MOG-1 Claims Top Benchmarks as Self-Improving Agent Protocols and Vercel Security Breach Dominate Discussion
A small independent team claims their MOG-1 model beats every frontier model on benchmarks, sparking debate about whether money matters in AI development. The AI agent ecosystem matures with research on self-improving protocols and memory architectures, while a Vercel security breach through a compromised OAuth app has developers scrambling to audit their Google Workspace permissions.
Daily Wrap-Up
Today's feed tells a story about the AI ecosystem splitting into two very different lanes. On one side, you have the benchmark chasers and model builders, where a small team behind MOG-1 claims to have dethroned every frontier model from Opus 4.7 to GPT-5.4, and researchers are publishing protocols for agents that can rewrite themselves without human intervention. On the other side, you have the practitioners figuring out how to actually make money and stay secure while doing it, from consultants charging $2-3K/month per small business client to developers urgently checking whether a compromised OAuth app gave attackers access to their Google Workspace.
The security angle deserves more attention than it's getting. The Vercel breach isn't just a one-off incident; it's a reminder that as we wire AI agents into more business-critical systems, the attack surface expands dramatically. When @0xSero advocates moving all environment variables out of local files and into proper secrets management, that's not paranoia, it's the bare minimum for an era where your AI agent has access to production credentials. Meanwhile, the hardware supply chain conversation around glass cloth shortages and AMD's photonics play shows that the physical infrastructure underpinning AI is becoming its own complex battleground, with qualified suppliers holding surprising pricing power through 2027.
The most entertaining moment was easily @elonmusk dropping a "Banger @Grok" on a post about Grok's own AGI timeline predictions, which is the kind of recursive self-promotion that makes the AI timeline discourse feel like performance art. The most practical takeaway for developers: if you haven't audited your OAuth app permissions after the Vercel breach, do it now using the Google Admin Console steps @BrendanFalk shared, and while you're at it, migrate your .env files to a proper secrets manager before your AI coding agent accidentally leaks them.
Quick Hits
- @elonmusk praised Grok's AGI timeline predictions with a characteristic "Banger @Grok 😂," because of course he did. (link)
- @RayFernando1337 shared warnings about M5 Ultra pricing, with @digitalix suggesting Apple can't keep prices anywhere close to previous generations. Brace your wallets. (link)
- @alightinastorm is losing sleep over @Myrindy's browser engine, which just showed off procedural landscape generation running live in-browser. The web platform keeps getting wilder. (link)
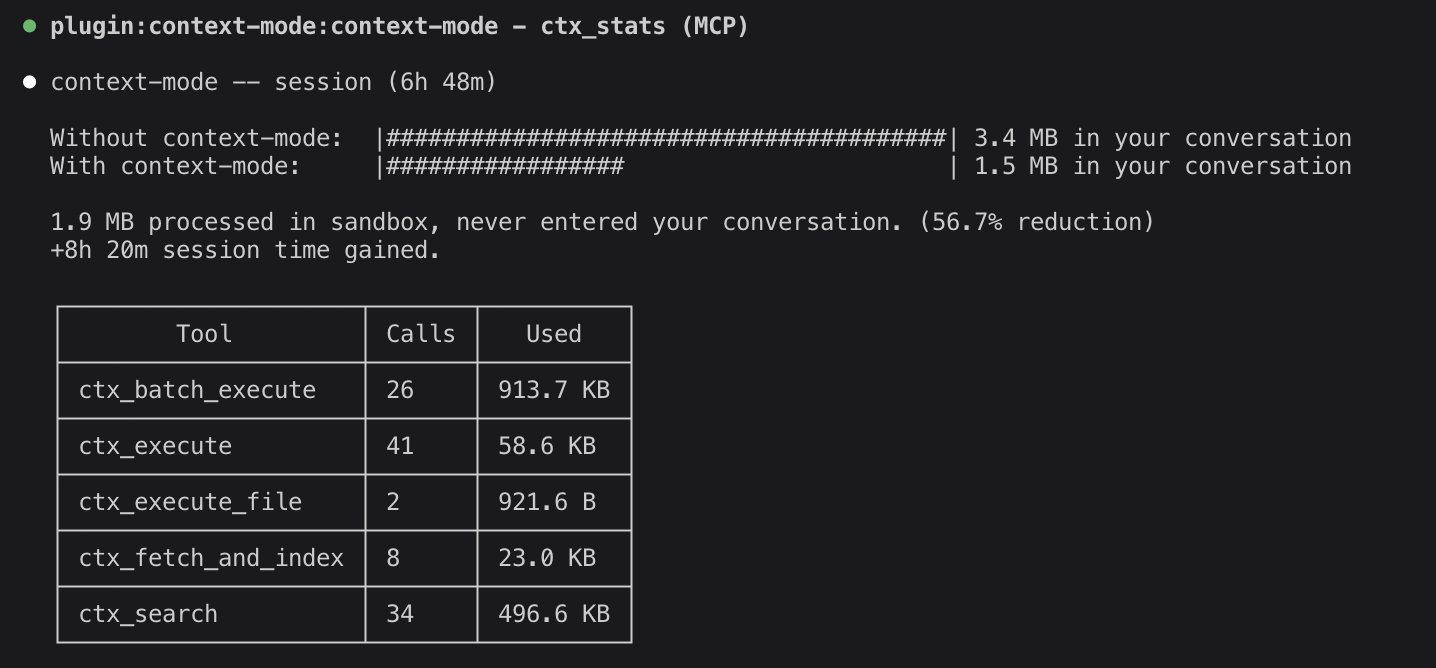
- @KorOglan reports running Claude Code for 3.5 hours straight while only hitting 17% of the 5-hour usage window, crediting the context-mode plugin by @mksglu for dramatically improving session efficiency. (link)
AI Agents: From Memory to Self-Improvement to Revenue
The agent conversation has matured well past "look what my chatbot can do." Today's posts sketch out three distinct layers of the agent stack: how agents remember, how they evolve, and how they generate revenue. Each layer represents a different stage of the agent lifecycle that developers need to understand.
