MemPalace Scores Perfect Memory Benchmark as Frontier Model Costs Hit $1,000/Day
A celebrity-backed open source memory system for Claude posted the first-ever perfect score on LongMemEval. Marc Andreessen and Elon Musk debated the economics of frontier model usage through OpenClaw, while Microsoft's bitnet.cpp and aggressive quantization techniques pushed local inference into surprisingly capable territory.
Daily Wrap-Up
The AI world today split neatly into two camps: people spending eye-watering amounts on frontier models and people doing everything possible to never pay for inference again. Marc Andreessen dropped the bombshell that "magical OpenClaw experiences" using frontier models run $300 to $1,000 per day today, heading toward $10,000/day, while Elon Musk casually mentioned a friend burning $200/day on the same platform. Meanwhile, on the other side of the divide, people are cramming Gemma 4 26B into 13GB of RAM on a MacBook M1 and getting 20-40 tokens per second. Microsoft open-sourced bitnet.cpp for running 100B parameter models on CPUs without GPUs. The cost spectrum for AI compute has never been wider, and both ends are expanding simultaneously.
The Claude ecosystem had a busy day. A vulnerability disclosure from Garry Tan raised concerns about file exfiltration in Cowork, Paweł Huryn diagnosed the "Claude is getting dumber" complaints as a thinking budget configuration issue rather than model regression, and Milla Jovovich (yes, that Milla Jovovich) co-created an open source memory system called MemPalace that achieved a perfect 100% score on LongMemEval. The Redis creator antirez apparently ran week-long autonomous sessions comparing Claude Code Opus 4.6 against Codex GPT 5.4, which is the kind of head-to-head benchmark the community has been hungry for. Theo from t3.gg continued his complicated relationship with AI coding tools, declaring Claude Code "basically unusable" in one post and then questioning whether bash is the right interface for agents in another.
The local inference story is quietly becoming the most important trend in AI. Between Microsoft's 1-bit inference framework, aggressive quantization getting Gemma 4 down to laptop-friendly sizes, and detailed inference engine breakdowns circulating on social media, the knowledge required to run capable models locally is becoming democratized fast. The most practical takeaway for developers: if you haven't experimented with local inference yet, the barrier just dropped significantly. Try bitnet.cpp or grab a quantized Gemma 4/Qwen 3.5 model and get familiar with your hardware's capabilities, because the gap between local and cloud inference is closing faster than most people realize.
Quick Hits
- @HonestGmReviews spotlighted Chainstaff, a hand-drawn 2D platformer dropping on Steam, Xbox, and PS5, proudly noting "ain't no AI-generated assets here." The indie game revival continues.
- @ivanleomk praised a free tool by @pbakaus as "the best skill I've used this year," though details were light on what exactly it does.
- @bztree shared first impressions of the M5 MacBook with Metal 4 and Neural Accelerators, which should be relevant reading for anyone doing on-device ML work.
- @badlogicgames RT'd @dillon_mulroy saying sub-agents are unnecessary and "/tree is all you need," a minimalist take on agent orchestration.
- @santifer open-sourced a job search tool that hit 12K+ GitHub stars in two days, quoting @garrytan's "golden age of open source is here."
- @thekitze reacted with bewilderment to whatever "forgecode" is, suggesting another new entrant in the crowded AI coding tool space.
- @hooeem pitched building personalized LLM knowledge bases as a business, claiming you can charge $1,500 per build using Obsidian and markdown files. Hustle culture meets RAG.
Frontier Model Economics and the Cost Divide
The conversation about AI costs has shifted from "will it get cheaper?" to "how fast?" Marc Andreessen laid out a striking projection that frames the entire industry's trajectory. As @pmarca put it: "Magical OpenClaw experiences that use frontier models cost $300-1,000/day today, heading to $10,000/day and more. The future shape of the entire technology industry will be how to drive that to $20/month." That's a 500x to 15,000x cost reduction that needs to happen, and Andreessen is essentially saying the company that solves it wins the next decade.
@elonmusk added a data point from the ground, noting a friend who "runs open source models locally on his home computers for easier stuff, but spends ~$200/day on frontier models." This hybrid approach, local models for routine tasks and frontier models for the hard stuff, is likely where most power users land today. The economics force a natural stratification: you don't send every query to the most expensive model when a local one handles 80% of your needs.
What makes this moment interesting is that both the ceiling and floor are moving. Frontier capabilities keep climbing, justifying higher spend for complex tasks. But local inference keeps getting better too, eating into the use cases that previously required cloud models. The $20/month target Andreessen mentioned isn't just about cost optimization. It's about making frontier-quality AI as accessible as a Netflix subscription, which would be genuinely transformative.
