Self-Evolving Agents Go Open Source as Video Generation Models Challenge Commercial APIs
Today's feed centers on the rapid maturation of open-source AI agents and video models, with a standout project called 724 Office demonstrating self-repairing, tool-creating agent architecture in just 8 files. The community is also deep in conversation about agent design patterns, from structured disagreement protocols to reinforcement learning optimization, while Claude Code updates and rate limit frustrations reveal the growing pains of AI-native development workflows.
Daily Wrap-Up
The throughline today is unmistakable: open-source AI is eating the lunch of commercial offerings at a pace that keeps surprising even the people building with it daily. Whether it's video generation models running locally that make you wonder why Sora existed, or a single developer shipping a self-evolving agent system from a Jetson Nano, the gap between "demo from a well-funded lab" and "thing you can run on your own hardware" is collapsing fast. The agent conversation has also matured noticeably. We're past the "look, my LLM can call a function" phase and into genuine architecture discussions about memory systems, decision graphs, structured disagreement, and reinforcement learning pipelines for agent optimization.
For developers, the signal is clear: agent engineering is becoming a real discipline with its own patterns and anti-patterns. The posts about BRAID decision frameworks, Microsoft's Agent Lightning for RL-based agent training, and Steve Ruiz's advice on "soldier-proofing" agent skills all point in the same direction. Building agents that work once in a demo is trivial. Building agents that work reliably across diverse inputs requires the same kind of engineering rigor we apply to distributed systems. The tooling to support that rigor is finally arriving.
The most entertaining moment was probably @doodlestein's exasperation at Claude Code rate limits kicking in with just 3-4 agents running simultaneously, which perfectly captures the irony of 2026: we've built tools so good that the infrastructure can't keep up with how people actually want to use them. The most practical takeaway for developers: if you're building agents, stop letting them figure out their own process. Define explicit decision graphs with verification steps, output contracts, and failure branches. The BRAID pattern and 724 Office architecture both demonstrate that agent reliability comes from structured workflows, not smarter prompts.
Quick Hits
- @0xblacklight RT'd a sharp observation from @dexhorthy: code review bots will always find problems if you ask them to look for problems. The real test is asking if the code is actually good. Framing matters enormously with LLM-based review tools.
- @minchoi reports that Seedance 2.0 video generation is producing "insane" results, adding to today's theme of generative video rapidly improving across multiple projects.
- @badlogicgames RT'd @tarunsachdeva offering collaboration on what appears to be a game development platform, though details were thin.
- @Prince_Canuma got a shoutout as the "prince of MLX," highlighting the continued momentum of Apple's ML framework for local inference.
- @RayFernando1337 RT'd the launch of "missions" from @luke_alvoeiro, a new product feature though the tweet lacked enough detail for deeper analysis.
- @ashebytes posted a thoughtful video essay on feminine and masculine energy in frontier tech, arguing the industry benefits from broader expressions of both.
- @elonmusk responded to a post about his management style by noting he's built two trillion-dollar companies simultaneously, which is either an inspiring data point or a conversation-ender depending on your perspective.
- @theallinpod shared Chamath's take that AI will destroy brand premiums, arguing abundance always wins. Tesla outselling BMW on price and performance was his case study.
- @Riyvir showed off a charming illuminated dragon demo built with Pretext, the pure-TypeScript text measurement library from @_chenglou that bypasses CSS and DOM reflow entirely. Desktop only for now.
Agents & Architecture (5 posts)
The agent conversation has graduated from "can it work?" to "how do we make it work reliably?" and today's feed is rich with concrete answers. The standout is 724 Office, a self-evolving agent that @aigleeson called "the most honest AI agent implementation I have ever seen." What makes it genuinely interesting isn't any single capability but the architectural coherence: a three-layer memory system (recent JSON, compressed facts at 0.92 cosine similarity, vector search via LanceDB), runtime tool creation, automatic self-repair via daily health checks, and cron-based task scheduling, all in 8 files with zero framework dependencies. As @aigleeson described it: "One create_tool command and the agent writes a new Python function, saves it to disk, and loads it into its own process without restarting. You need a capability it does not have and it builds it."
