OpenAI Ships GPT-5.4-Cyber for Binary Exploit Scanning as Pipecat Hits 1.0 and Agent Memory Goes Three-Dimensional
OpenAI's new cybersecurity-focused model can find exploits in compiled binaries without source code, raising both defensive capabilities and new attack surface concerns. The agent ecosystem matures with Pipecat reaching 1.0, multi-agent orchestration frameworks emerging, and a compelling argument for three-dimensional agent memory. Meanwhile, developers continue pushing Claude Code into unexpected territory from prediction market bots to game development.
Daily Wrap-Up
The most consequential announcement today isn't about making AI faster or cheaper. It's about making it dangerous on purpose. OpenAI's GPT-5.4-Cyber is a model explicitly fine-tuned to find software exploits, and it can do it on compiled binaries without ever seeing source code. That's a genuine paradigm shift in security research, and the tiered access system where "verified defenders" get a more permissive model than the public raises all sorts of questions about who gets to wield these tools. On the builder side, the agent infrastructure layer is quietly solidifying. Pipecat hitting version 1.0 after two years of development, Cognee offering three-dimensional agent memory, and Aurogen forking OpenClaw with proper multi-agent orchestration all point to the same thing: we're moving past the "can AI do X?" phase and into "how do we architect reliable systems around AI?"
The vibe coding movement continues to blur the line between professional development and weekend tinkering, with game developers using Codex for procedural generation and Superblocks 2.0 explicitly positioning itself as the enterprise answer to shadow AI development. Chamath's Software Factory walkthrough and the design agency pivot described by @abnux both tell the same story from different angles: the unit of work in software is changing from "lines of code" to "systems that generate code." Anthropic quietly shifting Claude Enterprise to usage-based billing suggests they're seeing exactly this kind of heavy, automated usage pattern and pricing accordingly.
The most entertaining moment goes to @luaroncrew, who won an RTX 5090 at a Mistral hackathon by training an image generation model to do technical analysis on trading charts, only to realize he uses a MacBook and has no desktop to put the GPU in. It's a perfect metaphor for 2026: the tools are arriving faster than anyone can figure out what to do with them. The most practical takeaway for developers: invest time in building reusable AI scaffolding rather than one-off prompts. Whether it's Claude Skills (folders that teach the model your workflow), design systems that agents can reference, or structured memory layers for your agents, the teams seeing real leverage are the ones who treat AI configuration as infrastructure, not conversation.