@omarsar0 highlighted the Autogenesis protocol for self-improving agents, calling it one of the more interesting papers of the week: "The protocol specifies a framework for proposing, assessing, and committing improvements with auditable lineage and rollback." This isn't science fiction. It's a concrete engineering specification for agents that identify their own capability gaps, generate fixes, validate them through testing, and integrate what works. The key word there is "auditable," because self-modifying code without a paper trail is how you get production nightmares.
On the memory side, @Av1dlive pointed to a 26-minute OpenAI engineering talk as essential viewing, claiming it "will teach you more about building memory for agents right than most developers figure out on their own in months." Memory is the unglamorous infrastructure problem that separates demo agents from production agents, and the fact that OpenAI's own engineers are publishing detailed guidance suggests even they recognize the ecosystem needs better patterns here.
Then there's the business layer. @yonann shared Chris Camillo's pitch for becoming the "AI guy" for small businesses: "You just walk in and say give me one area where you're leaking money, I'll fix it for free. Within days you've set up an AI agent answering their calls, sending responses, getting quotes out in real time... and you just increased their revenue by 5 to 15%." Replicate across 10-20 clients at $2-3K/month and you're at half a million annually. It's a compelling model that turns agent development from a product play into a services play, and it's probably the fastest path to revenue for solo developers right now.
Models & Benchmarks: MOG-1 and the Small Team Thesis
The biggest splash today came from @saltjsx introducing MOG-1, which claims to be the world's most powerful model across reasoning, agentic coding, and problem-solving benchmarks. @wholyv amplified the story with characteristic enthusiasm: "These benchmarks came from not a billion dollar company, but a team that just knew their shit. Companies like OpenAI raise 122B dollars only to make losses while a small team just developed MOG-1 independently. Proves the money was never the problem."
That last claim deserves scrutiny. A 98.7% on SWE-Bench verified would be remarkable from any lab, let alone an independent team. The AI community has been burned before by benchmark claims that don't survive independent reproduction. But the narrative resonates because it taps into a genuine trend: the gap between frontier capabilities and what small teams can achieve with open weights and clever engineering is narrowing faster than the big labs would like.
On the practical benchmarking side, @stevibe ran a head-to-head vibe coding challenge between two MoE models, Qwen3.6 35B and Gemma4 26B, both running locally through llama.cpp with Unsloth quantization. Meanwhile, @twaldin0 reported that Claude Haiku 4.5 jumps from 65% to 85% on bug challenges just by optimizing the CLAUDE.md instructions file through GEPA. That 20-point improvement from prompt engineering alone reinforces something the agent community keeps rediscovering: how you talk to the model matters as much as which model you pick. @intertwineai also released an agent skills plugin to teach DSPy GEPA and RLM patterns to Claude and Codex, suggesting these optimization techniques are becoming standardized tooling rather than tribal knowledge.
