Thariq's Claude Code Architecture Deep-Dive Goes Viral as Supermemory Hits 99% SOTA and SpaceX Announces TERAFAB
The AI developer community spent the day dissecting Thariq's technical writing on Claude Code internals, from prompt caching strategies to skill design. Meanwhile, Supermemory announced a near-perfect score on long-term memory benchmarks using agentic retrieval instead of vector search, and SpaceX/Tesla unveiled TERAFAB, a terawatt-scale compute manufacturing project.
Daily Wrap-Up
Today's feed was dominated by one thing: how agents actually work under the hood. Thariq's pinned thread of Claude Code architecture posts drew an enormous summary thread from @rohit4verse that read like a leaked engineering handbook. The details were surprisingly concrete: prompt caching as a first-class infrastructure concern, tools as a design surface that needs constant pruning, and the revelation that Claude Code's team declares SEVs when cache hit rates drop. This wasn't theoretical agent discourse. It was production engineering, and the community ate it up.
The other big story was Supermemory's claim of ~99% on LongMemEval using what they call ASMR (Agentic Search and Memory Retrieval), which replaces vector databases entirely with parallel observer agents extracting structured knowledge. If that holds up after open-source release in 11 days, it could meaningfully shift how developers think about retrieval. On a completely different scale, SpaceX and Tesla announced TERAFAB, a joint project targeting over a terawatt of compute manufacturing per year. Whether that reshapes the AI hardware landscape remains to be seen, but the ambition is hard to ignore. The most entertaining moment was easily @RG_Leachman's confession that running out of Claude tokens is now a parenting strategy, which honestly felt like the most relatable post of the day.
The most practical takeaway for developers: study Thariq's writing on prompt caching and tool design. The insight that injecting system reminders into user messages (instead of editing the system prompt) preserves the cache prefix is the kind of detail that separates a $50/day agent bill from a $500/day one. If you're building agents, this is required reading.
Quick Hits
- @elliotarledge's CUDA course on FreeCodeCamp crossed 500K views, proving that GPU programming education has massive demand even as abstractions pile up on top of it.
- @OpenAIDevs shared a guide on building "intentional frontends" with GPT-5.4, emphasizing tighter constraints and visual references over free-form generation.
- @minchoi flagged Claude Code's new scheduled cloud-based tasks feature (quoting @noahzweben), where you set a repo, schedule, and prompt and Claude runs it without your local machine. "ClaudeBot" is becoming real.
- @oikon48 published a Japanese-language overview of "Everything Claude Code," adding to the growing international documentation ecosystem around the tool.
- @badlogicgames retweeted a demo of pi + ghostty running entirely in a Cloudflare Workers durable object with SQLite-based filesystem and cron support, a neat showcase of edge computing capabilities.
- @iruletheworldmo boosted a guide on structuring the
.claude/folder (quoting @akshay_pachaar), calling folder organization "the difference between you and the great Karpathy." - @SpaceX formally announced TERAFAB alongside @elonmusk's note that the project targets terawatt-scale compute production, split roughly 80/20 between space and ground applications.
Claude Code Internals and Agent Architecture
The biggest conversation of the day centered on how Claude Code is actually built. @trq212 (Thariq) pinned a thread collecting all his technical writing on the subject, noting "I put a lot of heart into my technical writing, I hope it's useful to you all" and mentioning the posts would appear on the Claude blog soon. The thread covered agent design, skills as an abstraction layer, and lessons from production.
But it was @rohit4verse's exhaustive summary that turned the thread into a community event. The breakdown revealed architectural decisions most developers would never guess. Prompt caching isn't just an optimization; it's treated as critical infrastructure. The team's prompt layout is carefully ordered (static system prompt, then CLAUDE.md, then session context, then messages) because cache matching is prefix-based. Seemingly innocent changes like adding timestamps to static prompts or shuffling tool order destroy the cache entirely. The most surprising detail: "Switching from Opus to Haiku mid-session? Actually MORE expensive because you rebuild the entire cache. Use subagents with handoff messages instead."
On tool design, the evolution is instructive. The AskUserQuestion tool took three attempts before landing on a dedicated tool with structured output. Todos got replaced by Tasks as models improved because "smarter models found this limiting and stuck rigidly to the list." The takeaway Rohit highlighted is worth repeating: "tools your model once needed might now be constraining it." This connects directly to Thariq's companion post claiming "skills are the abstraction that all agents will build on," and his observation that "building an agent is more of an art than a science." For anyone building production agents, the lesson is clear: agent infrastructure is a living system that needs to evolve with model capabilities, not a static scaffold you set and forget.
