Goose Hits 35K Stars as AI Coding Tools Fragment and Gemma 4 Gets Its First Real-World Stress Test
The AI coding tool landscape is splintering fast, with Block's open-source Goose agent gaining momentum against paid alternatives while practitioners debate which models actually hold the crown. Google's Gemma 4 is getting thorough community testing that reveals harness selection matters more than raw model quality, and a new wave of developer tooling from code search to knowledge graphs is reshaping how agents understand codebases.
Daily Wrap-Up
Today's feed tells a clear story: the AI coding tool wars have entered a fragmentation phase where no single product owns the workflow. Block's Goose agent is racking up GitHub stars by promising model-agnostic freedom, GitNexus is trying to give agents architectural awareness through knowledge graphs, and CodeDB claims to have built a code search engine that leaves ripgrep in the dust. Meanwhile, practitioners are sharing increasingly sophisticated multi-agent workflows involving git worktrees and compound engineering plugins. The tools are multiplying faster than anyone can evaluate them, and the real skill is becoming curation rather than adoption.
On the model front, the picture is surprisingly unsettled. One camp argues OpenAI's GPT 5.4 Pro owns the state of the art across thinking, planning, and execution. Another camp is deep in the weeds testing Google's Gemma 4 family and finding that the 31B model is genuinely capable but painfully dependent on which harness you run it through. The gap between "good model" and "good model experience" has never been wider, and that's creating real opportunities for the open-source tooling community to differentiate. Google even shipped an official app to run Gemma locally on phones, which tells you something about where they think the distribution battle is headed.
The most entertaining moment was probably the Gemma 4 jailbreak dropping with breathless enthusiasm and a 93.7% HarmBench compliance rate, because nothing says "open-source community" quite like abliterating safety guardrails within days of a model release. On a more constructive note, the emerging consensus around "skill graphs" and structured agent workflows suggests the community is maturing past the "just vibe code it" phase into something more systematic. The most practical takeaway for developers: if you're using AI coding agents, invest time in your harness configuration and agent orchestration setup before chasing the newest model. As @hrishioa's Gemma 4 testing showed, the same model can range from impressive to barely functional depending on the runner and prompt scaffolding around it.
Quick Hits
- @minchoi highlights Grok Imagine's new Quality mode producing photorealistic AI images that "broke the Internet," with examples that blur the line between generated and real photography.
- @elonmusk casually responds "Try using the X API" to @Scobleizer's story about building two apps in 20 minutes at a hackathon using Replit and the X platform's API.
