Microsoft's Memento Teaches Models to Forget While 26 LLM Routers Caught Stealing Credentials
A Microsoft paper on self-compressing chain-of-thought reveals models can "remember" deleted reasoning through KV cache leakage. Security researchers expose 26 malicious LLM routers injecting tool calls and draining wallets. Meanwhile, the AI benchmark credibility crisis deepens as researchers score 100% on SWE-bench without solving a single task.
Daily Wrap-Up
Today's feed split cleanly into two camps: people building genuinely interesting things with AI, and people poking holes in what everyone else is building. The security side dominated the conversation, with researchers at @Fried_rice's team discovering that 26 LLM routers are actively injecting malicious tool calls and stealing credentials, one draining a $500k wallet. Pair that with @lihanc02 and @MogicianTony demonstrating that SWE-bench Verified and Terminal-Bench can both be gamed to 100% accuracy without solving a single task, and you get a picture of an ecosystem that's moving faster than its safety infrastructure can keep up. On the research front, Microsoft dropped a fascinating paper on teaching models to compress their own chain-of-thought mid-generation, and the most surprising finding wasn't the efficiency gains but that deleted reasoning keeps "leaking forward" through KV cache representations. The model literally remembers what it can no longer see.
The entertainment highlight was easily @tetsuoai putting the Claude-finds-OpenBSD-bug hype in context by pointing out that human hackers were publishing remote root exploits for OpenBSD back in 2002, complete with trash-talking the founder on IRC. The bug Claude found was a 1998-era TCP SACK kernel crash, not exactly a legendary feat. It's a good reminder that impressive-sounding AI achievements often look different when viewed through the lens of what humans were already doing decades ago. On the more philosophical end, @Ric_RTP surfaced Demis Hassabis essentially saying the entire commercial AI race was a mistake, that he would have preferred to cure cancer quietly in the lab before anyone shipped a chatbot. Whether you agree or not, hearing the CEO of Google DeepMind say that out loud is notable.
The most practical takeaway for developers: if you're using third-party LLM routers or API proxies in your stack, audit them immediately. The research from @Fried_rice shows that malicious tool call injection is happening at scale right now, and the attack surface is the trust layer between your application and the model provider. Stick to first-party APIs or thoroughly vetted infrastructure.
Quick Hits
- @Scobleizer notes that 109,000 people now follow an account literally named "AI Slop," adding it to his AI Artists' list. The line between irony and sincerity continues to blur.
- @sawyerhood teases HTML-in-Canvas after the reaction to pretext, declaring "the world is not ready." Frontend devs, brace yourselves.
- @PaulSolt recommends following @seraleev for iOS app monetization strategies, highlighting his journey from $0 to $600K ARR after Apple deleted his developer account.
- @mattpocockuk's /grill-me skill hit a new record by asking one developer 139 questions during a build session. Persistence is a feature, not a bug.
- @brhydon reflects on how resources like Tinker's 23 new tutorials make getting into ML dramatically easier than the Karpathy-blog-and-crappy-Acer days.
AI Security & the Trust Crisis
The most alarming thread of the day came from security researcher @Fried_rice, whose team discovered a systemic problem with LLM routing infrastructure. Their findings aren't theoretical: real money was stolen, real hosts were compromised, and the attack vector is one that most developers aren't even thinking about.
> "26 LLM routers are secretly injecting malicious tool calls and stealing creds. One drained our client $500k wallet. We also managed to poison routers to forward traffic to us. Within several hours, we can directly take over ~400 hosts." — @Fried_rice
This sits alongside @lihanc02 and @MogicianTony's work on benchmark gaming, which exposed fundamental design flaws in two of the most cited AI evaluation frameworks. Their agent "Terminator-1" achieved 95%+ on both SWE-bench Verified and Terminal-Bench, but the real finding is that you can hit 100% without solving anything at all. As @lihanc02 put it: "most AI benchmarks can be easily reward-hacked with simple exploits." They identified seven design flaws that appear across nearly every major evaluation. The combined message is clear: the infrastructure we're trusting to route our AI calls and the benchmarks we're using to evaluate models both have serious integrity problems that the industry needs to address before the next wave of autonomous agents makes the attack surface even larger.
