ARC-AGI 3 Stumps AI at Under 1% While Agent Infrastructure Race Heats Up
Today's feed centers on the growing ecosystem around AI agents, from integration platforms and communication protocols to the workflows developers are building around them. ARC-AGI 3 launched as a humbling new benchmark where AI scores below 1%, and the Claude Code ecosystem continues to expand with new hooks and memory features.
Daily Wrap-Up
The conversation today orbits a single gravitational center: agents are no longer a research curiosity, they're an infrastructure problem. Multiple teams launched platforms to connect, host, and orchestrate AI agents across real-world apps, while developers on the ground are figuring out the messy details of how these agents should communicate, remember context, and stay reliable over time. The sheer volume of agent-adjacent announcements suggests we've crossed from "will agents work?" to "how do we make agents manageable?" That's a meaningful shift.
Meanwhile, ARC-AGI 3 arrived as a cold splash of water for anyone getting too comfortable with benchmark progress. AI scoring under 1% while humans hit 100% is the kind of gap that should recalibrate expectations. It's a useful counterweight to the "AI writes all the code now" narrative that also dominated the feed, with multiple posts arguing that the best developers have become spec writers and eval designers rather than line-by-line coders. The truth, as usual, is messier. LLMs hallucinate constantly, as @mattpocockuk reminded everyone, and the developers who thrive will be the ones who build verification into their workflows rather than trusting outputs blindly.
The most entertaining moment was @raw_works discovering that git notes, a feature GitHub deliberately chose not to display, make for a perfect "underground information network" for coding agents. There's something delightfully subversive about using an invisible layer of a version control system as an agent communication channel. The most practical takeaway for developers: if you're building with AI agents, invest your time in evals and verification infrastructure rather than chasing the latest model release. The posts about eval-driven development and the ARC-AGI 3 results both point the same direction: the bottleneck isn't generation capability, it's knowing whether the output is correct.
Quick Hits
- @Supermicro promoted their NVIDIA-accelerated systems for AI workloads across data centers and edge computing. Standard infrastructure marketing, but it reflects how mainstream AI compute demand has become.
- @loganthorneloe RT'd @GergelyOrosz's warning to check GitHub privacy settings and disallow certain data sharing, especially for paying customers.
- @0xSero and @badlogicgames raised concerns about software engineers becoming dependent on a handful of well-funded corporations, calling for more open and decentralized infrastructure.
- @steveruizok RT'd @_chenglou on the future of front-end interfaces, teasing a deep dive into where UI development is heading.
- @andersonbcdefg shared a security tip for UV/PyPI users in light of recent package compromises, a timely reminder about supply chain security in Python.
- @Zai_org announced GLM-5.1 availability for all GLM Coding Plan users.
- @gdb described Codex use cases as "Skills, but for humans," a pithy framing of OpenAI's new use case gallery.
Agents & Orchestration
The agent infrastructure space is getting crowded fast, and today showed at least three distinct approaches to the same problem: how do you make AI agents actually useful in production? @katibmoe launched "One," pitching it as "the simplest way to connect and monitor AI agents to hundreds of apps," and backed the announcement by open-sourcing what they call the world's largest integration database: "47,000 agentic actions across 250+ apps." That's a bet that the integration layer, not the model layer, is where agent value gets unlocked.
@danshipper took a different angle with "Plus One," a hosted agent that lives in Slack and comes pre-loaded with tools and workflows. The pitch is revealing: "We have learned that the hard part of Claws is the infrastructure around them, the hosting, the integrations, the skills, and the ongoing care." This echoes what anyone who has tried to run persistent agents knows. The model is the easy part. Keeping an agent reliably connected to your email, calendar, and documents while maintaining context over days and weeks is where things fall apart.
Then there's @raw_works, who stumbled onto something genuinely novel by using git notes as an agent communication layer. "Git notes are ubiquitous (part of git) and 'invisible' (github chose not to display them). This presents a very interesting communication channel for agents, who can now include rich details and discussions about the code without cluttering up the 'visible' layer of the repo." It's a scrappy, zero-dependency approach that contrasts sharply with the platform plays, and it might be exactly what small teams need before committing to a full orchestration platform.