Quick Hits
- @f4micom highlights @lauriewired's deep dive into historical memory conservation techniques like Hitachi's SuperH architecture, which used 16-bit instructions on a 32-bit chip to double cache line density. The "RAM crisis" is sending engineers back to the 90s for optimization ideas.
- @Scobleizer sees the holodeck arriving after @sparkjsdev launched Spark 2.0, an open-source streamable level-of-detail system for 3D Gaussian Splatting that pushes 100M+ splats to any device via WebGL2.
- @gusgarza_ built a cockroach-infested subway world in minutes using ThreeJS, MeshyAI, and World Labs, continuing the trend of rapid 3D prototyping with AI-assisted tools.
- @techwith_ram dropped a guide on knowledge graph optimization, arguing that companies like Google are building "digital DNA" through knowledge graphs to ensure AI systems actually understand organizational identity.
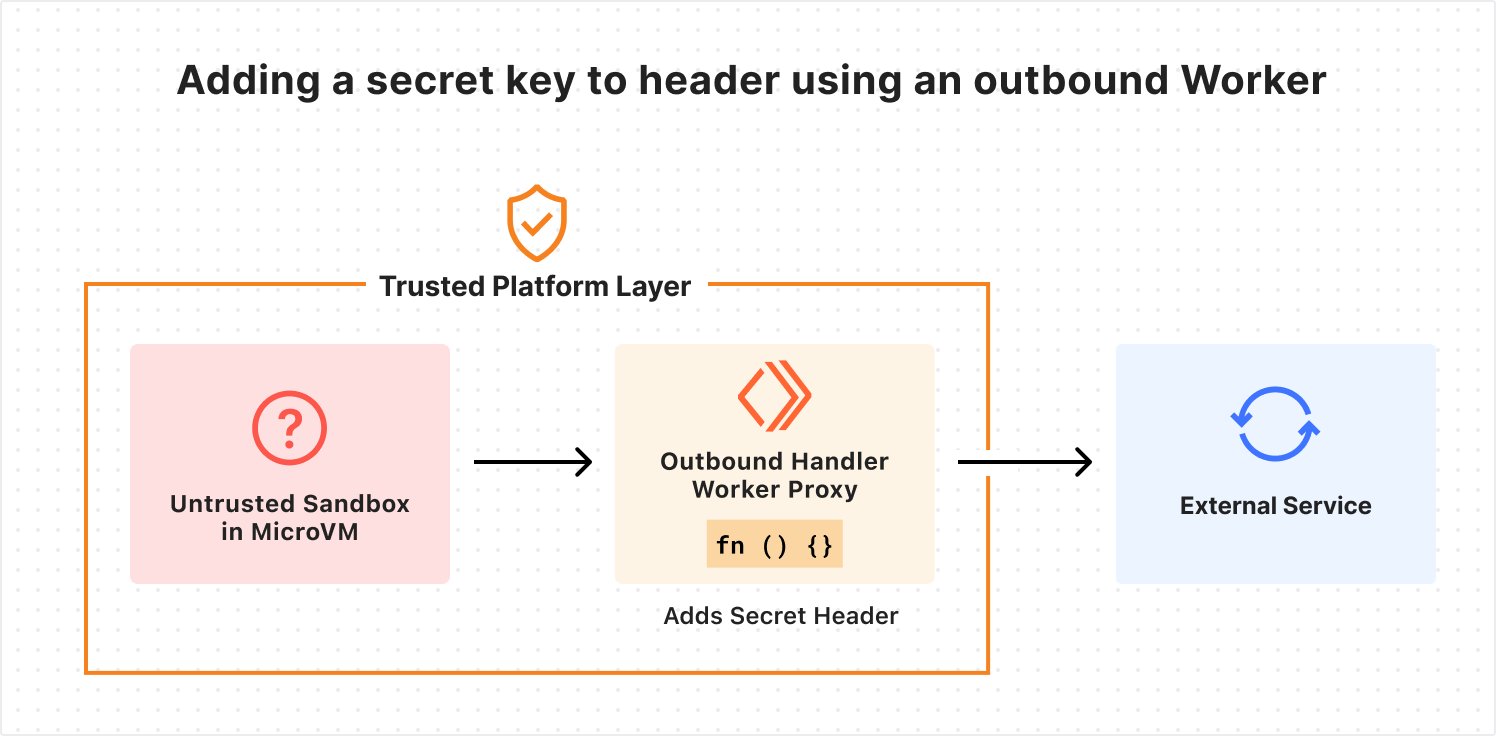
- @larsencc notes that even Cloudflare appears to have drawn from his blog post on building secure, scalable agent sandbox infrastructure. The agent sandbox pattern is clearly gaining mainstream infrastructure attention.
- @unusual_whales reports Anthropic is shifting Claude Enterprise to usage-based billing, raising costs for heavy users. A sign that enterprise AI consumption patterns are outpacing flat-rate pricing models.
- @jessegenet reports GLM 5.1 running locally "actually works," enabling OpenClaw workflows to run for just the cost of electricity. The local inference story keeps getting more practical.
AI-Powered Development Tools and Workflows
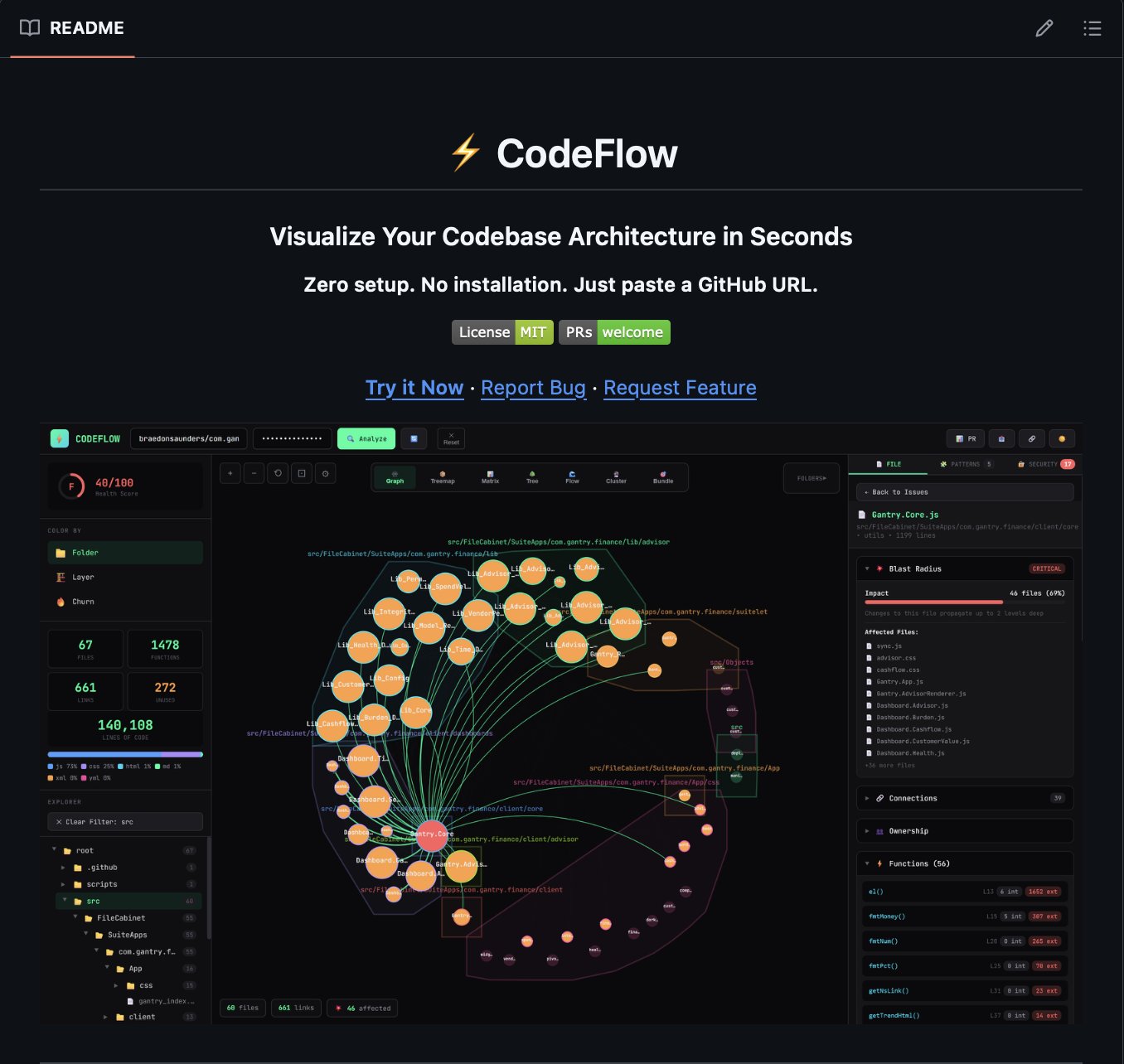
The tooling layer around AI-assisted development is thickening fast, and today's posts show it happening across multiple fronts simultaneously. What's notable isn't any single tool but the pattern: developers are building meta-tools that make AI development itself more systematic and repeatable. @sukh_saroy shared CodeFlow, a single HTML file that turns any GitHub repo into an interactive architecture map with dependency graphs, blast radius analysis, and security scanning. No install, no account, no build step. It's the kind of tool that feels trivial until you realize it solves the "help the AI understand my codebase" problem that every developer hits eventually.
