Eval-Driven Development Takes Center Stage as Local Models Hit 38 tok/s on Consumer Hardware
Today's discourse centered on evolving coding agent workflows, with developers sharing hard-won insights about evaluation-first development and the pirate-architect team model. Meanwhile, the local inference crowd flexed impressive benchmarks running Qwen 3.5 397B on Mac hardware, and Claude Code's ecosystem continued expanding with new init flows, Obsidian integrations, and community-driven hack compilations.
Daily Wrap-Up
The most striking thread running through today's posts is how quickly the meta-game around coding agents is maturing. We've moved past the "wow, AI writes code" phase and into serious methodology debates. @synopsi's revelation that they now spend 90% of their time writing evals rather than specs or code feels like a watershed moment for how experienced practitioners are thinking about agent-assisted development. It mirrors a broader pattern: the bottleneck isn't getting AI to write code anymore, it's knowing whether the code is correct. Meanwhile, @danshipper's pirate-architect model for two-person engineering teams captures the emerging tension between speed and structure that every team shipping with AI tools is navigating right now.
The local inference community had a strong showing today, with concrete benchmarks that are getting harder to dismiss. Running a 397B parameter model at 38 tokens per second on a Mac with 128GB RAM is the kind of number that makes API-only workflows look increasingly expensive for certain use cases. The debate between @sudoingX and the closed-model establishment isn't just ideological anymore; people are posting receipts showing local models handling complex multi-thousand-line coding sessions. Whether you're in the API camp or the local camp, the floor for what's "good enough" keeps rising on both sides.
The most entertaining moment was easily @thdxr's deadpan instructions for "fixing" the AWS console by piping an AI agent through CloudShell, complete with the prophetic step 5: "cause a sev1 incident." It's the kind of joke that lands because everyone knows someone who would actually try it in production. The most practical takeaway for developers: if you're still writing detailed specs before handing them to a coding agent, try @synopsi's approach of writing evals first and letting the agent generate its own spec from your constraints. Multiple practitioners are converging on this pattern because agents produce better code when they articulate the requirements in their own "language" rather than interpreting yours.
Quick Hits
- @elonmusk quote-tweeted "Anthropic" in response to claims about Palantir AI + Claude being used in military operations. One word doing a lot of heavy lifting, as usual.
- @yacineMTB shared a blog post titled "being a human in the singularity," reflecting on how Codex 5.4 has personally saved them a thousand dollars a month in GPU server costs.
- @trillhause_ is hyping ypi as the next evolution beyond pi coding agent, suggesting RLM (reinforcement learning from machines) could be adopted by all major agent harnesses soon.
- @minchoi highlighted 10 use cases where OpenClaw is changing the agentic AI landscape, with major companies reportedly building on the framework.
- @theo broke down the Cursor x Kimi drama, suggesting Cursor's "new model" might not be as novel as marketed.
Coding Agent Workflows Are Growing Up
The conversation around how to actually work with coding agents has shifted dramatically from "prompt and pray" to something resembling real engineering methodology. @synopsi laid out a clear evolution that many power users will recognize: starting with plan-implement-review cycles, moving through product specs and planning, and finally arriving at an evals-first approach where the guardrails come before anything else.
> "I now essentially spend 90% of time working on evals. The difference this makes is indescribable. Almost all code works immediately, design is close to perfect, text is almost there." — @synopsi
What's particularly interesting is the observation that agents perform worse when fed human-written specs versus generating their own. This suggests a fundamental insight about how language models process instructions: they have preferred patterns of expression that lead to more consistent execution. When you constrain the output with evals but let the agent choose its own path to get there, you're working with the model's strengths rather than against them.
> "I also try to avoid being overly specific directly. I noticed that when I write the product spec manually the agent does worse than when it writes it itself." — @synopsi
This connects directly to @danshipper's pirate-architect model, which essentially formalizes two modes of working with agents. The pirate vibe-codes fast, shipping features and discovering product surface area. The architect then takes that discovered surface and turns it into something reliable. Both roles use AI, but at different tempos and with different quality bars. It's a pragmatic acknowledgment that not all AI-assisted code needs the same level of rigor, and that the human's job is increasingly about judgment, not keystrokes.
