Claude Code Dominates the Conversation as Cloudflare Ships Browser Run and Memory Systems Get Smarter About Forgetting
Today's feed was dominated by Claude Code discourse, from Team OS deployments at DoorDash to scathing desktop app reviews from @theo. Alongside that, agent infrastructure moved forward with Cloudflare's Browser Run launch, Modal's Anthropic acquisition reveal, and a push for self-pruning memory graphs that finally treat forgetting as a feature.
Daily Wrap-Up
The through-line today is that the tools everyone is building agents around are growing up in public, with all the awkwardness that implies. Claude Code showed up in nearly every other post, sometimes as the vehicle for ambitious team infrastructure and sometimes as a punching bag for its shaky desktop app. Cloudflare rebranded Browser Rendering into Browser Run with live views and human-in-the-loop controls, Modal revealed an Anthropic acquisition, and a quiet but important conversation emerged around LLM verifiers getting better at finer-grained scoring. It was less a day of launches and more a day of people measuring what the last six months of agentic infrastructure actually amounts to.
A notable tension ran underneath everything: the split between people who want to scaffold AI work with heavyweight specs, domain models, and bounded contexts, and those who insist the whole point of this moment is tighter feedback loops. @allenholub spent a long thread tearing into spec-based development as warmed-over waterfall, while @mattpocockuk made the opposite case that Domain-Driven Design might be the answer to every agent alignment problem. Meanwhile @aakashgupta documented how a single PM at DoorDash spent 1,500 hours in Claude Code and turned it into team-wide leverage, and @theo catalogued 40 bugs in the Claude Code desktop app in under an hour. You can hold both at once: the infrastructure is genuinely transformative and also unmistakably half-baked.
The most entertaining moment of the day came from @tszzl, who confessed that "clankers" made his taxes harder, not easier, prompting @doodlestein to point at his own 158-file, 2.7-megabyte tax preparation skill as the response. The most practical takeaway for developers: stop treating your AI coding setup as a personal productivity hack and start investing the 30 days needed to turn it into shared team infrastructure, with metrics, SQL, and playbooks checked into a repo every function can self-serve from.
Quick Hits
- @mattpocockuk pitched Domain-Driven Design as a universal fix for model confusion, codebase sprawl, and lost decision context.
- @LaubRebecca teased a stealth launch with @michaelblhssn, framing emotional intelligence as the next commoditization frontier after IQ.
- @mkurman88 posted a 5x-speed video of a coding harness he claims he hasn't touched since Monday.
- @zeeg noted that
CLAUDE_CODE_AUTO_COMPACT_WINDOW=400000is going into his dotfiles, courtesy of a tip from @trq212. - @0xSero celebrated his REAP variants of Gemma 4 topping Terminal-Bench 2.0 in a small run shared by @vicnaum.
- @doodlestein linked a Skill.md issue in reply to @tszzl's tax automation lament.
- @hyperindexed asked whether anyone is still writing AI evals by hand, pointing to Palantir's AI FDE demo.
Claude Code as Team Infrastructure (and Growing Pains)
Claude Code was the single most discussed product today, and the conversation split cleanly between ambitious deployment stories and pointed quality complaints. On the ambitious side, @aakashgupta broke down how @hannahstulberg spent over 1,500 hours inside Claude Code at DoorDash and concluded that the real leverage wasn't personal productivity at all. The argument is that shared repos beat individual speedups by a wide margin once you force every team function through the same infrastructure.
> "One PM. 30 days of setup. Then that PM supports 20+ people without being the bottleneck on any of them... Step 8 is the enforcement mechanism that makes the whole system durable. No feature launches until metrics, queries, schemas, dashboards, and playbooks are checked in."
On the opposite end, @theo unleashed a frustrated post-mortem on the Claude Code desktop app, claiming he found "at least 40 [bugs] in under an hour" and that "any one of these issues would have been enough for me to do a massive post-mortem and likely fire someone." @ryanlpeterman shared a clip of Claude Code creator @bcherny recommending Functional Programming in Scala as the one book that changed how he codes, arguing type signatures matter more than the code itself. Put together with @zeeg's dotfile tweak to expand the autocompact window to 400k tokens, the picture is of a product that power users are actively reshaping around while simultaneously losing patience with its rough edges. The people doing Team OS work are buying a bet that the surface issues get fixed before the abstraction wins run out.