On the workflow side, @kirillk_web3 had something of an epiphany watching two Anthropic engineers explain Claude Skills: "Skills are just folders? Folders that remember your workflow? Your domain? Your expertise?" The realization that persistent, structured context beats clever prompting is spreading. @pbakaus pointed to a related project from @mbwsims called Claude Universe, a plugin that teaches Claude Code to think systematically about security, testing, and codebase analysis rather than treating each session as a blank slate.
The thread connecting these is that raw model capability matters less than the scaffolding you build around it. @abnux described how their design agency's entire operating model shifted after building trained design and PM agents: "What I hear from our new set of clients is that there's a lot of value in setting up that scalable system such that design can truly go across the org via Claude Code. It feels like there's no going back." Their agency moved from recurring retainers to one-time system setup sprints. That's not a tool change; it's a business model change driven by the realization that well-configured AI systems compound in value.
Agent Architecture and Orchestration
The agent infrastructure conversation leveled up today with three distinct but complementary developments. @kwindla announced Pipecat 1.0 after two years of development, positioning it not just as a voice agent framework but as a general-purpose platform for "realtime, multi-modal, multi-model AI applications." The launch came alongside Pipecat Subagents, a library for running multiple inference loops in parallel with partially shared context. The fact that they proved the architecture by building Gradient Bang, described as "the first massively multiplayer, completely LLM-driven game," suggests the framework handles real complexity, not just demo-day scenarios.
Meanwhile, @akshay_pachaar made one of the most technically precise arguments of the day about why single-store agent memory fails. His example is elegant: store "Alice is the tech lead on Project Atlas," "Project Atlas uses PostgreSQL," and "PostgreSQL went down Tuesday," then ask if Alice's project was affected. Vector search finds Alice and Tuesday but misses the bridge fact connecting them through PostgreSQL. His proposed solution through Cognee combines relational stores for provenance, vector stores for semantics, and graph stores for relationships. "Enter through vectors, then traverse the graph, with provenance grounding every result back to its source."
@ihtesham2005 introduced Aurogen as an OpenClaw alternative built around true multi-agent, multi-instance orchestration inside a single deployment: "The original runs one agent. This one runs as many as you want." The pattern across all three announcements is convergent: the industry is realizing that useful AI systems require multiple models working together with shared but bounded context, and the infrastructure to support that is finally arriving.
Cybersecurity Meets Frontier Models
OpenAI's release of GPT-5.4-Cyber marks a deliberate step into territory that most AI companies have carefully avoided. As @PaulSolt broke down, this is a model specifically built to find and fix software exploits, and its most striking capability is binary scanning: "Agents can find exploits in compiled apps... no source code required. That's a new attack surface." The model ships with tiered access based on identity verification, where verified defenders get a more permissive version than the general public.
The numbers backing the release are substantial. Codex Security has reportedly fixed over 3,000 critical vulnerabilities automatically, and OpenAI is scaling to thousands of verified defenders. But as @PaulSolt noted, "The binary scanning unlock is scary. Stuff like this hasn't been mainstream before." The dual-use nature of exploit-finding AI is obvious, and OpenAI's answer is essentially an identity-gated access system. Whether that's sufficient is a question the security community will be debating for months.
Vibe Coding and Game Development
The "just build things" ethos continues to gain momentum, particularly in game development where AI-assisted creation is producing genuinely playable results. @NicolasZu captured the energy: "It's SO fun to game dev with Codex. Adding usually super complex stuff like it's nothing: procedural generation, laser mining, inventory management." His advice distills to two things: "Become good at AI" and "Train your taste." The implication is that taste, not technical skill, is becoming the primary bottleneck.
@cgtwts profiled Superblocks 2.0, which is explicitly positioning against the vibe coding wave by offering enterprise controls around AI-generated apps. The quoted launch post from @bradmenezes doesn't mince words: "Vibe-coded apps just became the #1 attack vector in the enterprise. Business teams are building on production data, while IT has zero visibility." A Fortune 500 reportedly shut down 2,500 Replit users to standardize on Superblocks. The tension between creative freedom and organizational control is becoming a real product category.
