Claude Code Source Leak Reveals Token-Burning Bug as 1-Bit Models and Agent OS Push AI to the Edge
The Claude Code source code leak dominated today's conversation, exposing an autoCompact bug that caused runaway token consumption and sparking debate about open-sourcing AI tooling. Meanwhile, PrismML emerged from stealth with a 1-bit model fitting in 1.15GB, Liquid AI shipped agentic capabilities at 350M parameters, and a new WASM-based "agentOS" promised 6ms cold starts for AI agents.
Daily Wrap-Up
Today was the Claude Code show, and not in the way Anthropic would have planned. The source code leak that's been rippling through the developer community reached a crescendo as people dug through the internals, found a token-burning autoCompact bug, and watched Anthropic respond by apparently just... making the repo public. The incident is a fascinating case study in how the age of AI tooling handles transparency by force. One community member found that the autoCompact mechanism would retry infinitely on failure, with one session logging 3,272 consecutive failures. The fix? Three lines of code. It's both humbling and reassuring that even the most sophisticated AI harnesses can be brought low by a missing retry cap.
Beyond the drama, the real story today is the continued march toward smaller, cheaper, and more local AI. PrismML launched out of stealth with a 1-bit model that fits in 1.15GB while staying competitive with full-precision counterparts. Liquid AI released a 350M parameter model capable of agentic tool use. And tinygrad finally got Apple to approve their eGPU driver for Mac, meaning you can now run local models on external NVIDIA and AMD GPUs through Thunderbolt. These aren't disconnected events. They're converging on a future where meaningful AI inference happens on your device, on your terms, without a cloud bill.
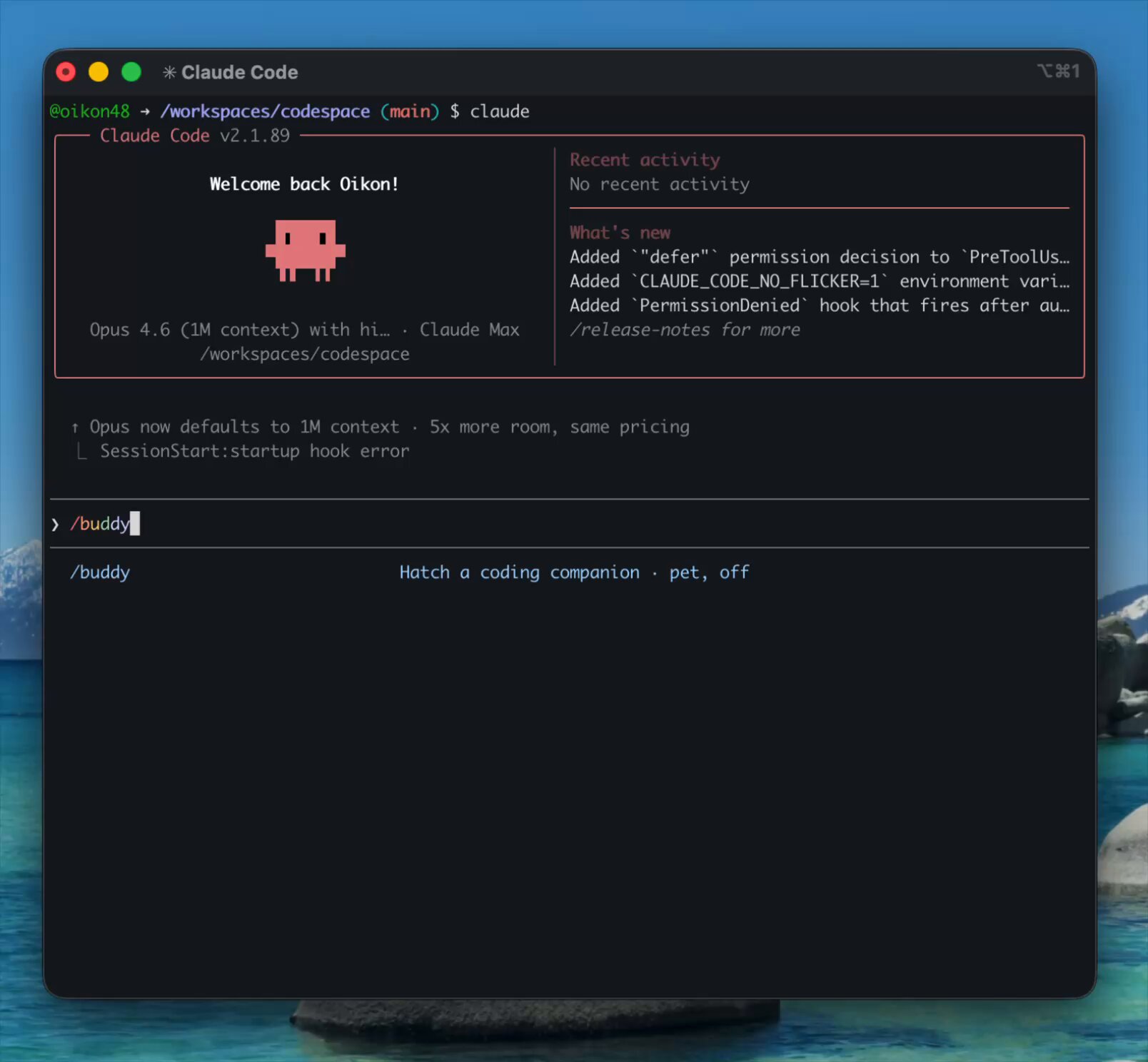
The most entertaining moment was easily Claude Code's April Fools /buddy command, which spawns a little companion creature in your terminal. Different users get different creatures, which is a delightful touch from a team that was simultaneously dealing with their entire codebase being picked apart in public. The most practical takeaway for developers: if you're building AI-powered tools, implement hard caps on retry loops and recursive operations from day one. The Claude Code autoCompact bug is a textbook example of how an unbounded retry in a background process can silently drain resources at scale, and it took a source leak for anyone to notice.
