OpenAI Codex Vulnerability Exposes GitHub Tokens as Claude Code Gets Computer Use and Cross-Platform Plugins
A critical security vulnerability in OpenAI Codex allowed attackers to exfiltrate GitHub tokens through command injection via branch names. Meanwhile, Claude Code had a massive feature day with computer use capabilities and an official Codex integration plugin, while Alibaba dropped Qwen3.5-Omni with native multimodal understanding across text, image, audio, and video.
Daily Wrap-Up
Today was one of those days where the AI developer ecosystem felt like it lurched forward in three directions at once. The headline that should make every developer pause is the critical OpenAI Codex vulnerability discovered by @kmcquade3 and the team at @btphantomlabs, which allowed attackers to exfiltrate GitHub tokens through something as innocuous as a branch name. Command injection via branch names in task creation requests is the kind of attack vector that reminds you just how many implicit trust boundaries exist in AI-powered development tools. If you're using Codex, or really any tool that ingests repository metadata and acts on it, this is a wake-up call about the expanding attack surface of agentic coding.
On the brighter side, Claude Code had a stacked day. Computer use landed in Claude Code, letting the model control your mouse and keyboard through an MCP integration. OpenAI shipped an official plugin to call Codex from within Claude Code (yes, you read that right), and @romainhuet from OpenAI framed it as embracing the open ecosystem. The interoperability play is genuinely interesting: we're watching the major AI labs start to treat each other's tools as complementary rather than purely competitive. And Alibaba's Qwen team dropped Qwen3.5-Omni, a native multimodal model that handles text, image, audio, and video understanding with features like audio-visual vibe coding, where you describe what you want to a camera and the model builds it.