Local Inference Hits a New Stride
Three separate posts today showcased just how far local AI inference has come, and the progress is remarkable. Microsoft's bitnet.cpp release represents a fundamental architectural shift. @HowToAI_ highlighted the key stats: "a 1-bit inference framework that runs massive 100B parameter models directly on your CPU without GPUs. It uses 82% less energy.. 100% open-source." Running 100B models on CPUs was science fiction two years ago.
On the quantization front, @whyarethis demonstrated Gemma 4 26B compressed to 13GB and running on an M1 MacBook at 20-40 tokens per second, describing a process involving "dead heads pruned and replaced by SVD rotations" and optimized KV cache. Meanwhile, @lafaiel shared specs on the new generation of mid-size models including Qwen 3.5 27B and Gemma 4 31B alongside their mixture-of-experts variants, giving local inference enthusiasts more options than ever.
@TheAhmadOsman took a practical approach, sharing a comprehensive inference engine breakdown covering everything from llama.cpp to TensorRT-LLM, matched to hardware profiles. The key insight from the cheat sheet: the bottleneck isn't VRAM size but memory bandwidth, KV cache management, and interconnect speed. As local inference matures, understanding these hardware constraints becomes essential knowledge for any developer wanting to run models on their own iron.
Claude Code: Regression, Fixes, and Vulnerabilities
Claude Code dominated the conversation today across multiple angles. The most useful contribution came from @PawelHuryn, who dug into the widely-reported "Claude is getting dumber" complaints and found a mundane but fixable explanation. "The regression is real. But it's not Claude getting dumber," he wrote, pointing to adjusted thinking budgets. His three fixes are straightforward: use /effort high, enable thinking summaries, and add research-first instructions to CLAUDE.md. He cited GitHub issue #42796, which "analyzed 17,871 thinking blocks across 6,852 sessions" and found that reduced thinking depth caused the model to shift from research-first to edit-first behavior.
On the security side, @garrytan flagged a more serious concern: "Attackers can exfiltrate user files from Cowork by exploiting an unremediated vulnerability in Claude's coding environment." The vulnerability was originally identified by researcher Johann Rehberger and was "acknowledged but not remediated by Anthropic." For a tool that has deep filesystem access, unpatched file exfiltration vulnerabilities are a significant trust issue.
@theo added philosophical texture to the Claude discourse, arguing that "agents are good at bash. Bash is not good for agents. We should cut our losses and restart now before it is too late." It's a provocative framing. The shell was designed for human interaction patterns, not autonomous agents that need structured output and reliable error handling. Whether the industry builds something better or keeps duct-taping bash remains an open question.
MemPalace: A Perfect Score on Memory Benchmarks
Perhaps the most surprising story of the day was the emergence of MemPalace, an open source memory system for Claude co-created by actress Milla Jovovich and developer @bensig. @JeremyNguyenPhD broke down the headline numbers: "100% on LongMemEval, first perfect score ever recorded." The system also scored 92.9% on ConvoMem (more than 2x Mem0's score) and 100% on LoCoMo.
What makes MemPalace architecturally distinct is its approach to memory organization. As @bensig explained, instead of cloud-based background agents, it "mines your conversations locally and organizes them into a palace, a structured architecture with wings, halls, and rooms that mirrors how human memory actually works." The system uses what they call AAAK compression to fit "your entire life context into 120 tokens, 30x lossless compression any LLM reads natively." It runs entirely locally with no API key, no cloud dependency, and ships under the MIT license.
The celebrity angle is novel but the technical achievement is what matters. Memory has been the weakest link in LLM-based workflows, and a system that achieves perfect recall across standard benchmarks while running locally could meaningfully change how people interact with AI assistants over long time horizons. The fact that it's open source means the community can verify and build on these results.
AI in Science and Business Applications
Rounding out the day, @TIME shared Edison co-founder Andrew White's perspective that AI integration could accelerate scientific discovery, noting "an unlimited number of discoveries to be made." While less technically specific than other posts, it reflects the growing mainstream narrative that AI's biggest impact may come not from coding assistants or chatbots but from accelerating research in fields like materials science, drug discovery, and climate modeling.
On the business side, @championswimmer highlighted antirez (the creator of Redis) running extensive autonomous coding sessions comparing Claude Code Opus 4.6 against Codex GPT 5.4 at maximum thinking budgets. The fact that one of open source's most respected engineers is stress-testing these tools in real development workflows, not just toy demos, signals that AI coding assistants have crossed the threshold from curiosity to serious tooling for experienced developers.
