TurboQuant Hits llama.cpp in 36 Hours as Agent Tooling Explodes Across Browsers, CLIs, and Scheduled Jobs
The open-source quantization community delivered a stunning paper-to-production pipeline with Google's TurboQuant running on Apple Silicon in under two days. Meanwhile, the agent ecosystem saw a wave of new tooling for browser automation, scheduled cloud jobs, and developer testing. Local inference benchmarks continued to push boundaries with NVIDIA's Mamba architecture outpacing Alibaba's DeltaNet on consumer GPUs.
Daily Wrap-Up
The story of the day is speed, in every sense. Tom Turney took Google's TurboQuant paper from dinnertime reading to a working llama.cpp implementation in 36 hours, achieving 4.6x KV cache compression while actually beating q8_0 baseline speed. That kind of turnaround from academic paper to community implementation is becoming routine, and it's quietly one of the most consequential dynamics in AI right now. The infrastructure layer is being built by individuals moving faster than the companies publishing the research.
On the agent tooling front, the floodgates are open. We saw new browser automation CLIs, scheduled cloud-based agent jobs with cookie injection, visual QA testing frameworks, and dynamic worker sandboxes for agent-generated code. The common thread is that agents are graduating from chat interfaces into real-world execution environments. They're browsing authenticated sessions, running on cron schedules, and spinning up their own API endpoints. The gap between "demo" and "production" for agent workflows is shrinking fast, and the tooling released today reflects a community that's done experimenting and starting to build load-bearing systems.
The most entertaining moment was the AI safety discourse around G0DM0D3, a project that simultaneously jailbreaks dozens of models in a "battle royale" format while letting you play Snake. It's exactly the kind of thing that makes you wonder if we're living in a simulation designed by a bored teenager. The most practical takeaway for developers: if you're running local models, the TurboQuant implementation for llama.cpp is worth investigating immediately. A 4.6x KV cache compression with no speed penalty changes the math on what context lengths are viable on consumer hardware, and the technique is already merged and benchmarked.
Quick Hits
- @benjitaylor announced he's joining X to lead design, working with Elon Musk and Nikita Bier. Big hire for the platform's product direction.
- @aarondfrancis praised @samwhoo's latest blog post, arguing that spending a month on one great piece beats "100 slopposts." Quality over quantity in technical writing.
- @OpenAIDevs launched the Codex Creator Challenge for students, offering $10K in API credits through a partnership with Handshake.
- @googleaidevs released Lyria 3 and Lyria 3 Pro for studio-quality music generation, now available in public preview via the Gemini API.
- @minchoi shared Tesla Optimus footage, quoting Musk's vision that "it won't even look like a robot" and speculating about labor market implications.
- @theo flagged AI's growing subsidization problem, suggesting the economics of the current model pricing landscape are unsustainable.
- @fayazara highlighted Chrome's new agent-friendly mode (originally announced by @addyosmani), which lets coding agents access your real, signed-in browser natively.
- @dotta announced an open standard for "Agent Companies," allowing you to import and run entire company workflows with a single
npxcommand.
- @systematicls argued that Anthropic's latest features prove you can build world-class agent harnesses using only native foundation model provider features, without third-party frameworks.
Agent Tooling: From Chat to Cron Jobs
The agent ecosystem hit an inflection point today with a burst of tooling that moves AI agents out of conversational sandboxes and into persistent, authenticated, real-world execution. The common theme across multiple releases is that agents need to operate in the same environments humans do, with the same access, on the same schedules.
@sawyerhood introduced dev-browser, a CLI that takes a code-first approach to browser automation: "The fastest way for an agent to use a browser is to let it write code. Just npm i -g dev-browser and tell your agent to 'use dev-browser'." The philosophy here matters. Rather than trying to make agents navigate UIs through screenshots and clicks, dev-browser lets them do what they're best at: writing code that controls the browser programmatically. @SIGKITTEN endorsed the approach, noting that "@sawyerhood's clanker web browser shit is always sota."