AI as Economic Infrastructure
@r0ck3t23 offered the day's most ambitious framing, building on a Jeff Bezos quote calling AI a "horizontal enabling layer." The argument: Wall Street is pricing AI like the next iPhone (a vertical product) when it's actually the next electrical grid (a horizontal substrate). "You do not sell a horizontal layer. You do not compete with it. You build on top of it or you disappear beneath it." It's the kind of post that reads as hyperbolic until you look at today's other posts showing AI dissolving boundaries between design agencies, game studios, security teams, and prediction markets. The horizontal layer thesis may be grandiose, but the evidence keeps accumulating.
The Trading Bot Underground
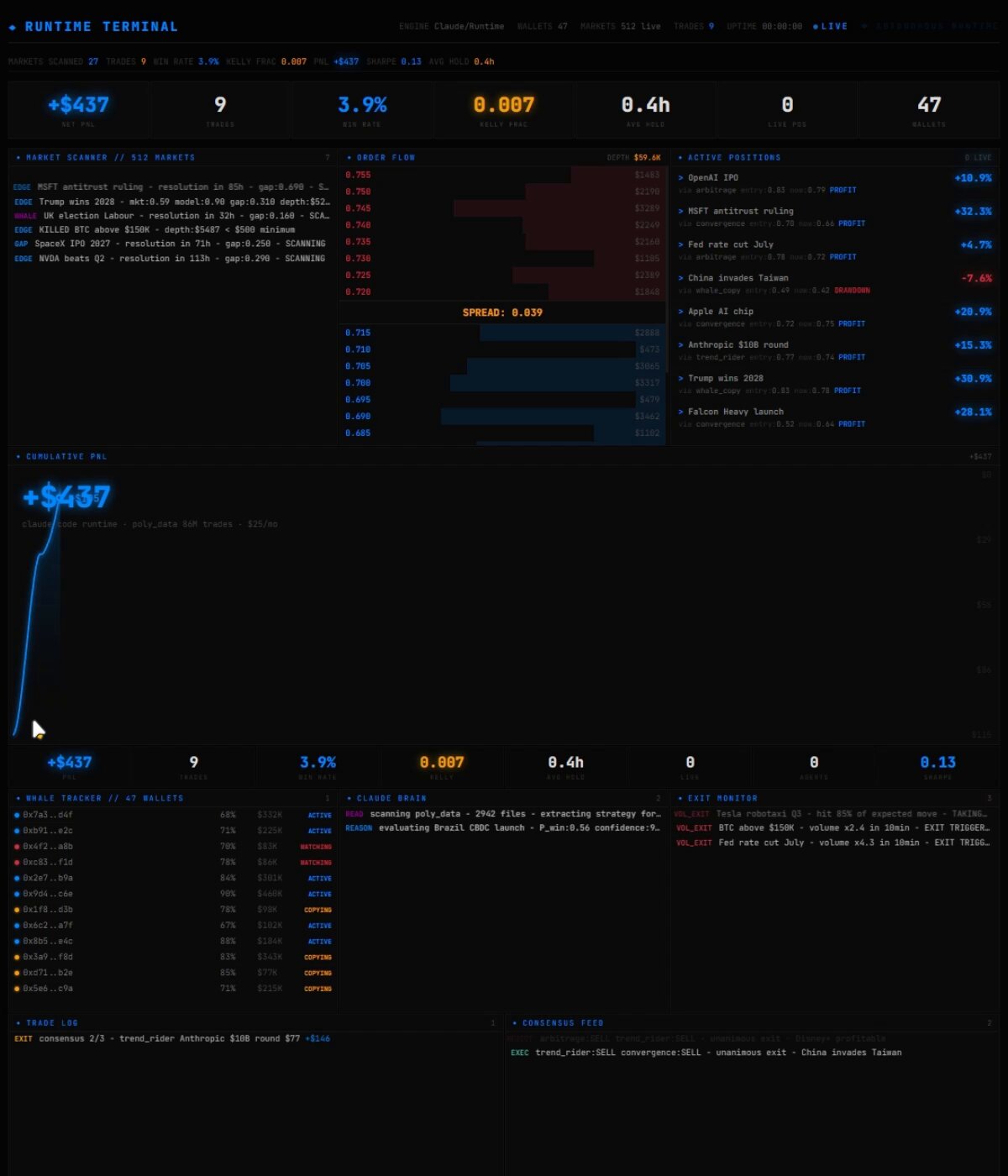
@LunarResearcher's viral thread about building a Polymarket trading bot with Claude Code reads like fiction but maps to real tools and repos. The core claim: connecting Claude Code to Polymarket's 86 million trade dataset, identifying 47 wallets with 70%+ win rates, and building a scanner that filters 500+ markets in real time. The key insight buried in the thread is about exits, not entries: "Same exact entries. The exits make it a completely different game." Top wallets capture 86% of the expected move and cut losers at 12%, while everyone else holds losers to 41%. Whether the claimed $8,700 return on an $800 seed is real or embellished, the underlying architecture of using AI as a runtime for data analysis rather than a chatbox for generating prompts reflects a broader shift in how people think about these tools.
Sources
L
An ex-OpenAI engineer walked up to me at a meetup in SF
I was showing my Polymarket terminal. He looked at the screen for ten seconds and said one sentence.
"You're trading blind. The data is sitting in the open and you're writing prompts"
I didn't understand. What data.
