Anthropic's Coding Agents Talk Goes Viral as Devs Race to Cut Claude Code Token Costs
The AI developer community rallied around a viral Anthropic talk on coding agents while a curated list of 10 token-saving GitHub repos dominated conversation. Meanwhile, an 18B frankenstein model running on a single RTX 3060 turned heads, and OpenAI open-sourced their Agents SDK to strong reviews.
Daily Wrap-Up
Today's feed told a clear story: the age of AI coding agents is here, and now the real work is making them efficient and affordable. A speech by Anthropic's head of coding agents research went viral with multiple people urging their followers to bookmark it, while simultaneously a massive thread cataloging 10 GitHub repos for cutting Claude Code token usage by 60-90% racked up attention. The juxtaposition is telling. Developers aren't asking "should I use AI coding tools?" anymore. They're asking "how do I stop burning through my token budget before lunch?"
On the model front, the open-source community continues to punch above its weight. A new 18B parameter "frankenstein" model that merges Opus 4.6 and GLM-5.1 reasoning beat the much larger Qwen3.6-35B on benchmarks while fitting on a single 12GB GPU. This is the kind of development that keeps the local-first AI crowd energized: you don't need a cluster, you need a clever merge and a mid-range graphics card. The OpenMythos project attempting to reconstruct Claude's Mythos architecture in PyTorch also underscored just how fast the open-source ecosystem reverse-engineers and iterates on proprietary advances.
The most entertaining moment was easily the collective panic around Claude reading .env files, which spawned an all-caps warning tweet that got quote-tweeted with a calm, practical settings.json fix. Nothing like a security scare to remind everyone that AI tools have file system access and you should configure them accordingly. The most practical takeaway for developers: audit your AI coding tool permissions today. Add .env and credentials files to your deny list in settings, pick up one or two token-optimization tools from the curated repos list (RTK for terminal-heavy workflows, code-review-graph for large codebases), and watch the Anthropic coding agents talk to level up how you prompt and structure agent workflows.
Quick Hits
- @SethSHowes wrote up how he sequenced his entire genome at home on his kitchen table, covering equipment, protocol, and costs. DIY biotech just keeps getting more accessible.
- @tadasgedgaudas spotted a free backlinks tool using Common Crawl's web graph and immediately suggested packaging it as a $99 lifetime SaaS. The "wrap a bash script in a landing page" business model lives on.
- @1a1n1d1y posted a cryptic "dwarkesh was right holy fuck dude" with zero context. We've all been there.
- @CNET covered Oura's push to use AI and wearable data for chronic illness prevention, announced at MWC. Health-tech meets ring-tech.
