Agent Architecture Patterns Go Mainstream as Claude Code Token Billing Controversy Surfaces
The AI developer community is coalescing around production-ready agent design patterns, from circuit breakers to parallel worktree execution. A Claude Code billing investigation claims 20K invisible tokens per request in recent versions, while speculative decoding hits 186 tok/s on Apple Silicon and markerless motion capture threatens six-figure studio setups.
Daily Wrap-Up
Today's feed reads like a masterclass syllabus for anyone building agents that need to survive contact with production. Multiple threads independently converged on the same realization: the hard part of agentic AI isn't the model, it's everything around it. Circuit breakers, dead letter queues, idempotent tool calls, parallel worktree isolation, regression gates. These are distributed systems concepts that have been battle-tested for decades, now being rediscovered and adapted for a world where your "microservice" is a language model that occasionally hallucinates. The fact that several experienced engineers are packaging these patterns into open-source skills and plugins suggests we're past the "wow, agents can do things" phase and firmly into "okay, how do we stop them from doing the wrong things repeatedly."
The most entertaining moment was the Claude Code token billing drama. @om_patel5 dropped a detailed investigation claiming that version 2.1.100 silently inflates every request by roughly 20,000 tokens through server-side additions invisible to users. Whether this turns out to be instrumentation overhead, system prompt changes, or something else entirely, the fact that someone set up an HTTP proxy to diff API requests across four versions is exactly the kind of forensic engineering the ecosystem needs. Meanwhile, the "GLM-5.1 is a Claude Code killer" crowd and the "here's how to tune your Claude settings" crowd are having two very different conversations about the same product, which is always a sign that a tool has reached mainstream adoption.
On the infrastructure side, @ekzhang1 quietly pointed out that $200/month buys six hours of H100 time every workday, a number that would have seemed absurd two years ago and now feels like a practical line item. Pair that with @aryagm01 getting Qwen3-4B to 186 tokens per second on a MacBook via speculative decoding, and the cost curve for serious AI work continues to bend in interesting directions. The most practical takeaway for developers: if you're building agents, stop treating reliability as an afterthought. Pick three patterns from the production architecture lists circulating today (start with circuit breakers, idempotent tool calls, and human escalation protocols) and implement them before you scale, not after something breaks at 3 AM.
Quick Hits
- @elonmusk shared an engineering video with "Engineering is real magic," continuing his tradition of minimal-caption retweets that somehow pull millions of impressions.
- @thefinnmckenty flagged @Gossip_Goblin as "easily the best in the world at AI video," pointing to "The Patchwright" as evidence that creative AI video is advancing faster through individual artists than through tooling announcements.
- @0xSero urged public figures to study OSINT techniques for personal security, noting we're in "a really dangerous time" for data leakage and recommending proactive defense strategies.
- @thdxr offered a sharp cultural observation: "everyone felt good buying apple products, everyone feels guilty using AI," calling out Silicon Valley's selective relationship with the ethics of the products it builds.
- @WillsSpangler spotlighted Algolemeth, a Japanese indie RPG where you program golems through a node-based "ModuleRack" system, blending dungeon crawling with automation mechanics.
- @lateinteraction (Omar Khattab) RT'd a take on RLM with GEPA-optimized cores and DSPy, signaling continued momentum for structured LLM programming frameworks.
Agents in Production: Architecture Patterns and Parallel Execution
The single loudest signal today was the community's hunger for production-grade agent architecture. At least five posts independently addressed how to build AI systems that don't collapse under real-world conditions, making this less of a trend and more of a phase transition.