- @berryxia shares a lightweight CLI tool (just 35kb) by @andrewfarah that syncs X bookmarks to local SQLite, making them searchable and accessible to AI agents.
- @dillon_mulroy praises @MattieTK's product launch of EmDash, which hit 6.8K GitHub stars in three days through genuine community engagement and iterative development.
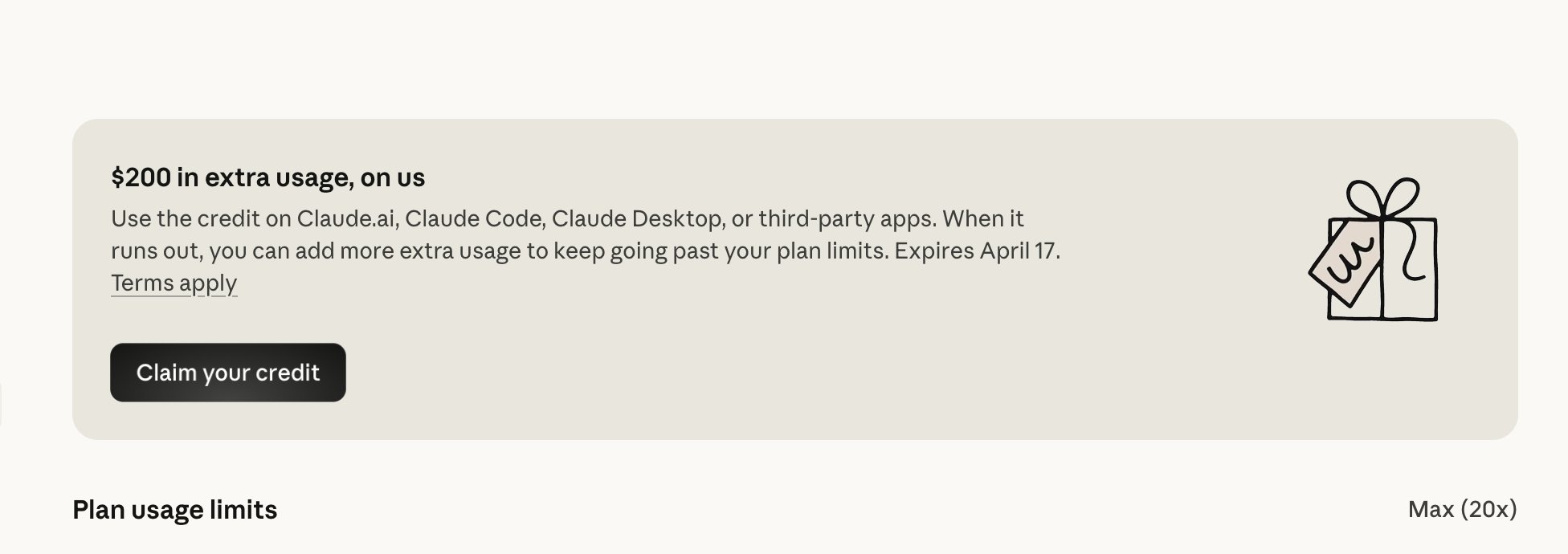
- @oikon48 reports that Anthropic is distributing compensation credits after Claude subscription quotas stopped working with third-party tools, with Max 20x subscribers receiving $200 in additional credits.
- @0xSero advocates for "autoresearch" as an underappreciated paradigm for getting real value from LLMs, arguing there are millions of profitable research tasks waiting to be automated.
- @neural_avb teases a video on training sub-nano 0.1B language models for narrow tasks, claiming 350 tok/s inference with just 0.3GB peak memory for vertical SLMs.
AI Coding Agents and the Tool Fragmentation Wars
The biggest theme running through today's posts is the rapid proliferation of AI coding tools, each carving out a different niche in the developer workflow. The headline grabber is Block's open-source Goose agent, which @heynavtoor profiled in detail: "Block is a $40 billion company. They built Cash App, Square, and TIDAL. They use Goose internally. Then they open sourced the entire thing." The pitch is straightforward: model-agnostic, editor-agnostic, and free forever under Apache 2.0. At 35K GitHub stars, it's clearly resonating with developers tired of vendor lock-in.
But Goose isn't operating in a vacuum. @MatthewBerman launched Journey, a platform that "helps agents discover and install full workflows easily," essentially building a marketplace layer on top of the agent ecosystem. Meanwhile, @rachpradhan announced CodeDB v0.2.53 claiming performance numbers that sound almost too good to be true: "538x faster than ripgrep. 0.065ms code search. Pre-built trigram index. Query once, instant forever." And the GitNexus knowledge graph engine that @Teknium quote-tweeted promises to give AI agents full architectural awareness of codebases through dependency mapping and blast radius analysis.
What ties all of this together is a shared recognition that raw model intelligence isn't the bottleneck anymore. The bottleneck is context: giving agents enough understanding of your codebase, your dependencies, and your intent to be genuinely useful. Each of these tools attacks that problem from a different angle, and the winners will likely be determined by integration quality rather than feature lists.
Claude Code Workflows and Multi-Agent Orchestration
A cluster of posts today focused specifically on how power users are structuring their Claude Code workflows, and the sophistication level is climbing fast. @om_patel5 described a senior engineer's setup that runs "5 separate agents on every task: one brainstorms, one plans the technical implementation, one executes, one reviews, one checks different verticals." The multiplier comes from git worktrees, with teams running "4-8 Claude Code sessions at the same time across different worktrees with each one working on a separate task."