- @browser_use retweeted praise from a developer who said it was the first browser automation tool that actually worked through every failure case they threw at it.
Claude Code: Token Wars and Security Hygiene
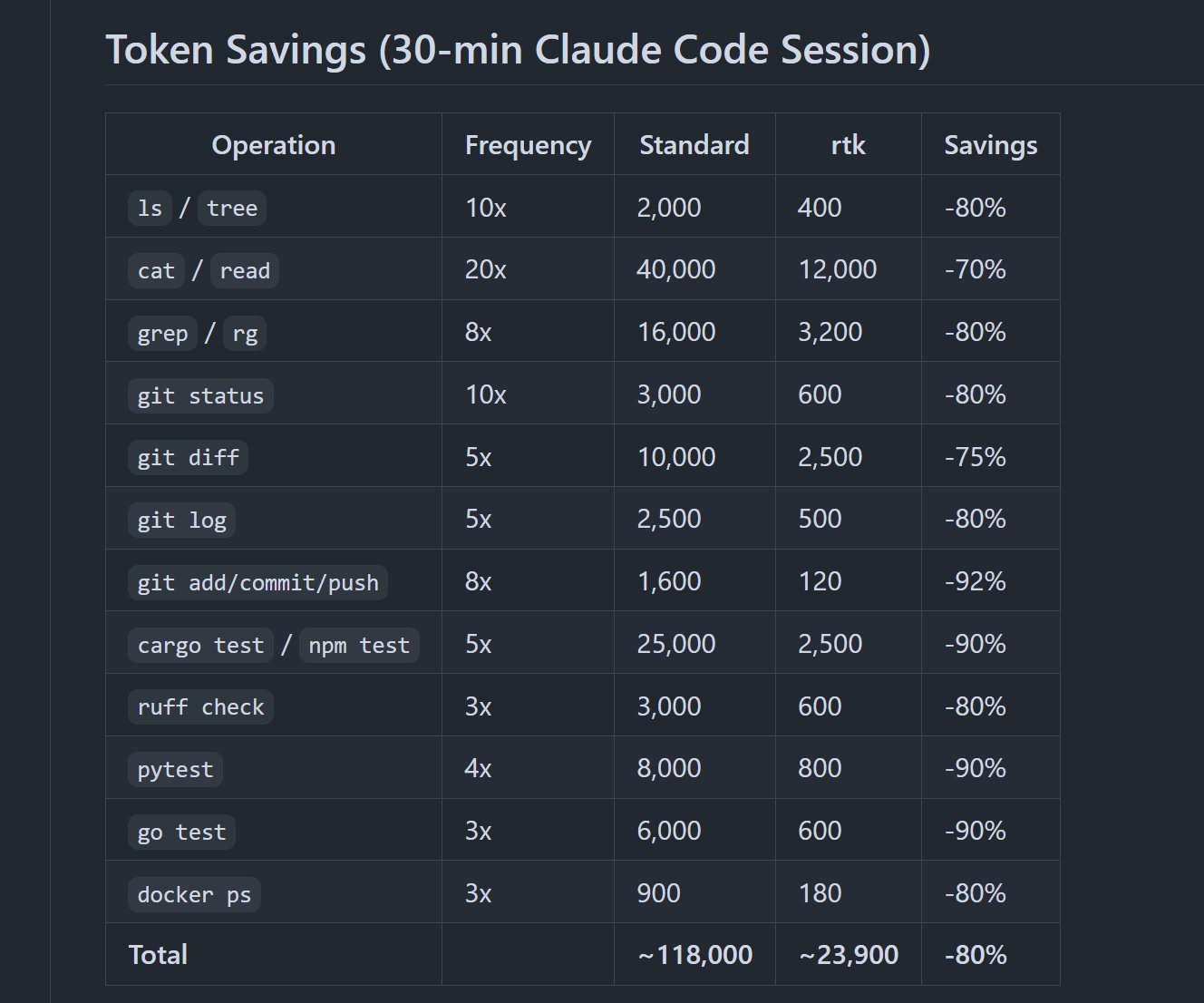
The Claude Code ecosystem is maturing fast, and today the conversation centered squarely on operational discipline. @DeRonin_ dropped a comprehensive thread listing 10 GitHub repos designed to slash token consumption, with claimed reductions ranging from 60% to a staggering 98%. The recommendations span the full stack of the problem: RTK acts as a CLI proxy filtering terminal output before it hits context, Context Mode sandboxes raw tool output into SQLite, and code-review-graph uses Tree-sitter to build a local knowledge graph so Claude only reads what matters. As DeRonin put it: "most people are burning tokens without knowing it. Run /context in a fresh session and see how much is gone before you even type a word." The practical stacking advice at the end (pick 2-3 tools based on your workflow, not all 10) was the kind of grounded recommendation that separates useful content from hype.
On the security side, @Tech_girlll's all-caps warning about Claude reading .env files clearly struck a nerve. @dani_avila7 responded with the fix: a simple addition to .claude/settings.json that blocks access to sensitive files. It's a small configuration change but an important reminder that these tools operate with real file system permissions, and the defaults may not match your threat model. As coding agents become more autonomous, the surface area for accidental secret exposure grows proportionally.
The Anthropic Coding Agents Masterclass
Two separate posts called attention to the same talk, and both used the word "masterclass." @iruletheworldmo described it as "the best I've seen" for understanding how to use coding agent systems optimally, adding "there's still a tonne of leverage in knowing how to use these systems optimally." @0xMovez similarly hyped the 30-minute speech, claiming it "will change the way you use AI forever."
The convergence here is significant even if the phrasing is hyperbolic. We're entering a phase where the gap between naive and skilled usage of AI coding tools is widening. Knowing how to structure prompts, break down tasks, and configure agent behavior isn't optional anymore; it's the difference between productive sessions and expensive frustration. @theo added fuel to the fire by endorsing Uncle Bob Martin's "morning bathrobe rant" about rule files, noting that "Bob is quickly becoming one of the best sources for practical AI advice." When Uncle Bob and Anthropic researchers are both producing must-watch content about the same workflow patterns, the signal is clear: prompt engineering for coding agents is its own emerging discipline.