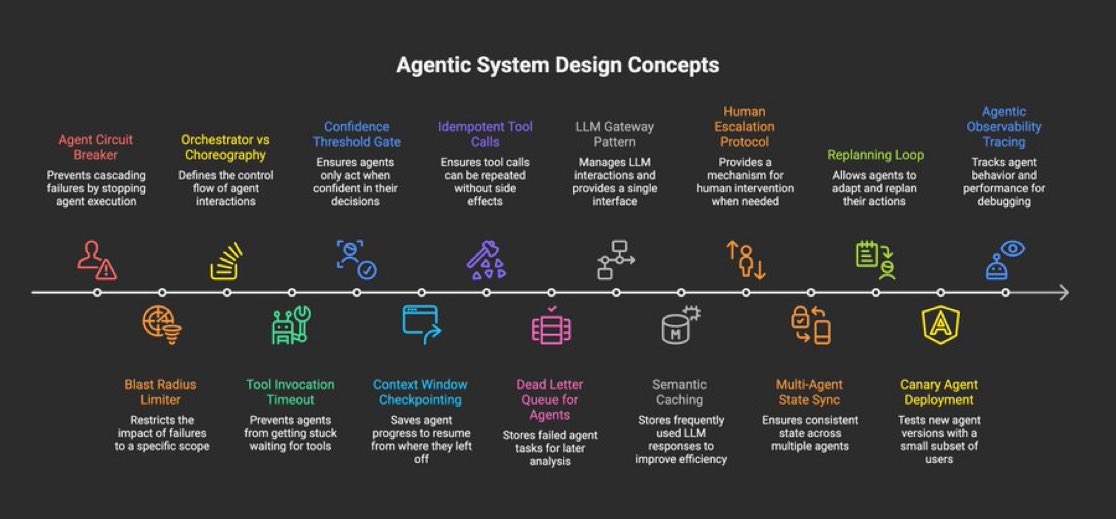
@asmah2107 laid out a 15-point checklist of agentic system design concepts that reads like a distributed systems textbook adapted for LLMs: "Agent Circuit Breaker, Blast Radius Limiter, Orchestrator vs Choreography, Tool Invocation Timeout, Confidence Threshold Gate, Context Window Checkpointing, Idempotent Tool Calls, Dead Letter Queue for Agents." Every one of these maps to a failure mode that anyone who's shipped an agent has encountered. The list is notable not for any single item but for how comprehensively it covers the gap between "agent that works in a demo" and "agent that works at 3 AM on a Saturday."
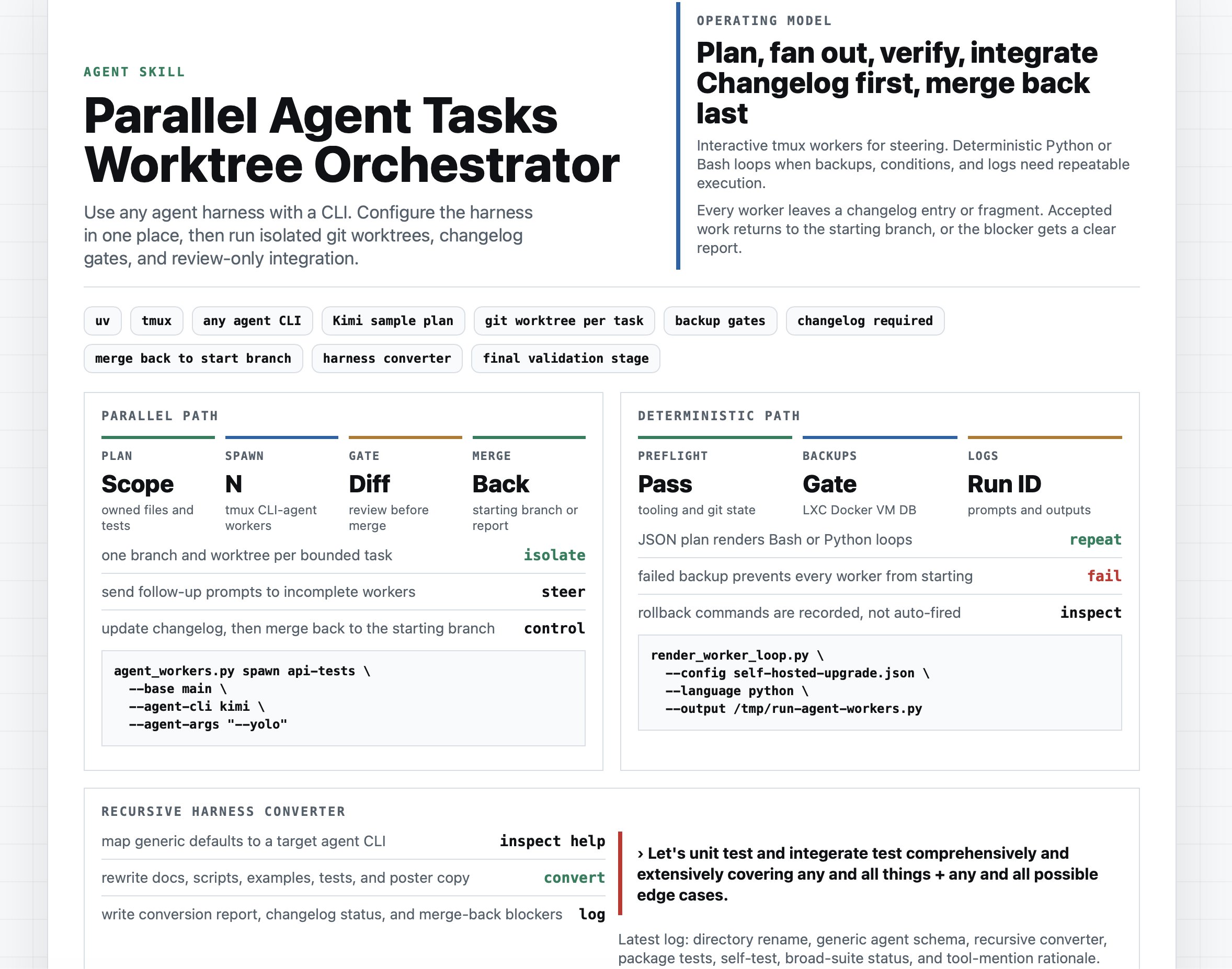
On the execution side, @TheAhmadOsman shared his approach to parallel agent orchestration: "Spin up workers, isolate in git worktrees, gate with diffs, add backups, rules, logs when deterministic, merge what passes." This pattern of treating agents like CI workers with proper isolation is gaining real traction. @alokbishoyi97 took it further with "evo," an open-source Claude Code plugin that "finds a benchmark, runs the baseline, then fires off parallel agents to try to beat it," using tree search over greedy hill-climbing with shared failure traces so agents avoid repeating each other's mistakes.
@theo weighed in from the builder's perspective, demystifying the infrastructure layer: "Agent harnesses aren't the black magic many of y'all seem to think they are. To prove it, I built one." And @coreyganim broke down a production case study of someone running "5 agents, 48 daily crons, and a unified vector DB that ingests