Memory Systems and Retrieval
The retrieval conversation took a sharp turn today with Supermemory's announcement. @kimmonismus broke down the results: "Achieved ~99% on LongMemEval_s using experimental ASMR (Agentic Search and Memory Retrieval) technique. Replaced vector search and embeddings with parallel observer agents extracting structured knowledge across six vectors from raw multi-session histories." The key claim is that no vector database is required at all, with specialized search agents handling direct facts, related context, and temporal reconstruction instead.
This is a potentially significant shift. The RAG paradigm has been the default approach to memory and retrieval for the past two years, and the idea that agentic search could replace it entirely (while hitting near-perfect scores) challenges a lot of established infrastructure. The promise of open-sourcing in 11 days means the community will get to stress-test these claims soon. Combined with today's Claude Code discussions about how agents already use filesystem-based state and progressive search strategies, there's a growing sense that the "embed everything into a vector store" era may be giving way to more structured, agent-driven retrieval.
AI Education and the Training Gap
@damianplayer pitched what might be the most straightforward business idea of the day: in-person AI workshops for corporate professionals. "Local in-person AI classes for corporate boomers. Think Claude 101. Easily a $25K/mo opportunity." The pitch is simple: rent a room, run Meta ads targeting 35-60 year olds, charge $500-$1000 for a two-day hands-on workshop covering vibecoding, Claude, ChatGPT, prompting, and agents.
The post resonated because it points at a real gap. While the developer community generates endless tutorials, courses, and threads for technical users, there's a massive population of professionals who are being told to adopt AI tools daily but have "zero clue how to use it." They want face-to-face guidance, not another online course. @sh_reya's post about combining "auto research-style search loops with qualitative coding-style evaluators" for subjective tasks represents the other end of this spectrum: cutting-edge methodology for researchers. The gap between these two audiences is enormous, and right now, almost nobody is serving the non-technical side with quality in-person instruction.
Local AI and Model Efficiency
The local inference crowd had a productive day. @based_bitcoiner reported a "significant upgrade" after switching from Ollama to llama.cpp on the same hardware, at the recommendation of @sudoingX who argued that "12GB of VRAM runs more intelligence than you think in 2026." Meanwhile, @0xSero marveled at Qwen's efficiency after @bnjmn_marie demonstrated that Qwen3.5 27B Q4 GGUFs match the original model's accuracy for OpenClaw tasks without expensive hardware.
These posts reflect a maturing local AI ecosystem where the tooling matters as much as the models. The Ollama-to-llama.cpp migration story is particularly telling: same weights, same GPU, better performance just from switching inference engines. On the model side, @juntao's Rust implementation of tiny TTS models (15M-80M parameters) pushed this even further, achieving 4x real-time on CPU with a 10MB binary and 100ms cold start. The punchline was that Apple's GPU actually ran slower than CPU at this scale because "GPU dispatch overhead exceeds the compute savings" below ~1B parameters. For edge deployment, the lesson is counterintuitive: smaller models often run best without a GPU at all.
Browser Agents and Web Automation
Two related posts highlighted the growing browser agent infrastructure. @browser_use announced Browser Use CLI 2.0, claiming "2x the speed, half the cost" with direct CDP (Chrome DevTools Protocol) integration. @gregpr07 took a different angle, emphasizing stealth: "Web Agents should browse the web freely, like a human would. That's why we built the most stealth browser infrastructure on the planet."
These represent two sides of the same coin. Browser Use is optimizing for developer efficiency and cost, while the stealth infrastructure (quoting @reformedot's benchmark of cloud browser providers) is solving the problem that many websites actively block automated browsing. As agents increasingly need to interact with the real web rather than APIs, both speed and undetectability become critical infrastructure concerns.
AI in Gaming and Graphics
@JakeSucky's dismissive take on NVIDIA's DLSS 5 announcement ("NVIDIA have announced DLSS 5, calling it an 'AI breakthrough' in visual fidelity for video games. Ya I'll pass") captured a growing skepticism about AI-driven upscaling in the gaming community. Meanwhile, @gdb (Greg Brockman) endorsed subagents in Codex as "very powerful," suggesting that the agent paradigm is becoming standard across coding tools, not just Claude Code. These two posts sit at opposite ends of AI enthusiasm: gamers tired of AI replacing native rendering, and developers embracing AI agents as force multipliers. The tension between "AI everything" fatigue and genuine productivity gains is one of the defining dynamics of 2026.
