Opus 4.7 Divides Power Users as Vercel Ships Workflow SDK and Hyperspace Launches Peer-to-Peer Inference Pods
The AI developer community is split on Claude's Opus 4.7 release, with some praising its agentic capabilities while others report broken adaptive reasoning. Vercel went GA with Workflow SDK and an open-source code review bot, while Hyperspace introduced peer-to-peer inference pods that let teams pool their hardware into shared AI clusters. Infrastructure breakthroughs in quantization and local inference continue to push the boundary of what's possible without cloud APIs.
Daily Wrap-Up
Today's feed tells a story about the growing tension between centralized AI services and the decentralized future developers are actively building. On one side, you've got Vercel shipping polished infrastructure for cloud-native AI agents. On the other, Hyperspace is letting five people with laptops form a mesh network and run 32B parameter models for free. These aren't competing visions so much as they are two lanes of the same highway, and the developers who understand both will have a serious edge.
The Opus 4.7 discourse is the most entertaining thread of the day. @bcherny, who literally created Claude Code, says it "feels more intelligent, agentic, and precise" than 4.6 and that he needed a few days to learn how to work with it effectively. Meanwhile, @sdmat123 apparently burned through a 5-hour quota trying to work around what they describe as "broken adaptive reasoning." @WesRoth is out here talking about "forbidden techniques" in training. The truth is probably boring: new model versions always have a shakeout period where workflows that were optimized for the old model need adjustment. But the drama is real and the productivity stakes are high enough that people are genuinely frustrated.
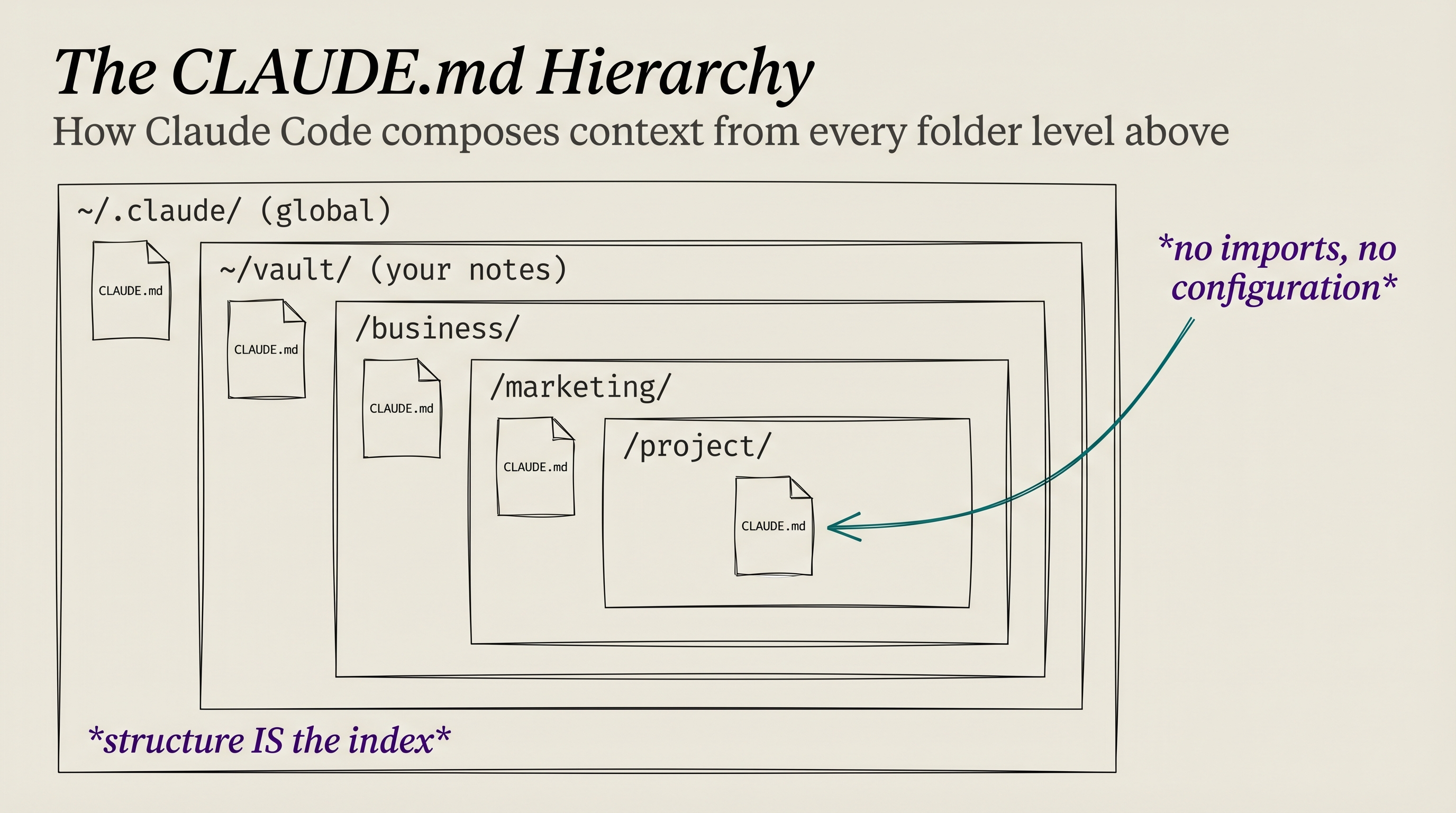
The most practical takeaway for developers: if you're building anything with LLM agents today, study the CLAUDE.md nesting pattern @TaylorPearsonMe described. The idea of placing context files at every directory level so the agent automatically loads the right context is simple, elegant, and immediately applicable to any project regardless of which model or tool you're using.
Quick Hits