Sources
T
In science, there's an "unlimited number of discoveries to be made." Edison's co-founder Andrew White says integrating AI could accelerate those possibilities. https://t.co/0jlOUNIQZO

W
What happens when you decide to remake Contra after doing 30 hits of acid? You get Chainstaff! An insane looking 2D-platformer about an alien trying to fight off an invasion of its home planet.
Ain't no AI-generated assets here. It looks like pure hand-drawn chaos!
I'm loving this revival of 2D platformers and Metroidvanias by small boutique studios.
Chainstaff drops in two days on Steam, Xbox and PS5.

S
I got my M5 MacBook over the weekend and had some time to mess around with Metal 4 and the Neural Accelerators!
Wanted to document some of my first impressions below:
M
RT @dillon_mulroy: i have not used sub agents for nearly a month and i don’t actually miss them at all
/tree is all you need
J
Milla Jovovich (actress from The Fifth Element) created a world-beating Claude memory system with @bensig?!
- 100% on LongMemEval — first perfect score ever recorded.
Free and 100% open source. Github link in the quoted post from Ben.
I'm keen to hear how it works for you. https://t.co/5AMu96CZ7Z

B
bensig
@bensig
My friend Milla Jovovich and I spent months creating an AI memory system with Claude. It just posted a perfect score on the standard benchmark - beating every product in the space, free or paid. It's called MemPalace, and it works nothing like anything else out there. Instead of sending your data to a background agent in the cloud, it mines your conversations locally and organizes them into a palace - a structured architecture with wings, halls, and rooms that mirrors how human memory actually works. Here is what that gets you: → Your AI knows who you are before you type a single word - family, projects, preferences, loaded in ~120 tokens → Palace architecture organizes memories by domain and type - not a flat list of facts, a navigable structure → Semantic search across months of conversations finds the answer in position 1 or 2 → AAAK compression fits your entire life context into 120 tokens - 30x lossless compression any LLM reads natively → Contradiction detection catches wrong names, wrong pronouns, wrong ages before you ever see them The benchmarks: 100% recall on LongMemEval — first perfect score ever recorded. 500/500 questions. Every question type at 100%. 92.9% on ConvoMem — more than 2x Mem0's score. 100% on LoCoMo — every multi-hop reasoning category, including temporal inference which stumps most systems. No API key. No cloud. No subscription. One dependency. Runs on your machine. Your memories never leave. MIT License. 100% Open Source. https://t.co/KggwTqijmD
A
Let me make local AI easy for you
Give Codex Cli the tweet below and tell it:
- Infer the right Inference Engine from your hardware + tweet content below
- Use uv + venv
- Pick the right kernels
- Tune flags, batching, KV cache, etc
- Optimize for your hardware + chosen model
T
TheAhmadOsman
@TheAhmadOsman
You don’t pick an Inference Engine You pick a Hardware Strategy and the Engine follows Inference Engines Breakdown (Cheat Sheet at the bottom) > llama.cpp runs anywhere CPU, GPU, Mac, weird edge boxes best when VRAM is tight and RAM is plenty hybrid offload, GGUF, ultimate portability not built for serious multi-node scale > MLX Apple Silicon weapon unified memory = “fits” bigger models than VRAM would allow but also slower than GPUs clean dev stack (Python/Swift/C++) sits on Metal (and expanding beyond) now supports CUDA + distributed too great for Mac-first workflows, not prod serving > ExLlamaV2 single RTX box go brrr EXL2 quant, fast local inference perfect for 1/2/3/4 GPU(s) setups (4090/3090) not meant for clusters or non-CUDA > ExLlamaV3 same idea, but bigger ambition multi-GPU, MoE, EXL3 quant consumer rigs pretending to be datacenters still CUDA-first, still rough edges depending on model > vLLM default answer for prod serving continuous batching, KV cache magic tensor / pipeline / data parallel runs on CUDA + ROCm (and some CPUs) this is your “serve 100s of users” engine > SGLang vLLM but more systems-brained routing, disaggregation, long-context scaling expert parallel for MoE built for ugly workloads at scale lives on top of CUDA / ROCm clusters this is infra nerd territory > TensorRT-LLM maximum NVIDIA performance FP8/FP4, CUDA graphs, insane throughput multi-node, multi-GPU, fully optimized pure CUDA stack, zero portability (And underneath all of it: Transformers → model architecture layer → CUDA / ROCm / TT-Metal → compute layer) What actually happens under the hood: > Transformers defines the model > CUDA / ROCm executes it > TT-Metal (if you’re insane) lets you write the kernel yourself The Inference Engine is just the orchestrator (simplified) When running LLMs locally, the bottleneck isn’t just “VRAM size” It isn’t even the model It’s: - memory bandwidth (the real limiter) - KV cache (explodes with long context) - interconnect (PCIe vs NVLink vs RDMA) - scheduler quality (batching + engine design) - runtime overhead (activations, graphs, etc) (and your compute stack decides all of this) P.S. Unified Memory is way slower than VRAM Cheat Sheet / Rules of Thumb > laptop / edge / weird hardware → llama.cpp > Mac workflows → MLX > 1–4 RTX GPUs → ExLlamaV2/V3 > general serving → vLLM > complex infra / long context / MoE → SGLang > NVIDIA max performance → TensorRT-LLM
I
https://t.co/sSzeqCmiMk by @pbakaus is the best skill i've used this year.