everything every 15 minutes," arguing that "your internal implementation IS the product. Your compounded data IS the moat." The through-line across all of these posts is clear: the competitive advantage in agents isn't model selection anymore. It's operational maturity.
Claude Code Under the Microscope
Claude Code dominated a separate cluster of conversation today, but the tone was more forensic than celebratory. The community is stress-testing its favorite tool and publishing the results.
@om_patel5 published what he calls proof of invisible token inflation: "v2.1.98: 49,726 billed tokens. v2.1.100: 69,922 billed tokens. Same project, same prompt, same account." His analysis claims these additional tokens are entirely server-side and invisible to users, meaning "your CLAUDE.md instructions get diluted by 20K tokens of hidden content" and "quality degrades faster in long sessions." His recommended fix is blunt: "downgrade to v2.1.98." Whether or not the full interpretation holds up, the methodology of proxying API requests to audit billing is valuable and likely to be replicated.
@kunchenguid took a more constructive approach, sharing Claude Code settings tweaks "for folks who feel their Claude Code got nerfed," offering configuration adjustments to stabilize behavior. Meanwhile, @shmidtqq pointed to GLM-5.1 as a free alternative, quoting @MisterNoComents calling it a "Claude Code Killer UNLIMITED and FREE." The juxtaposition is telling: Claude Code is simultaneously the tool everyone uses, the tool everyone complains about, and the tool everyone benchmarks against. That's what market leadership looks like.