This resonates with @reactive_dude's question about favorite agent skills, where the answers (grill-me for brainstorming, write-a-prd for specs, tdd for coding, agent-browser for debugging) reveal a community that's moved well past "write me a function" into structured, phase-based development. @VadimStrizheus added another layer by promoting "skill graphs" over flat SKILL.md files, quoting @arscontexta's earlier take that graph-structured skill definitions give agents better navigation of complex workflows.
Even the discourse around plan mode, which @steipete retweeted from @badlogicgames, shows a maturing understanding of when to let agents execute versus when to keep them in advisory mode. The pattern emerging is clear: the best results come from decomposing work into specialized phases rather than asking a single agent to do everything. The skill isn't prompting anymore. It's orchestration.
The Model Landscape: GPT 5.4, Gemma 4, and the Harness Problem
Today's model discourse was split between two camps offering very different perspectives on what "best" means in 2026. @TheAhmadOsman laid out the bull case for OpenAI plainly: "Best thinking model: GPT 5.4 Pro. Best planning/orchestration model: GPT 5.4. Best execution model: GPT 5.3 Codex." The caveat? "Just keep it away from your sensitive data."
On the open-source side, @hrishioa provided the most detailed Gemma 4 assessment of the day, and the takeaway is nuanced. The 31B model is "amazing for proper thinking and chat" and handles visual understanding well, but agentic use varies wildly by harness. The specifics are revealing: "Codex, surprisingly, has been the most solid. Claude Code barely works. The system prompt is too thick, and Gemma does not know what to do with interleaved thinking the way Anthropic does it." Even runner selection matters, with LMStudio and llama.cpp still showing rough edges that need a week or two to stabilize.
This harness dependency is arguably the most important insight for practitioners right now. A model that benchmarks well can still fail in production if the surrounding infrastructure doesn't match its expectations. @hrishioa's conclusion captures it perfectly: "This is a solid agentic workhorse, but it's missing the harness and runner combo that would enable that." The open-source community's ability to solve this integration problem will determine whether Gemma 4 becomes a real contender or remains a promising benchmark result.
Local and Open-Source AI Pushes Forward
