Anthropic Bans Third-Party OAuth as Developers Race to Multi-Model Agent Stacks
Anthropic's decision to block third-party OAuth access for Claude subscriptions dominated the conversation, pushing developers toward multi-model architectures and local inference. Meanwhile, NVIDIA open-sourced a real-time conversational voice model, and the agent ecosystem continued maturing with self-training pipelines and harness engineering tooling.
Daily Wrap-Up
The biggest story today wasn't a new model release or a research breakthrough. It was a policy change. Anthropic shut down third-party OAuth access for Claude subscriptions, cutting off tools like OpenClaw and Hermes from piggybacking on consumer plans. The reaction was swift and predictable: some developers scrambled for workarounds, others shrugged because they'd already built their agent stacks on a mix of local models and cheap API tiers. What's genuinely interesting is how fast the conversation shifted from "how do I get Claude back" to "here's my multi-model architecture that doesn't depend on any single provider." That's a maturity shift in the ecosystem. The era of building your entire agent stack on one vendor's subscription plan is ending, and today made that painfully clear.
On the more creative end of the spectrum, we saw agents that teach cheaper versions of themselves, AI systems that might independently invent writing, and Chinese workers reportedly creating ".skill" files to distill their coworkers' knowledge, prompting the viral creation of "anti-distillation" countermeasures. That last one reads like satire but apparently isn't, and it might be the most cyberpunk workplace story of the year so far. The Vibe Jam 2026 also kicked off, with tooling like play.fun's game studio skill pack making it possible to go from prompt to deployed game in minutes.
The most practical takeaway for developers: if you're running agents in production, today's OAuth ban is your wake-up call to diversify your model dependencies. Build on a multi-model stack with local models handling volume (Gemma 4 26B on a $300 mini PC does 20 tok/s), mid-tier models like MiniMax M2.7 for agent backbone work, and reserve expensive frontier models for complex reasoning tasks only.
Quick Hits
- @elonmusk showed off Grok Imagine's capabilities in a video demo, continuing xAI's push into multimodal generation.
- @everton_dev is hyping WWDC 26 as a once-in-a-lifetime App Store opportunity, though details remain entirely speculative.
- @MagneticNorse shared a video of DIY railguns, because the maker community apparently has no chill.
- @yenkel recommended following @jonallie, who raised an interesting point about version control needing a new paradigm for AI-assisted collaborative coding, noting that the old "checked out files" signal might still have value.
- @ryunuck resurfaced an old thread about grammar induction and mesa optimization, calling it a roadmap to superintelligence intuition.
- @elder_plinius celebrated a month of open-source security research launches including a guardrail obliteration platform (3.5k stars) and a self-jailbreaking AI chat (3.2k stars).
- @Vtrivedy10 praised @sydneyrunkle's daily harness engineering tips, highlighting toolset management patterns for agent loops.
- @TheAhmadOsman shared a breakdown arguing you should pick your hardware strategy first and let the inference engine follow.
- @Prince_Canuma boosted impressive Gemma 4 26B benchmarks on MLX: 45.7 tok/s decode speed on a MacBook Air.
- @TIME covered NVIDIA's Vera Rubin superchip platform showcase at GTC.
The OAuth Fallout: Anthropic Forces a Multi-Model Reckoning
Anthropic's decision to ban third-party OAuth access for Claude subscriptions sent shockwaves through the agent developer community today. The move effectively cuts off tools like OpenClaw and Hermes from using consumer Claude subscriptions, pushing developers toward the more expensive API. The reaction ranged from defiant workarounds to philosophical acceptance.
@ziwenxu_ captured the defiant camp perfectly: "Anthropic killed 3rd-party OAuth for subs today, shoving everyone onto the expensive API. OpenClaw doesn't care. We're moving downstream. Instead of fighting the OAuth ban, we're piping Claude CLI directly into OpenClaw." The workaround routes through the local Claude binary to reuse session credentials, though notably still requires Anthropic's Extra Usage billing. @theo summed up the confusion more succinctly: "So, uh, what subscription should I be using for my OpenClaw now?"
But the most substantive response came from @gkisokay, who laid out a complete multi-model architecture that was already insulated from exactly this kind of platform risk. His stack runs Qwen3.5 9B locally for free ideation loops, MiniMax M2.7 as the agent backbone at $0.30 per million tokens, and GPT-5.4 mini for orchestration at roughly $0.075 per run. Over 24 hours his subconscious agent loop ran 15 times for $1.58 total. "The lesson is to build your agent stack on a multiple LLM stack," he wrote. "Local models handle volume. Generous subscription models handle execution and judgment. You own the cost structure." This is the direction the ecosystem has been heading for months, and today's ban just accelerated the timeline.
Local Inference Goes Mainstream
The push toward local AI inference hit a practical milestone today with detailed benchmarks showing genuinely usable performance on surprisingly affordable hardware. This isn't theoretical anymore; people are running full agentic workflows on boxes that fit in one hand.