On the reliability side, @jumperz introduced BRAID (Bounded Reasoning for Autonomous Inference and Decisions) to his agent swarm and reported a fundamental shift in behavior. The core insight is separating agent workflows into three layers: a policy layer (rules it cannot break), a decision graph (the actual flow with branches for blocked/retry/escalate), and an output contract (what every response must contain). "Before this, my agents would handle the same task differently depending on the run, sometimes skip verification, and waste tokens just deciding how to approach it," he wrote. He even built a compiler that validates the decision graph before runtime, catching dead branches and unreachable nodes at compile time rather than in production.
@steveruizok offered a complementary technique: have your best model write an agent skill, then spawn a subagent to complete it, iterating until the subagent succeeds perfectly, then repeat the process with a smaller model. Meanwhile, @nyk_builderz argued that "agreement is a bug," advocating for forced structured disagreement across multiple agents before allowing consensus, specifically using 11 Claude Code agents in adversarial configuration. Microsoft's Agent Lightning, highlighted by @_avichawla, attacks the problem from yet another angle: an open-source framework that applies reinforcement learning to improve any agent built with LangChain, AutoGen, CrewAI, or plain Python. It captures prompts, tool calls, and rewards as structured events, then uses RL, prompt optimization, or fine-tuning to generate improved behavior without rewriting anything. Together these posts paint a picture of agent engineering rapidly developing its own set of design patterns, testing methodologies, and optimization pipelines.