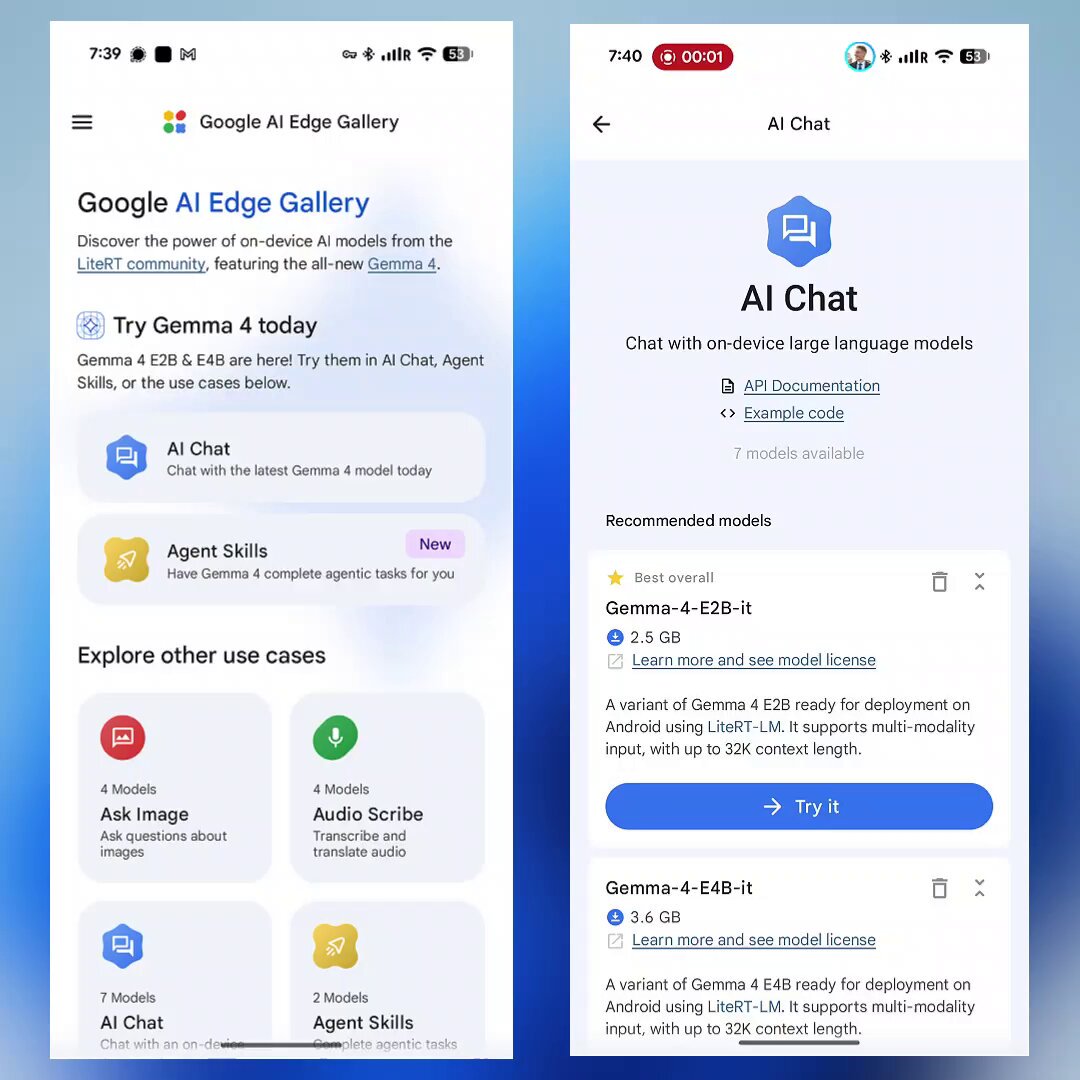
Google's two-track strategy is becoming impossible to ignore. @EXM7777 highlighted the tension between Gemini (closed, paid, cloud-only) and the Gemma family (open, free, run-anywhere), and both tracks got significant attention today. @itsPaulAi reminded everyone that Google ships an official app to run Gemma 4 on phones: "100% open source. Fully offline and private. Multimodal with text/audio/image. Works with Gemma E4B and E2B." Available on both iOS and Android, it's a clear bet on edge distribution.
The jailbreak community moved fast too, with @outsource_ announcing "Gemma-4-31B-JANG_4M-CRACK" hitting 93.7% HarmBench compliance with an 18GB mixed-precision MLX quant for Apple Silicon. Whether you view this as a feature or a problem depends on your perspective, but it underscores how quickly open-weight models get remixed once released. Combined with @neural_avb's work on sub-nano 0.1B models running at 350 tok/s, the local AI stack is getting simultaneously more powerful and more accessible. The trend line points toward a future where cloud APIs are for heavy lifting and local models handle everything else.
Sources
O
Claudeのサブスク利用枠がサードパーティツールで使えない件のお詫びとして、契約プラン分の追加利用クレジットが配布されています。
Max 20x を契約している人は、$200 分の追加クレジットがもらえます( 受け取りは4月17日まで)
https://t.co/auEA7rHq19 https://t.co/gL6sStkDna
O
oikon48
@oikon48
【重要: Claudeサブスクによるサードパーティツールの利用について】 明日12 pm PT (日本時間4 am)から、Claudeのサブスク利用枠でOpenClawなどのサードパーティツールの利用ができなくなります。 サードパーティツールを利用する場合はサブスクのextra usage、もしくはAPI キー従量課金のみとなります。 サーバー側の負荷が問題になっているらしく、 返金対応もするとのこと。 https://t.co/bsWlRZXuDT
A
What are your favorite agent skills? I'll start:
> grill-me (brainstorming)
> write-a-prd (specs)
> tdd (the best way to code with agents rn)
> agent-browser (great for debugging/qa)
D
if you want to see a masterclass in product engineering/work, scroll through @MattieTK’s timeline from the past week in launching EmDash
he’s taken criticism in stride, engaged with everyone in good faith, iterated on the product, and started building community
M
MattieTK
@MattieTK
EmDash is at 6.8k GH stars after just three days. 😲 We're blown away by the community gathering on GitHub but it's getting very busy for us! To bring together the hundreds of people enthused by EmDash, we've put together a Discord ⤵️ https://t.co/rfZazbnFVS
R
RT @Dimillian: I want to double down on that. Just ask Codex to build anything you want connecting to the Codex App Server. It’s very self-…
M
I built something...
