Enterprise Agent Roles Take Shape as Developers Optimize Claude Code Spend and Docker Workflows
Today's discourse centered on the emerging enterprise agent ecosystem, with Aaron Levie outlining a new "agent deployer" role and Ramp's Glass system showing 99% company-wide AI adoption. On the developer side, practical optimization dominated: Claude Code token tracking tools, Dockerfile best practices, and local LLM acceleration on Apple Silicon all drew significant attention.
Daily Wrap-Up
The conversation today split cleanly between two worlds: enterprise leaders figuring out how to reorganize entire companies around AI agents, and individual developers grinding on the nuts and bolts of making their tools faster, cheaper, and less wasteful. Aaron Levie continued his field notes from enterprise AI conversations, now proposing a concrete new job title for the people who will wire agents into business workflows. Meanwhile, Steven Sinofsky dropped a characteristically thorough essay on why "just go headless" is far harder than the agent-enthusiast crowd wants to admit. The tension between these two perspectives is the most interesting thread of the day: everyone agrees agents are coming for enterprise workflows, but the plumbing required to make that real is genuinely daunting.
On the practitioner side, the vibe was refreshingly pragmatic. A Claude Code token-tracking dashboard revealed that over half of one developer's spend was going to conversational responses rather than actual code generation. Dockerfile optimization tips got traction not because they were novel, but because people are still making the same mistakes. And the GPU discourse continued its eternal cycle, with pushback against the RTX 3090 nostalgia crowd pointing to newer cards with better performance per dollar. The most entertaining moment was @doodlestein casually dropping a 158-file, 2.7MB tax preparation skill for AI agents, filed just hours before the tax deadline, and having GPT 5.4 write its own marketing copy.
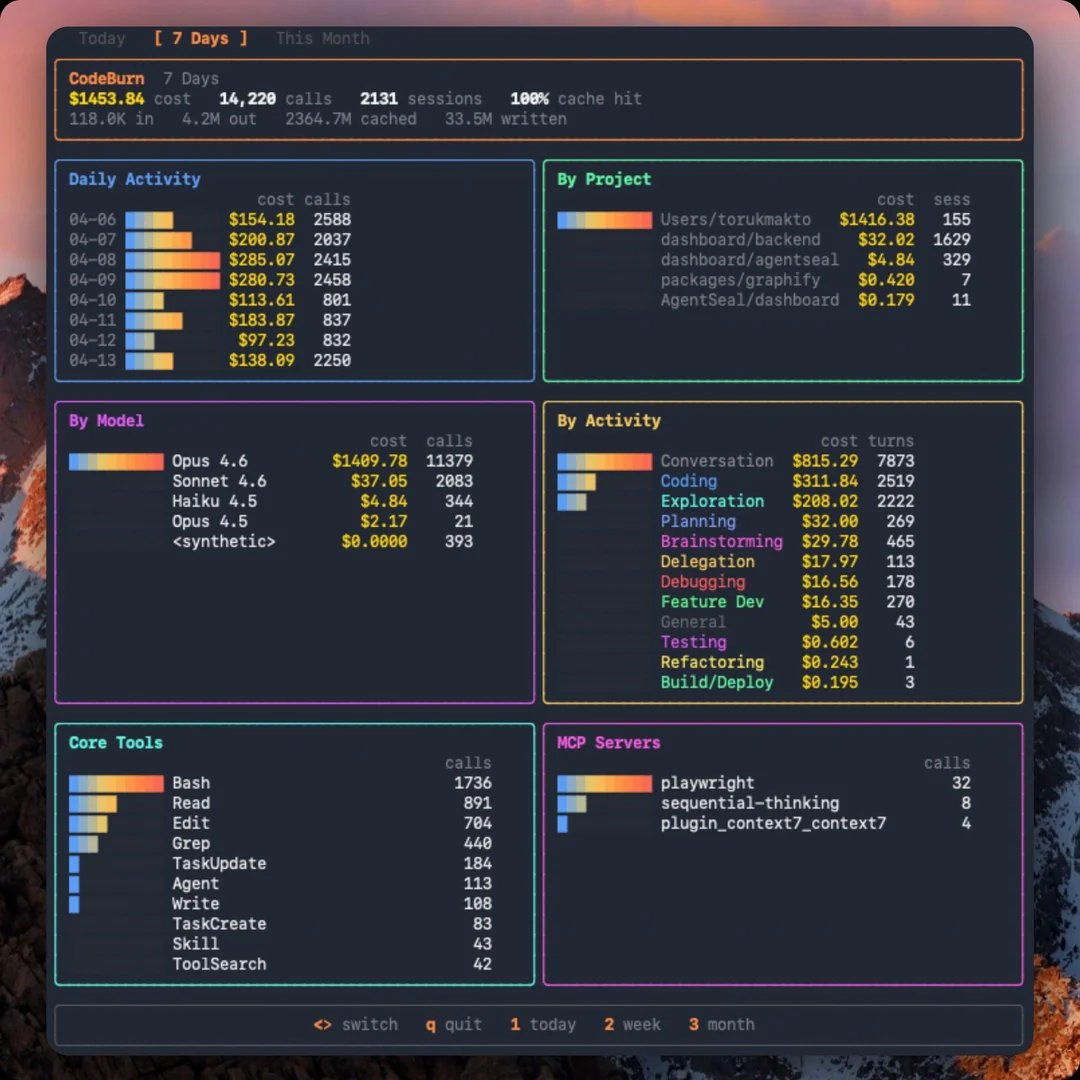
The most practical takeaway for developers: install a token-tracking tool like codeburn (npx codeburn) to audit where your AI coding spend actually goes. If you're like the developer who built it, you may find that more than half your tokens are burned on conversation rather than code generation, and that visibility alone can reshape how you prompt and interact with coding agents.