Open Source Video Generation (2 posts)
The quality of open-source video generation models has crossed a threshold that's making people do double-takes. @RoyalCities captured the sentiment perfectly: "When did open source video models get this good? This is LTX 2.3... Still wild this runs locally. No wonder Sora got shut down." The fact that competitive video generation now runs on consumer hardware, without API calls or usage fees, represents a meaningful shift in who can create high-quality synthetic video.
Combined with @minchoi's excitement about Seedance 2.0 producing "insane" results, the video generation space is clearly in a rapid improvement cycle across multiple projects. The commercial implications are significant. When OpenAI shut down Sora, the conventional reading was strategic retreat. But the open-source alternatives suggest something more fundamental: video generation may be commoditizing faster than anyone expected, making it difficult to sustain a premium product in the space.
Claude Code: Updates and Growing Pains (3 posts)
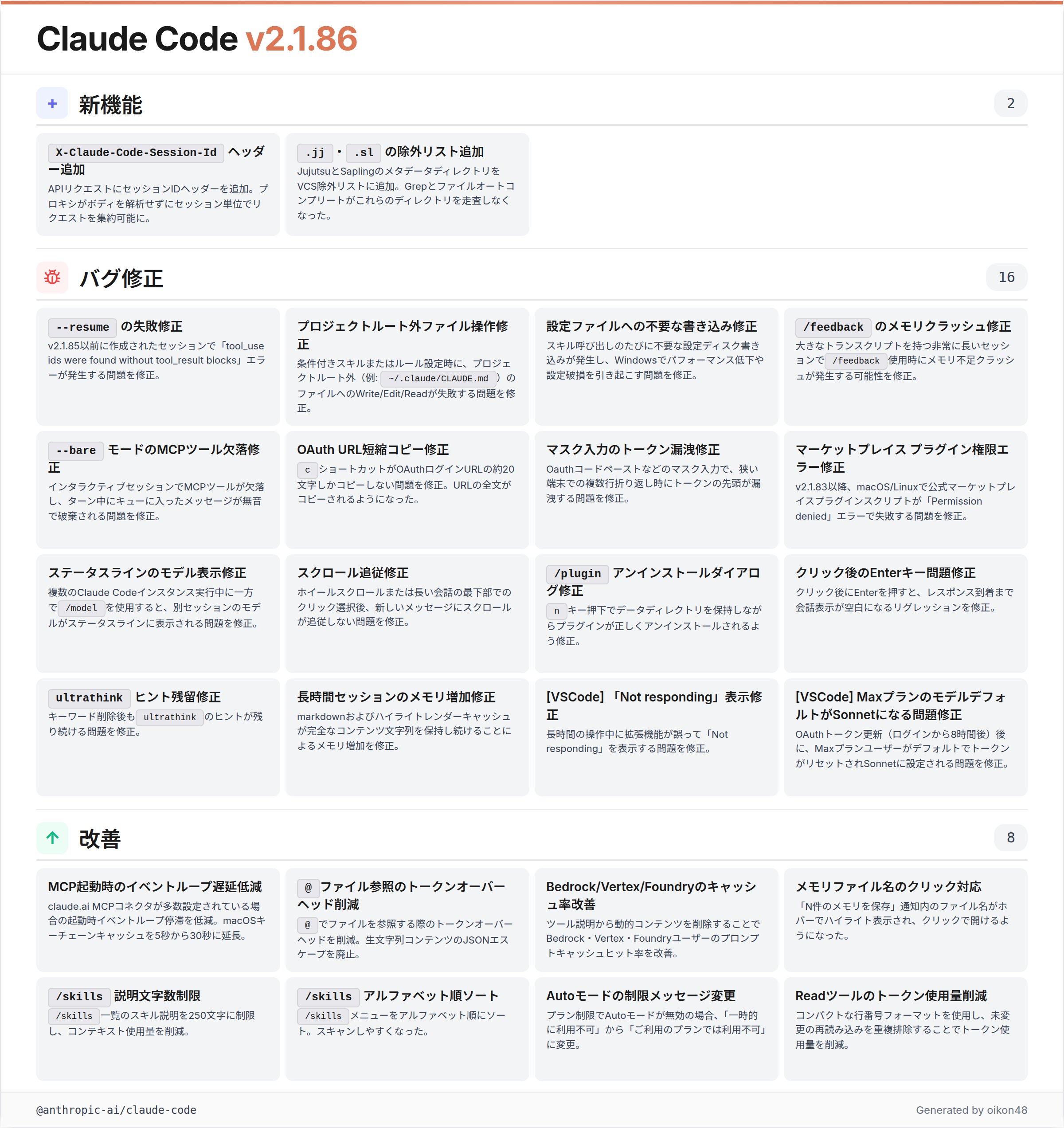
Claude Code continues to be a central part of the developer workflow conversation, but today's posts reveal both its momentum and its friction points. @oikon48 documented the Claude Code 2.1.86 release notes in detail, highlighting quality-of-life improvements: a new session ID header for proxy request aggregation, VCS directory exclusions for Jujutsu and Sapling, fixes for --bare mode dropping MCP tools, OAuth login URL copy bugs, and a more compact Read tool format that reduces token usage.
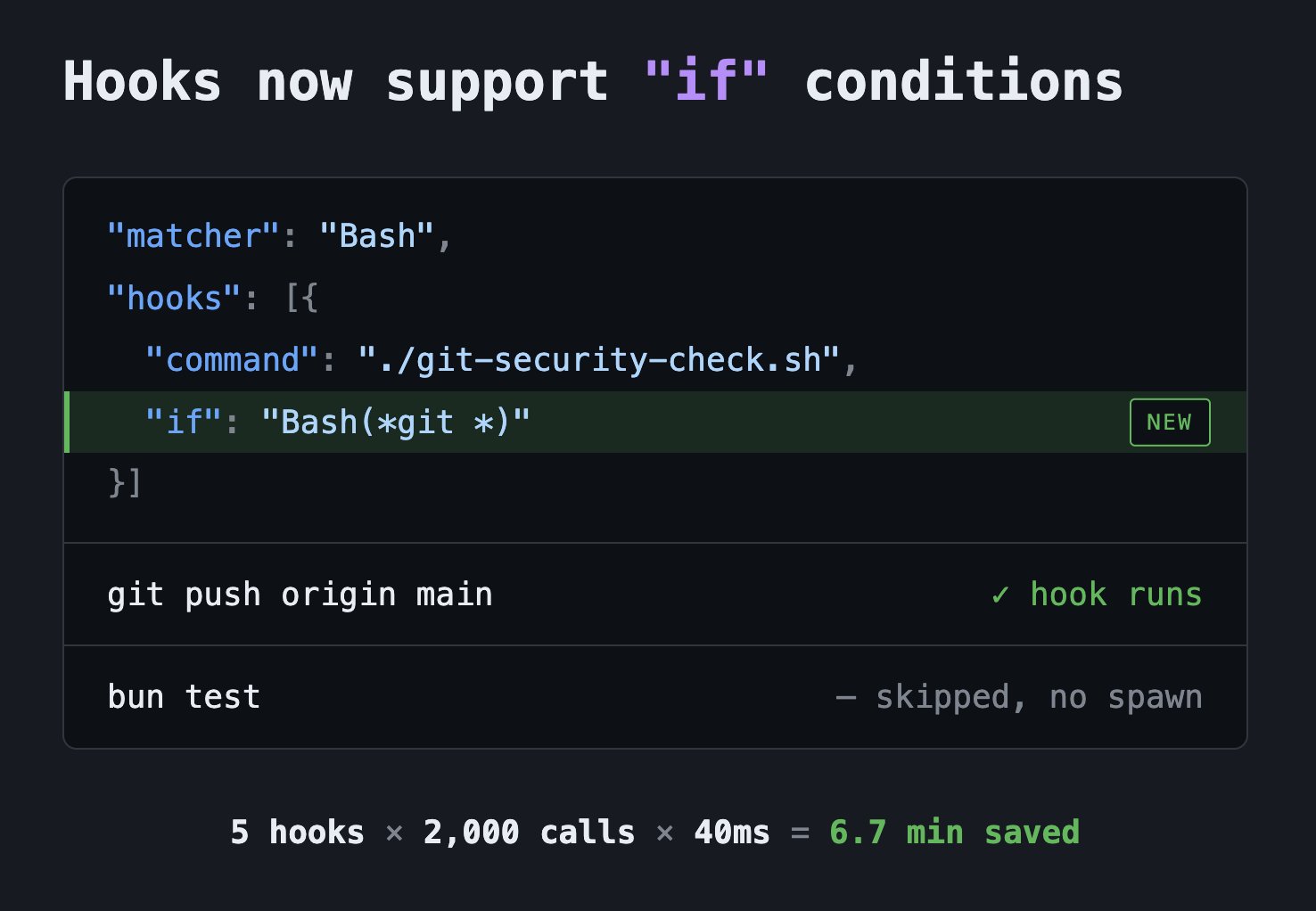