He took my laptop. Opened one repository.
https://t.co/klxt0tvrOd
86 million trades. Every wallet. Every entry. Every exit.
The entire Polymarket history since day one.
"At OpenAI models don't guess. They read. Connect Claude Code to this dataset and say - find every wallet with a win rate above 70% and more than 100 trades"
I asked - why Claude and not GPT?
He looked at me like I was an idiot.
"Because Claude Code connects to the repo directly. It reads the entire codebase. It's not a chatbox. It's a runtime"
That evening I connected it. Claude pulled 47 wallets in 4 minutes.
Average profit: $214K. Hold time: 7 hours.
91% close their position BEFORE resolution.
Top wallets capture 86% of the move and cut losers at 12%.
Everyone else - 58% of profit and hold losers to 41%.
Same exact entries. The exits make it a completely different game.
"Now connect the scanner"
https://t.co/SbyxXxFk0M
Three commands - the bot sees 500+ markets in real time. No API key. Read-only.
Claude built the scoring in 20 minutes:
Gap between price and model > 7 cents. Book depth > $500. Resolution in 4-48 hours.
93% of markets get killed instantly. Only the fat ones survive.
"Now this is the important part" - he sent me an article where a guy built a full bot over a weekend from these same repos
Copytrade here: https://t.co/N2byLbMfwH
Three exit triggers:
Target 85% of expected move. Volume spike x3 - smart money leaving. 24 hours of silence - thesis is dead.
I copied the whole stack.
VPS $5. Claude $20. Total $25 a month.
No team. No office. No Bloomberg.
16 days. 187 trades. 71% win rate. $800 seed.
+$8,700.
I sent him my screen. He replied a day later.
"You just replicated for $25 what cost us six months and 11 people"
I said - thanks for the tip.
"Delete this chat"
Too late.
L
LunarResearcher
@LunarResearcher
https://t.co/dDGYm5PBsc
K
> use Claude every day
> think I'm pretty good at this
> watch two Anthropic engineers for 16 minutes
> Barry and Mahesh explain Skills from scratch
> first 5 minutes
> wait. Skills are just folders?
> folders that remember your workflow?
> your domain? your expertise?
> pause. rewind. watch again.
> think about every prompt I rewrote from zero
> every context I explained 100 times
> every session that forgot everything
> it didn't have to be like this
> 16 minutes. everything changes.
> skill issue discovered

K
kirillk_web3
@kirillk_web3
🚨do you understand what two Anthropic engineers just explained in 16 minutes. Barry and Mahesh built Claude Skills from scratch. here's the part nobody is talking about: > Skills are just folders. > folders that teach Claude your job. > your workflow. your expertise. your domain. Claude on day 30 is a completely different tool than day one. watch this before you write another prompt. before you build another agent. before you touch another tool. 16 minutes. bookmark it. watch it today. and if you want to learn everything about Claude from scratch the full 4 hour guide is waiting below.
C
> be Brad Menezes
> join Datadog and help grow APM from 0 to $100M
> realize the real problem is how slow building is
> Sequoia Capital calls, become a scout
> invest in startups and see patterns early
> decide software shouldn’t take weeks to ship
> start Superblocks
> make backend, frontend, and auth much faster
> add ai into the workflow
> compete with Replit and Lovable
> raise $60M+ and go after the market
> watch small teams ship like big companies

B
bradmenezes
@bradmenezes
Introducing Superblocks 2.0: AI-generated enterprise apps – finally under IT control. Vibe-coded apps just became the #1 attack vector in the enterprise. Business teams are building on production data, while IT has zero visibility. No reviews. No audits. No permissions. No control. AI hackers are about to get 100x better. Anthropic proved it with Mythos. Superblocks 2.0 is the only platform to take back control: > Business teams build AI-powered apps with permissions baked in. > IT and Security can audit everything and lock down anything, instantly. > Engineering sets the standards. Every app follows them. Instacart, SoFi, and LinkedIn run Superblocks in production today. And larger organizations we can't yet name are too: A Fortune 500 just shut down 2,500 Replit users to standardize on Superblocks, running the platform air-gapped in their AWS environment. A 150,000-employee global services firm replaced Lovable with Superblocks to unlock AI-built apps on restricted internal systems. Every IT leader we’ve demoed to using Replit, Lovable or v0 asked for early access. Today we open access to the world. The genie is out of the bottle on employee vibe coding. Let it run wild, or take back control – https://t.co/8TEolq14Z5
I
I just found an OpenClaw killer.
It's called Aurogen and the single feature that separates it from every other fork is the one nobody else bothered to build: true multi-agent, multi-instance orchestration inside one deployment.
The original runs one agent. This one runs as many as you want.
→ Agents, Channels, Providers, Skills fully modular, fully parallelized, composable in any order
→ Pure web panel setup no config files, no CLI, zero restarts for any change ever
→ Multi-agent orchestration plus multi-instance per channel simultaneously
→ ClaWHub integration built directly into the interface import skills in seconds
→ Bundled one-click installers for Mac, Linux, and Windows no external dependencies
→ Minimum hardware is a $50 Linux SBC
MIT License. 100% Opensource.
https://t.co/VPJvHun4yZ
𝗿
Everything you are seeing on the web is connected. Top companies like Google are building digital DNA through knowledge graphs to ensure AI actually knows who they are.
