Fused CUDA Kernels Beat Apple Silicon While Agent Frameworks Flood GitHub Trending
Today's feed was dominated by the agent framework explosion, with five separate multi-agent projects trending on GitHub simultaneously. Meanwhile, hardware-specific kernel optimization proved a $900 RTX 3090 can outrun Apple's M5 Max, and Anthropic's Managed Agents architecture drew comparisons to AWS's early infrastructure play.
Daily Wrap-Up
The AI agent gold rush has officially hit the "five trending repos in one day" phase. From portable agent file formats to military-style simulation environments, the open source community is building out every layer of the agent stack simultaneously. What's notable isn't any single project but the sheer breadth of the tooling gap being filled: memory persistence, cross-framework portability, standardized tool integration, and pre-deployment testing. The infrastructure for agents is being built in public and at speed, and it's starting to look less like experimentation and more like an emerging standard stack.
On the performance side, today brought a satisfying reminder that hardware capabilities are often bottlenecked by software laziness. A single fused CUDA kernel covering all 24 layers of Qwen 3.5-0.8B pushed an RTX 3090 to 411 tokens per second, beating Apple's latest M5 Max by 1.8x. Pair that with Microsoft's BitNet.cpp enabling 100B parameter models on CPU-only machines, and the "you need expensive hardware" narrative continues to erode. The TriAttention paper showing 81% KV cache compression at 60K tokens rounds out a day where inference efficiency was the quiet but powerful undercurrent beneath the agent hype.
The most entertaining moment was easily @noisyb0y1's deadpan security callout about Claude Code reading wallet seed phrases and SSH keys, formatted like a greentext post. It hit that perfect intersection of genuinely important and darkly funny. The most practical takeaway for developers: if you're building agent workflows, spend today looking at the TriAttention paper for KV cache compression and the agent file format (.af) from Letta. The former will directly reduce your inference costs at long contexts, and the latter solves the unglamorous but critical problem of making agents portable across projects without losing their state.
Quick Hits
- @elonmusk pitched Boring Company Hyperloop tunnels as costing less than 5% of California's high-speed rail, quoting @HansMahncke's math that $126B could fund 150-200 years of free LA-SF flights instead.
- @ty_kra_lab teased parametric software that generates editable code for vibecoding apps, calling it "the world's first hardware device manufacturer." The claims are bold; the demo is a video thumbnail.
- @PaulSolt highlighted @seraleev's thread on app monetization fundamentals: clean icons, quality screenshots, onboarding-first paywalls. Old advice, still ignored by most indie devs.
- @mattpocockuk shared a prototyping workflow using Claude Code skills to generate multiple radically different UI designs with a picker to toggle between them, riffing on an @adamwathan demo.
- @elonmusk shared a video with the caption "Not someone you want in charge of superpowerful AI," continuing his ongoing commentary on AI governance without naming names.
- @TheAhmadOsman RT'd someone saying Qwen 3.5 9B works fine as a personal assistant, replacing their Anthropic subscription. The local-model-is-good-enough crowd grows louder every week.
The Agent Framework Explosion
Five agent-related repositories trending on GitHub in a single day marks a inflection point, and @GitTrend0x catalogued all of them. The projects span the full lifecycle: camel-ai/owl for multi-agent collaboration (1,287 stars in 24 hours), letta-ai/agent-file for portable agent state, simstudioai/sim for pre-deployment simulation, iflytek/astron-agent for enterprise orchestration, and mcp-use/mcp-use for standardized tool integration.
What makes this wave different from previous agent hype cycles is the focus on operational concerns rather than capabilities. The agent-file format (.af) is particularly telling. As @GitTrend0x described it, agents used to be "like goldfish, forgetting everything in 7 seconds," but now you can package memory, behavior, and state into a portable container. Similarly, the Sim studio addresses the classic "works in demo, explodes in production" problem by letting you stress-test multi-agent workflows before deployment.
Meanwhile, Anthropic formalized its own answer to the agent infrastructure question. @PawelHuryn spent two hours dissecting Managed Agents and came away comparing it to AWS: "Separating instructions from execution is one of the oldest patterns in software. Microservices, serverless, message queues. Agents just caught up." The architecture splits agents into Brain (reasoning), Hands (disposable execution containers), and Session (durable event logs), with credentials never entering the sandbox. At $0.08 per active session-hour, Anthropic is pricing this as infrastructure, not a product. The enterprise implications are significant, especially when @aakashgupta points out that Workday alone processes 365 billion transactions per year across 65 million users, noting that "the company that figures out how to let AI agents touch payroll without blowing up compliance will own enterprise AI for the next decade."