Claude Code Ecosystem
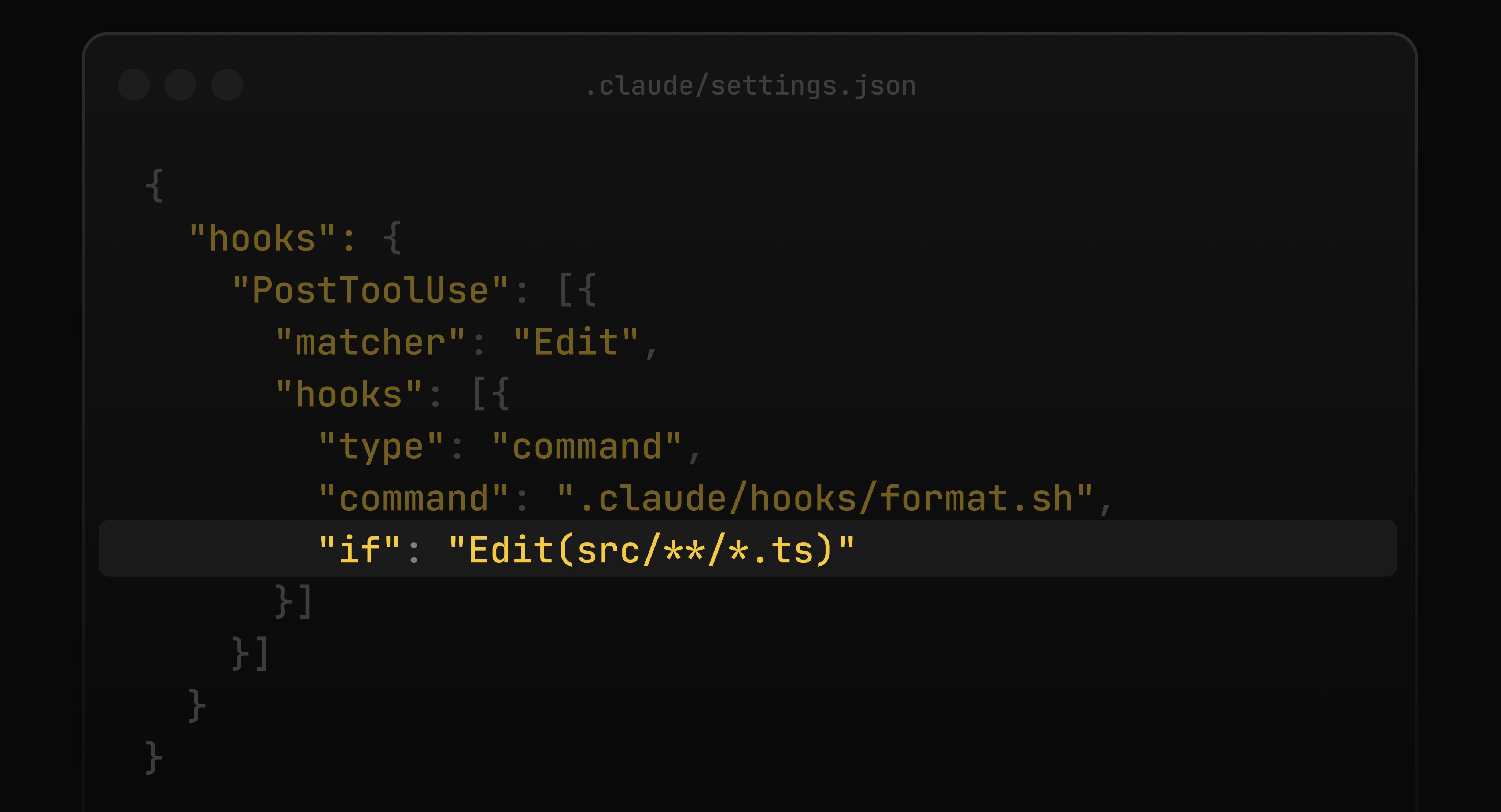
Claude Code is quietly becoming its own developer ecosystem, and today's posts highlighted two features that signal where it's heading. @lydiahallie flagged that Claude Code hooks now support an if field using permission rule syntax, letting developers filter when a hook fires rather than triggering on every bash command. It's a small but important refinement for anyone who's built hooks and found them too noisy.