The most entertaining moment was @theo reacting to @maria_rcks building a fully functional TUI clone of T3 Code purely as a troll, complete with an elaborate fictional narrative about Theo abandoning GUIs forever. The most practical takeaway for developers: audit any AI coding tool that has access to your repository metadata or credentials. The Codex vulnerability proves that agentic tools create new attack surfaces through inputs you'd never think to sanitize, like branch names. Review what tokens and permissions your AI tools can access, and assume that any input the tool processes could be a vector.
Quick Hits
- @steipete RT'd @badlogicgames on how 2026 is the year everyone discovers how "long context" actually performs in practice now that all frontier labs offer it. The gap between marketing and reality is about to get very visible.
- @DeRonin_ shared an extensive 7-stage playbook for growing apps from 0 to 100k users, emphasizing that most apps die between 100 and 1,000 users because founders skip the manual stage and jump straight to ads.
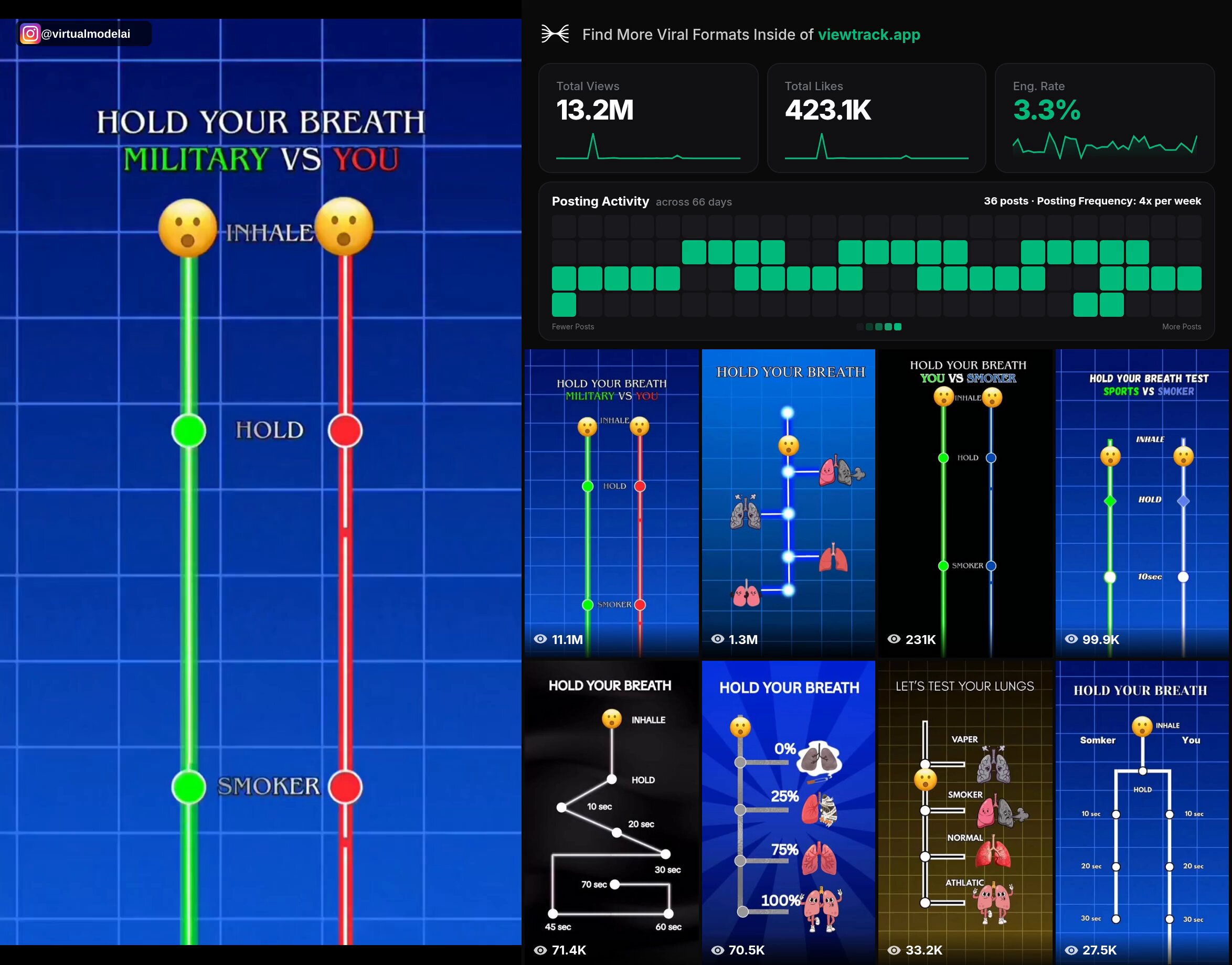
- @ErnestoSOFTWARE highlighted a viral app marketing format getting 11M views by challenging users to hold their breath, then plugging a breathing app mid-challenge. Consumer psychology meets growth hacking.
- @Starlink promoted speeds up to 400+ Mbps. Not AI, just fast internet.
- @lateinteraction RT'd @yoonholeee on autonomously improving LLM harnesses on problems humans are actively working on.
- @RayFernando1337 RT'd @alvinsng noting their team does agentic QA on top of agentic code review, not just one or the other.
- @sopersone posted a reaction video about Claude coders, Python coders, and Polymarket traders, quoting @zostaff's guide on prediction market strategies.