Agent Infrastructure Gets Concrete
Several posts converged on the theme that agent infrastructure is finally moving from demos to durable platforms. @MikeNomitch_CF called it a "massive day for Browsers on Cloudflare" as Cloudflare rebranded Browser Rendering into Browser Run, shipping live agent observation, human-in-the-loop handoff, CDP integration for Claude Code and Codex, and 4x higher concurrency limits. @erikdunteman finally got to talk about @modal's acquisition, sharing @akshat_b's demo of an ML research agent that spins up GPU sandboxes, runs subagent pools, persists memory, and snapshots state for fork and resume, all playing Parameter Golf in the background.
> "Browser Rendering is now Browser Run, with Live View, Human in the Loop, CDP access, session recordings, and 4x higher concurrency limits for AI agents."
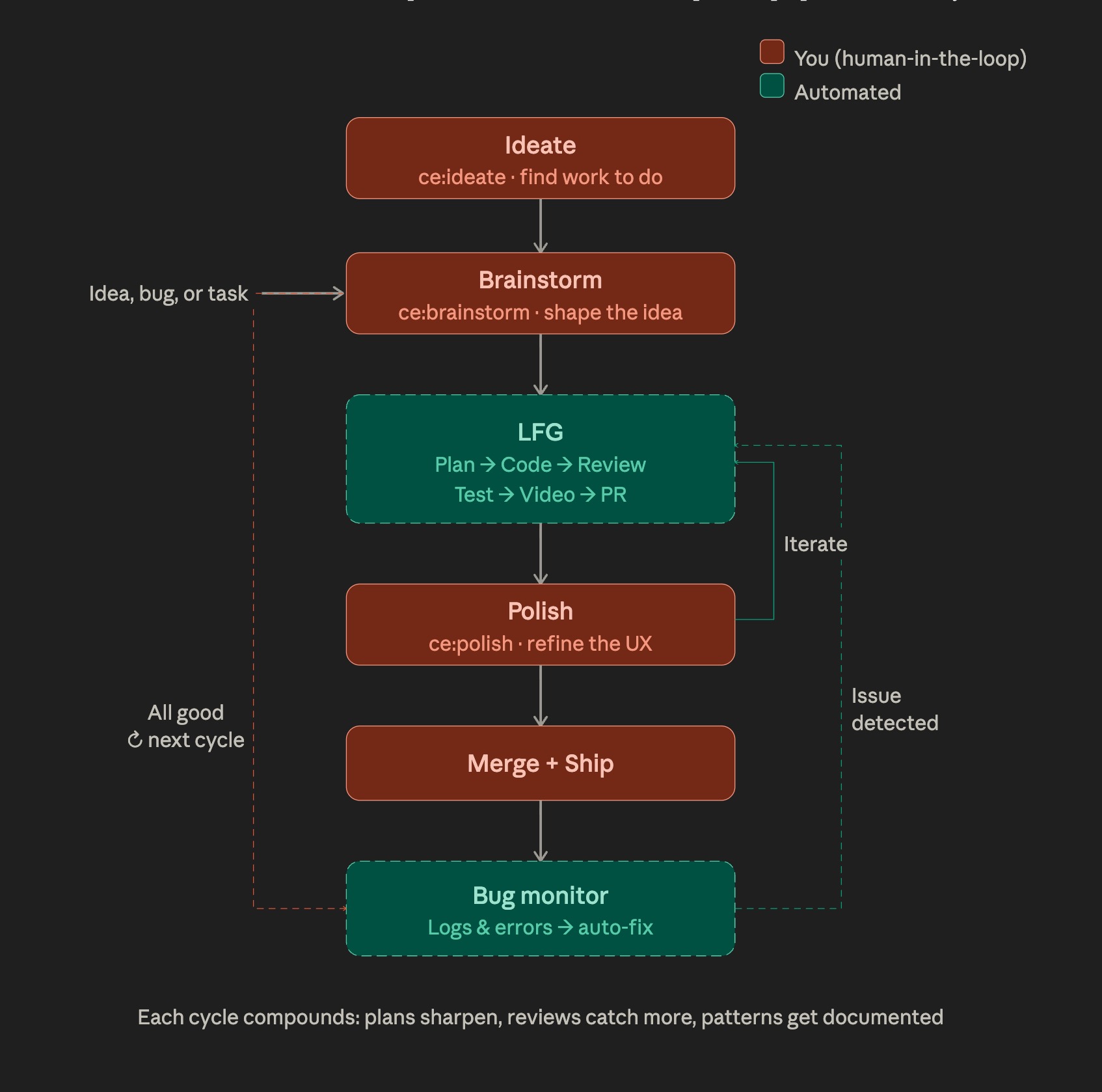
@kieranklaassen added a philosophical frame to where humans actually belong in these systems, arguing from his work on Cora that only two moments genuinely require human attention:
> "Building Cora, I found two moments where humans belong in the loop: Brainstorm (what to build) and Polish (is it actually good?). Everything else – plan, code, review, test, PR – is automated."