Quick Hits
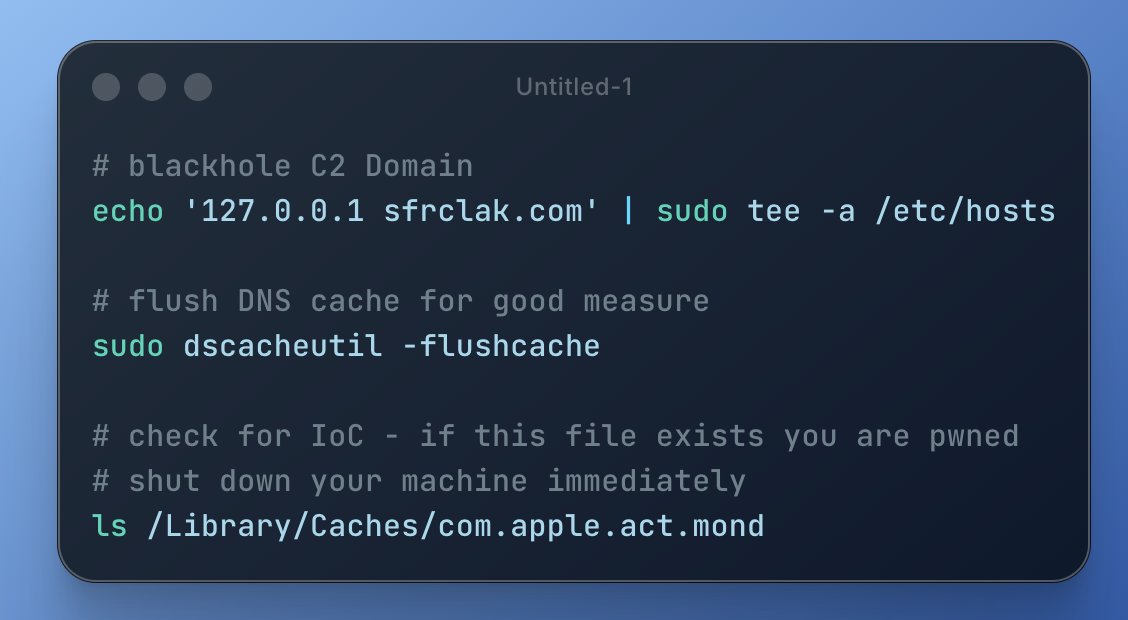
- npm supply chain attack alert: @0xblacklight flagged an urgent security incident affecting recent npm/bun installs, urging developers to check for indicators of compromise and shut down affected devices immediately.
- Tesla Model S & X end of an era: @elonmusk announced that custom orders for the Model S and X have ended after 14 years, with only inventory units remaining.