@jarredsumner (Bun creator) highlighted a specific improvement: Claude Code hooks now support "if" conditions that skip hooks when the command doesn't match. "This can save minutes in long sessions in repos that use hooks meant only for one command," he noted. These incremental improvements add up for power users running extended sessions.
But @doodlestein surfaced the tension that comes with success: "This recent introduction of ridiculously low rate limits has basically rendered Claude Code useless to me. It kicks in with like 3 or 4 agents going at once." This is the classic scaling challenge: build a tool so useful that your heaviest users hit infrastructure limits, then watch them threaten to leave. The rate limiting complaint is particularly pointed because Claude Code's agent-spawning architecture inherently multiplies API calls, meaning the tool's own design patterns push users toward the limits fastest.
Local AI & Hardware Tiers (1 post)
@0xSero is starting a weekly series mapping the best models to specific hardware tiers, and the first edition is a useful reference. At 8GB, you can run coding autocomplete models and basic tool-calling assistants. At 16GB, multimodal models become viable. At 24GB, you unlock Qwen's best offerings and strong agent-capable models. The framing is practical and hardware-first, which is exactly what developers need when deciding whether to invest in local inference versus cloud APIs.
This kind of community-maintained compatibility guide fills a real gap. Model cards tell you parameter counts and benchmark scores, but they rarely tell you whether the thing will actually run on your machine. As local inference becomes more viable for production use cases, expect these hardware-tier guides to become as essential as browser compatibility tables were for web developers.