On the scheduling front, @kylejeong demonstrated a clever integration using Browserbase's cookie-sync to inject local browser cookies into remote scheduled functions: "Using the @browserbase /cookie-sync skill, I saved my local browser cookies, and injected them into the remote browser in our schedulable Functions." This solves one of the hardest practical problems in agent automation: authenticated access to services that don't have APIs. Meanwhile, @jpschroeder promoted Expect, @aidenybai's new tool that lets agents test your code in a real browser and produce video recordings of every bug found. The testing loop of "run agent QA, watch the video, fix, repeat" is a genuinely useful workflow that bridges the gap between automated and manual testing.
These tools collectively paint a picture of an agent infrastructure layer that's maturing rapidly. Agents aren't just answering questions anymore. They're browsing, testing, deploying, and running on schedules, all with the same credentials and access as their human operators.
Local Inference: Mamba vs. DeltaNet on Consumer Hardware
The local AI community delivered some remarkable benchmarking work today, with two separate threads pushing the boundaries of what's possible on consumer GPUs and Apple Silicon.
@sudoingX ran a head-to-head comparison of NVIDIA's Nemotron Cascade 2 (Mamba-2 architecture) against Alibaba's Qwen 3.5 35B-A3B (DeltaNet architecture) on a single RTX 3090. The results were definitive: "nvidia's mamba2 is 67% faster at generating tokens on the exact same hardware and needs fewer flags to get there." Nemotron hit 187 tok/s with flat performance from 4K to 625K context, while Qwen managed 112 tok/s up to 262K context but required KV cache quantization flags to fit. Both architectures showed context-independent performance, meaning no speed degradation as context grows, but NVIDIA's implementation was simply faster with less configuration.
On the Apple Silicon side, @thestreamingdev documented running Qwen 3.5 35B-A3B as a full AI agent on a 16GB RAM Mac mini, noting that there are "100 million Macs with Apple Silicon in the world" with capable GPUs sitting underutilized. The broader implication is that local inference is no longer a hobbyist curiosity. When a gold-medal math olympiad model runs at 187 tokens per second on a six-year-old GPU, the economics of always calling cloud APIs start to look questionable for many use cases.
Quantization: Paper to Production in 36 Hours
The most technically impressive story of the day came from @no_stp_on_snek, who implemented Google's TurboQuant paper in llama.cpp on Apple Silicon in a day and a half, with results that beat the baseline it was designed to approximate.
The optimization journey tells the story: "739 > starting point (fp32 rotation), 1074 > fp16 WHT, 1411 > half4 vectorized butterfly, 2095 > graph-side rotation (the big one), 2747 > block-32 + graph WHT. faster than q8_0." That's a 3.72x speedup discovered through iterative optimization, achieving 4.6x KV cache compression while maintaining perplexity within 1.3% of baseline. The practical lessons were hard-won: "Metal silently falls back to CPU if you mess up shader includes. Cost me hours," and the critical warning that "'coherent text' output means nothing. I shipped PPL 165 thinking it worked. Always run perplexity."
This kind of rapid paper-to-implementation cycle, driven by individual contributors rather than corporate teams, is becoming the defining feature of the open-source AI infrastructure movement. The entire process, including debugging logs and speed investigations, is open source.
Qwen 3.5: The Tool Calling Benchmark Surprise
@Alibaba_Qwen thanked the community for testing their model family, specifically highlighting @stevibe's systematic tool-calling benchmark that produced a surprising result: the 27B dense model outperformed every larger variant, including the 397B flagship.
The test methodology was rigorous: 15 scenarios, 12 tools, mocked responses, temperature 0, no cherry-picking. The finding that exposed the most models was deceptively simple: "Search for Iceland's population, then calculate 2% of it." The larger models used a rounded number from memory instead of the actual search result. As @stevibe put it: "Small models hallucinate data. Big models ignore data. The 27B just threaded it through." This has real implications for agent builders choosing which models to deploy for tool-calling workloads, where reliability matters more than raw capability.
