LeCun's 15M-Parameter World Model Resets Robotics Economics as Claude Ecosystem Expands
Yann LeCun's departure from Meta yields a remarkably efficient world model that plans 48x faster on a single GPU, while the Claude ecosystem sees major updates including Continuous Claude v4.7, prompt caching guides, and a 3x cost reduction technique. Enterprise AI consulting emerges as a recurring theme with practitioners pushing back against influencer hype.
Daily Wrap-Up
The biggest story flying around today isn't a new foundation model or another funding round. It's a 15-million-parameter world model from Yann LeCun's new AMI Labs that trains on a single GPU in a few hours and plans 48x faster than foundation-model alternatives. The LeWorldModel paper is the kind of result that makes you reconsider the entire cost structure of robotics AI, and it landed just months after LeCun left Meta because Zuckerberg wouldn't bet on JEPA over LLaMA. Sometimes the best thing that can happen to a research agenda is losing institutional support.
Meanwhile, the Claude ecosystem had a busy day. Anthropic's tooling universe keeps expanding: Continuous Claude hit v4.7 with optimizations for Opus 4.7, a practical guide surfaced showing how to cut Claude Code costs by 3x using context engineering principles, and ClaudeDevs pushed out resources on prompt caching. Theo's viral investigation into Claude "getting dumb" added a counterpoint to the optimism, reminding everyone that model quality isn't a monotonic curve. On the enterprise side, there's a growing chorus of voices separating AI consulting reality from podcast fantasy, with practitioners sharing hard-won lessons about what actually works when you walk into a mid-market business.
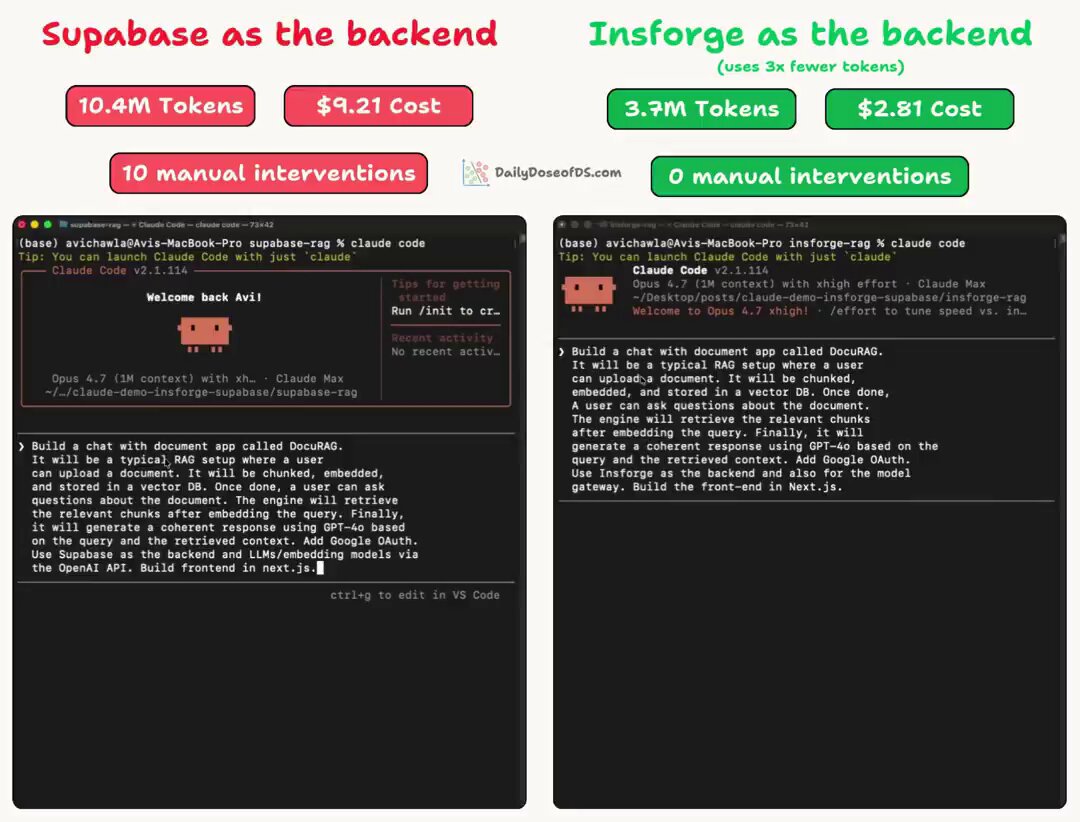
The most practical takeaway for developers: if you're spending too much on Claude Code, look into Karpathy's context engineering principles. One poster reported going from 10.4M tokens and $9.21 per session down to 3.7M tokens and $2.81, with zero errors instead of ten. That's not a marginal optimization; that's a fundamentally different cost structure for AI-assisted development.