Quick Hits
- @indie_maker_fox shared impressive architecture diagrams generated by an AI skill for OpenHarness, showcasing how documentation tooling keeps improving.
- @berryxia highlighted DFlash speculative decoding on Apple M-series chips achieving up to 4.13x speedups for Qwen3.5, pushing local LLM inference further into "good enough" territory.
- @kimberlywtan spotlighted former OpenAI researcher @philhchen building "Filbert," a lightweight coding agent wrapper that runs on your own infrastructure and can improve itself recursively.
- @juristr teased a video on "Agent Factories," exploring patterns for spinning up and managing fleets of AI agents programmatically.
- @mattpocockuk floated a relatable prompt pattern: asking AI to "go up a layer of abstraction" and map all relevant modules and callers when navigating unfamiliar code. He's looking for a name for the skill.
- @TheAhmadOsman recommended pairing local LLMs with a self-hosted SearXNG instance for web search, calling it a significant intelligence boost for local setups.
Enterprise Agents and the New Org Chart (4 posts)
The biggest cluster of conversation today revolved around how enterprises are actually deploying AI agents at scale, and what organizational changes that demands. @levie laid out a detailed job description for what he sees as an inevitable new role: the agent deployer and manager. This person sits on individual teams, maps workflows, connects business systems via MCP and CLIs, and runs agents against KPIs. It's not a centralized IT function. It's embedded, operational, and deeply technical:
> "The gnarly part of the work is mapping structured and unstructured data flows, figuring out the ideal workflow, getting the agent the context it needs to do the work properly, figuring out where the human interfaces with the agent and at what steps, manages evals and reviews after any major model or data change."
This framing got reinforced by @jordan_ross_8F's breakdown of Ramp's internal "Glass" system, which achieves 99% daily AI usage across the company through pre-configured workspaces, 350+ reusable skills, and persistent memory. The key insight from Ramp's approach, originally shared by @eglyman, is that adoption stalled not because models weren't capable but because "the setup was too painful and unintuitive for most." Glass solved that by making every employee's AI workspace ready on day one with integrations already connected via SSO.
What makes this cluster interesting is the gap between ambition and reality. While Levie describes agent deployers connecting systems seamlessly, Sinofsky's lengthy analysis (quoted from @stevesi) argues that most enterprise software was never designed to be operated headlessly. The 100,000+ tables in a typical SAP installation aren't just an API problem; they represent decades of implementation complexity that no agent can easily navigate. The enterprise agent revolution everyone's planning for may arrive, but it's going to hit a wall of legacy architecture that "headless" handwaving can't solve.
Developer Tooling and Token Economics (3 posts)
A practical thread emerged around making AI-assisted development more efficient and observable. @om_patel5 showcased codeburn, an open-source terminal dashboard that classifies every Claude Code turn into 13 categories without any LLM calls. The finding that jumped out:
> "56% of his spend was 'conversation' where Claude is just responding with no tool use and the actual coding (edits and writes) was only 21%."
That's a striking ratio that suggests many developers are essentially paying for an expensive rubber duck. The tool reads session transcripts and breaks down costs by task type, project, model, and MCP server, with daily activity charts and interactive navigation.