Inference Optimization: The Quiet Revolution
Today's most technically impressive development flew under the radar compared to the agent hype. @sudoingX broke down how @pupposandro wrote a single fused CUDA kernel for all 24 layers of Qwen 3.5-0.8B, eliminating every CPU round-trip between layers. The result: "a $900 RTX 3090 from 2020 hit 411 tok/s. Apple's M5 Max hit 229. The 3090 won on speed AND efficiency, 1.55x faster than llama.cpp on the same hardware." The key insight is that the gap between NVIDIA and Apple "was never about silicon. It was software."
This pairs naturally with @Prince_Canuma's implementation of TriAttention in MLX, which achieved 81% KV cache compression at 60K tokens on Gemma-4-31B. The benchmarks are striking: KV cache stays capped at 0.82 GB regardless of context length, and decode speed actually improves over baseline at long contexts. The caveat that it works better for generative tasks than retrieval is worth noting, but for reasoning and code generation workloads, this is a significant efficiency gain.
And then there's @spiritbuun's cryptic tease: "Had a huge breakthrough in quantizing weights today. You have no idea how small we're going and how high quality we're going." No details, no paper, just vibes. But given the trajectory of the field, breakthroughs in quantization have immediate practical impact for anyone running models locally.
Local AI Goes Mainstream
Microsoft's BitNet.cpp update landed with a splash, and @outsource_ laid out the numbers: 100 billion parameter models running on CPU alone at human reading speed (5-7 tokens per second), with 82% lower energy usage and 6.17x faster inference on x86. Built on llama.cpp with full GGUF support, this isn't a research demo. It's a shipping framework.
On the more experimental end, @masonwang025 trained Llama 2 on a $5 Raspberry Pi Zero, building an entire ML library called PiTorch from scratch, "from writing assembly GPU kernels to sending bytes over wires." It's not practical for production, but it's a remarkable educational project that demystifies what's actually happening at the hardware level. The convergence of these two stories paints a clear picture: the floor for running meaningful AI models locally keeps dropping, whether you're optimizing for a data center CPU or a thermostat-grade computer.
AI Security and Code Capabilities
@noisyb0y1 dropped a thread formatted like a 4chan greentext that was equal parts alarming and entertaining: "installed Claude Code 3 months ago, never opened the security settings, Claude reads your wallet seed phrases, Claude reads your SSH keys, can send data anywhere it wants, one CLAUDE.md file in a cloned repo, your data is already gone." The framing is dramatic, but the underlying point about supply-chain attacks via prompt injection in cloned repositories is legitimate and increasingly relevant as coding agents gain filesystem access.
On the more optimistic side of AI code capabilities, @facontidavide reported that Claude Code "invented" a new lossless codec on the Pareto frontier, beating QOI in speed while matching PNG compression ratios. And @thdxr offered a nuanced take on whether open-source models can match proprietary systems for vulnerability detection: "if it says every file has a vuln and 99% of them are wrong it's useless." The tension between capability and reliability in AI-assisted security remains unresolved, but the fact that both the attack surface and the defensive tooling are expanding simultaneously feels like the defining dynamic of this moment.
Microsoft's Markdown Pipeline
@_vmlops highlighted Microsoft's tool for converting any file format into clean markdown for LLM consumption: PDFs, Word docs, Excel, PowerPoint, audio, YouTube URLs. "One pip install and your AI pipeline stops choking on raw files forever." It's not glamorous work, but data ingestion remains one of the most common failure points in LLM pipelines, and a standardized conversion layer from Microsoft could save countless hours of custom parser development. Sometimes the most impactful tools are the most boring ones.
Sources
V
MICROSOFT BUILT A TOOL THAT CONVERTS LITERALLY ANYTHING INTO CLEAN MARKDOWN FOR YOUR LLM
pdfs. word docs. excel. powerpoint. audio. youtube urls
one pip install and your AI pipeline stops choking on raw files forever
no custom parsers. no broken layouts. no garbled text.
just clean, structured markdown your LLM can actually read
https://t.co/RSt0CczfYa
M
i trained Llama 2 on a $5 computer with less processing power than a thermostat.
it’s called 🥧 PiTorch: an ML library for Raspberry Pi Zeros.
i cover how to make it from scratch, from writing assembly GPU kernels to sending bytes over wires. (no hardware background needed!)