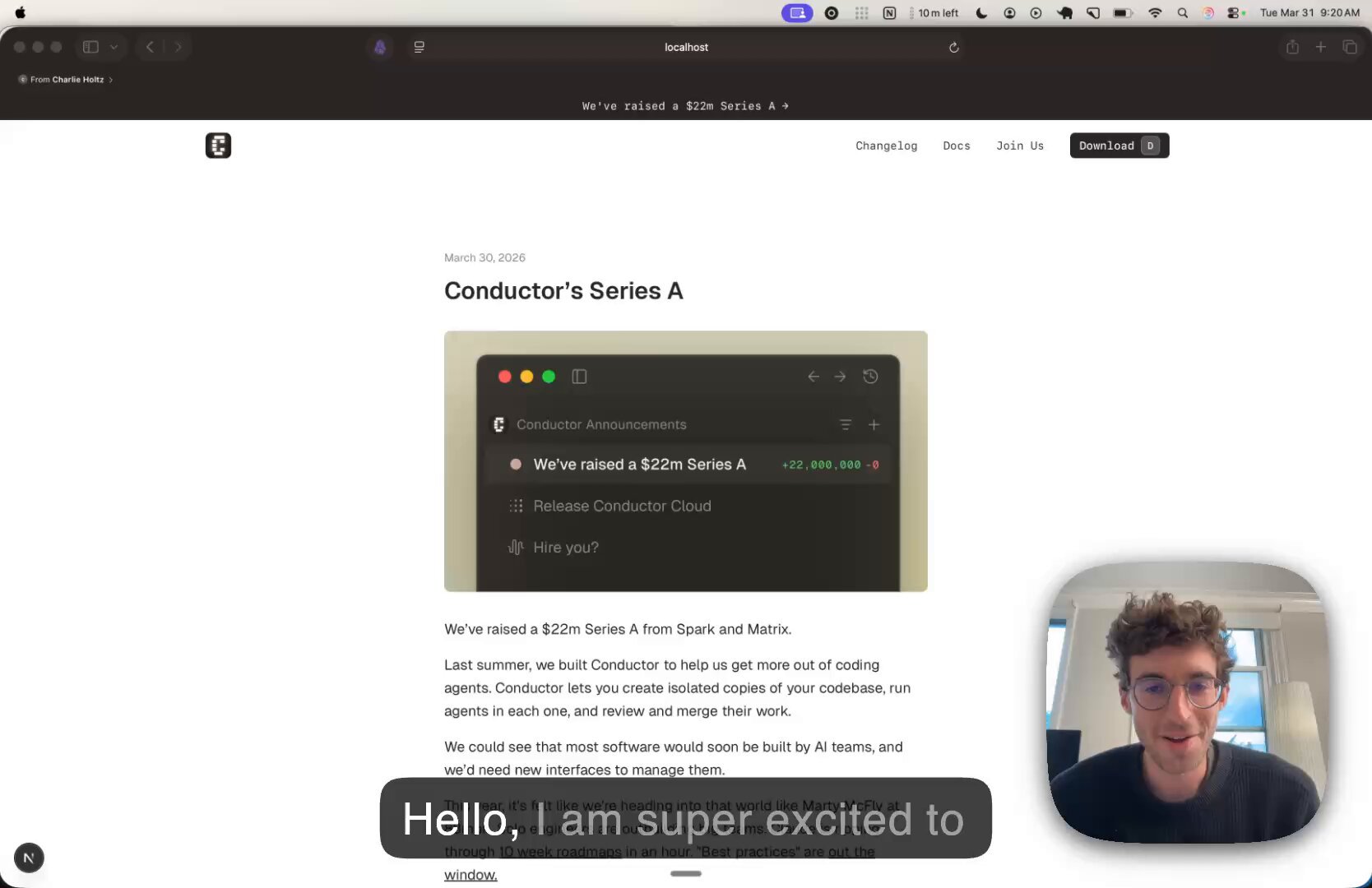
- Conductor Build raises $22M Series A: @charlieholtz announced the round led by Spark and Matrix, with backing from YC and founders of Notion and Linear.
- Codex rate limit reset: @thsottiaux reset usage limits for all Codex plans after dashboards showed unexplained rate limit spikes, and celebrated banning a pocket of fraudulent accounts that freed up compute.
- Grok Imagine generating buzz: @minchoi highlighted creative use cases emerging from Grok's image generation capabilities.
- AI for non-software engineers: @hive_echo polled mechanical, electrical, and other traditional engineers on whether AI accelerates their daily work, seeking real-world adoption stories beyond the software bubble.
- Semiconductor cost reset: @jukan05 amplified @rtodi's deep analysis of why MCU and wireless chip prices are permanently resettling higher due to geopolitical tensions, fab capacity constraints, and packaging bottlenecks.
- LangChain DeepAgents recommendation: @mstockton praised DeepAgents from LangChain and @sydneyrunkle's harness engineering series covering dynamic config and middleware patterns.