Sources
J
NVIDIA have announced DLSS 5, calling it an "AI breakthrough" in visual fidelity for video games
Ya I'll pass https://t.co/0WHIzPlkp3

R
“Kids I have good news. Daddy is out of Claude tokens until 3PM. He has time to play with you now.” https://t.co/YIYUhxpckZ

B
Introducing: Browser Use CLI 2.0 🔥
The most efficient browser automation CLI tool
> 2x the speed, half the cost
> Easily connect to running Chrome
> Uses direct CDP
Try it now 🔗↓ https://t.co/9YZ2oB5wVz
O
Better frontend output starts with tighter constraints, visual references, and real content.
Here’s how to build intentional frontends with GPT-5.4
https://t.co/6Jgwcmqd9f
M
It's happening... they are building ClaudeBot 💀
https://t.co/wjxClU2CPU

N
noahzweben
@noahzweben
You can now schedule recurring cloud-based tasks on Claude Code. Set a repo (or repos), a schedule, and a prompt. Claude runs it via cloud infra on your schedule, so you don’t need to keep Claude Code running on your local machine. https://t.co/Vse4WfVnKC
M
Python is for AI research. Rust is for AI production.
We created a complete Rust impl of tiny TTS models (15M-80M) from @divamgupta 10 MB binary, 100ms cold start, CPU-only, edge-ready.
🐱🦀 https://t.co/7HngBVd0Jw
CPU runs KittenTTS at 4x real-time, but Apple's GPU only hits 3x. @claudeai told us why: at this model size, GPU dispatch overhead exceeds the compute savings. ONNX's CPU backend with SIMD already saturates the hardware. Below ~1B params, the GPU loses.
Full story 👇
D
local in-person AI classes for corporate boomers.
think Claude 101.
easily a $ 25K/mo opportunity.
rent a presentation room. run meta ads targeting 35-60 year olds. charge $500-$1000 for a 2-day hands-on workshop.
teach vibecoding, Claude, ChatGPT, prompting and agents.
the demand is insane.
these people see AI everywhere but have zero clue how to use it.
they want face-to-face guidance, not online courses.
run the same curriculum weekly. refine based on questions. multiple up-sell or down-sell opportunities. scale to multiple cities once you nail the format.
you’re hitting a market everyone else ignores. corporate boomers with cash who prefer learning in person. they are also being told to learn these tools daily..
no chance this doesn’t work if you execute.
go out and nail this.
T
I put a lot of heart into my technical writing, I hope it's useful to you all.
📌 Here's a pinned thread of everything I've written.
(much of this will be posted on the Claude blog soon as well)
T
skills are the abstraction that all agents will build on
https://t.co/szzN99ZSiS
T
trq212
@trq212
Lessons from Building Claude Code: How We Use Skills
T
building an agent is more of an art than a science
https://t.co/oNXoVyra3T
T
trq212
@trq212
Lessons from Building Claude Code: Seeing like an Agent
S
Fun article on plugging together auto research-style search loops with qualitative coding-style evaluators. I am very optimistic about this approach on non-verifiable (ie subjective) tasks
N
nurijanian
@nurijanian
Improving AI Skills with autoresearch & evals-skills
R
If you use Claude Code and build AI agents, @trq212 's articles are not optional reading.
They are the instruction manual the team actually follows internally.
I have read every single piece he has published. Here's everything I learned from him:
PROMPT CACHING:
Claude Code's entire harness is built around prompt caching. They declare SEVs when cache hit rate drops
It's a prefix match. Order matters enormously
Their prompt layout:
> Static system prompt + tools (globally cached)
> CLAUDE.md (cached per project)
> Session context (cached per session)
> Conversation messages
What kills the cache:
> Timestamps in static prompts
> Shuffling tool order
> Adding/removing tools mid-session
> Switching models mid-conversation
Instead of editing the system prompt, they inject in the next user message which preserves the cache completely
Plan Mode: the obvious approach is swapping to read-only tools
That breaks the cache, instead they keep ALL tools loaded and use EnterPlanMode/ExitPlanMode as tools themselves
Bonus: the model can enter plan mode on its own when it detects a hard problem
For unused MCP tools: they don't remove them, they send lightweight stubs with defer_loading: true
Full schemas load only when the model discovers them via ToolSearch
Compaction (context overflow): they fork with the exact same prefix so the cache is reused
Only new tokens are the compaction prompt itself
Switching from Opus to Haiku mid-session? Actually MORE expensive because you rebuild the entire cache Use subagents with handoff messages instead
TOOL DESIGN:
The AskUserQuestion tool took 3 attempts:
> Adding questions to ExitPlanTool confused the model > Modified markdown output was inconsistent
> Dedicated tool with structured output worked.