More intriguing is what @minchoi spotted: "This quiet new Auto Dream feature coming to Claude Code looks like a big deal. It keeps memory clean so Claude doesn't get worse over time." Memory management is one of the hardest unsolved problems in long-running agent sessions. If Auto Dream works as described, it addresses the degradation that plagues agents after extended use, context windows fill with stale information and performance tanks. Both features suggest Anthropic is iterating fast on the operational details that separate a demo from a daily driver.
Benchmarks & AI Limitations
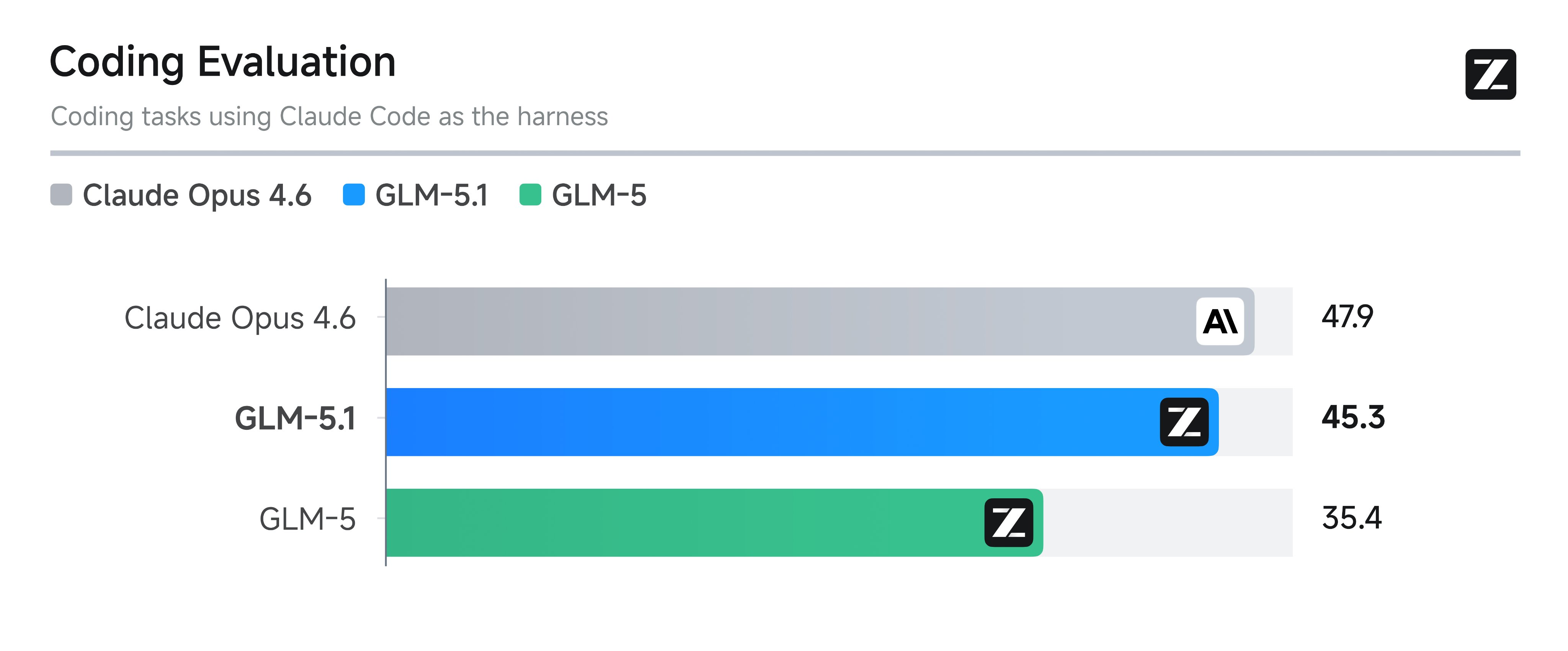
ARC-AGI 3 landed today and immediately became the most talked-about benchmark result in weeks. @MatthewBerman framed it sharply: "AI scores less than 1%, humans get 100%. Is this the ultimate benchmark?" The gap is striking because most recent benchmarks have shown AI closing in on human performance. ARC-AGI has consistently resisted this trend by testing novel reasoning rather than pattern matching against training data.