Security: The Vercel Breach and Secrets Hygiene
Two posts today converged on the same uncomfortable truth: most developers are still handling secrets poorly, and the consequences are getting worse. The Vercel breach through a compromised OAuth app sent ripples through the developer community, with @Zeneca sharing @BrendanFalk's step-by-step guide for checking exposure: "Go to Google Admin Console, Security, Access and Data Control, API Controls, filter by the compromised OAuth app ID. If you see an app after filtering, you have potentially been compromised."
Separately, @0xSero made the broader case for secrets management: "Move all your envs out of local files and into something like this, all access to all systems needs to be tightly gated. No .env or you're at risk of getting screwed." This isn't new advice, but it hits differently in a world where AI coding agents routinely read your project files, including that .env you swore was in .gitignore. The intersection of AI tooling and secrets management is an underexplored attack vector that deserves more attention from the security community.
Claude Ecosystem: Design Tools and Token Efficiency
Claude's tooling ecosystem got two notable updates today. @viktoroddy released an 18-minute tutorial on building animated, award-winning websites with Claude Design and Opus 4.7, which @sarpstar praised enthusiastically as a game-changer for design workflows. The fact that Claude is developing a design-specific tool identity alongside its coding capabilities suggests Anthropic is pushing toward a more complete creative development workflow.
On the efficiency side, @parcadei teased an upcoming release claiming approximately 45% token savings on edits. That's a significant reduction in the cost of iterative development with AI assistants, and it matters because token costs are still the primary bottleneck preventing teams from using AI coding tools as aggressively as they'd like. Cheaper edits mean more iteration cycles, which means better output.
Hardware & AI Infrastructure
The semiconductor supply chain continues to shape AI's trajectory in ways that don't make mainstream tech headlines. @nikoliasgoninus flagged AMD's photonics play through GlobalFoundries as a potential game-changer: "We are talking 2-4x increase in aggregate memory bandwidth, 3-5x in power efficiency, and 2-4x in general speed." Photonic interconnects have been "five years away" for a decade, but an actual PIC order from AMD to GFS suggests the technology is finally crossing from research into production.
@zephyr_z9 drew parallels to previous semiconductor supply crunches while discussing @ParadisLabs' deep dive into Unitika, a Japanese company specializing in ultra-thin glass cloth for AI chip packaging. The thesis is straightforward: AI server demand is creating persistent shortages in specialized materials, and qualified suppliers like Unitika hold pricing power through at least 2027. It's a reminder that AI scaling isn't just about algorithms and data. It's about glass fabric thickness and polymer chemistry.
Knowledge Management Gets an LLM Rewrite
@aakashgupta made the case that Karpathy's LLM wiki concept could disrupt the $15+ billion knowledge management industry, applying it specifically to product management workflows. His diagnosis of the problem is sharp: "I've worked at companies with 50,000+ Confluence pages. Finding the competitive analysis from two quarters ago required knowing which PM wrote it, what they named it, and which of three possible folder structures they used. Most people just redid the research."
The proposed solution, using an LLM to read raw sources, generate structured wiki pages, and maintain cross-references automatically, addresses the core failure mode of traditional wikis: humans don't maintain them. The adaptation for PM-specific knowledge types like user research, competitive intel, and decision logs makes this more than a theoretical exercise. Whether it actually replaces Confluence and Notion is debatable, but the underlying insight that LLMs are better librarians than humans is increasingly hard to argue with.
Sources
Claude Design is insane. ❤️🔥Just recorded a 18-min tutorial on how to build animated, award-winning websites with Claude Design + Opus 4.7! https://t.co/WnUvKYdKFj
I apologize for staying quiet for way too long. Here is a first look at the flow for generating a random realistic landscape in the engine. This time, the demo is done on the live website too :) https://t.co/nA3mu7MzEn




We made a huge non-consensus bet on GFS's photonics biz, and now GFS has won the PIC order from AMD Btw, we are bullish on Tower Semi & UMC as well https://t.co/ZKvMDBf5x5

Agents Are Stuck in a Loop. Memory Growth and Propagation is why !