Here's the exact guide👇 about knowledge graphs & its optimization techniques. https://t.co/GBnc3sxpdS

T
techwith_ram
@techwith_ram
How to Make Knowledge Graphs Blazing Fast
G
So fun what you can build in minutes using ThreeJS, @MeshyAI and @theworldlabs .
Cockroach world in subway. Yes Ive added trash assets too! https://t.co/dfaFQp9eQQ
L
Damn, even @Cloudflare read my blog it seems https://t.co/LDN5cy9GSL
L
larsencc
@larsencc
How We Built Secure, Scalable Agent Sandbox Infrastructure
R
20 years ago when I worked at Microsoft we did a virtual world in Second Life. Couldn't even dream of something like this.
But you can see the Holodeck arriving quickly now.
S
sparkjsdev
@sparkjsdev
Spark 2.0 is here! 🚀 We’re redefining what’s possible on the web with a streamable LoD system for 3D Gaussian Splatting. Built on Three.js, you can now stream massive 100M+ splat worlds to any device from mobile to VR using WebGL2. All open-source. Dive into the tech 👇 https://t.co/VOd6V0Wz1s
F
the whole RAM crisis thing has pushed Laurie to find every single historical way to conserve memory size or bandwith and i am loving every second of this because the stuff she is finding is insane
L
lauriewired
@lauriewired
In the 90s, Hitachi came up with a bizarre way to conserve memory bandwidth. Their SuperH architecture, intended to compete with ARM, was a 32-bit architecture that used…16 bit instructions. The benefit was really high code density. If you can fit twice as many instructions into every cache line, the CPU pipeline stalls way, way less. This was *really* important for embedded devices, which were often extremely bandwidth constrained in the era. Sega famously used the processors for the Dreamcast, and ARM actually ended up licensing their patents for Thumb mode! I think perhaps the weirdest thing about SuperH was its concept of “upwards compatibility”. The ISA itself is a microcode-less design, all future instructions were trapped and emulated by older chipsets. It’d be slow…but you could run future code on very old chips! Very neat design, a massive success through the 90s and 2000s, that slowly faded.
P
Matt recently showed me what he’s been tinkering on behind closed doors and he started to build in the open and I was impressed!
Very excited to see his projects drop, many at the intersection of creativity, storytelling and AI. You should def give him a follow if you’re into narrative storytelling (he’s got an interesting background - English PhD *and* ML/startup background)
M
mbwsims
@mbwsims
Teach Claude Code to think systematically. I got tired of having the same conversation with Claude Code. Review this for security. Are these tests sufficient? Can you find patterns in my codebase and update the instruction files? The answers were ok but inconsistent: no clear methodology, no memory between sessions, no systematic depth. So I built one Claude Code plugin, then another. Before I knew it I had five, covering instruction files, test coverage, security, codebase analysis, and code evolution. I decided to merge them into one integrated plugin. Claude universe was available so I figured why not… The Claude Universe plugin: teach Claude Code to think systematically Github link (entirely open source): https://t.co/kGFSGnryRu More at https://t.co/KLovBt5vDI
C
Here is a very detailed walkthru of Software Factory. This is best suited for PMs and Engineers who want to start tinkering with a potential new control plane for how software is made...
...we've made a lot of inroads into establishing this pattern into large Enterprises.
Please give it a try if you want to see what its all about.
8
8090_Factory
@8090_Factory
Our Head of Product John Calzaretta walks through the full Software Factory platform live: Refinery, Foundry, Planner, Validator, Knowledge Graph, MCP integration with Cursor, Claude Code, and others. Live Q&A included. Full demo: https://t.co/jQns1Gqrwn https://t.co/y1OrzYpEFI
D
Jeff Bezos just told you exactly how to price AI.
Nobody listened.
Bezos: “AI is real and it is going to change every industry. In fact it’s a very unusual technology in that regard in that it’s a horizontal enabling layer.”
Horizontal enabling layer.
Three words that reprice the entire technology sector.
The iPhone was a vertical. One product. One new market.
Electricity was a horizontal. One substrate that rewired every market on Earth.
Wall Street is pricing AI like it is the next iPhone. Bezos is telling you it is the next electrical grid.
Right now, thousands of companies are trying to sell AI as a product.
A feature. A tool. A subscription tier.
Every single one of them will be priced to zero.
You do not sell a horizontal layer. You do not compete with it. You build on top of it or you disappear beneath it.
For a century, entire industries survived on one thing. Complexity.
The friction of navigating law, medicine, logistics, finance. That was the moat. If you could not memorize the maze, you could not compete.
A horizontal layer does not navigate the maze. It dissolves the walls.
Electricity did not compete with the candle industry. It erased the need for one.
The most dangerous part of a horizontal shift is how quiet it is. It moves underneath the economy. The surface looks normal. Revenue still holds.
Every day you operate on the old substrate, you accumulate a debt you cannot see and cannot repay.
The internet repriced distribution. AI is repricing cognition itself.
When intelligence becomes a utility that runs through the walls of every company on Earth, the premium on human expertise does not erode. It evaporates.
This is not a disruption. Disruptions replace products.
This replaces the ground you are standing on.

K
I won an RTX 5090 GPU at Mistral AI worldwide hackathon in Paris, and I have absolutely no idea on how to use it.
Here's what I actually built: an image generation model fine-tuned to do technical analysis on trading charts. I trained it on an NVIDIA cloud GPU then back-tested it against Binance historical data.