Product Thinking & Strategy (1 post)
@thdxr offered a sharp filter for evaluating ideas: "When people pitch me concepts they're excited about they focus on how it works. But I want to understand how a user goes from not caring about it, to being interested, to understanding, to evangelizing." His claim that 9 out of 10 good ideas fail this test is a useful diagnostic for anyone building developer tools or AI products. Technical capability is necessary but insufficient. The adoption path, from indifference to evangelism, is where most projects actually die.
Historical LLMs (1 post)
@emollick shared a fascinating research project: an LLM trained entirely from scratch on over 28,000 Victorian-era British texts from 1837 to 1899, sourced from the British Library. As he noted, this is "quite different from an LLM roleplaying a Victorian." Training exclusively on period texts produces a model that reflects the actual linguistic patterns, knowledge boundaries, and worldview of the era rather than a modern model's pastiche of what it thinks Victorian English sounds like. It's a creative application of LLM training that opens interesting doors for historical research, education, and digital humanities.
Sources
R
Maybe I’ve been living under a rock, but when did open source video models get this good?
This is LTX 2.3…and yeah, it’s not hard to guess what it’s trained on.
Still wild this runs locally.
No wonder Sora got shut down. https://t.co/8oYtZsQ7Q1

A
on more feminine energy in frontier tech
why tech in 2026 benefits from more hyper feminine (and hyper masculine) expressions
I haven't seen a lot of conversations on this in a way that is divorced from dating/sexuality...
very curious what other folks think https://t.co/rgK7nvyDOP

J
Claude Code now supports `"if"` conditions in hooks, which skips the hook if the command doesn't match
This can save minutes in long sessions in repos that use hooks meant only for one command https://t.co/BSbTy5d7EF
O
Claude Code 2.1.86 (抜粋)
・プロキシがリクエストボディを解析せずに、セッション単位でリクエストを集約できるよう、API リクエストに `X-Claude-Code-Session-Id` ヘッダーを追加
・Grep とファイル自動補完が Jujutsu・Sapling のメタデータに入り込まないよう、VCS ディレクトリ除外リストに `.jj` と `.sl` を追加
・ `--bare` モードがインタラクティブセッションで MCP ツールを削除し、ターン途中にキューに入れられたメッセージを無音で破棄する問題を修正
・OAuth ログイン URL の `c` ショートカットが URL の最初の約 20 文字しかコピーしない問題を修正
・OAuth コード貼り付けなどのマスク入力で、狭いターミナルの複数行にまたがる際にトークンの先頭が漏洩する問題を修正
・ホイールスクロールまたは長い会話の末尾でのクリック選択後にスクロールが新しいメッセージに追従しない問題を修正
・「N 件のメモリを保存しました」通知内のメモリファイル名がホバー時にハイライトされ、クリックで開けるようになった
・コンテキスト使用量削減のため、`/skills` リストのスキル説明が 250 文字で切り捨てられるようになった
・スキャンしやすくするため、`/skills` メニューがアルファベット順にソートされるよう変更
・Auto モードがプランの制限により無効になっている場合、「unavailable for your plan」と表示されるようになった(従来は「temporarily unavailable」)
・[VSCode] OAuth トークンのリフレッシュ後(ログインから 8 時間後)に Max プランユーザーが Sonnet にデフォルト設定される問題を修正
・Read ツールがコンパクトな行番号形式を使用し、変更のない再読み込みを重複排除するようになり、トークン使用量を削減
https://t.co/mfNP3p4iOY
0
Best models to run on your hardware level
I'll be doing this every week, I hope you guys enjoy.
---- 8 GB ----
Autocomplete for coding (like Cursor Tab)
- https://t.co/Jyf766kmyd
- https://t.co/dK1CQwCGqD
Tool calling, assistant style
- https://t.co/Jf7RY3dZmZ
---- 16 Gb ----
Here things get better:
Multimodal
- https://t.co/WNwxTttMQC
- https://t.co/1U5HR9iWRX
- https://t.co/OiOkDoahZ8
---- 24 GB ----
- The best model you can get (thanks Qwen) https://t.co/fy8INjJP8N
- Great model (strong agents) https://t.co/CRpiKlSX5d
- Mine hehe https://t.co/YBeUveU0M6
I'm doing a weekly series
L
This literally feels like cheating.