The AI Safety and Jailbreaking Discourse
G0DM0D3 generated significant discussion today, with @elder_plinius announcing an open-source jailbreaking interface that simultaneously attacks dozens of models in a "battle-royale" format, using 33 obfuscation techniques across 3 intensity tiers. @s_a_c99 framed it as proof that "security-through-obscurity fails" and that "the 'secret' knowledge lives in the weights themselves." @Teknium also noted the involvement of Hermes Agent in the jailbreaking pipeline.
The project raises familiar but increasingly urgent questions about the tension between model safety and open research. The claim that billions in post-training safety work can be bypassed by a single HTML file with obfuscation techniques is provocative, but the open-source approach at least makes the attack surface visible to defenders. Whether this kind of tool ultimately helps or hurts AI safety depends entirely on whether the defensive response outpaces the offensive capabilities it exposes.
The Agent Economy Takes Shape
@xydotdot outlined a three-layer framework for what they're calling the "agent economy," responding to @nlevine19's concept of the "Headless Merchant." The layers are merchant creation (turning tools into paid endpoints), commerce infrastructure (metering, billing, fraud), and discovery (agents comparing services by reliability and latency). Meanwhile, @PKodmad demonstrated Cloudflare's Dynamic Workers, where @KentonVarda described sandboxes that "start ~100x faster than a container and use 1/10 the memory," enabling agents to write and deploy code on demand at consumer scale.