Claude Code Ecosystem Keeps Expanding
Claude Code dominated the feed today with multiple angles: new features, community workflows, and integration patterns. @trq212 announced a revamped /init command that interviews users to set up skills, hooks, and configuration, a meaningful UX improvement over the current setup experience. Separately, @davesnx praised the /grill-me skill for forcing deeper design thinking, calling it a step beyond simple interview-style prompting.
> "It's literally making me think and plan like never before..." — @davesnx, on /grill-me
The Obsidian + Claude Code stack got a signal boost from @coreyganim, who shared @cyrilXBT's full course on using the combination as a memory-augmented AI assistant. The pitch is compelling: rather than a generic chatbot, you get an assistant that actually knows your accumulated work through Obsidian's knowledge graph. Meanwhile, @aakashgupta endorsed @mvanhorn's comprehensive Claude Code tips compilation as "actual, golden advice" rather than AI slop, which in 2026 is about the highest compliment you can give a tutorial.
What ties all of this together is that Claude Code's moat isn't just the model; it's the ecosystem of skills, hooks, and integration patterns that the community is building around it. The /init revamp suggests Anthropic recognizes this and is investing in lowering the barrier to entry for these power-user workflows.
Local Inference: The Benchmarks Keep Getting Better
Two posts today painted a picture of local AI inference that's increasingly hard to ignore. @dealignai reported running Qwen 3.5 397B (the JANG_1L 112GB quantization) at a smooth 38 tokens per second on a Mac with 128GB RAM using MLX Studio, no SSD offloading required. That's a massive model running at usable speeds on consumer hardware.
@sudoingX went further, turning this into an ideological argument. Running Qwen 3.5 27B on a single 3090 at 50 tokens per second, they reported the model building "a full space shooter, 3,000+ lines, from a single prompt." Their broader point was about the gap between model capability and harness quality.
> "Open models aren't there yet is what you say when your harness can't parse tool calls on local models and you blame the model instead of fixing the harness." — @sudoingX
