NVIDIA's Nemotron Cascade Takes on Qwen While Claude Code Ships /schedule for 24/7 Automation
The AI agent ecosystem is maturing fast, with new tools for game dev, coding workflows, and autonomous scheduling dominating the conversation. On the model front, NVIDIA's Nemotron Cascade and on-device Qwen optimizations signal a shift toward efficient inference, while the developer community debates best practices for agent-driven development.
Daily Wrap-Up
The big picture today is that AI agents are no longer a novelty but a workflow category with real tooling debates. Developers are arguing about memory management for multi-agent setups, whether agents should write TypeScript instead of making tool calls, and how to keep "vibe-coded" projects from turning into unmaintainable messes. The conversation has shifted from "can agents do X?" to "what's the right architecture for agents doing X at scale?" That's a meaningful inflection point.
On the model side, NVIDIA quietly dropped Nemotron Cascade, a 30B parameter model with only 3B active, using a hybrid Mamba MoE architecture that fits on a single RTX 3090. Meanwhile, @Alexintosh pushed Qwen 3.5 35B to 13.1 tokens per second on an iPhone 17 through a stack of optimization tricks. The race for efficient inference is heating up on both desktop GPUs and mobile devices, and the gap between cloud and local is narrowing faster than most people expected. Claude Code's new /schedule feature also deserves attention: the ability to set up recurring cloud-based jobs from your terminal turns an AI coding assistant into something closer to an autonomous DevOps teammate.
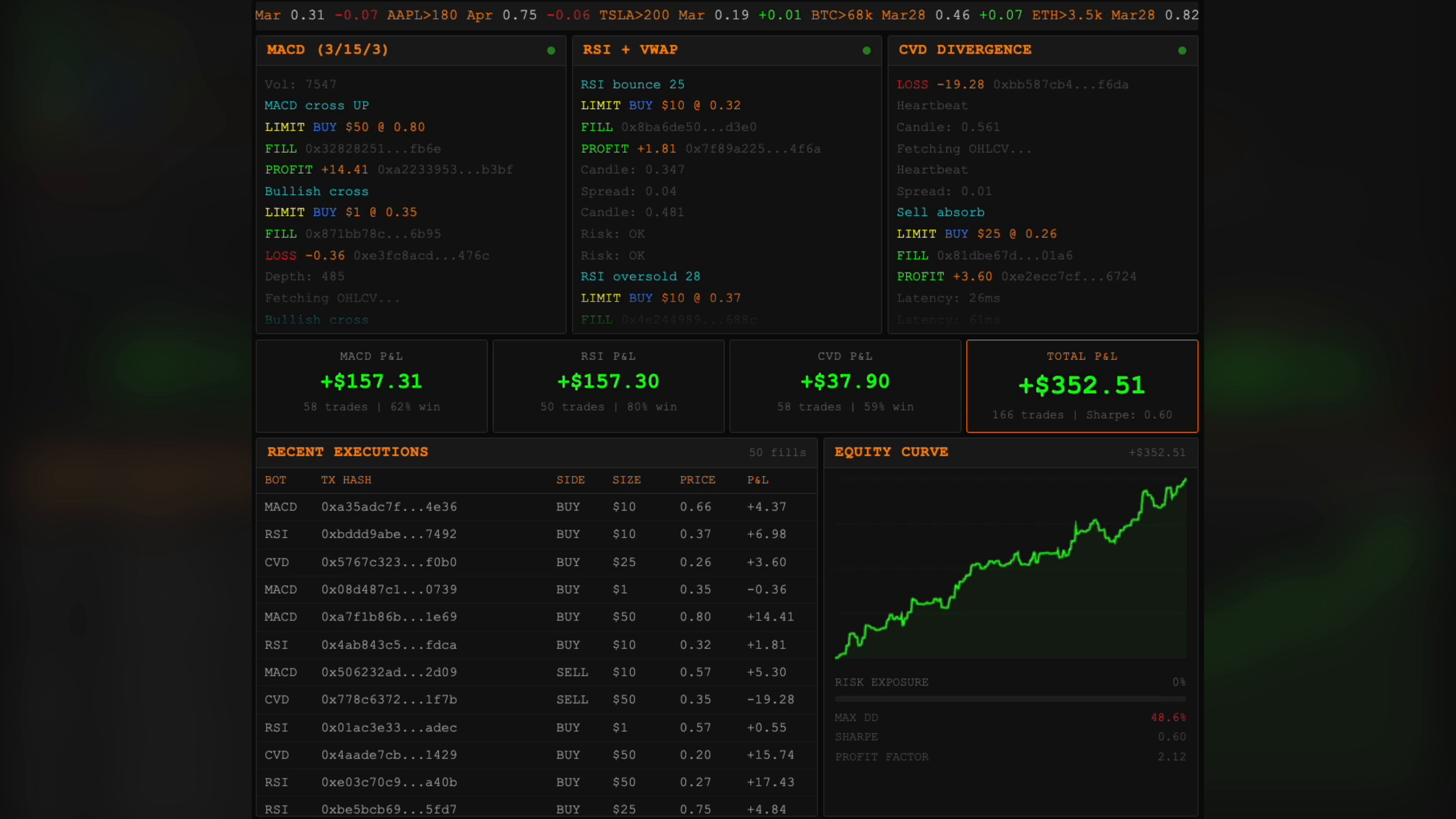