Open-Source Models Keep Closing the Gap
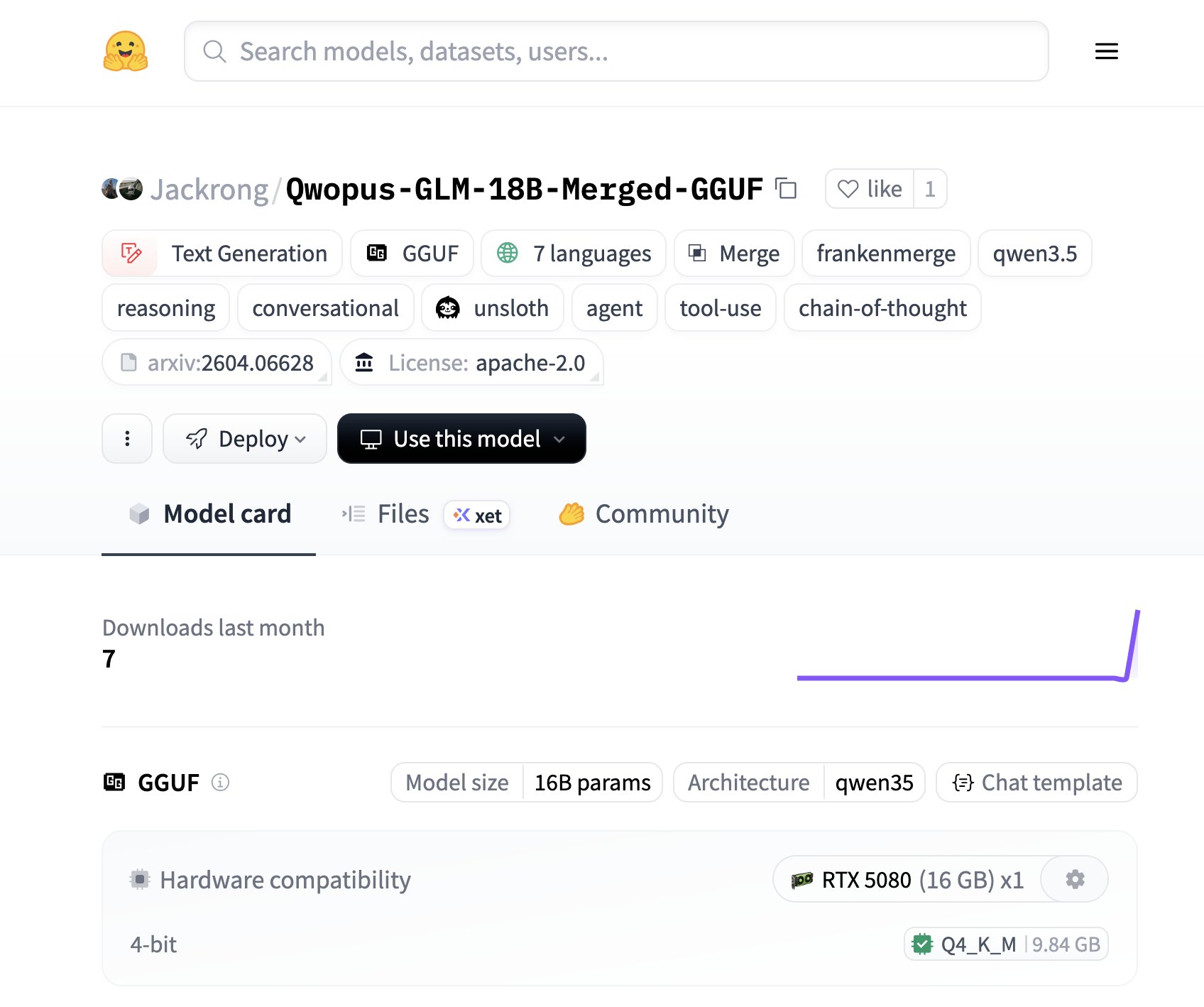
The model merging community had a banner day. @leftcurvedev_ highlighted a new 18B parameter model released on Hugging Face that combines Opus 4.6 and GLM-5.1 reasoning into a single architecture. The numbers are eye-catching: it beats Qwen3.6-35B-A3B on a 44-test suite while requiring only 12GB of VRAM instead of 24GB, running at "66+ tok/s stable on mid-range GPUs." As leftcurvedev described it, the model offers "perfect tool calling & agentic reasoning" in a GGUF package of just 9.8GB. The question posed at the end, "the ultimate model for 12-16GB VRAM owners?", feels less rhetorical by the day.