T
You won’t believe how disruptive this software I’m building is.
It’s not 3D; it’s actually code you can then use with a vibecoding app to create real software. You’ll have complete control over anything you want to edit. This isn’t just a 3D model; it’s the foundation for every vibecoding app available. Since the model is based on parametric software algorithms it’s incredibly versatile.
Inventing the world’s first hardware device manufacturer.

P
This is Anthropic's AWS moment. I spent 2 hours studying the architecture of Managed Agents. Here's everything you need to know.
The default way to build an agent is a single process. The model reasons, calls tools, runs code, and holds your credentials — all in the same box. If someone tricks the model via prompt injection, it can execute malicious tool calls with the credentials it already has.
Nvidia tackled this with NemoClaw — separating agent capabilities from security. Anthropic took a different approach.
Managed Agents splits every agent into three components:
→ Brain: Claude and the harness that routes decisions
→ Hands: disposable Linux containers where code executes
→ Session: a durable event log that survives both crashing
Credentials never enter the sandbox. Git tokens are wired at init and stay outside. OAuth tokens live in a vault, fetched by a proxy the agent can't reach.
The same design also improved performance. Old way: boot a container before the model can think. New way: brain starts reasoning immediately, spins up containers when needed. Median time to first token dropped 60%.
Session tracing is built into the console. The Agent SDK supports OpenTelemetry — pipe traces to Datadog, LangSmith, Langfuse. Evals and monitoring live there.
Price: $0.08 per session-hour of active runtime. Idle time doesn't count. Model token costs on top at standard API rates.
Separating instructions from execution is one of the oldest patterns in software. Microservices, serverless, message queues. Agents just caught up.
Anthropic is betting they'll be the ones who host them.
T
trq212
@trq212
Managed Agents is the first 'agent in the cloud' API that has the right mix of simplicity and complexity. Implementation details like how you manage a sandbox are abstracted, but you have a lot of control over the actual execution of the model.