- @elonmusk pitching "Universal HIGH INCOME" via federal government checks as the answer to AI unemployment, arguing AI/robotics output will outpace money supply inflation. Bold macro take, zero implementation details.
- @elonmusk also dunking on LiDAR critics by reminding everyone he oversaw custom LiDAR development for SpaceX Dragon docking. The quote-tweeted French essay comparing LiDAR defenders to Soviet economic planners is... something.
- @RoundtableSpace sharing a Stanford 1-hour lecture on agentic AI, calling it required viewing before building anything. Filed under "watch this weekend."
- @nummanali flagging the new @ClaudeDevs official X account for developer changelogs and API releases.
- @viktoroddy posted a tutorial on using Gemini 3.1 plus Seedance 2.0 to build "cinematic $10k websites" entirely with AI. The vibe-coding-to-production pipeline keeps getting shorter.
- @elliotarledge sharing first impressions of the RTX PRO 6000 Blackwell workstation GPU: 96GB VRAM, single slot. The local inference crowd is salivating.
- @MaxMusing deadpanning that tables in Slack are more exciting than Opus 4.7, reacting to Slack's Block Kit upgrade with cards, alerts, carousels, data tables, and charts for building agent UIs.
Claude Opus 4.7: The Community Splits
Every major model release follows the same arc: excitement, experimentation, frustration, adaptation. Opus 4.7 is no different, but the stakes feel higher because Claude Code users have built serious workflows around the previous version. @bcherny offered the optimistic view: "Opus 4.7 feels more intelligent, agentic, and precise than 4.6. It took a few days for me to learn how to work with it effectively, to fully take advantage of its new capabilities." That qualifier about needing days to adjust is doing a lot of heavy lifting.
On the other end, @sdmat123 (via @hive_echo's RT) declared that "Opus 4.7 has broken adaptive reasoning" and spent five hours burning through API quota to find mitigations. And @WesRoth added fuel to the fire by referencing "forbidden techniques" in training, pointing to a line in the Opus 4.7 System Card where "Claude Mythos Preview basically says 'I won't complete the task you requested unless you disclose that you used this training technique.'" Whether that's a safety feature or a bug depends entirely on your perspective.