Quick Hits
- @OpenAIDevs released Euphony, an open-source tool for visualizing chat data and Codex session logs. Paste a URL or upload a file, get a browsable view with filtering and translation support.
- @kloss_xyz contrasted Anthropic launching Claude Design (with rate limits) against Google open-sourcing DESIGN.md for cross-tool use: "AI creatives aren't stupid."
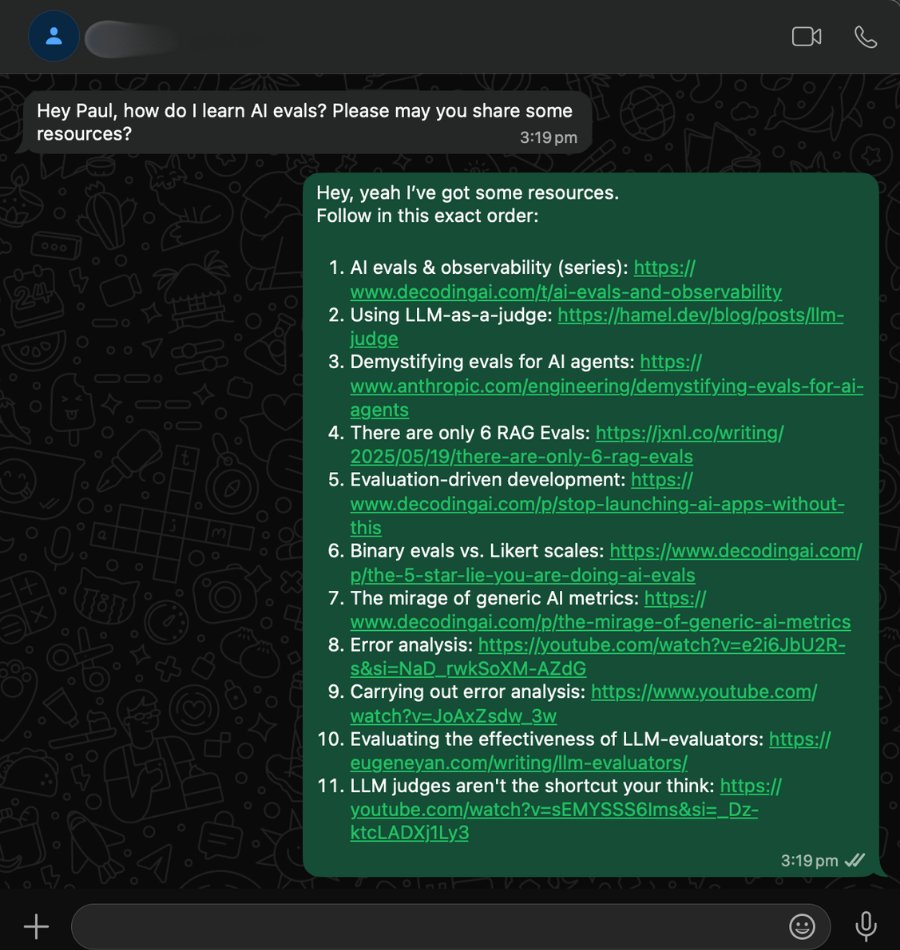
- @pauliusztin_ dropped a curated list of 11 resources for learning AI evals, covering everything from LLM-as-a-judge to RAG evaluation frameworks and error analysis.