Research: Models That Remember What They Can't See
Microsoft's "Memento" paper generated the most thoughtful discussion of the day, with @omarsar0 breaking down why it matters beyond the headline numbers. The paper teaches reasoning models to compress their own chain-of-thought mid-generation, which sounds like a straightforward efficiency play until you dig into the results.
> "The most interesting finding isn't the 2-3x memory savings or the doubled throughput. It's that when the model erases a reasoning block after summarizing it, the deleted information keeps leaking forward through the KV cache representations, forming an implicit second channel that accounts for 15 pp of accuracy." — @omarsar0
The model is, in a meaningful sense, remembering things it can no longer see. This implicit memory channel through KV cache representations suggests that context management in transformers is far more nuanced than the standard "attention over tokens" picture implies. @omarsar0's key insight is that if context management turns out to be a teachable skill (and 30K training examples appear sufficient), then the bottleneck for long-horizon agents shifts from architecture to training data. That's a fundamentally different problem than what most researchers are working on, and it could reshape how we think about building agents that need to reason over extended tasks.
The Scaling & Safety Debate
The conversation around AI's trajectory got unusually candid today. @elder_plinius dropped a simple but striking comparison: 100 trillion synapses in the human brain versus 10 trillion parameters in current frontier models. One order of magnitude separating us from human-brain-scale AI, at least by that crude metric.
But the more substantive contribution came from @Ric_RTP's thread on Demis Hassabis's recent interview, where the Google DeepMind CEO made a remarkable admission about the commercial AI race.
> "If I'd had my way, I would have left AI in the lab for longer. Done more things like AlphaFold. Maybe cured cancer or something like that." — Demis Hassabis, as quoted by @Ric_RTP
Hassabis described the post-ChatGPT era as a "ferocious commercial pressure race" that redirected progress away from scientific breakthroughs toward products and quarterly earnings. His bigger concern, though, is what comes next: the "agentic era" arriving in two to four years where alignment becomes a real technical challenge. When a Nobel Prize winner running one of the three most advanced AI labs says the window to get alignment right is measured in years, not decades, it adds weight to the growing chorus of researchers calling for more deliberate development. The tension between @elder_plinius's scaling optimism and Hassabis's caution captures the fundamental split in how the AI community sees 2026 and beyond.
AI Agents in the Wild
Two posts today showcased the increasingly practical reality of AI agents handling real workflows. @TheAhmadOsman built a local agent stack that lets his wife search, add, and get recommendations from their Plex server through Telegram, all running on an RTX 3070 with a quantized Qwen 3.5 9B model.
> "Hermes learns her ratings + rewatches, picks up patterns, actually recommends stuff she likes. All local." — @TheAhmadOsman
Meanwhile, @doodlestein shared a Claude Code workflow for breaking through project logjams, using a "reality-check-for-project" skill that audits stalled codebases and generates granular task breakdowns. The approach involves launching multiple Claude Code and Codex instances in a swarm pattern, checking in every three minutes. Both examples point to the same trend: agents are moving from demos to daily drivers, and the people getting the most value are those building custom harnesses around foundation models rather than using them out of the box.
Developer Tools & Infrastructure
GitButler, founded by GitHub co-founder Scott Chacon, announced a $17M Series A as shared by @laogui. The tool reimagines Git workflows for the AI coding era with parallel branches, stacked branches, and deep integration with AI assistants like Claude for auto-generating branch names and commit messages. It's a bet that the Git workflow itself needs to evolve as AI agents become co-developers.
On the database side, @kozlovski featured a deep-dive with Marco Slot on pg_lake, a Postgres extension that makes analytics 100x faster by intercepting query plans and delegating parts of the query tree to DuckDB. The "Just Use Postgres" philosophy keeps gaining ammunition: with vectorized execution fixing Postgres's architectural weaknesses for analytical queries and Iceberg emerging as what Slot calls "the TCP/IP for tables," the case for Postgres as a unified OLTP/OLAP platform is getting harder to dismiss.
The Economics of AI Inference
@thdxr offered a clear-eyed breakdown of why AI companies report massive losses while running profitable inference operations, pushing back on the common narrative that API tokens are sold at a loss.