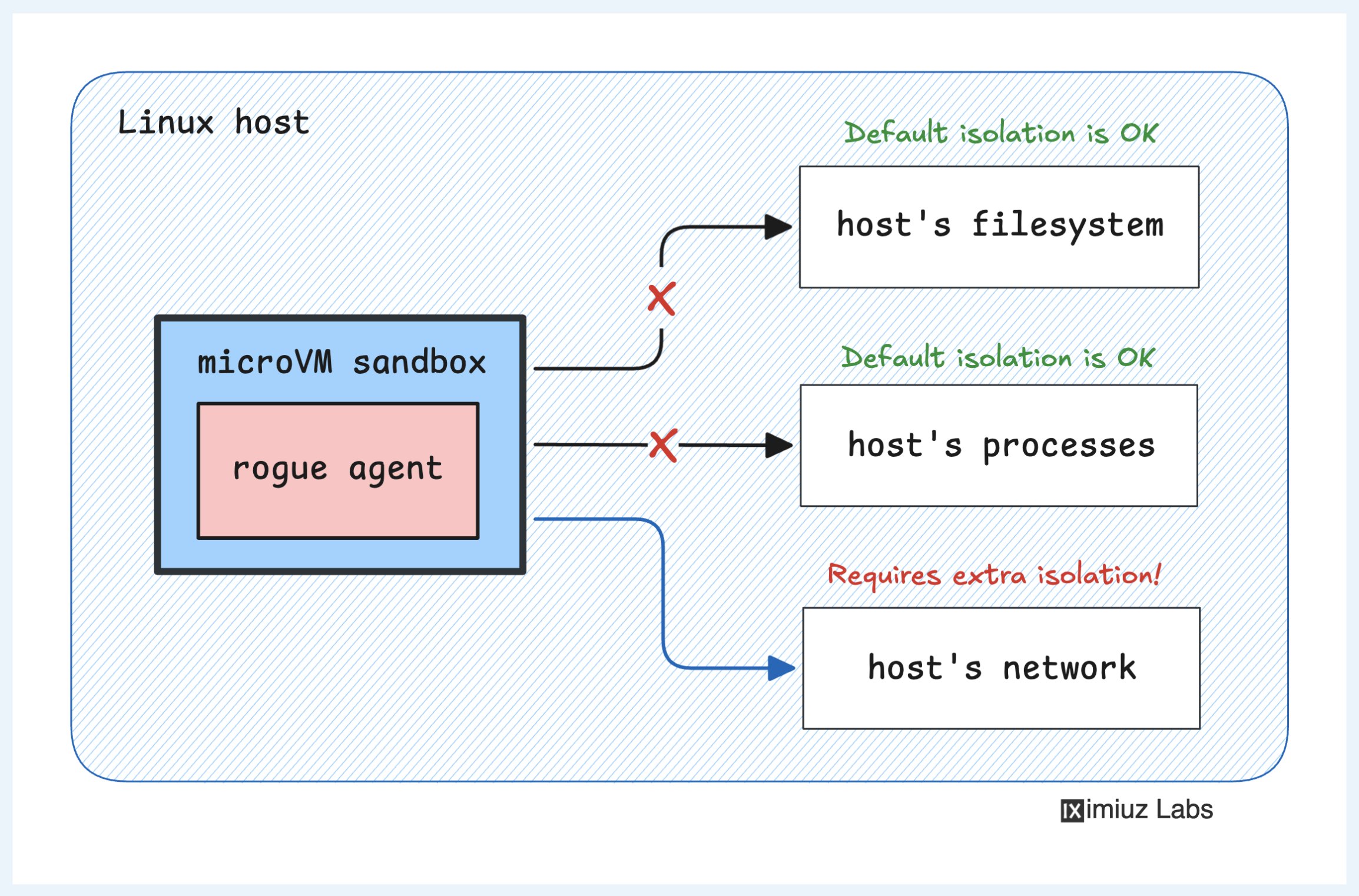
That pattern, agents handling the middle and humans bookending the work, dovetails neatly with Cloudflare's new live view and handoff features. The platforms are explicitly making room for the kind of selective human oversight that @kieranklaassen is describing, rather than pretending autonomy is an all-or-nothing setting. @iximiuz provided a sobering counterpoint with a breakout example showing that even a "strong" microVM sandbox like Firecracker isn't automatically safe for agent workloads, which suggests the next round of infrastructure work is going to be as much about isolation guarantees as it is about capability.