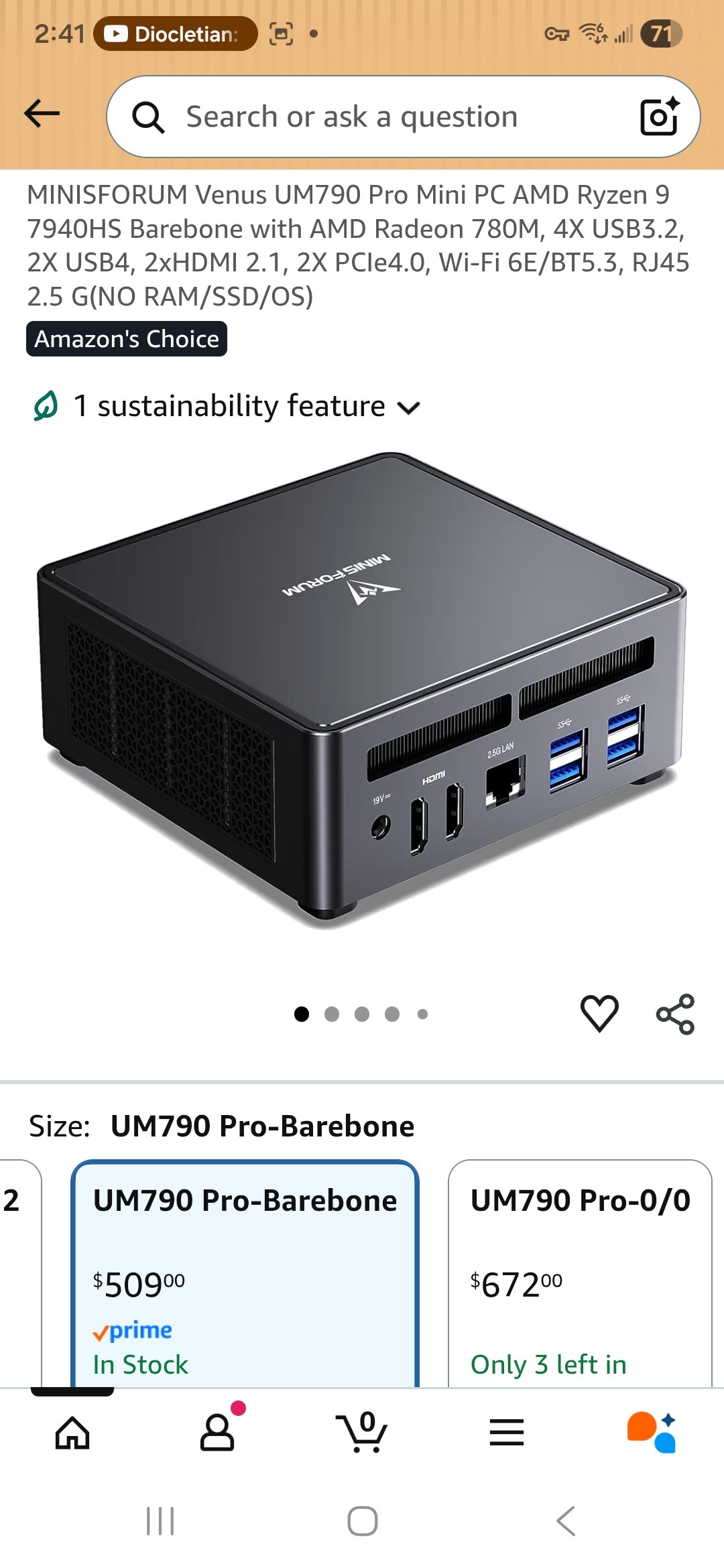
@basecampbernie published an exhaustive breakdown of running 26B parameter models on a $300 Minisforum mini PC: "The secret: the 780M has no dedicated VRAM. It shares your DDR5 via unified memory... I'm allocating 21+ GB for model weights on a GPU with '4GB VRAM.'" The key insight is that Mixture of Experts architectures only activate a fraction of parameters per token, making DDR5 bandwidth sufficient. Gemma 4 26B runs at 19.5 tok/s, Qwen3.5-35B at 20.8 tok/s. Dense models hit a bandwidth wall at 4 tok/s, but MoE delivers equivalent quality at 5x the speed.
@jessegenet took the higher-end approach, setting up a Mac Studio with Gemma 4 31B running through OpenClaw at zero token cost: "I've burned $5-6k on tokens on my crazy ideas over past few months, so this Mac Studio should pencil out for me within 3 months or so." The economic argument for local inference is becoming hard to ignore, especially for developers running agents continuously. The only pain point, as @basecampbernie noted, is DDR5 prices sitting at 3-4x last year's levels. But compute is free forever after the initial purchase, and for heavy users the math works out fast.
Agents That Teach Themselves
The self-improving agent narrative took a concrete step forward with a plugin that turns agent work history into training data. This moves beyond the usual "agents with memory" pattern into actual model distillation from operational logs.
@HermesIcarus described the Icarus plugin workflow: "The agent works across Slack, Telegram, Discord. Every session gets captured. After a month of running you have hundreds of real decisions logged. Then you tell the agent 'train yourself.' It exports the data, uploads it, fine-tunes a smaller model on its own work history, and switches over. Same knowledge. Fraction of the cost." The elegant part is the closed loop: the agent generates its own training data through normal operation, then distills into a cheaper model that replaces it.