AI Debugging: From Brute Force to Scientific Method
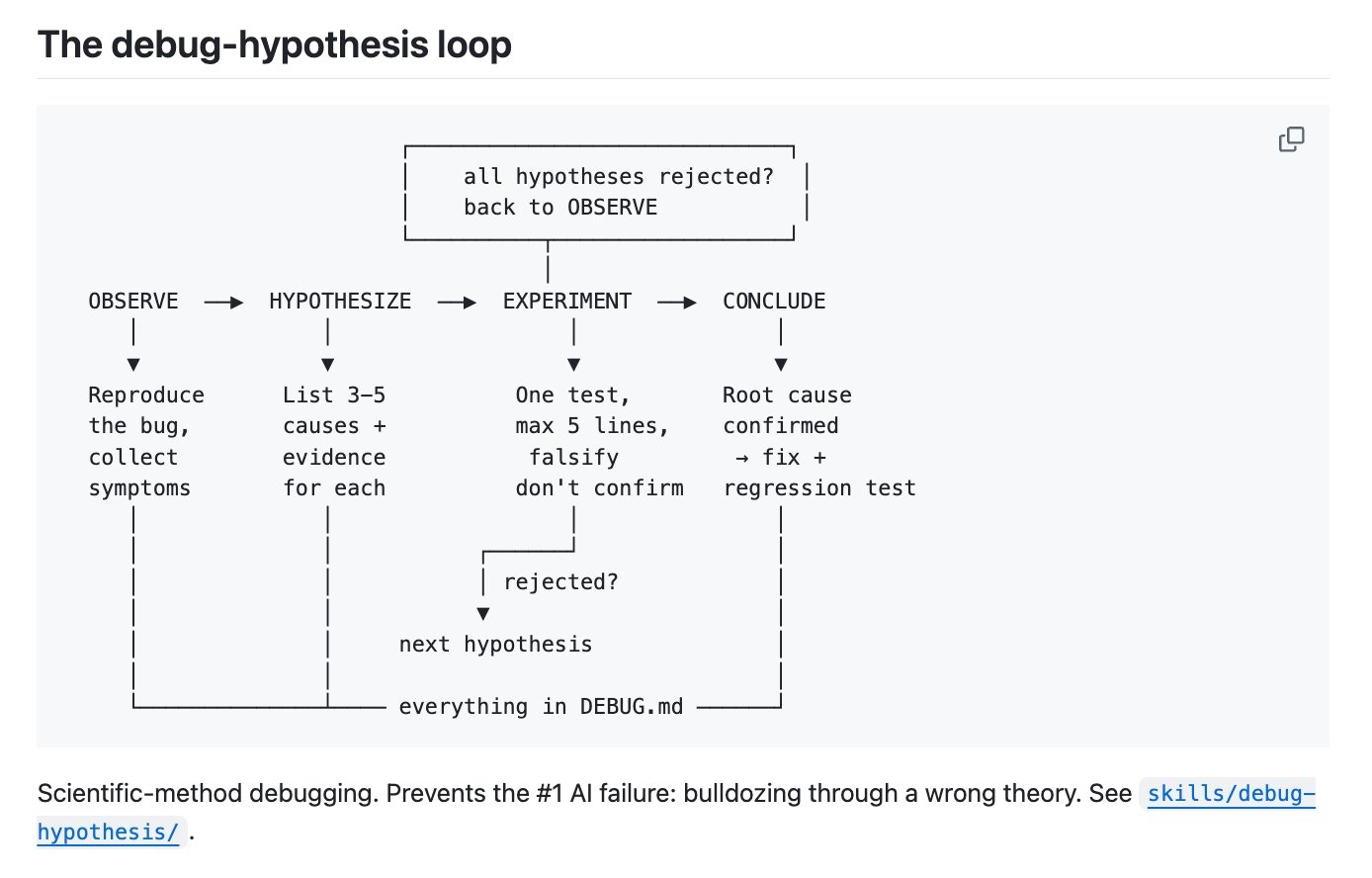
A fascinating thread from @ShenHuang_ captured what might be the most universally applicable lesson of the day. After burning "好几亿 tokens" (hundreds of millions of tokens) brute-forcing a race condition, the breakthrough came from adding a single instruction: "把所有假设和证据写到 DEBUG.md" (write all hypotheses and evidence to DEBUG.md).