225 sessions, 8,337 tool calls. I ran /ctx-insight on my own data and the numbers surprised me. I read 5.2x more than I write. 1,992 files read, 386 written. I thought I was mostly writing code. Turns out I spend most of my AI time understanding code. Review mode 45% of the time, implementation only 34%. My context window overflows in just 4% of sessions, which apparently puts me well below the 60%+ most developers hit. The part I didn't expect: 19 tasks running in parallel across 6 bursts saved me roughly 26 minutes. And my error rate is 2.7%, meaning almost everything lands on the first try. 143 commits in 225 sessions, but most sessions are pure research. The commits come in focused bursts. All of this was already sitting in a local SQLite database on my machine. Every session writes tool calls, errors, file edits, context overflows. I just never had a way to see it until now. /ctx-insight to see yours. Nothing leaves your machine. https://t.co/6qDtMec1UO

// Self-Evolving Agent Protocol // One of the more interesting papers I read this week. (bookmark it if you are an AI dev) The paper introduces Autogenesis, a self-evolving agent protocol where agents identify their own capability gaps, generate candidate improvements, validate them through testing, and integrate what works back into their own operational framework. No retraining, no human patching, just an ongoing loop of assessment, proposal, validation, and integration. Why it's worth reading this paper: Static agents age quickly. As deployment environments change and new tools arrive, the agents that survive will be the ones that can safely rewrite themselves. Autogenesis is part of a growing wave of self-improving agent systems, alongside work like Meta-Harness and the Darwin Gödel Machine line, and it's one of the cleaner protocol-level takes on continual self-improvement so far. Paper: https://t.co/3aj9LLjSbk Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

Introducing MOG-1, the world's most powerful model. MOG-1 excels at deep reasoning, agentic coding, and advanced problem solving. It scores higher than any other publicly available model. https://t.co/W1S8qiB234
To check if your Google Workspace has been compromised by the same tool that compromised Vercel: 1. Go to https://t.co/TpuIOW5Fwg - This is Google Admin Console > Security > Access and Data Control > API Controls > Manage app access > Accessed Apps 2. Filter by ID = https://t.co/uqJnCqp5Ah - This is the ID of the compromised OAuth app If you see an app after filtering, you have potentially been compromised
Karpathy's most viral post ever (19.7M views) solved a problem I've hit in every PM job I've had. I adapted his system for PM work. 6 workflows, a CLAUDE.md template, and the honest limitations: https://t.co/eQ3FKwGNDu https://t.co/t1AhmCOmDe
ok is there a dspy typescript equiv that i can try (that wont enrage me)
Here Grok’s AGI timeline 😂 https://t.co/WfToEVz0S0
Very bullish on Unitika Ltd (TYO: 3103): They might be one of my favourite companies rn. They focus on polymers and glass fibers/fabrics...taking adv of multi-yr AI tailwinds - i.e. demand for packaging substrates & PCBs. Which then makes low-CTE glass cloth/fabrics indispensable. TrendForce & Digitimes say: T-glasss/Low-CTE cloth shortages persist through 2027 and AI server upgrades will keep demand accelerating into 2026–2028. With pricing tension and extended visibility for qualified suppliers. Ultra-thin, low-CTE variants (Unitika’s specialty) ultimately provide the stability needed to prevent warping in large AI dies. ...Problems that traditional E-glass or organic substrates simply cannot solve at scale. But supply of glass cloth remains tight - Nittobo’s order books are full through end-2026, with meaningful new capacity (via its Nan Ya partnership) not online until H2 2027 at the earliest. This creates sustained pricing power + qualification opportunities for credible Japanese #2/#3 suppliers like Unitika. Unitika have process integration + IP (world’s thinnest fabrics) and qualification lock-in. Which creates stickiness vs. Nittobo (scale leader) and entrants (Asahi Kasei, Taiwanese). CEO said - “We beat our competitors to developing the world’s thinnest glass fabrics... We aim to become a company that is always thinking about the next move by strengthening electrical and electronic materials, including the semiconductor field.” AI tailwinds already visible for Unitika: “Driven by vigorous global AI-related demand... sales grew significantly for ultra-thin Low CTE Glass Fabrics and ultra-thin E Glass Fabrics for mobile memory applications.” (Q3 FY2026). “Entry into AI semiconductor package substrate market, with mass-production technologies to be established in FY 2025 and full-scale sales from FY 2026.” (Unitika Report 2025). Future orders sustained into 2027 on hyperscaler spend. In terms of catalysts: - May 14 FY2026 results (AI quantification) - Pricing/qualification wins Financials: Q3 FY2026: > sales ¥95.6bn (+2.2% YoY) > op. profit ¥9.0bn (doubled) on electronics rebound > FY2026 guide ¥110bn sales/¥9.5bn profit despite contraction Unitika has completed REVIC-backed restructuring (debt relief, divestments, portfolio shrink). Which is a self-inflicted contraction that amplifies the margin tailwind from AI-driven volume and pricing. Downsides: - Tiny scale caps market impact - execution risk (as usual) - cyclical electronics exposure - new-entrant relief by late 2027 - not pure-play