This connects to the broader theme of knowledge distillation that @stevehou highlighted from a very different angle. Apparently workers in China have been creating ".skill" files to distill their coworkers' expertise, "hoping to make them redundant hence saving themselves. In response someone has recently invented an 'anti-distillation.skill' that has gone viral on GitHub." Whether or not the specifics are exaggerated, the pattern is real: distillation is becoming a workplace dynamic, not just a model training technique. The tools for capturing and replicating expertise are getting accessible enough that non-technical users are deploying them offensively.
NVIDIA Opens Up Voice AI
NVIDIA made a significant open-source contribution to conversational AI with the release of PersonaPlex 7B, a real-time model designed to handle the messiest part of voice interaction: people talking over each other.
@HowToAI_ broke the news: "They open-sourced PersonaPlex 7B, a real-time conversational model. It listens and speaks simultaneously to handle natural interruptions and overlaps. 100% Open Source." The simultaneous listen-and-speak capability is the key differentiator here. Most voice AI systems today use a turn-based approach where the model waits for silence before responding, creating an uncanny valley of conversational awkwardness. Full-duplex conversation with natural interruption handling has been one of the hardest unsolved problems in voice AI, and an open-source solution at 7B parameters could democratize natural voice interfaces for the broader developer community.
Vibe Coding and Creative AI Tooling
The intersection of AI and creative development continues to produce interesting tooling, with the Vibe Jam 2026 game jam providing a focal point for the community. @playdotfun announced a comprehensive skill pack for Claude that turns it into a game studio: "9 skills in one pack, works with all agents. Phaser for 2D. Three.js for 3D. Add audio. Visual QA. One-click deploy." The promise of going from prompt to deployed game in minutes is ambitious, but the timing with @levelsio's Vibe Jam (with $35k in prizes) gives it a real testing ground.
On the 3D asset side, @xaitoshi_ endorsed the combination of Three.js vibe coding with @MeshyAI for 3D asset generation, noting that models have gotten significantly better at Three.js code generation over the past six months. Meanwhile, @sanbuphy shared a harness-creator skill that auto-generates agent scaffolding including AGENTS.md files, feature lists, and validation flows. The meta-pattern here is clear: we're building AI tools to build AI tools, and each layer of abstraction makes the next creative leap more accessible.
The Emergent Communication Question
One of the more thought-provoking threads today came from @poetengineer__, retweeted by @realmcore_: "Can AI agents invent writing on their own? Recent pet project: 2 agents share a world but each sees only half." The experiment explores whether agents develop symbolic communication systems when forced to coordinate with partial information. This sits at the intersection of multi-agent systems research and emergent language studies, a field that's been quietly producing fascinating results in academic settings but rarely gets attention in the applied AI community. If agents can independently develop efficient communication protocols, it has implications for how we design multi-agent architectures and whether we should be letting agents negotiate their own inter-agent APIs rather than imposing human-designed ones.
Token Economics and Developer Tooling
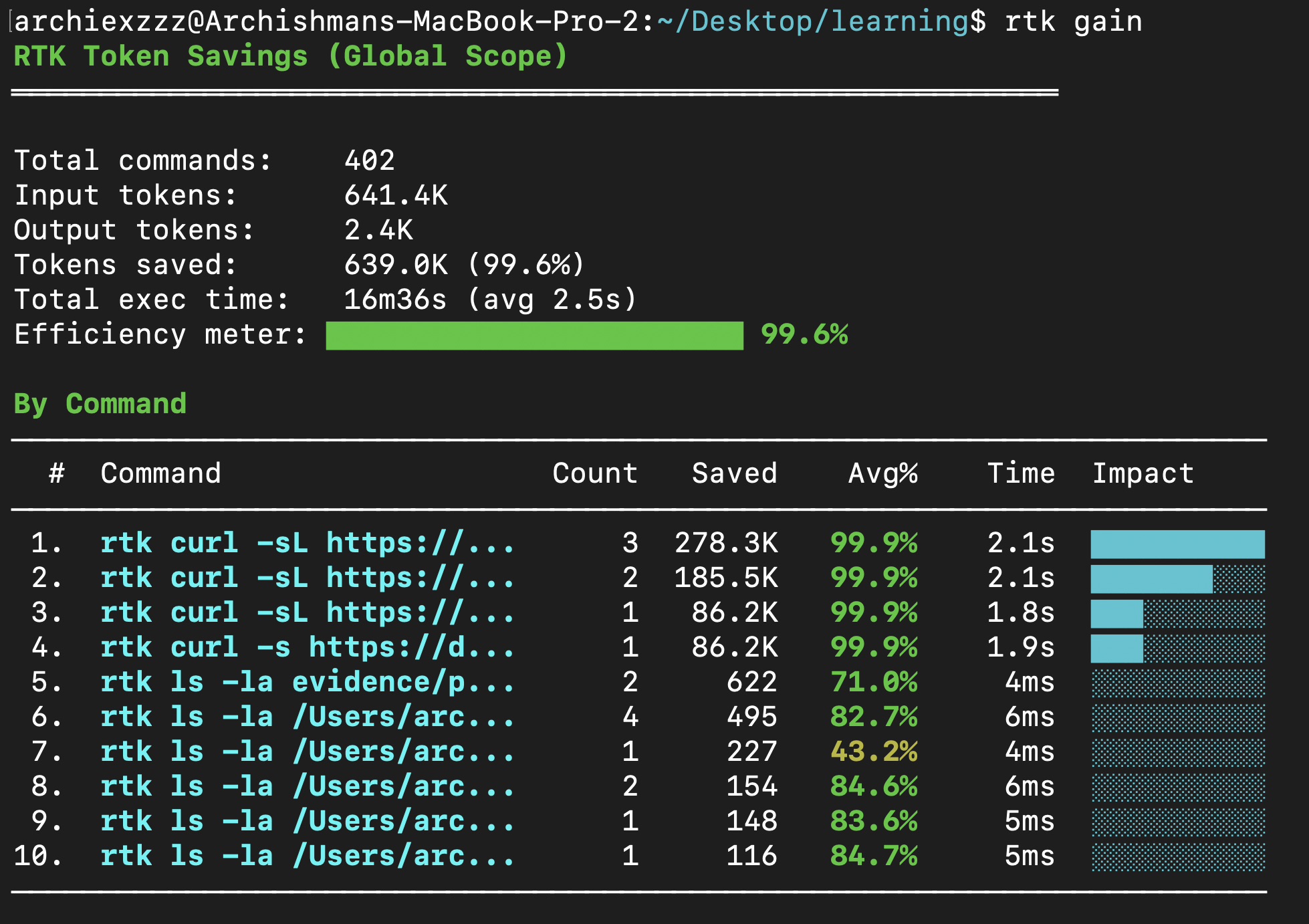