Memory, Verification, and the Science of Forgetting
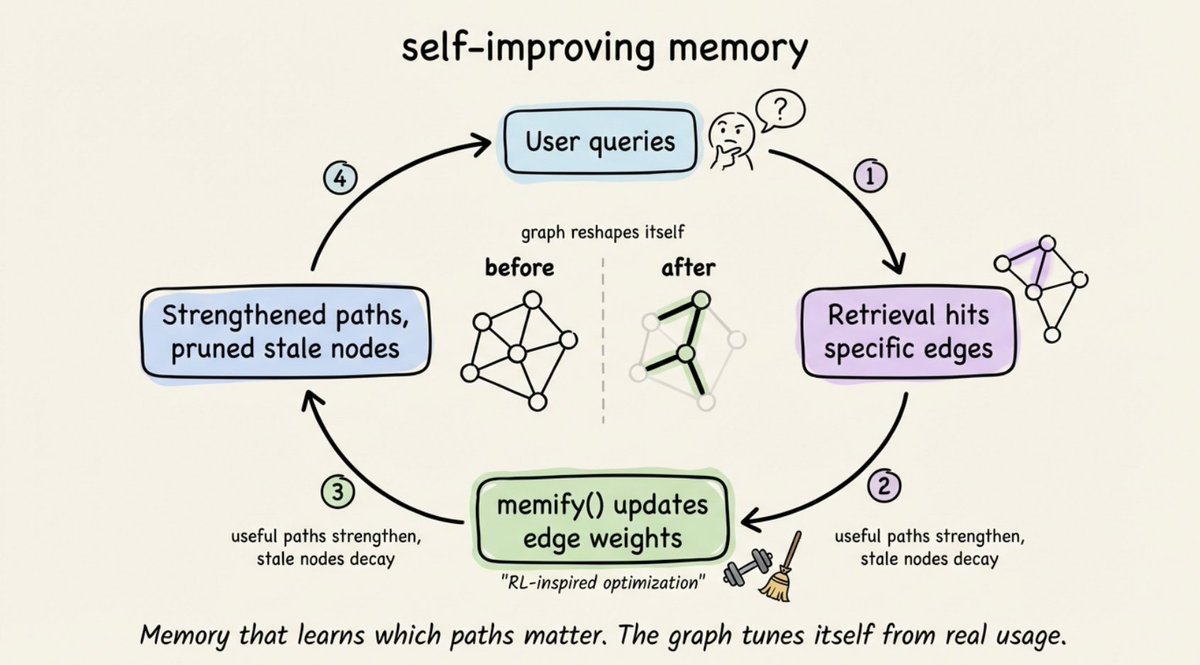
A quieter but substantive thread ran through posts about how agents evaluate and remember. @akshay_pachaar's long writeup on Cognee made the case that ingestion-heavy memory systems miss the point: "A memory that never forgets isn't actually useful. Stale nodes and unused connections pile up over time, and retrieval gets noisier." His proposed fix, memify(), runs an RL-inspired optimization pass over a knowledge graph, strengthening edges that led to good answers and letting unused ones decay.