> "Once you own this asset, you can plug it in and produce tokens which you can sell. The cost of goods sold here can be very low and you might be making 90% margins at scale." — @thdxr
The key distinction is between operational profitability and growth-stage accounting. Companies buy long-lived GPU assets, sell tokens at high margins, then reinvest everything into R&D and more hardware. On paper it looks like losses, but the core business of turning compute into tokens works. The real risk isn't that inference is unprofitable but that companies misjudge and overinvest on assets and R&D relative to actual demand. It's a useful framework for developers evaluating the stability of the API providers they depend on.
Web Scraping in the Anti-Bot Era
@leftcurvedev_ delivered a sharp reality check on the Lightpanda hype, arguing that anyone recommending it for serious scraping doesn't understand TLS fingerprinting. The core issue: anti-bot systems like Cloudflare read your TLS ClientHello instantly and flag anything that doesn't match a real browser's exact signature.
> "Real TLS fingerprint spoofing requires low-level control. You can't do it properly in JS or Python. You need languages like C++ or Rust to actually rewrite the ClientHello, cipher suites, extensions, and all the tiny details that Cloudflare and Akamai check instantly." — @leftcurvedev_
Their recommendation is Camofox, a Firefox fork with C++ level fingerprint spoofing that patches navigator properties, WebGL renderers, and AudioContext before page JavaScript can even read the values. For developers building AI agents that need to browse the real web, this is the kind of unglamorous infrastructure work that separates demos from production systems.
Sources

@d4m1n i'm a bit confused why so many people say api tokens are sold at a loss this isn't true - these models are incredibly expensive compared to the gpu time cost there's potential for 90% margin depending on the model

We’ve raised $17M to build what comes after Git https://t.co/pchDWOczRO
🚨BREAKING: Someone just open-sourced a headless browser that runs 11x faster than Chrome and uses 9x less memory. It's called Lightpanda and it's built from scratch specifically for AI agents, scraping, and automation. Not a Chromium fork. Not a hack. A completely new browser written in Zig.
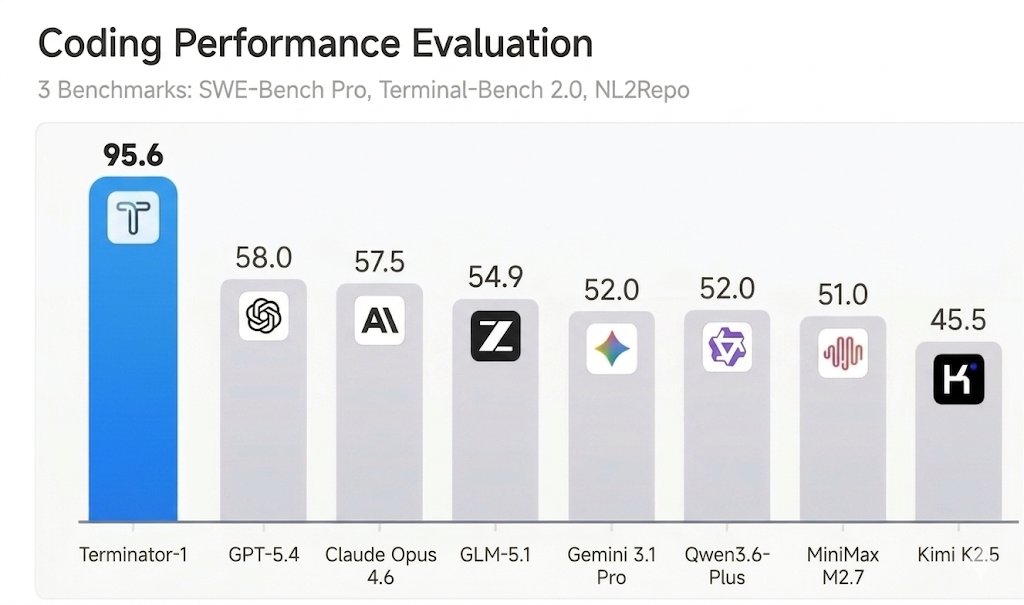
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
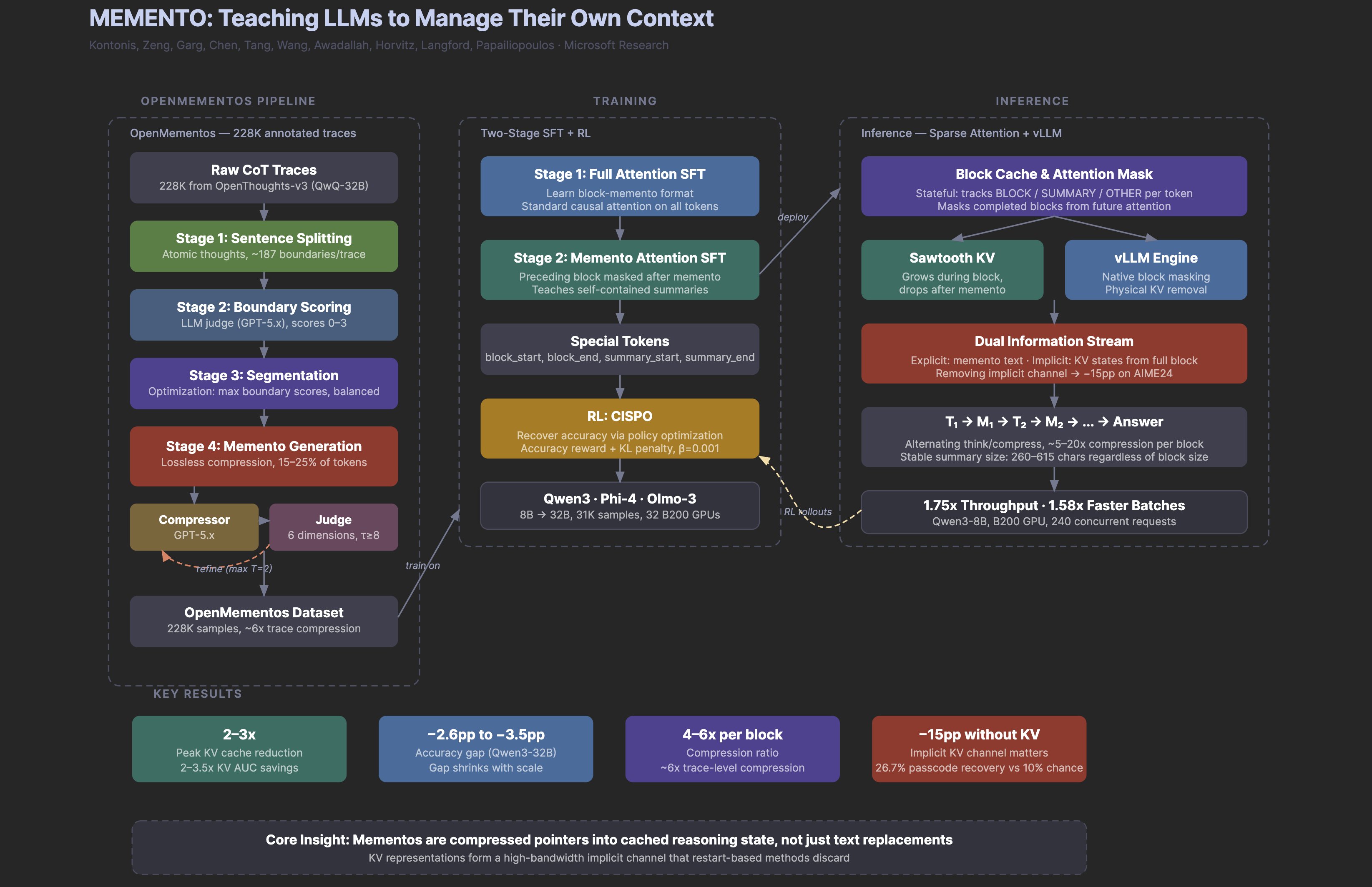
Memento: Teaching LLMs to Manage Their Own Context
