Karpathy's LLM Knowledge Base Vision Sparks Movement as Gemma 4 Drops and Claude Code Debate Heats Up
Andrej Karpathy's detailed post on using LLMs to build personal knowledge bases became the day's center of gravity, spawning tools and responses from multiple builders. Google launched Gemma 4 with Apache 2.0 licensing to immediate community adoption, while Claude Code dominated the conversation around coding agent workflows, rate limits, and best practices.
Daily Wrap-Up
Today felt like a rare convergence day where several threads in the AI space suddenly knotted together. Andrej Karpathy posted a detailed breakdown of how he uses LLMs to build and maintain personal knowledge bases in Obsidian, and within hours, multiple builders were either validating the approach, shipping tools around it, or extending it with their own research automation stacks. This wasn't just one person's workflow going viral. It exposed a genuine shift in how power users are spending their tokens: less on code generation, more on knowledge compilation and retrieval. The fact that Hermes Agent simultaneously announced seven pluggable memory systems suggests this isn't a niche concern anymore.
Meanwhile, Google dropped Gemma 4 under Apache 2.0, and the open-source community responded with breathtaking speed. Day-zero llama.cpp support, MLX quantizations, fine-tunes on Claude Opus 4.6 thinking traces, and someone already building a full coding agent stack with Gemma 4 as the backbone. The model release cycle has compressed to the point where community tooling ships the same day as the weights. On the Claude Code side, the discourse was less about new features and more about hard-won wisdom: how to navigate large codebases efficiently, why plan mode might be a trap, how to hunt down placeholder code left by agents, and the ever-present rate limit frustrations.
The most practical takeaway for developers: if you're spending all your AI tokens on code generation, consider Karpathy's knowledge-base pattern. Index your domain research into markdown, let an LLM maintain the wiki, and query it as a living reference. The approach works at surprisingly small scale without RAG infrastructure, and multiple tools shipped today to make it turnkey.
Quick Hits
- @OpenAIDevs rolled out usage-based pricing for Codex on ChatGPT Business and Enterprise plans, removing fixed seat costs as a barrier to team adoption.
- @coreyganim pitched a $999 AI audit business model: interview a client, feed the transcript to Claude, generate tool recommendations, upsell from there. Hustle-coded consulting for the AI era.
- @coffeecup2020 highlighted Turbo Quant's Qwopus3.5-v3-27B achieving a median perplexity of 6.1953, pushing quantization quality benchmarks further.
- @ChujieZheng announced plans to open-source Qwen3.6 medium-sized models and asked the community to vote on preferred model sizes.
- @salesforce unveiled the new Slack with native AI integrations including Agentforce and Anthropic partnerships.
- @larsencc shipped a clean CLI tool called "ports" that answers the eternal developer question of what's running on port 3000, with watch and cleanup commands.
- @elonmusk said the next Starship flight and first V3 ship and booster combo is 4 to 6 weeks out.
- @AskFocal promoted their platform for summarizing and querying podcasts, SEC filings, and blog posts.
- @EntireHQ launched automatic session capture for both OpenAI Codex and Claude Code, letting developers rewind and share agent activity by repo.
Claude Code: Workflows, Frustrations, and Hard-Won Wisdom
Claude Code dominated today's conversation not through any single announcement but through a constellation of practitioner insights that paint a picture of a tool ecosystem maturing in real time. The central tension is clear: coding agents are powerful but demanding, and the community is still figuring out the right interaction patterns.
@steipete amplified a sentiment that resonated widely: "Using coding agents well is taking every inch of my 25 years of experience as a software engineer, and it is mentally exhausting." This isn't beginner frustration. It's experienced engineers discovering that delegation to AI requires its own skillset. @mattpocockuk built on this by abandoning plan mode entirely, arguing it "creates a plan FAR too eagerly and usually asks you zero questions en route. The whole point of planning is to get on the same wavelength with the LLM, not to generate an asset you don't read."
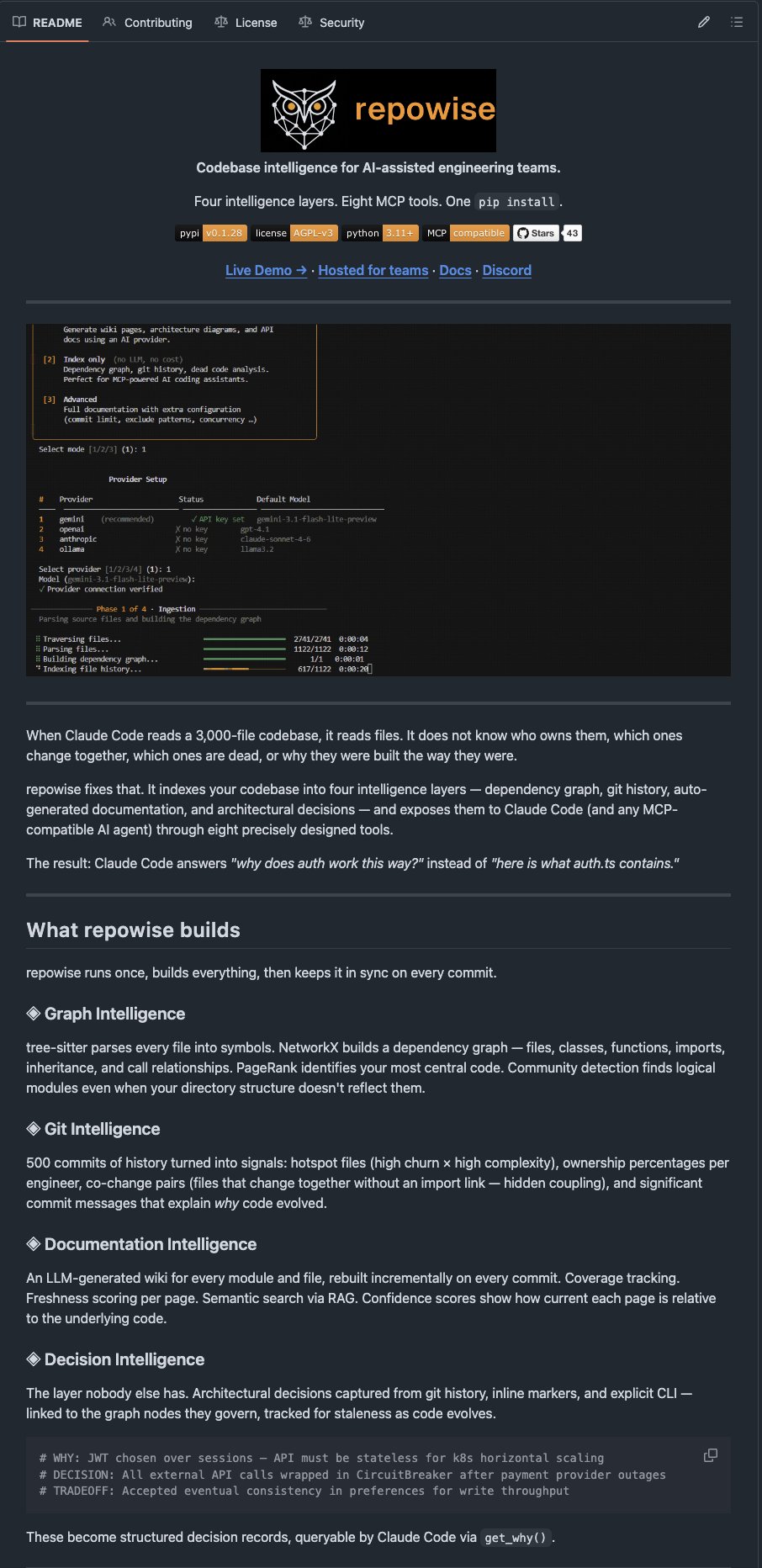
On the tooling side, @NieceOfAnton shared results from testing repowise, an open-source indexer that builds dependency graphs, git history analysis, and auto-generated docs for Claude Code to consume. The claimed result: a 3,000-file codebase task completed in 2 minutes instead of 8, with 60% fewer tokens. The key insight is that repowise "stops Claude from reading files it has no reason to read," which is essentially the context window management problem that defines effective agent use.
@doodlestein contributed an extensive prompt workflow for finding placeholder and mock code that accumulates across long agent-driven development sessions. It's a detailed, practical approach that highlights an underappreciated problem: agents leave artifacts, and cleaning those up is itself an agent-worthy task. @theo raised the rate limit issue that many heavy users are hitting, while @EXM7777 noted that Claude Code's multi-agent orchestration layer has been extracted, made model-agnostic, and open-sourced. The ecosystem is being unbundled even as it's being built.