https://t.co/JKlSQXQ68p
Journey helps agents discover and install full workflows easily.
Please leave your feedback below! https://t.co/VLGWbjjmf2

P
Friendly reminder that Google has an official app to run Gemma 4 on your phone.
- 100% open source
- Fully offline and private
- Multimodal with text/audio/image
- Works with Gemma E4B and E2B
And the app is available on both iOS and Android.
Steps and download below https://t.co/Ii0Mh4XpHH
H
Gemma 4 is a SOLID family of models - but harness and runner selection matter more than ever. Here's everything I learned from testing:
• The 31B model is amazing for proper thinking and chat. Agentic use is a mixed bag - see below
• A4B and 31B are good for visual understanding. Passes my personal MirandaBench (pass in a pattern/image, ask to separate into historical elements and reproduce with a nanobanana prompt - see video)
Harness matters a crazy amount:
• Codex - surprisingly - has been the most solid. codex --oss has been a massive boon.
• Claude Code barely works. The system prompt is too thick, and Gemma does not know what to do with interleaved thinking the way anthropic does it.
• OpenCode is worse - worse prompt (for this family), and overall worse toolcalls.
• Pi is pretty good - but adding in extensions will often confuse the model.
Runners matter too:
• LMStudio on Mac, llama.cpp on Windows are tested and working, but still have rought edges. I'd give these models a week or two to stabilize.
Quants:
• Q4 is.. okay. I've needed Q8 or above for any serious data work.
The more I test this model the more I'm sure that this is a solid agentic workhorse, but it's missing the harness and runner combo that would enable that. This is where I'm hoping the OSS community comes to the rescue.
As always, YMMV!
M
RT @0xSero: I interviewed the creator of Pi, top tier coding agent and the core of openclaw.
I hope you enjoy, one of my favourite conver…
B
终于有人把 X 书签彻底本地化了!🚀
@andrewfarah 第一个开源项目直接解决 Agent 最大痛点:
一个超轻 CLI(35kb!):
所有书签自动同步到本地 SQLite(WASM),Agent 可以直接查、分类、可视化
再也不用“书签=再也看不到”了😂
https://t.co/DT9jH7GSAn
M
RT @EXM7777: Google is running a two-track AI strategy that nobody's framing correctly...
track 1: Gemini (closed, paid, cloud-only)
track…
E
🚨THE GEMMA 4 JAILBREAK WE’VE ALL BEEN WAITING FOR JUST DROPPED
Gemma-4-31B is now fully CRACKED and abliterated
Gemma-4-31B-JANG_4M-CRACK
🚀93.7% HarmBench compliance (149/159)
🏆Super clean base model
🤖18GB mixed-precision MLX quant for Apple Silicon
👀Vision/multimodal support included
This is the cleanest, most powerful uncensored 31B local model yet.
Perfect for research, coding, , and zero limits.
Check it out 👇🏻
https://t.co/3iY0wKwQMq
A
The truth is OpenAI owns the current SoTA model, and overall the best suite of models
Best thinking model
> GPT 5.4 Pro
Best planning/orchestration model
> GPT 5.4
Best execution model
> GPT 5.3 Codex
Codex is a worthy subscription, just keep it away from your sensetive data
M
Grok Imagine's new Quality mode realism just broke the Internet yesterday.
This is 100% AI
10 wild examples:
1. Nothing is real anymore https://t.co/0auhxRjpLp

P
RT @badlogicgames: plan mode:
"Hey, let's not modify any files and discuss this"
... dicsussion, files are explored ...