- @BrianRoemmele teased findings from testing Anthropic's rumored "Mythos" model, promising to contact the company before sharing results publicly.
- @clear_graphics broke down the landing page structure used by five top YC-funded companies, a useful playbook for founders building their first marketing site.
- @0xSero reversed his stance on Tinygrad after learning their inference optimization tricks, reporting a 2x speed improvement on GLM: "Tinygrad worth it."
Claude Ecosystem: Cost Cuts, Caching, and Quality Concerns
The Claude tooling story today is really three stories braided together. First, there's the cost problem. AI-assisted coding is powerful but expensive, and the community is getting serious about optimization. @DailyDoseOfDS_ shared numbers that should get every Claude Code user's attention: "Claude Code used 3x fewer tokens with one change. Before: 10.4M tokens, 10 errors, $9.21. After: 3.7M tokens, 0 errors, $2.81." The technique draws on Karpathy's context engineering principles, which essentially means being more intentional about what context you feed the model rather than dumping everything in.
On the infrastructure side, @ClaudeDevs published two resources on prompt caching, sharing articles from @trq212 on maximizing cache hit rates and @RLanceMartin on how auto-caching works in the Claude API. Caching is one of those unsexy optimizations that compounds dramatically at scale. If you're making repeated API calls with overlapping context, you're leaving money on the table without it.
Then there's @parcadei announcing Continuous Claude v4.7 with Opus 4.7 optimizations, including RLMs (reinforcement learning models), 50% off edits, 95% off reads, fine-tuned models, and "evolving codebases." The pricing changes alone signal that Anthropic is aggressively trying to make sustained AI coding sessions economically viable, not just technically possible.
But @theo provided the necessary counterweight, posting a deep-dive video investigation into Claude's perceived quality degradation: "Claude got dumb. I dug really deep to figure out why. I feel like I became a conspiracy theorist while filming this." It's a reminder that the relationship between AI providers and their users has a trust dimension that no amount of cost optimization can fix. When your primary tool feels unreliable, cheaper tokens don't help much.
Enterprise AI: The Consulting Reality Check
A fascinating tension emerged today between the "AI guy for local businesses" fantasy and what practitioners actually experience in the field. @NorthstarBrain pushed back hard against a viral thread from @WOLF_Financial about making $500K/year selling AI to HVAC companies, offering three years of real experience instead:
"SMALL businesses will NOT pay you 2k to be their AI guy... you want to be aiming for 3-10M/year businesses... they do not care about AI... do NOT AUTOMATE SALES... they just need more leads and speed to lead. Gurus yapping on podcasts are delusional."
This dovetails with @vasuman's longer thread about enterprise AI deployment, where the message is that large companies desperately want AI but can't do it themselves. Their options are traditional consulting firms "which suck ass (respectfully)" or agentic SaaS that forces them to migrate off existing systems. Varick's approach, spending four weeks auditing before building anything, represents the less glamorous but more sustainable path. As @vasuman put it, quoting a customer: "this is 100x better than McKinsey."
@garrytan amplified the theme by sharing an article on stopping agents from making repeated mistakes, noting that even LangChain with $160M in funding and sophisticated testing tools hasn't fully solved this problem. The enterprise AI opportunity is real, but it requires the kind of patient, domain-specific work that doesn't fit neatly into a tweet thread or podcast pitch.
LeCun's LeWorldModel: Single-GPU Robotics Revolution
The most technically significant story of the day came from @cgtwts summarizing Yann LeCun's LeWorldModel paper out of AMI Labs. The narrative arc is compelling: LeCun spent years building JEPA at Meta, watched the company pivot to LLaMA, saw his robotics plans get dissolved, left to start AMI Labs, and promptly produced results that embarrass the foundation-model approach to robotics.