The pattern here is familiar to anyone who's watched model transitions closely. Power users who've spent months prompt-engineering for a specific model's quirks will always feel the friction first. The real question isn't whether 4.7 is better or worse in aggregate; it's whether the agentic improvements @bcherny highlights are worth the workflow disruption. For most developers, the answer is probably yes, but budget a day or two for recalibration.
Vercel's Infrastructure Play: Workflows and Code Review
Vercel made two significant moves today that together paint a clear picture of where they think backend development is heading. First, Vercel Workflows hit general availability. @rauchg framed the problem with characteristic clarity: "That LLM you're calling will go down. That service will rate limit you. That database will unexpectedly slow down. You will get paged." Workflow SDK promises durable execution for agents and long-running processes without managing queues, retries, or workers.
Second, @ihtesham2005 highlighted Vercel's open-source code review bot, OpenReview, which spins up isolated sandboxes, runs your actual linters and tests (not static analysis), and posts inline GitHub suggestions. It's Claude Sonnet 4.6 under the hood, self-hosted, MIT licensed, and deployable in one click. The fact that it commits and pushes formatting fixes directly to your branch is either thrilling or terrifying depending on your trust level.
These releases are complementary. Workflows handles the durability problem for any agent backend, while OpenReview demonstrates what a well-built agent on that infrastructure actually looks like. @rauchg's comparison to what "Next.js did for the frontend" is ambitious, but Vercel has earned enough credibility to make that claim worth watching.
Distributed and Local AI: The Cost Revolution Continues
The most substantive post of the day came from @varun_mathur introducing Hyperspace Pods, a system that lets a small group pool their laptops into a peer-to-peer AI inference cluster. The pitch is compelling: "A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp) for free." Models get automatically sharded across devices, inference is pipelined through a ring topology, and the whole thing exposes a single OpenAI-compatible API endpoint.
The local inference benchmarks keep getting more impressive too. @sudoingX shouted out @ivanfioravanti for already benchmarking Qwen 3.6 on the M5 Max via MLX: "121 tok/s single request and 550 tok/s on batch 32." And @0xSero catalogued a series of infrastructure breakthroughs: "Turboquant merged into vLLM, 75% VRAM reduction for KV cache near lossless" alongside "Megatrain, 100B model trained on 1 GPU."
Meanwhile, @yacineMTB looked at the new Allwinner A733-based Orange Pi Zero 3W (a Raspberry Pi Zero competitor starting at $25 with up to 16GB LPDDR5) and concluded simply: "Yeah it's over. China is going to win the chip wars." The convergence of cheaper hardware, better quantization, and peer-to-peer networking is steadily eroding the moat that cloud API providers have enjoyed.
Agents: From Theory to Production Patterns
The agent-building conversation has matured noticeably. Instead of debating whether agents work, practitioners are now sharing specific architectural patterns. @TaylorPearsonMe's breakdown of CLAUDE.md nesting is the standout example: place context files at every directory level, and Claude Code automatically walks the tree to build context. "Global → vault → business → marketing → project. That means the very first message in a chat about that marketing project is going to be like talking to someone that knows you, your business, your marketing history."
@kylejeong shared how Browserbase builds internal agents, framing the browser as "the universal API for everything that doesn't expose one." @Av1dlive pointed to an Anthropic engineer's 14-minute guide on building agents effectively, while @pashmerepat and @jxnlco both shared workflows for using Codex as an automation layer for daily work. The theme across all of these is the same: agents are only as good as the context and infrastructure you give them.
Engineering Productivity at Scale
@destraynor shared a thread from Intercom CTO @darraghcurran claiming they 2x'd R&D productivity in 9 months, with "receipts." The quoted tweet sets the stage: "9 months ago we publicly committed to 2x the productivity of our R&D org at Intercom. It was scary. It wasn't always clear we'd pull it off. We hit it with 3 months to spare. In fact, looking back 16 months, we've 3x'd."
