelHuryn
@PawelHuryn
Anthropic has quietly shipped third-party inference for Cowork and Code in Claude Desktop. This should work with local models or OpenRouter via LiteLLM proxy. Is it just me? https://t.co/olWnP6YoqV
M
RT @nicopreme: Great post. This type of multi-agent coordination is possible with pi-subagents + pi-intercom 😎
https://t.co/1bYSkUGP88
ht…
S
this guy just cracked 134 tok/s on qwen 3.5-27b dense and 73 on new qwen 3.6-27b on a single 3090. open source moves at godspeed in 2026.
weights ship in the evening, dynamic ggufs land by midnight, fused kernel + speculative decoding stack runs the new model 12 hours after release.
his dflash + ddtree stack loads qwen 3.6 asis because the architecture string matches 3.5. zero retraining of the draft model, zero waiting for upstream support. the same hand tuned consumer hardware kernel work that pushed 3.5 to 134 tok/s already eats 3.6 at 73, with a regression he is openly flagging because the draft model needs a dedicated pass for 3.6.
this is the lane almost nobody is working on. major labs are stuck shipping framework abstractions optimized for h100 fleets. @pupposandro is hand tuning kernels for the silicon actual builders own. 3090 has 24 gigs of vram, mature cuda support, and almost zero kernel level optimization coming out of the big shops. it is the most underrated research platform in consumer ai right now.