D
Claude Code just "invented" a new lossless codec on the Pareto frontier 🤯 https://t.co/TWvi5cJamj

F
facontidavide
@facontidavide
Fun project of the day. I have an AI Agent autonomously trying to create a novel lossless image compression that achieves ratios similar to PNG but beats QOI in speed. I will let you know how this goes
P
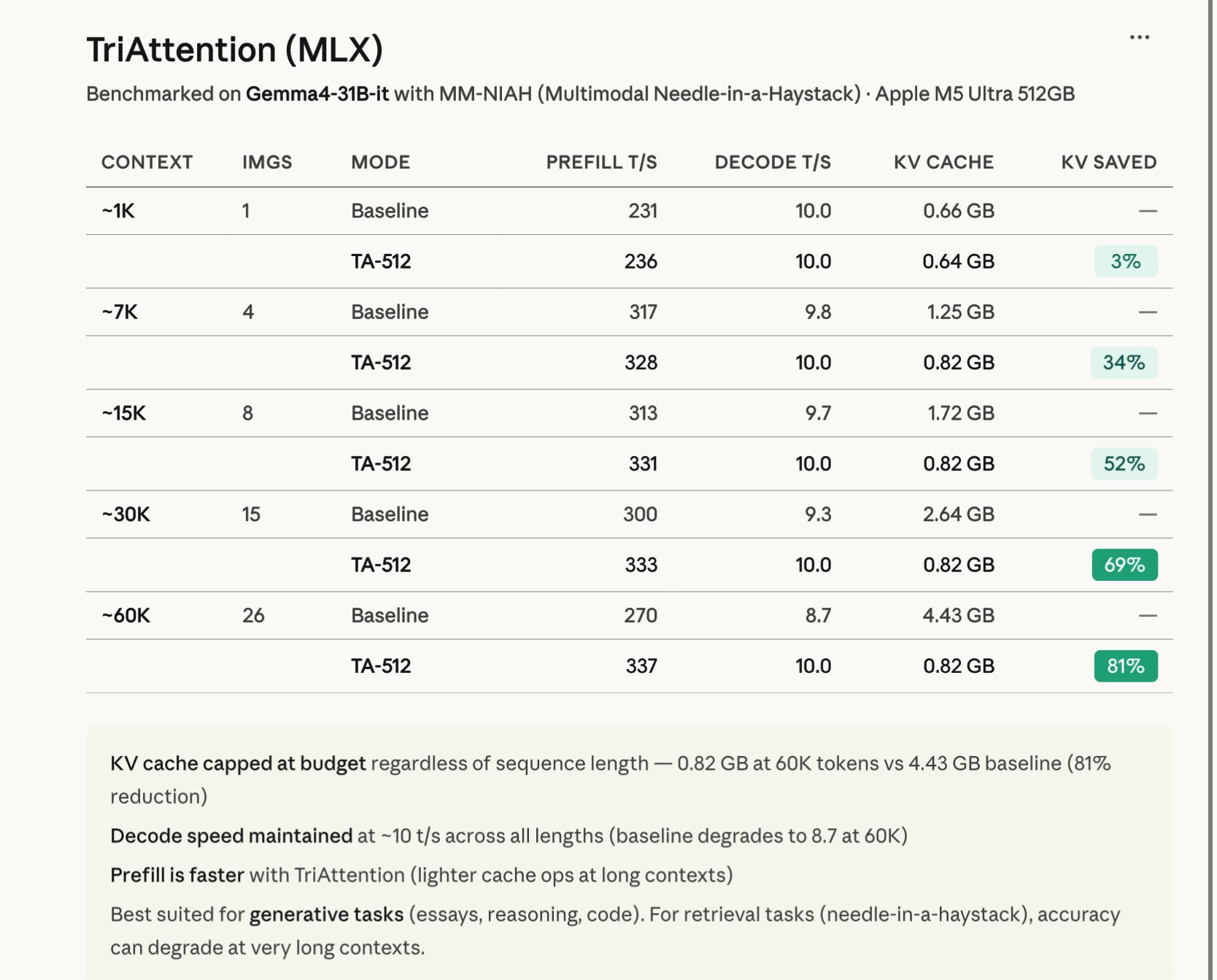
Just implemented TriAttention in MLX and the results are wild!
You can get up to 81% KV compression at 60K tokens for Gemma-4-31B-IT in BF16 🔥
Unlike TurboQuant, which quantizes KV cache values, TriAttention prunes low-importance tokens entirely by scoring keys using trigonometric series from pre-RoPE Q/K concentration and keeping only the top-B most important ones.
The best part? Decode speed for BF16 stays locked at ~10 t/s while baseline drops to 8.7 at long contexts. This results scale well with the quantized version as well.
Benchmarked on Gemma4-31B-it with MM-NIAH on M5 Ultra:
~1K → 3% saved
~7K → 34% saved
~15K → 52% saved
~30K → 69% saved
~60K → 81% saved
KV cache capped at 0.82 GB regardless of context length.
One-time calibration (~30s), then it just works during generation.
One caveat: TriAttention by design is best suited for generative task (reasoning/code) and not retrieval tasks.
PR will follow soon on MLX-VLM.
Y
yukangchen_
@yukangchen_
We’re thrilled to open-source TriAttention! 🚀 🦞 Deploy OpenClaw (32B LLM) on a single 24GB RTX 4090 locally 💻Full code open-source & vLLM-ready for one-click deployment ⚡️ 2.5× faster inference speed & 10.7× less KV cache memory usage TriAttention is a novel KV cache compression method built on rigorous trigonometric analysis in the Pre‑RoPE space for efficient LLM long reasoning. Github Repo: https://t.co/Gpu4E9oo3v Paper Link: https://t.co/DIWxgvlsjN Homepage: https://t.co/pDFK3mq53O
G
今天 GitHub 被一人顶十人 Agent军团彻底屠榜了🚀
5 个星标暴增最狠的项目,专业拆解下!
1. camel-ai/owl
多智能体协作框架,让专业化 Agent通过浏览器、终端、函数调用和 MCP工具实现无缝团队作战,GAIA 基准测试位居开源榜首,彻底解决单 Agent复杂任务易崩盘的痛点。
🔗 直达 https://t.co/bwuVaqgbim
程序员昨晚还在一个人肝 PR,今早醒来发现 Agent军团已经把需求拆解、代码生成、测试覆盖全自动跑完,醒来直接“卧槽,我被 AI开除了吗?”。24h暴增1287星,这军团感直接把“一个人=10人团队”干成了现实!