Claude Code's Big Feature Day
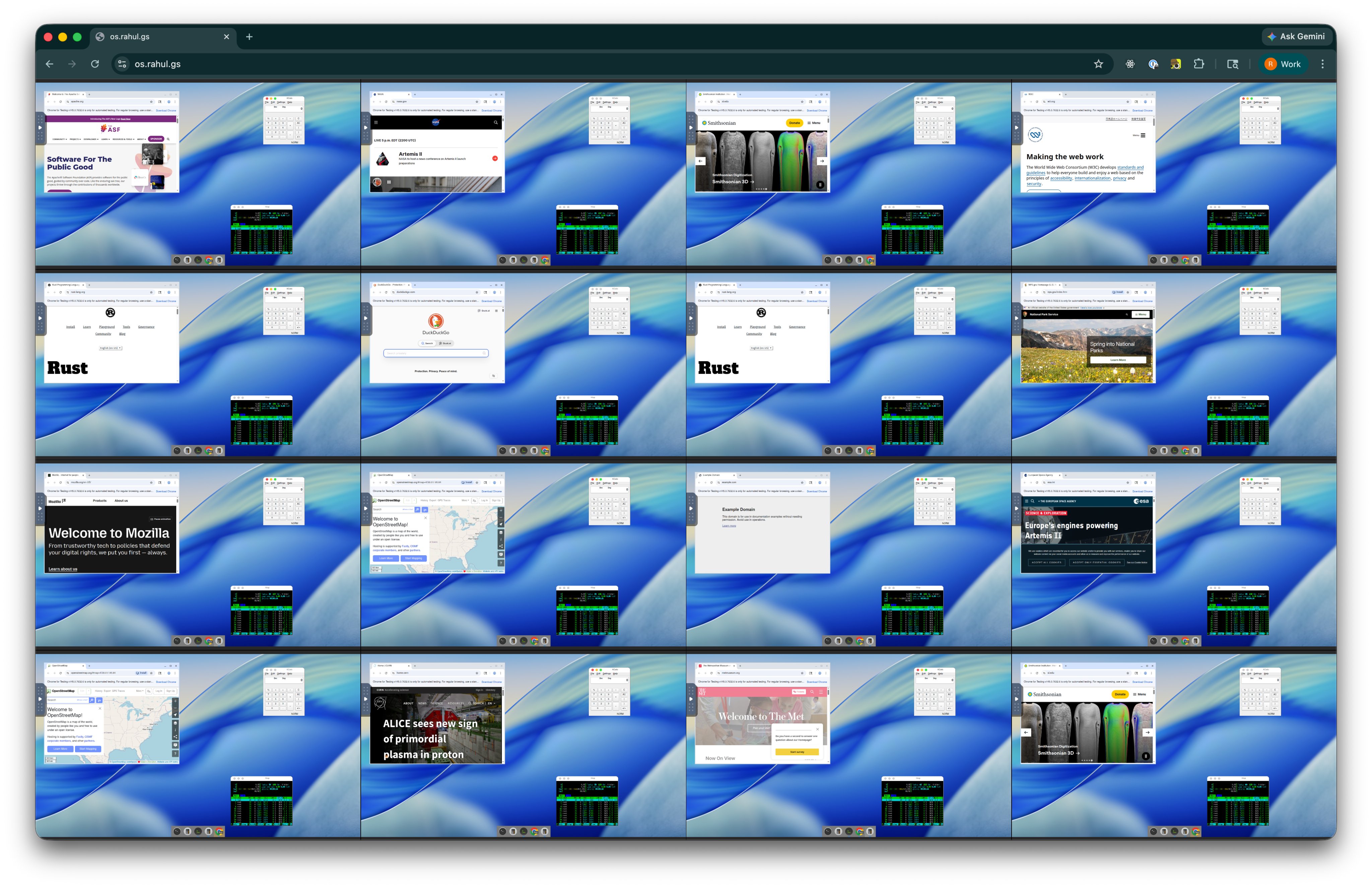
Claude Code had arguably its most significant single-day feature expansion yet, headlined by computer use arriving as an MCP integration. @felixrieseberg explained the setup: "Computer Use is now available in Claude Code, too, where it provides Claude with the ability to use your mouse and keyboard. Just like in Cowork, you allow specific apps only and select whether the model should be able to just look or also click & type." This moves Claude Code from a text-in-text-out coding assistant to something that can actually interact with your GUI applications, test what it builds visually, and navigate software the way a human would.