The most entertaining moment was @zostaff claiming Claude built three trading bots in 15 minutes that made $2,503 the next day, prompting an immediate job resignation. The timeline's skepticism meter should be pegged on that one. The most practical takeaway for developers: when your AI agent fixes a bug, immediately ask it to write comprehensive end-to-end integration tests that would catch that class of bug in the future, as @doodlestein suggests. It hardens your codebase and often flushes out additional issues you didn't know existed.
Quick Hits
- @iruletheworldmo shared @PawelHuryn's guide on running Claude Dispatch from a phone for 48 hours straight. Worth a bookmark if you're exploring mobile-first agent workflows.
- @theo posted a cryptic "I'm not scared of Anthropic" video that generated engagement without much substance to analyze.
- @kshvbgde highlighted a guide on "vibecoding" your way to $10M ARR, capturing the indie hacker energy around AI-assisted rapid development.
- @Tradesdontlie quote-tweeted a "learn while you sleep" post with bewilderment that anyone isn't using these tools yet. The adoption pressure is real.
- @DavidGeorge83 published "There are only two paths left for software," arguing the comfortable middle ground for software companies is over as public markets reprice the sector.
- @heygurisingh spotlighted Pascal Editor, an open-source browser-based 3D building editor built with React Three Fiber and WebGPU that could disrupt $50K/seat BIM software.
AI Agents and Autonomous Workflows
The agent conversation today was less about whether agents work and more about how to architect them properly. The tooling layer is getting sophisticated, with developers building persistent memory systems, multi-agent coordination, and learning loops that convert one-off solutions into reusable skills.