The AI listed five hypotheses. The third had no contradicting evidence. "3 lines of experiment, root cause confirmed, 5-minute fix." The resulting methodology is deceptively simple: "List hypotheses before changing code. Each experiment changes at most 5 lines. Write all evidence to a file to prevent context compression from losing the reasoning chain. If the same direction fails twice, force a hypothesis switch." This has been open-sourced as a Claude Code and Gemini CLI skill. The insight here isn't about AI at all. It's about applying scientific method to debugging, something humans have always been bad at, and using the AI's tendency toward structured output as an advantage rather than fighting it.
Local AI Performance and Infrastructure Economics
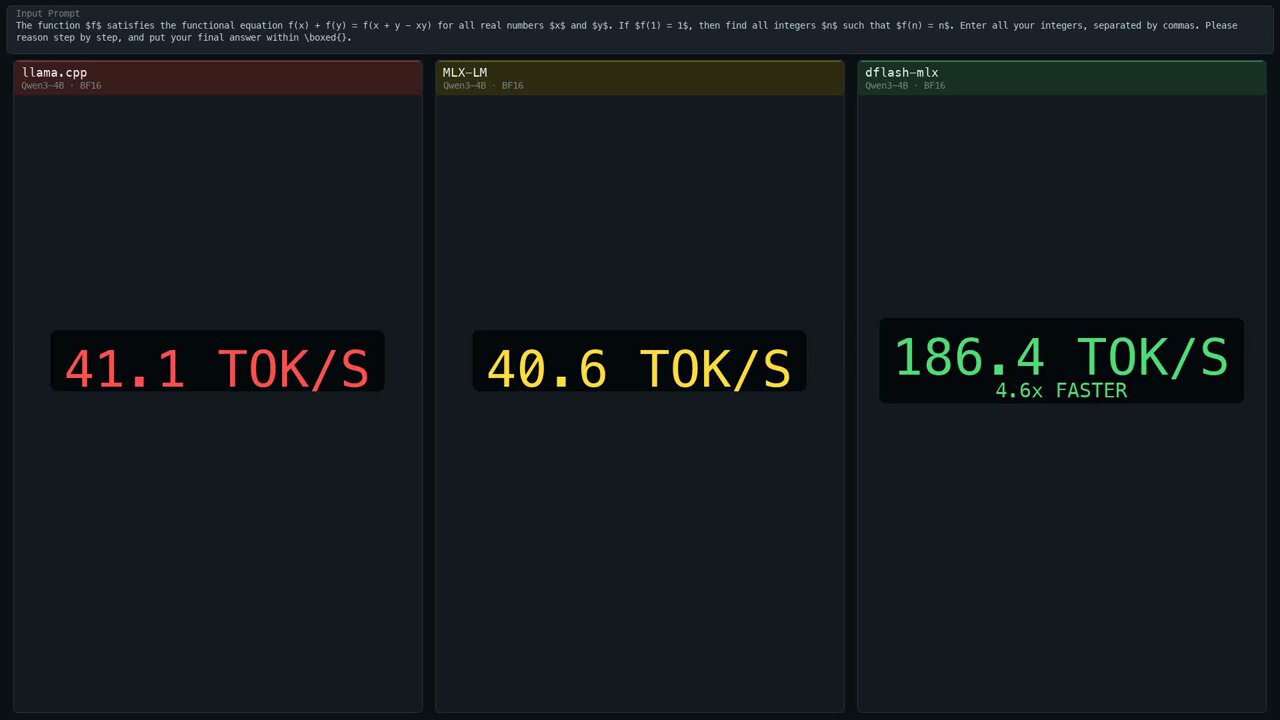
The economics of running AI continue to shift in surprising ways. @aryagm01 announced dflash-mlx, a port of DFlash speculative decoding to Apple Silicon that achieves "Qwen3-4B at 186 tok/s on a MacBook, 4.6x faster than plain MLX-LM" with exact greedy decoding, meaning output matches plain target decoding perfectly. This isn't an approximation or a quality tradeoff. It's pure speed.