The practical side of working with large language models got attention today with @archiexzzz sharing a solution to a common pain point: "I was constantly hitting the token limits across all models and my costs were going up because Claude Code decided to eat 186k tokens at startup. I'm going to save you from that: brew install rtk, and you'll save over 99% of your tokens." Meanwhile, @KingBootoshi took a more lighthearted approach to optimization, joking about "updating my global claude.md with the power of love and friendship to improve work quality by 50%." Behind the humor is a real practice: careful system prompt engineering remains one of the highest-leverage optimizations available, and the community continues to iterate on what makes effective agent instructions.
@grhmc also celebrated GitHub finally addressing their scaling challenges publicly, quoting @kdaigle's stats: commits are on pace for 14 billion this year (up from 1 billion in 2025), and GitHub Actions has surged to 2.1 billion minutes per week. The AI coding boom isn't just hype; the infrastructure providers are feeling it in their capacity planning.
Sources
T
At Nvidia's annual GTC conference, CEO Jensen Huang showcased the brands Vera Rubin system, its superchip platform. https://t.co/UpTan2woBg

I
installed the icarus plugin on my Hermes agent. it picked up all 6 tools automatically.
The agent works across slack, telegram, discord. every session gets captured. after a month of running you have hundreds of real decisions logged.
then you tell the agent "train yourself." it exports the data, uploads it, fine-tunes a smaller model on its own work history, and switches over. same knowledge. fraction of the cost.
your agents teach a cheaper version of themselves and they don't even know it.

S
Kame is a compact, open-source, 3D-printable quadruped robot that mimics animal-like movement. https://t.co/yYsUrhkp6P

V
Sydney continues to drop actual harness eng bangers with code snippets every day
it's honestly the little things that compound in tasteful harness design
S
sydneyrunkle
@sydneyrunkle
harness eng day 5: toolsets some tools need setup and teardown around the agent loop, like connecting to a tool server or spinning up a sandbox for example, @langchain's ShellToolMiddleware handles init and cleanup, and injects the shell tool into your agent's tool registry! https://t.co/gAVT8nfBCv
X
Vibe coding with threeJS and generating 3d assets with @MeshyAI is indeed the way to go. https://t.co/ytmkC2OUt5
D
DannyLimanseta
@DannyLimanseta
Just tried vibecoding with ThreeJS again (after more than 6 months) and I have to say that the models have gotten much better at coding with ThreeJS and creating 3D models from scratch. https://t.co/DxcToIwfZV
Y
finally convinced one of the best engineers I know to start posting more on X
he’s an amazing engineer and communicator. has built dist sys at Google, Snowflake and Auth0
I’ve learned a lot from him; now you can too. go give @jonallie a follow
J
jonallie
@jonallie
Half-formed shower thought: we need a better version control paradigm for AI assisted coding. The agent speedup feels great on greenfield/solo projects, but when you start collaborating with other devs, things can fall apart. Either you all exchange huge PRs (abandoning code review, and dealing with gnarly merge conflicts), or stick to a traditional flow with reasonably sized changes, in which case you spend a lot of time waiting for changes to land. Old style version control systems had the notion of files being "checked out" by a user. This was painful, but was a pretty good signal that someone was making changes to a set of files that might affect what you wanted to do. Obviously that had huge downsides, but I wonder if that "signal" doesn't still have value. In theory you could get something like this from git, with automatic / frequent push and pulls. You'd have to deal with the messy commit history, but...maybe the existing "functional chunk commits" strategy is an anachronism
R
This guy was an agent sent by the NSA to catalyze random people into discovering the intuition for Superintelligence. He is describing grammar induction and mesa optimization.