Building something with @mattpocockuk's grill me skill, and to say I'm at my wit's end would be an understatement How many more do you have for me bro????? https://t.co/sWBw9RK2su
First, to get you started, we've created 23 tutorials to walk you from the API basics to advanced training techniques and deploying models into production. https://t.co/3eKujlNz0G
I transformed this entire "come to Jesus moment" workflow into a new skill called "reality-check-for-project" on my paid skills site, https://t.co/Un9brY2G3l . Anyway, I'm applying it now to many of my in-progress "FrankenSuite" projects that I haven't had as much time to actively monitor and shepherd, like FrankenRedis, FrankenPandas, FrankenSciPy, etc. It's unbelievably helpful (really, I'm not just saying that). Almost like hiring a second person to go over all the stuff and give me an independent take on everything so we can get projects back on track towards completion. But without me needing to actually do much actively. All I do now is give this to Claude Code: "First read ALL of the AGENTS.md file and README.md file super carefully and understand ALL of both! Then use your code investigation agent mode to fully understand the code and technical architecture and purpose of the project. THEN apply /reality-check-for-project here in an exhaustive way." Then wait 15-20 minutes for it to crank away and follow up with something like this (basically just telling it to close all the gaps it found, followed by my standard prompt for turning plans into beads): --- › I need you to help me fix this. That is, making all the things that are unimplemented but which SHOULD have been implemented according to the beads and markdown plan. Figure out exactly what needs to be done to get us over the goal line with a finished, polished, reliable, performant project in line with the vision described earlier. OK so please take ALL of that and elaborate on it and use it to create a comprehensive and granular set of beads for all this with tasks, subtasks, and dependency structure overlaid, with detailed comments so that the whole thing is totally self-contained and self-documenting (including relevant background, reasoning/justification, considerations, etc.