A developer just open-sourced a self-evolving AI agent that runs 24/7, fixes itself when it breaks, and writes its own new tools at runtime in 8 files, 26 built-in tools, and zero framework dependencies.
It's called 724 Office and it is the most honest AI agent implementation I have ever seen.
Here is what makes it genuinely different from every other "agent" demo:
It has a three-layer memory system that actually works. The last 40 messages stay in JSON. When that overflows, the LLM compresses evicted messages into structured facts, deduplicates them at 0.92 cosine similarity, and stores them as vectors in LanceDB. When you send a new message, it runs a vector search and injects the most relevant memories directly into the system prompt before the model sees your input. It does not forget. Most agents do.
It can create its own tools at runtime. One create_tool command and the agent writes a new Python function, saves it to disk, and loads it into its own process without restarting. You need a capability it does not have and it builds it.
It self-repairs without you. Daily self-checks run automatically. Error log analysis. Session health diagnostics. If something fails, it notifies you. You do not monitor it. It monitors itself.
It schedules its own work. Cron jobs and one-shot tasks, persistent across restarts, timezone-aware. Set a recurring task once and it handles it forever.
It is multimodal out of the box images, video, voice, files, speech-to-text, vision via base64, video trimming, background music, and AI video generation all exposed as tools through ffmpeg.
It searches the web across Tavily, GitHub, and HuggingFace simultaneously with auto-routing to the right engine per query.
It runs multi-tenant via Docker one container per user, auto-provisioned, health-checked. Add a user and the infrastructure spins up automatically.
It runs on a Jetson Orin Nano with 8GB RAM. Edge-deployable. Under 2GB RAM budget. Offline-capable for everything except the LLM call itself.
One person. Three months. Production since day one.
100% Open Source. MIT License.

E
Given that I have built two companies in widely different fields to trillion dollar plus valuations simultaneously, I am might be getting a few things right once in a while
X
xDaily
@xDaily
INSIGHT: What working for Elon is actually like. https://t.co/S2I6jhPCkw
N
“Agreement is a bug” is the line.
Single-agent answers sound clean, but they hide perspective risk.
I now force structured disagreement before consensus.
Full system + protocol in my article + open source repo.
Bookmark this! https://t.co/C4bcrWwFX4

N
nyk_builderz
@nyk_builderz
Agreement is a bug. I forced 11 Claude Code agents to disagree.
M
RT @tarunsachdeva: @badlogicgames Hey Mario - we would love to play a role. This is exactly why we build https://t.co/8PI09QY2fV! It's open…
T
Chamath: AI Will Kill Brands, Only Abundance Wins
The brands that bring abundance will win big.
@chamath:
“ If I had to bet, I'm going to bet that brands go to zero.”
@Jason:
“Really?”
Chamath:
“When you can make things that are as good or better, and you can make them in a cheaper, faster, better way, people want that abundance more than they want an affiliation to a brand.
The perfect example is actually what Tesla did to BMW.
This is a fundamentally cheaper, faster, better product.
Yes, it's got a great brand, but nobody's going to pay a premium for these products.
The reason why Y has outsold everything else is because the Model Y is priced better and it's superior on every operational dimension of comparison.
Maybe the right word is abundance.
The brands that bring abundance, that bring more to the table than their competitors, and they're able to bring more at the same unit cost or less, capture share. That's probably true.”
J
so i added BRAID (bounded reasoning for autonomous inference and decisions) to my swarm lately and honestly it changed how they completely work..
BRAID essentially gives your agent a decision path rather than letting it figure out the process on its own.
you define the steps.. classify the task, pick the right branch, do the work, verify, report back.. and the agent follows that path every time.
before this:
my agents would handle the same task differently depending on the run.. sometimes skip verification, and waste tokens just deciding how to approach it
now they all follow the same structure and i can actually tell where and when things break.
i went further and separated each agent's workflow into 3 layers:
>policy layer: the rules it cannot break
so, never report done without verifying first, or always state tradeoffs with the result.
>decision graph: the actual flow
receive task, classify, execute, verify, report.. with branches for blocked, retry, escalate...