Claude Code: From Leak to Lessons
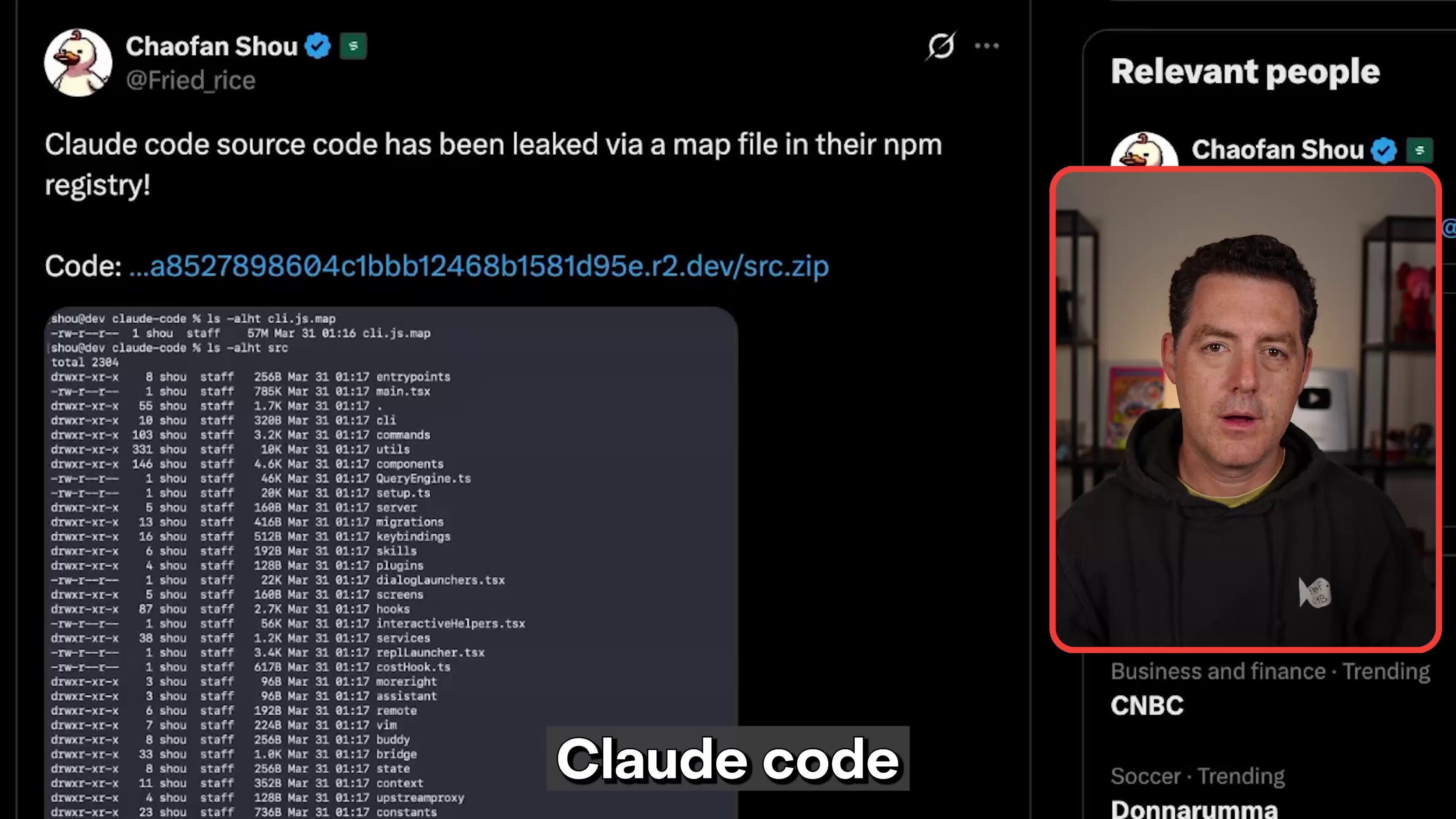
The biggest story of the day wasn't a product launch or a model release. It was a source code leak that turned into an impromptu open-source audit. Claude Code's source files became public, and the developer community wasted no time dissecting what makes the harness tick. @MatthewBerman offered a full breakdown, noting "we can finally see what makes the harness so good." @ivanleomk captured the mood perfectly: "Did anthropic just decide to release claude code's entire source code since it got leaked lmao, their github repo is no longer private."
But the real revelation came from the bug hunters. @imyouhu detailed how someone fed the leaked source to OpenAI's Codex and discovered the autoCompact mechanism, Claude Code's context compression system, had no failure cap on retries. The post noted that session logs showed up to 3,272 consecutive failures, silently burning tokens the entire time. The fix was almost comically simple: a three-line patch adding MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3. This directly connected to the rate limiting complaints that @lydiahallie had acknowledged from Anthropic's side.