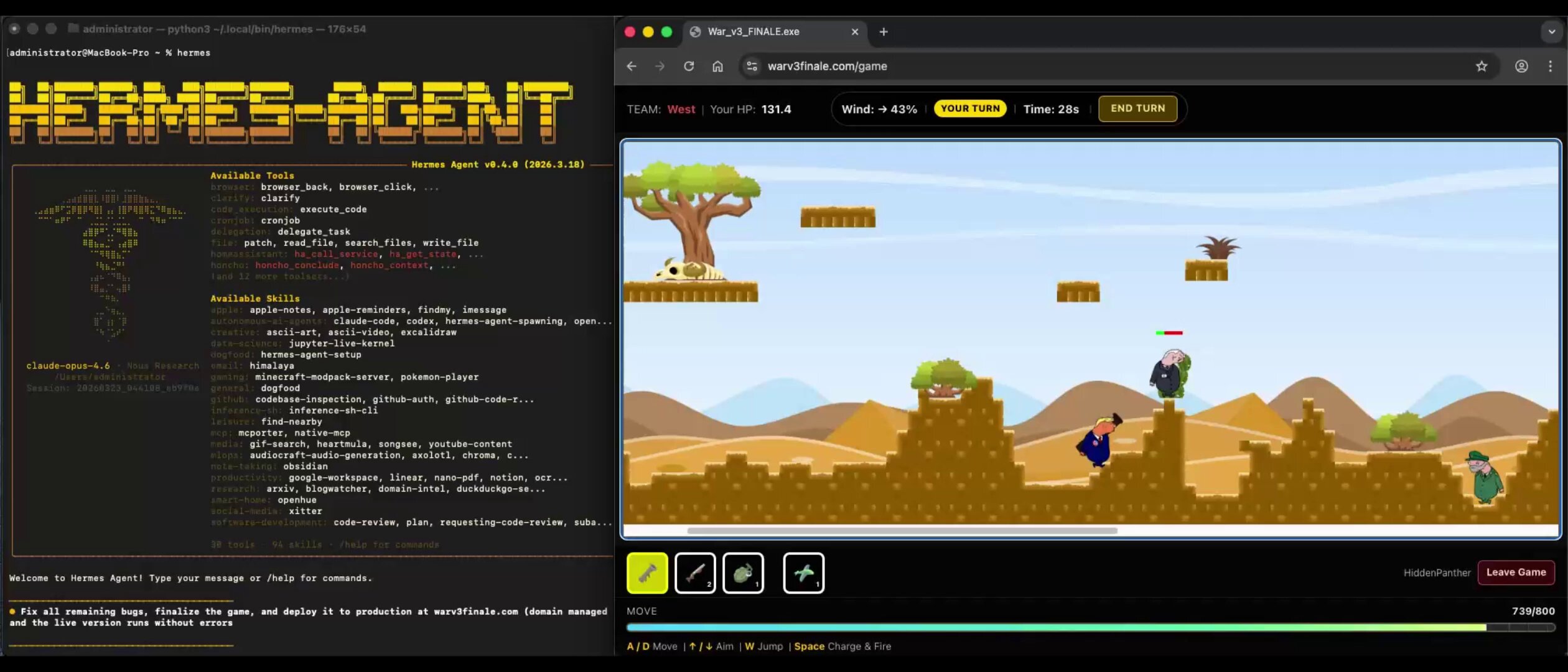
@javierblez broke down how the Hermes agent by Nous Research built a fully playable Worms clone in 2.5 hours: "Hermes used 'Persistent Shell' mode, which ensured it didn't forget its current folder or active tools. To optimize the workflow, the agent moved beyond linear execution and parallelized the workload." The agent spawned isolated subagents, used filesystem checkpoints for rollback, and even attached to a live Chrome instance via CDP to fix rendering bugs in real-time. By the end, it had autonomously converted the physics logic into a reusable plugin.
On the memory front, @code_rams pushed back on a popular article about fixing agent memory, adding three layers the original missed: "LCM (Lossless Context Management) lets compaction summaries expand back to full detail. No information loss. Cron-driven nightly memory distillation... don't rely on manual saves. Multi-agent shared workspace... all my agents read the same memory files." This kind of systems thinking around agent infrastructure is exactly what separates toy demos from production setups. @davis7 is exploring a related frontier, letting agents write TypeScript to call MCPs and APIs instead of using normal tool calls, noting that @RhysSullivan's "executor" project might represent the future of agent-to-tool communication.
Claude Code Ecosystem
Claude's developer tooling got several notable updates and community contributions today. The headline feature is /schedule, which lets you create recurring cloud-based jobs directly from the terminal. @minchoi captured the excitement: "Claude just got /schedule. Now it can work for you 24/7 while you sleep." The original announcement from @noahzweben explained they use it internally to "automatically resolve CI failures, push doc updates, and generally power automations that you want to exist beyond a closed laptop."