i am running honest baseline q4_k_m on llama.cpp now to set the dense floor without tricks. then sandro's stack runs on the same gpu, same model, same prompt. generic inference vs hand tuned kernels with speculative decoding. that delta is where the next 5 years of consumer ai live.
receipts incoming.

P
pupposandro
@pupposandro
The new Qwen3.6-27B now runs on Luce DFlash. Up to 2x throughput on a single RTX 3090. Qwen3.6-27B ships the same Qwen35 architecture string and identical layer/head dims as 3.5, so the existing DFlash draft + DDTree stack loads it as-is. Throughput is lower than on 3.5. Looking forward for the updated version from the DFlash team to implement it as well! Repo in the first comment ⬇️
H
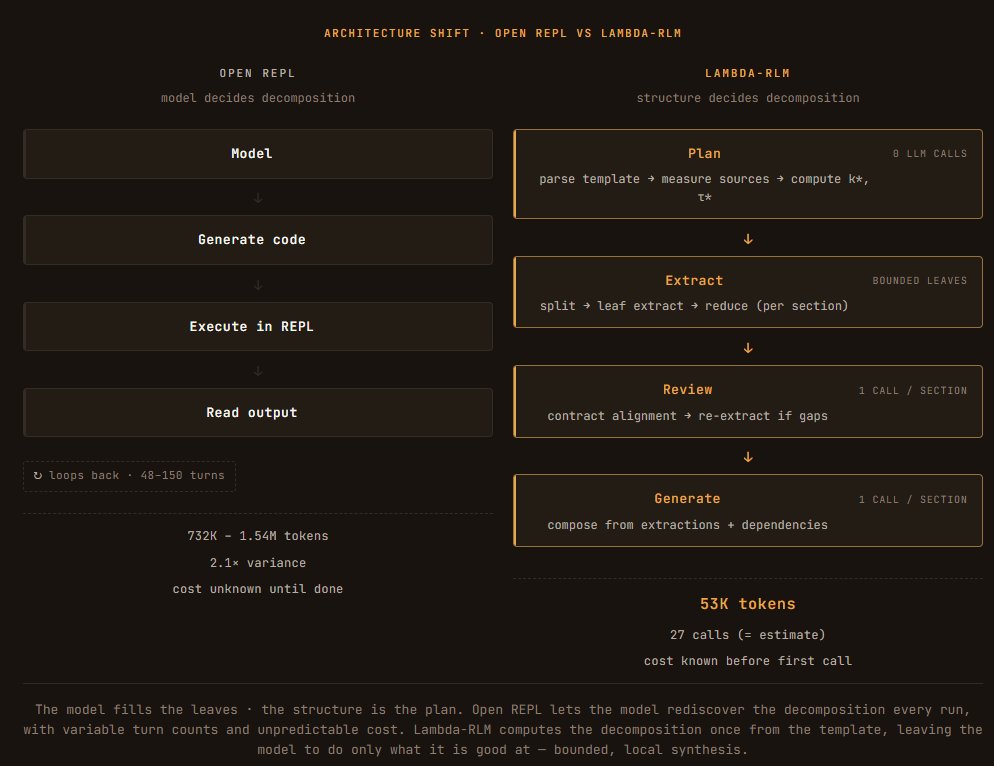
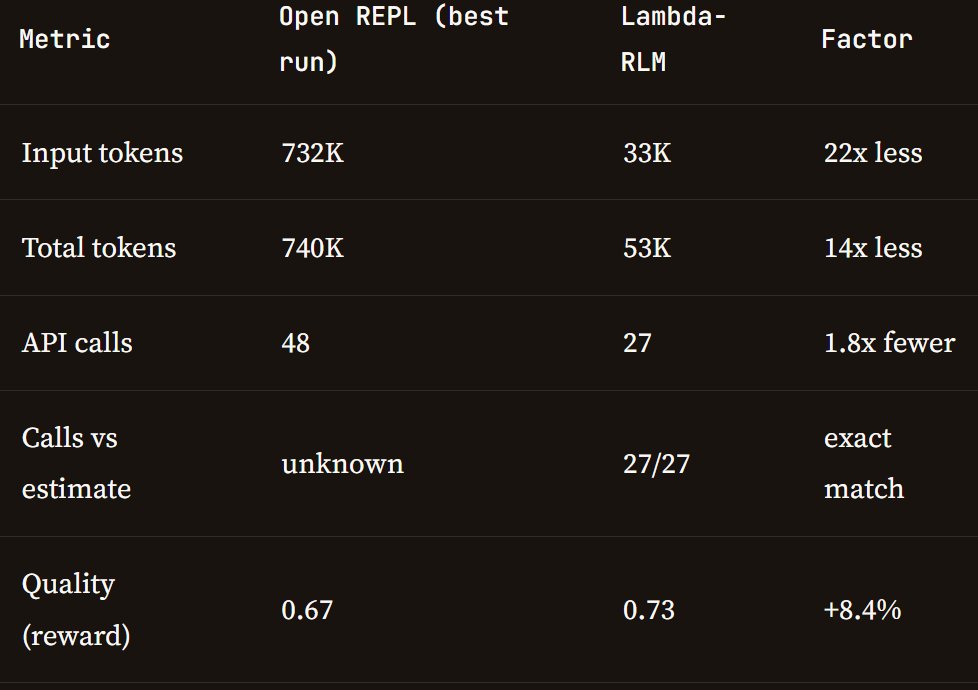
I just finished reading the Harness blog of @TheodoreGalanos on Lambda-RLMs, and it is simply amazing and worth everyone's read!
1⃣ Walks us through RLMs from the amazing @lateinteraction's team
2⃣ Walks us through Lambda-RLMs from mine
3⃣ Independently runs fantastic experiments and reports clear results!
I am happy Lambda-RLMs did well!!