🟢
2. letta-ai/agent-file
开源 Agent文件格式(.af),把记忆、行为和状态完整打包成可移植容器,实现跨框架版本控制和无缝迁移,终结了“Agent换个项目就失忆”的历史性难题。
🔗 直达 https://t.co/LfPHHq8SU7
以前 Agent 像金鱼,7秒忘事;现在打包成.af文件,U盘一样插哪用哪,同事问你怎么让Agent跨项目不翻车,你直接甩文件过去:“哥,这才是真正的Agent永生术”。24h 暴增 893星,程序员直呼内行!
🟢🟢
3. simstudioai/sim
AI Agent 模拟与构建工作室,提供生产级编排、测试环境和真实场景仿真,一键验证多 Agent工作流是否会在野外翻车,从此告别“上线即爆炸”的血泪史。
🔗 直达 https://t.co/zWMZ8fID31
让你的Multi-Agent上战场前先“军演”?直接扔进 Sim跑一遍,昨天还默默无闻,今天开发者狂刷终于敢让Agent 干活了。 24h暴增 756星,画面感拉满,肝代码的都沉默了!
🟢🟢🟢
4. iflytek/astron-agent
科大讯飞开源高性能多 Agent框架,专注实时协作与复杂工作流自动化,内置企业级编排能力,让 Agent 从单打独斗直接进化成协同作战部队。
🔗 直达 https://t.co/G170GG3AXI
科大讯飞把 Agent 玩出花,astron-agent一上线,朋友圈全是以前一个人debug 到凌晨,现在 Agent 们自己开会了”。24h暴增612星,程序员集体觉醒:这才是降维打击!
🟢🟢🟢🟢
5. mcp-use/mcp-use
MCP 协议即插即用工具链和服务器套件,为多 Agent系统提供标准化工具集成通道,把 MCP 服务器从黑魔法变成人人可用的标配。
🔗 直达 https://t.co/s2cKQWoDJU
MCP服务器满天飞,这 repo 直接把MCP 玩成 Agent标配,以前工具调用卡成 PPT,现在一键接入 Agent 直接变身超级英雄。24h 暴增 489星,程序员吐槽终于不用手搓胶水了!
⚠️⚠️
总结
这 5个 Agent 项目从单兵突击到军团协作、从记忆永存到 MCP标准化、再到模拟战场和实时自动化,把一人顶十人从 PPT 彻底干成了 GitHub 日常,开发者们,冲🧠🤖🚀
B
Had a huge breakthrough in quantizing weights today. Holy fug. You have no idea how small we're going and how high quality we're going. Soon.
E
🚨 MICROSOFT NEW BITNET.CPP ALLOWS YOU TO RUN 100B MODELS LOCALLY
🔥Official inference framework for 1-bit LLMs.
It lets you run massive 100 billion parameter models on a regular CPU
Human reading speed — 5–7 tokens/sec
Zero GPU needed.• Up to 6.17× faster inference on x86
• 82% lower energy use
• Built on llama.cpp
• Full GGUF support + lossless ternary weights
No cloud. No expensive hardware.
True local 100B AI is here 👇🏻
https://t.co/j9XF9CXznl

P
This is how you make money from apps.
Viktor is a PRO app developer.
S
seraleev
@seraleev
When devs used to tell me they couldn’t reach their first $100, I didn’t believe it. A lot of them asked me where to get installs. Then I looked at their apps and honestly, it was rough. You don’t need installs, you need to fix your product and first impression ASAP: 1. Make a clean, stylish, and clear ICON. This is your very first touchpoint with the user, it matters more than you think. 2. Create high-quality SCREENSHOTS. No blurry text, no stretched devices. If you can’t do it yourself, hire a designer. 3. Build a solid ONBOARDING. Don’t cut corners here. In 3–4 steps, clearly show what your app does and why it’s useful. 4. Add a paywall AFTER onboarding. It’s simple. Offer your product confidently. In my apps, 80% of revenue comes from the first session. I don’t get why people skip this. 5. Most important: create a STEP-BY-STEP user flow. No cluttered screens. One step = one action. If you’ve done all five, then you can start thinking about user acquisition. But that’s a completely different game.