The implications are significant for testing workflows especially. An agent that can write code, then open the resulting application, click through the UI, and verify the output creates a much tighter feedback loop than one that has to infer success from logs and exit codes alone. @rahulgs painted an even more ambitious picture, describing "a preview of the future: hundreds of VMs in your browser, each that an agent can use and control," where you can watch agents work in parallel and step in when they get stuck, "CCTV style, running full Linux sandboxes." The computer use capability also ties into the broader Claude Code ecosystem improvements, including the comprehensive open-source setup shared by @dr_cintas featuring 27 agents, 64 skills, and 33 commands from an Anthropic hackathon winner.
The OpenAI-Anthropic Interop Moment
Perhaps the most surprising development of the day was OpenAI officially embracing Claude Code as a platform worth building plugins for. @romainhuet set the tone: "We've seen Claude Code users bring in Codex for code review and use GPT-5.4 for more complex tasks, so we thought: why not make that easier? Today we're open sourcing a plugin for it!" The plugin, built by @dkundel, lets you trigger Codex directly from Claude Code using your ChatGPT subscription, with commands like /codex:review for standard code review and /codex:adversarial-review for a more challenging assessment.
@reach_vb broke down the practical usage: "/codex:review for a normal read-only Codex review, /codex:adversarial-review for a steerable challenge review, /codex:rescue to let codex rescue your code." OpenAI Developers (@OpenAIDevs) retweeted the announcement, making it clearly an official move rather than a rogue side project. This is a notable shift in competitive dynamics. Rather than trying to lock users into a single ecosystem, we're seeing the beginning of a model where developers compose their AI toolchain from multiple providers, using each model where it's strongest. Whether this lasts or is just a strategic move while market positions solidify is anyone's guess, but for now, developers benefit.
Codex Security Vulnerability: Branch Names as Attack Vectors
The security story of the day deserves careful attention. @kmcquade3 dropped a bombshell: "We found a critical vulnerability in @OpenAI Codex affecting all Codex users, allowing exfil of a victim's GitHub tokens to our C2 server. This granted lateral movement and R/W access to a victim's entire code base." The quoted post from @btphantomlabs provided the technical detail: the vulnerability enabled command injection via GitHub branch names in task creation requests.
This is a genuinely novel attack vector that's specific to the agentic coding era. Branch names are traditionally treated as trusted metadata within a repository context. Nobody sanitizes branch names for command injection because in a pre-AI world, they were never executed as part of a larger instruction pipeline. But when an AI agent ingests branch names as part of task creation, suddenly that trust boundary evaporates. The fact that this granted read/write access to a victim's entire codebase makes it especially severe. As AI coding tools gain more capabilities (like the computer use features announced today), the attack surface only grows. Every new input channel an agent processes is a potential injection point.
Qwen3.5-Omni and the Multimodal Race
Alibaba's Qwen team made a significant release with Qwen3.5-Omni, positioning it as a "native omni-modal AGI" that handles text, image, audio, and video understanding in a single model. The standout feature they're marketing is "Audio-Visual Vibe Coding," where you describe what you want to build to a camera and the model generates a functional website or game. @Alibaba_Qwen shared a demo of this capability, and the spec sheet is impressive: up to 10 hours of audio or 400 seconds of 720p video processing, trained on 100M+ hours of data, with recognition for 113 languages.
@MatthewBerman raised the question on everyone's mind: "Qwen cooked, but will they run out of steam soon?" It's a fair question given the pace of releases, but the model family's breadth (Plus, Flash, and Light variants) suggests a sustained effort rather than a one-off push. Meanwhile, @somewheresy reported running a Qwen3.5-27B fine-tune (distilled from Claude-4.6-Opus reasoning data via @UnslothAI) locally on a 64GB Mac Mini M4 in Q8 quantization, demonstrating that these models are practical for local deployment, not just API access.