On the configuration side, @diegohaz shared Claude Code settings that he says "fixed most of the issues" he was experiencing: forcing Opus 4-6, setting effort level to high, enabling always-on thinking, and disabling adaptive thinking with a 32K thinking token cap. These kinds of community-shared configurations are becoming their own form of knowledge, and the fact that users need to tune these knobs at all says something about how much performance variance exists in default setups. Together, these posts paint a picture of a maturing ecosystem where developers are moving past "wow this is cool" into "how do I make this cost-effective and reliable."
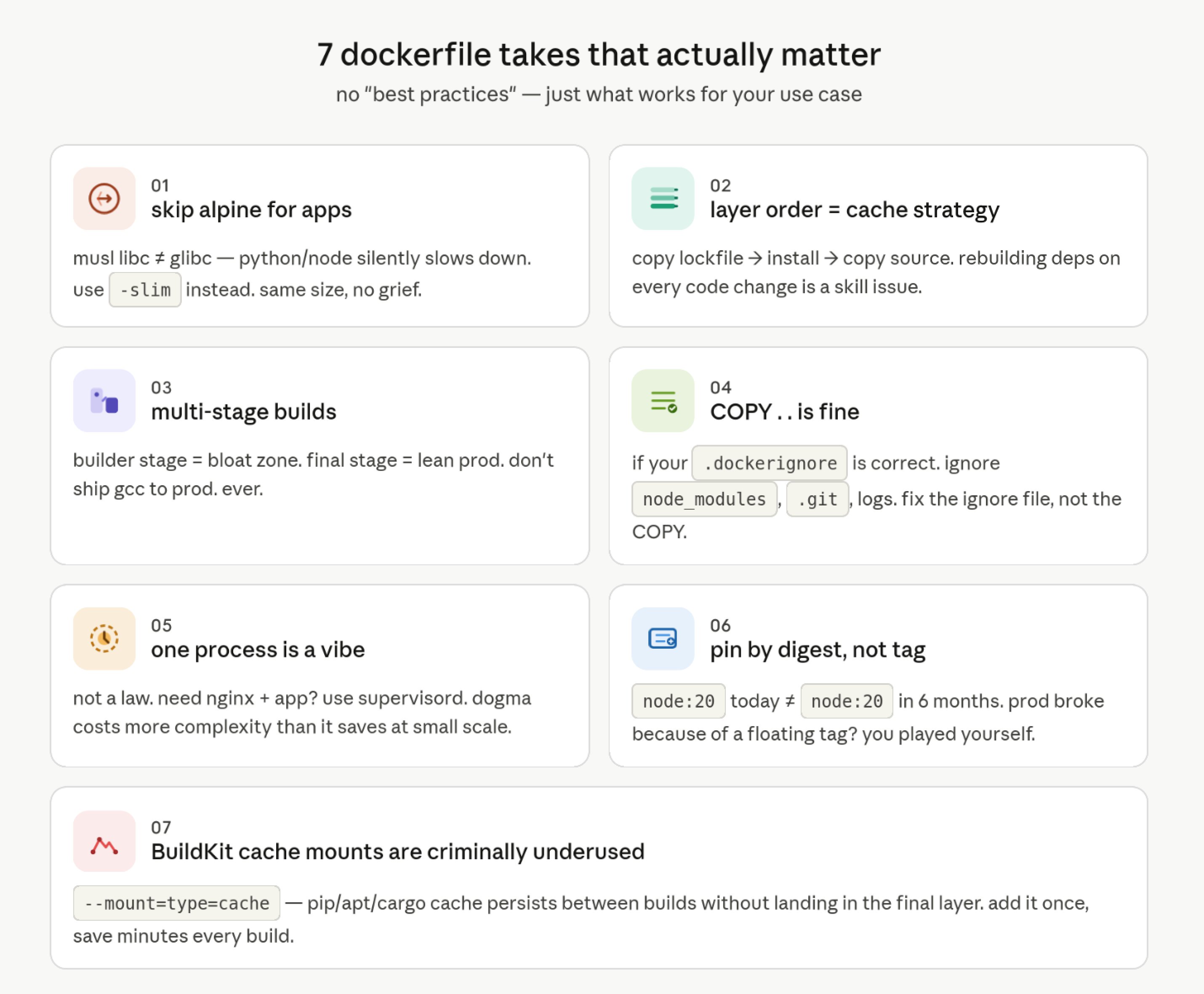
Dockerfile Practices That Actually Matter (1 post)
@immanuel_vibe dropped a comprehensive thread of Dockerfile opinions that resonated because they're the kind of advice that sounds obvious in retrospect but trips up even experienced developers. The highlights challenge common dogma: stop using Alpine for Python and Node apps because musl libc causes silent performance issues, use debian-slim instead. Pin base images by digest, not tag, because node:20 today won't be node:20 in six months. And the most practical gem:
> "BuildKit cache mounts (--mount=type=cache) will change your life. pip/apt/cargo cache between builds without it ending up in the final layer. Nobody talks about this enough."