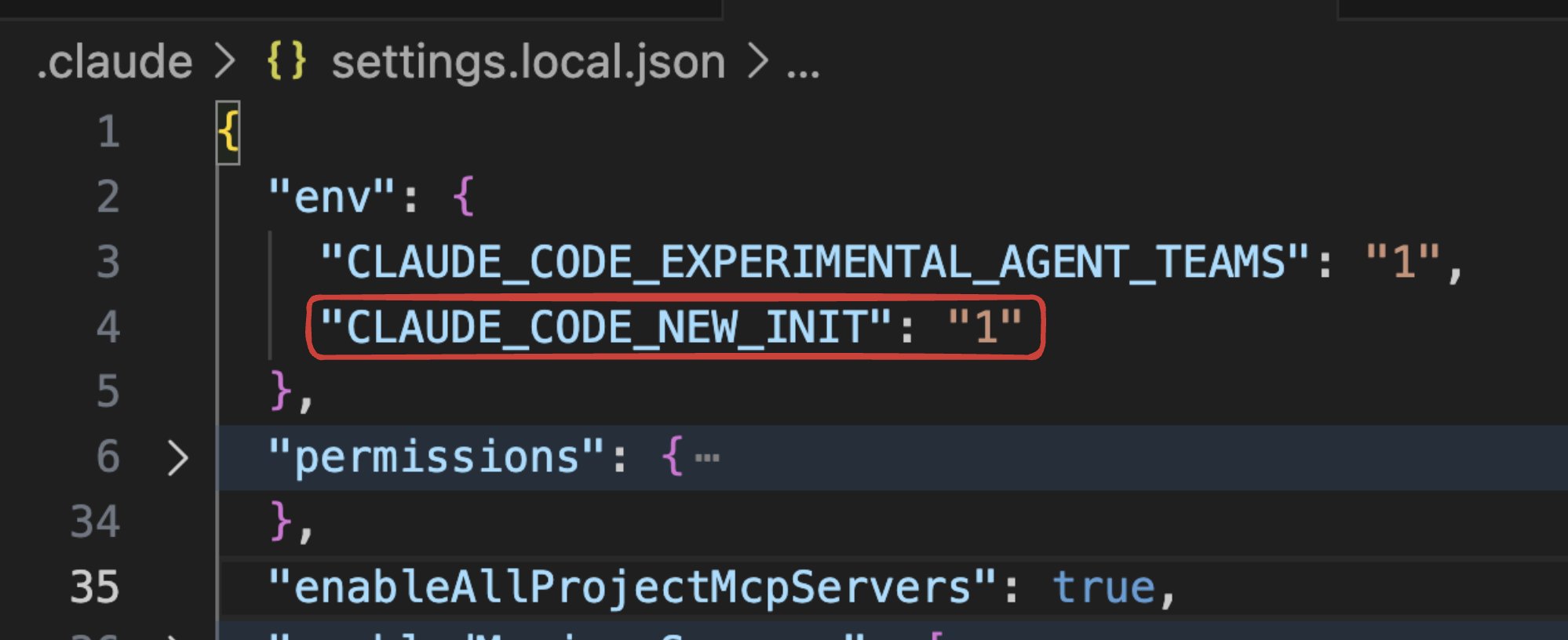
@lydiahallie shared a practical tip for anyone building with the Claude Agent SDK: "If you're building a read-only tool, make sure to mark it with readOnlyHint: true. This tells Claude Code it has no side effects and is safe to parallelize. Otherwise no other tool can run alongside it, essentially creating a 'serializing barrier.'" Meanwhile, @dani_avila7 revealed the Claude Code team is testing a revamped /init command that interviews you, scans your codebase, and sets up CLAUDE.md, skills, and hooks automatically. Enable it with "CLAUDE_CODE_NEW_INIT": "1" in your settings.json.
@coreyganim also pushed out a guide on the "anatomy of a perfect OpenClaw setup," emphasizing that the real value comes from configuring memory, skills, and custom behavior rather than just installing and chatting. These posts collectively paint a picture of Claude Code evolving from a coding assistant into a configurable development platform.