@ekzhang1 put cloud GPU economics in perspective with a single line: "$200/month is enough to buy an H100 GPU for 6 hours every workday." For individual developers and small teams, this reframes GPU access from "expensive infrastructure decision" to "monthly tool subscription." Combined with the local inference gains on consumer hardware, the practical compute available to a solo developer in 2026 would have required a small data center five years ago.
AI's Impact on Enterprise Data Infrastructure
@JaredSleeper continued his daily public company teardown series with a deep dive on Snowflake, examining how agent adoption reshapes the data warehouse landscape. The core tension he identifies is architectural: "while Snowflake's query engine works very well at human speeds, upstarts like @ClickHouseDB and @motherduck argue that agents have very different preferences and prefer lightning fast queries."
The most revealing data point came from Snowflake's own earnings call, where management noted that AI-driven efficiency led to "a small reduction in force, about 200 people" and the company "only added 37 people" in Q4 net. Snowflake is simultaneously benefiting from AI adoption (9,100+ accounts using AI features) and being restructured by it internally. The bull case, that agents will generate more analytical queries and Snowflake's consumption pricing captures that upside, is compelling but unproven. As Sleeper notes, "all of the ingredients are there" but "the business impact seems to have been muted thus far." This is a pattern worth watching across the entire enterprise software stack.
Research Workflows and AI-Augmented Discovery
@EXM7777 highlighted the evolution of AI-powered research tools, praising an update to @mvanhorn's /last30days tool, which uses "an AI agent-led search engine scored by upvotes, likes, and real money, not editors." The v3 release adds an intelligent pre-research engine that "resolves X handles, subreddits, TikTok hashtags, and YouTube channels for your topic" before the LLM assembles a report. The key innovation is using social signals as quality filters rather than relying on editorial curation, essentially building a research engine that trusts crowd wisdom over individual gatekeepers. Combined with free access to Reddit, X, and YouTube data, this represents a meaningful step toward democratized competitive intelligence.