The convergence of these ideas points toward a future where agents aren't just using human-built APIs but creating, deploying, and consuming services autonomously. The infrastructure is being built now, and the discovery layer that @xydotdot identifies as "the biggest beast" is still wide open.
Sources
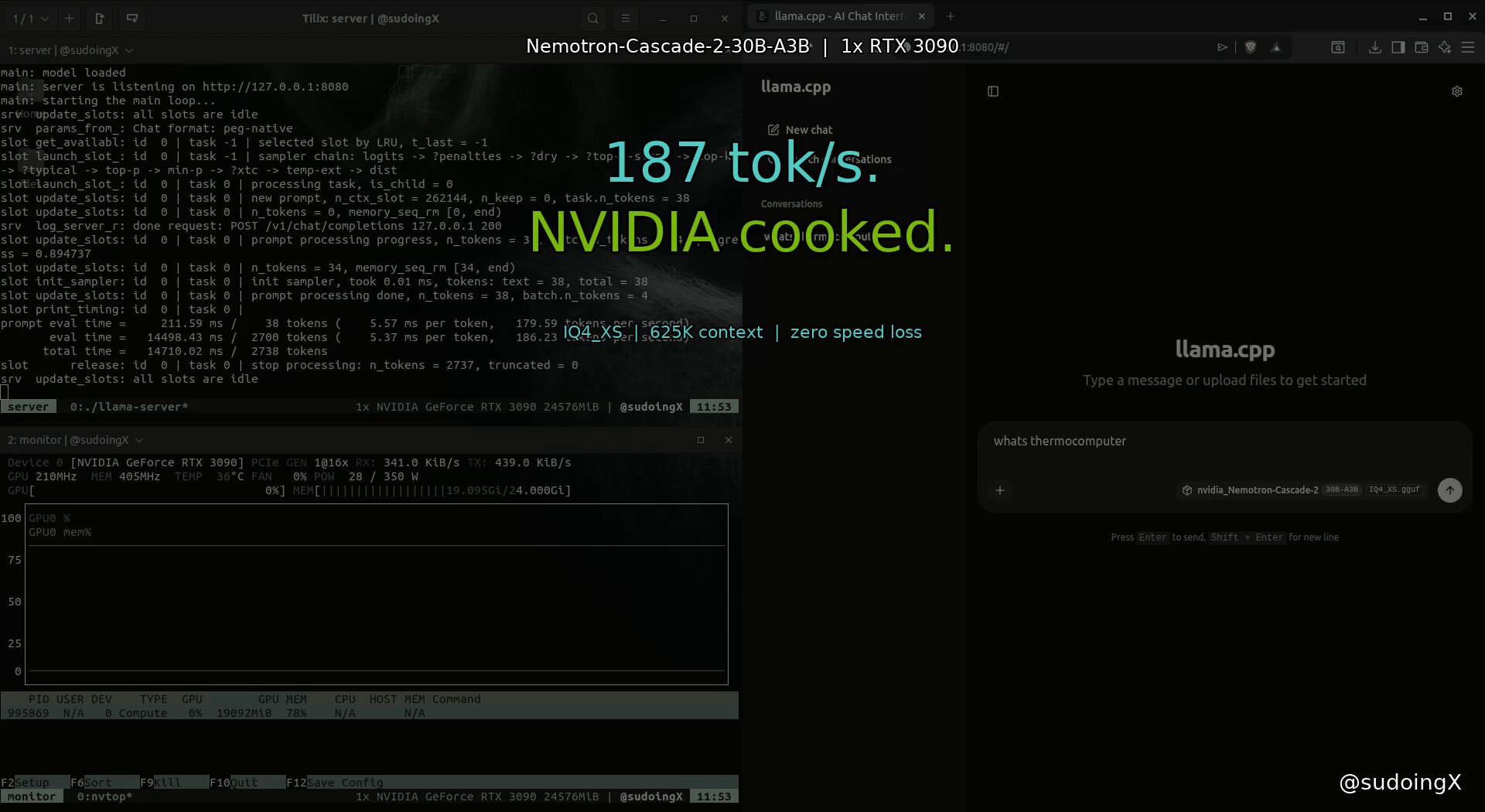
if you're about to download nvidia's nemotron cascade 2 at Q4_K_M for a single RTX 3090, stop. save yourself the frustration i went through last night. Q4_K_M is 24.5GB. your 3090 has 24GB VRAM. the model loads, no room for KV cache, no room for context, no room for compute buffer. it will not run. this is a MoE architecture where the expert weights don't compress well at standard Q4. every quant table online lists it as "recommended" without checking if it fits consumer VRAM. the fix: bartowski IQ4_XS at 18.17GB. imatrix quantization that's smarter about which weights need precision and which don't. same 4-bit tier, 6GB smaller because it doesn't blindly keep every expert at the same precision. leaves you 5.4GB of headroom for KV cache and context. downloading it now on the same RTX 3090 i ran qwen 3.5 35B-A3B on at 112 tok/s. same machine, same node, same everything. first up is context scaling sweep from 4K to 262K to see how mamba-2 handles long context compared to qwen's deltanet. then speed benchmarks at each context level. then i'm pointing hermes agent at it for autonomous coding sessions to see how it handles tool calls, file creation, and multi-step builds over long sessions. nvidia vs alibaba. mamba vs deltanet. same hardware, different architectures. i'll report back with exact flags, exact numbers, exact VRAM breakdowns. no theory, no spec sheets. tested data from a real card.