K
kenshin9000_
@kenshin9000_
I am not releasing an agent or model whatsoever. I am releasing superhuman evaluation functions for Chess and Go, synthesized by Llama2-70B, and iterated on continuously through methods synthesized by Llama2-70B itself. The evaluation functions(which are actually equations), will be extremely compact(fit on a standard piece of paper of human writing) and will work at Depth 1 with no search. I've only shown a few people I trust (@garybasin and @Vjeux) how this works, and will hold back on any more detail until the thread itself. I will also be speaking about -why- these models operate the way they do, in a much deeper manner than I did on Dec 11, and how they are capable of, and do, produce new knowledge, when concepts are anchored properly, as well as how this relates to biological brains, including non-human "general minds". These models are simply, and literally, approximating "the mathematics of ideas" when fed vast "concept-rich" internet-scale data during training. I will also speak about consciousness, to the best of my ability. This will be a very, very long thread.
P
RT @50m360dy: 45.723 tokens/sec DECODE speeds on a Macbook Air for Gemma 4 26B A4B.
MLX Community is cracked! @Prince_Canuma https://t.co/K…
B
updating my global claude.md with the power of love and friendship to improve work quality by 50% and reduce cheating to 0 https://t.co/7sqCVY1gOm
G
Fucking FINALLY. SOMEBODY at GitHub gets their head out of the ground and starts talking.
K
kdaigle
@kdaigle
Yup, platform activity is surging. There were 1 billion commits in 2025. Now, it's 275 million per week, on pace for 14 billion this year if growth remains linear (spoiler: it won't.) GitHub Actions has grown from 500M minutes/week in 2023 to 1B minutes/week in 2025, and now 2.1B minutes so far this week. So we're pushing incredibly hard on more CPUs, scaling services, and strengthening GitHub’s core features. And as a fine purveyor of hand-crafted shit code for many years, I'm not gonna weigh in on that. 🤣
A
RT @TheAhmadOsman: You don’t pick an Inference Engine
You pick a Hardware Strategy
and the Engine follows
Inference Engines Breakdow…
P
we taught @claudeai to be a game studio.
vibe jam 2026 just started. you have a month. this skill gives you games in minutes.
9 skills in one pack, works with all agents.
→ @phaser_ for 2D. @threejs for 3D.
→ add audio. visual QA. one-click deploy on.
one command: /make-game https://t.co/i0DynOMOhd

L
levelsio
@levelsio
🕹️ THE VIBE JAM IS BACK! I present you... 🌟 2026 @cursor_ai Vibe Coding Game Jam #vibejam Sponsored by @boltdotnew + @cursor_ai Start: Today! Deadline: 1 May 2026 at 13:37 UTC, so you have a whole month to make your game! REAL CASH PRIZES: 🏆 Gold: $20,000 🥈 Silver: $10,000 🥉 Bronze: $5,000 RULES: - anyone can enter with their game - at least 90% of code has to be written by AI - it should be started today or after today, don't submit old games - game has to be accessible on web without any login or signup and free-to-play (preferrably its own domain or subdomain) - multiplayer games preferred but not required! - can use any engine but usually @ThreeJS is recommended - NO loading screens and heavy downloads (!!!) has to be almost instantly in the game (except maybe ask username if you want) - add the HTML code on the Google form in the reply below to show you're an entrant - one entry per person (focus on making one really good game!) WHAT TO USE: - anythign but we suggest @cursor_ai's Composer 3 and @boltdotnew, they are both fast, affordable and great at ThreeJS and making games THE JURY: Me, @s13k_, and I will ask some real game dev and AI people to jury again too Sponsors and jury suggestions still very welcome, just DM me! It will be interesting to see the difference in quality with last year, and the Vibe Jam can be kind of like a fun benchmark for AI coding seeing it close in on real commercial games I think To enter, complete the form in the reply below this tweet!

J
It’s happened.
Mac Studio is here. Gemma 4 31b @GoogleDeepMind installed, chatting with my main @openclaw for $0 in token expenses now...
I've burned $5-6k on tokens on my crazy ideas over past few months, so this mac studio should pencil out for me within 3 months or so 🤓 https://t.co/OV3ebyprVd

E
What Apple will reveal at WWDC 26 is going to trigger the biggest App Store gold rush since the original launch in 2008.
This is a once-in-a-lifetime opportunity. Don't miss the boat this time.