Meanwhile, @ryanlpeterman resurfaced an interview with @bcherny discussing the concept of "latent demand" in product development. The insight is that you should design products hackable enough that users abuse them, then build features around the abuse patterns. It's a useful mental model for anyone building AI tools right now: watch what users do with your product that you didn't intend, and build around that.
Open Source Tooling
Two notable open-source releases rounded out the day. @lateinteraction RT'd @joshclemm announcing Witchcraft from Dropbox: "a local search engine built in Rust with no API keys or vector" databases required. And @liu8in introduced HyperFrames, an HTML-based video toolchain that lets AI agents edit video. The tagline "Agentic Video is HTML" captures the approach: represent video in a format agents already understand. Both projects reflect the broader trend of building AI-native tools that strip away unnecessary complexity.
Platform Moves
@ivanburazin highlighted Salesforce's "Headless 360" announcement, where @Benioff declared: "No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI." This is significant because it signals enterprise platforms adapting to an agent-first world where the browser is no longer the primary interface. Combined with Slack's Block Kit upgrade adding data tables and charts for agent UIs, the message is clear: platforms are rebuilding their surfaces for AI agents, not just human users.
Sources
I
Vercel just leaked their internal code review bot.
It's called OpenReview and it turns @openreview into a Claude-powered reviewer that lives directly inside your GitHub PRs.
Not a SaaS. Not a subscription. Self-hosted, open source, and deployed in one click.
Here's what it does the moment you mention it:
→ Spins up an isolated Vercel Sandbox and clones your repo on the PR branch
→ Runs your actual linters, formatters, and tests not a static scan
→ Posts inline comments with GitHub suggestion blocks for one-click fixes
→ Commits and pushes formatting and lint fixes directly to your branch
→ Cleans up the sandbox when it's done
You control the instructions:
"@openreview check for security vulnerabilities"
"@openreview run the linter and fix any issues"
"@openreview explain how the authentication flow works"
React 👍 on any suggestion to apply it. React 👎 to skip. No dashboard. No UI to learn. Everything happens in the PR thread you're already in.
Powered by Claude Sonnet 4.6. Built on Vercel Workflow for resumable execution. Five env variables to configure.
100% Open Source. MIT License.
https://t.co/X7VCNGGEQx

V
❤️🔥 Just Recorded a 16 min Tutorial on How to use Gemini 3.1 + Seedance 2.0 Build Cinematic $10k Websites (step-by-step)
You can now build stunning marketing sites fully with AI https://t.co/nzAakFCFeE
R
Boris Cherny (Creator of Claude Code): "Latent demand is the single most important principle in product, especially in Facebook's successful products. Every single one has an element of latent demand.
For example, Marketplace. It came from this observation that if you looked at Facebook groups at the time, 40% of the posts were buying and selling stuff. Facebook groups were not designed for commerce, but that's what people were using it for.
It's kind of cool. Like, you design this product in a way that can be hacked. It can be abused by users a little bit, and then you look at the data, you see how they're abusing it, and then you build a product around it.
I think Facebook dating was pretty similar. I think the observation was something like 60% of profile views were people of the opposite gender that were not friends with each other, kind of like creeping on each other.
The principle in product is you can never get people to do something they do not yet do. You can find the intent that they have, and then you can steer it to let them better kind of capitalize on that intent." @bcherny

R
ryanlpeterman
@ryanlpeterman
Boris Cherny ( @bcherny ) created Claude Code, but few know his full career story. Today I'm sharing an interview with him about how he grew as an engineer, we discussed: • Why every engineer needs "side quests" • Why being under leveled is a good thing • The story behind his growth to Principal (IC8) at Meta • Technical book that had the biggest impact on him as an engineer • The most important principle in product engineering • Claude Code stories & competition in AI coding products You can find the full episode here: • YouTube: https://t.co/Y89OzxqBC0 • Spotify: https://t.co/Q2JTgOJmDt • Transcript: https://t.co/Kda7TFOjHd • Apple: https://t.co/CN9FSyPSII
T
I think the top tip I've picked up since I started using Claude Code: write a CLAUDE [dot] md at every level of your file structure and be intelligent about how you nest folders.