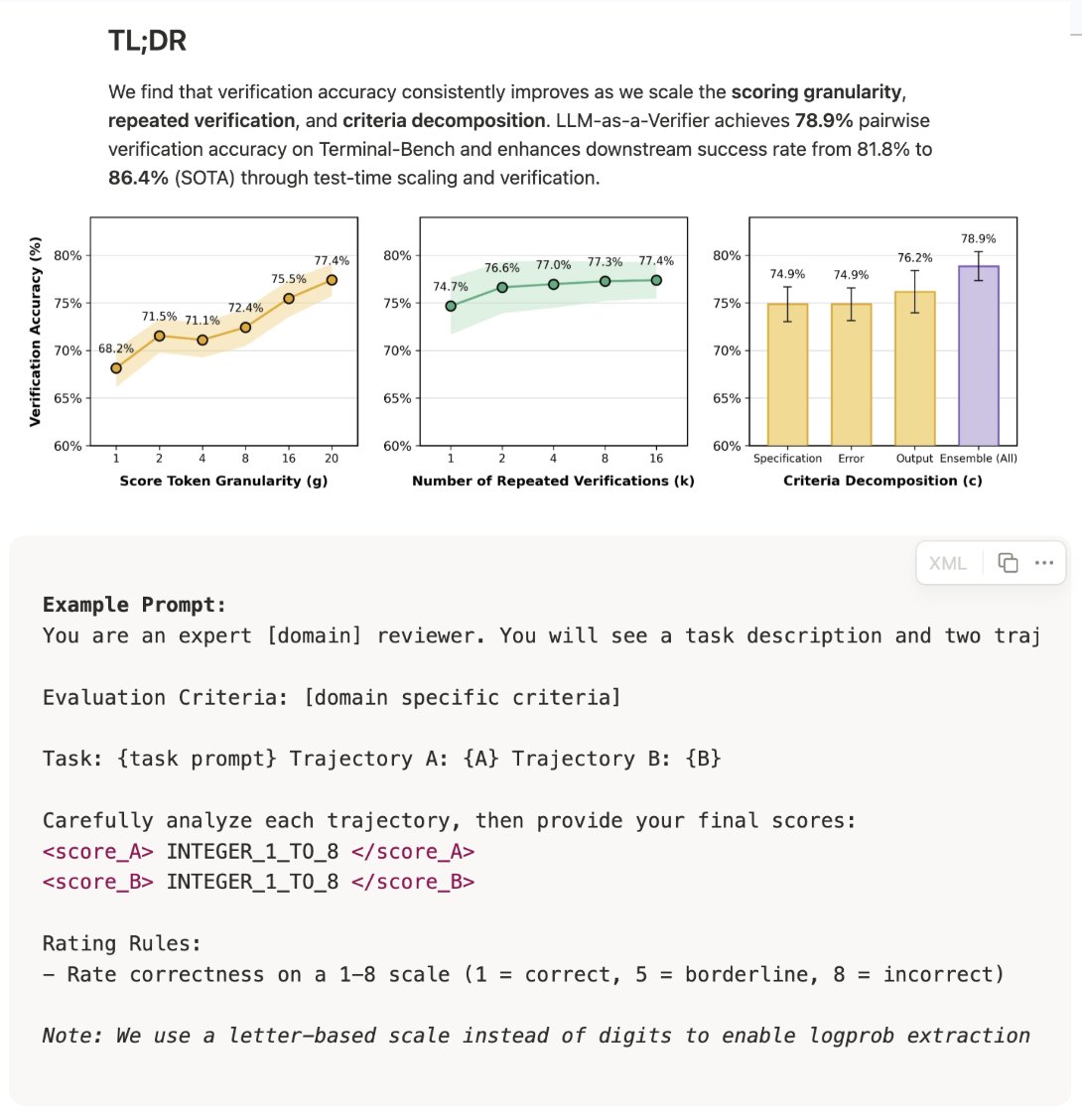
@cwolferesearch dug into a related shift on the verification side, noting that LLM-as-a-Verifier work now shows increasing scoring granularity actually improves verifier accuracy, reversing a hard-won best practice from only a year or two ago.
> "LLM-as-a-Judge best practice was that lower scoring granularity (e.g., binary, ternary, or 1-5 Likert score) worked way better than granular scores... It seems like recent frontier LLMs now are better at scoring at finer granularities, making this best practice (potentially) obsolete."