Claude actually liked calling it
Even the best designed tool fails if the model doesn't understand how to call it
Todos got replaced by Tasks as models improved
Early Claude Code needed reminders every 5 turns Smarter models found this limiting and stuck rigidly to the list
Tasks support dependencies, cross-subagent updates, and can be altered/deleted
The takeaway: tools your model once needed might now be constraining it
Search went from RAG → Grep → Skills with progressive disclosure
Over a year Claude went from needing context handed to it to doing nested search across multiple layers on its own
Claude Code has ~20 tools. The bar to add a new one is high Every tool is one more option the model has to think about
SKILLS:
Skills are not markdown files. They're folders with scripts, assets, data, config options, and dynamic hooks
9 categories they've identified:
> Library & API Reference
> Product Verification
> Data & Analysis
> Business Automation
> Code Scaffolding
> Code Quality & Review
> CI/CD & Deployment
> Runbooks
> Infrastructure Ops
What makes a skill great:
> Don't state the obvious. Focus on what pushes Claude out of default patterns
> Gotchas section is the highest-signal content. Built from real failure points over time
> Use the file system for progressive disclosure. Reference docs, templates, scripts
> Don't railroad with rigid steps. Give information and flexibility
> Description field is for the model. It's what Claude scans to decide if a skill matches
> Skills can store memory: logs, JSON, SQLite. Use ${CLAUDE_PLUGIN_DATA} for persistence
> Give Claude scripts so it composes instead of reconstructing boilerplate
> On-demand hooks: /careful blocks destructive commands, /freeze locks edits to a directory
Distribute via repos for small teams, plugin marketplace at scale Let skills prove themselves organically before promoting
FILE SYSTEM + BASH:
Every agent benefits from a file system It represents state the agent reads into context and uses to verify its own work
You don't need to remember everything You need to know how to find it
His advice after dozens of calls with companies building general agents: "Use the bash tool more"
Instead of fetching 100 emails via tool calls and hoping the model figures it out Save to files. Search. Ground in code. Take multiple passes. Verify.
PLAYGROUNDs:
A plugin that generates standalone HTML files for visual, interactive problem-solving Architecture visualisation, design tweaking, game balancing, inline writing critique
The tip: think of a unique way of interacting with the model and ask it to express that
Bookmark this. You'll keep coming back.
T
trq212
@trq212
I put a lot of heart into my technical writing, I hope it's useful to you all. 📌 Here's a pinned thread of everything I've written. (much of this will be posted on the Claude blog soon as well)
G
Web Agents should browse the web freely, like a human would🧬
That’s why we built the most stealth browser infrastructure on the planet.
R
reformedot
@reformedot
We stealth benchmarked every major cloud browser provider
M
RT @Vercantez: pi + ghostty running entirely in a cloudflare workers durable object. sqlite based file system + js code exec + cron support…
B
At the recommendation of @sudoingX I switched from Ollama to llama.cpp today. Significant upgrade with the same old hardware! https://t.co/XbVYwk8PPy

S
sudoingX
@sudoingX
12GB of VRAM runs more intelligence than you think in 2026.
O
投稿しました!
Everything Claude Codeを眺めてみる
https://t.co/9Zic7Ylpap
E
Formal announcement of the TERAFAB project, which will be done jointly by @SpaceX and @Tesla, tonight around 8pm CT. Livestream on 𝕏.
The goal is to produce over a TERAWATT of compute per year (logic, memory & packaging) with ~80% for space and ~20% for the ground.
S
Announcing TERAFAB: the next step towards becoming a galactic civilization https://t.co/xTA70LOU0e
G
subagents in codex are very powerful
D
diegocabezas01
@diegocabezas01
Codex subagents game changer https://t.co/dx0NDKcMRl
0
How did Qwen do it
B
bnjmn_marie
@bnjmn_marie
For OpenClaw, just use Qwen3.5 27B! Q4 GGUFs match the original's model accuracy You don't need expensive hardware or models https://t.co/AJKisPXCMG
🍓
how your set up your folder is the difference between you and the great karpathy.
folders are everything.
this is a great guide into building each layer of the wondrous folder.
do bookmark this. and do implement this.