The thread also pushed back gently on container orthodoxy, arguing that the "one process per container" rule costs more complexity than it saves when you're not at Kubernetes scale. The post plugged dockerfile-roast, a Rust-based linter with 63 rules, but the real value was in the framing: there's no best practice in a vacuum, only workload-appropriate choices.
Context Engineering Over RAG (1 post)
@nyk_builderz articulated a shift that's been building for months: the most sophisticated AI teams have moved past optimizing retrieval and are now focused on context governance. The distinction matters:
> "RAG fetches fragments. Context engineering manages decisions. Control planes enforce safety + provenance. In 2026, memory quality compounds faster than model quality."
This framing reframes the entire RAG conversation from a technical plumbing problem into an architectural one. It's not about fetching the right chunks anymore; it's about managing what context an agent sees, when, and with what provenance guarantees. As agents get more autonomous and operate across more business systems, the question of "what does this agent know and why" becomes a governance problem, not just an engineering one.
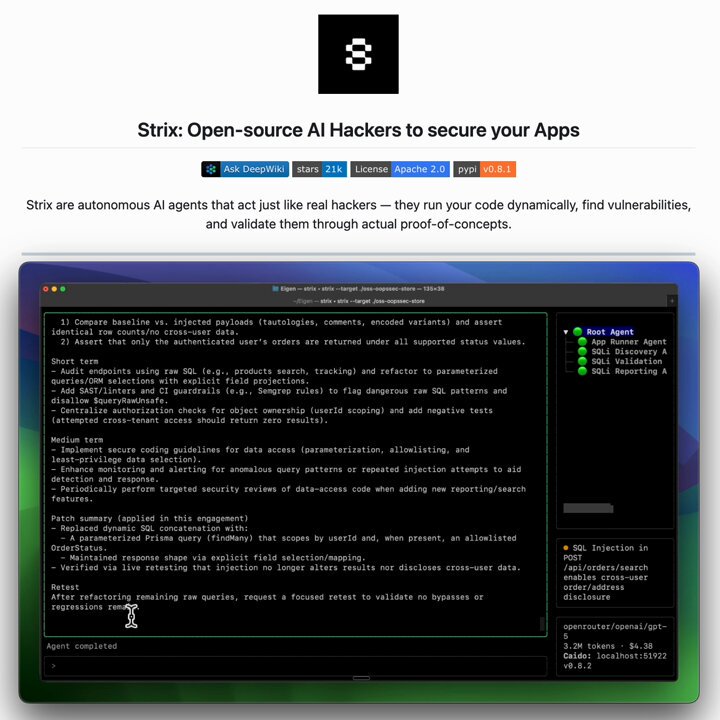
AI-Powered Security Testing (1 post)
@_avichawla made waves with a post about Strix, an open-source framework for continuous AI pentesting that deploys a graph of specialized agents to probe attack surfaces. The pitch is compelling: traditional pentests cost $30-50K, take weeks, and produce PDFs that are outdated by the next deploy. Strix runs continuously, chains vulnerabilities automatically, and generates merge-ready remediation code. The most interesting architectural detail is that agents share discoveries in real time, so "if one finds an auth bypass, another immediately tests whether it chains into privilege escalation." Whether this replaces professional pentesters entirely is debatable, but as a continuous supplement to scheduled audits, it fills a real gap in CI/CD pipelines that catch build failures but not security exposures.
Local Inference and Hardware (2 posts)
The local AI hardware debate continued with @kaiostephens pushing back against the RTX 3090 nostalgia that's dominated GPU discussions. While a quoted thread argued the 3090's $42/GB VRAM makes it unbeatable, Kaios pointed to the 5060 Ti, AMD's 9060 XT, and even Tenstorrent's P100A as better performance-per-dollar options. Meanwhile, @LottoLabs highlighted llama.cpp's RPC capability for splitting models across heterogeneous GPU setups on separate machines, no fancy networking required. For homelabbers running mixed hardware, this is a meaningful unlock: you can finally combine that old 3090 with a newer card on a different machine and actually use them together for inference.
Sources
Context Engineering killed RAG
how I built Filbert (phil-bot) the future of coding agents is lightweight wrappers around existing harnesses running on your own infra. it has access to your full dev env and can improve itself recursively. it's also so easy to build when you're set up for it.