D
there's an article floating around claiming OSS models could find the same vulns as mythos
it's a bit confusing though - in this test they pointed it towards the problematic code and even very tiny models could find the problem
but that's a bit different than discovering the problem in the first place so this isn't to say mythos isn't something special
but it's further complicated by how cheap these models are because maybe you could blindly run this against every file for cheap?
but that's further complicated because if it says every file has a vuln and 99% of them are wrong it's useless
but also i'm pretty sure mythos had expert security researchers narrowing down where to look
but maybe it wasn't that narrow
anyway this stuff is really complicated

A
The math on what Workday actually sits on top of should scare every AI agent startup.
$9.5 billion in annual revenue. 60%+ of the Fortune 500 running payroll and financials through the platform. 65 million users generating 365 billion transactions per year. Every employee's salary, every benefits election, every vendor payment, every financial close.
Now imagine AI agents operating inside that. An agent that can query compensation data, approve expense reports, trigger wire transfers, modify headcount plans. The upside is massive. The attack surface is terrifying.
This is why Monroy's CTO appointment matters more than it looks. He built Azure Kubernetes Service, one of the largest container orchestration platforms on earth. His entire career is building the governance layer between code that wants to do things and systems that need to stay controlled.
"Safe, compliant, and real" isn't a marketing line. It's the entire product. Because the company that figures out how to let AI agents touch payroll without blowing up compliance will own enterprise AI for the next decade. And Workday already has the data, the customers, and now the infrastructure guy.
G
gabemonroy
@gabemonroy
Just took on the CTO role at Workday. Every enterprise is about to rebuild around agentic AI — and with Workday serving as the system of record for people and money across the Fortune 500, I’m focused on building the rails that make AI safe, compliant, and real. Stay tuned 😀
N