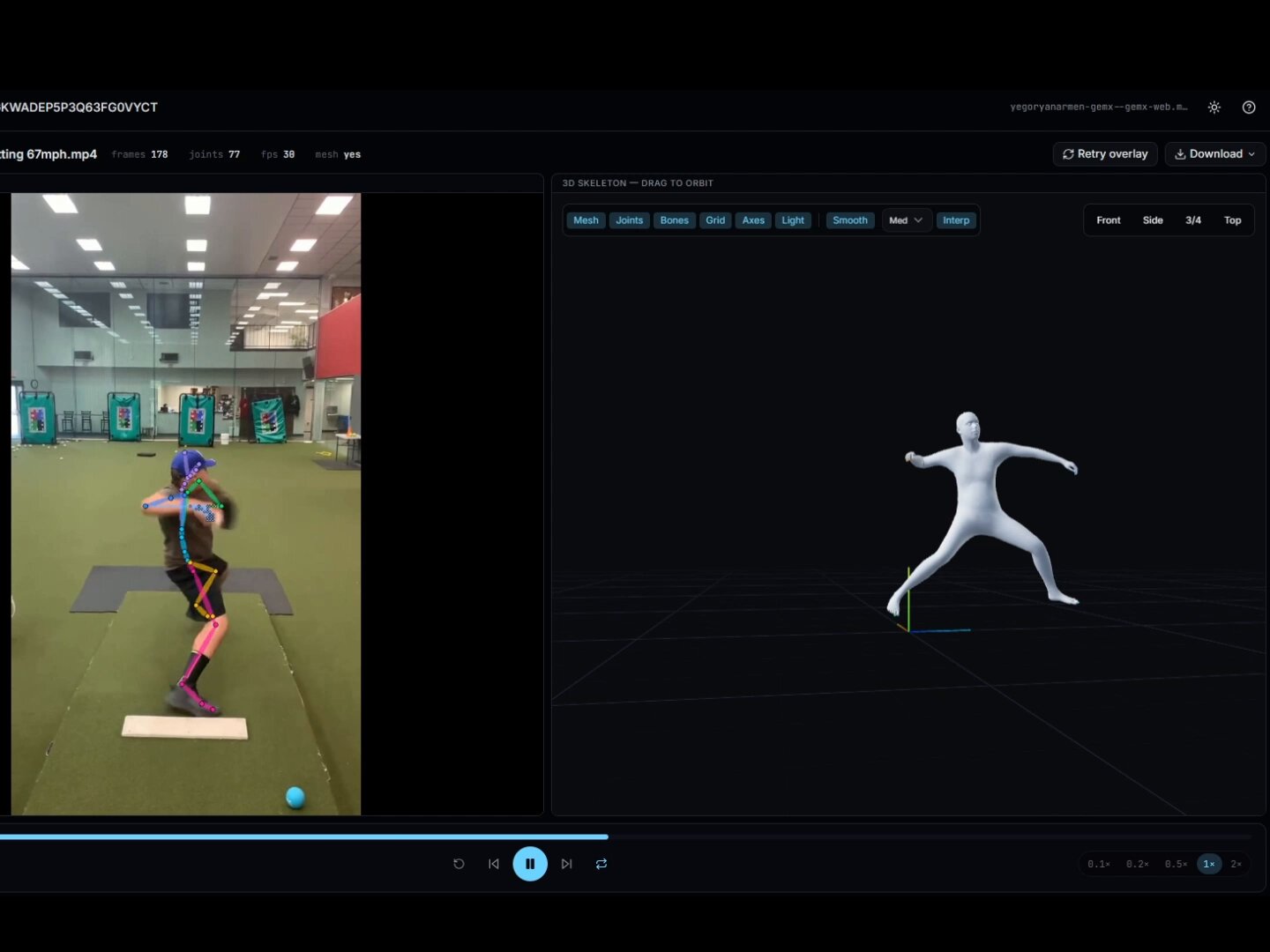
Markerless Motion Capture Goes Handheld
@Armen_Yegoryan demonstrated markerless motion tracking using a single handheld camera with no GPU or CPU usage, running entirely over WiFi and functioning smoothly on a Chromebook. The system handles occlusion by having the AI predict joint positions, and according to the demo, "it nails it every single time."
The provocative claim that "$150K motion capture setups are total scams at this point" is obviously hyperbolic for professional VFX work, but the direction is clear. The gap between consumer-grade and professional motion capture is closing faster than the incumbents would like, driven by pose estimation models that have become remarkably good at inferring what they can't directly observe. For indie game developers, fitness applications, and sports analytics, the implications are immediate and practical.
Sources
v3 of @slashlast30days is here. 20,000+⭐ on GitHub. The biggest upgrade yet. An AI agent-led search engine scored by upvotes, likes, and real money - not editors. Reddit comments, X posts, and YouTube transcripts are now FREE. No API keys needed for the core sources. v3 killer feature: intelligent search. Before it searches, a Python pre-research brain resolves X handles, subreddits, TikTok hashtags, and YouTube channels for your topic. It finds the RIGHT places to search before the LLM judge assembles the report. Shout out to @jeffreysperling for building this engine New in v3: - Free Reddit, X, and YouTube (no API keys) - Intelligent pre-research engine - Best Takes (the funniest Reddit comments are first-class) - Cross-source cluster merging - Single-pass comparisons (X vs Y in 5 min, not 12) - GitHub person-mode - ELI5 mode

GLM 5.1 - Claude Code Killer UNLIMITED and FREE

How I built a real marketing team on OpenClaw that's better than most marketers I've hired

The Patchwright - Out Now! Link in comments. https://t.co/0doZ1yNb5a