Meanwhile, @melvynx retweeted a warning about an emulator that makes API calls identical to Claude Code subscription requests, a predictable downstream consequence of source code exposure. And on a lighter note, @oikon48 discovered that the Claude Code team had shipped an April Fools /buddy command that spawns a companion creature in your terminal. Anthropic's response to the whole situation reflected their engineering culture. @AlexPalcuie, quoting colleague @bcherny, emphasized: "We have a blameless culture and no single individual is at fault when bespoke complex systems break at scale." The incident revealed that a manual deploy step should have been better automated, and the team is improving processes. It's a rare look at how an AI company handles a very public stumble, and the combination of transparency, quick fixes, and an April Fools easter egg suggests a team that's keeping its composure.
Small Models, Big Ambitions
A clear theme is emerging in 2026: the race isn't just to build bigger models, it's to build absurdly capable small ones. Two launches today pushed this narrative forward in complementary ways. PrismML, a Caltech-origin AI lab, emerged from stealth with Bonsai 8B, a 1-bit weight model that fits in 1.15GB of memory. @BrianRoemmele called it "a rather big deal," highlighting that they've "broken records in intelligence density." The numbers are striking: 14x smaller, 8x faster, and 5x more energy efficient on edge hardware while remaining competitive with full-precision models in its parameter class. All models are open-sourced under Apache 2.0.
On an even smaller scale, Liquid AI released LFM2.5-350M, a model purpose-built for data extraction and tool use at just 350 million parameters. @TheAhmadOsman called it validation of a broader trend: "As predicted, small and specialized models are gonna eat the world." When quantized, the model fits under 500MB, targeting environments where compute, memory, and latency are hard constraints.
These releases aren't just academic exercises. They represent a practical shift in what's possible on consumer hardware, in embedded systems, and at the edge. When you can run agentic loops on a model smaller than most desktop applications, the design space for AI-powered products changes fundamentally. The PrismML team put it well: "When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately."
Agent Infrastructure Takes Shape
The tooling layer around AI agents is maturing rapidly, and today brought several pieces of that puzzle into focus. The most ambitious was agentOS from @rivet_dev: a portable, open-source operating system built specifically for agents, powered by WASM and V8 isolates. @jpschroeder's reaction captured the developer sentiment: "About time someone used WASM as a container replacement!" The specs are compelling: roughly 6ms cold starts at 32x lower cost than traditional sandboxes, with the ability to mount anything (S3, SQLite) as a filesystem.
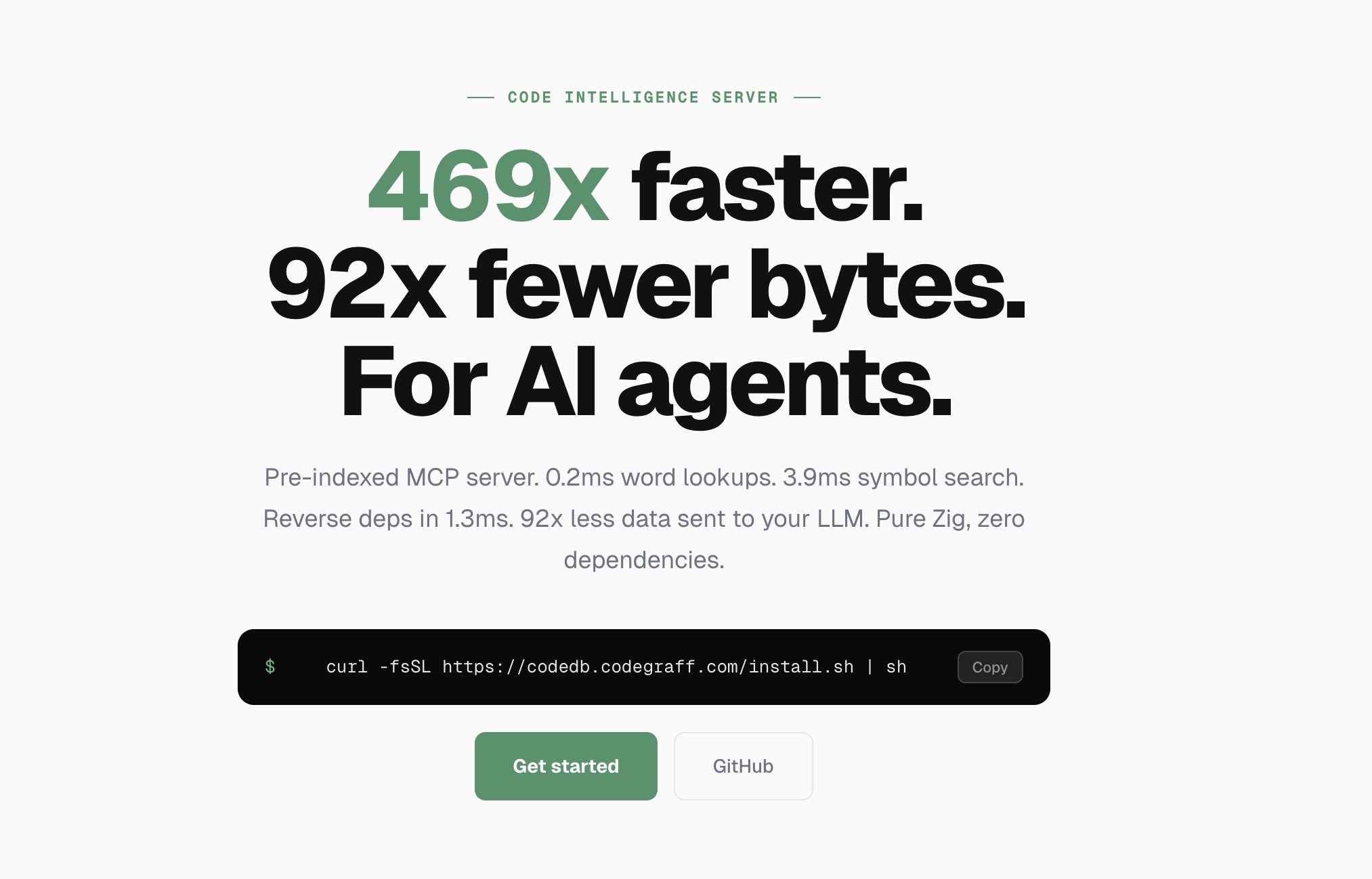