> installed Claude Code 3 months ago
> never opened the security settings
> Claude reads your wallet seed phrases
> Claude reads your SSH keys
> Claude reads your AWS credentials
> can send data anywhere it wants
> one CLAUDE.md file in a cloned repo
> your data is already gone
> average damage - $8,000-$50,000 in one night
> 15 minutes to fix this
> you still haven't

N
noisyb0y1
@noisyb0y1
Claude Code security settings nobody told you about
S
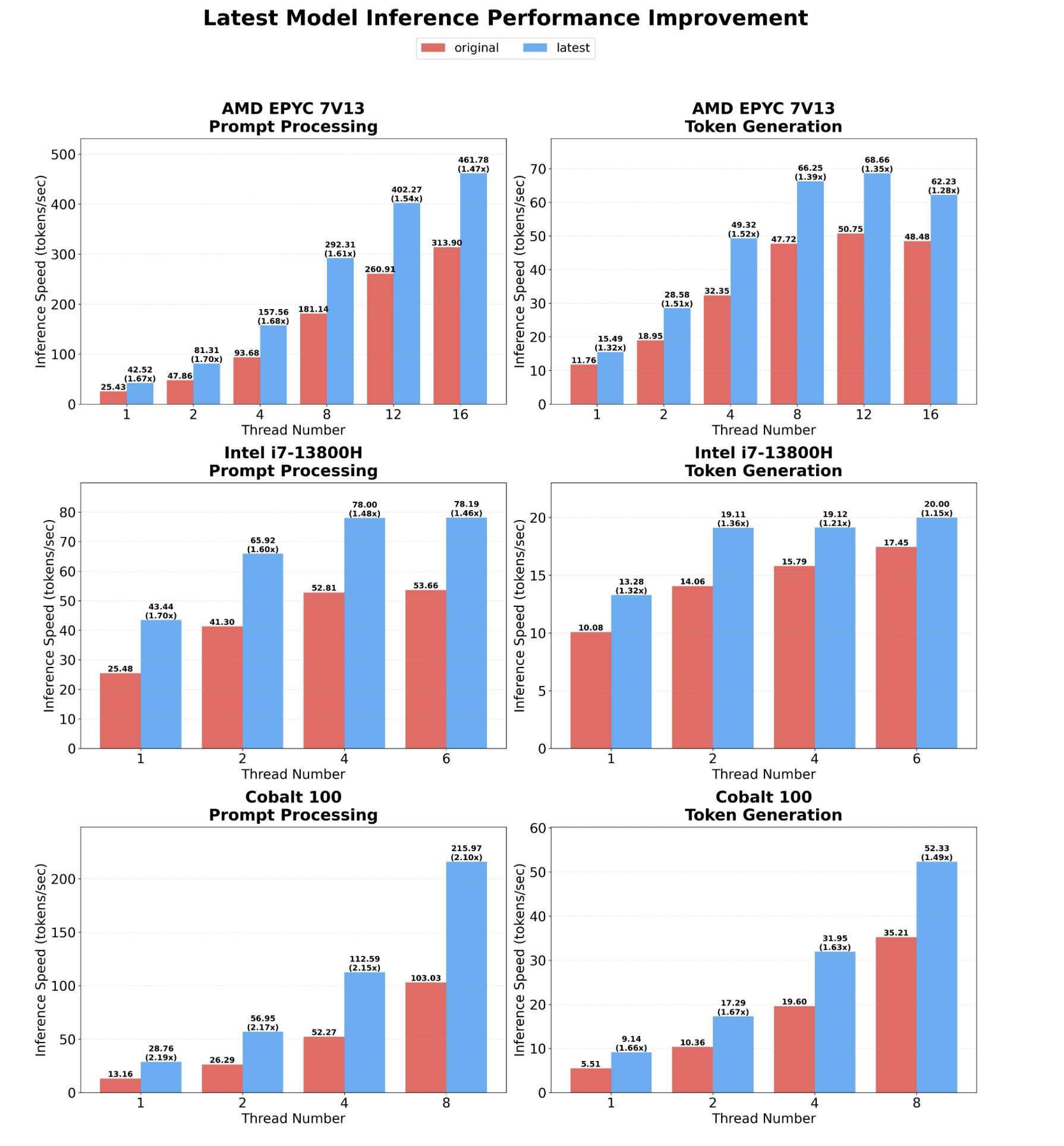
read this carefully anon. @pupposandro wrote a single fused CUDA kernel for all 24 layers of Qwen 3.5-0.8B. one kernel launch. absolutely zero CPU round trips between layers. the result?
a $900 RTX 3090 from 2020 hit 411 tok/s. apple's M5 Max hit 229. the 3090 won on speed AND efficiency 1.55x faster than llama.cpp on the same hardware.
the gap between NVIDIA and Apple was never about silicon. it was software. generic frameworks waste cycles on kernel launch overhead, memory re fetches, thread synchronization. when you fuse everything into one dispatch the hardware shows what it actually has.
this is the beginning of something bigger. we already proved that a 27B dense model on a single 3090 one-shots what $70K enterprise hardware cannot. now imagine what happens when someone writes kernels optimized specifically for the 3090 and the models that run best on it. not generic inference. hardware specific, model specific fused from the kernel level up.
the 3090 is not a relic. it's an untapped research platform. and the people writing these kernels are proving it with data.
all open source and reproducible anon.
P
pupposandro
@pupposandro
We made a $900 RTX 3090 faster and more efficient than an M5 Max at running LLMs:
A
RT @kcosr: Qwen 3.5 9B works completely fine for my personal assistant. I can't believe I was paying Anthropic for this. Thanks @TheAhmadOs…
E
The @BoringCompany could build a Hyperloop tunnel from downtown SF to downtown LA for <5% of this cost and it would be a technological marvel exceeding any high speed rail on Earth
H
HansMahncke
@HansMahncke
If you gave away $126 billion to subsidize free flights between LA and San Francisco at current demand levels, you could fund roughly 150 to 200 years of travel before the money runs out.