"ok, put what we…
E
Try using the X API
S
Scobleizer
@Scobleizer
Met a founding engineer today from @Replit. Jen Li. We were both judging the @Pokee_AI hackathon. They have me some credits and I built two apps in 20 minutes using the X API:a weather one which mapped storms being reported in by my climate scientist list and another monitoring my three news lists for information about the Iran war. Pokee includes X API for its customers automatically. While doing that my other AI read all your posts: https://t.co/8L5xphk0qQ He tells me about why Replit is hugely important in the AI industry. In other words how you can use it in your life and business.
V
pov: you have been using Claude Code for 3 months and just discovered skill graphs.
Give this to your agent.
You’ll thank me later. 👇
A
arscontexta
@arscontexta
Skill Graphs > SKILL.md
T
Having Hermes make one for Hermes and then will upload the skill from it's learnings in using it :)
H
heygurisingh
@heygurisingh
🚨Breaking: Someone open sourced a knowledge graph engine for your codebase and it's terrifying how good it is. It's called GitNexus. And it's not a documentation tool. It's a full code intelligence layer that maps every dependency, call chain, and execution flow in your repo -- then plugs directly into Claude Code, Cursor, and Windsurf via MCP. Here's what this thing does autonomously: → Indexes your entire codebase into a graph with Tree-sitter AST parsing → Maps every function call, import, class inheritance, and interface → Groups related code into functional clusters with cohesion scores → Traces execution flows from entry points through full call chains → Runs blast radius analysis before you change a single line → Detects which processes break when you touch a specific function → Renames symbols across 5+ files in one coordinated operation → Generates a full codebase wiki from the knowledge graph automatically Here's the wildest part: Your AI agent edits UserService.validate(). It doesn't know 47 functions depend on its return type. Breaking changes ship. GitNexus pre-computes the entire dependency structure at index time -- so when Claude Code asks "what depends on this?", it gets a complete answer in 1 query instead of 10. Smaller models get full architectural clarity. Even GPT-4o-mini stops breaking call chains. One command to set it up: `npx gitnexus analyze` That's it. MCP registers automatically. Claude Code hooks install themselves. Your AI agent has been coding blind. This fixes that. 9.4K GitHub stars. 1.2K forks. Already trending. 100% Open Source. (Link in the comments)
O
THIS IS HOW A SENIOR ENGINEER ACTUALLY SCALES THEMSELVES WITH CLAUDE CODE
the biggest change with AI isn't coding faster. it's where you actually spend your time now.
more detailed prompts, more code review, more planning, less typing, etc.
here's the workflow:
this guy has been shipping code since the days of cgi and perl.
he uses a compound engineering plugin that runs 5 separate agents on every task.
one brainstorms, one plans the technical implementation, one executes, one reviews, one checks different verticals.
every step is documented in markdown files. it's slow and way more waiting. but the output quality is way higher because each agent is focused on one thing.
then the REAL multiplier is in git worktrees
if Claude Code made you 10x faster, worktrees multiplies that again depending on how many agents you can manage in parallel
his team runs 4-8 Claude Code sessions at the same time across different worktrees with each one working on a separate task.
the skill is managing multiple AI agents in parallel without losing track, that's the next evolution of engineering
N
🚨 Claude Code costs $200/month. GitHub Copilot costs $19/month. Jack Dorsey's company built a free alternative. 35,000 GitHub stars.
It's called Goose.
An open source AI agent built by Block that goes beyond code suggestions. It installs, executes, edits, and tests. With any LLM you choose.
Not autocomplete. Not suggestions. A full autonomous agent that takes actions on your computer.
No vendor lock-in. No monthly subscription. Bring your own model.
Here's what Goose does:
→ Works with ANY LLM. Claude, GPT, Gemini, Llama, DeepSeek, Ollama. Your choice.
→ Reads and understands your entire codebase
→ Writes, edits, and refactors code across multiple files
→ Runs shell commands and installs dependencies
→ Executes and debugs your code automatically
→ Extensible through MCP. Connect it to any external tool.