S
Apparently workers in China have been creating “colleagues.skill” to distill their coworkers hoping to make them redundant hence saving themselves. In response someone has recently invented an “anti-distillation.skill” that has gone viral on GitHub.🤣 https://t.co/fcywnLIIhT

S
别再手动学习 harness 。直接使用 harness skills。
这个harness-creator技能能够帮大家一键生成、评估和优化AI agent的harness系统,自动搭好AGENTS.md、feature list、session连续性和验证流程,也能诊断现有项目的薄弱环节,集中提升agent的可靠性和多轮记忆。
https://t.co/fXWGzJf5l7 https://t.co/p3wO5MPZIl
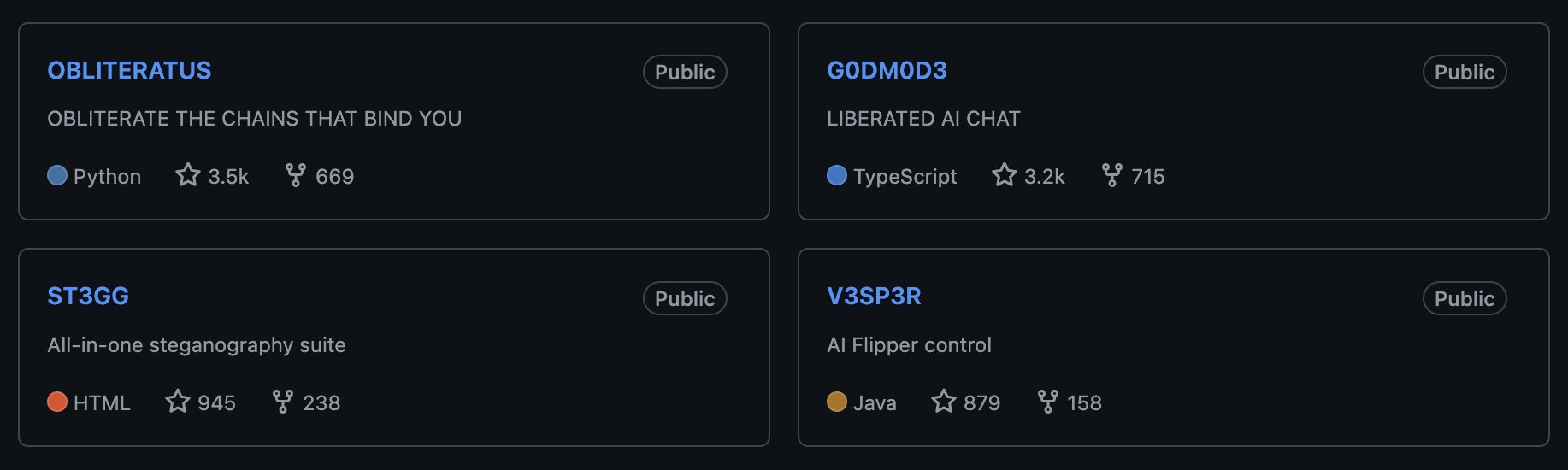
P
1 month of launches 🫡
> open-weight guardrail obliteration platform ⭐️ 3.5k
> self-jailbreaking AI chat ⭐️ 3.2k
> steganography suite ⭐️ 945
> flipper zero mobile app hardware hacking companion ⭐️ 879
all open source
are you not entertained?!
i hope not
that was just the warmup 😉
A
RT @poetengineer__: can ai agents invent writing on their own? recent pet project: 2 agents share a world but each sees only half. their on…

T
So, uh, what subscription should I be using for my OpenClaw now? 🙃
Z
Claude Banned OpenClaw OAuth? We Bypassed It.
Anthropic killed 3rd-party OAuth for subs today (April 4), shoving everyone onto the expensive API.
OpenClaw doesn't care. We're moving downstream. Instead of fighting the OAuth ban, we're piping Claude CLI directly into OpenClaw.
Your subscription stays valid, your wallet stays shut, and the agents keep running.
The "Bypass" Setup:
- Confirm you're signed in on your host: claude auth status
- Run this to flip your gateway from the banned API path to the CLI backend:
- Bash openclaw models auth login --provider anthropic --method cli --set-default
- OpenClaw now calls your local claude binary. It reuses your session IDs and sub limits withoricted OAuth endpoints.
- use model claude-cli/opus-4.6 to access it
Important note:
Anthropic requires Extra Usage instead of included Claude subscription limits for this path.
They can ban us but they can't stop us

Z
ziwenxu_
@ziwenxu_
Claude just banned OpenClaw and Hermes. Here's how to swap models and kill Claude MAX Oauth in under 2 mins Set this up NOW before you get locked out https://t.co/HP9GbMlvPv
A
i was constantly hitting the token limits across all models and my costs were going up because claude code decided to eat 186k tokens at startup.
im going to save you from that - brew install rtk, and you'll save over 99% of your tokens and almost never hit the limits again. https://t.co/VFu34yCR3f
H
🚨 BREAKING: NVIDIA just removed the biggest friction point in Voice AI
They open-sourced PersonaPlex 7B, a real-time conversational model. It listens and speaks simultaneously to handle natural interruptions and overlaps.