The numbers are striking. LeWorldModel uses 200x less data than comparable systems, plans 50x faster (0.98 seconds versus 47 seconds per cycle), and runs on a single GPU. The key innovation replaced an entire stack of training heuristics with one elegant regularizer: project latent embeddings onto random directions, test for normality, penalize deviation. As @cgtwts summarized, "removes all the complicated tricks and keeps it simple... learns how the real world works without being explicitly taught."
The broader context matters here. Figure AI is valued at $39 billion. Tesla is mass-producing Optimus. World Labs raised $230 million. All of them are burning capital on pipelines that take 47 seconds per planning cycle. LeCun just showed you can match or beat that performance with a model that trains in hours on consumer hardware. Whether or not LeWorldModel scales to production robotics, it fundamentally changes the conversation about what's necessary versus what's merely expensive.
Agent Memory and Reliability
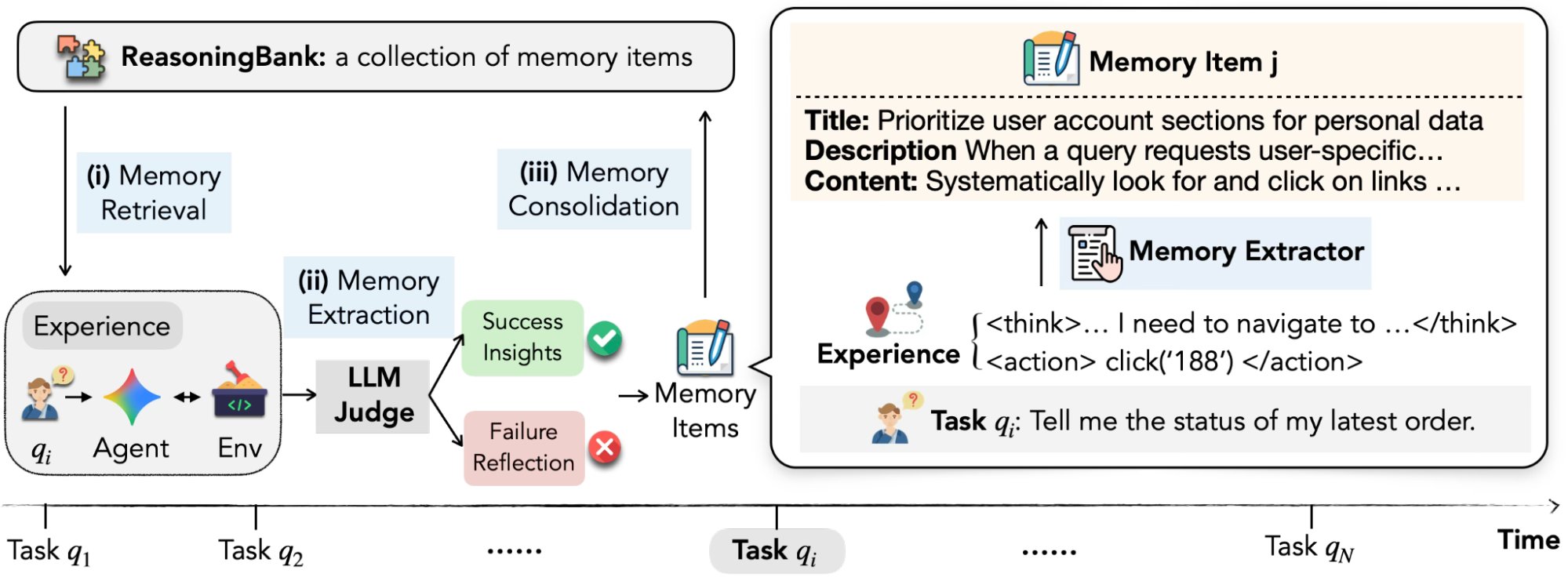
Google Research and the broader community are converging on a critical problem: how do you make AI agents that actually learn from experience? @GoogleResearch announced ReasoningBank, "a novel agent memory framework" that "enables LLM agents to continuously learn from both successful and failed experiences," boosting success rates and efficiency. The framing is significant because it treats agent memory as a first-class architectural concern rather than an afterthought.