Taken together with @_avichawla's deep dive on prompt caching (citing a 92% cache hit-rate at Claude), the theme is clear: the surrounding stack around raw LLM inference is getting smarter, more self-regulating, and more empirical. Memory prunes itself, verifiers tune themselves across granularity, repeated verifications, and criteria count, and caches reshape how much of the conversation needs to be resent on every turn. None of this is the glamorous part of AI, but it's where the compounding efficiency gains actually live.
Process Wars: Specs, DDD, and Incremental Delivery
The methodology debate flared up today with unusual sharpness. @allenholub went full broadside on spec-based development, calling it "nothing but a fancy way to describe a phase-gated waterfall" and arguing the irony is that AI should make incremental delivery easier, not harder.
> "The real advantage of AI-assisted development is that it tightens the feedback loop and enables incremental development. Why would anybody throw away that advantage and revert to a half-century-old way of working that has been proven ineffective?"
@mattpocockuk took the opposite tack, leaning into structure as the answer to agentic chaos, arguing that shared language fixes misaligned models, bounded contexts rescue massive codebases, and ADRs preserve decision context that agents otherwise keep re-litigating. These positions look contradictory but probably aren't. Holub is arguing against a monolithic upfront spec as a contract to hand to either humans or AI; Pocock is arguing for the kind of ambient architectural vocabulary that makes small increments legible. The real practical question is whether teams can get the DDD-shaped scaffolding without sliding back into the waterfall posture Holub describes. @rauchg's observation that every team can now build its own "design factory" using Claude Code, Three.js, and Next.js gestures at a middle path: tight feedback loops running inside well-named, well-bounded contexts that the agents can actually navigate.
Open-Source Agents and Internal Tools
A handful of posts captured the accelerating DIY energy around purpose-built agents. @ashpreetbedi announced a post and an open-source data agent, noting that "OpenAI, Vercel, Uber, LinkedIn, Salesforce, DoorDash are all building data agents" and inviting people to clone, run, and query from Slack. @rauchg used the launch of @basementstudio's Shader Lab, built on Claude Code, Three.js, Next.js, and Vercel, to make a broader point about the shift in procurement logic: "It's now easier to generate software re-assembling powerful building blocks, than searching and procuring the right SaaS for the job."
@doodlestein's 2.7-megabyte tax preparation skill, which he actually used to file his own return with the Aiwyn MCP tax connector and Playwright MCP, may be the most extreme example of this trend. What used to be the domain of specialized SaaS is now shippable as a markdown bundle inside a general-purpose agent harness. That doesn't mean it's easy, as @tszzl's rueful note that "clankers" made his taxes harder, not easier, makes clear. The emerging pattern is that deeply specified skills built by practitioners beat both greenfield agents and off-the-shelf SaaS, provided someone is willing to do the 158-file, multi-day grounding work that @doodlestein's tax skill represents. Internal tool factories are real, but they still run on somebody's hard-won expertise.
Sources
Forward deployed engineering is no longer limited to humans. At DevCon 5, Palantir Software Engineers Ankit Shankar and Colton Rusch demonstrate new AI FDE capabilities to write AIP Logic functions, author evals, and safely debug in a branch-aware, continuous loop. https://t.co/nivSbqkOZZ

Boris Cherny ( @bcherny ) created Claude Code, but few know his full career story. Today I'm sharing an interview with him about how he grew as an engineer, we discussed: • Why every engineer needs "side quests" • Why being under leveled is a good thing • The story behind his growth to Principal (IC8) at Meta • Technical book that had the biggest impact on him as an engineer • The most important principle in product engineering • Claude Code stories & competition in AI coding products You can find the full episode here: • YouTube: https://t.co/Y89OzxqBC0 • Spotify: https://t.co/Q2JTgOJmDt • Transcript: https://t.co/Kda7TFOjHd • Apple: https://t.co/CN9FSyPSII
gm, today we're launching Shader Lab, like photoshop but for shaders • design slick layered shader compositions • export high-quality assets or shaders • OSS package to plug & play ↳ https://t.co/5FjvLy8UIQ https://t.co/9FSvad3TS2
Browser Rendering is now Browser Run, with Live View, Human in the Loop, CDP access, session recordings, and 4x higher concurrency limits for AI agents. https://t.co/uVsYYLhsRN
IQ is dead. Intelligence has been commoditized. I spent 5 years designing iPhones at @Apple most recently the iPhone 17 Pro enclosure. I learned what it means to be obsessive about every detail, leave no stone unturned, and still ship 100 million devices a year. Then I walked away. For the last decade I've been obsessed with one question: can human emotion be scientifically understood and measured? We're living in the noisiest era in history. Understanding what you feel, and why, has never been harder or more valuable. Here's what most people miss: we regulate through each other. We connect to feel, and we feel to create. The future belongs to those who are emotionally intelligent. I'm going all in on technology that makes self-awareness tangible and uses it as a stepping stone for humans reconnecting. Just joined @ycombinator P26. Coming out of stealth soon. Some will think it's crazy. Some will feel it immediately. If you see it too and you're in SF, let's talk?