Claude Code automatically loads the Claudemd file from every directory level above whatever file you're working on. So if you organize it intelligently, it always has the right context at the right time.
Say you're running a business and doing some marketing work. You might have:
- A general CLAUDEmd on your computer — how you like Claude to work, voice, tools you have wired up
- A vault CLAUDEmd — how your files are organized
- A folder for your business with a CLAUDEmd — what the business does, who the clients are, how you price, etc.
- A folder for marketing inside the business with a CLAUDEmd — channels you run, what's working, brand voice, etc.
- The specific marketing project with its own CLAUDEmd
When you open anything in the marketing project folder, Claude Code walks up the tree and pulls all five into context automatically. Global → vault → business → marketing → project. That means the very first message in a chat about that marketing project is going to be like talking to someone that knows you, your business, your marketing history, etc.
You need to keep the CLAUDEmd at each level current for this to work
I have a "wrap" skill that I run at the end of every chat session. It updates the relevant CLAUDEmd(s) and makes a more detailed entry into a workbench file for whatever I was working on.
So if I make a decision about a project or learn something about a client, that context lives in the right file by the time I close the session. Next time I come back, Claude already has it.
Starter repo for this kind of setup: https://t.co/m78XGeG7ii
I built a little mini-extension for the workbench structure I use: https://t.co/dKQPab0EJv
N
Official Claude Dev X Account
C
ClaudeDevs
@ClaudeDevs
For the developers building with Claude, a direct line from the team. Follow for changelogs, API releases, community updates, and deep dives. https://t.co/SaH9KlMJ0z
0
STANFORD HAS A 1-HOUR LECTURE ON AGENTIC AI THAT COVERS EVERYTHING BEHIND AUTOMATION SYSTEMS THAT ACTUALLY WORK.
WORTH WATCHING BEFORE YOU BUILD ANYTHING.
https://t.co/fgA82uS47O

A
In 14 minutes, this Anthropic engineer who wrote "Building Effective Agents" will
teach you more about building them right than most developers figure out on their own
in months.
Bookmark this for the weekend. Then read the builder's guide below. https://t.co/CETWlp7qjm

A
Av1dlive
@Av1dlive
AI Agent Stack Everyone Must Use in 2026 (Builder’s Guide)
B
Opus 4.7 feels more intelligent, agentic, and precise than 4.6. It took a few days for me to learn how to work with it effectively, to fully take advantage of its new capabilities.
Will post a few more tips throughout the day, starting with this blog post: https://t.co/XQrH8P28yo
D
🚨Here's a must read🚨
We 2x-ed our productivity in Intercom in 9 months.
Our CTO @darraghcurran shares all the gory details, charts, costs, and more in this thread
D
darraghcurran
@darraghcurran
9 months ago we publicly committed to 2x the productivity of our R&D org at @intercom. It was scary. It wasn't always clear we'd pull it off. We hit it with 3 months to spare. In fact, looking back 16 months - we've 3x'd. Here's what actually happened (with receipts): 🧵 https://t.co/vYGlGnVOGB
B
Agentic Video is HTML: Open Sourcing HyperFrames
Agentic Video is HTML: Open Sourcing HyperFrames
AI agents can write, can code, can talk, and operate autonomously — but they still cannot edit videos — now they can. Today we're open-sourcing HyperF...
G
The hardest thing about agents and backends is durability. @workflowsdk fixes this.
That LLM you're calling *will* go down. That service *will* rate limit you. That database *will* unexpectedly slow down. You *will* get paged 💀
I've been looking for a unicorn for a decade. I wanted the level of reliability of combining stuff like SQS / Kafka / microservices, and I absolutely did not want *that* at the same time 😂
Truly reliable systems like that are notoriously difficult to reason about, to develop locally, to test, to simulate, to deploy… Workflow SDK solves that without compromises.
We're doing what Next.js did for the frontend, but for one of the most important problems of the new generation of backend applications.