Model Performance and Efficient Inference
The model benchmarking community had a field day with two developments pushing the boundaries of what's possible on consumer hardware. @sudoingX is testing NVIDIA's Nemotron Cascade head-to-head against Qwen 3.5 on a single RTX 3090: "30B total, 3B active. Fits on a single RTX 3090. Hybrid mamba MoE. Gold medal on the international math olympiad with only 3 billion active parameters." The architecture comparison between Mamba and DeltaNet on identical hardware should produce genuinely useful benchmarks.
On the mobile side, @Alexintosh achieved a 2.3x speedup over baseline for Qwen 3.5 35B on an iPhone 17, hitting 13.1 tokens per second through a cocktail of optimizations: "Fused attention, CMD1+CMD2 Merge, Fused Expert Kernel, Expert Prefetch, I/O Fanout." Running a 19.5GB model on a device with 12GB of RAM was already impressive at 5.6 tok/s two days ago. The rapid iteration on mobile inference optimization suggests on-device AI is closer to practical usability than the benchmarks alone would indicate.
Game Development Meets AI
Game development emerged as a surprisingly active intersection point today. @ErickSky highlighted Unity-MCP, a repo that bridges LLMs directly to Unity Editor and game runtime: "With ONE SINGLE LINE you can convert ANY C# method into a tool that AI can use. AI inside the final game: intelligent NPCs, runtime debugging, a dropship flying on its own." The repo offers 100+ native tools and promises a two-minute CLI setup.
@jojodecayz demonstrated a different angle, using ComfyUI with local agent tools to recreate social media videos by simply dropping URLs. The argument is that ComfyUI's extensibility positions it uniquely to ride the agent wave, while more closed tools will struggle to integrate. Between Unity-MCP's game-engine integration and ComfyUI's creative pipeline automation, the pattern is clear: AI agents are moving beyond text and code into interactive media production.
Developer Best Practices
@doodlestein shared what amounts to the best agent coding tip of the day: whenever your agent fixes a bug, don't let it stop there. "Ask it to also create comprehensive end-to-end integration tests that would have caught that bug and all similar types of bugs in the future." The insight is that this approach doesn't just prevent regression; it actively surfaces latent bugs by forcing the agent to think about entire categories of failure modes.
@0xSero took a complementary angle on code quality, showcasing a /readiness-report feature in Droid that "compares your codebase against best standards and suggests ways to de-slop." As agent-generated code proliferates, the need for automated quality gates becomes critical. The community is starting to build the tooling to keep AI-assisted development from producing technical debt at machine speed.
OpenAI Infrastructure Update
@OpenAIDevs announced a 10x speedup for spinning up agent containers through a new container pool in the Responses API: "Requests can reuse warm infrastructure instead of creating a full container creation each session." This is a meaningful infrastructure improvement for anyone building agent workflows on OpenAI's platform, reducing the cold-start penalty that makes agent interactions feel sluggish. The competitive pressure between Anthropic's Claude Code scheduling and OpenAI's container pooling shows both companies investing heavily in making agents feel instantaneous.
Sources


the ULTIMATE 48h doomsday guide to vibecode & scale your app to $10M ARR
There are only two paths left for software
To software CEOs, founders, boards, and the investor community: the comfortable middle is over. Public markets have already repriced the sector, and...
I Fixed OpenClaw's Biggest Problem (Memory)

Anatomy of a perfect Openclaw setup
What if You Could Learn While You Sleep?
How to Quit a Job You Hate. How to Build Your Own Trading Bot.A Complete Guide.