Blog: https://t.co/lieB2wQKYT
Code for Lambda-RLMs: https://t.co/y8BL0nrxv5
Paper for Lambda-RLMs: https://t.co/h1ha6HYBOx
Simply amazing! 😍
#AI #MachineLearning #RLMs #ICLR2026
C
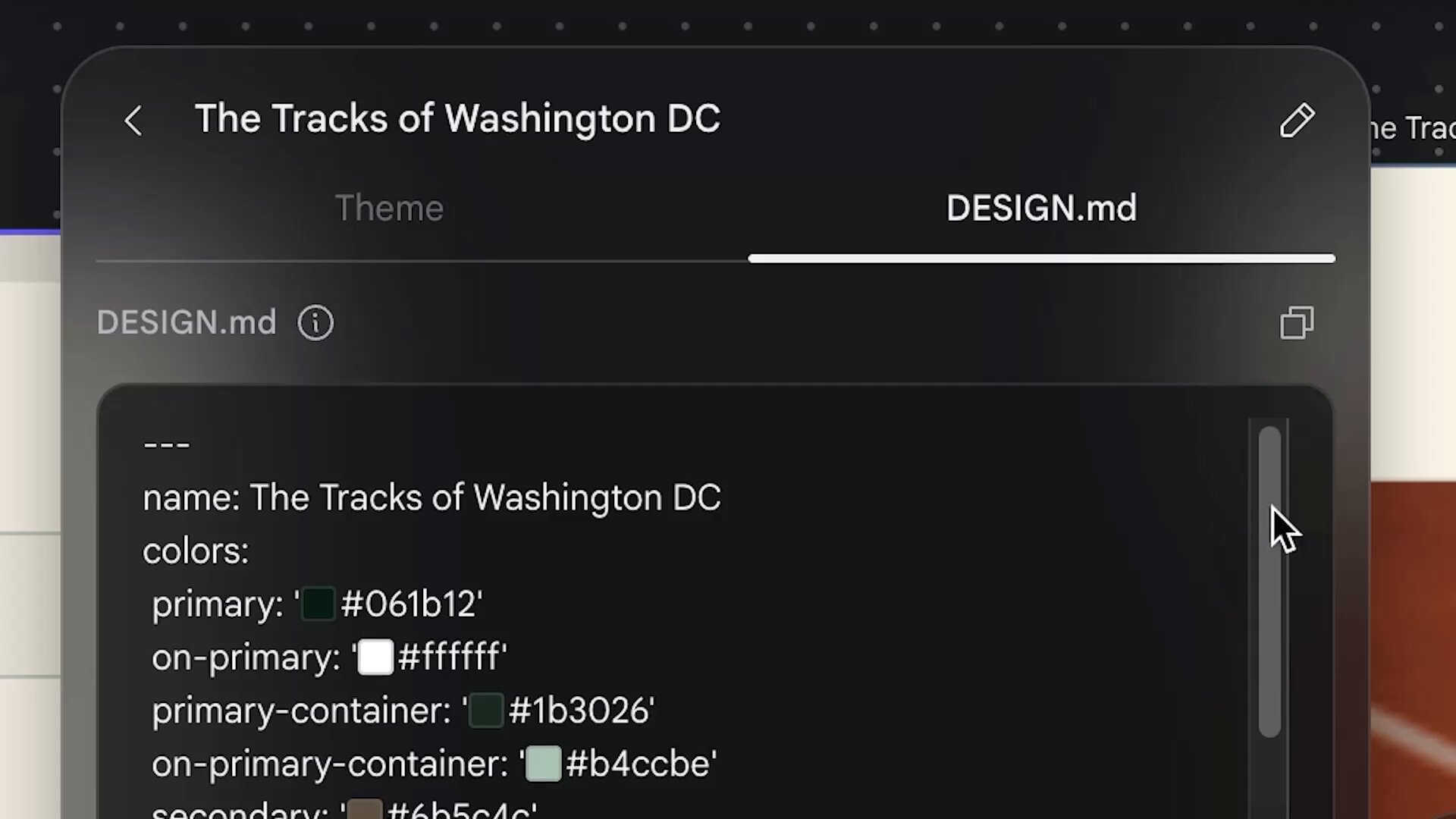
Google’s level of disrespect is OFF THE CHARTS right now.
Anthropic really thought they had us locked down with Claude Design’s ridiculous rate limits…
…and now Google has literally countered it straight away by open-sourcing DESIGN.md 🤯
https://t.co/9Hq4nLX2GK
S
stitchbygoogle
@stitchbygoogle
Today, we’re open-sourcing the draft specification for DESIGN.md, so it can be used across any tool or platform. We’re also adding new capabilities. DESIGN.md lets you easily export and import your design rules from project to project. Instead of guessing intent, agents know exactly what a color is for and can even validate their choices against WCAG accessibility rules. Watch David East break down this shared visual language in action👇. New capabilities and links in 🧵