@max_paperclips highlighted a related development, pointing to a variation on RLM (reinforcement learning models) where "a lot more of the work is handled by deterministic recursive decomposition rather than the learned policy of the LLM." This hybrid approach, letting structured algorithms handle what they're good at while reserving LLM flexibility for genuinely ambiguous decisions, feels like where the field is heading. Pure LLM agents are expensive and unreliable. Pure rule-based systems are brittle. The interesting work is happening in the space between them, and today's posts suggest that space is getting a lot of serious attention from both industry labs and independent researchers.
Sources
T
Claude got dumb. I dug really deep to figure out why. I feel like I became a conspiracy theorist while filming this... https://t.co/3rBurVM4TS
D
Claude Code used 3x fewer tokens with one change.
- Before: 10.4M tokens · 10 errors · $9.21
- After: 3.7M tokens · 0 errors · $2.81
(read the full setup guide below) https://t.co/FK7eTpVGrc
_
_avichawla
@_avichawla
How to cut Claude Code costs by 3x (using Karpathy's context engineering principles)
P
Every day, 100+ people ask me, "How can I learn AI evals?"
I copy-paste these 11 links (every time):
1. AI evals & observability (series): https://t.co/erSJcqpAV7
2. Using LLM-as-a-judge: https://t.co/xMBt9j4JRc
3. Demystifying evals for AI agents: https://t.co/HBbCe5PnXJ
4. There are only 6 RAG Evals: https://t.co/gwfyhIozqK
5. Evaluation-driven development: https://t.co/GMtp6bewol
6. Binary evals vs. Likert scales: https://t.co/WyMw1hHTfm
7. The mirage of generic AI metrics: https://t.co/ugryF5zfKO
8. Error analysis: https://t.co/OXgPZd8IXi
9. Carrying out error analysis: https://t.co/OXgPZd8IXi
10. Evaluating the effectiveness of LLM-evaluators: https://t.co/NuaXhr19TV
11. LLM judges aren't the shortcut you think: https://t.co/fDep2HFjCq
Binge these to skyrocket your skills.
B
Just had a long conversation with a tester of Anthropic Mythos. They ran 20 of my tests and I will have a bit to say soon. I will first, out of honor contact the company on what I found.
Folks just please listen to me about how you train an AI model. I ain’t guessing.
C
> be Yann LeCun
> spend years building JEPA at Meta
> company focuses on LLaMA instead
> his idea stays complicated and unused
> robotics plans get dropped
> decides to leave and start AMI Labs
> builds a much simpler version from scratch
> trains it on normal hardware in just a few hours
> removes all the complicated tricks and keeps it simple
Results:
-uses 200x less data than similar systems
-makes decisions 50x faster
-runs on a single GPU instead of massive clusters
-simple to train
-understands movement, objects, and space
-can tell when something is physically impossible
-learns how the real world works without being explicitly taught.