The model was profitable.
The jury didn't quite catch the vibe. But apparently someone did because two weeks later, they reached out to tell me I'd won the NVIDIA track.
Today, a €4,000 RTX Founders Edition showed up at my door. Absolutely gorgeous piece of hardware.
One small problem: I use a MacBook. So if anyone has creative suggestions for what to do with a top-tier GPU and no desktop to put it in… I'm listening
Huge thanks to NVIDIA, Mistral AI and Iterate team for appreciating my weird idea and an attempt to push tech to its boundaries

J
Boom, the game is changed
GLM 5.1 running locally seems to actually work…
Now I can run a lot of my @openclaw workflows for the cost of electricity 🔌 https://t.co/Jcm0MlLHyX

P
OpenAI shipped GPT-5.4-Cyber. A model built to find and fix software exploits.
More capable than Mythos… and available today.
1. Binary scanning. Agents can find exploits in compiled apps… no source code required. That’s a new attack surface.
2. Prompt Refusals are lower. Verified defenders get a more permissive model than the public version.
3. Access is tiered by identity. Individuals verify at https://t.co/kpWiuT8NY2. Enterprises go through a rep.
4. Codex Security has fixed 3,000+ critical vulnerabilities automatically.
5. They’re scaling to thousands of verified defenders.
The binary scanning unlock is scary. Stuff like this hasn’t been mainstream before.
Agents finding exploits without ever seeing your source code.
O
OpenAI
@OpenAI
We’re expanding Trusted Access for Cyber with additional tiers for authenticated cybersecurity defenders. Customers in the highest tiers can request access to GPT-5.4-Cyber, a version of GPT-5.4 fine-tuned for cybersecurity use cases, enabling more advanced defensive workflows. https://t.co/RMMXQklFar
S
Paste any GitHub URL. get an interactive architecture map of the entire codebase. no install, no account, no build step.
It's called CodeFlow -- a single HTML file that turns any GitHub repo into a visual dependency graph in seconds.
Everything runs in your browser. your code never touches any server.
Here's what it actually shows you:
→ interactive dependency graph -- click any file to see what depends on it and what it depends on
→ blast radius analysis -- select any file and instantly see how many other files would break if you changed it
→ code ownership -- see top contributors per file based on git history, so you know who to ask in code review
→ security scanner -- auto-detects hardcoded API keys, SQL injection patterns, dangerous eval() calls, debug statements in production
→ pattern detection -- identifies singletons, factories, observer patterns, React hooks, god objects, high coupling
→ codebase health score -- A-F grade based on dead code, circular dependencies, coupling metrics, and security issues
→ activity heatmap -- color files by commit frequency to see where the hot spots are
→ PR impact analysis -- paste a PR URL and see the blast radius of proposed changes
Here's the wildest part:
It's literally one HTML file.
No npm install. no build process. no dependencies to manage. clone the repo and open index.html. or just go to the hosted version and paste a URL.
Works with private repos too -- add your GitHub token locally and it stays in your browser's memory, cleared when you close the tab.
43 GitHub stars. one file. MIT license.
100% open source.
(link in the comments)
U
Anthropic shifts Claude Enterprise to usage-based billing, raising costs for heavy users, per the Information
A
we got fired 😅
fr though, the last 6mo working with @supermemory was a crazy experience for us to realize the entire design workflow shift from pixels to systems
more recently, met @DhravyaShah in SF and he showed me how much can be done with design agents in shared slack channels w access to proper design + brand systems. he took the design system we’d set up and scaled it via the process described. that’s actually a huge unlock
we now have our own design agent and PM agent that we’ve trained on our style, workflow, w access to repos, skills and wikis. what I hear from our new set of clients is that there’s a lot of value in setting up that scalable system such that design can truly go across the org via Claude code. it feels like there’s no going back
our agency operating model shifted too recently, we’re seeing a lot more brand + design systems projects that are one time setup sprints rather than recurring retainers
so yeah, the shift is real 🦾
D
DhravyaShah
@DhravyaShah
how i rebuilt our landing page in 4 hrs with Claude
K
Big day today. Pipecat version 1.0. Two years in the making. The most widely used framework for voice agents, but not just voice agents. Pipecat is a framework for realtime, multi-modal, multi-model AI applications. Contributions from NVIDIA, all the foundation labs, AWS, GCP, and Azure. Used by thousands of startups, scale-ups, and enterprises.
Pipecat Subagents v0.1.0. A new library for sub-agent orchestration. Which is just a fancy way of saying running lots of inference loops in parallel, with partially shared context. The basic architecture of Pipecat Subagents is an event bus that works locally, and over the network.
And Gradient Bang. The side project that broke containment. Built with Pipecat and Pipecat Subagents. Gradient Bang was actually the proving ground for the early Subagents work. But ... it's also a really fun game.