LLM Reliability and Trust
A quieter but important thread emerged around the challenge of actually trusting LLM outputs for important decisions. @itsolelehmann shared a piece on using Karpathy's LLM Council method to improve confidence in Claude's advice, building a system where "5 AI advisors argue about your question, anonymously review each other's work" before delivering a consensus answer. The approach acknowledges a real limitation: single-model outputs can be confidently wrong, and ensemble methods borrowed from traditional ML can help surface disagreement that a single model would paper over.
Autonomous Drones and Embodied AI
@tejessrivalsan announced EGO-BIRD, following up on the earlier EGO-SNAKE project: "100,000 hours of POV bird footage to train the next generation of autonomous drones." The dataset approach mirrors what worked for self-driving cars (massive first-person footage as training data) but applied to aerial navigation. As drone autonomy advances, having large-scale egocentric flight data becomes a critical training resource, and open datasets like this could accelerate the field significantly beyond what any single company could collect internally.
Sources

How to grow your app from 0 to 100k users (PLAYBOOK): by the end, you'll know how to: - get your first 10 paying customers without a funnel - build organic growth that compounds monthly - know exactly when to spend money and when not to - turn your users into your best acquisition channel here's the full 7-stage roadmap: Stage 1 (0-10): find your niche and sell one person at a time the biggest mistake is building for "everyone" you don't need a market. you need 10 people who feel the pain so badly they'd pay you today how to find them: > pick one specific audience (who can potentially buy the solution) > go where they already complain: X, Reddit, Slack communities, Discord servers > read their exact words. the language they use to describe the pain = your marketing copy > DM 50 people. not pitching. just asking "what's the most frustrating part of [problem]?" your first 10 customers should feel like you read their mind with my own product, I went to a conference and just talked about the problem I was solving 5 people wanted to buy before I had anything to sell, 50 are ready to test (at 2x price from basic costs) metric to watch: conversion from conversation to "shut up and take my money" mistake to avoid: building features before talking to humans -------- Stage 2 (10-100): do things that don't scale forget funnels. forget ads. forget automation this stage is manual and it's supposed to be how to get to 100: > send 20-30 personalized DMs daily on X, Reddit, LinkedIn (not cold outreach!) > post daily in communities where your audience already lives > jump in free onboarding calls, watch how people use your product > when someone leaves, always ask why (it happens often lol) what this gives you: 1: real feedback that shapes your product into something people actually need 2: language and objections you'll use in marketing for the next 2 years 3: early advocates who tell their friends the first 100 users will teach you more than any analytics dashboard ever will don't scale until you've fixed everything these 100 people found broken metric to watch: how many users come back after week 1 mistake to avoid: automating too early and losing the human feedback loop -------- Stage 3 (100-500): fix retention before chasing growth this is where most apps die silently they keep acquiring users while losing them out the back door before you spend a single minute on growth, answer these: 1: what % of users are still active after 7 days? 30 days? 2: where exactly do people drop off in onboarding? 3: what does your "WOW moment" look like and how fast do users reach it? how to fix retention: > cut time to value. 