Every team at your company should be creating their own 'Team OS' in Claude Code on Github. Here's how: 1:45 - What is a Team OS 13:37 - Shared skills and commands 25:24 - Shared team automations 59:50 - The learning flywheel https://t.co/KyZ3WsMrLB
To show off what you can do with @OpenAI Agent SDK + @modal, we built an ML research agent (inspired by @karpathy). It can: - Spin up GPU sandboxes of any shape - Run a pool of subagents - Persist memory - Snapshot state for fork/resume Here it is playing Parameter Golf: https://t.co/r7QhvNmdEq
With my modest 5-task run of Terminal-Bench 2.0 on 13 different models - all REAP variants of Gemma 4 by @0xSero are best again! Even beating the original Gemma lol. Also the fastest, even compared to the smallest models. I'm honestly impressed! https://t.co/m0tqvazsir

Well, it's probably coming too late for most people unless you're planning on filing an extension, but I created a truly ambitious skill for tax preparation on my skills site, https://t.co/Un9brY2G3l This skill spans 158 markdown files totaling 2.7 megabytes of text. It covers every state, tons of different professions, life events, and all sorts of sophisticated tax strategies, with all kinds of expertise about even niche topics like opportunity zones and captive insurance. Much of the underpinnings of it, including the nuts-and-bolts use of the Aiwyn MCP tax connector and the use of https://t.co/kxK2ZKXoly with Playwright MCP, is based on my actual multi-day session history preparing and filing my own fairly complex return, so I know it all works (I just finished filing mine a few hours ago). Here's how GPT 5.4 describes it and what makes it special: The "tax-return-preparation-and-advice-generic" skill is a source-verified, multi-year tax intelligence skill that turns AI from a glorified form-filler into a high-end tax strategist. It helps analyze returns across years, detect missed deductions and carryforwards, reconcile life events and profession-specific rules, model aggressive but defensible planning moves, and ground recommendations in current law instead of stale tax folklore. The result is a tax-prep and tax-planning system that is broader than software, more systematic than a one-off CPA review, and dramatically more useful for complex real-world filers. What makes it special: - It is multi-year by design. Most tax tools look at one return; this skill looks for patterns, carryovers, inconsistencies, and missed opportunities across years. - It is verification-first. The methodology is built around checking current IRS instructions, publications, and state guidance before making live filing claims. - It is aggressively practical. It does not stop at “here are the rules”; it pushes toward elections, timing moves, entity choices, depreciation strategies, retirement optimization, PTET, QBI, and other real savings levers. - It is unusually universal. It routes by profession, life event, situation, and jurisdiction, so it can adapt to freelancers, high earners, retirees, students, business owners, rental investors, divorce, inheritance, relocation, and more. - It is audit-aware. It emphasizes documentation, defensibility, and red-flag detection instead of encouraging sloppy “tax hacks.” - It is built for real execution. It includes filing workflows, tool guidance, and structured reference material, so an agent can move from analysis to action rather than just giving vague advice.
You can also set your autocompact threshold yourself and effectively lower your context window if you'd prefer. For example, 400k context is a good compromise: CLAUDE_CODE_AUTO_COMPACT_WINDOW=400000 claude see docs here: https://t.co/NuhBuTSSDt
Prompt caching in LLMs, clearly explained
A case study on how Claude achieves 92% cache hit-rate Every time an AI agent takes a step, it sends the entire conversation history back to the LLM...
Build Agents that never forget