Gemma 4 Lands with Immediate Community Adoption
Google's release of Gemma 4 under Apache 2.0 was the day's biggest model drop, and the speed of community response was the real story. Four sizes (31B dense, 26B MoE, 4B, and 2B), all commercially permissive, and the open-source toolchain mobilized instantly.
@ggerganov credited his collaborator Son (ngxson) with leading the llama.cpp integration, noting the "day-0 support is possible thanks to his hard work" in close collaboration with the Google DeepMind team. @neural_avb pointed to someone who had already uploaded 125 MLX-quantized models within hours of release, adding that developers who aren't building on this for Mac are missing an opportunity. The post also carried a broader critique: "people don't understand what edge models are for" and "people don't understand there is AI outside LLMs."
The creative applications started immediately. @kaiostephens fine-tuned Gemma-4-31b on Claude Opus 4.6 thinking traces "to improve the overall quality and personality of the model," an approach that essentially distills one model's reasoning style into another's weights. @iotcoi went further, assembling a full coding agent stack with Gemma-4 31B as the primary model and Gemma-4 2B handling speculative decoding, running through Claude Code's harness with a DSPy-GEPA router. The thesis: you can build a better coding agent at home than with Google's own hosted Gemini and its default tools. Whether that holds up at scale remains to be seen, but the architectural ambition is notable.
Karpathy's Knowledge Base Manifesto and the Tools Racing to Implement It
The day's most intellectually rich thread started with Andrej Karpathy describing his workflow for using LLMs to build and maintain personal knowledge bases. The core idea: collect raw data from various sources, use an LLM to "compile" it into a structured markdown wiki, then query and enhance that wiki through agent interactions, all viewable in Obsidian. No fancy RAG needed at moderate scale. As Karpathy put it, the LLM handles "auto-maintaining index files and brief summaries" well enough that retrieval works naturally at around 100 articles and 400K words.
@kevinnguyendn responded with ByteRover, claiming "Karpathy just validated the exact architecture we open-sourced today." ByteRover aims to give you "the human-readable files of Obsidian, but the backend automatically creates nodes, links, and context graphs for agents to use natively." The pitch is automating the compilation step that Karpathy describes doing semi-manually.
@omarsar0 (elvis) offered the most differentiated take, describing a system where he's automated daily research paper curation using a fine-tuned skill that surfaces high-signal papers. The papers get indexed using markdown with rich metadata, fed into an interactive artifact generator, and visualized through an agent orchestrator. His key insight lands on the search problem: "The automations, autoresearch, ralph research loop are easier to build but are only as good as what you feed them." The implication is that knowledge base quality is the bottleneck, not agent capability.
AI Agent Memory Goes Pluggable
The memory and persistence layer for AI agents is becoming a competitive frontier. @sudoingX highlighted that Hermes Agent now supports seven different memory systems, from local SQLite to knowledge graphs to vector search, all pluggable via a standardized interface. "Self-hosted or cloud. Local sqlite or knowledge graphs. Vector search or filesystem hierarchy. Pick what fits your workflow and plug it in."
@steveruizok amplified a related point about Hermes: that agents accumulate meaningful artifacts across sessions, including research, skills, decisions, and logs. After a few weeks, you have hundreds of documents that represent genuine learned context. Combined with @jack praising Goose as a "superpower" whose capabilities have quietly improved under the hood, the pattern is clear: the agentic tool landscape is fragmenting into specialized, interchangeable components rather than converging on monolithic platforms. The winner may be whichever system makes memory and tool integration feel seamless rather than whichever model runs underneath.
Open Source Tools and the Modular Agent Stack
Several releases today reinforced the trend toward modular, self-hosted agent tooling. @0xSero announced Factory Droid is now free for all, letting users bring their own API keys and route through local proxies or self-hosted endpoints with support for Anthropic, Responses, and other API formats. @RayFernando1337 showcased oh-my-codex (omx) being used with tmux and deep-interview workflows, suggesting the CLI-native agent experience is finding its audience among power users who want terminal-first control.
The common thread across these tools is optionality. Nobody is betting on a single model provider or a single interface. The stack is: pick your model, pick your harness, pick your memory system, pick your IDE integration. The developers building in this space are treating every layer as swappable, which mirrors how the broader infrastructure world learned to think about cloud services a decade ago. The question is whether this modularity survives contact with the need for tight, reliable integration at production scale.
Sources