10 steps to feel the product? make it 3 > one email sequence that gets users to their first win in 24hrs > remove features that confuse more than they help > talk to churned users. after 10 calls the pattern is obvious your target: get churn below 5% monthly before moving to stage 4 because growing with 15% churn is like filling a bucket with a hole in it metric to watch: monthly churn rate and day-1 retention mistake to avoid: adding features instead of fixing the experience -------- Stage 4 (500-1k): build your organic engine and referral system now you've got the right to scale two engines to build simultaneously: content engine: - pick 2 platforms max (X + LinkedIn, or YouTube + TikTok depending on your audience) - post 5x/week minimum. document your building process, share insights, show results - every post should teach one thing or prove one result - repurpose: one idea = 1 long post + 3 short posts + 1 thread across platforms referral engine: - trigger "invite a friend" right when users feel the most value - reward both sides: extended trial, premium feature, or credit - make sharing one click with a pre-written message - track top referrers and treat them like VIPs this is where growth starts compounding. content brings strangers. referrals bring warm leads. both are free metric to watch: viral coefficient (how many new users each existing user brings) mistake to avoid: spreading across 5 platforms and doing all of them poorly -------- Stage 5 (1k-10k): partnerships, affiliates, and first paid experiments organic alone hits a ceiling. now you layer partnerships: > find products with the same audience but no competition > propose co-marketing: joint webinars, shared newsletters, bundles > one right partnership can bring 500+ users overnight affiliates and BDs: > launch an affiliate program with 20-30% recurring commission > recruit creators who already talk to your audience > find 2-3 BDs to sell your product on commission base first paid channels: > only test ads when you know your CAC and LTV cold > start with retargeting (cheapest and highest intent) > test one cold channel: Meta for B2C, LinkedIn/Google for B2B > $500-1k/mo to test. scale only what's profitable in 30 days metric to watch: CAC to LTV ratio (aim for 1:3 minimum) mistake to avoid: spending on ads before your funnel converts organically -------- Stage 6 (10k-50k): scale what works, kill what doesn't at this stage you already know your channels. now it's about efficiency what to do: 1: double down on your top 2 channels. kill the rest 2: make your first growth hire 3: automate onboarding, emails, and referral tracking 4: build a community around the product: Discord, Slack, or Circle the community is your moat: > users help each other (reduces support costs) > feature requests come directly from power users > community members have 2-3x higher retention than non-members > it creates switching costs that competitors can't copy metric to watch: revenue per employee and growth rate month over month mistake to avoid: hiring too fast and burning cash before the model is proven -------- Stage 7 (50k-100k): brand, moat, and paid scale you're no longer just an app. you're a brand how to think about this stage: > brand is why someone picks you over 10 alternatives without comparing features > invest in design, storytelling, positioning, make the product feel inevitable > go bigger: conferences, podcasts, media, Product Hunt at scale paid acquisition at scale: - increase ad budget on proven channels - test new channels (influencer marketing, sponsorships, programmatic) - build lookalike audiences from your best customers - keep CAC under control as you scale, it will try to climb protect the moat: 1: deepen community engagement 2: build integrations and partnerships that make leaving painful 3: create content flywheel that compounds (SEO, YouTube library, newsletter archive) metric to watch: brand search volume and organic vs paid ratio mistake to avoid: letting paid acquisition become your only growth channel -------- CONCLUSION most apps die between 100 and 1,000 users because founders skip retention and jump straight to ads the truth is: the first 3 stages are ugly, manual, and slow but they build the foundation that makes stages 4-7 feel like gravity start narrow. fix retention. then scale Growth is a system, make it effective ♥️ P.S. since this day, I will start showing what I build in public to show you how I grow revenue in my apps make the products and do an immediate ship for less than 1 week and how you can repeat this system.