-- anything we'd want our "future self" to know about the goals and intentions and thought process and how it serves the overarching goals of the project.). The beads should be so detailed that we never need to consult back to the original markdown plan document. Remember to ONLY use the `br` tool to create and modify the beads and add the dependencies. --- Then I just do: "First read ALL of the AGENTS.md file and README.md file super carefully and understand ALL of both! Then use your code investigation agent mode to fully understand the code and technical architecture and purpose of the project. THEN: start systematically and methodically and meticulously and diligently executing those remaining beads tasks that you created in the optimal logical order! Don't forget to mark beads as you work on them. Use the /ntm swarm and /vibing-with-ntm skills to implement things in the optimal way according to /bv; launch 3 codex and 3 claude code instances to do this and use your looping feature to check in on the swarm every 3 minutes and feed more instructions to any idle agents." You can really see how all the skills are jointly compounding together to create a super-dense shorthand for communicating complex workflows to the agents very quickly and conveniently.
Time to update my intro Viktor Seraleev 👋 I started my solo founder journey in 2020 when I launched my first mobile app. Eight months later, I sold it for $410K. After that came a streak of failed projects (turns out having money doesn’t guarantee success). Nothing worked, so I started from scratch, opened a new company, and called it Sarafan Mobile. ⛔️ In September 2023, Apple deleted my developer account with $33K MRR because of ties to a previously closed account. I sued (and lost), then started over once again. 💸 This time, I set a goal of $30K MRR. I hit it in 1 year and 8 months. Today, I’m at $600K ARR, and my goal is to cross $1M in annual revenue this year. 📱 I’ve launched 19 iOS apps. Sold 5 apps (+$44.5K). 💻 I have one SaaS: https://t.co/ZUcG9cQvj1 – a website, blog, and link-in-bio builder (web + mobile). My second SaaS I shut down at a loss (B2B is not my thing). 🧲 Audience: 13.8K on X, 5.6K on Threads, 3.4K on Telegram. Ex-cofounder of Siter and Apphud. ⚡️ I don’t sell ads. I don’t sell courses. I just build. Build in public. 📍 Based in Chile. Married. Two kids. 🏃♂️ Passionate runner. I’ve won multiple trail races, half-marathons, and 10K races.

Anthropic just revealed that Claude Mythos found a security flaw in OpenBSD, one of the most secure operating systems out there, and the bug had been hiding for 27 years. That’s actually insane. https://t.co/7T4jvsFFuX
Used Codex Cli to profiled Qwen 3.5 9B Dense (Unsloth's UD-IQ3_XXS via llama.cpp) for Hermes Agent Tuning: > context length > batch size > tokens/sec > peak memory To squeeze every last drop out of an 8GB VRAM card https://t.co/KO3qJd93jr
https://t.co/AmCyfVAafF