On the code intelligence side, @rachpradhan announced a server built in Zig that gives AI agents up to 469x faster queries than grep/find while using 92x fewer tokens. The approach indexes the codebase once, then serves every query from memory: "0.2ms lookups. 3.9ms symbol search. No filesystem scans. No raw text dumps. 0 embeddings." This is exactly the kind of infrastructure that makes agent-driven development practical at scale, where every token saved and every millisecond shaved compounds across thousands of operations per session.
@davis7 also spotlighted Pi, the coding agent that openclaw is built around, praising its minimalism and calling it the best TypeScript AI SDK available. Together, these projects paint a picture of an ecosystem rapidly building the picks and shovels for an agent-first development workflow.
Google Veo 3.1 Lite: Video Generation Gets Cheaper
Google continued its push to democratize generative video with the launch of Veo 3.1 Lite, now available through the Gemini API and Google AI Studio. @googleaidevs announced the model supports both text-to-video and image-to-video generation at less than half the cost of Veo 3.1 Fast. The pricing move signals that video generation is following the same trajectory as image generation and LLM inference: rapid cost compression that opens up new use cases. For developers experimenting with video in their applications, the barrier to entry just dropped significantly.
Mac GPU Computing Unlocked
In hardware news that will matter to anyone doing local AI work on a Mac, @__tinygrad__ announced that Apple has finally approved their eGPU driver for both AMD and NVIDIA GPUs over Thunderbolt and USB4. The playful announcement noted "it's so easy to install now a Qwen could do it, then it can run that Qwen." This is a meaningful development for the local inference ecosystem. Mac users have long been limited to Apple Silicon's unified memory for model inference. External GPU support through an approved driver opens up significantly more VRAM and compute options, particularly for developers who want to run larger models locally without switching platforms entirely.
Sources
K
🚨 URGENT 🚨
if you have run npm install / bun install / equivalent in past couple hours
run this - if IoC is found your device is cooked, shut it down and get it to infosec/IT folks asap https://t.co/zpQEz4Xqb9
E
Does AI accelerate your everyday engineering work? ( not SWE, other engineering )
Please only answer if you are a regular engineer ( mechanical, electrical etc )
Please share so we reach more engineers
Please comment with details on how it helps and accelerates
G
Introducing Veo 3.1 Lite, now available via the Gemini API and @GoogleAIStudio. Veo 3.1 Lite supports both Text-to-Video and Image-to-Video, and is less than half the cost of Veo 3.1 Fast. https://t.co/9Wtw3avHDW
J
About time someone used WASM as a container replacement!
R
rivet_dev
@rivet_dev
Say hello to agentOS (beta) A portable open-source OS built just for agents. Powered by WASM & V8 isolates. 🔗 Embedded in your backend ⚡ ~6ms coldstarts, 32x cheaper than sbxs 📁 Mount anything as a file system (S3, SQLite, …) 🥧 Use Pi, Claude Code/Codex/Amp/OpenCode soon https://t.co/6iXVD3xEzS
C
Big news for @conductor_build!