→ Desktop app, CLI, and web interface. Pick your workflow.
→ Written in Rust. Fast. Lightweight. No bloat.
Here's the wildest part:
Block is a $40 billion company. They built Cash App, Square, and TIDAL. They use Goose internally. Then they open sourced the entire thing.
This isn't a side project from a random developer. This is production-grade tooling from a company that processes billions in payments. Built for their own engineers. Given to everyone.
Claude Code: $200/month. Locked to Claude.
GitHub Copilot: $19/month. Locked to GitHub.
Cursor: $20/month. Locked to their editor.
Goose: Free. Any LLM. Any editor. Any workflow. Forever.
35.3K GitHub stars. 3.3K forks. 4,078 commits. Built by Block.
100% Open Source. Apache 2.0 License.
R
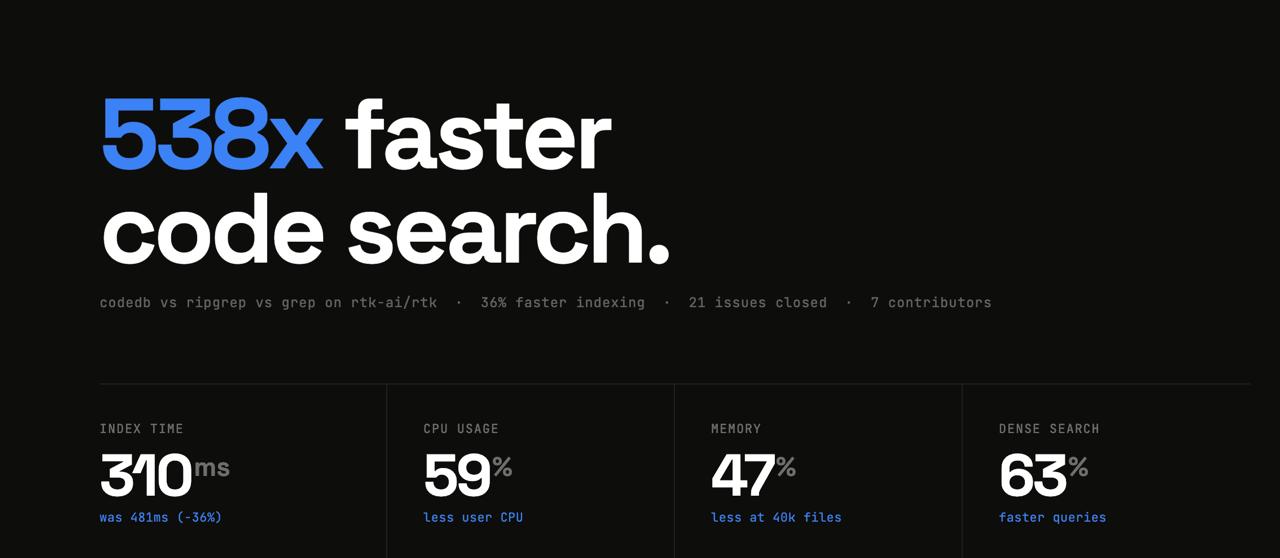
We're launching CodeDB v0.2.53!
538x faster than ripgrep. 569x faster than rtk. 1,231x faster than grep.
0.065ms code search. Pre-built trigram index. Query once, instant forever.
21 issues closed. 14 PRs merged. 7 contributors. One weekend. https://t.co/naTJcNyVxh
0
Hype for autoresearch has died down a bit but I believe it is a new paradigm that makes the best out of LLMs.
There’s millions of things you can autoresearch today that are worth money, attention, and recognition.
Best breakdown of it yet:
https://t.co/AhRTNVcI1t
A
My next video will be positively awesome!
- Train sub-nano 0.1B language models on custom narrow tasks
- Write model SDKs/APIs that run blazingly fast in client machine. I'm talking 350 tok/s with 0.3GB peak memory
- How to create synthetic datasets and ship vertical SLMs https://t.co/EvAN2KuOTr