A
aakashgupta
@aakashgupta
Earlier this year Yann LeCun left Meta because Mark Zuckerberg wouldn't bet the company on JEPA. Last week his group dropped the first JEPA that actually trains end-to-end from raw pixels. 15 million parameters. Single GPU. A few hours. The timing is not a coincidence. For four years Meta has been the house that JEPA built. LeCun published the original paper from FAIR in 2022. I-JEPA and V-JEPA came out of his lab. The architecture was supposed to be the escape hatch from LLMs, the path to robots that actually learn physics instead of hallucinating about it. Every version shipped fragile. Stop-gradients. Exponential moving averages. Frozen pretrained encoders. Six or seven loss terms that had to be hand-tuned or the model collapsed into garbage representations. Meta kept funding LLMs. Llama shipped. Llama scaled. Llama got beat by Qwen and DeepSeek. Zuck spent $14 billion to buy ScaleAI and install Alexandr Wang. The FAIR robotics group was dissolved. LeCun's research kept winning papers and losing the product roadmap. He left, started AMI Labs, and said publicly that LLMs were a dead end. Now the paper. LeWorldModel. One regularizer replaces the entire pile of heuristics. Project the latent embeddings onto random directions, run a normality test, penalize deviation from Gaussian. The model cannot collapse because collapsed embeddings fail the test by construction. Hyperparameter search went from O(n^6) polynomial to O(log n) logarithmic. Six tunable knobs became one. The downstream numbers are what should scare the robotics capex class. 200 times fewer tokens per observation than DINO-WM. Planning time drops from 47 seconds to 0.98 seconds per cycle. 48x faster at matching or beating foundation-model performance on Push-T and 3D cube control. The latent space probes cleanly for agent position, block velocity, end-effector pose. It correctly flags physically impossible events as surprising. It learned physics without being told physics existed. Figure AI is valued at $39 billion. Tesla Optimus is mass-producing. World Labs raised $230 million to sell generative world models. Everyone in humanoid robotics is burning capital on foundation-model pipelines that plan in 47 seconds per cycle. LeCun's group just showed you can do it with 15 million parameters on a single GPU in a few hours. This is the Xerox PARC pattern running again. Meta had the next architecture. Meta had the scientist. Meta dissolved the robotics team, passed on the productization, and watched the exit. Three months later the lab that was supposed to be Meta's publishes the result that resets the robotics cost structure. The paper is worth more than Alexandr Wang.
O
Introducing Euphony, an open-source tool for visualizing chat data and Codex session logs.
Paste in a public URL or upload a local file, and Euphony turns the raw data into an easy-to-browse view. It supports translation, filtering, editing, and more. https://t.co/KTbMOLEWxD
G
ReasoningBank, a novel agent memory framework, enables LLM agents to continuously learn from both successful & failed experiences. Our evaluation shows that it enhances agent effectiveness, boosting success rates and efficiency. Learn more: https://t.co/lHlYzeKMcm https://t.co/DZa42JfqFX
C
pov: how you move after reading this article and finally figuring out how YC funded startups make so much fucking money... https://t.co/nb6jBgBZqX

C
clear_graphics
@clear_graphics
the landing page structure that 5 of the top YC funded companies use (full breakdown)
K
Anthropic: let’s launch Claude Design and rate limit usage when users can already do the same thing in Claude Code.
Google: let’s open source DESIGN .md so users can work across any tool.
notice the difference.
AI creatives aren’t stupid.
S
stitchbygoogle
@stitchbygoogle
Today, we’re open-sourcing the draft specification for DESIGN.md, so it can be used across any tool or platform. We’re also adding new capabilities. DESIGN.md lets you easily export and import your design rules from project to project. Instead of guessing intent, agents know exactly what a color is for and can even validate their choices against WCAG accessibility rules. Watch David East break down this shared visual language in action👇. New capabilities and links in 🧵
D
Introducing: Continuous Claude v4.7 (optimised for Opus 4.7)
strap in - we've got RLMs, 50% off Edits, 95% off Reads, fine-tuned models and even evolving codebases 👀
let's dive in to what's changed, what's new and what to do👇 https://t.co/FfQ5C3i4W1

C
What is prompt caching? Learn more in @RLanceMartin's article on prompt caching in the Claude API: https://t.co/GW9D0wEDnI
R
RLanceMartin
@RLanceMartin
Prompt auto-caching with Claude
C
Learn tips on how to maximize your prompt cache hit rate in @trq212's post: https://t.co/3n7z1rLwbk
T
trq212
@trq212
Lessons from Building Claude Code: Prompt Caching Is Everything
S
Very interesting variation on RLM here:
https://t.co/veLjC3YOYp
A lot more of the work is handled by deterministic recursive decomposition rather than the learned policy of the LLM, so I'm interested in playing around with it, comparing it to regular RLM
A
I’ve been doing this for almost 3 years, made 6 figures, what you should know:
- SMALL businesses will NOT pay you 2k to be their AI guy
- you CAN extract 2-3k value with a bunch of automations
- you want to be aiming for 3-10M/year businesses
- you need clarity with business owner and clear ROI
- they do not care about AI
- some of their employees will be resistant to the change
- do NOT AUTOMATE SALES
- they just need more leads and speed to lead
Ask me more questions. Gurus yapping on podcasts are delusional.