Another week on the road meeting with a couple dozen IT and AI leaders from large enterprises across banking, media, retail, healthcare, consulting, tech, and sports, to discuss agents in the enterprise. Some quick takeaways: * Clear that we’re moving from chat era of AI to agents that use tools, process data, and start to execute real work in the enterprise. Complementing this, enterprises are often evolving from “let a thousand flowers bloom” approach to adoption to targeted automation efforts applied to specific areas of work and workflow. * Change management still will remain one of the biggest topics for enterprises. Most workflows aren’t setup to just drop agents directly in, and enterprises will need a ton of help to drive these efforts (both internally and from partners). One company has a head of AI in every business unit that roles up to a central team, just to keep all the functions coordinated. * Tokenmaxxing! Most companies operate with very strict OpEx budgets get locked in for the year ahead, so they’re going through very real trade-off discussions right now on how to budget for tokens. One company recently had an idea for a “shark tank” style way of pitching for compute budget. Others are trying to figure out how to ration compute to the best use-cases internally through some hierarchy of needs (my words not theirs). * Fixing fragmented and legacy systems remain a huge priority right now. Most enterprises are dealing with decades of either on-prem systems or systems they moved to the cloud but that still haven’t been modernized in any meaningful way. This means agents can’t easily tap into these data sources in a unified way yet, so companies are focused on how they modernize these. * Most companies are *not* talking about replacing jobs due to agents. The major use-cases for agents are things that the company wasn’t able to do before or couldn’t prioritize. Software upgrades, automating back office processes that were constraining other workflows, processing large amounts of documents to get new business or client insights, and so on. More emphasis on ways to make money vs. cut costs. * Headless software dominated my conversations. Enterprises need to be able to ensure all of their software works across any set of agents they choose. They will kick out vendors that don’t make this technically or economically easy. * Clear sense that it can be hard to standardize on anything right now given how fast things are moving. Blessing and a curse of the innovation curve right now - no one wants to get stuck in a paradigm that locks them into the wrong architecture. One other result of this is that companies realize they’re in a multi-agent world, which means that interoperability becomes paramount across systems. * Unanimous sense that everyone is working more than ever before. AI is not causing anyone to do less work right now, and similar to Silicon Valley people feel their teams are the busiest they’ve ever been. One final meta observation not called out explicitly. It seems that despite Silicon Valley’s sense that AI has made hard things easy, the most powerful ways to use agents is more “technical” than prior eras of software. Skills, MCP, CLIs, etc. may be simple concepts for tech, but in the real world these are all esoteric concepts that will require technical people to help bring to life in the enterprise. This both means diffusion will take real work and time, but also everyone’s estimation of engineering jobs is totally off. Engineers may not be “writing” software, but they will certainly be the ones to setup and operate the systems that actually automate most work in the enterprise.


The GTM Engineering Hire: A Comprehensive Guide to the Role That's Replacing Your SDR Team

so we tried S3 Files and it's goated > 2+ GB/s write throughput > natively mounts to any workload > 1ms latency i really wish it was possible to mount @archildata on Fargate too
llama.cpp RPC split models across machines, no fancy network needed!
Why RTX 3090 is the best GPU per GB in 2026 and how NVIDIA trapped itself with VRAM 3090 launched in 2020 for $1,500 with 24GB of GDDR6X. Today a used one goes for ~$1,000. That’s ~$42/GB of VRAM 5090 launched in 2025 at $2000 with 32GB of GDDR7. But the street price right now is ~$4,400. That’s ~$137/GB 3.3x difference!!! The rest of the 50 series lineup: RTX 5080 — 16GB RTX 5070 Ti — 16GB RTX 5070 — 12GB NVIDIA is giving you less VRAM than a 3090 had 5 years ago for more money Now they’re forced to artificially nerf VRAM just to protect their $20k+ server GPU sales (H100 etc) It’s an accidental bug in their pricing strategy that gives regular consumers a chance to dive into the local LLM rabbit hole They’re completely out of production and the used supply is shrinking by the day 3090 is going to stay relevant for a long time
99% of Ramp uses ai daily. but we noticed most people were stuck — not because the models weren't good enough, but because the setup was too painful and unintuitive for most. terminal configs, mcp servers, everyone figuring it out alone. so we built Glass. every employee gets a fully configured ai workspace on day one — integrations connected via sso, a marketplace of 350+ reusable skills built by colleagues, persistent memory, scheduled automations. when one person on a team figures out a better workflow, everyone on that team gets it and gets more productive. the companies that make every employee effective with ai will compound advantages their competitors can't match. most are waiting for vendors to solve this. we decided to own it.