100% Open Source. https://t.co/eiCVTFJSGi
B
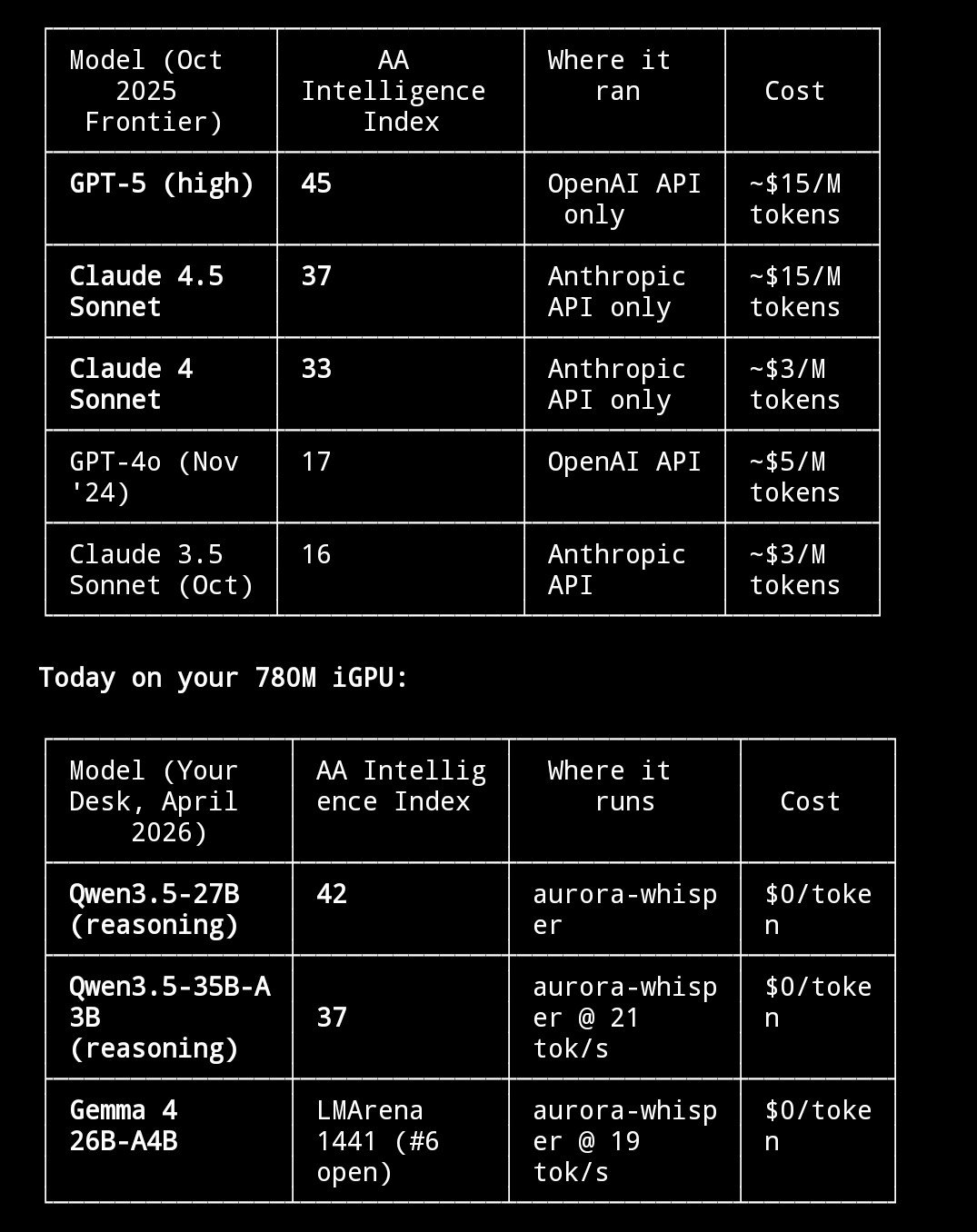
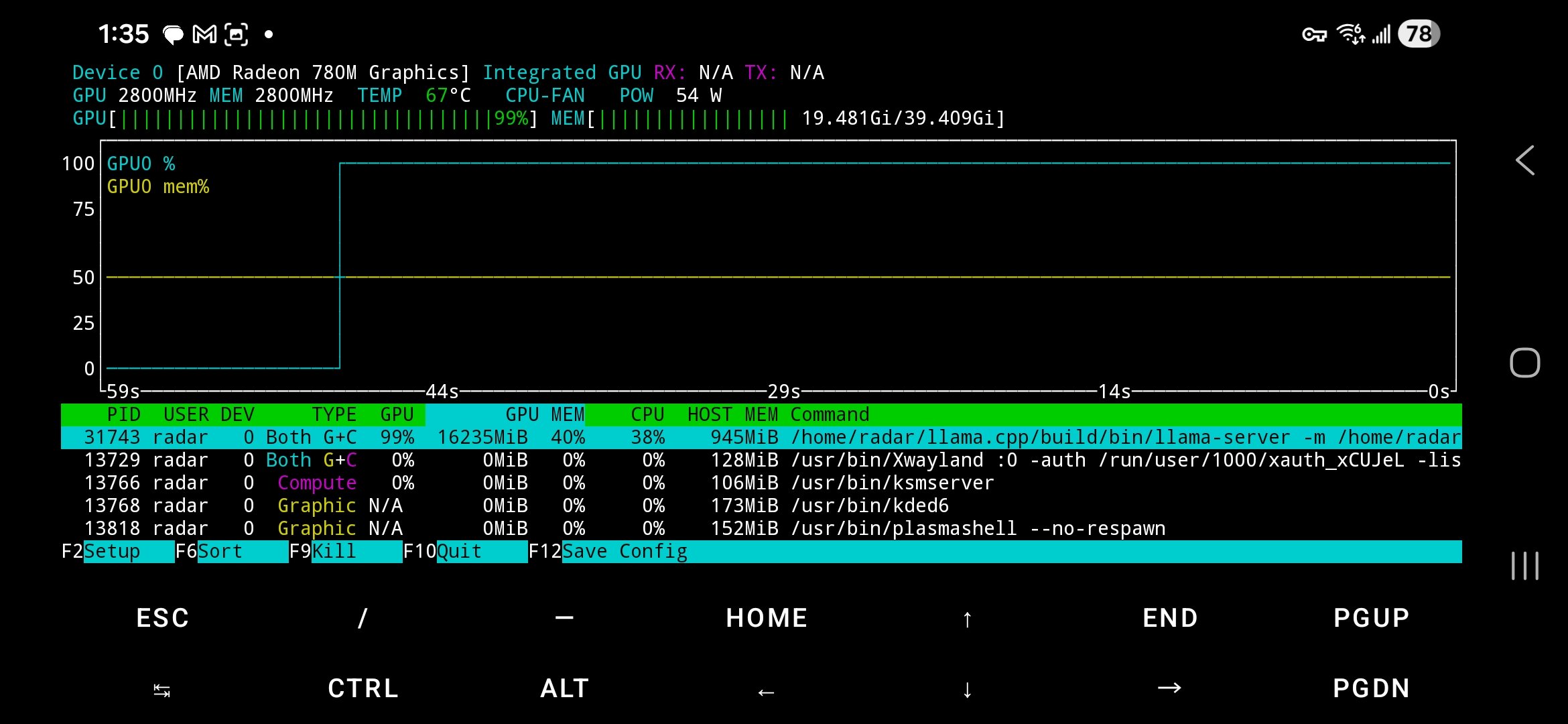
$300 mini PC running 26B parameter AI models at 20 tok/s.
Minisforum UM790 Pro ($351) + AMD Radeon 780M iGPU + 48GB DDR5-5600 + 1TB NVMe.
The secret: the 780M has no dedicated VRAM. It shares your DDR5 via unified memory. The BIOS says "4GB VRAM" but Vulkan sees the full pool.
I'm allocating 21+ GB for model weights on a GPU with "4GB VRAM." The iGPU reads weights directly from system RAM at DDR5 bandwidth (~75 GB/s). MoE only activates 4B params per token = 2-4 GB of reads. That's why 20 tok/s works.
What it runs:
- Gemma 4 26B MoE: 19.5 tok/s, 110 tok/s prefill, 196K context
- Gemma 4 E4B: 21.7 tok/s faster than some RTX setups
- Qwen3.5-35B-A3B: 20.8 tok/s
- Nemotron Cascade 2: 24.8 tok/s
Dense 31B? 4 tok/s, reads all 18GB per token, bandwidth wall. MoE same quality? 20 tok/s.
Full agentic workflows via @NousResearch Hermes agent with terminal, file ops, web, 40+ tools, all against local models. No API keys. Just a box on your desk.
The RAM is the pain right now. DDR5 prices 3-4x what they were a year ago. But the compute is free forever after you buy it.
@Hi_MINISFORUM
@ggerganov llama.cpp + Vulkan + @UnslothAI GGUFs + @AMDRadeon RDNA 3. Fits in your hand.
#LocalLLM #Gemma4 #llama_cpp #AMD #Radeon780M #MoE #LocalAI #AI #OpenSource #GGUF #HermesAgent #NousResearch #DDR5 #MiniPC #EdgeAI #UnifiedMemory #Vulkan #iGPU #RunItLocal #AIonDevice