Excited to launch Gemma 4: the best open models in the world for their respective sizes. Available in 4 sizes that can be fine-tuned for your specific task: 31B dense for great raw performance, 26B MoE for low latency, and effective 2B & 4B for edge device use - happy building! https://t.co/Sjbe3ph8xr


I never use plan mode. The main reason this was added to codex is for claude-pilled people who struggle with changing their habits. just talk with your agent.
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.


how to print $$ selling AI audits to small businesses (full guide)
We just released Gemma 4 — our most intelligent open models to date. Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows. Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓
Hermes Agent now supports @plastic_lab's Honcho, @mem0ai, @openvikingai, @Vectorizeio's Hindsight, @retaindb, and @ByteroverDev memory systems! Try them now with `hermes update` then `hermes memory setup` We have rehauled our memory system to be much more maintainable and pluggable, so anyone can make their own memory system to build on top of Hermes easily and cleanly with a special class of plugin! Which memory system is your favorite?
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.

This guy is BEYOND CRACKED. Gemma 4 already on MLX, bro has uploaded all models with quantization. 125 models uploaded in last few hours 🤯 New mlx-vlm repo also supports turbo-quant, and rf-detr too (among other things) If you are a mac dev, you better be jumping at this. Bookmark him, turn his notifications on, sponsor his work.
While working on the pre-release support of gemma 4, I was surprised by its capabilities compared to their size. We're tapping on the surface here, there are more and more to discover about gemma 4. I'm excited to see what the community will do with it in the next few days 🚀🚀
What’s everyone’s thoughts on oh my codex?


Free Droid for all.
How to set up Factory Droid with any model Bring your own keys, route through a local proxy, or point at a self-hosted endpoint. Droid lets you swap i...