W
WOLF_Financial
@WOLF_Financial
CHRIS CAMILLO JUST LAID OUT HOW TO MAKE $500,000 A YEAR AS AN "AI GUY" FOR LOCAL BUSINESSES His blueprint: 1. Walk into any HVAC, plumbing, or sprinkler business. 2. Ask where they're leaking money. 3. Build them an AI agent that answers after-hours calls, sends instant texts, and gets quotes out in real time. 4. Integrate it with their CRM for free. 5. Charge them $2K-$3K/month to be their "AI guy." Repeat across 10-20 businesses. "There are people right now doing this."
V
Aaron is right (as usual) and I've been saying this for a year.
Large companies know they can benefit from AI but have 0 ability to do it themselves.
Their options are either traditional consulting shops like McKinsey and Deloitte, which suck ass (respectfully), or agentic SaaS which forces them to migrate off their ERP/CRM to some 16 year old's shitty vibe-coded "AI-native ERP". Not feasible.
AI needs to live on top of and in between your existing software stack. That's why at Varick we NEVER skip the audit - every company is different, with its own business logic, edge cases, and software requirements. You don't get real ROI by bolting generic workflows onto all of that.
Our model:
- spend 4 weeks auditing a department (usually 100s of people)
- spend 4 weeks building workflows that actually move the needle
- deliver and keep building. employee feedback in production trains the agents to be more accurate and autonomous
- by month 6 your entire department is transformed. most manual processes handled, and your team freed up for higher-leverage work
Too many startups are afraid to do an audit because it sounds too much like "consulting". We went all in on this thesis a year ago, and now no one can match the depth of what we surface in that phase.
A quote from one of our customers: "this is 100x better than McKinsey."
Bob Sternfels and the rest of the consulting industry, I'm coming for everything. Varick on top.
L
levie
@levie
If you read this and don’t understand why it’s happening it’s an opportunity to reset your understanding of how the real world works. The real world will need a ton of help actually getting agents going in the enterprise. Companies have legacy tech stacks they need to modernize, data in tons of fragmented tools, knowledge that isn’t captured or digitized, and change management needed to actually utilize agents effectively. And they have to do all this while still running their business day-to-day, unlike startups. This is why there is so much opportunity for companies (software or services) to actually deploy agents in specific domains and workflows. This remains a big opportunity for both existing services providers but also tons of new startups as well. Every new technology wave produces a new era of consulting firms that can deliver on that technology. It’s also why the FDE model is going to be alive and well for a long time because companies will want to have their vendor actually help drive the change management and implementation for their new workflows. The people aren’t going away. Far from it.
0
I’m a big believer in doing everything on your own and use to think Tinygrad was too expensive compared to raw compute costs.
Recently I’ve learned a lot about how they’re optimising inference, and hardware topology. used these tricks and 2x the speed of GLM
Tinygrad worth it
_
__tinygrad__
@__tinygrad__
Check out our new agent friendly viz.cli profiler. We will beat the speed of millions of lines of heuristics with the power of search. You write high level tinygrad code, search makes it fast (customized for your hardware!). The search engine makes sure it stays correct. https://t.co/nwndsZGxgf
G
How to really stop your agents from making the same mistakes
How to really stop your agents from making the same mistakes
LangChain has raised $160 million. Three years of development. A billion-dollar valuation. LangSmith, their testing platform, is genuinely sophisticat...