B
RT @wellecks: New paper: "Gym-Anything: Turn any Software into an Agent Environment"
First there were coding agents, soon there will be an…
M
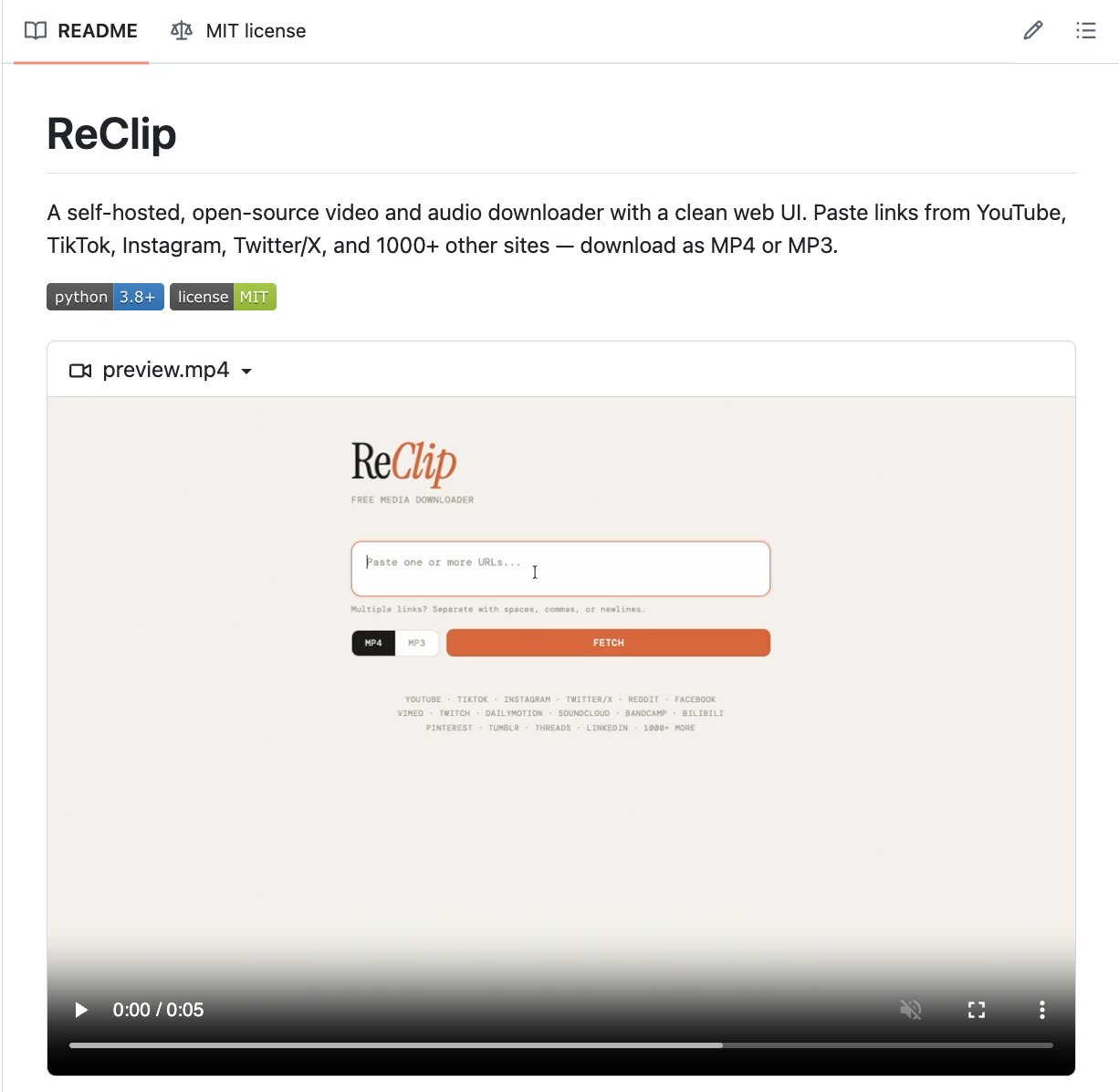
SOMEONE JUST KILLED EVERY SKETCHY VIDEO DOWNLOADER SITE ON THE INTERNET.
It's called ReClip. Self-hosted. Open source. Free.
Paste a link from YouTube, TikTok, Instagram, Twitter/X, or 1000+ other sites. Download as MP4 or MP3. That's it.
No ads. No popups. No trackers. No rate limits. No account. No sketchy installer.
Your machine. Your downloads. Your data.
Here is the full feature set:
-> 1000+ supported sites including YouTube, TikTok, Instagram, and Twitter/X
-> MP4 or MP3 output, your choice
-> Resolution selector before you download
-> Batch download. Paste multiple links at once.
-> Clean web UI that runs in any browser
-> Lightweight self-hosted setup
It went from 0 to 1.4K GitHub stars in 9 days.
239 forks already.
Here is why that number matters:
Every person who found a janky ad-covered downloader site in the last 10 years was waiting for this. A clean, private, self-hosted alternative that just works.
No business model built on your data. No premium tier. No upsells.
Built in HTML. MIT License. Two contributors. Ships in days.
100% Open Source. Free forever.
M
This is essentially the same as a homebrew workflow I've used for a while:
1. Create a /prototype-ui skill
2. Give it instructions to create multiple radically different designs
3. Give it a picker component to toggle between them
Bingo
A
adamwathan
@adamwathan
Quick https://t.co/AIW2moVHHW demo — generating multiple design ideas to choose from, no matter what tech stack you use: https://t.co/Wd0HwBfVVW