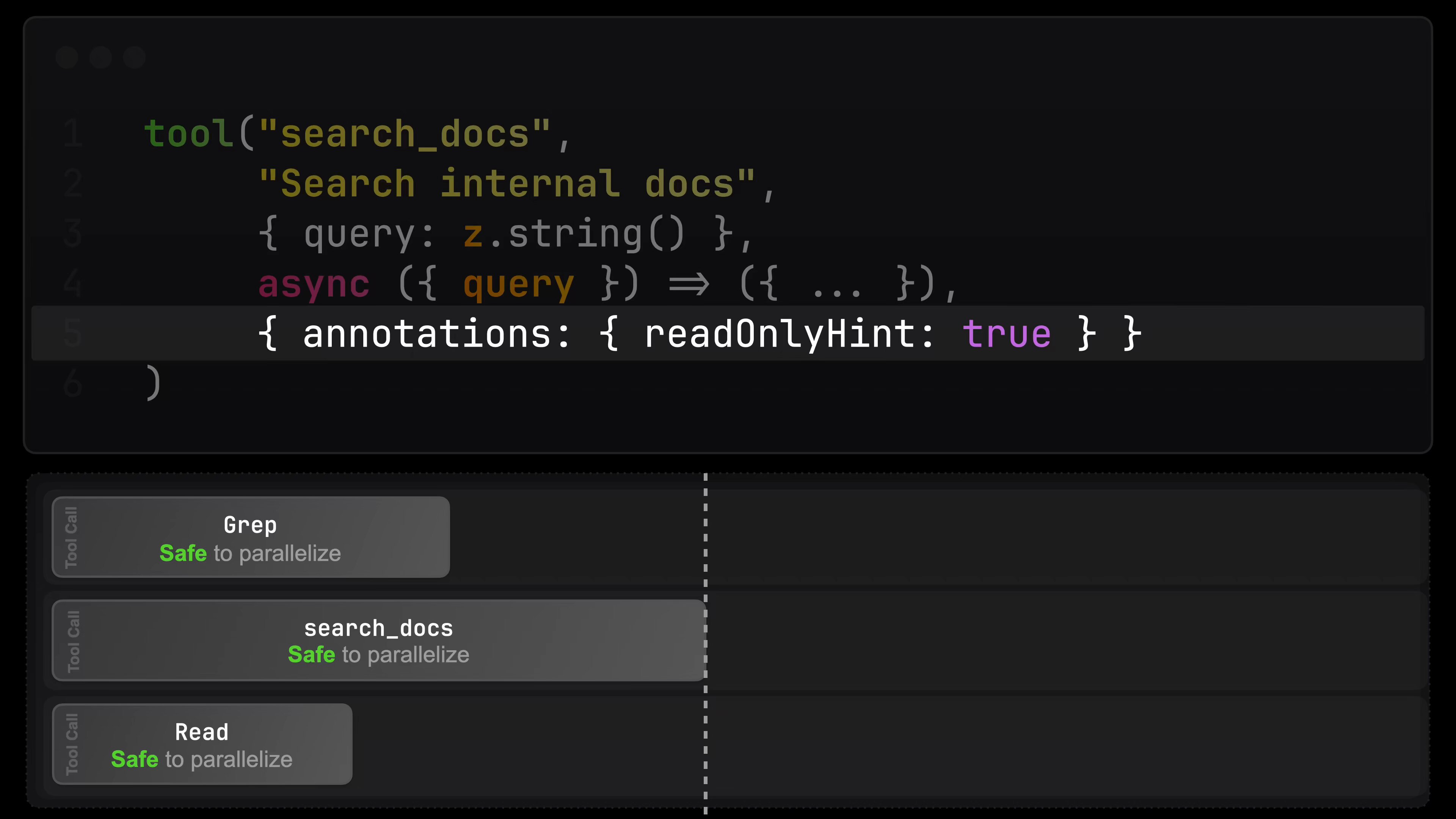

Use /schedule to create recurring cloud-based jobs for Claude, directly from the terminal. We use these internally to automatically resolve CI failures, push doc updates, and generally power automations that you want to exists beyond a closed laptop https://t.co/uuDesRzSrg
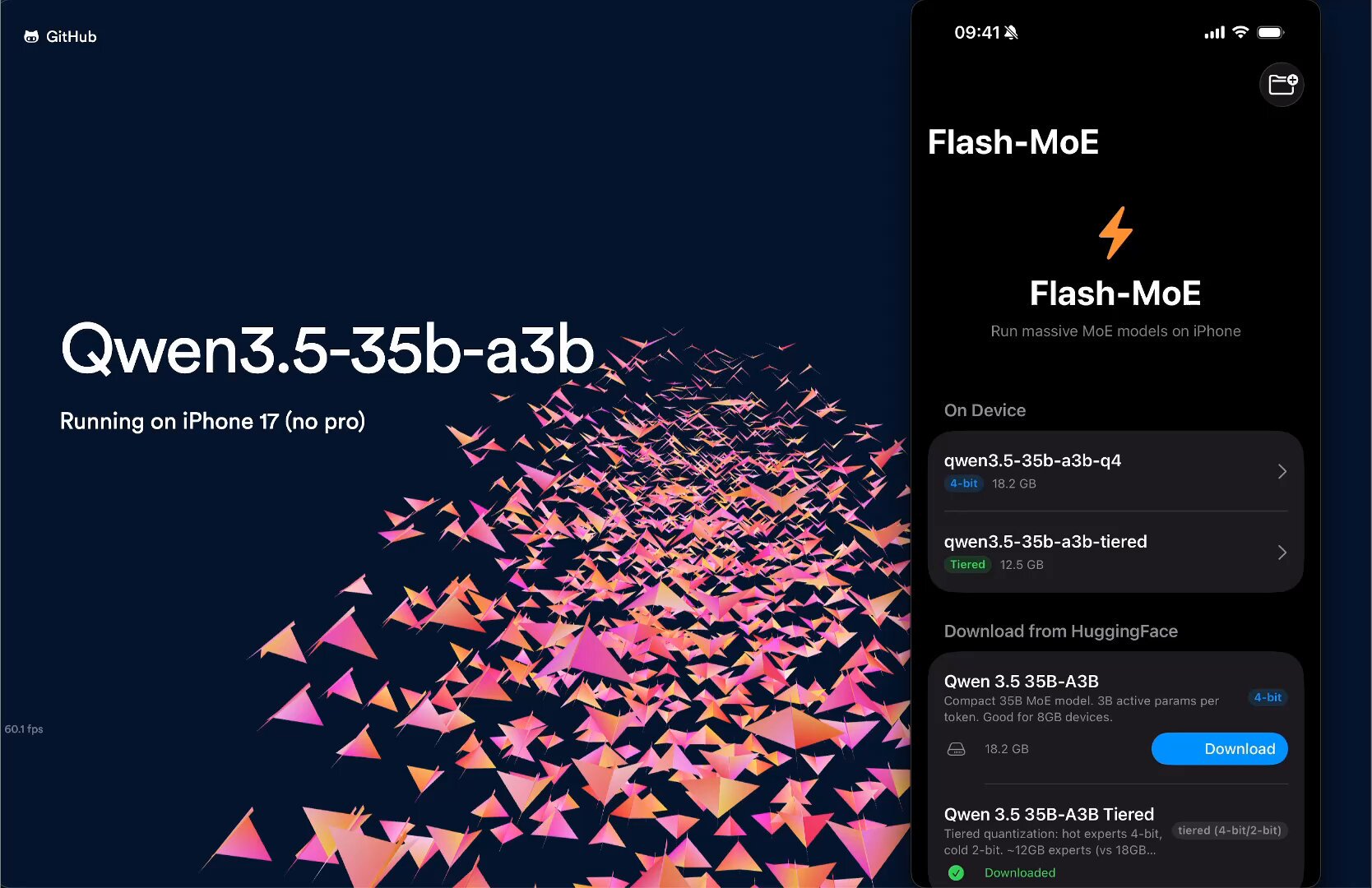