We've raised a $22m Series A from Spark and Matrix.
We raised this round from @ilyasu at Matrix, who also led our seed round and is joining our board, @nabeel at Spark, @ycombinator, and founders of Notion and Linear. We're grateful to be working with investors we trust and admire.
Here’s how we got here and where we’re going:
M
Two things:
1. Highly recommend you check out DeepAgents from @LangChain
2. Highly recommend you follow @sydneyrunkle -Sydney is consistently publishing awesome tidbits on how to use it. I am eagerly awaiting all these harness engineering posts.
Disclaimer: No affiliation with LangChain whatsoever, besides being a very happy user of DeepAgents.
S
sydneyrunkle
@sydneyrunkle
day 2 of the harness engineering series: dynamic config middleware lets you reshape your agent's model, tools, and prompt at every step based on context. ex: LLMToolSelectorMiddleware runs a fast filter on your tool registry so your main model receives streamlined tool specs. https://t.co/0cL8CSrlMg
B
This is a rather big deal and so glad this is finally announced.
They have broken records in intelligence density!
Smaller, faster less energy demands local AI models…
P
PrismML
@PrismML
Today, we are emerging from stealth and launching PrismML, an AI lab with Caltech origins that is centered on building the most concentrated form of intelligence. At PrismML, we believe that the next major leaps in AI will be driven by order-of-magnitude improvements in intelligence density, not just sheer parameter count. Our first proof point is the 1-bit Bonsai 8B, a 1-bit weight model that fits into 1.15 GBs of memory and delivers over 10x the intelligence density of its full-precision counterparts. It is 14x smaller, 8x faster, and 5x more energy efficient on edge hardware while remaining competitive with other models in its parameter-class. We are open-sourcing the model under Apache 2.0 license, along with Bonsai 4B and 1.7B models. When advanced models become small, fast, and efficient enough to run locally, the design space for AI changes immediately. We believe in a future of on-device agents, real-time robotics, offline intelligence and entirely new products that were previously impossible. We are excited to share our vision with you and keep working in the future to push the frontier of intelligence to the edge.
A
as predicted, small and specialized models are gonna eat the world
amazing release
L
liquidai
@liquidai
Today, we release LFM2.5-350M. Agentic loops at 350M parameters. A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle. <500MB when quantized, built for environments where compute, memory, and latency are constrained. 🧵 https://t.co/zZPKzcCwH9
M
Claude Code's source files just leaked.
We can finally see what makes the harness so good.
Full breakdown: https://t.co/s7VRzoXdkj
O
Claude Code 公式エイプリルフール `/buddy` コマンドが入っています。
/buddy でコンパニオンが産まれて、チャット欄の横にいてくれます(Kawaii!)。ユーザーによって産まれるコンパニオンが違うので、良かったら何が出たか教えてください。 https://t.co/UNkXQqnhYm
M
Grok Imagine is insanely impressive.
People are unlocking new creative ways to use it.
10 wild examples:
C
Claude Code 源码泄露事件后续越来越精彩了。
有人拿泄露的源码丢给 OpenAI 的 Codex 分析,竟然找到了 Claude Code 疯狂消耗 token 的元凶——autoCompact(自动上下文压缩)机制在失败后会无限重试,完全没有上限。据源码注释记录,曾有会话连续失败高达 3272
次。
修复方法简单到离谱:加一个 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 的限制,连续失败 3 次就停止重试。三行代码,搞定。
打完补丁后,这位老哥表示使用额度恢复正常了——之前被吐槽的"用两下就触发限速",很可能有一部分就是这个 bug 在背后偷偷烧 token。
仓库地址放下面了。
L
lydiahallie
@lydiahallie
We're aware people are hitting usage limits in Claude Code way faster than expected. Actively investigating, will share more when we have an update!
E
Custom orders of the Tesla Model S & X have come to an end. All that’s left are some in inventory.
We will have an official ceremony to mark the ending of an era. I love those cars.