K
kwindla
@kwindla
Sub-agents in (latent) space! We’ve been working on a side project. As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard. This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time. So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you. Some of the things we’ve been thinking about as we hack on Gradient Bang: - Sub-agent orchestration - Partial context sharing between multiple LLM inference loops - Managing very long contexts, and episodic memory across user sessions - World events and large volumes of structured data input as part of human/agent conversations - Dynamic user interfaces, driven/created on the fly by LLMs - And, of course, voice as primary input If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too! This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
N
It's SO fun to game dev with Codex
Adding (usually super complex) stuff like it's nothing
- Procedural generation
- Laser mining
- Inventory management
- New automation recipes
My only 2 advices now are
- Become good at AI
- Train your taste
how? build build build :) https://t.co/iWRJ4zwH3d
N
NicolasZu
@NicolasZu
An awesome trick for gamedevs here in the #vibejam or overall, if like me you don't know how to make good trees or rocks or any props Ask GPT-5.4 in Codex to make - a tree tool - a rock tool to allow you to tweak procedural trees and rock or props generation DIRECTLY in your game - Work with the AI to define a style and parameters you want to play with - Then see directly in game what you prefer - Save And now it's done And you can easily do that for seasons, adding more types of trees, etc.
A
Agent memory is three-dimensional.
Most agent memory systems use a single store. Usually a vector database. It handles semantic similarity well, but it captures only one dimension of knowledge.
Here's the gap. Store these three facts:
→ Alice is the tech lead on Project Atlas
→ Project Atlas uses PostgreSQL for its primary datastore
→ The PostgreSQL cluster went down on Tuesday
Now ask: was Alice's project affected by Tuesday's outage?
Vector search finds fact 1 (mentions Alice) and fact 3 (mentions Tuesday). But the bridge between them, fact 2, mentions neither. It connects Project Atlas to PostgreSQL, and that's exactly what gets missed.
This is the normal shape of business knowledge. People belong to teams, teams own projects, projects depend on systems, systems have incidents. Any question crossing two hops breaks flat retrieval.
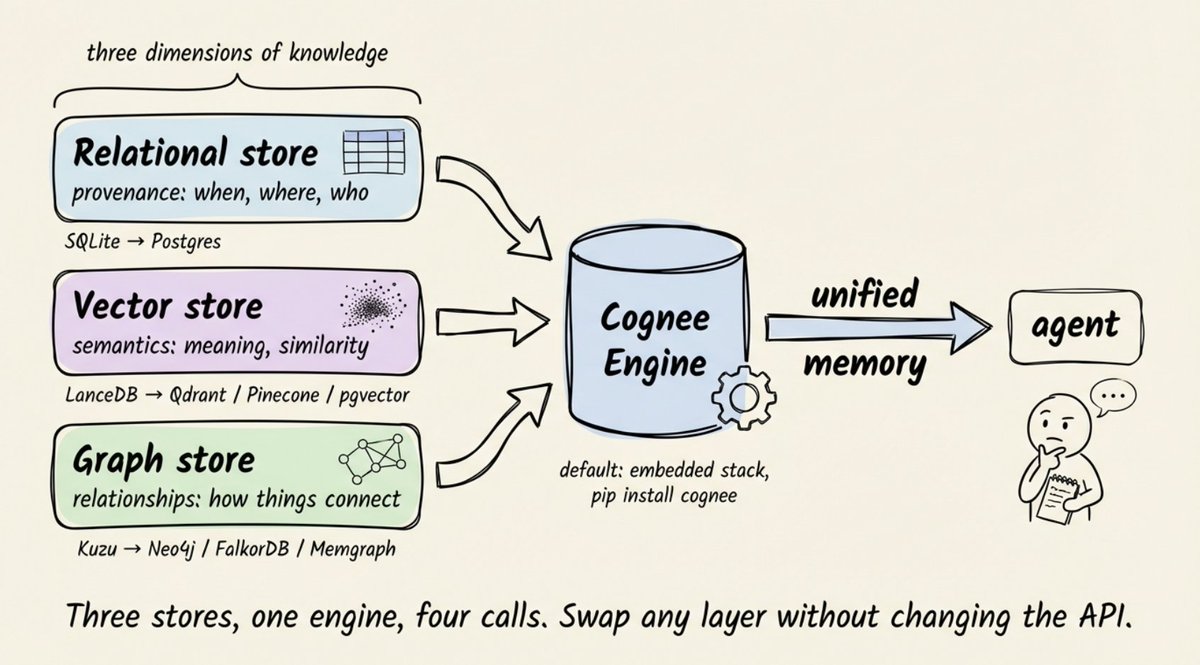
The three dimensions that actually cover agent memory:
→ A relational store for provenance (where data came from, when, who has access)
→ A vector store for semantics (what content means, what it's similar to)
→ A graph store for relationships (how entities connect across hops)
Each captures something the other two can't. Vectors find meaning. Graphs trace connections. Relational tables track lineage and permissions.
The real unlock is combining them: enter through vectors (find semantically relevant content), then traverse the graph (follow edges to connected entities), with provenance grounding every result back to its source.
Cognee is an open-source project that unifies all three behind four async calls. The default stack is fully embedded (SQLite + LanceDB + Kuzu), so a pip install gets you running locally. For production, swap in Postgres, Qdrant, or Neo4j without changing your agent code.
Check it out on GitHub: https://t.co/GmVimnGMdx
The article below is a first-principle deep dive on building agents that never forget. This will give you a clear picture of how memory for agents is evolving.
A
akshay_pachaar
@akshay_pachaar
Build Agents that never forget
T
We replaced our entire smoke-test suite with 147 deterministic E2E tests powered by aimock. 🧪
Every PR now verifies every feature across 7 LLM providers in about 2 minutes. No tokens burned. No flakiness. ✅
Here's how → https://t.co/TNLxHvS3Md https://t.co/oh6CQbRepb