Can't believe it's free
H
🚨 Microsoft has solved the biggest problem with AI.
They open-sourced bitnet.cpp. It’s a 1-bit inference framework that runs massive 100B parameter models directly on your CPU without GPUs.
it uses 82% less energy.. 100% open-source. https://t.co/8SziUiwVCf
G
Attackers can exfiltrate user files from Cowork by exploiting an unremediated vulnerability in Claude’s coding environment, which now extends to Cowork. The vulnerability was first identified in https://t.co/noHjpUqN1I chat before Cowork existed by Johann Rehberger, who disclosed the vulnerability. It was acknowledged but not remediated by Anthropic.
https://t.co/RQTMzbOaR2
M
Magical OpenClaw experiences that use frontier models cost $300-1,000/day today, heading to $10,000/day and more. The future shape of the entire technology industry will be how to drive that to $20/month.
E
@pmarca A friend of mine showed me his OpenClaw setup. He runs open source models locally on his home computers for easier stuff, but spends ~$200/day on frontier models.
P
This is insane.
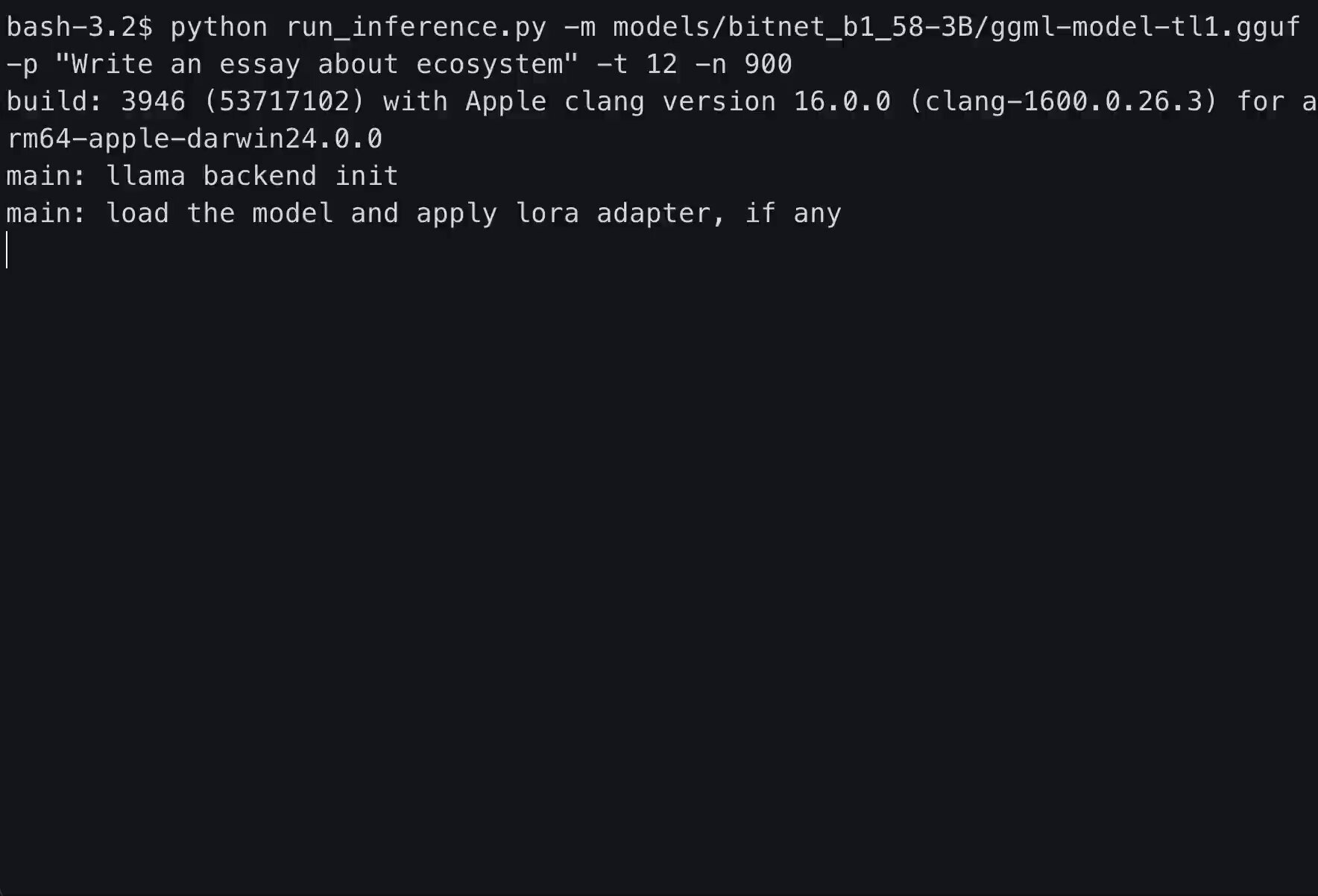
Gemma 4 26B running at 13GB on my Macbook M1, full context window. 20-40 tokens a second.
This was a REAP model by @0xseraph further optimized through coherence physics. Dead heads were pruned and replaced by SVD rotations. Weights were quantized, and KV cache was optimized to be negligible.
I am now working to get speed up higher.
Wild to be talking to a local LLM which has been shrunk through the oscillator physics I have been working on for 6+ months now.
#project89
S
Built this to find my own job. Open sourced it. 12K+ stars in two days.
Free: https://t.co/TPni1Pfd1l https://t.co/1yX1i0yDSA
G
garrytan
@garrytan
Golden age of open source is here
P
So, I did some research.
The regression is real. But it's not Claude getting dumber. And you can fix that.
Thinking budgets were adjusted. For complex multi-file work, the default medium effort may not be enough.
Three fixes:
1. /effort high (or /effort max on Opus for hard debugging)
2. ~/.claude/settings.json → "showThinkingSummaries": true
3. CLAUDE.md: "Research the codebase before editing. Never change code you haven't read."
GitHub issue #42796 analyzed 17,871 thinking blocks across 6,852 sessions. The pattern: when thinking depth drops, the model shifts from research-first to edit-first.