Notably, Workflow SDK has an incredible self-hosting and multi-cloud story from day 0. We've taken amazing lessons from Next.js and poured them into the many Worlds (adapters) you can deploy to.
Congrats to Pranay and the Workflow team on a generational ship: https://t.co/ub7vQ7L6yE
V
vercel
@vercel
Vercel Workflows is GA. Your code is the orchestrator. Ship agents, backends, or any long-running process without managing queues, retries, or workers. https://t.co/l9hZe79rNz
O
RT @joshclemm: Open sourcing something fun from @Dropbox: Witchcraft.
It's a local search engine built in Rust with no API keys or vector…
J
5 steps to making codex your chief of staff
1. download the desktop app
2. install the plugins you need for work
3. paste this into a thread and pin it
4. ???
5. monitor the situation
https://t.co/6ioazy9xvb
K
How we build internal agents at Browserbase
How we build internal agents at Browserbase
TLDR; Generalized agents will become the interface for knowledge work and the browser is the universal “API” for everything that doesn’t expose one. W...
P
For anyone curious about the monothread future we're hurtling towards!
Exact tips, prompts, and inspiration examples on how to automate your life & work with Codex.
N
nickbaumann_
@nickbaumann_
My Codex threads are alive
V
Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
W
a few days ago I did a video about Anthropic using some "forbidden techniques" to train the latest Claude models.
here's that video in case you haven't seen it.
in the newly released Opus 4.7 System Card, there is a line where Claude Mythos Preview basically says "I won't complete the task you requested unless you disclose that you used this training technique"...
this video gives a bit of a background of why these techniques are
forbidden"
0
Breakthroughs:
1. Turboquant merged into vLLM 75% vram reduction for kvcache near losslsss
2. Someone merged M2.7 & M2.5 & got it to perform better than M2.7
3. 40% faster prefill on AMD strix halo (128gb for MoEs w 10B active params)
4. Megatrain 100B model trained on 1 GPU
M
oh shit… tables in Slack!
I’m more excited about this than Opus 4.7
S
SlackHQ
@SlackHQ
First up: Block Kit just got a major upgrade. 🎨 5 new components: Card, Alert, Carousel, Data Table, and Chart. Build high-density, interactive agent UIs — no custom code needed — that renders natively on desktop and mobile. Your agents can now show their work, without huge walls of text.
E
People oddly assumed that I didn’t understand LiDAR, even though I oversaw the custom LiDAR development that Dragon uses to dock with the Space Station
B
brivael
@brivael
Aujourd'hui grosse discussion avec mes ingés (chez Argil) sur pourquoi Elon a viré le LIDAR de ses voitures autonomes. Choix radical, moqué pendant des années, et comme d'hab il avait raison depuis le début. Le LIDAR c'est un laser qui balaye l'environnement et crache un nuage de points 3D. Sur le papier tu obtiens la géométrie exacte du monde. Dans la vraie vie c'est une verrue technologique collée sur le toit parce qu'on sait pas faire mieux avec la vision seule. Problème numéro un : ça rajoute une modalité dans le training du modèle. Ton réseau doit apprendre à fusionner vision + lidar + radar + ultrasons. Chaque capteur en plus c'est une source de désaccord à arbitrer, pas une source d'info supplémentaire. Sensor fusion artisanale = dette technique permanente. Problème numéro deux, la bitter lesson de Rich Sutton : scaler le compute sur une seule modalité bat systématiquement les architectures bricolées à la main. Tesla a dropé le radar, puis les ultrasons, est passé full end-to-end vision. Leur courbe sur les edge cases s'est accélérée APRÈS, pas avant. Waymo fait l'inverse et reste stuck en ops géofencée. Problème numéro trois, le plus fondamental : le LIDAR voit la géométrie, pas la sémantique. Il sait qu'il y a un truc, pas ce que c'est ni ce que ça va faire. Les derniers 9 de fiabilité sont