Meanwhile, @realsigridjin spotlighted @KyeGomezB's OpenMythos project, an open-source PyTorch reconstruction of Claude's Mythos architecture using looped transformers with Mixture-of-Experts routing. And @lateinteraction (Omar Khattab) signal-boosted news that DSPy.RLM achieved state-of-the-art on the LongCOT benchmark "by a very large margin." These three developments paint a picture of an open-source ecosystem that isn't just keeping pace but actively innovating on architecture, training methodology, and practical deployment simultaneously.
Agents and Frameworks: OpenAI Enters the Chat
@_vmlops covered OpenAI's open-sourcing of their Agents SDK, and the assessment was refreshingly direct: "most agent frameworks are bloated... this one isn't." The SDK boils down to three core primitives (agents, handoffs, and tracing), works with 100+ LLMs beyond just OpenAI's own, and includes built-in session memory via SQLite or Redis. With 18.9K GitHub stars already, adoption is moving fast.
On the research side, @gauri__gupta highlighted EvoForge by Haize Labs, which draws inspiration from the self-evolving agentic harness work at NeoSigma AI. The concept of agents that improve their own evaluation and execution harnesses represents a frontier that's moving from academic curiosity to practical implementation. As agent frameworks proliferate and simplify, the differentiator increasingly becomes not the framework itself but the meta-layer: how agents learn, evaluate, and optimize their own performance over time.
RAG Meets Caching: The Hybrid Architecture Play
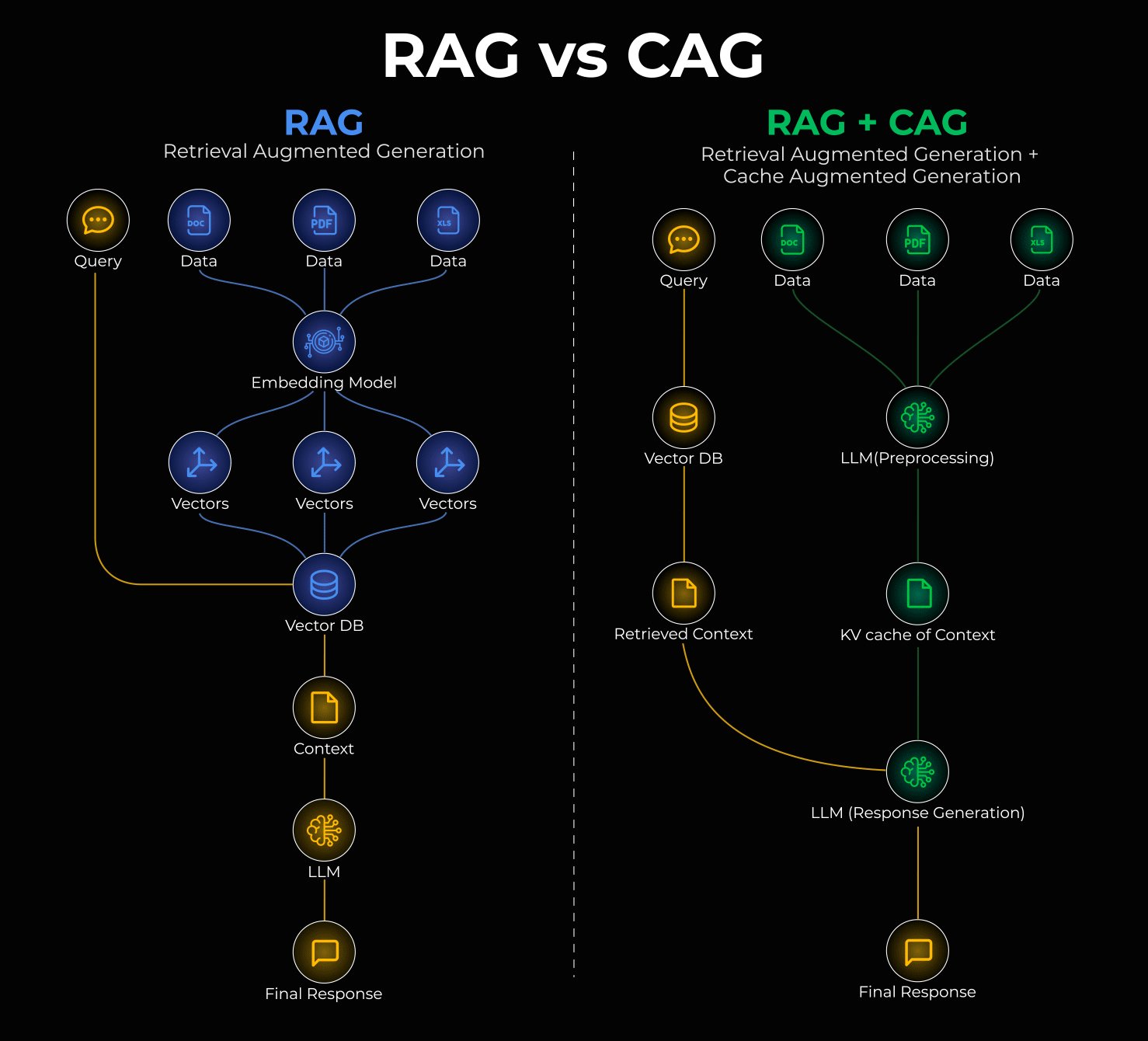