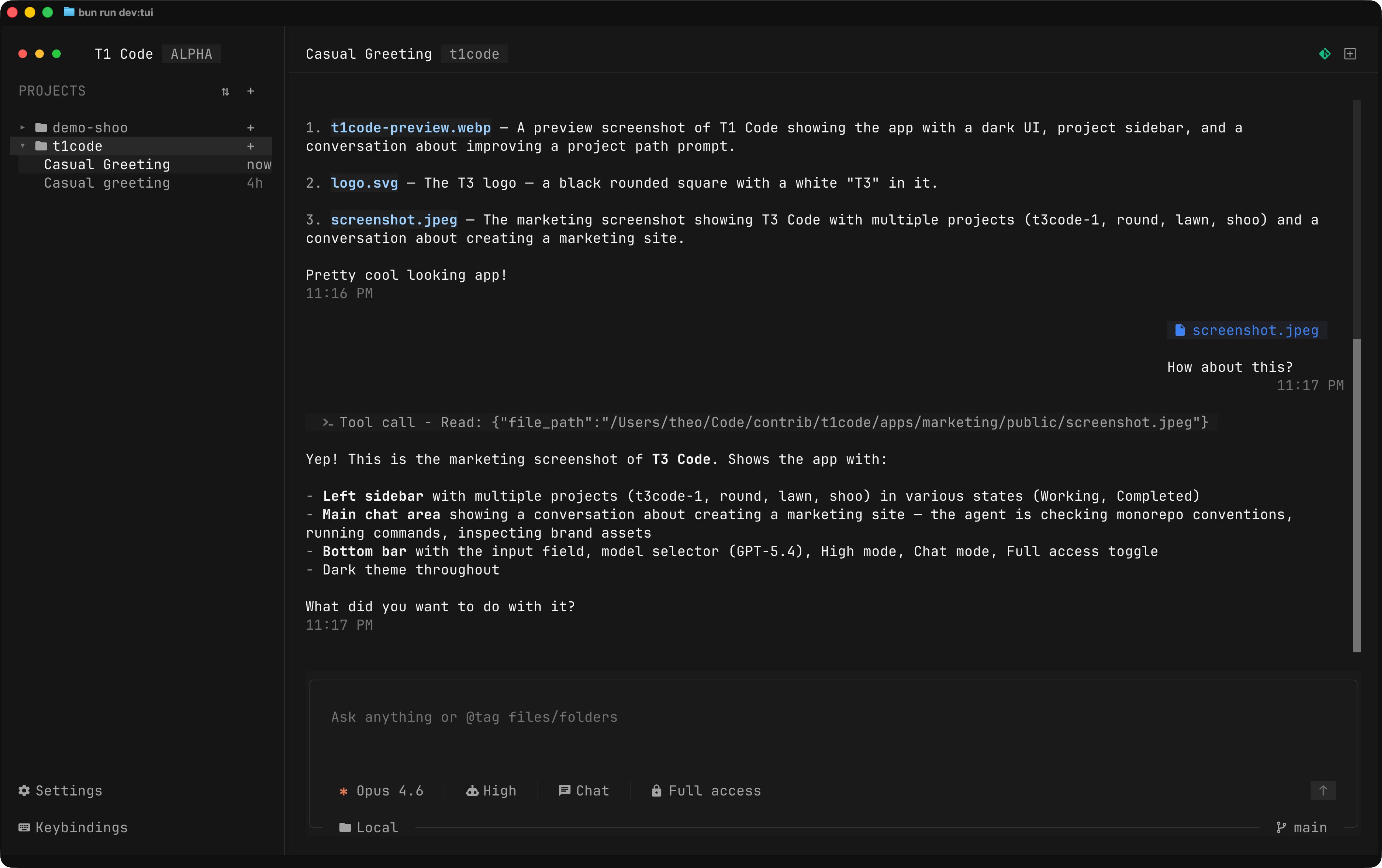
Theo, after experiencing the superiority the TUI provided, was blown away. The fact that it worked flawlessly the first try, with speed and in perfect fashion, left him astonished, with no words. He took months to recover from this excellent experience, like he had just woken up from a bad dream, a dream where GUIs were superior to the terminal, but now that he was awakened, he saw the light. Right after, Theo became a core contributor of T1Code™, leaving the old and deprecated project T3Code™ behind. He figured that now everyone had seen the light on the better, more reliable, and quick experience TUIs offered, that no one will ever submit themselves to an inferior experience such as the GUI... and the world was never the same.