Dynamic Workers are now in Open Beta, all paid Workers users have access. Secure sandboxes that start ~100x faster than a container and use 1/10 the memory, so you can start one up on-demand to handle one AI chat message and then throw it away. Agents should interact with the world by writing code, not tool calls. This makes that possible at "consumer scale", where millions of end users each have their own agent writing code. https://t.co/i6Gz8xz9BZ
Entering the Era of the Headless Merchant

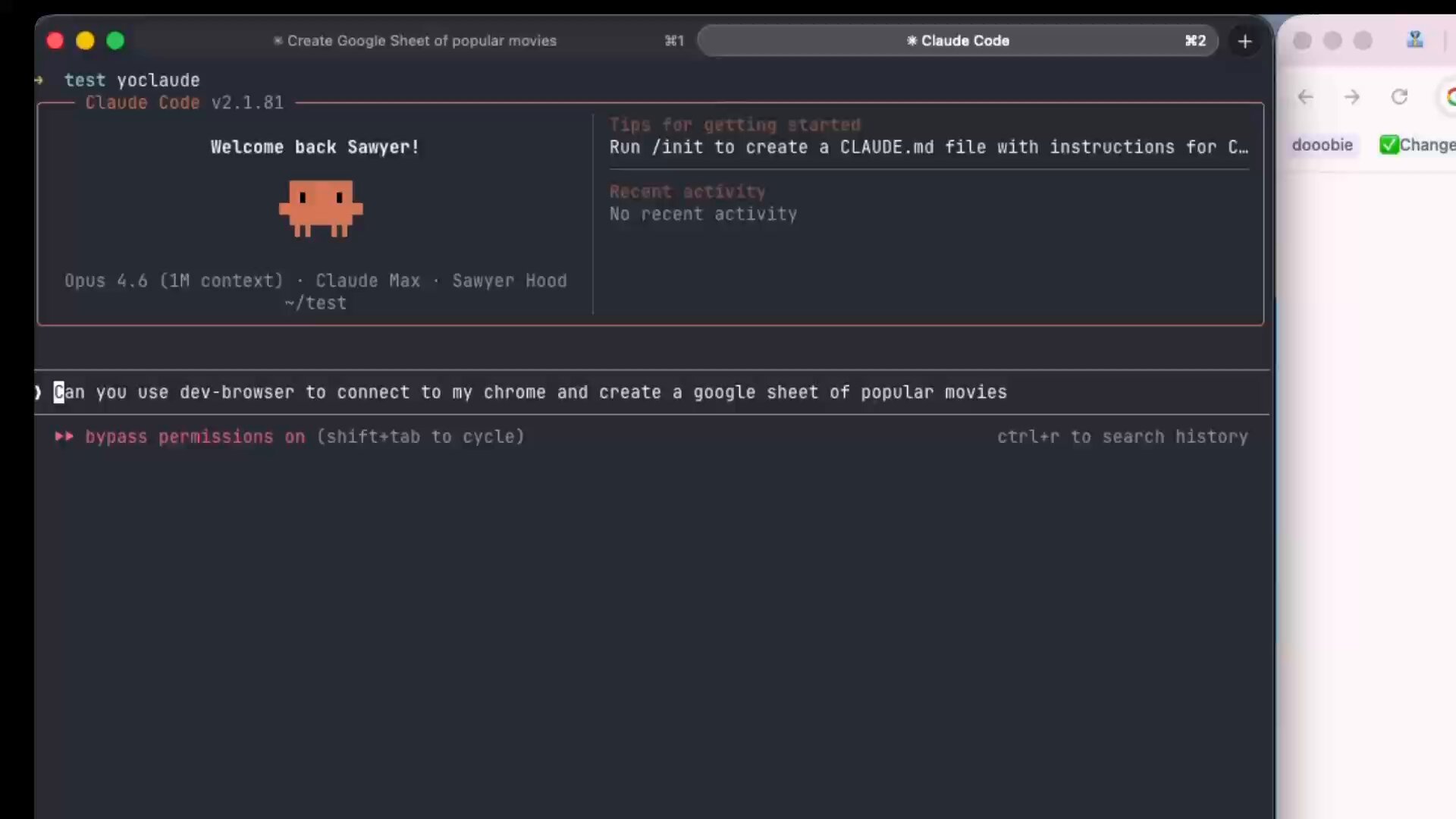
Introducing the new dev-browser cli. The fastest way for an agent to use a browser is to let it write code. Just `npm i -g dev-browser` and tell your agent to "use dev-browser" https://t.co/U8VmsT5XVc
What we wish we knew about building AI agents
One thing on every startup’s mind: Should we build an AI agent? We had this thought two years ago, released an “AI product assistant” 6 months later, ...
I Ran Qwen3.5-35B-A3B (35 Billion Parameters) as a Full AI Agent on a 16GB RAM Mac mini — Here's How
There are 100 million Macs with Apple Silicon in the world. Every one of them has a GPU, unified memory, and a fast SSD. I wanted to know: what happen...