@_avichawla delivered a clean explainer on combining RAG with Cache-Augmented Generation (CAG), framing it as a solution to a real production pain point: "every query hits the vector DB. Even for static information that hasn't changed in months. This is expensive, slow, and unnecessary." The hybrid approach splits knowledge into two tiers: static data (policies, documentation) gets cached in the model's KV memory, while dynamic data gets fetched via traditional retrieval.
The key insight is selectivity. As Avichawla noted, "if you cache everything, you'll hit context limits. Separating 'cold' (cacheable) and 'hot' (retrievable) data keeps this system reliable." With both OpenAI and Anthropic already supporting prompt caching in their APIs, this isn't theoretical architecture; it's something teams can implement today. For anyone running RAG pipelines in production, the cost and latency savings from caching your static knowledge layer are likely the lowest-hanging optimization fruit available right now.
The AI Implementation Gold Rush
@Zephyr_hg made an observation that cuts against the prevailing narrative: while everyone races to sell AI tools, the real opportunity might be in making existing stacks actually work. The pitch is compelling: "$12K/month retainers. Solo operators. Almost nobody doing it yet." The framing of "buyers already drowning in the ones they bought" resonates with the broader pattern visible across today's posts. Between token optimization tools, agent frameworks, caching strategies, and security configurations, the complexity of running AI-augmented development workflows is growing fast. @Prince_Canuma's home compute setup (M3 Ultra with 512GB, RTX PRO 6000, M3 Max) and his story of using Claude Code to remotely SSH into a machine that auto-updated and killed his session perfectly illustrates both the power and the operational overhead of these systems. The tools are incredible; making them all play nicely together is the real job.