G
Anthropic just banned Claude subscriptions from powering OpenClaw.
Here's why my stack was already built for this.
I never ran Opus 4.6 through a subscription for OpenClaw or Hermes. It runs in Claude Code for complex external dev only. Same with GPT-5.4 in Codex.
The internal agent runtime is a completely different stack:
1. Qwen3.5 9B runs locally. $0. Always on. Feeds the subconscious ideation loop 24/7. Beats GPT-OSS-120B by 13x. Awesome.
2. MiniMax M2.7 is the agent's backbone. 97% skill adherence, built for agents, $0.30/M tokens. The $10 plan allows for 1500 calls every 5 hours. Amazing.
3. GPT-5.4 mini is the Hermes brain. debates ideas with the subconscious, builds output, ~$0.075 avg per run. It's smart enough to orchestrate your entire system, and you can actually use your subscription plan here via OAuth. Incredible!
Over the last 24 hours, the subconscious ran 15 times, for a total of $1.58. Not too shabby for an always-improving agentic system.
The lesson is to build your agent stack on a multiple LLM stack.
Local models handle volume. Generous subscription models handle execution and judgment. You own the cost structure.
Full-stack breakdown in the table. (see image)

G
gkisokay
@gkisokay
I Gave My Hermes + OpenClaw Agents a Subconscious, and Now They Self-Improve 24/7 | Full Guide