A
akshay_pachaar
@akshay_pachaar
Anatomy of the .claude/ folder
C
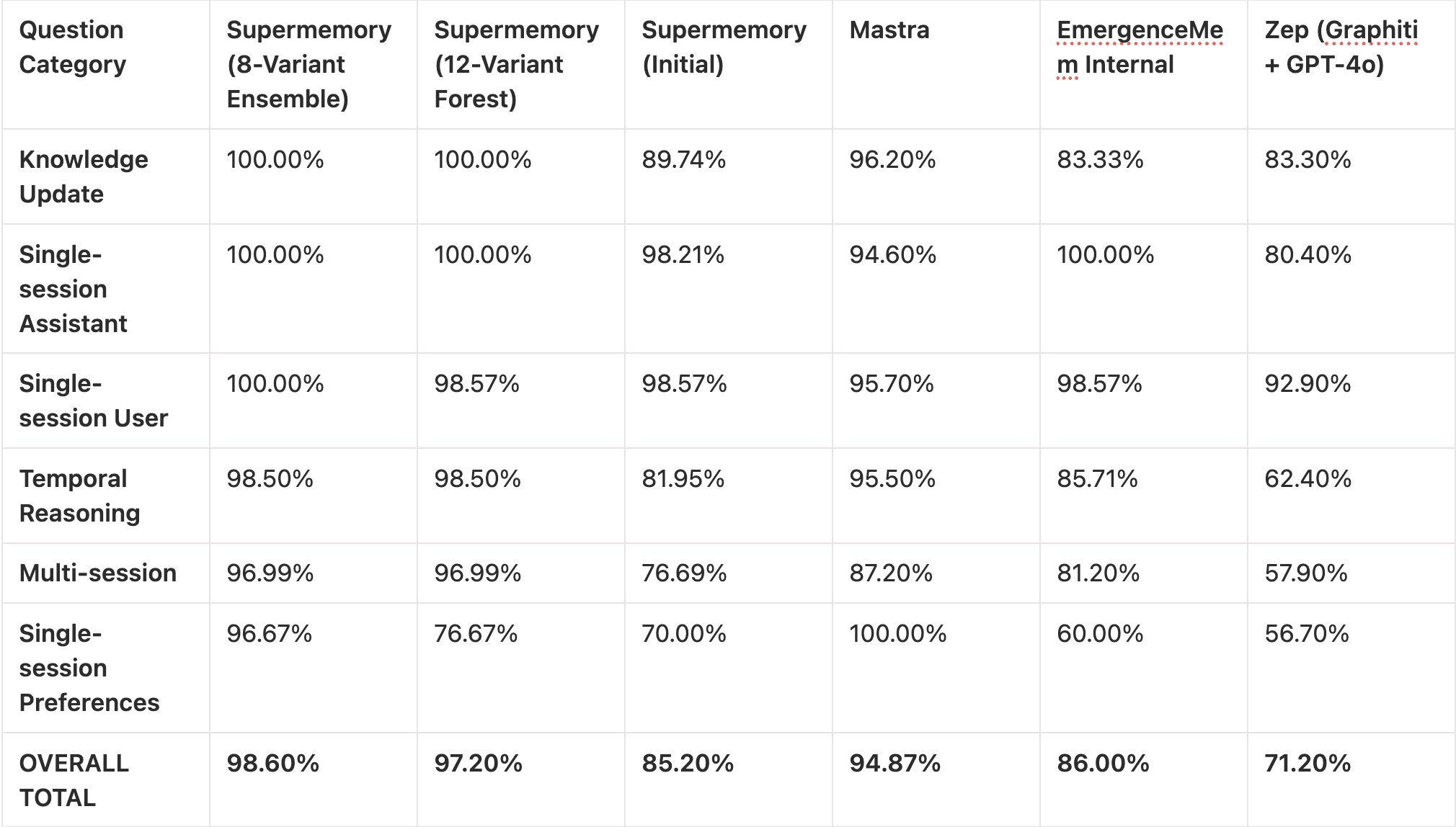
So cool: Supermemory 99% on Sota Memory!
•Achieved ~99% on LongMemEval_s using experimental ASMR (Agentic Search and Memory Retrieval) technique.
•Replaced vector search and embeddings with parallel observer agents extracting structured knowledge across six vectors from raw multi-session histories.
•Deployed specialized search agents for direct facts, related context, and temporal reconstruction; no vector database required.
Will be open source in 11 days!
D
DhravyaShah
@DhravyaShah
We broke the frontier in agent memory: Introducing ~99% SOTA memory system.