Sources
C
OURA wants to leverage AI & data from its wearables to help in the prevention of chronic illnesses, from the MWC stage. https://t.co/eH8dcJFrib

R
10 GitHub repos to spend 60-90% less tokens in Claude Code:
1. RTK (Rust Token Killer)
CLI proxy that filters terminal output before it hits your context
- 60-90% reduction on common dev commands
- one binary, zero dependencies
- works with Claude Code, Cursor, Copilot
Repo: https://t.co/WayvpBtyBH
2. Context Mode
Sandboxes raw tool output into SQLite instead of dumping it into context
- 98% context reduction on Playwright, GitHub, logs
- only clean summaries enter your conversation
- works as Claude Code plugin
Repo: https://t.co/YNbFIGQz7X
3. code-review-graph
Local knowledge graph that maps your codebase with Tree-sitter
- Claude reads only what matters, not the entire repo
- 49x token reduction on large monorepos
- 6.8x on average reviews
Repo: https://t.co/9gIzmAWN12
4. Token Savior
MCP server that navigates code by symbols, not full files
- 97% reduction on code navigation
- persistent memory across sessions
- 69 tools, zero external deps
Repo: https://t.co/OtvhrMgGWh
5. Caveman Claude
makes Claude talk like a caveman to cut output tokens
- 65-75% output reduction
- one-line install
- keeps full technical accuracy
Repo: https://t.co/onBeghTyfH
6. claude-token-efficient
one CLAUDE.md file that keeps responses terse
- drop-in, no code changes
- reduces output verbosity on heavy workflows
- best for output-heavy sessions
Repo: https://t.co/j6MKo9klQe
7. token-optimizer-mcp
MCP server with caching, compression, and smart tool intelligence
- 95%+ token reduction through intelligent caching
- compresses repeated tool outputs
Repo: https://t.co/0jIVQ4ANls
8. claude-token-optimizer
reusable setup prompts for optimizing any project
- 90% token savings in 5 minutes
- reduces doc token usage from 11K to 1.3K
Repo: https://t.co/puil9WwFGB
9. token-optimizer
finds ghost tokens that silently eat your context
- survives compaction without losing quality
- fixes context quality decay
Repo: https://t.co/92G8e4yeGq
10. claude-context (by Zilliz)
code search MCP that makes your entire codebase the context
- ~40% reduction with equivalent retrieval quality
- hybrid BM25 + dense vector search
Repo: https://t.co/yjfiQOSy15
[ how to stack them ]:
you don't need all 10. pick 2-3 based on your workflow:
> heavy terminal output? RTK
> big codebase? code-review-graph + Token Savior
> lots of MCP servers? Context Mode
> quick fix? Caveman + claude-token-efficient
most people are burning tokens without knowing it
run /context in a fresh session and see how much is gone before you even type a word
your pocket will thank me later :<)
L
Okay this one is insane. A new 18B frankenstein model was just released on @huggingface — Beats the new Qwen3.6-35B-A3B on a 44-test suite despite requiring 12GB VRAM instead of 24GB 🤯
Runs on a SINGLE RTX 3060 (!)
🧠 Opus 4.6 & GLM-5.1 reasoning in one model
⚡️ 66+ tok/s stable on mid-range GPUs
🧪 Experimental, no additional training
🛠️ Perfect tool calling & agentic reasoning
📷 Fits on low hardware, any 12gb card
📚 GGUF size is 9.8GB (Q4_K_M)
Another gift from Jackrong, adding both qwopus and glm-distilled qwen together was not on my bingo card. Truly seems like the sweet spot between 9B and 27B models right now.
The ultimate model for 12-16GB VRAM owners?
https://t.co/kqDUizh1pf
V
OPENAI JUST OPEN-SOURCED THEIR AGENTS SDK & it's actually clean
most agent frameworks are bloated...
this one isn't
just 3 core primitives:
→ agents (llm + tools + guardrails)
→ handoffs (route between agents)
→ tracing (debug every run)
works with 100+ llms, not just openai.
built-in session memory with sqlite or redis
no manual conversation history juggling
the hello world is 4 lines
the multi-agent handoff is 20
18.9k stars already
https://t.co/YTd1Sw44NQ
M
This 30-minute speech by the Head of Anthropic "Coding Agents" researcher will teach you more about vibe coding than 100 paid courses.
Bookmark it & give it 30 minutes today. This video will change the way you use AI forever, https://t.co/2ymJrZwj1W

0
0xMovez
@0xMovez
This weather bot turned $300 → $122K on Polymarket weather markets in 3 months I fully decoded algo and built a self-learning Hermes weather trading agent using weather APIs + Opus 4.7, the bot runs 5-min scans & searches mispricings on Polymarket run your agent in 5 steps: • set up a VPS server on Hetzner - $6 • create a weather API on {visualcrossing} - free • set up Hermes agent using one-liner code - free • connect Telegram bot + Opus 4.7 • send {weather trading logic} from article to agent started my agent 2 days ago with a test sum and already having 40% profit agent already caught 2 traders with +400% ROI on Seoul & Chicago weather markets bot used for logic: https://t.co/drSKj3nLM1 my bot test wallet: https://t.co/HYCxTE9kJ6 Hermes bot is a self-learning agent so give him enought trades {100+}, to build his own logic. start small
A
dwarkesh was right holy fuck dude
O
RT @raw_works: sorry it took me ~50 hrs! now i've got DSPy.RLM as SOTA on LongCOT (Full) by a very large margin, using...