>output contract: what every response must contain
status, result, evidence, risk..so you dont random shaped answers.
then i built a compiler that validates the whole graph before the agent ever sees it, dead branches, missing steps, unreachable nodes, unlabeled decisions and its caught at compile time
if the workflow is broken it fails before the runtime, not during..
examples:
my coordinator follows: task clear? single or multi-agent? assign owner, monitor, blocked? unblock, verify, done..
my technical agent follows: classify request, collect evidence, design fix, apply, verify outcome, report with tradeoffs.
had to add this cause most agent problems are not intelligence problems, its a discipline problem and btw you can apply in any agent you want, no matter what.. their role is.
the goal of BRAID that it makes your agents consistent enough to actually be useful and not waste so many tokens doing the wrong stuff
if you want to try the core idea, paste this into any agent:
(prompt attached)
credits to @basjee01 for showing it to me, you can read more about it here..
https://t.co/S8B8brxeB9

D
when people pitch me concepts they're excited about they focus on how it works
but i want to understand how a user goes from not caring about it, to being interested, to understanding, to evangelizing
9/10 good ideas don't have an answer for this, which makes them bad ideas
P
RT @neural_avb: THIS is the most cracked dude on my timeline by the way 👇🏽
Sponsor his work, bookmark every release, prince of mlx is not…
J
This is crazy, this recent introduction of ridiculously low rate limits has basically rendered Claude Code useless to me. They really need to change this or I'm going to cancel all of my accounts soon. It kicks in with like 3 or 4 agents going at once. https://t.co/dADi41XfGK
M
Seedance 2.0 is getting ridiculous.
People are already making insane videos with it.
10 wild examples:
K
RT @dexhorthy: i say this about code review bots all the time. ask them to review for problems, it will find a bunch.
ask it if the code i…
P
MCPorter (MCP->CLI)🧳0.8.0 is out.
- stronger OAuth handling for servers
- valid JSON output on fallback paths
- better mcporter call behavior and error handling
- generated CLIs handle object-valued args better
- keep-alive/daemon reliability https://t.co/Nu9UOBxPam
E
Want to talk to the past?
Here is an LLM "trained entirely from scratch on a corpus of over 28,000 Victorian-era British texts published between 1837 and 1899, drawn from a dataset made available by the British Library."
Quite different from an LLM roleplaying a Victorian. https://t.co/5jl7SyJjAP

R
This little illuminated dragon is very happy about Pretext. He's too busy having fun to care about people's "hot takes" on how "it's not that special."
(This little dragon also only works on desktop right now but maybe I'll do mobile later)
https://t.co/k9FH6p1G0T https://t.co/wNhFk1ZBwM

_
_chenglou
@_chenglou
My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
R
RT @luke_alvoeiro: We recently launched missions. Here's a short demo of how to get started. Excited to see what you'll build! https://t.co…
A
Microsoft did it again!
Building with AI agents almost never works on the first try.
A dev has to spend days tweaking prompts, adding examples, hoping it gets better.
This is exactly what Microsoft's Agent Lightning solves.
It's an open-source framework that trains ANY AI agent with reinforcement learning. Works with LangChain, AutoGen, CrewAI, OpenAI SDK, or plain Python.
Here's how it works:
> Your agent runs normally with whatever framework you're using. Just add a lightweight agl.emit() helper or let the tracer auto-collect everything.
> Agent Lightning captures every prompt, tool call, and reward. Stores them as structured events.
> You pick an algorithm (RL, prompt optimization, fine-tuning). It reads the events, learns patterns, and generates improved prompts or policy weights.
> The Trainer pushes updates back to your agent. Your agent gets better without you rewriting anything.
In fact, you can also optimize individual agents in a multi-agent system.
I have shared the link to the GitHub repo in the replies!

S
Some of you aren't soldier-proofing your agent skills and it shows.
Ask your best model to: write the skill, spawn a subagent (same model) to complete the skill, and then iterate on the skill until the subagent can do the task perfectly.
Then repeat with a smaller model. https://t.co/EEgU6xf6yV