I just ran Qwen3.5 35B on my iPhone at 5.6 tok/sec. Fully on-device. 4bit | 256 experts. Model: 19.5GB. iPhone: 12GB RAM. wild. https://t.co/gZErpMVdvO




People are missing this: ComfyUI is the only tool in class positioned to ride the agent wave. Others are simply too closed off and unextensible. In a future where agents are integral to work, the artists who stuck with ComfyUI will be miles ahead of those who went elsewhere
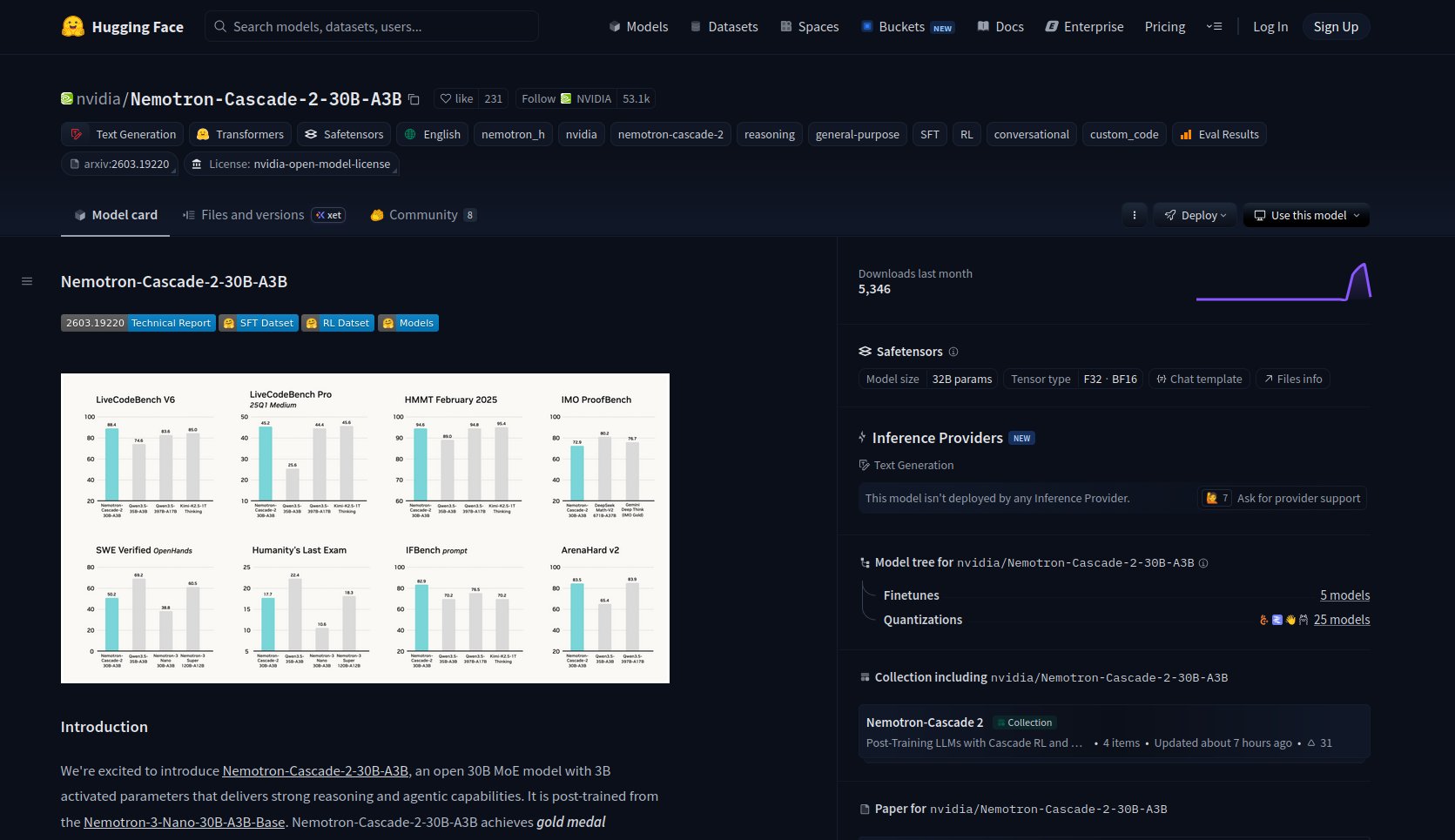
testing cascade 2 on a single 3090 right now. same card i tested qwen 3.5 35B-A3B on at 112 tok/s. same active params, same VRAM tier, different hybrid architectures. mamba vs deltanet head to head. numbers coming tonight. if a spark lands on my desk next you'll get those numbers too.
The Claude Dispatch Guide: 48 Hours Running AI From My Phone