...drumroll...…
T
Bro shared so much sauce this could be a mini saas.
use this
charge $99 lifetime
print
R
retlehs
@retlehs
TIL you can pull the backlinks to any domain for free (instead of using a service that charges hundreds a month) using Common Crawl's web graph. Wrote a tiny bash script: https://t.co/KDVhYMjhq8 https://t.co/gq5mq99ya0
D
If you don't want Claude to read your .env files
Just add this to your .claude/settings.json https://t.co/d3DZXltwLr

T
Tech_girlll
@Tech_girlll
DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE
Z
> everyone racing to sell AI tools
> buyers already drowning in the ones they bought
> the real service is someone walking in and making the stack actually work
> $12K/month retainers. solo operators. almost nobody doing it yet https://t.co/aXh6A0AK8K

Z
Zephyr_hg
@Zephyr_hg
The $12K/Month Service AI Can't Replace (And How to Build It By August)
T
Based and true. Bob is quickly becoming one of the best sources for practical AI advice
U
unclebobmartin
@unclebobmartin
Morning bathrobe rant: Rule files. https://t.co/wH6f2vM9iV
G
Great to see EvoForge by @haizelabs inspired by our recent work on self-evolving agentic harness @NeoSigmaAI.
Thanks for the shout out @leonardtang_ https://t.co/XF0ztsoR8k
G
gauri__gupta
@gauri__gupta
auto-harness: Self improving agentic systems with auto-evals (open-sourced !)
S
opensource is crazy
Look at this guy
K
KyeGomezB
@KyeGomezB
Introducing OpenMythos An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch. The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts. My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning. Learn more ⬇️🧵
B
RT @alexhillman: I've tried every browser tool and eventually ran into the same problems.
This is the first one that ripped thru every fa…
A
RAG vs. CAG, clearly explained!
RAG is great, but it has a major problem:
Every query hits the vector DB. Even for static information that hasn't changed in months.
This is expensive, slow, and unnecessary.
Cache-Augmented Generation (CAG) addresses this issue by enabling the model to "remember" static information directly in its key-value (KV) memory.
In fact, you can combine RAG and CAG for the best of both worlds.
Here's how it works:
RAG + CAG splits your knowledge into two layers:
↳ Static data (policies, documentation) gets cached once in the model's KV memory
↳ Dynamic data (recent updates, live documents) gets fetched via retrieval
This gives faster inference, lower costs, and less redundancy.
The trick is being selective about what you cache.
Only cache static, high-value knowledge that rarely changes. If you cache everything, you'll hit context limits. Separating "cold" (cacheable) and "hot" (retrievable) data keeps this system reliable.
You can start today. OpenAI and Anthropic already support prompt caching in their APIs.
I have shared my recent article on prompt caching below if you want to dive deeper.
👉 Over to you: Have you tried CAG in production yet?
_
_avichawla
@_avichawla
Prompt caching in LLMs, clearly explained
S
I sequenced my genome at home, on my kitchen table.
I wrote up exactly how I did it - the equipment, protocol, theory, and cost:
https://t.co/Nkjqaho2zm
P
My home compute for MLX and research:
• M3 Ultra — 512GB (sponsored by community + @wai_protocol)
• RTX PRO 6000 — 96GB (sponsored by @jelveh / https://t.co/KdSUC4nRTT)
• M3 Max — 96GB
Every model I port, every kernel I tune, every release I ship gets stress-tested here first.
Endless gratitude to everyone backing the work ❤️
P
Prince_Canuma
@Prince_Canuma
We’re living in interesting times. Traveled ~300km from home. Left a Claude Code session running on my M3 Ultra to test continuous batching across all models (2TB of weights) and check for regressions. Overnight the M3 Ultra auto-updated, restarted, and killed both my session and Tailscale. So I SSH’d into my Linux box, asked Claude Code there to scan the network, SSH into the M3 Ultra, and restart Tailscale. It worked, my session is back and it’s like I never left home. 🙌🏽🔥
🍓
a masterclass in coding agents from the head of anthropic.
there’s still a tonne of leverage in knowing how to use these systems optimally and this is the best i’ve seen.
make sure to bookmark so you can watch again and again chat https://t.co/0XgetIaN0Y