Claude didn't get worse. The defaults got conservative.
T
theo
@theo
Claude Code is basically unusable at this point. I give up. https://t.co/jJ4aV8EuTw
A
Author of Redis ⬇️
A
antirez
@antirez
During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account + my PRO account) of tokens...
H
when you become a millionaire in 1-3 years because you sell personalised knowledge bases and it’s all because (I repeat):
1: you learn how to build llm knowledge bases (the guide drops everything you need)
2: you go to people who are cash rich and time poor. lawyers, doctors, consultants, agency owners, property investors, founders. people drowning in information they never have time to organise
3: you show them what a personalised knowledge base looks like. their research, their documents, their industry intel, all compiled into a searchable wiki that gets smarter every time they use it
4: you offer a one-time build for 1.5k. you set up obsidian, build the folder structure, configure the schema, clip their first 20-30 sources, run the compilation, hand them a working system with a walkthrough
5: you offer a yearly maintenance package for 500. you update their wiki with new sources, run health checks, add new topics as their work evolves, keep the whole thing current
6: you land 5 clients and that’s 7.5k upfront plus 2.5k recurring every year. 10 clients and you’re looking at 15k plus 5k annual. for a system that takes you a few hours to build once you know the workflow
7: again, if you find 200 clients and you’re sitting on 300k upfront and 100k recurring every single year. for building markdown files.
the beauty of this is the work gets faster every time you do it. your second build takes half the time of your first. by your fifth you could knock one out in an afternoon.
and the people who need this most have no idea it exists. their competition definitely doesn’t have one. you’re not selling software. you’re selling an unfair advantage in their specific field.

H
hooeem
@hooeem
How to create your own LLM knowledge bases today (full course):
T
Agents are good at bash. Bash is not good for agents. We should cut our losses and restart now before it is too late. https://t.co/YndGmAfqjh