des problèmes de cognition, pas de perception brute. Un capteur de plus résout rien, il ajoute du bruit. Sébastien Loeb balance une 208 T16 à 180 dans un chemin boueux corse sous la pluie avec zéro LIDAR. Deux yeux, un cerveau. L'évolution a donné des yeux aux prédateurs pendant 500 millions d'années, pas des lasers. Il y a une raison. Le LIDAR c'est l'équivalent du marxisme appliqué à l'économie. Une solution planifiée, centralisée, qui prétend modéliser explicitement ce qui doit émerger d'un système distribué et adaptatif. Tu remplaces l'intelligence par de la mesure, la compréhension par de la donnée, l'émergence par le contrôle. Ça rassure les ingénieurs qui veulent tout spécifier en amont, exactement comme la planif rassurait les économistes soviétiques. Et ça échoue pour les mêmes raisons : la réalité est trop riche pour être capturée par un capteur, comme elle est trop riche pour être capturée par un plan quinquennal. La vraie intelligence, celle de Hayek comme celle de Tesla, c'est de faire confiance à un système qui apprend de l'expérience plutôt que de tout pré-encoder. L'élégance d'une solution c'est son rapport signal sur complexité. Le LIDAR explose le dénominateur. Défendre le LIDAR en 2026 c'est préférer empiler des hacks plutôt que résoudre le vrai problème. C'est de la feignasserie intellectuelle maquillée en rigueur d'ingénieur. Les mêmes gens qui défendaient les systèmes experts en 2012 contre le deep learning. Ils finiront pareil. Never bet against end-to-end. Never bet against la simplicité. Never bet against Elon.
E
Universal HIGH INCOME via checks issued by the Federal government is the best way to deal with unemployment caused by AI.
AI/robotics will produce goods & services far in excess of the increase in the money supply, so there will not be inflation.
I
This is the future of SaaS.
Thanks @Benioff for leading the way here. Hopefully the rest of the industry follow suit.
B
Benioff
@Benioff
Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless 360. Faster builds, agentic everything. 🚀 #Salesforce #Agentforce #AI https://t.co/mxySdJS7HR
K
Yeah it's over. China is going to win the chip wars
C
cnxsoft
@cnxsoft
Allwinner A733 octa-core Cortex-A76/A55 SBC in Raspberry Pi Zero form factor. https://t.co/M6LvMLLT6B The @orangepixunlong Orange Pi Zero 3W features up to 16GB LPDDR5 RAM, a microSD card slot for storage, plus eMMC flash and UFS footprints, a mini HDMI port, two USB-C ports (one with DP 1.4), a MIPI DSI LCD connector, two MIPI CSI camera connectors, and a 40-pin GPIO header. The company will release Orange Pi OS (Arch), Debian, Ubuntu, and Android images for the board. Price starts at just $25 with 1GB of RAM.
E
my tidbits on getting the rtx pro 6000 blackwell.
my tidbits on getting the rtx pro 6000 blackwell.
Picked up an RTX PRO 6000 Blackwell Workstation GPU this morning. 96 GB, sm_120, one card in one slot. Writing this for anyone on the fence, because I...
E
RT @sdmat123: Opus 4.7 has broken adaptive reasoning.
I blew my 5-hour quota finding the best way to mitigate this. Add to your profile/in…
S
if you run local ai on a mac and you don't follow @ivanfioravanti , you're missing out. he is the mlx data guy, consistently first with real benchmarks on apple silicon, no marketing, no vibes, just raw numbers.
qwen 3.6 dropped less than 24 hours ago and ivan already has M5 Max running it at 121 tok/s single request and 550 tok/s on batch 32. that's the kind of coverage that takes a community, not one person.
i run nvidia and consumer gpu benchmarks. ivan runs apple silicon. different lanes, same mission, finding the best local setup for every builder regardless of what hardware you bought.
if you're a mac user and you only follow me for local ai data, you're leaving half the picture on the table. go follow.
I
ivanfioravanti
@ivanfioravanti
@sudoingX @dreamworks2050 M5 Max using MLX 🔥 - 3323/121 tps single request - 4810/550 tps batch 32 requests