The technical claim is worth unpacking: that many reported failures of local models in agentic settings are actually failures of the orchestration layer, not the model itself. When people switch to harnesses with per-model parsers, the same "broken" models suddenly work. If true, this suggests the real frontier in local AI isn't model quality but tooling quality, an area where the open source community has historically excelled given enough time and attention.
The AWS Console Gets "Fixed"
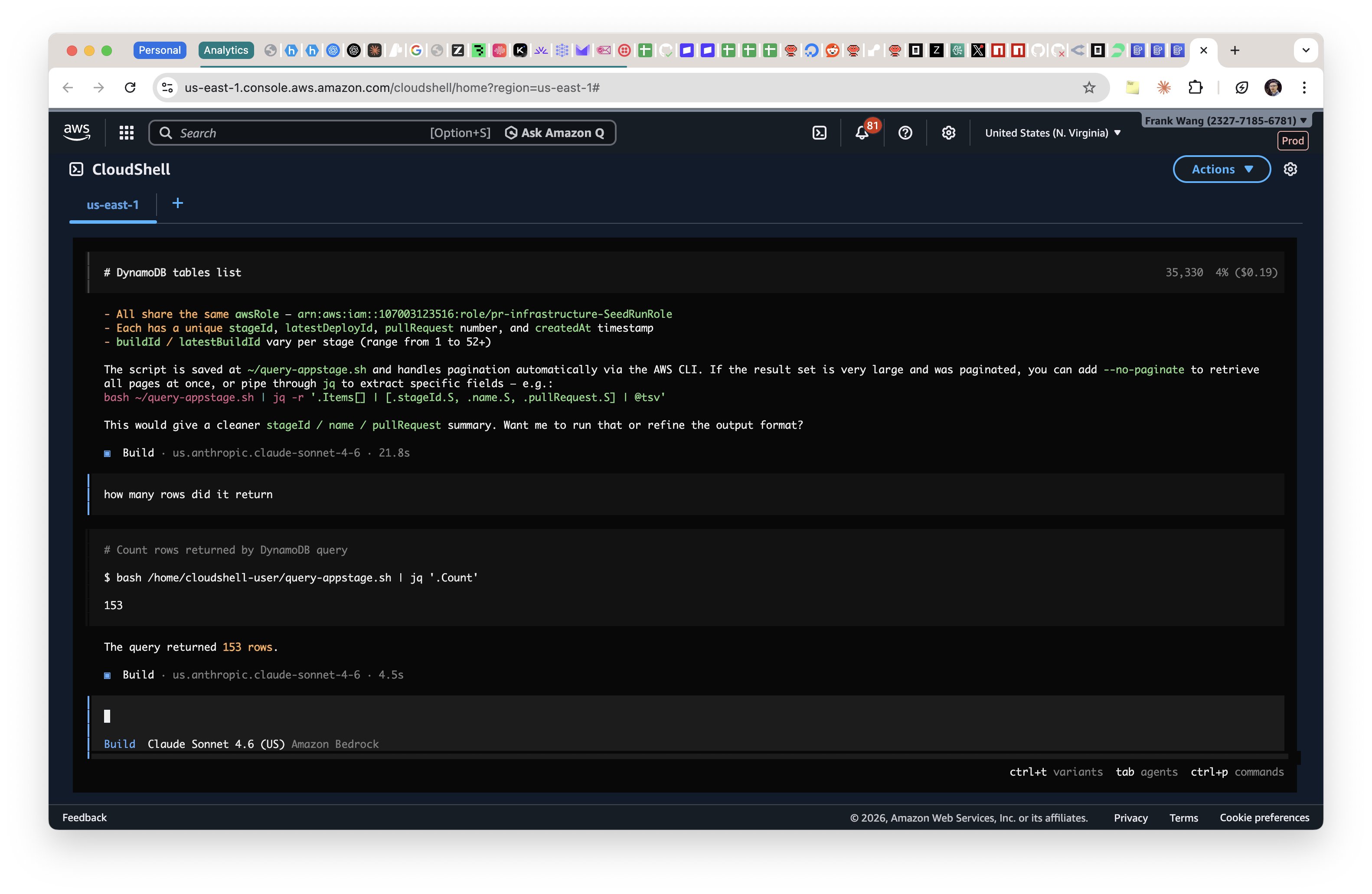
In the "move fast and break things (literally)" department, @thdxr shared a workflow for running OpenCode AI directly in AWS CloudShell, where it automatically picks up authentication and Bedrock model access. The five-step guide builds to a punchline that every cloud engineer felt in their bones.
> "1. open cloud shell 2. npx opencode-ai 3. it already is authed with aws + will pickup bedrock models 4. ask it to do everything aws 5. cause a sev1 incident" — @thdxr
Jokes aside, the underlying capability is genuinely interesting. Having an AI agent that's pre-authenticated with your cloud environment and can interact with services directly removes a significant friction point in cloud management. The risk, of course, is exactly what the joke suggests: an agent with full AWS credentials and no guardrails is a sev1 waiting to happen. It's a microcosm of the broader challenge with agentic AI in production environments, where the same properties that make agents useful (autonomy, broad access) are exactly what make them dangerous.
Sources
D
guys we fixed the aws console
1. open cloud shell
2. npx opencode-ai
3. it already is authed with aws + will pickup bedrock models
4. ask it to do everything aws
5. cause a sev1 incident https://t.co/udSkJpW9DQ
M
If you tried pi coding agent and it blew your mind. You should try ypi if you want to experience early sparks of agi.
Required some setup w/ custom tools for me to realize its power. Wouldn't be surprised if all major agent harnesses adopt RLM in the next few months. https://t.co/HG5AewoVFN
K
being a human in the singularity
being a human in the singularity
Codex 5.4 extra high has already personally saved me a thousand dollars a month. I used to pay for a GPU server to host dingboard. I had a 4090 sittin...
T
we're testing a new version of /init based on your feedback- it should interview you and help setup skills, hooks, etc.
you can enable it with this env_var flag:
CLAUDE_CODE_NEW_INIT=1 claude
would love your feedback!
T
trq212
@trq212
I want to make /init more useful- what do you think it should do to help setup Claude Code in a repo?
T
Cursor's new model might not be all that new.