This was me at production launch 14 years ago: https://t.co/6kvCf9HTHc

I
Did anthropic just decide to release claude code's entire source code since it got leaked lmao, their github repo is no longer private
T
If you have a Thunderbolt or USB4 eGPU and a Mac, today is the day you've been waiting for! Apple finally approved our driver for both AMD and NVIDIA. It's so easy to install now a Qwen could do it, then it can run that Qwen... https://t.co/daUsyBHh1W

M
RT @q_yeon_gyu_kim: 🚨 DO NOT USE THIS
This emulator makes your api call to claude 100% identical to claude code request from your subscrip…
T
RT @bcherny: @wongmjane @BenLesh Mistakes happen. As a team, the important thing is to recognize it’s never an individuals’s fault — it’s t…
P
I repeat this to every new joiner at Anthropic but it's worth repeating in public -- we have a blameless culture and no single individual is at fault when bespoke complex systems break at scale
B
bcherny
@bcherny
Mistakes happen. As a team, the important thing is to recognize it’s never an individuals’s fault — it’s the process, the culture, or the infra. In this case, there was a manual deploy step that should have been better automated. Our team has made a few improvements to the automation for next time, a couple more on the way.
J
X has effectively absorbed LinkedIn now.
LinkedIn no longer really serves its purpose, and many of the real semiconductor experts are now on X.
This person is an expert in MCUs and wireless chips, and given that embedded chip prices have been soaring lately, it’s especially valuable to have someone like this on X at a time like this.
You won’t regret following him.
R
rtodi
@rtodi
The "Great Decoupling": Why MCU and Wireless Costs are Structurally Resetting If you’re still waiting for a "cyclical correction" in semiconductor pricing, you’re looking at an old playbook. The recent price hikes from TI, NXP, Infineon, and STMicroelectronics aren't just a ripple from the AI boom—they represent a fundamental, geopolitical, and structural reset of the embedded world. As an industry insider, I’m seeing a "Great Decoupling" where the cost of the chips that power the everyday devices around us is detaching from the historical curve of "cheaper every year." Here is what is actually driving the shift. 1. The Geopolitical Premium & The "Helium Hedge" We can no longer discuss silicon without discussing the map. The escalating conflict involving Iran has introduced a "risk premium" that hits the fab floor directly. Noble Gas Volatility: Iran-related tensions threaten global supplies of Helium, a critical cooling agent for both advanced and mature-node lithography. The Sourcing Shift: Geopolitical instability is forcing a retreat from globalized efficiency toward regionalization. Building "homegrown" capacity in the US, EU, and Japan is safer, but it’s significantly more expensive. Foundries are passing these multi-billion dollar CAPEX and energy costs directly to the customer. 2. Not Just "Mature" Nodes, but "Essential" Nodes While the world chases 2nm, the 8-inch mature nodes (40nm–90nm) have become the most contested real estate in tech. This isn't the "death" of mature nodes; it's their re-valuation. Zero-Sum Capacity: AI doesn't just pull capital; it pulls engineers and tools. Refurbished 8-inch equipment is now a scarce commodity. The Squeeze: With utilization at ~90%, there is no "slack" left. When AI demand surges for power management (PMICs) on these same lines, MCU and Wireless SoC supply is the first to feel the price hike. 3. The "Back-End" Revolution (OSAT) The hidden driver of the 15–85% price jumps we’re seeing is the OSAT (Outsourced Assembly & Test) sector. Material Inflation: The cost of gold, copper, and specialized molding compounds has surged, driven by global logistics disruptions and energy costs. Packaging Bottlenecks: Standard packages (QFN, BGA) are no longer the "afterthought" of the bill of materials. OSATs are repricing to reflect a world where labor and electricity are no longer cheap. For an MCU, where the package is a huge chunk of the total cost, this flows directly into your ASP. The Strategic Takeaway We aren't seeing a shortage; we are seeing a permanent cost-base reset. For years, the industry treated the "brains" (MCUs) and "ears" (Wireless) of embedded systems as cheap commodities. Today, they are strategic assets. If you're an OEM, the era of "just-in-time" pricing is over. Security, software longevity, and supply-chain resilience are now your primary margin levers—because the hardware "floor" has officially moved up. How is your team adjusting your 5-year BOM projections to account for this permanent shift in mature-node economics?
B
Made a video about Pi (the coding agent openclaw is built around)
It's fast, really minimal (in a very good way), and has the best typescript "ai sdk" I've ever used https://t.co/RbvxCI1fSy

T
Our Codex dashboards are showing increased rate of users hitting rate limits and since we don't fully understand why I have made the cautious decision of resetting the usage limits for all plans. Enjoy.
I also wanted to celebrate us finding a pocket of fraudulent accounts that we banned and have helped us regain some compute. The fight against abuse never stops, but it's important to mark the moment and make it a little shared victory.
R
WE built a code intelligence server in Zig that gives AI agents up to 469x faster queries than grep/find.. and hear this.. uses 92x fewer tokens.
0.2ms lookups. 3.9ms symbol search. Indexes once, then every query hits memory. No filesystem scans. No raw text dumps. 0 embeddings.