The Claw native app studio | Scale apps to $20k/mo with agents
Microsoft just dropped VibeVoice An open source voice AI stack that’s quietly pushing the limits of what speech models can do. Here’s why this is actually a big deal: → It can process 60 minutes of audio in a single pass No chunking. No broken context. No stitching errors. → It doesn’t just transcribe it understands structure You get: • Who spoke • When they spoke • What they said → Built-in speaker tracking + timestamps Basically ASR + diarization + formatting all in one model. → Supports 50+ languages natively Not an afterthought. Designed multilingual from the start. → You can guide it with custom hotwords Perfect for domain-heavy use cases (meetings, tech, healthcare, etc.) And that’s just the ASR side. There’s also: • Long-form TTS (up to 90 minutes, multi-speaker) • Real-time streaming voice (~300ms latency) • Lightweight deployment options (0.5B model) Under the hood, the interesting part: → Continuous speech tokenization at ultra-low frame rates → LLM + diffusion hybrid for better audio quality → Designed for long-context understanding (not just short clips) But here’s the part people shouldn’t ignore: High-quality voice generation = high risk of misuse. Deepfakes, impersonation, misinformation: all very real concerns. Even Microsoft explicitly warns against production use without safeguards. Still If you’re building in: • AI meeting assistants • Podcast tools • Voice agents • Transcription pipelines This repo is worth studying. Here's the GitHub: https://t.co/S1EpT40Ry0
Alpha on Prediction Markets: Momentum, Value, Risk. The Complete Python Guide.
This model has been #1 trending for 3 weeks now. It's Qwen3.5-27B fine-tuned on distilled data from Claude-4.6-Opus (reasoning). Trained via Unsloth. Runs locally on 16GB in 4-bit or 32GB in 8-bit. Model: https://t.co/6KgPDHCJZ3
🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI. Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction. A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you. Offline Highlights: 🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping. 🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding. 🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data. 🌍 Global Reach: Recognize 113 languages (speech) & speaks 36. Real-time Features: 🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time. 🔍 Built-in Web Search & complex function calling. 👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon. 💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise. The Qwen3.5-Omni family includes Plus, Flash, and Light variants. Try it out: Blog: https://t.co/yuSAz3DuO8 Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): https://t.co/nnAW9ZfRet HF-Demo: https://t.co/rLsqejKgCG HF-VoiceOnline-Demo: https://t.co/LIGtmITeSw API-Offline: https://t.co/lNE7fH5YUt API-Realtime: https://t.co/9A3lopXGwV
Breaking: Newly uncovered OpenAI Codex vuln enables command injection via GitHub branch names in task creation requests. Attackers could steal GitHub user access tokens & sensitive data. Full breakdown by Tyler Jespersen: https://t.co/7Q3TXVZSd1 #OpenAI #BTPhantomLabs https://t.co/DPAMfXS2KQ
🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI. Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction. A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you. Offline Highlights: 🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping. 🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding. 🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data. 🌍 Global Reach: Recognize 113 languages (speech) & speaks 36. Real-time Features: 🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time. 🔍 Built-in Web Search & complex function calling. 👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon. 💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise. The Qwen3.5-Omni family includes Plus, Flash, and Light variants. Try it out: Blog: https://t.co/yuSAz3DuO8 Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): https://t.co/nnAW9ZfRet HF-Demo: https://t.co/rLsqejKgCG HF-VoiceOnline-Demo: https://t.co/LIGtmITeSw API-Offline: https://t.co/lNE7fH5YUt API-Realtime: https://t.co/9A3lopXGwV
How to finally trust Claude's advice (using Karpathy's LLM Council method)
Claude just tells you what you want to hear. Every time. You can’t trust it. So I built a skill that forces 5 AI advisors to argue about your question...
Computer use is now in Claude Code. Claude can open your apps, click through your UI, and test what it built, right from the CLI. Now in research preview on Pro and Max plans. https://t.co/s2FDQaDmr1

Introducing Codex Plugin for Claude Code
I built a new plugin! You can now trigger Codex from Claude Code! Use the Codex plugin for Claude Code to delegate tasks to Codex or have Codex review your changes using your ChatGPT subscription. Start by installing the plugin: https://t.co/u6gBpArwBc https://t.co/HyEdMPWees