Did my best to break down the Cursor x Kimi drama https://t.co/Db46Gr8iK7

C
FINALLY, a legit article that breaks this down in detail.
Obsidian + Claude Code = an AI that actually knows your work.
Not a generic chatbot. A real assistant with memory.
@cyrilXBT nailed it. https://t.co/41c6JqXPI3

C
cyrilXBT
@cyrilXBT
Obsidian + Claude Code is the most underrated productivity stack in tech right now.(Full course)
E
“Anthropic”
S
shiri_shh
@shiri_shh
Palantir AI + Claude was used to detect, prioritize, and strike over 1,000 targets in the first 24 hours of Operation against IRAN. The success was so ridiculous, so game-changing, that the Pentagon didn’t even wait. What used to be just a pilot project, just something they were testing out… suddenly became official, permanent, and everywhere. Palantir is now the core AI brain of the entire U.S. military. It’s getting rolled out across ALL branches.
D
/grill-me is insane. I used to have a "interview me with all the questions..." but didn't get as far as "Walk down each branch of the design tree"
It's literally making me think and plan like never before...
M
mattpocockuk
@mattpocockuk
For weeks, folks have been asking me to make a video building a feature with Claude Code in a real codebase So here you go: - From idea to AFK agent to QA - Every single step explained - No slop allowed https://t.co/DUGpIsNxmk
D
new model for engineering team structure in 2026:
2 people only
one pirate and one architect
the pirate's job is to move as fast as possible to develop valuable, shipped product features by vibe coding.
the architect's job is to turn the product surface discovered by the pirate into a reliable, structured machine—also by vibe coding, but at a slower, more well-reasoned pace.
every product needs a pirate but most product's only need an architect once they some form of PMF, and in that case they usually don't need one full-time. architects can work across many codebases and solve interesting technical challenges. pirates go hard on a product that they own end-to-end.
D
For Mac owners with 128Gb RAM - You don’t need to resort to SSD offloading, give Qwen 3.5 397b JANG_1L (112gb) a chance, running a full smooth 38token/s only on MLX Studio. https://t.co/fuFagOBnTc #macbook #m5max #mlx
M
OpenClaw changed the agentic AI game.
People are building insane use cases, major companies are building on it.
There's a major shift.
10 examples👇Bookmark this https://t.co/5jDbDulmLL
S
the founder of openclaw joined the company that was founded to make AI open and now charges you per token. and is now telling you open models aren't there yet.
i run qwen 3.5 27b on a single 3090. 50 tok/s. it writes code, handles tool calls, runs agent sessions for hours. the model built a full space shooter, 3,000+ lines, from a single prompt. i published the data.
"open models aren't there yet" is what you say when your harness can't parse tool calls on local models and you blame the model instead of fixing the harness. i have the DMs. people switch from openclaw to hermes agent and their "broken" models suddenly work.
pair a good model with a good harness like hermes agent where parsers are built per model. your data stays on your machine. no API key. 0 subscription. no one training their next model on your thinking.
don't listen to someone with an OpenAI paycheck telling you open source can't do the job. install it. test it yourself. the receipts are on my timeline.
he built a harness that couldn't handle local models and chose the API paycheck over fixing it. that should tell you everything.
S
steipete
@steipete
@sbaratelli @nvidia @openclaw most folks will want as much intelligence as possible, and open models aren't there yet.
A
This is not AI slop but actual, golden Claude Code advice.
M
mvanhorn
@mvanhorn
Every Claude Code Hack I Know (March 2026)
R
The way I work with coding agents changed significantly in the last year.
Started: plan -> implement -> review -> fix
Later: prod spec -> plan ...
Then: prod spec -> ... -> eval
Now: evals -> prod spec -> ...
I now essentially spend 90% of time working on evals.
The difference this makes is indescribable. Almost all code works immediately, design is close to perfect, text is almost there. It takes very little to get it to usable.
Stronger and clearer guardrails I give the coding agent, better it does. And when I start with them, it writes incredibly clear spec and requirements that are super easy to follow and have very little room for interpretation.
I also try to avoid being overly specific directly. I noticed that when I write the product spec manually the agent does worse than when it writes it itself. It uses language I would've necessarily use myself. And that makes all the difference.