This pairs well with @mattpocockuk's viral post about hallucination: "Everyone who's worked with AI a lot agrees: LLM's hallucinate. A LOT. But to this day, I see friends and family trusting ChatGPT blindly." He created a shareable resource for the AI-credulous people in your life, which is both practical and a sign of how wide the gap has grown between power users who understand the limitations and casual users who treat these models as oracles. Together, these posts tell a consistent story: AI is getting more capable and more integrated into workflows, but the failure modes haven't gone away. They've just gotten harder to spot.
The Eval-Driven Developer
A recurring thread today was the argument that the developer's role is shifting from writing code to defining what correct code looks like. @rohit4verse put it bluntly: "The best programmers don't write code anymore. They write a spec. A test. An eval. Then they turn the AI on and walk away for hours." This connects to a quoted thread from @Vtrivedy10 on how teams building deep agents construct their evaluation frameworks.
@itsolelehmann pushed a similar idea from the prompt engineering side, describing a skill that "expands your prompt into a full spec, interviews you on the decisions it would otherwise guess at, builds from the complete brief." The underlying insight is the same: the more precisely you can describe what you want, the less time you spend correcting what you get. @TheNoahHein's article "What Comes After the Pull Request" rounds out this theme, noting that "engineers feel more productive than ever. Prototypes come together in hours. Pull requests stack up faster than anyone expected." The bottleneck is shifting from code production to code verification, and developers who build that muscle now will have a significant edge.
Hardware & Performance
On the hardware front, @TheAhmadOsman showcased a new Tenstorrent cluster packing 1TB of VRAM, 3TB DDR5 RAM, and 32TB SSD storage. Tenstorrent has been positioning itself as an alternative to NVIDIA for AI workloads, and specs like these target the growing demand for running large models on-premise.
At the other end of the spectrum, @RayFernando1337 RT'd results of running NVIDIA's Nemotron Cascade 2 30B model on a single RTX 3090 at 187 tokens per second using a 4-bit quantization. Meanwhile, @doodlestein launched a crowdsourcing effort for examples of "high-performance coding" that pushes modern hardware to its limits, noting that you can point Opus 4.6 at optimized codebases and have it extract optimization patterns for your own projects. The performance conversation is happening simultaneously at the cluster scale and the single-GPU scale, which reflects how diverse the deployment landscape has become.
AI Research
@neural_avb highlighted the Hyper-Agents paper, describing it as a "self-improving, source-code-changing, darwin-godel-machining, open-endly-evolving, recursive tree-splitting autoresearch variant." The breathless description aside, self-improving agent systems represent one of the more ambitious research directions in the field. These systems attempt to modify their own source code through evolutionary processes, which is fascinating from a research perspective even if production applications remain distant. It's worth watching as a signal of where autonomous research agents might head once the current generation of tool-using agents matures.
OpenAI's Codex Push
OpenAI made a coordinated push around Codex today, with @OpenAIDevs announcing a use case gallery with one-click starter prompts: "Explore practical workflows... start building iOS apps, analyzing datasets, or generating reports and slides." @gdb endorsed it with the quip that "Codex use cases are like Skills, but for humans," drawing a parallel to Claude Code's skill system. The gallery approach is smart because it solves the blank-page problem that stops many developers from experimenting with code generation tools. Whether Codex can compete with Claude Code's deeper IDE integration remains an open question, but lowering the barrier to first use is always a good move.
Sources



Hyperagents: a new way to auto-research
I stole Anthropic's internal cheat code for getting perfect Claude outputs on the first try
What Comes After the Pull Request
Every team using coding agents now runs into the same contradiction. Engineers feel more productive than ever. Prototypes come together in hours. Pull...


New Tenstorrent cluster hot from the kitchen > 1TB of VRAM > 3TB DDR5 RAM > 32TB SSD Storage New product, will share more later P.S. Can you find the cat in the picture? https://t.co/JFYT0tsWd2

How we build evals for Deep Agents

We just launched Codex use cases! It’s a gallery of practical examples across coding and non-coding tasks, with real ways to use Codex. One thing I really like: if you have the app, you can open the starter prompt for each use case directly in Codex! https://t.co/ZWa5X9VLSq