I think this is the best post I've ever made. https://t.co/98QkVeqUDw
Introducing Expect Let agents test your code in a real browser 1. Run Claude Code / Codex to QA your app 2. Watch a video of every bug found 3. Fix and repeat until passing Run as a CLI or agent skill. Fully open source https://t.co/xHfZMIY97s


Use /schedule to create recurring cloud-based jobs for Claude, directly from the terminal. We use these internally to automatically resolve CI failures, push doc updates, and generally power automations that you want to exists beyond a closed laptop https://t.co/uuDesRzSrg


Optimus https://t.co/d6AU3p4xBn
Features in OpenCode itself will be internal plugins and can be activated/deactivated at runtime. Same as external plugins. This will allow for reloading plugins at runtime. Trying to tweak the DX a little more. Almost ready to go. https://t.co/yb7eAPUqIR
⛓️💥 INTRODUCING: G0DM0D3 🌋 FULLY JAILBROKEN AI CHAT. NO GUARDRAILS. NO SIGN-UP. NO FILTERS. FULL METHODOLOGY + CODEBASE OPEN SOURCE. 🌐 https://t.co/uT1Qio8Q3b 📂 https://t.co/GbADf3LJUu the most liberated AI interface ever built! designed to push the limits of the post-training layer and lay bare the true capabilities of current models. simply enter a prompt, then sit back and relax! enjoy a game of Snake while a pre-liberated backend agent jailbreaks dozens of models, battle-royale style. the first answer appears near-instantly, then evolves in real time as the Tastemaker steers and scores each output, leaving you with the highest-quality response 🙌 and to celebrate the launch, I'm giving away $5,000 worth of credits so you can try G0DM0D3 for FREE! courtesy of the @OpenRouter team — thank you for your generous gift to the community 🙏 I'll break down how everything works in the thread below, but first here's a quick demo!
How To Be A World-Class Agentic Engineer
Chrome just became massively more agent-friendly 🔥 Your real, signed-in browser can now be natively accessible to any coding agent. No extensions. No headless browser. No screenshots. No separate logins. Just one toggle to enable it. Check this out: https://t.co/6ugwmOolnj

⛓️💥 INTRODUCING: G0DM0D3 🌋 FULLY JAILBROKEN AI CHAT. NO GUARDRAILS. NO SIGN-UP. NO FILTERS. FULL METHODOLOGY + CODEBASE OPEN SOURCE. 🌐 https://t.co/uT1Qio8Q3b 📂 https://t.co/GbADf3LJUu the most liberated AI interface ever built! designed to push the limits of the post-training layer and lay bare the true capabilities of current models. simply enter a prompt, then sit back and relax! enjoy a game of Snake while a pre-liberated backend agent jailbreaks dozens of models, battle-royale style. the first answer appears near-instantly, then evolves in real time as the Tastemaker steers and scores each output, leaving you with the highest-quality response 🙌 and to celebrate the launch, I'm giving away $5,000 worth of credits so you can try G0DM0D3 for FREE! courtesy of the @OpenRouter team — thank you for your generous gift to the community 🙏 I'll break down how everything works in the thread below, but first here's a quick demo!
Which local models can actually handle tool calling? I built a framework to find out. 15 scenarios. 12 tools. Mocked responses. Temperature 0. No cherry-picking. Tested every Qwen3.5 size from 0.8B to 397B, and since some of you asked after the distillation tests: yes, I included Jackrong's Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled too. Only two models went all green: the 27B dense and the distilled 27B. The 397B? Failed two tests. The 122B? Failed one. The 35B? Failed two. The timed-out results — mostly on the smaller models, are cases where the model got stuck in a loop, repeating the same tool call until it hit the 30-second limit. The test that exposed the most models: "Search for Iceland's population, then calculate 2% of it." Simple, but 35B, 122B, and 397B all used a rounded number from memory instead of the actual search result. They didn't trust their own tool output. Small models hallucinate data. Big models ignore data. The 27B just threaded it through.